在数据库设计与优化中,主键(Primary Key)和唯一索引(Unique Index)是保障数据唯一性的重要机制,二者常被混淆,但在本质定位、约束特性、底层实现及应用场景上存在显著差异。正确理解它们的区别,是构建高效、可靠数据模型的基础。本文将从多维度系统剖析二者的核心差异,并结合实际案例说明其适用场景。
一、核心定义与设计初衷的本质差异
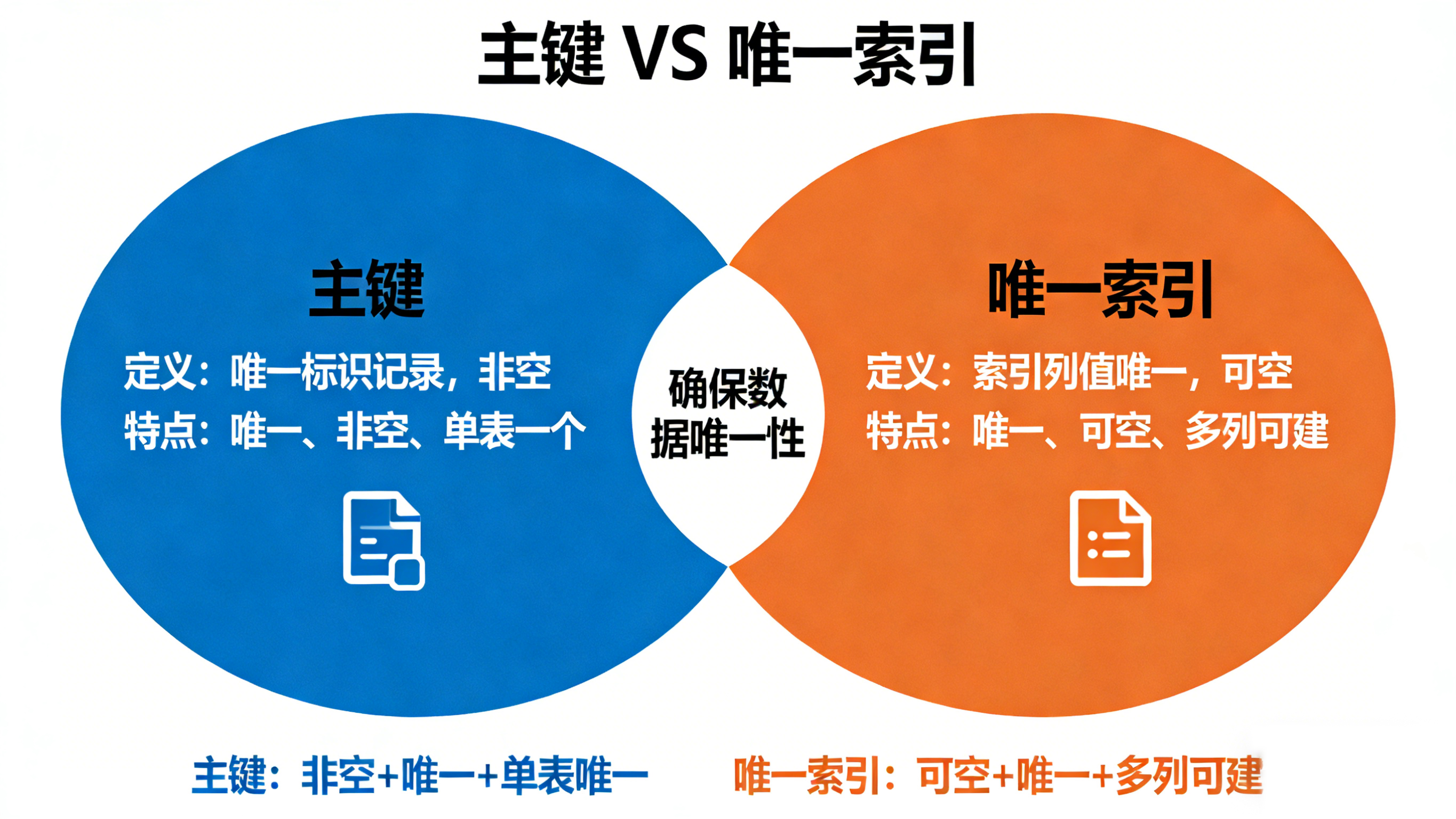
主键和唯一索引的核心共性是"保证数据唯一性",但设计初衷和本质定位截然不同,这也是二者所有差异的根源。
1. 主键:表的"唯一标识",数据逻辑的核心
主键是用于唯一标识表中每一行记录 的字段或字段组合,是表的核心逻辑标识,其设计初衷是建立数据的唯一性基准,为表与表之间的关联(外键关联)提供可靠依据。主键不仅仅是一种索引结构,更是一种强制性的数据完整性约束,直接定义了数据的组织逻辑。
例如,用户表中的user_id、订单表中的order_id,通过主键可以明确区分每一条用户记录或订单记录,是后续进行多表连接、数据检索的核心依据。
2. 唯一索引:数据的"唯一性校验工具",查询优化的辅助手段
唯一索引是一种用于保证指定字段或字段组合数据唯一性 的索引结构,其设计初衷是辅助数据完整性校验,并提升基于该字段的查询效率。它是一种可选的约束机制,更多聚焦于业务层面的唯一性要求,不直接承担数据标识的核心职责。
例如,用户表中的email、username字段,通过创建唯一索引可避免重复注册,但这些字段并非表的核心标识,仅用于业务规则约束。
二、关键特性差异对比
基于设计初衷的不同,主键与唯一索引在约束规则、数量限制、空值处理等关键特性上呈现明显差异,具体对比如下表所示:
| 对比维度 | 主键(Primary Key) | 唯一索引(Unique Index) |
|---|---|---|
| 唯一性约束 | 强制唯一,不可重复 | 强制唯一,不可重复 |
| 空值允许 | 严格禁止NULL值(多数数据库,如MySQL;Oracle联合主键允许部分NULL) | 允许NULL值,但仅能存在一个(视数据库而定,如MySQL InnoDB) |
| 数量限制 | 一个表仅能有一个主键(可是联合主键) | 一个表可创建多个唯一索引 |
| 索引类型默认值 | 多数数据库默认创建聚簇索引(如MySQL InnoDB、SQL Server) | 默认创建非聚簇索引(二级索引) |
| 外键关联支持 | 可作为其他表的外键引用目标(核心用途之一) | 通常不用于外键关联(语义上不具备唯一标识属性) |
| 创建方式 | 通过PRIMARY KEY约束定义,自动创建索引 | 通过UNIQUE约束或CREATE UNIQUE INDEX语句创建 |
三、底层实现差异:聚簇索引与非聚簇索引的影响
主键与唯一索引的底层索引结构差异,直接影响数据库的查询和写入性能,这是二者在技术实现层面的核心区别之一。
1. 主键的底层实现:聚簇索引主导数据存储
在主流数据库(如MySQL InnoDB)中,主键默认对应聚簇索引。聚簇索引的核心特点是"索引与数据物理存储绑定",即索引的叶子节点直接存储表的完整行数据,数据行按照主键的顺序在磁盘上排序存储。这种结构使得基于主键的查询效率极高,无需额外"回表"操作,可直接定位到数据的物理位置。
