一.背景
数据中心目前部署了两台VMware集群,存在exsi5.0,exsi5.5、exsi6.0和exsi6.7以及exsi7.0等多个版本,使用现有prometheus监控系统监控VMware集群的运行状态并实现告警。具体实现如下
ESXi 与 vCenter 的指标,通过vmware_exporter采集指标数据统一纳入到Prometheus,前端由 Grafana 呈现,告警统一通过alertmanager实现告警信息发送到企业微信告警群。
vmware_exporter的主要作用是解析 VMware 的 vSphere API (ESXi/vCenter 原生提供的 REST API),将 VMware 私有格式的虚拟化指标 → 转换成 Prometheus 标准的Prometheus metrics 格式,暴露 HTTP 接口供 Prometheus 拉取。监控的指标如下:
-
VMware vCenter Server(推荐,企业级必用,管理多台 ESXi)
-
VMware ESXi 物理宿主机(单台也可直接对接)
-
宿主机上的所有虚拟机 (VM)、数据存储 (Storage)、交换机、网卡、CPU / 内存 / 磁盘 / 网络等全维度指标
其获取数据的链路如下
VMware(ESXi/vCenter)→VMware_exporter(采集+格式转换)→Prometheus(拉取+存储+告警)→Grafana(可视化大屏)
vmware_exporter的项目地址是https://github.com/pryorda/vmware_exporter,通过连接 vCenter 或直接 ESXi,暴露 /metrics,本次采用的是直接连接到vCenter采集指标数据。vmware_exporter通过docker部署,也可以使用源码部署。
二.环境准备
1.VMware 端:创建专用只读监控用户
绝对不要用管理员账号(administrator@vsphere.local)配置 exporter,权限过大有安全风险,且 exporter 只需要只读权限即可采集所有监控指标,无任何写操作需求
2.Docker 与 Compose 环境
3.部署好 Prometheus、alertmanager与Grafana
三.部署 VMware_exporter
1.创建连接vCenter的配置文件。
vim config-01.env
VSPHERE_USER=monitor@vsphere.local
VSPHERE_PASSWORD='123456'
VSPHERE_HOST=10.10.13.1
VSPHERE_IGNORE_SSL=TRUE
VSPHERE_SPECS_SIZE=2000如果是多集群,可以配置多个配置文件,启用多个vmware_exporter进程服务。
vim config-02.env
VSPHERE_USER=monitor@vsphere.local
VSPHERE_PASSWORD='1qaz1234'
VSPHERE_HOST=10.20.10.2
VSPHERE_IGNORE_SSL=TRUE
VSPHERE_SPECS_SIZE=2000配置文件的字段说明如下
# VMware_exporter 核心配置文件 config.yml
default:
# VMware的vCenter/ESXi的登录地址(必填,vCenter优先填这个,ESXi填ESXi的IP)
vsphere_host: 192.168.10.100
# 刚才创建的 只读监控账号(必填)
vsphere_user: vmware_monitor
# 该账号的密码(必填)
vsphere_password: VMware@Monitor@2026
# 是否忽略SSL证书验证(必开!VMware默认是自签证书,不开会采集失败,填 true)
ignore_ssl: true
# 采集超时时间(默认10秒,建议改成30秒,避免大环境采集超时)
timeout: 30
