基于 Java 的分布式系统实战:分布式锁 + 事务 + 一致性算法,干货满满

🌸你好呀!我是 lbb小魔仙
🌟 感谢陪伴~ 小白博主在线求友
🌿 跟着小白学Linux/Java/Python
📖 专栏汇总:
《Linux》专栏 | 《Java》专栏 | 《Python》专栏

- [基于 Java 的分布式系统实战:分布式锁 + 事务 + 一致性算法,干货满满](#基于 Java 的分布式系统实战:分布式锁 + 事务 + 一致性算法,干货满满)
- 一、引言
- 二、分布式锁实现:基于Redis的高可用方案
-
- [2.1 核心设计要点](#2.1 核心设计要点)
- [2.2 完整Java实现代码](#2.2 完整Java实现代码)
- [2.3 工程落地坑点与解决方案](#2.3 工程落地坑点与解决方案)
- [三、分布式事务处理:Seata TCC模式在订单-库存场景的应用](#三、分布式事务处理:Seata TCC模式在订单-库存场景的应用)
-
- [3.1 TCC模式核心原理](#3.1 TCC模式核心原理)
- [3.2 订单-库存场景实战(Seata TCC模式)](#3.2 订单-库存场景实战(Seata TCC模式))
-
- [3.2.1 环境准备](#3.2.1 环境准备)
- [3.2.2 库存服务TCC接口实现](#3.2.2 库存服务TCC接口实现)
- [3.2.3 订单服务事务协调逻辑](#3.2.3 订单服务事务协调逻辑)
- [3.3 坑点与解决方案](#3.3 坑点与解决方案)
- 四、一致性算法集成:Raft算法与Java集群实现
-
- [4.1 Raft算法核心原理](#4.1 Raft算法核心原理)
- [4.2 Java集成Raft集群(基于Atomix开源库)](#4.2 Java集成Raft集群(基于Atomix开源库))
-
- [4.2.1 依赖引入(Maven)](#4.2.1 依赖引入(Maven))
- [4.2.2 简易Raft节点集群实现](#4.2.2 简易Raft节点集群实现)
- [4.3 工程落地要点](#4.3 工程落地要点)
- 五、系统整体协作流程
- 六、总结与最佳实践
-
- [6.1 三大技术协同核心要点](#6.1 三大技术协同核心要点)
- [6.2 性能权衡策略](#6.2 性能权衡策略)
- [6.3 生产环境调优建议](#6.3 生产环境调优建议)
- [6.4 工程落地避坑总结](#6.4 工程落地避坑总结)
一、引言
随着业务规模的扩张,单体系统因性能瓶颈、单点故障等问题逐渐无法满足需求,分布式系统成为企业级应用的主流架构。但分布式环境下,跨节点的并发控制、数据一致性保障、服务协同调度等挑战愈发突出:多个服务实例同时操作共享资源易引发数据冲突,跨服务事务因网络延迟、节点故障可能导致数据不一致,元数据(如配置信息、节点状态)的分布式同步需解决容错与共识问题。
分布式锁、分布式事务与一致性算法(如Raft、Paxos)是解决上述问题的三大核心技术。本文将跳出理论框架,以实战为核心,结合Java生态技术栈,演示如何在真实业务场景中整合三者,构建高一致、高可靠的分布式系统,同时拆解工程落地中的"坑"与解决方案。
二、分布式锁实现:基于Redis的高可用方案
分布式锁的核心目标是在分布式环境中保证同一时刻只有一个服务实例操作共享资源,需满足互斥性、高可用、可重入、超时释放等特性。Redis因高性能、部署便捷,是工业界主流的分布式锁实现载体,以下基于Redis实现具备重入、超时、看门狗机制的分布式锁。
2.1 核心设计要点
-
互斥性:利用Redis的SET NX EX命令(原子操作),确保只有一个实例能成功设置锁键。
-
可重入:通过Redis哈希结构存储锁持有者ID与重入次数,避免同一实例重复获取锁失败。
-
超时释放:设置锁的过期时间,防止因服务宕机导致锁无法释放(死锁)。
-
看门狗机制:针对长耗时任务,启动后台线程定期延长锁过期时间,避免任务未完成锁已释放。
-
高可用 :基于Redis主从+哨兵架构,避免单点Redis故障导致锁服务不可用。

2.2 完整Java实现代码
java
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import java.util.concurrent.TimeUnit;
/**
* 基于Redisson的分布式锁工具类(自带重入、超时、看门狗机制)
* Redisson是Redis官方推荐的Java分布式锁实现库,封装了底层细节,可靠性更高
*/
public class RedisDistributedLockUtil {
// Redisson客户端(单例模式,避免重复创建连接)
private static RedissonClient redissonClient;
