本期内容为自己总结归档,7天学会Redis。其中本人遇到过的面试问题会重点标记。
(若有任何疑问,可在评论区告诉我,看到就回复)
Day 5 - Redis Cluster集群架构
5.1 数据分片与路由
5.1.1 哈希槽分配算法
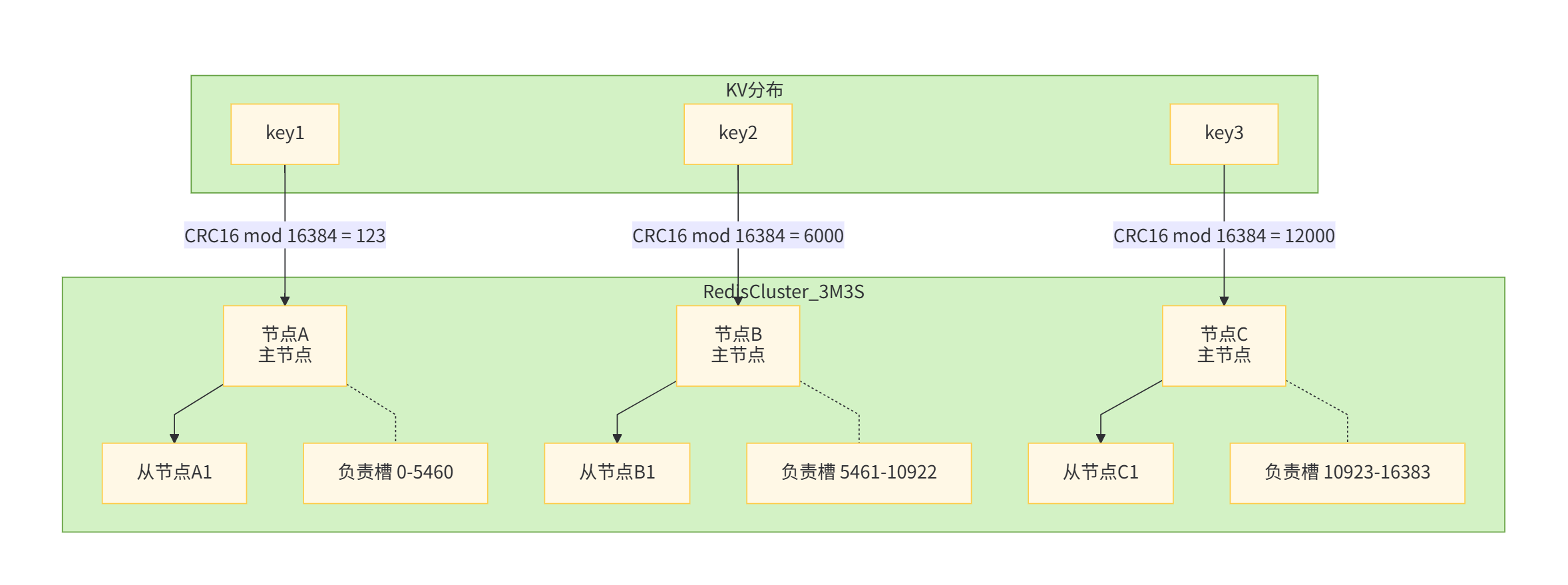
哈希槽概念
Redis Cluster采用哈希槽(Hash Slot) 作为数据分片的基本单位,整个集群共有16384个槽(0-16383)。每个键值对根据键的CRC16值模16384映射到一个具体的槽,每个槽只由一个节点负责。
为什么是16384个槽?
