基于检索增强的漫画/图片序列上色任务。
intro

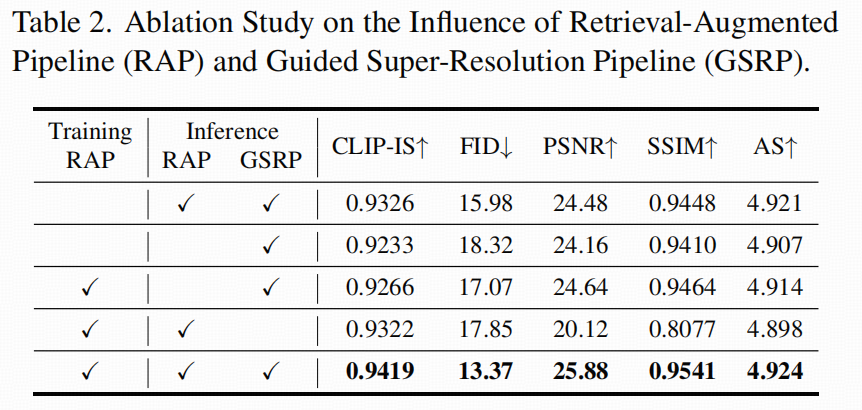
现有问题:不是把一张黑白图随便上色,而是要在同一角色跨多张分镜/多帧时,尽量保持发色、衣服配色等"身份颜色(ID color)"一致,而且还要让操作流程"像工具"一样好用:不需要为每个角色单独 finetune,也不强行抽取显式的 ID embedding。论文把整个方案拆成三个阶段:RAP(检索增强)、ICP(in-context 扩散上色)、GSRP(引导式超分复原)。
任务设定:Reference-based Image Sequence Colorization
-
输入:一张待上色的黑白图(来自漫画/分镜序列中的某一帧)+ 一个"参考图池"(同章节或同序列里若干张已经有颜色的图)。
-
输出:一张彩色结果,要求在序列层面尽量保持角色/物体的颜色身份一致(例如同一角色的头发颜色在多帧一致)。
-
关键难点:参考池里信息多、分镜构图变化大、同角色会变形/遮挡/局部出现;如果只做"全图风格迁移式上色",很容易把颜色"上对了氛围但上错了人"。
method
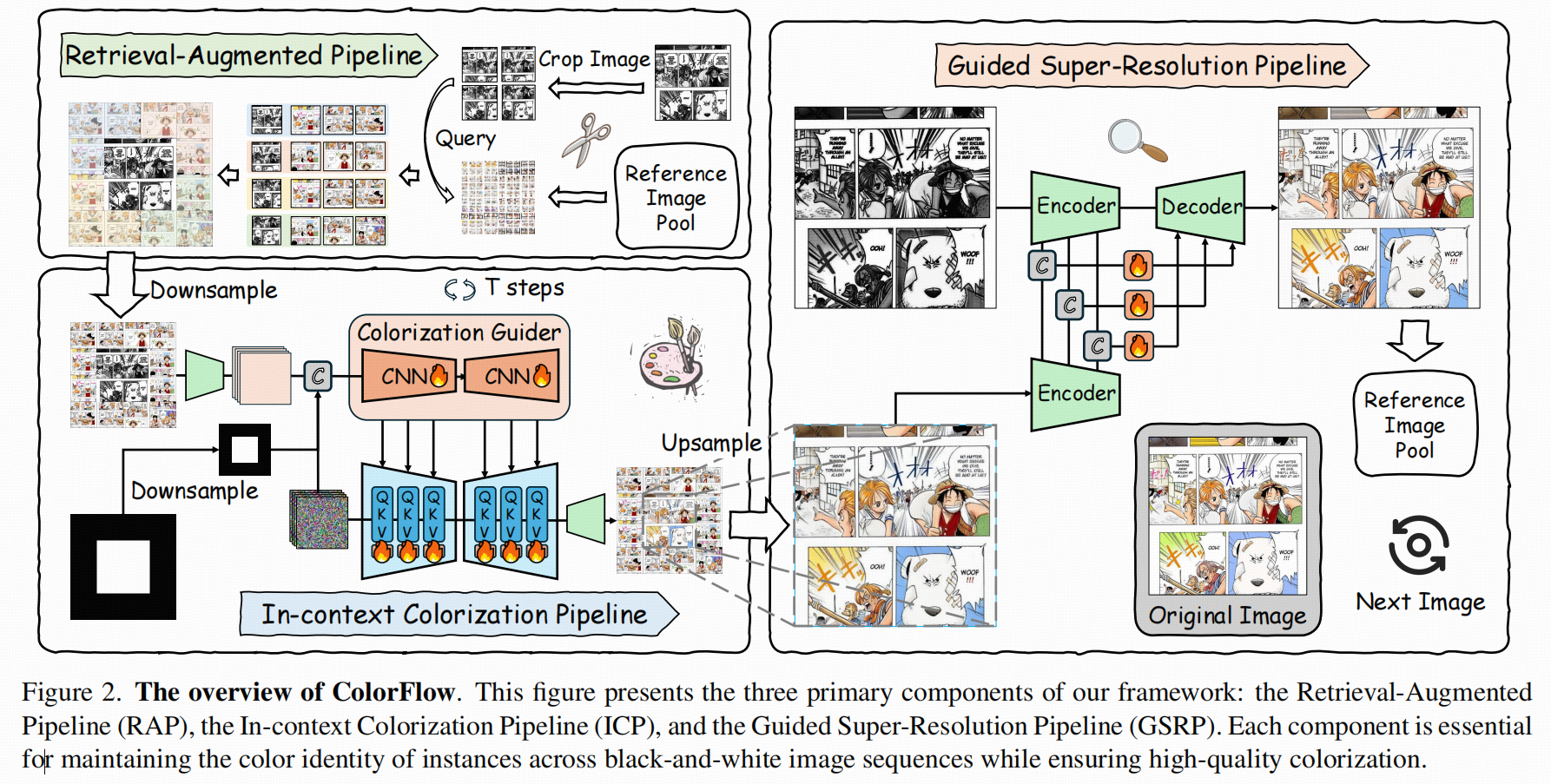