static {
// 初始化Redisson客户端(生产环境建议通过配置文件加载,支持哨兵/集群模式)
Config config = new Config();
// 单机模式(测试用,生产环境替换为哨兵/集群配置)
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379")
.setPassword("123456") // 生产环境必须设置密码
.setConnectionPoolSize(50) // 连接池大小,根据并发量调整
.setConnectionMinimumIdleSize(10); // 最小空闲连接数
redissonClient = Redisson.create(config);
}
/**
* 获取分布式锁(默认开启看门狗机制,锁过期时间30秒,每10秒续期一次)
* @param lockKey 锁键(对应共享资源唯一标识,如order:123)
* @return 分布式锁对象
*/
public static RLock lock(String lockKey) {
RLock lock = redissonClient.getLock(lockKey);
// 阻塞式获取锁,无超时时间(看门狗自动续期)
lock.lock();
return lock;
}
/**
* 获取分布式锁(自定义过期时间,不开启看门狗)
* @param lockKey 锁键
* @param leaseTime 锁持有时间(过期自动释放,单位:秒)
* @return 分布式锁对象
*/
public static RLock lock(String lockKey, long leaseTime) {
RLock lock = redissonClient.getLock(lockKey);
lock.lock(leaseTime, TimeUnit.SECONDS);
return lock;
}
/**
* 尝试获取分布式锁(非阻塞式)
* @param lockKey 锁键
* @param waitTime 最大等待时间(获取不到锁时,等待多久,单位:秒)
* @param leaseTime 锁持有时间(单位:秒)
* @return true-获取成功,false-获取失败
* @throws InterruptedException 线程中断异常
*/
public static boolean tryLock(String lockKey, long waitTime, long leaseTime) throws InterruptedException {
RLock lock = redissonClient.getLock(lockKey);
return lock.tryLock(waitTime, leaseTime, TimeUnit.SECONDS);
}
/**
* 释放分布式锁
* @param lockKey 锁键
*/
public static void unlock(String lockKey) {
RLock lock = redissonClient.getLock(lockKey);
// 仅释放当前线程持有的锁,避免误释放其他线程的锁
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
/**
* 释放分布式锁(直接传入锁对象,更安全)
* @param lock 分布式锁对象
*/
public static void unlock(RLock lock) {
if (lock != null && lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
/**
* 判断锁是否被持有
* @param lockKey 锁键
* @return true-被持有,false-未被持有
*/
public static boolean isLocked(String lockKey) {
RLock lock = redissonClient.getLock(lockKey);
return lock.isLocked();
}
// 关闭Redisson客户端(应用关闭时调用)
public static void closeClient() {
if (redissonClient != null) {
redissonClient.shutdown();
}
}
}
// 测试代码
class RedisLockTest {
public static void main(String[] args) throws InterruptedException {