-
内存考虑:每个节点需要存储槽的分配信息,如果槽数太多,节点间通信的数据包会很大
-
性能考虑:16384在压缩位图中占用2KB空间,适合网络传输
-
经验值:足够满足大多数集群规模,同时保持高效
键到槽的映射:
HASH_SLOT = CRC16(key) mod 16384槽分配策略
Redis Cluster中的槽分配采用集中式配置,所有节点的槽分配信息在集群配置中统一管理。
哈希标签(Hash Tags)
为了支持多个键映射到同一个槽,Redis Cluster支持哈希标签:
bash
# 大括号{}中的内容会被用于计算哈希值
SET user:{1001}:name "张三" # 哈希标签为1001
SET user:{1001}:age 25 # 哈希标签为1001
# 这两个键会被分配到同一个槽哈希标签的计算规则:如果键包含{...},则只计算大括号内的内容。
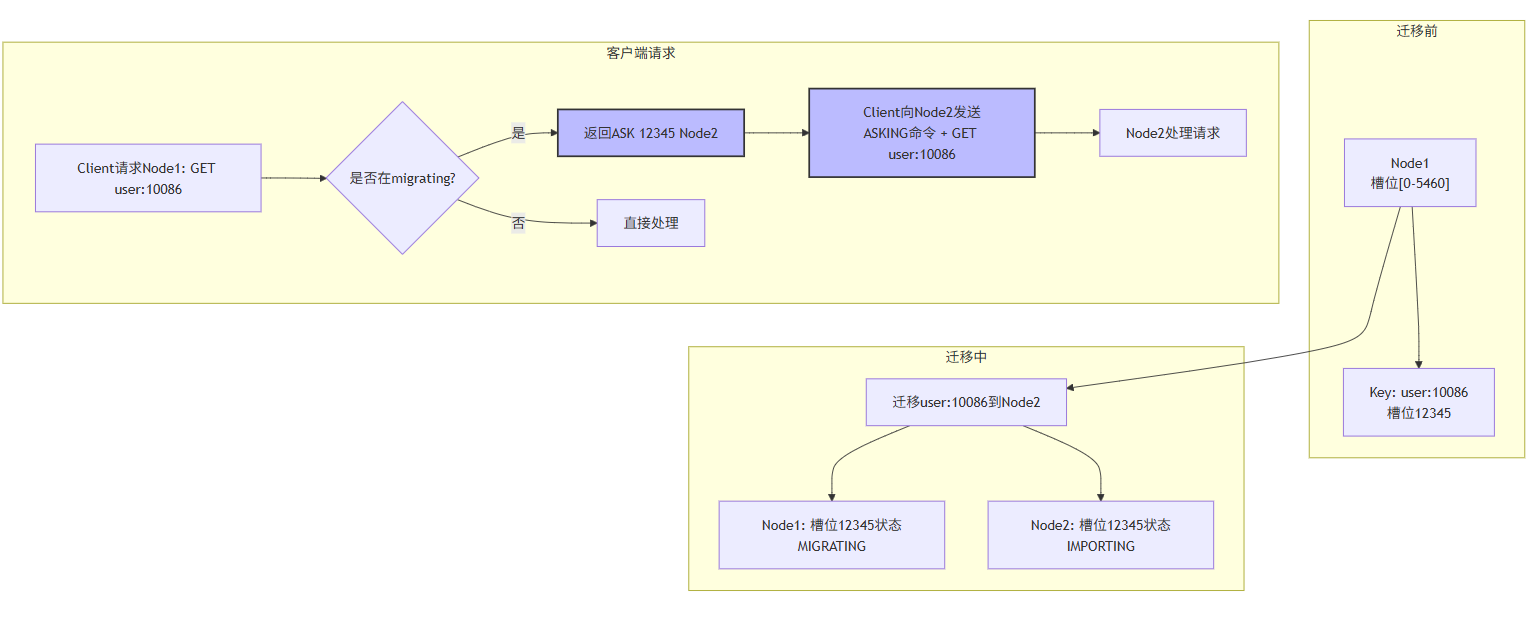
5.1.2 MOVED/ASK重定向
普通客户端(如redis-cli):
# 客户端连接Node1,但Key在Node2
SET order:10001 "value"
→ MOVED 7072 192.168.1.10:6379 # Node2地址