Retrieval-Augmented Pipeline
目的:把"对的颜色线索"先捞上来。这一步非常像 RAG 的"检索"思想:先从参考池里找最相关的彩色片段,再把这些片段组织成一个结构化的条件输入。
怎么切 patch(为什么是 4 个重叠 patch,且覆盖 3/4 尺寸)
-
对输入黑白图:切成 4 个重叠 patch(左上/右上/左下/右下),每个 patch 覆盖原图的 3/4 宽高。这样做的直觉是:
-
角色可能跨越中心线或边界,用重叠 + 大 patch能把关键局部(脸、头发、衣服)尽量完整包含进去;
-
同时还能保留一定全局上下文(避免只看局部导致错配)。
-
-
对每张参考彩色图:做 5 个 patch:同样的 4 个重叠 patch + 整张图 patch(full image),让检索既能匹配局部,也能在必要时用全局做兜底。
怎么检索(CLIP embedding + 余弦相似度 + top-k)
-
用预训练 CLIP image encoder对 query patch 和 reference patch 编码得到 embedding。

-
对每个 query patch,和所有 reference patches 做余弦相似度,取每个区域最相似的 top-3 patch。
-

"拼贴(stitching)"成复合条件图(composite image)
-
把检索到的结果按空间位置"拼回去",形成一个 composite reference image(论文中强调这种空间摆放能让后续模型更容易对齐上下文)。
-
训练时还会构造与之对应的"目标彩色拼贴"(把当前黑白帧对应的真彩色图按同样方式拼贴),形成训练对。
可以理解为:RAP不去做精确实例匹配,而是先保证"参考里大概率就有这人/这件衣服/这个场景的颜色线索",把"可用信息密度"先抬起来。
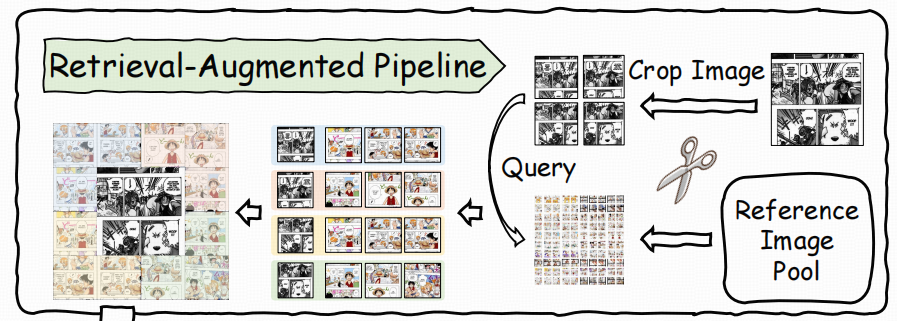
In-context Colorization Pipeline
------扩散模型怎么"靠自注意力"学会对号入座。
论文最核心的设计有两点:
-
把参考和彩色目标放到同一"画布(canvas)"里,让扩散 U-Net 的 self-attention天然承担"在上下文里找对应"的工作;
-
做一个双分支结构:一支更偏"抽取/传递颜色身份线索",另一支做主干去噪生成。
关键结构:Colorization Guider(辅助分支)
-
由扩散模型 U-Net 的卷积层"复制初始化"(replicate weights)得到;