String lockKey = "resource:order:123";
// 方式1:默认看门狗机制
RLock lock = RedisDistributedLockUtil.lock(lockKey);
try {
// 执行业务逻辑(如订单创建、库存扣减)
System.out.println("获取锁成功,执行核心业务...");
TimeUnit.SECONDS.sleep(20); // 模拟长耗时任务,看门狗会自动续期
} finally {
// 必须在finally中释放锁,避免异常导致锁泄露
RedisDistributedLockUtil.unlock(lock);
System.out.println("释放锁成功");
}
// 方式2:尝试获取锁
boolean isLocked = RedisDistributedLockUtil.tryLock(lockKey, 3, 10);
if (isLocked) {
try {
System.out.println("尝试获取锁成功,执行核心业务...");
} finally {
RedisDistributedLockUtil.unlock(lockKey);
}
} else {
System.out.println("获取锁失败,跳过或重试");
}
}
}2.3 工程落地坑点与解决方案
-
坑点1:Redis主从切换导致锁丢失 :主节点持有锁但未同步到从节点时主节点宕机,从节点升级为主节点后,其他实例可重新获取锁。
解决方案:使用Redis红锁(RedLock),同时向多个独立Redis节点获取锁,仅当多数节点获取成功才算锁生效,牺牲部分性能换取更高可靠性。
-
坑点2:误释放其他线程的锁 :未判断锁持有者直接释放,导致并发问题。
解决方案:Redisson内部已通过线程ID标识锁持有者,释放时先校验是否为当前线程持有,工具类中已封装该逻辑。
-
坑点3:看门狗机制滥用导致锁长期占用 :若业务逻辑陷入死循环,看门狗会持续续期,导致锁无法释放。
解决方案:结合业务场景设置合理的最大锁持有时间,或在看门狗中加入超时熔断机制,超过阈值自动终止续期。
三、分布式事务处理:Seata TCC模式在订单-库存场景的应用
分布式事务是指跨多个服务节点的事务,需满足ACID特性(分布式环境下难以完全满足,通常追求最终一致性)。Seata是阿里开源的分布式事务框架,支持AT、TCC、Saga等模式,其中TCC模式适用于对一致性要求高、业务逻辑可拆分的场景(如订单-库存联动)。
3.1 TCC模式核心原理
TCC(Try-Confirm-Cancel)将分布式事务拆分为三个阶段,由业务代码自定义实现,无侵入性且一致性可控:
-
Try阶段:资源检查与预留(如检查库存是否充足,预留库存数量),确保后续操作可执行。
-
Confirm阶段:确认执行业务(如扣减预留库存、创建订单),仅当所有服务的Try阶段成功后执行,该阶段需保证幂等性。
-
Cancel阶段:回滚操作(如释放预留库存、删除订单草稿),当任意服务的Try阶段失败时执行,同样需保证幂等性。
3.2 订单-库存场景实战(Seata TCC模式)
场景描述:用户创建订单时,需扣减对应商品库存,涉及订单服务(OrderService)与库存服务(StockService),跨服务事务需保证订单创建与库存扣减的一致性。
3.2.1 环境准备
- 引入Seata依赖(Maven):
xml
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.7.1</version>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-tcc-api</artifactId>
<version>1.7.1</version>
</dependency>- 配置Seata(application.yml):
yaml
seata:
tx-service-group: order-stock-group # 事务组名称,需与Seata Server配置一致
service:
vgroup-mapping:
order-stock-group: default # 事务组与集群映射
grouplist:
default: 127.0.0.1:8091 # Seata Server地址
data-source-proxy-mode: AT # 兼容AT模式,TCC模式无需代理数据源3.2.2 库存服务TCC接口实现
java
import io.seata.rm.tcc.api.BusinessActionContext;
import io.seata.rm.tcc.api.BusinessActionContextParameter;