# 采集的指标模块(核心!开启对应模块才会采集对应指标,全部开启即可)
collect_only: [vm, host, datastore, datacenter, cluster, resourcepool, network, datastorecluster]
# 采集频率相关(全局配置,无需修改)
limits:
max_query_metrics: 256
max_query_objects: 128
max_sessions: 10
collector_threads: 4
# 自定义标签(可选,给所有指标加自定义标签,方便Prometheus区分)
labels:
env: prod
region: china-
vsphere_host:vCenter 填 vCenter 的 IP / 域名,单 ESXi 填 ESXi 的 IP,不要加 http/https 前缀,只填 IP / 域名! -
ignore_ssl: true:必须设置为 true,99% 的采集失败都是因为没开这个配置,VMware 的 SSL 证书是自签的,Python 会校验失败。 -
collect_only:采集模块,建议全部开启,涵盖所有核心监控对象:-
vm:虚拟机指标(CPU、内存、磁盘、网络、开机状态、快照等) -
host:ESXi 宿主机指标(CPU、内存、磁盘、网卡、电源状态等) -
datastore:数据存储(磁盘使用率、可用空间、读写速率) -
其余为虚拟化拓扑指标,无性能损耗,建议全开。
-
2.启动vmware_exporter服务
以下是两个集群的vmware_exporter的docker-compose.yml文件
services:
vmware_exporter_01:
# image: pryorda/vmware_exporter:latest
image: docker.cnb.cool/srebro/docker-images-chrom/pryorda-vmware_exporter:latest_amd64 # 已配置镜像加速地址
container_name: vmware_exporter_01
restart: always
ports:
- "9272:9272"
env_file:
- ./config-01.env
healthcheck:
test: ["CMD", "nc", "-z", "localhost", "9272"] # 检测本地9272端口
interval: 30s # 检测间隔
timeout: 10s # 单次检测超时时间
retries: 3 # 连续失败3次后标记为不健康
start_period: 60s # 启动后60秒开始检测
vmware_exporter_02:
image: docker.cnb.cool/srebro/docker-images-chrom/pryorda-vmware_exporter:latest_amd64 # 已配置镜像加速地址
container_name: vmware_exporter_02
restart: always
ports:
- "9273:9272" # 主机9273映射容器9272端口
env_file:
- ./config-02.env
healthcheck:
test: ["CMD", "nc", "-z", "localhost", "9272"] # 检测容器内部9272端口
interval: 30s
timeout: 10s
retries: 3
start_period: 60s启动服务
docker-compose up -d 3.验证 VMware_exporter 是否启动成功
启动后,浏览器 / 服务器 curl 访问以下地址,能返回Prometheus 标准 metrics 指标 即代表成功,成功标志:返回一大串以# HELP、# TYPE开头的指标数据,包含vmware_vm_power_state、vmware_host_cpu_usage等 VMware 相关指标
