这是一个非常经典的高并发场景设计问题。**核心目标**是让Redis这个容量有限的缓存空间,尽可能只保存最常被访问的"热点"数据。
为了实现这个目标,需要一套组合策略,下图清晰地展示了从数据进入、访问到淘汰的完整流程与关键决策点:
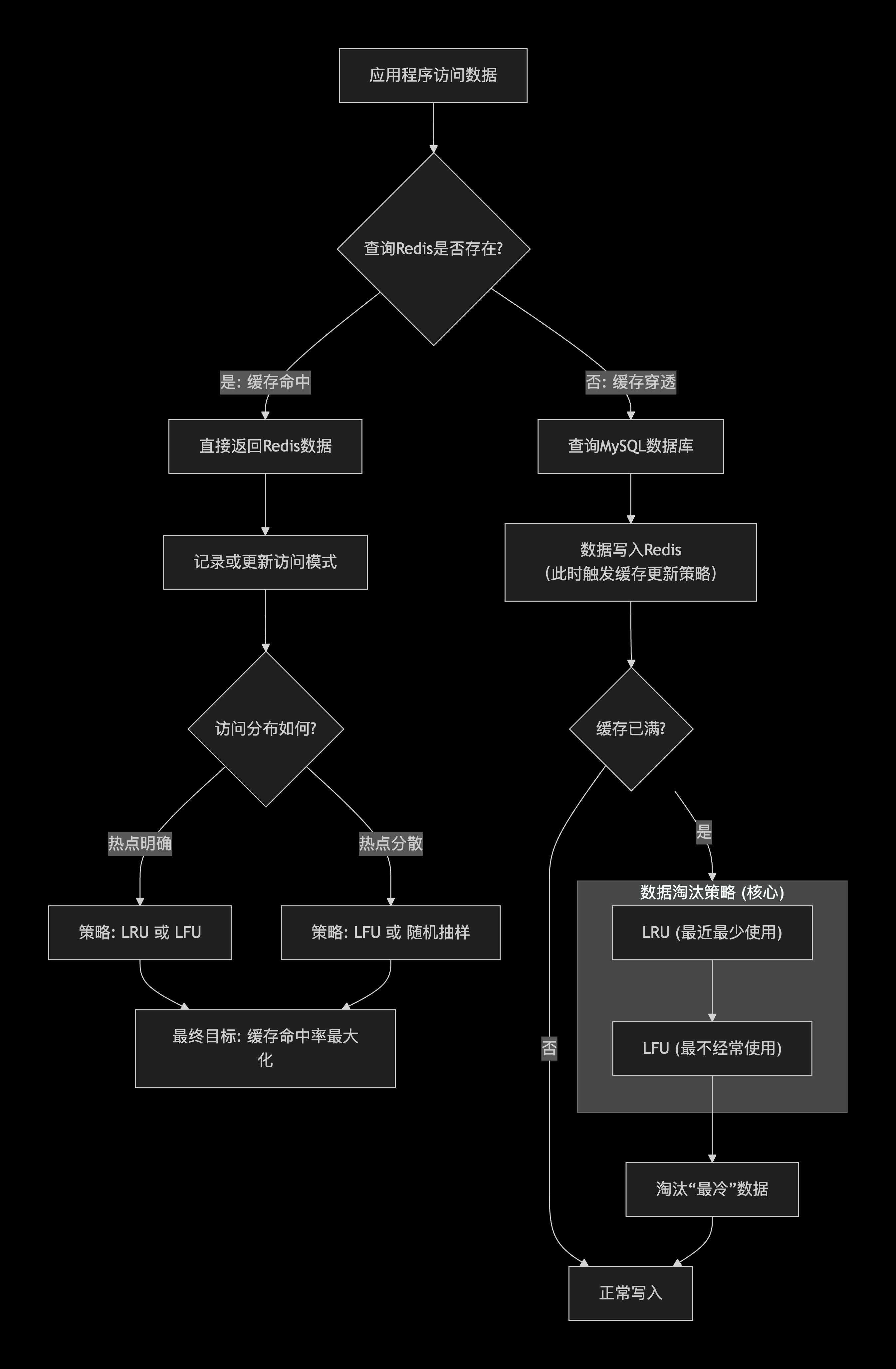
下面,我们来分解图中的各个环节,并提供具体的实施建议。
**一、 核心策略:数据淘汰策略**
这是保证Redis数据"热"的**最根本机制**。当Redis内存达到上限时,它会根据预设规则自动删除一些键。
| 策略 | 配置 (`maxmemory-policy`) | 工作原理 | 适用场景 |
| :--- | :--- | :--- | :--- |
| **LRU** | `allkeys-lru` | 淘汰**最近最少使用**的键。Redis会近似追踪访问时间戳。 | **最通用**。访问模式相对稳定,近期访问过的数据很可能再次被访问。 |
| **LFU** | `allkeys-lfu` | 淘汰**最不经常使用**的键。Redis会统计访问频率。 | 有明确、固定的热点(如少数明星商品、新闻头条),需要区分访问频率高低。 |
| **随机淘汰** | `allkeys-random` | 随机淘汰键。 | 没有明确的访问模式,或者所有数据访问概率均等,仅想简单腾出空间。 |
**生产环境建议:**
* **首选 `allkeys-lru`**:它在大多数情况下表现良好,是平衡实现复杂度和效果的最佳选择。
* **配置命令**(在 `redis.conf` 中或运行时配置):
```bash
CONFIG SET maxmemory-policy allkeys-lru
```
**二、 关键辅助:缓存更新与写入策略**
这决定了数据**何时**、**如何**从MySQL加载到Redis,是控制数据"温度"的入口。
| 策略 | 描述 | 优点 | 缺点 |
| :--- | :--- | :--- | :--- |
| **惰性删除** | 写时直接更新或删除Redis,读时若缓存缺失再从DB加载。 | 实现简单,只缓存真正被请求的数据。 | 冷数据可能偶然进入并停留一段时间。 |
| **主动预热** | 系统启动或低峰期,提前将预测的热点数据(如昨日销量TOP商品)加载到Redis。 | 高峰前准备好热点,用户体验好。 | 预测可能不准,浪费资源。 |
| **异步更新** | 数据变更时,发消息通知缓存更新,或设置较短的过期时间保证最终一致性。 | 避免缓存与数据库长期不一致。 | 架构变复杂,需消息队列等组件。 |
**建议组合使用**:日常主要依赖**惰性删除**,在大型活动前结合**主动预热**。
**三、 架构与监控保障**
这是让上述策略有效运行的基础。