import io.seata.rm.tcc.api.LocalTCC;
import io.seata.rm.tcc.api.TwoPhaseBusinessAction;
/**
* 库存服务TCC接口(LocalTCC注解标识为TCC服务)
*/
@LocalTCC
public interface StockTccService {
/**
* Try阶段:预留库存
* name:TCC事务名称,需唯一
* commitMethod:Confirm阶段方法名
* rollbackMethod:Cancel阶段方法名
*/
@TwoPhaseBusinessAction(name = "stockTccAction", commitMethod = "confirm", rollbackMethod = "cancel")
boolean tryDeductStock(
BusinessActionContext context,
@BusinessActionContextParameter(paramName = "productId") Long productId,
@BusinessActionContextParameter(paramName = "count") Integer count);
/**
* Confirm阶段:确认扣减库存(Try成功后执行)
*/
boolean confirm(BusinessActionContext context);
/**
* Cancel阶段:释放预留库存(Try失败后执行)
*/
boolean cancel(BusinessActionContext context);
}
// 实现类
@Service
public class StockTccServiceImpl implements StockTccService {
@Autowired
private StockMapper stockMapper; // 库存DAO层
/**
* Try阶段:检查库存并预留
* 库存表需设计预留字段(reserve_count),避免直接扣减可用库存导致并发问题
*/
@Override
public boolean tryDeductStock(BusinessActionContext context, Long productId, Integer count) {
System.out.println("库存服务Try阶段:预留库存,productId=" + productId + ", count=" + count);
// 1. 检查可用库存是否充足(可用库存 = total_count - reserve_count)
Stock stock = stockMapper.selectById(productId);
if (stock == null || stock.getAvailableCount() < count) {
// 库存不足,Try失败
return false;
}
// 2. 预留库存(更新reserve_count += count)
int rows = stockMapper.reserveStock(productId, count);
return rows > 0;
}
@Override
public boolean confirm(BusinessActionContext context) {
Long productId = Long.valueOf(context.getActionContext("productId").toString());
Integer count = Integer.valueOf(context.getActionContext("count").toString());
System.out.println("库存服务Confirm阶段:确认扣减库存,productId=" + productId + ", count=" + count);
// 扣减可用库存,释放预留库存(available_count -= count, reserve_count -= count)
int rows = stockMapper.confirmDeductStock(productId, count);
// 幂等处理:若已执行过Confirm,rows=0仍返回true
return rows >= 0;
}
@Override
public boolean cancel(BusinessActionContext context) {
Long productId = Long.valueOf(context.getActionContext("productId").toString());