# 客户端需重新连接Node2再执行
redis-cli -h 192.168.1.10 -p 6379
SET order:10001 "value" # 成功MOVED重定向:
-
场景:槽位已迁移完成,客户端请求旧节点
-
响应 :
MOVED <slot> <ip:port> -
客户端动作:更新本地槽位映射表,永久重定向到新节点
ASK重定向:迁移期间的临时重定向
迁移图示:
ASK vs MOVED区别:
| 特性 | ASK | MOVED |
|---|---|---|
| 场景 | 槽位迁移中,临时重定向 | 槽位已迁移完成 |
| 客户端行为 | 只重定向本次请求,不更新槽位映射 | 更新槽位映射表,后续请求直接访问新节点 |
| 命令前缀 | 必须发送ASKING命令 |
无需特殊命令 |
| 性能影响 | 迁移期间增加RTT | 一次重定向后永久生效 |
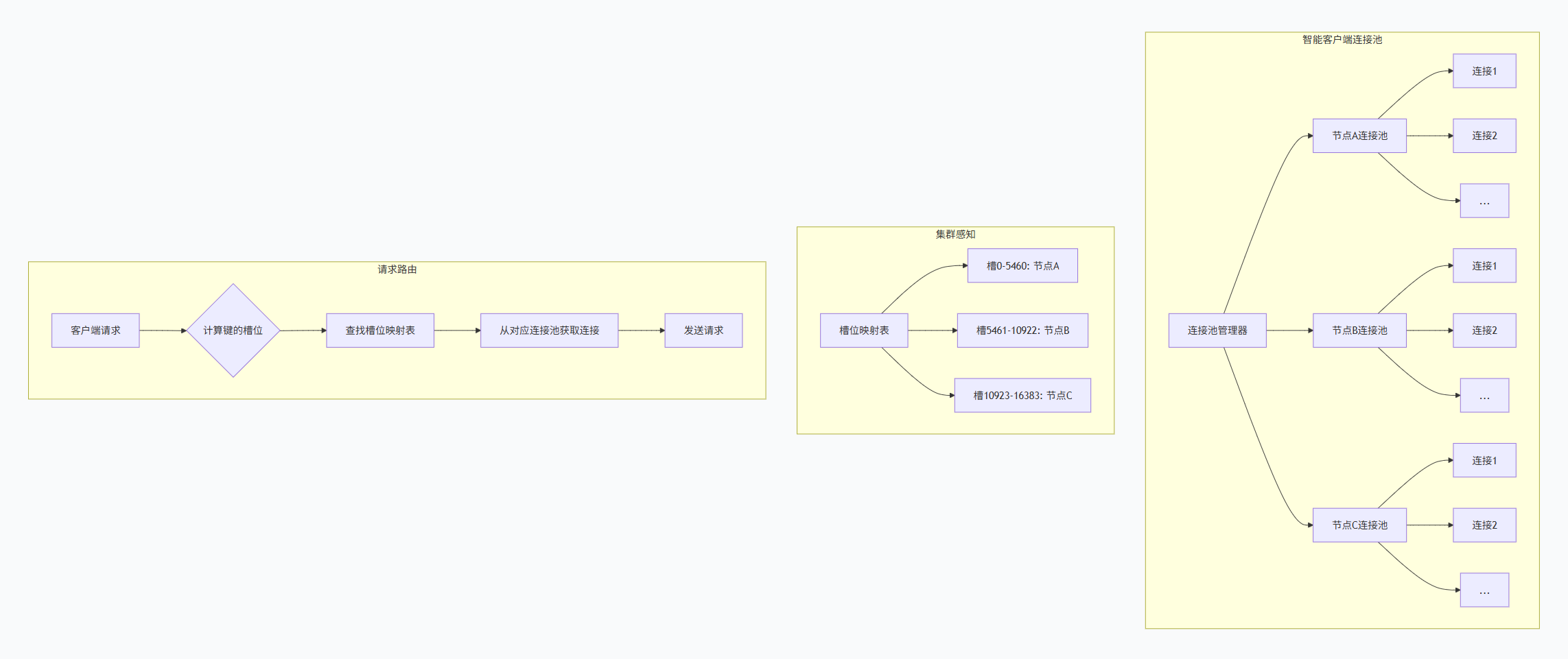
5.1.3 智能客户端实现
智能客户端需要维护以下信息:
-
槽位映射表:槽号到节点的映射关系
-
连接池:到各个节点的连接
-
重试机制:处理重定向和故障
连接池管理
5.2 集群节点通信
5.2.1 Gossip协议实现
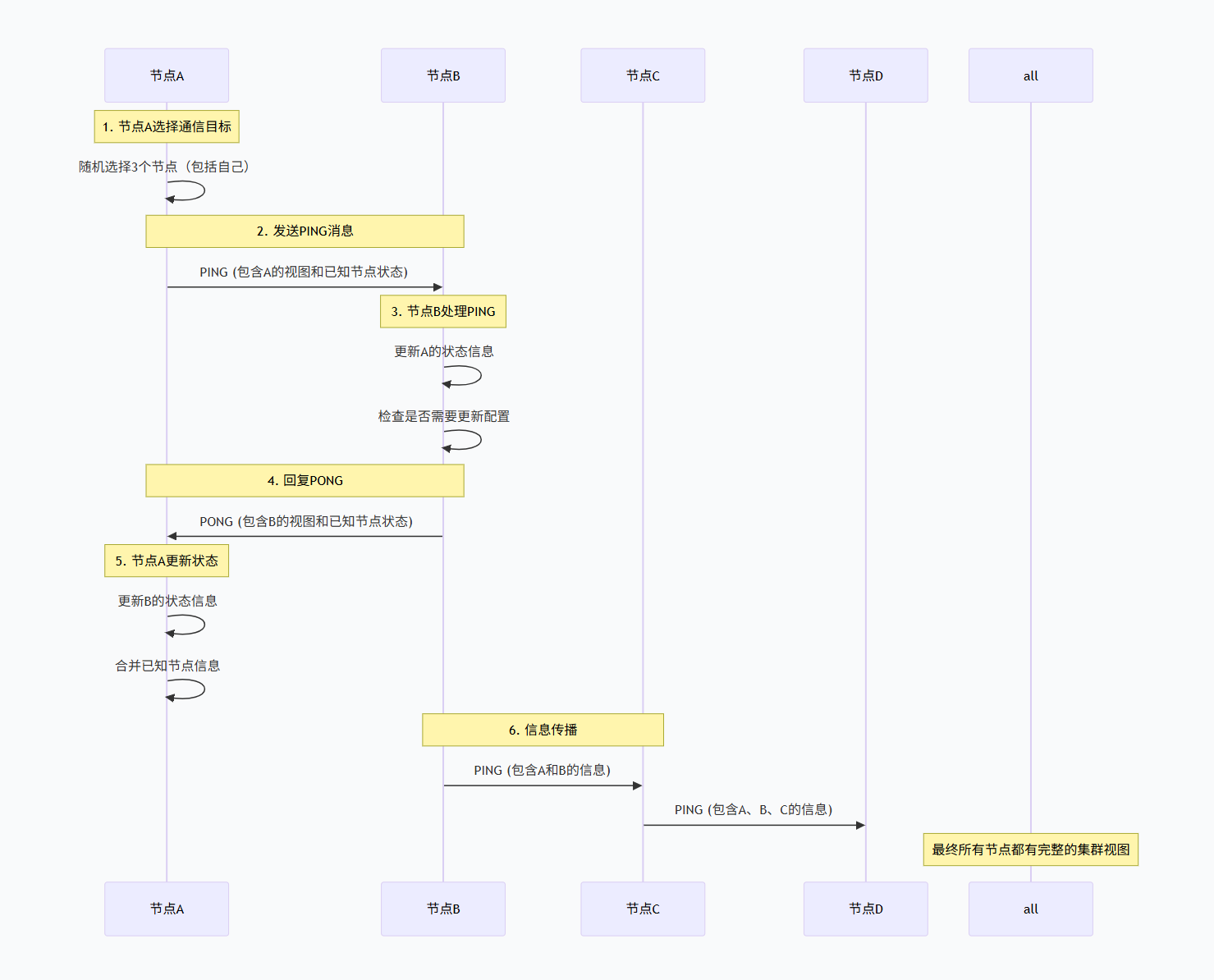