curl http://localhost:9272/metrics
curl http://localhost:9272/metrics核心指标说明
VMware_exporter 采集的指标非常全面,所有指标均以 vmware_ 为前缀,以下是生产环境最常用的核心指标(Grafana 面板、告警规则均基于这些指标),类型均为gauge
宿主机 (ESXi) 核心指标
-
vmware_host_cpu_usage:宿主机 CPU 使用率(百分比,0-100) -
vmware_host_memory_usage:宿主机内存使用率(百分比,0-100) -
vmware_host_memory_usage_bytes:宿主机内存使用量(字节) -
vmware_host_disk_usage:宿主机磁盘使用率(百分比) -
vmware_host_power_state:宿主机电源状态(1 = 开机,0 = 关机)
虚拟机 (VM) 核心指标
-
vmware_vm_power_state:虚拟机电源状态(1 = 开机运行,0 = 关机 / 挂起,核心指标) -
vmware_vm_cpu_usage:虚拟机 CPU 使用率(百分比) -
vmware_vm_memory_usage:虚拟机内存使用率(百分比) -
vmware_vm_disk_usage_bytes:虚拟机磁盘使用量(字节) -
vmware_vm_network_receive_bytes_total:虚拟机网络入流量(累计值) -
vmware_vm_network_transmit_bytes_total:虚拟机网络出流量(累计值) -
vmware_vm_guest_tools_status:虚拟机 VMware-tools 状态(1 = 正常,0 = 未安装 / 异常)
数据存储核心指标
-
vmware_datastore_usage:数据存储使用率(百分比,告警核心,超过 85% 建议告警) -
vmware_datastore_free_space_bytes:数据存储剩余空间(字节)
四.在 Prometheus 的 scrape_configs 中加入 vmware_exporter
在prometheus配置文件中添加以下配置
- job_name: 'vmware_vcenter'
metrics_path: /metrics
static_configs:
- targets:
- '10.20.12.75:9272'
- '10.20.12.75:9273'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance注意:targets 填写的是 VMware_exporter 的地址,不是 VMware 的 vCenter/ESXi 地址。
重载 Prometheus 配置(无需重启,生产推荐)
# 方式1:curl热重载(推荐)
curl -X POST http://Prometheus_IP:9090/-/reload
# 方式2:如果没开热重载,重启Prometheus
systemctl restart prometheus验证监控
Prometheus Targets 页面应看到 vmware_exporter 处于 UP 状态
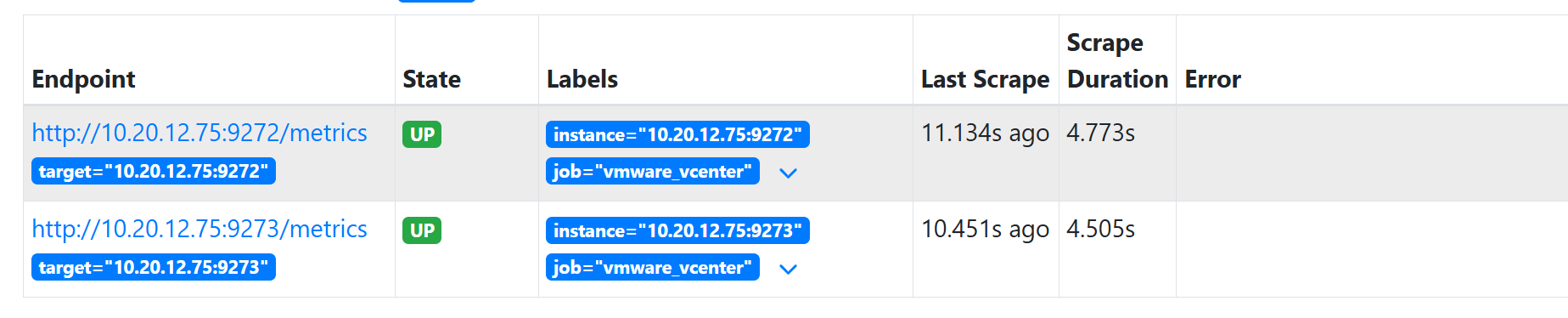
五.添加告警规则
在这里提供一个提供一个标准的 prometheus 的 rules.yaml 文件
groups:
- name: vmware_alerts
rules:
- alert: ESXI宿主机离线
expr: vmware_host_power_state==0
for: 30s
labels:
severity: "1"
annotations:
summary: "ESXI宿主机离线"