Integer count = Integer.valueOf(context.getActionContext("count").toString());
System.out.println("库存服务Cancel阶段:释放预留库存,productId=" + productId + ", count=" + count);
// 释放预留库存(reserve_count -= count)
int rows = stockMapper.cancelReserveStock(productId, count);
// 幂等处理:若已执行过Cancel,rows=0仍返回true
return rows >= 0;
}
}3.2.3 订单服务事务协调逻辑
java
import io.seata.core.context.RootContext;
import io.seata.spring.annotation.GlobalTransactional;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper; // 订单DAO层
@Autowired
private StockTccService stockTccService; // 库存TCC服务(远程调用,如Feign)
/**
* 创建订单(全局事务入口,GlobalTransactional注解标识)
* rollbackFor:指定异常类型触发回滚
*/
@GlobalTransactional(rollbackFor = Exception.class, name = "order-stock-tcc")
public Long createOrder(Long userId, Long productId, Integer count) {
System.out.println("全局事务ID:" + RootContext.getXID());
// 1. 调用库存服务Try阶段:预留库存
boolean stockTrySuccess = stockTccService.tryDeductStock(RootContext.getContext(), productId, count);
if (!stockTrySuccess) {
throw new RuntimeException("库存不足,创建订单失败");
}
// 2. 本地创建订单(Try阶段,仅创建草稿状态订单)
Order order = new Order();
order.setUserId(userId);
order.setProductId(productId);
order.setCount(count);
order.setStatus(0); // 0-草稿状态,1-确认成功,2-取消
orderMapper.insert(order);
System.out.println("创建订单草稿,orderId=" + order.getId());
// 3. 模拟业务异常(测试回滚)
// throw new RuntimeException("模拟异常,触发全局回滚");
// 若无异常,Seata会自动触发所有服务的Confirm阶段
return order.getId();
}
// 订单Confirm阶段(本地事务,由Seata回调)
public boolean confirmCreateOrder(Long orderId) {
System.out.println("订单服务Confirm阶段:更新订单状态为成功");
int rows = orderMapper.updateStatus(orderId, 1);
return rows >= 0;
}
// 订单Cancel阶段(本地事务,由Seata回调)
public boolean cancelCreateOrder(Long orderId) {
System.out.println("订单服务Cancel阶段:更新订单状态为取消");
int rows = orderMapper.updateStatus(orderId, 2);
return rows >= 0;
}
}3.3 坑点与解决方案
-
坑点1:TCC三阶段幂等性问题 :Confirm/Cancel阶段可能因网络重试被多次调用,导致重复执行。
解决方案:基于全局事务ID(XID)记录事务执行状态,执行前先校验状态,避免重复操作;或使用数据库唯一索引约束。
-
坑点2:Try阶段资源预留失败后Cancel不执行 :服务宕机或网络故障导致Seata无法回调Cancel方法,预留资源泄露。
解决方案:Seata自带事务日志与重试机制,同时结合定时任务扫描未完成的事务,主动触发Cancel回调。
-