Gossip协议概述
Redis Cluster使用Gossip协议进行节点间通信,每个节点定期与其他节点交换信息,最终达到一致状态。
Gossip协议特点:
-
去中心化:没有主节点控制通信
-
最终一致性:信息最终会传播到所有节点
-
容错性强:部分节点故障不影响整体通信
-
可扩展性好:新节点加入容易
消息类型
Redis Cluster节点间通信的主要消息类型:
-
PING/PONG:心跳检测和状态交换
-
MEET:邀请新节点加入集群
-
FAIL:节点故障通知
-
PUBLISH:发布订阅消息
-
UPDATE:配置更新
Gossip通信流程
通信频率配置
bash
# redis.conf集群配置
cluster-node-timeout 15000 # 节点超时时间,默认15秒
cluster-ping-interval 1000 # PING发送间隔,默认1秒
cluster-slave-validity-factor 10 # 从节点有效性因子通信频率计算:
每个节点每秒发送: NODE_COUNT / 10 个PING消息
例如:10个节点的集群,每个节点每秒发送1个PING5.2.2 故障检测与转移
故障检测流程
Redis Cluster的故障检测分为两个阶段:
阶段1:疑似故障(PFAIL)
-
单个节点在
cluster-node-timeout时间内未收到目标节点的PONG回复 -
该节点将目标节点标记为PFAIL
-
PFAIL状态仅在本地记录,不广播
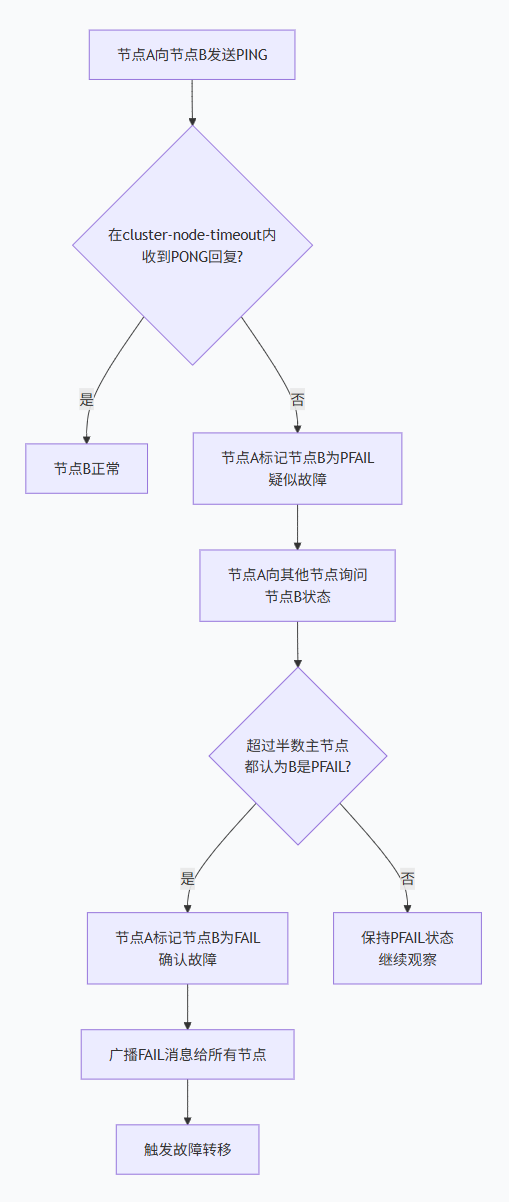
阶段2:确认故障(FAIL)
-
当超过半数的主节点都标记某节点为PFAIL时
-
第一个发现此情况的节点将其标记为FAIL
-
广播FAIL消息给所有节点
故障转移流程
当主节点故障时,其从节点会发起故障转移:
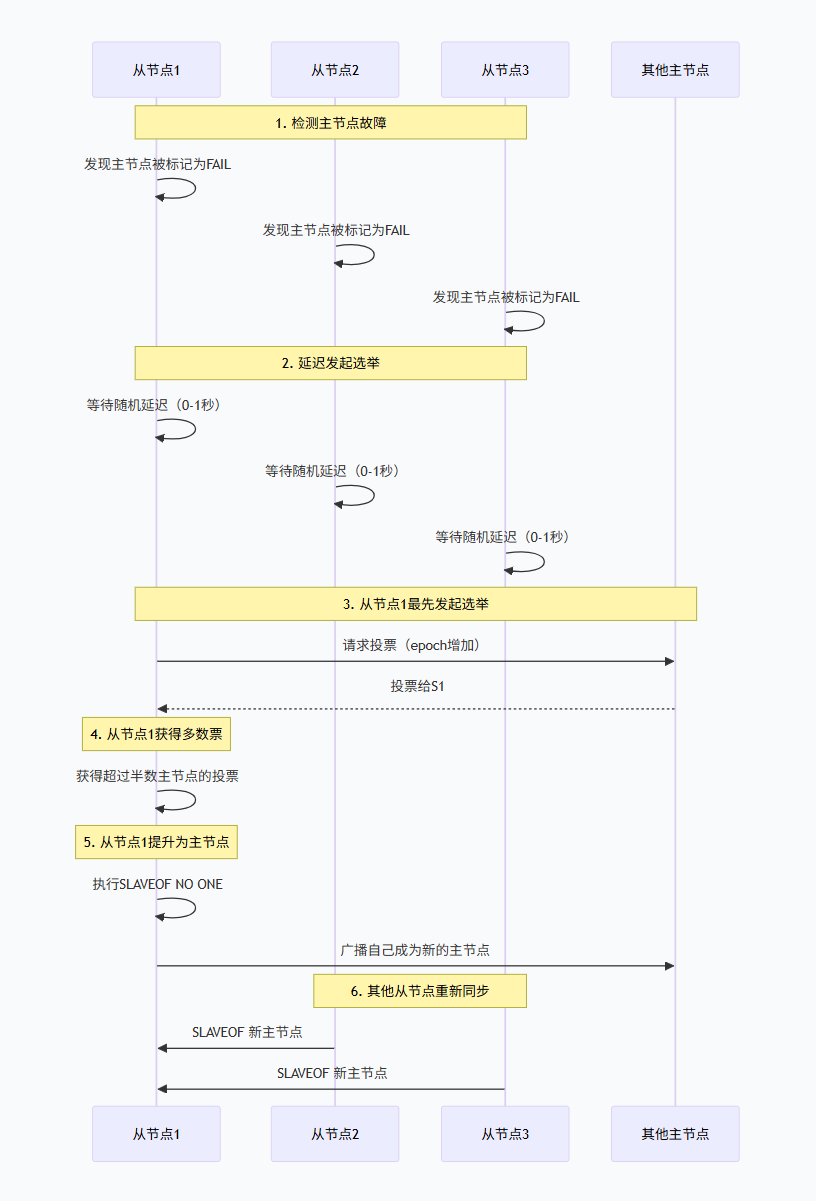
选举算法细节
选举条件:
-
从节点的主节点处于FAIL状态
-
主节点负责的槽不为空
-
从节点与主节点的复制连接断开时间不超过指定值
投票规则:
-
每个主节点在每个配置纪元(epoch)只能投一票
-
先到先得:优先投票给最先请求的从节点
-
需要获得超过半数的主节点投票
配置纪元(epoch):
-
集群范围单调递增的64位数字
-
用于区分不同的集群配置版本
-
每次配置变更(故障转移、槽迁移)都会增加epoch
5.2.3 集群伸缩操作
添加新节点
步骤1:启动新节点
bash
# 新节点配置文件
port 6380
cluster-enabled yes
