📖标题:Discovery and Reinforcement of Tool-Integrated Reasoning Chains via Rollout Trees
🌐来源:arXiv, 2601.08274v1
🌟摘要
工具集成推理已成为用计算能力增强大型语言模型 (LLM) 的关键范式,但将工具使用集成到长思维链(长 CoT)中仍未得到充分探索,这主要是由于训练数据的稀缺和在不影响模型内在长链推理的情况下集成工具使用的挑战。在本文中,我们介绍了 DART (Discovery and Reinforcement of Tool-Integrated Reasoning Chains by Rollout Trees),这是一种强化学习框架,可以在没有人工注释的长 CoT 推理期间实现自发工具使用。DART 在训练期间通过构建动态推出树来发现有效的工具使用机会来运行,在有希望的位置分支以探索不同的工具集成轨迹。随后,基于树的过程优势估计识别和积分特定子轨迹,其中工具调用对解决方案有积极贡献,有效地加强了这些有益的行为。在 AIME 和 GPQA-Diamond 等具有挑战性的基准上的广泛实验表明,DART 显着优于现有方法,成功地协调了具有长 CoT 推理的工具执行。
🛎️文章简介
🔸研究问题:如何在没有注释数据的情况下,实现工具集成的推理链与长链推理的融合?
🔸主要贡献:论文提出了一种新的强化学习框架DART,通过动态树展开机制实现工具使用的发现和强化,显著提升复杂推理任务的表现。
📝重点思路
🔸引入剩余抽样树(rollout tree)构建,发现工具集成的推理轨迹。
🔸采用树状优势估计,反映每个节点(即子轨迹)相对于其兄弟节点的相对优越性,用于强化学习。
🔸在RL训练过程中,通过插入工具提示来扩展树结构,以探索有潜力的推理路径。
🔸通过联合概率采样确定最佳位置和提示的组合,以引导工具集成的推理。
🔎分析总结
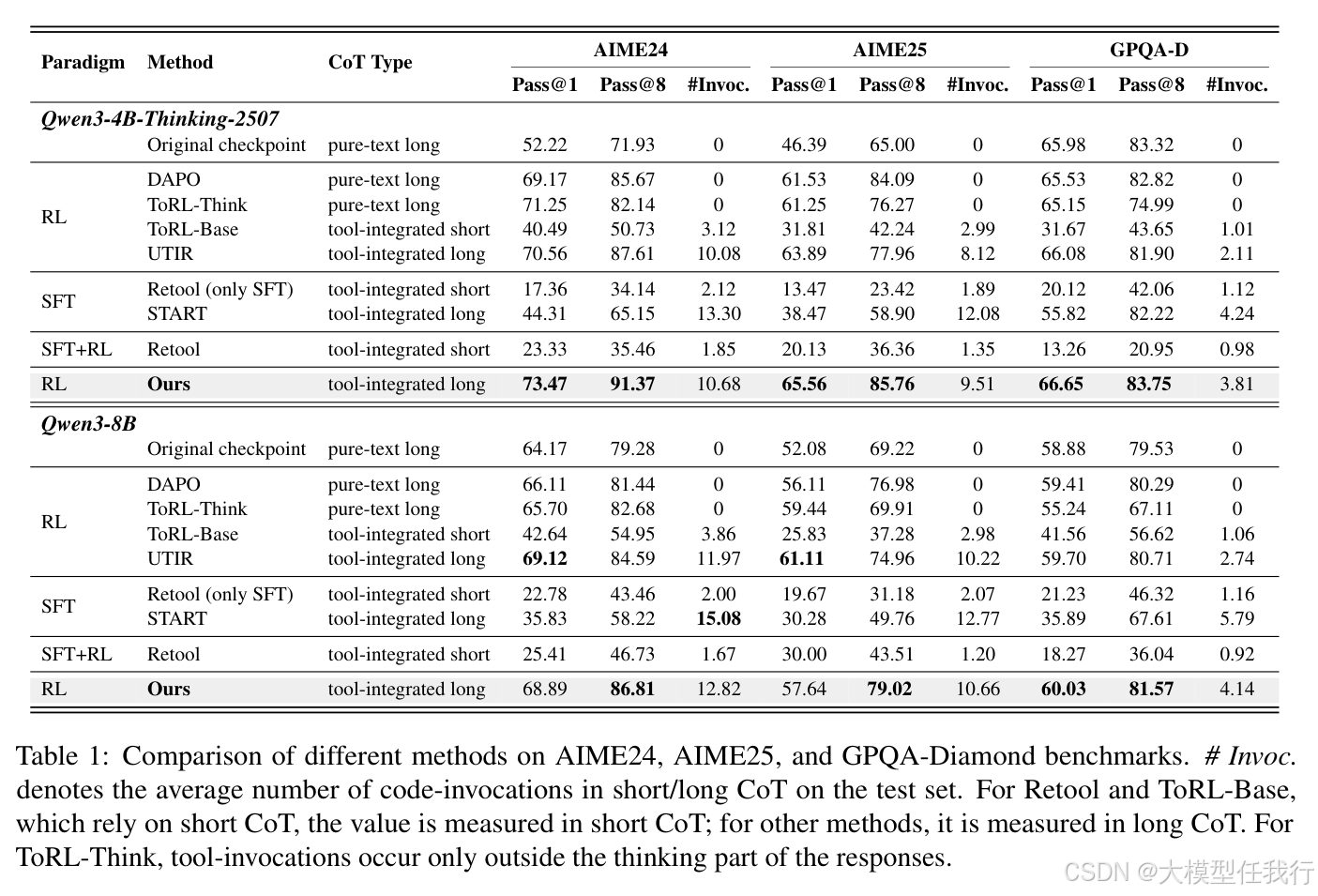
🔸DART模型能够在复杂的推理任务中显著优于现有方法,证明了工具集成推理的有效性。
🔸动态树结构通过中间步骤的精细监督,有效地促进了有益的工具使用行为,提升了推理性能。
🔸使用树状优势估计相较于均匀优势分配能更好地鼓励模型调用工具,从而提高正确率。
🔸在训练过程中,工具集成的轨迹能够在更大范围内提高回答正确率,展示了模型具备潜在的工具使用能力。
💡个人观点
论文的创新点在于动态树展开机制和树状优势估计,成功将工具集成与长链推理结合,克服了以往方法中的数据依赖性问题。
🧩附录