坑点3:跨服务调用超时导致事务卡顿 :Try阶段调用远程服务超时,影响整体事务性能。
解决方案:设置合理的远程调用超时时间,结合熔断机制(如Sentinel),超时后直接触发Cancel阶段,避免阻塞。
四、一致性算法集成:Raft算法与Java集群实现
一致性算法用于解决分布式系统中多个节点的数据同步与共识问题,确保即使部分节点故障,数据仍能保持一致。Raft算法相比Paxos更易理解与实现,分为领导者(Leader)、跟随者(Follower)、候选人(Candidate)三种角色,通过选举、日志复制、安全性约束实现一致性。
4.1 Raft算法核心原理
-
领导者选举:初始所有节点为Follower,超时无Leader心跳则转为Candidate,向其他节点发起投票,获得多数票者成为Leader,任期(Term)递增。
-
日志复制:客户端请求先发送至Leader,Leader将日志条目追加到本地,再同步至所有Follower,待多数Follower确认后,Leader提交日志并通知Follower提交。
-
安全性约束:确保已提交的日志不会被覆盖,Leader仅同步任期大于等于自身的日志,选举时仅投票给日志较新的节点。
4.2 Java集成Raft集群(基于Atomix开源库)
Atomix是基于Raft算法的分布式一致性框架,封装了集群管理、日志复制、分布式数据结构等功能,可快速集成到Java系统中,用于元数据(如配置、节点状态)的一致性管理。
4.2.1 依赖引入(Maven)
xml
<dependency>
<groupId>io.atomix</groupId>
<artifactId>atomix-cluster</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>io.atomix</groupId>
<artifactId>atomix-raft</artifactId>
<version>3.2.0</version>
</dependency>4.2.2 简易Raft节点集群实现
java
import io.atomix.cluster.Cluster;
import io.atomix.cluster.ClusterMembershipEvent;
import io.atomix.cluster.Node;
import io.atomix.raft.RaftServer;
import io.atomix.raft.storage.RaftStorage;
import io.atomix.utils.net.Address;
import java.io.File;
import java.util.concurrent.CompletableFuture;
/**
* 基于Atomix的Raft节点集群,用于元数据一致性管理
*/
public class RaftClusterNode {
private final RaftServer raftServer;
private final Cluster cluster;
public RaftClusterNode(String nodeId, Address address, Iterable<Address> peers) {
// 1. 初始化集群配置
this.cluster = Cluster.builder()
.withNodeId(nodeId)
.withAddress(address)
.build();
// 2. 初始化Raft存储(日志与快照存储路径)
RaftStorage storage = RaftStorage.builder()
.withDirectory(new File("./raft-storage/" + nodeId)) // 每个节点独立存储目录
.build();
// 3. 构建Raft服务器
RaftServer.Builder raftBuilder = RaftServer.builder(nodeId)
.withCluster(cluster)
.withStorage(storage)
.withAddress(address);
// 添加集群节点(若为新集群,需指定所有初始节点;若为加入现有集群,指定已有节点)
peers.forEach(peer -> raftBuilder.withPeer(Node.builder()
.withId("node-" + peer.port()) // 节点ID与端口关联,简化配置
.withAddress(peer)
.build()));
this.raftServer = raftBuilder.build();
// 4. 监听集群成员变化事件
cluster.membershipService().addListener(event -> {
