一、背景
课程列表有两个名称类似的课程,例如:
高中数学-预科拓展-高二上
高中数学预科拓展-高二上
当搜索关键字是"高中数学预科拓展-高二上" 或 "高中数学-预科拓展-高二上",搜索结果都能是上面两个课程。
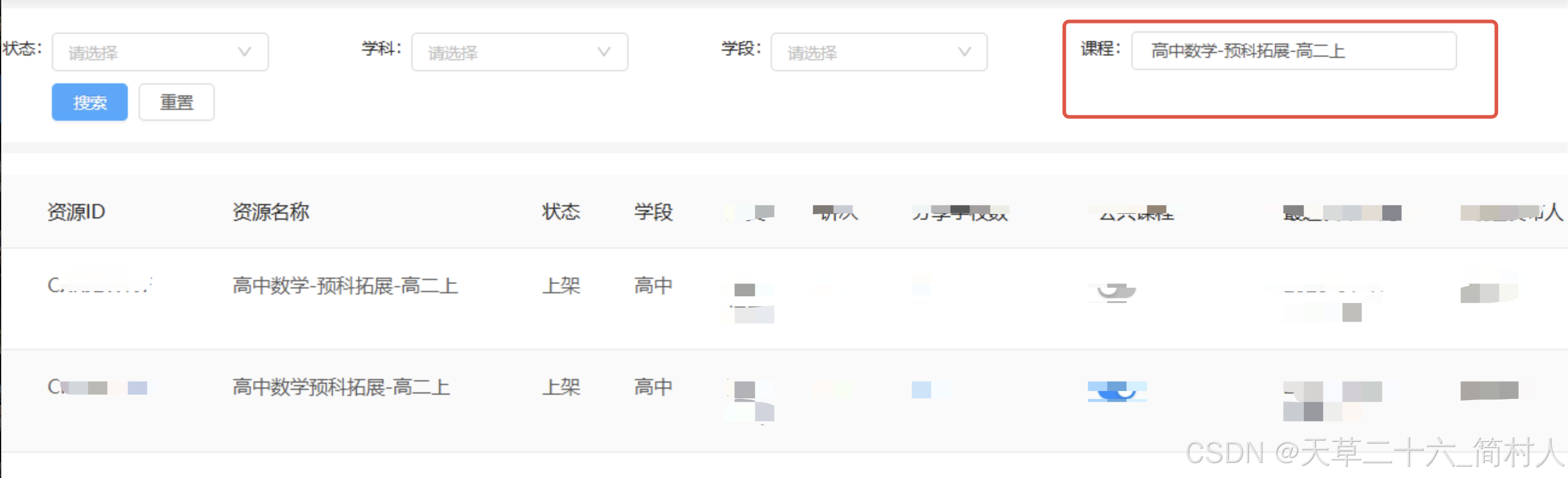
而业务使用方希望看到的效果是,当搜索"高中数学预科拓展-高二上"时,只看到课程名称等于"高中数学预科拓展-高二上"的课程,而不展示另外那个"双胞胎"课程--"高中数学-预科拓展-高二上"。
也就是说,需要对课程名称进行精准匹配,而非模糊匹配。
但是,终端用户的需求是对课程名称进行模糊匹配。
所以,我们对接口的改造是,不同的接口,传入不同的参数,区分是否模糊搜索。
二、es索引检索的逻辑
1、现状
json
"mappings" : {
"_doc" : {
"properties" : {
"courseName" : {
"type" : "text"
}
}
}courseName是text类型的字段。
java的写法
es将自动对课程名称courseName进行分词,
java
BoolQueryBuilder nameQueryBuilder = QueryBuilders.boolQuery();
for (String keyword : keywords) {
nameQueryBuilder = nameQueryBuilder.should(QueryBuilders.matchPhraseQuery("courseName", keyword));
}在 Elasticsearch 的 match_phrase 查询里,横杆 - 属于默认的停用字符(token filter 中的 standard 会把 - 当成分隔符),因此:
关键词1: 高中数学-预科拓展-高二
在倒排索引里会被拆成:
高中数学、预科拓展、高二
关键词1: 高中数学预科拓展高二
如果用的是 ik_max_word / standard 等分词器,同样也会被拆成:
高中数学、预科拓展、高二