description: "宿主机:{{ $labels.host_name }} ESXI宿主机离线,当前值 {{ $value }}%,请登录vCenter查看"
- alert: ESXi存储使用率超阈值
expr: ((1-(vmware_datastore_freespace_size/vmware_datastore_capacity_size))*100)>95
for: 1m
labels:
severity: "1"
annotations:
summary: "ESXi存储使用率超阈值"
description: "{{ $labels.dc_name }}存储名:{{ $labels.ds_name }} 使用率超过95%,当前值 {{ $value }}%"
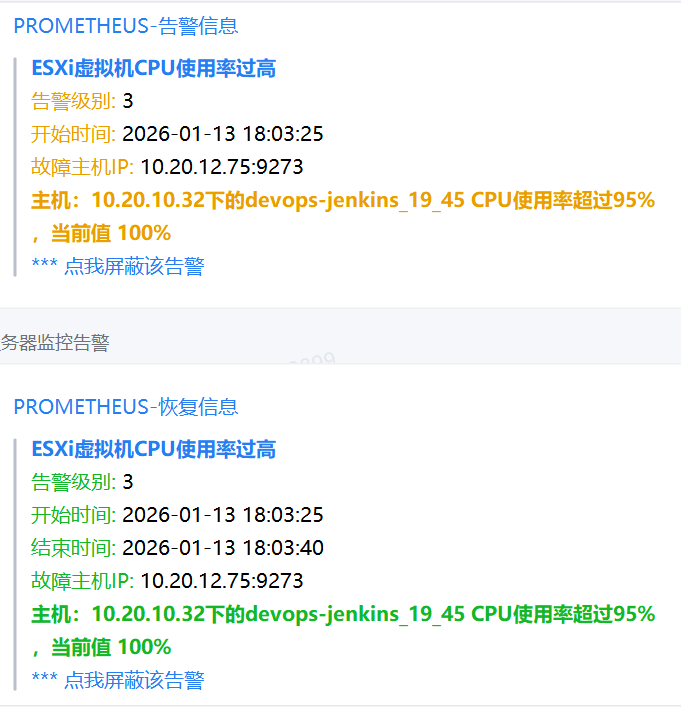
- alert: ESXi虚拟机CPU使用率过高
expr: vmware_vm_cpu_usage_average/100>=95
for: 30s
labels:
severity: "3"
annotations:
summary: "ESXi虚拟机CPU使用率过高"
description: "主机:{{ $labels.host_name }}下的{{ $labels.vm_name }} CPU使用率超过95%,当前值 {{ $value }}%"
- alert: ESXi虚拟机内存使用率过高
expr: vmware_vm_mem_usage_average/100>=95
for: 30s
labels:
severity: "3"
annotations:
summary: "ESXi虚拟机内存使用率过高"
description: "主机:{{ $labels.host_name }} 下的{{ $labels.vm_name }}内存使用率超过95%,当前值 {{ $value }}%"
- alert: ESXi实例CPU负载过高
expr: (vmware_host_cpu_usage/vmware_host_cpu_max)*100>90
for: 1m
labels:
severity: 1
annotations:
summary: "ESXi实例CPU负载过高"
description: "宿主机:{{ $labels.host_name }} CPU负载超过90%,当前值 {{ $value }}%"
- alert: ESXi实例内存使用率过高
expr: (vmware_host_memory_usage/vmware_host_memory_max)*100>95
for: 30s
labels:
severity: "1"
annotations:
summary: "ESXi实例内存使用率过高"
description: "{{ $labels.host_name }} 内存使用率超过95%,当前值 {{ $value }}%"
- alert: ESXi虚拟机快照数量过多
expr: vmware_vm_snapshots>5
for: 30s
labels:
severity: "3"
annotations:
summary: "ESXi虚拟机快照数量过多"
description: "主机:{{ $labels.host_name }} 下的{{ $labels.vm_name }}快照数量超过5个,当前值 {{ $value }}%"告警截图
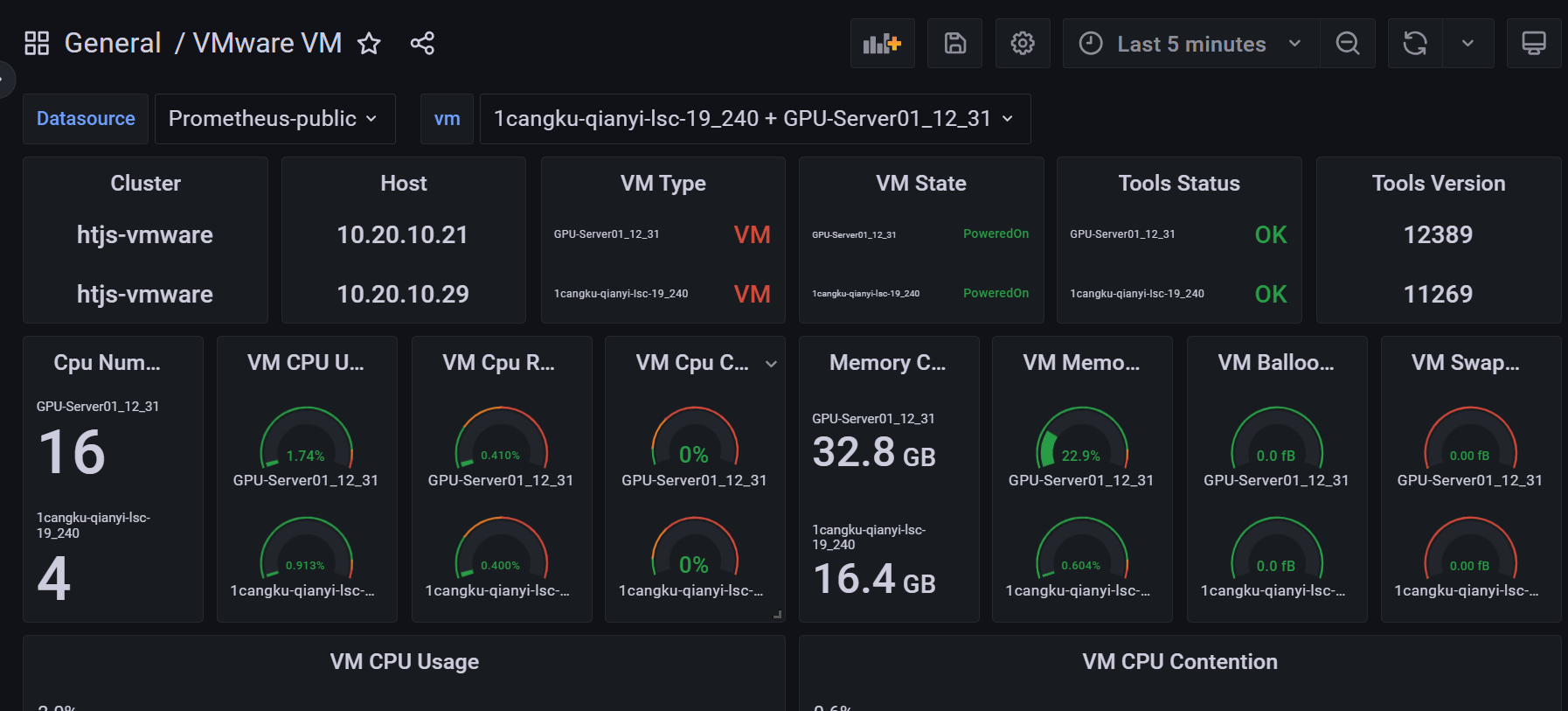
六.grafana图表展示
添加 Prometheus 数据源,指向 Prometheus HTTP 地址,可导入15446 和 11243。
以下是项目上的dashboard,可根据情况导入vmware_exporter/dashboards at main · pryorda/vmware_exporter · GitHub
virtualmachine.json