if (event.type() == ClusterMembershipEvent.Type.MEMBER_ADDED) {
System.out.println("节点加入集群:" + event.member().id());
} else if (event.type() == ClusterMembershipEvent.Type.MEMBER_REMOVED) {
System.out.println("节点离开集群:" + event.member().id());
}
});
}
// 启动Raft节点
public CompletableFuture<Void> start() {
System.out.println("启动Raft节点:" + raftServer.nodeId());
return raftServer.start()
.thenRun(() -> {
// 打印节点角色
raftServer.role().subscribe(role -> {
System.out.println("节点" + raftServer.nodeId() + "角色变更为:" + role);
});
});
}
// 停止Raft节点
public CompletableFuture<Void> stop() {
System.out.println("停止Raft节点:" + raftServer.nodeId());
return raftServer.stop();
}
// 提交元数据到Raft集群(仅Leader节点可处理,Follower会转发至Leader)
public CompletableFuture<Boolean> submitMetadata(String key, String value) {
// 构建日志条目(自定义元数据格式,key-value)
String metadata = key + ":" + value;
return raftServer.submit(metadata.getBytes())
.thenApply(result -> {
System.out.println("元数据提交成功,key=" + key + ", value=" + value);
return true;
})
.exceptionally(ex -> {
System.err.println("元数据提交失败:" + ex.getMessage());
return false;
});
}
public static void main(String[] args) throws InterruptedException {
// 启动3节点Raft集群(最小集群规模,确保多数节点可用)
Address node1Addr = Address.from("localhost", 8081);
Address node2Addr = Address.from("localhost", 8082);
Address node3Addr = Address.from("localhost", 8083);
// 节点1(初始集群节点)
RaftClusterNode node1 = new RaftClusterNode("node-8081", node1Addr, java.util.Arrays.asList(node2Addr, node3Addr));
// 节点2(初始集群节点)
RaftClusterNode node2 = new RaftClusterNode("node-8082", node2Addr, java.util.Arrays.asList(node1Addr, node3Addr));
// 节点3(初始集群节点)
RaftClusterNode node3 = new RaftClusterNode("node-8083", node3Addr, java.util.Arrays.asList(node1Addr, node2Addr));
// 启动所有节点
node1.start().join();
node2.start().join();
node3.start().join();
// 等待选举完成(约1-2秒)
TimeUnit.SECONDS.sleep(2);
// 向集群提交元数据(任意节点提交,自动转发至Leader)
node1.submitMetadata("system:config:timeout", "3000");
node2.submitMetadata("system:node:status", "running");
// 模拟节点故障(停止节点2)
TimeUnit.SECONDS.sleep(5);