- **监控与度量**
* **核心指标**:通过 `INFO stats` 命令监控 `keyspace_hits` 和 `keyspace_misses`,**计算缓存命中率**。这是衡量策略是否有效的黄金指标。
* **内存分析**:使用 `redis-cli --bigkeys` 或 `MEMORY USAGE` 命令分析大Key和内存分布。
- **键设计优化**
* **避免大Key**:将大对象(如列表、集合)拆分或压缩,防止单个Key占用过多内存,影响淘汰效率。
* **设置过期时间**:即使预期是热点数据,也**务必设置合理的TTL**(例如几小时到几天)。这是防止数据"永驻"内存的最后保险,可以与淘汰策略形成双重保障。
- **容量规划**
* 根据业务特点(如20万热点数据的大小)和服务器内存,合理设置 `maxmemory`。通常建议预留20%-30%的缓冲区。
**四、 一个简单的实施示例**
假设有一个用户查询系统,2000万用户中只有活跃用户会被频繁查询。
- **配置Redis**:
```bash
设置最大内存为4GB,使用LRU策略
maxmemory 4gb
maxmemory-policy allkeys-lru
```
- **应用层逻辑(伪代码)**:
```python
def get_user(user_id):
1. 先查Redis
user_data = redis.get(f"user:{user_id}")
if user_data:
return user_data
2. Redis没有,查MySQL
user_data = mysql.query("SELECT * FROM users WHERE id = %s", user_id)
if user_data:
3. 写入Redis,并设置1天过期(自动续期)
redis.setex(f"user:{user_id}", 86400, user_data)
return user_data
```
- **监控告警**:当缓存命中率持续低于 **85%**(这是一个经验阈值,可根据业务调整)时,触发告警,需要review淘汰策略或排查是否有访问模式变化。
**总结**
保证Redis中都是热点数据,是一个 **"策略组合 + 持续优化"** 的过程:
-
**设置 `allkeys-lru` 作为基础淘汰策略**。
-
**所有缓存键都必须设置合理的TTL**。
-
**通过惰性删除为主、主动预热为辅的方式更新缓存**。
-
**持续监控命中率、内存使用和大Key**,根据数据调整策略。
这样的设计,可以让20万容量的Redis,高效地为2000万的数据集提供高速访问服务。