所以两份文档的 token 列表完全一致,match_phrase 查询的 position 序列也相同,于是返回结果一样。
2、解决办法
不需要改原来的 text 字段,只要给它补一个 keyword 子字段即可;
已有数据也不会丢失,ES 会自动重新生成新子字段的索引。
json
PUT /share_course_index/_mapping/_doc
{
"properties": {
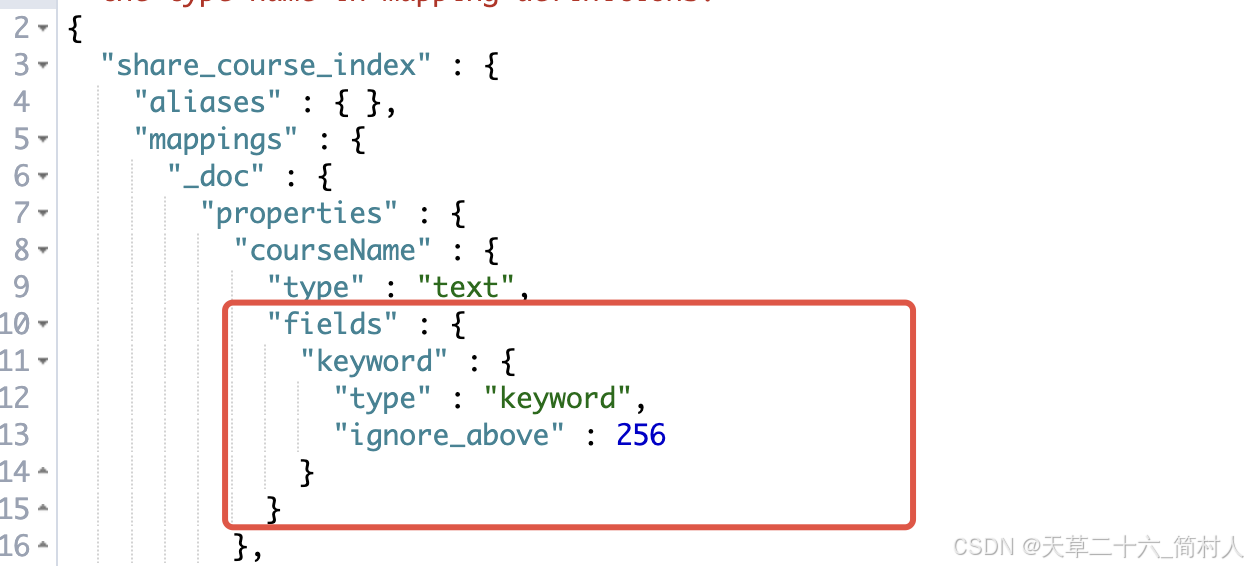
"courseName": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}原 courseName 仍是 text,旧查询不受影响。
新增 courseName.keyword 用来做精准匹配,区分横杆、空格、大小写。
- 修复旧数据
之后写入的数据会自动拥有 keyword 子字段;
json
# 旧数据需要执行一次
POST /course/_update_by_query让 ES 把已有文档重新扫一遍,生成 keyword 倒排索引即可(耗时视数据量而定)。
3、java代码
java
// 是否模糊匹配
boolean isFuzzySearch;
BoolQueryBuilder nameQueryBuilder = QueryBuilders.boolQuery();
for (String keyword : keywords) {
if (isFuzzySearch) {
// 模糊搜索
nameQueryBuilder.should(QueryBuilders.matchPhraseQuery("courseName", keyword));
} else {
// 精准搜索
nameQueryBuilder.should(QueryBuilders.termQuery("courseName.keyword", keyword));
}
}三、总结
别忘记了修复旧数据,es给courseName字段新增了keyword类型的字段,默认为空。


至此,课程名称的不同,做到了精准搜索,相差的横杆不会被es索引忽略掉。