-
输入包含三部分拼接:
-
噪声 latent zt(扩散过程中的当前状态),
-
复合条件图(composite image)经 VAE 编码得到的 latent,
-
下采样后的 mask m(指示哪些区域是需要上色/生成的区域)。
-
-
这个 Guider 输出的多尺度特征会逐层(progressively)注入主 U-Net,让条件信息从"文本级/全局级"变成像素级、稠密的条件嵌入。
-
loss:
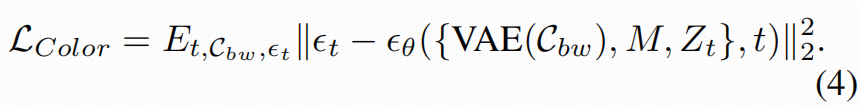
作用是"更贴合上色任务的 Control 分支":不是只给一个向量条件,而是让参考拼贴图里的颜色线索,以多尺度特征的形式持续影响去噪过程。
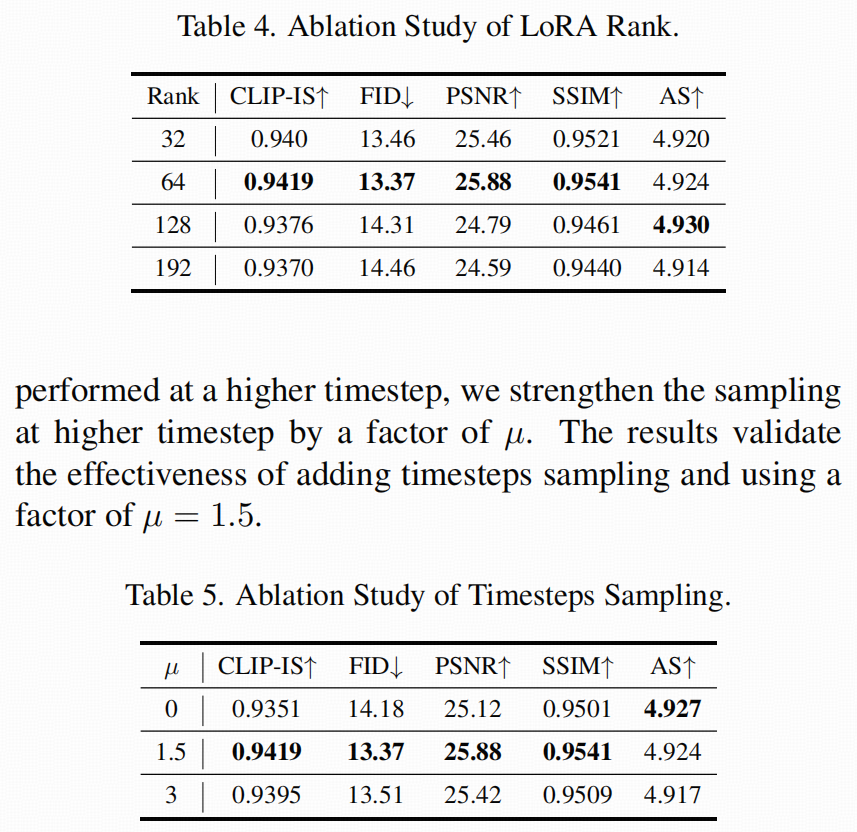
LoRA 微调:为什么说"轻量"且不容易把底模能力改坏
- 他们用 LoRA 对预训练扩散模型做微调,用较小的低秩更新来适配上色任务,从而"保留底模已有的生成/上色能力"。
训练目标:为什么"去噪"就能实现上色?
-
ICP 的训练目标基本就是标准扩散训练:从真彩色 latent z0z_0z0 正向加噪得到 ztz_tzt,训练 U-Net 预测噪声(或等价参数化),最小化噪声预测误差。