cluster-config-file nodes-6380.conf
cluster-node-timeout 15000
appendonly yes步骤2:加入集群
bash
# 在集群任意节点执行
redis-cli -h 192.168.1.100 -p 6379 cluster meet 192.168.1.104 6380步骤3:分配槽位
bash
# 从现有节点迁移槽到新节点
# 使用redis-trib.rb或redis-cli
redis-cli --cluster reshard 192.168.1.100:6379节点角色变更
主节点降级为从节点:
bash
# 让节点成为另一个节点的从节点
redis-cli -h 192.168.1.104 -p 6380 cluster replicate <node-id>从节点提升为主节点:
bash
# 故障转移后自动提升
# 或手动故障转移(主节点在线时)
redis-cli -h 192.168.1.101 -p 6379 cluster failover移除节点
步骤1:迁移槽位
bash
# 将要移除节点的槽迁移到其他节点
redis-cli --cluster reshard --cluster-from <node-id> \
--cluster-to <new-node-id> --cluster-slots <num> \
--cluster-yes 192.168.1.100:6379步骤2:移除空节点
bash
# 当节点没有槽位时,可以从集群中移除
redis-cli -h 192.168.1.100 -p 6379 cluster forget <node-id>步骤3:关闭节点
bash
# 安全关闭节点
redis-cli -h 192.168.1.104 -p 6380 shutdown save集群重新分片
重新分片是将槽从一组节点迁移到另一组节点的过程:
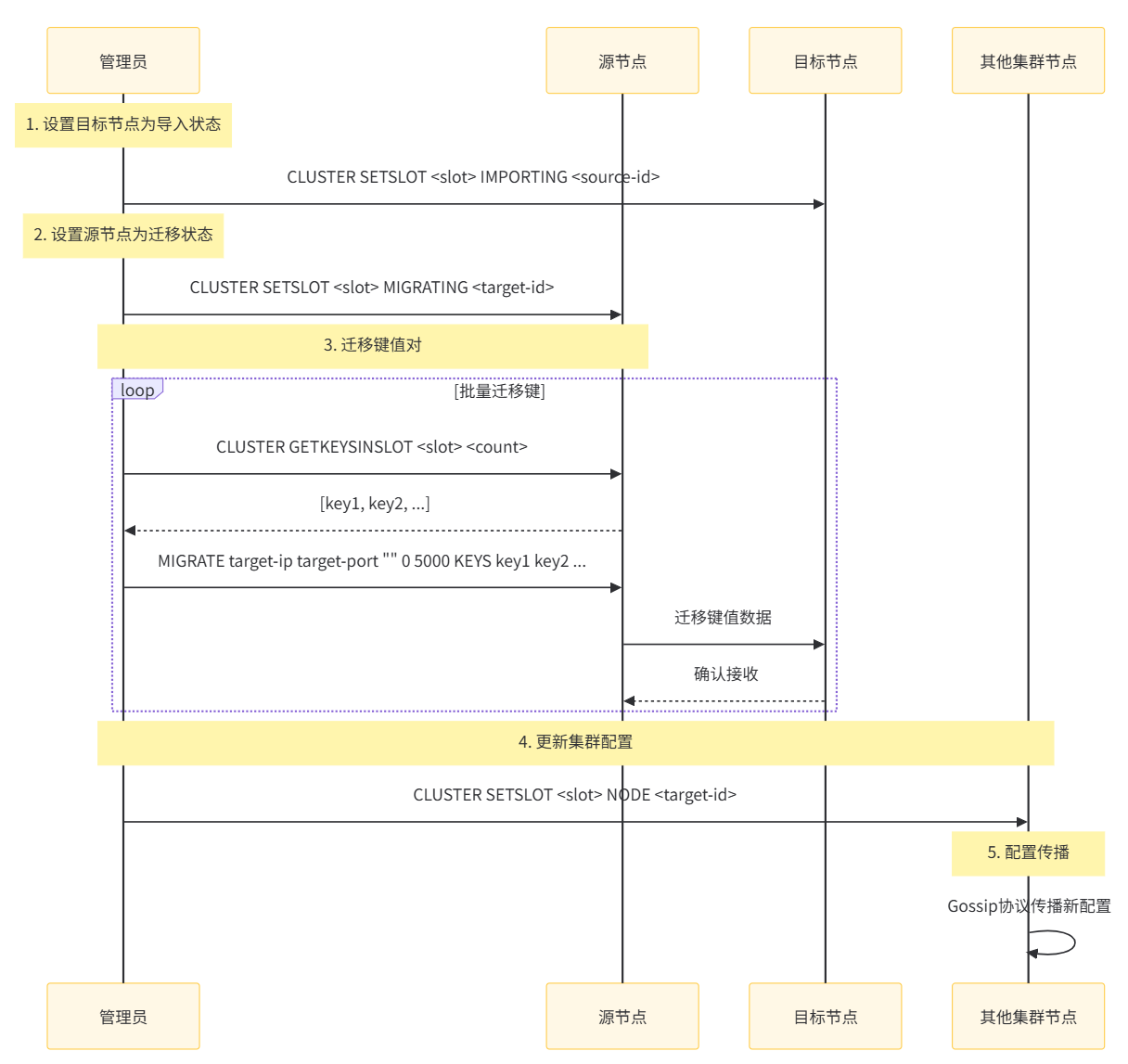
5.3 面试高频考点
考点1:Redis Cluster的数据分片原理是什么?
面试回答:
Redis Cluster采用**哈希槽(Hash Slot)**进行数据分片,核心原理如下:
-
槽数量:整个集群有16384个槽(0-16383),每个槽是数据分片的基本单位
-
键到槽映射:使用CRC16算法计算键的哈希值,然后模16384得到槽号:
text
slot = CRC16(key) mod 16384 -
槽分配:集群启动时,槽被分配给各个主节点。每个主节点负责一部分槽
-
哈希标签 :支持使用
{}指定哈希标签,确保相关键分配到同一个槽 -