node2.stop().join();
System.out.println("节点2故障,集群剩余节点:node-8081、node-8083");
// 故障后仍可提交元数据(多数节点存活)
node1.submitMetadata("system:node:fault", "node-8082");
// 保持集群运行
TimeUnit.MINUTES.sleep(10);
}
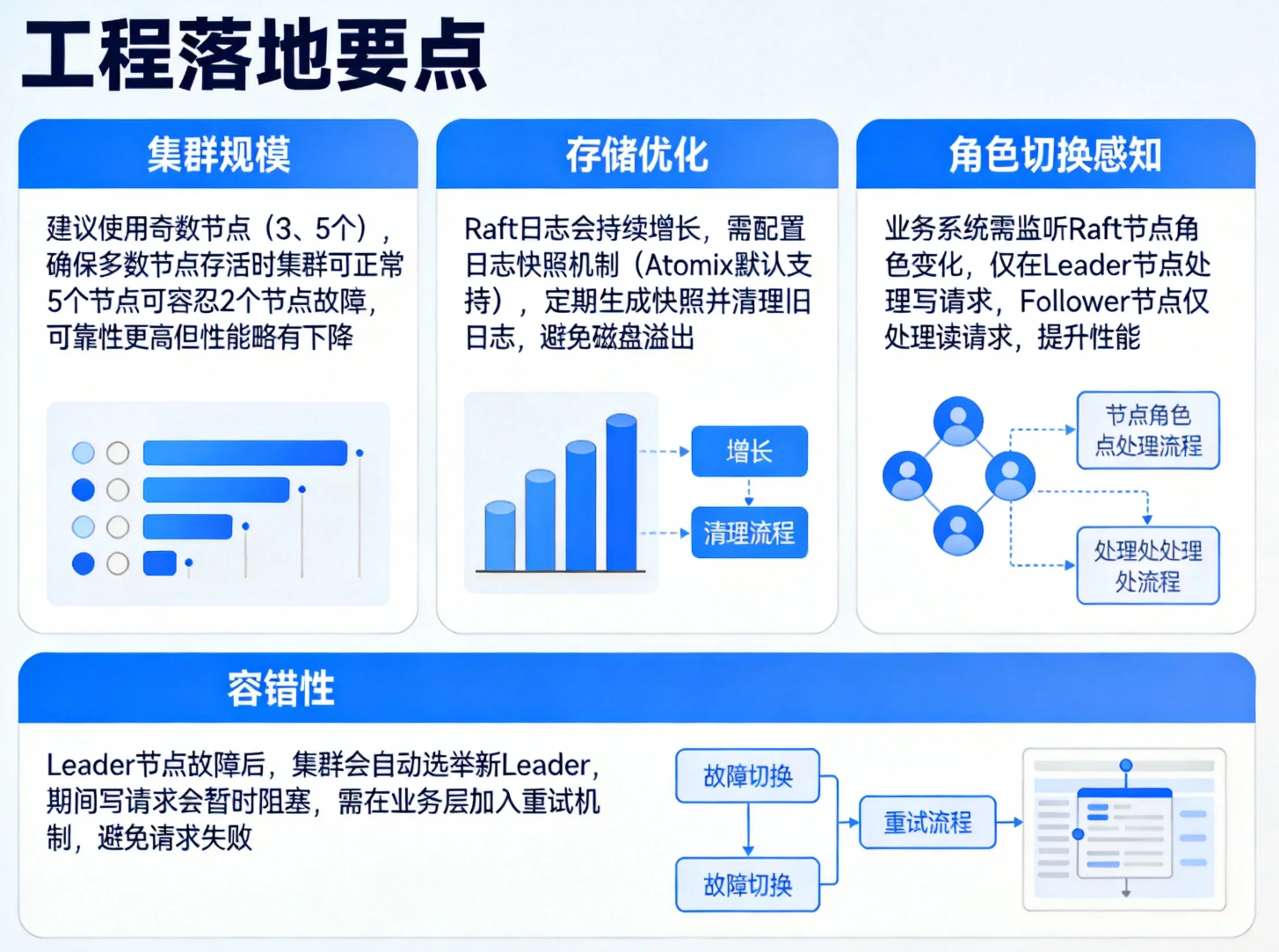
}4.3 工程落地要点
-
集群规模:建议使用奇数节点(3、5个),确保多数节点存活时集群可正常工作,5个节点可容忍2个节点故障,可靠性更高但性能略有下降。
-
存储优化:Raft日志会持续增长,需配置日志快照机制(Atomix默认支持),定期生成快照并清理旧日志,避免磁盘溢出。
-
角色切换感知:业务系统需监听Raft节点角色变化,仅在Leader节点处理写请求,Follower节点仅处理读请求,提升性能。
-
容错性 :Leader节点故障后,集群会自动选举新Leader,期间写请求会暂时阻塞,需在业务层加入重试机制,避免请求失败。
五、系统整体协作流程
以下通过Mermaid流程图,展示用户创建订单请求从入口到分布式锁获取、事务执行、一致性状态同步的完整流程,整合分布式锁、Seata TCC事务、Raft集群三大技术。
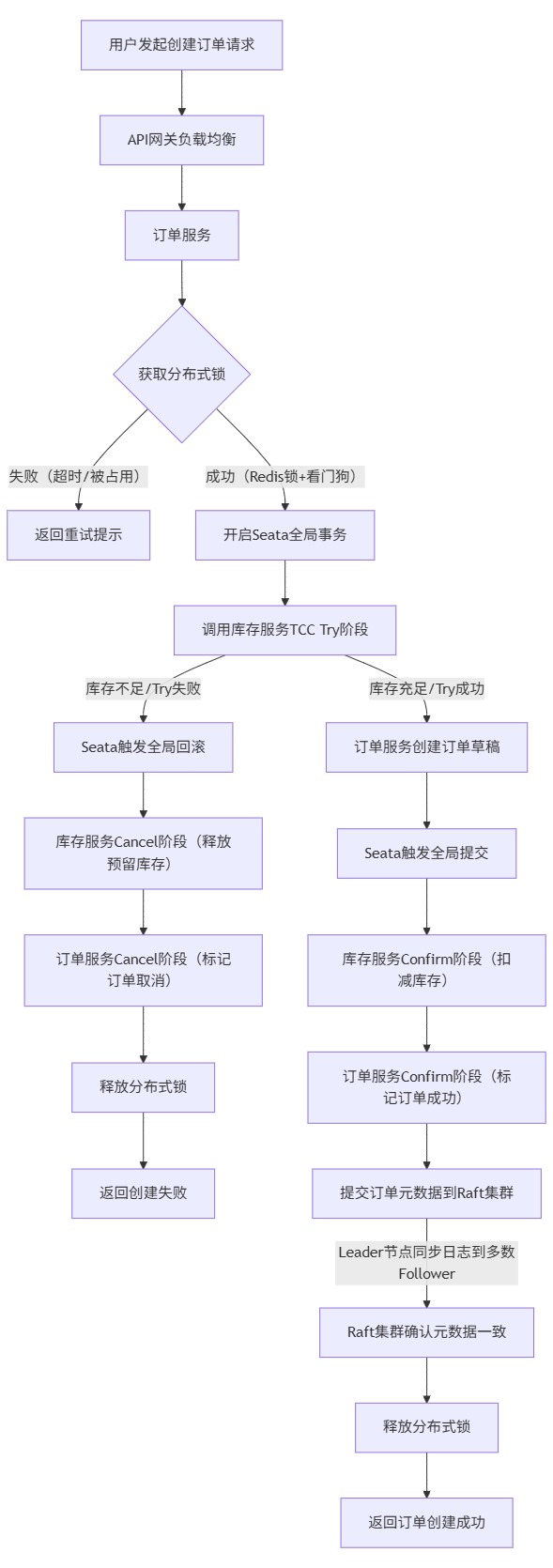
流程说明:
-
用户请求经API网关路由至订单服务,首先获取分布式锁,防止并发创建订单导致数据冲突。
-
获取锁成功后开启Seata全局事务,触发TCC模式的Try阶段,检查并预留库存,创建订单草稿。
-
Try阶段全量成功则执行Confirm阶段,确认库存扣减与订单状态更新;任意节点Try失败则执行Cancel阶段,回滚所有操作。
-
事务提交成功后,将订单元数据(如订单状态、创建时间)提交至Raft集群,确保分布式节点间元数据一致。
-
所有操作完成后释放分布式锁,返回结果给用户;锁获取失败则提示用户重试,避免业务阻塞。
六、总结与最佳实践
6.1 三大技术协同核心要点
分布式锁、分布式事务、一致性算法并非孤立存在,协同使用时需明确边界与依赖关系:
-
边界划分:分布式锁用于控制共享资源的并发访问(粒度较细,如单订单、单商品);分布式事务用于保证跨服务业务的原子性(粒度较粗,如订单-库存联动);一致性算法用于元数据、配置等核心数据的全局同步(全局粒度)。
-
依赖顺序:通常先获取分布式锁,再开启分布式事务,避免事务执行中因锁竞争导致回滚;事务执行结果(如订单状态)需通过一致性算法同步,确保全局可见。
6.2 性能权衡策略
-
分布式锁:优先使用Redis锁(高性能),对可靠性要求极高的场景(如资金交易)使用红锁,牺牲部分性能换取一致性。
-
分布式事务:对一致性要求高的场景用TCC,对一致性要求低、追求性能的场景用Saga(最终一致性);避免过度使用分布式事务,尽量拆分业务,减少跨服务事务。
-
一致性算法:Raft集群规模控制在3-5个节点,避免过多节点导致日志同步性能下降;读请求可路由至Follower节点,分担Leader压力。
6.3 生产环境调优建议
-
分布式锁调优:根据业务耗时设置合理的锁过期时间,看门狗续期间隔建议为过期时间的1/3;Redis锁使用连接池复用连接,避免频繁创建销毁连接。
-
Seata事务调优:优化TCC三阶段的远程调用超时时间(建议5-10秒);开启Seata事务日志异步写入,提升性能;集群部署Seata Server,避免单点故障。
-
Raft集群调优:调整选举超时时间(默认1-2秒,网络不稳定时可适当延长);配置日志快照间隔(如每小时生成一次快照),定期清理旧日志;使用SSD存储Raft日志,提升IO性能。
-
监控与告警:接入Prometheus+Grafana监控分布式锁的获取/释放成功率、事务提交/回滚率、Raft集群节点状态与日志同步延迟;设置告警阈值,及时发现锁泄露、事务卡顿、节点故障等问题。
6.4 工程落地避坑总结
- 避免分布式锁与事务的滥用,优先通过业务设计(如幂等、最终一致性)减少对技术组件的依赖;2. 分布式锁必须在finally中释放,事务必须做好幂等与回滚补偿;3. Raft集群不可用于高频写场景,仅适用于元数据、配置等低频写、高频读的数据同步;4. 所有远程调用必须加入超时、熔断、重试机制,提升系统容错性。
综上,构建高可靠的分布式系统,需结合业务场景合理选择技术方案,在一致性、性能、容错性之间找到平衡,同时重视工程落地中的细节与监控,才能真正发挥三大核心技术的价值。
📕个人领域 :Linux/C++/java/AI
🚀 个人主页 :有点流鼻涕 · CSDN
💬 座右铭 : "向光而行,沐光而生。"