-
条件信息(复合参考 + mask + guider 特征)把"结构必须对齐黑白图""颜色要跟参考一致"的约束注入到去噪轨迹里:
-
结构约束来自黑白内容与 mask(哪些区域要生成、线稿/明暗在哪里);
-
颜色身份约束来自检索到的参考拼贴,以及 in-context self-attention 的"对齐能力"。
-
推理技巧:Timestep shifted sampling(为什么强调高 timestep)
- 论文认为"上色主要在更高噪声阶段就决定了",所以把采样的 timestep 做偏移,让采样更偏向高 timestep(论文里给了系数,取 1.5)。
风格增强:Screenstyle augmentation(适配漫画网点/印刷风格)
- 用 ScreenVAE 把彩色漫画转换成日式黑白网点风格输出,再与普通灰度图做随机线性插值,扩充"黑白风格分布",提升泛化。
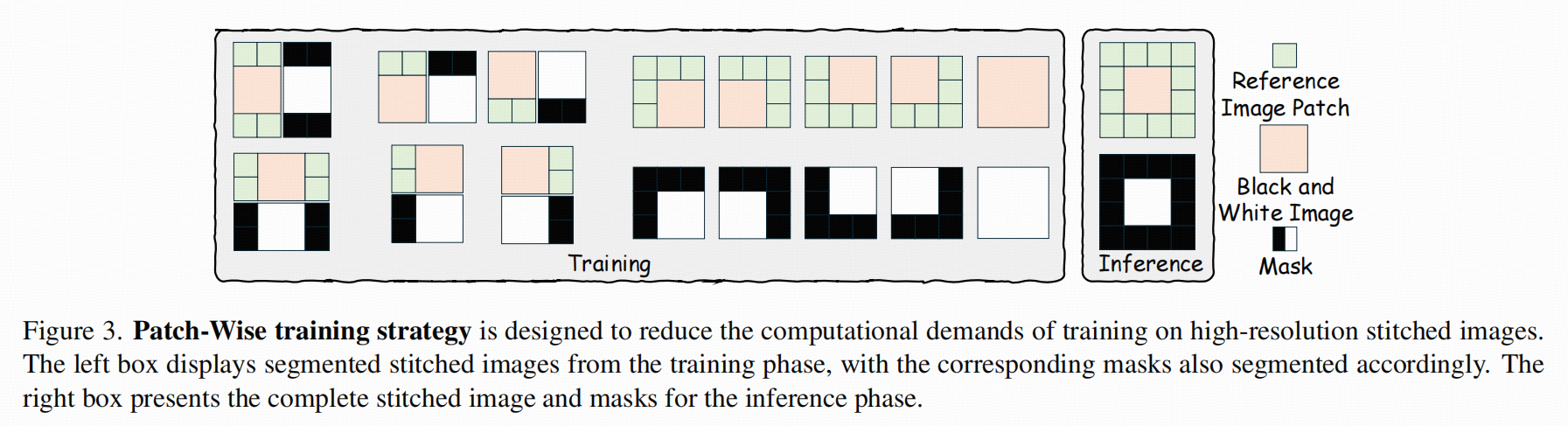
训练省显存:Patch-wise training strategy
- 因为拼贴后的图分辨率高、成本大,所以训练时随机裁剪一块来训,但保证黑白区域始终被包含,mask 也同步裁剪;推理时用完整拼贴图获取最大上下文。