动态重分片:支持运行时迁移槽,重新平衡数据分布
这种设计的优点:
-
负载均衡:槽均匀分布到所有节点
-
可扩展性:通过迁移槽实现水平扩展
-
数据局部性:相关数据可通过哈希标签放在同一节点
-
高效路由:客户端可缓存槽到节点的映射
考点2:MOVED和ASK重定向的区别?
面试回答:
MOVED和ASK都是Redis Cluster中的重定向机制,但用途不同:
MOVED重定向:
-
含义:槽已永久迁移到新节点
-
响应格式 :
-MOVED <slot> <ip>:<port> -
触发条件:
-
客户端请求的键不属于当前节点负责的槽
-
槽迁移已完成,集群配置已更新
-
-
客户端处理:更新槽缓存,后续请求直接发往新节点
ASK重定向:
-
含义:槽正在迁移过程中,键可能已迁移到新节点
-
响应格式 :
-ASK <slot> <ip>:<port> -
触发条件:槽处于迁移状态,且请求的键已迁移到目标节点
-
客户端处理:
-
向目标节点发送ASKING命令
-
重新发送原命令
-
不更新槽缓存(因为迁移可能未完成)
-
关键区别:
-
MOVED表示永久重定向 ,ASK表示临时重定向
-
MOVED要求客户端更新缓存,ASK不更新缓存
-
MOVED用于槽迁移完成后的路由,ASK用于迁移过程中的路由