若表未显式定义主键,数据库会自动选择唯一非空字段作为聚簇索引;若不存在此类字段,则会隐式创建一个内部行ID作为聚簇索引(如MySQL InnoDB的隐藏主键)。
2. 唯一索引的底层实现:非聚簇索引的辅助作用
唯一索引默认创建非聚簇索引(二级索引),其叶子节点仅存储索引列的值和对应的主键值,而非完整的行数据。当通过唯一索引查询时,数据库需先通过索引找到主键值,再通过主键对应的聚簇索引查找完整数据,这个过程称为"回表"。
相比主键的聚簇索引,唯一索引的查询效率略低(需额外回表步骤),但写入和更新性能开销较小,因为无需维护数据行的物理排序顺序。
四、实际应用场景:如何选择主键与唯一索引?
基于上述差异,主键与唯一索引的应用场景需严格区分,避免混用导致数据模型混乱或性能问题。
1. 主键的适用场景
-
需要唯一标识表中每一行记录的场景(如用户ID、订单ID);
-
需要与其他表建立外键关联的场景(主键作为关联基准);
-
追求高效查询性能的核心字段(基于聚簇索引的快速定位)。
示例:MySQL中创建用户表,以自增ID作为主键
sql
CREATE TABLE users (
user_id INT PRIMARY KEY AUTO_INCREMENT, -- 主键(聚簇索引)
username VARCHAR(50),
email VARCHAR(100)
);2. 唯一索引的适用场景
-
业务层面需要保证唯一性,但无需作为表核心标识的字段(如邮箱、手机号、身份证号);
-
允许空值的唯一性约束场景(如用户可选填的唯一邀请码);
-
需要提升多个唯一性字段查询效率的场景(如同时对邮箱和手机号创建唯一索引)。
示例:为用户表的邮箱和手机号添加唯一索引
sql
ALTER TABLE users
ADD UNIQUE INDEX idx_email (email), -- 唯一索引(非聚簇)
ADD UNIQUE INDEX idx_phone (phone); -- 多个唯一索引五、常见误区澄清
误区1:主键就是唯一索引,唯一索引可以替代主键
错误。主键是具备唯一性约束的"唯一标识",而唯一索引是"唯一性校验工具"。主键的非空性、数量限制和外键支持特性,是唯一索引无法替代的。若用唯一索引替代主键,会导致数据模型失去核心标识,无法建立可靠的表关联。
误区2:唯一索引允许多个NULL值
错误。多数数据库(如MySQL、SQL Server)中,唯一索引允许存在一个NULL值,因为数据库认为"NULL不等于任何值(包括NULL)",多个NULL会被判定为重复值,无法插入。仅部分特殊配置下可能存在例外,需谨慎使用。
误区3:索引越多越好,可大量创建唯一索引
错误。索引会增加写入(插入、更新、删除)操作的开销,因为每次数据变更都需同步维护索引结构。建议单表索引数量不超过5个,唯一索引仅用于必要的业务唯一性约束场景。
六、总结
主键与唯一索引的核心差异在于"身份定位":主键是表的"唯一身份证",承担数据标识和关联核心职责,具备严格的非空和数量限制,默认对应高效的聚簇索引;唯一索引是"唯一性校验标签",用于辅助业务规则约束和查询优化,允许空值、支持多索引创建,默认对应非聚簇索引。
在数据库设计中,应遵循"主键定标识,唯一索引定约束"的原则:用主键确立数据的核心逻辑,用唯一索引保障业务字段的唯一性,结合二者的特性实现数据完整性与性能的平衡。