Guided Super-Resolution Pipeline
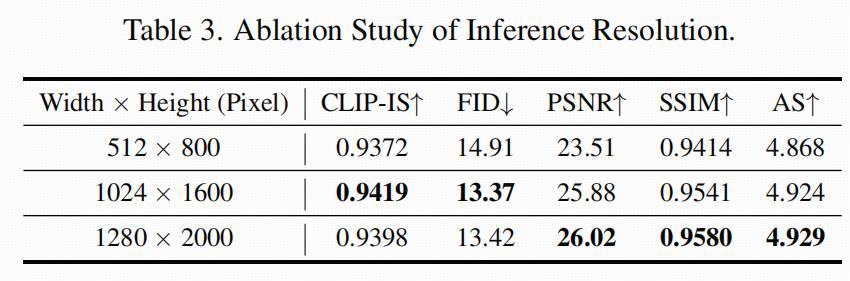
------解决"低分辨率上色 + 解码形变"的后处理硬伤。ICP 往往在较低分辨率 latent 上做生成,最后 VAE 解码到高分辨率时容易产生结构细节扭曲。GSRP 的思路是:用高分辨率黑白图把结构细节"拉回来"。
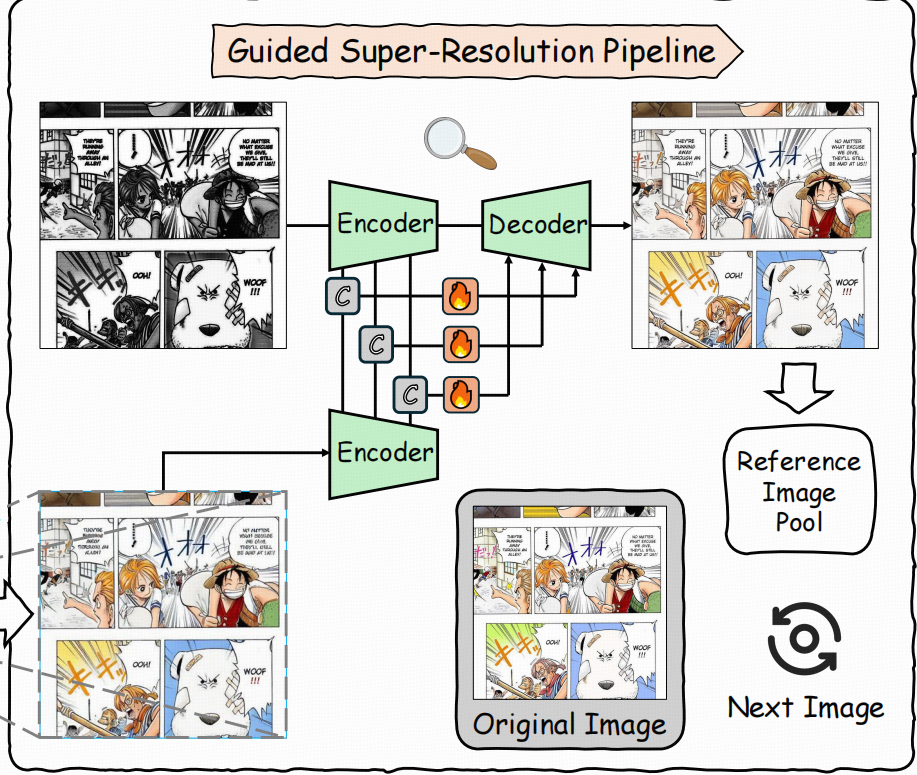
做法要点:
-
把 ICP 输出的低分辨率彩色结果先插值上采样到高分辨率;
-
将"高分黑白图"和"上采样彩色图"都送入 VAE encoder,拿到多尺度中间特征;
-
用 skip guidance:把两路 encoder 的中间特征拼接,经融合模块后送到 decoder 对应层,做细节复原。
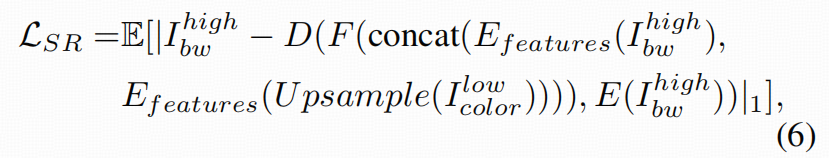
experiment
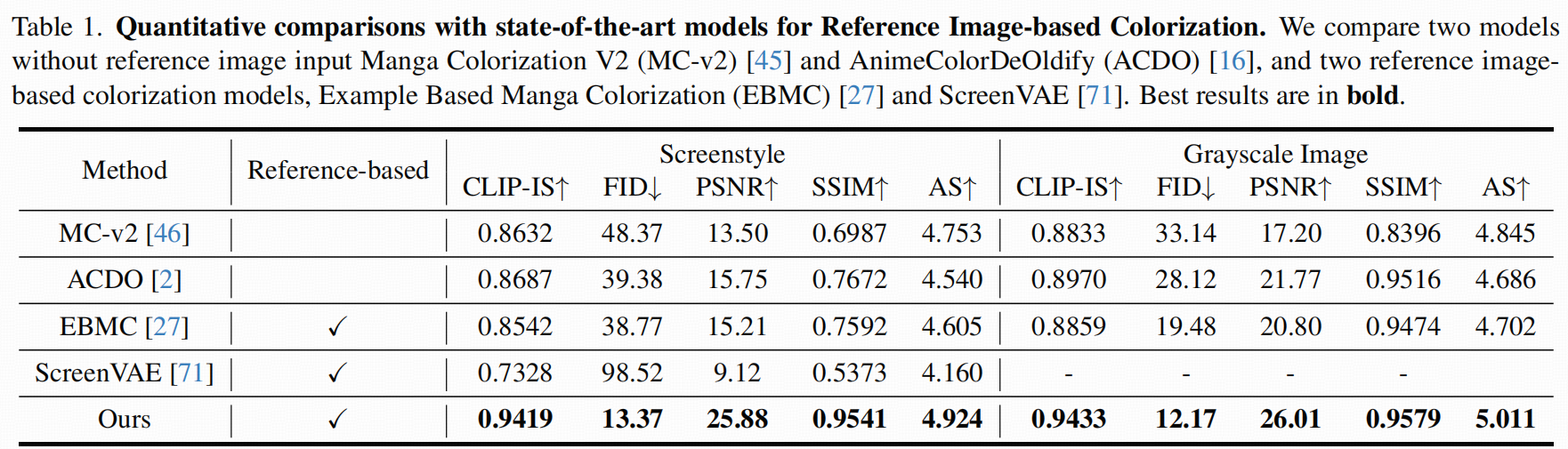
构建了 ColorFlow-Bench(30 个章节,每章 50 张黑白 + 40 张参考图)。