这条指令是使用 ModelScope Swift 框架对 Qwen-VL (视觉语言大模型)进行 LoRA 微调 的完整脚本。
1. 完整指令代码
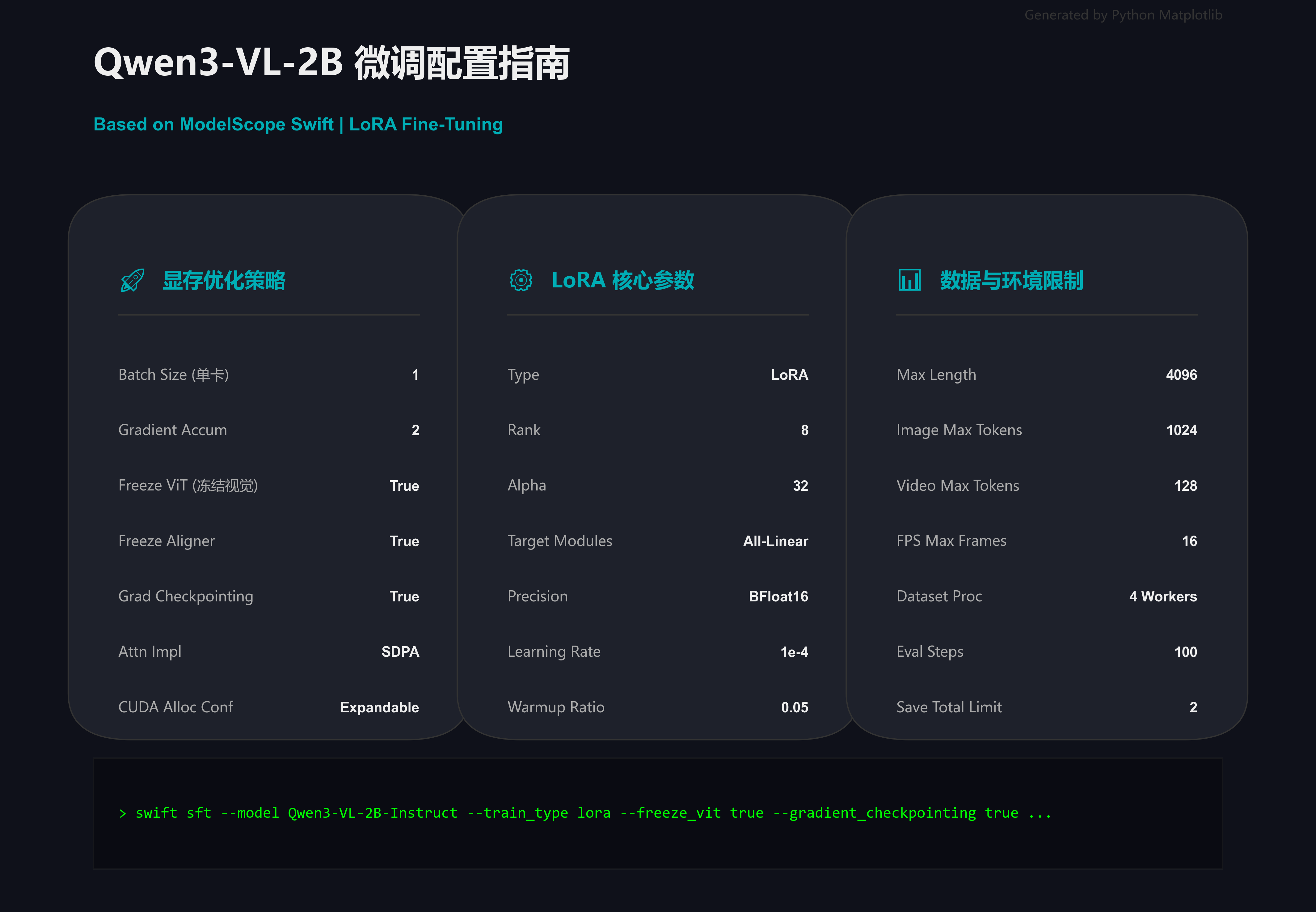
bash
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
IMAGE_MAX_TOKEN_NUM=1024 \
VIDEO_MAX_TOKEN_NUM=128 \
FPS_MAX_FRAMES=16 \
NPROC_PER_NODE=1 \
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model '/root/autodl-tmp/models/Qwen/Qwen3-VL-2B-Instruct' \
--dataset /root/autodl-tmp/plate/train.jsonl \
--val_dataset /root/autodl-tmp/plate/val.jsonl \
--load_from_cache_file true \
--split_dataset_ratio 0.01 \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--attn_impl sdpa \
--padding_free false \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--freeze_aligner true \
--packing false \
--gradient_checkpointing true \
--vit_gradient_checkpointing false \
--gradient_accumulation_steps 2 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 4096 \
--output_dir /root/autodl-tmp/loras/Qwen/Qwen3-VL-2B-Instruct \
--warmup_ratio 0.05 \
--dataset_num_proc 4 \
--dataloader_num_workers 42. 详细参数解析
2.1 环境变量配置 (Environment Variables)
这些变量在 Python 脚本启动前配置了显存管理和多模态数据的处理上限。
| 变量名 | 值 | 说明 |
|---|---|---|
| PYTORCH_CUDA_ALLOC_CONF | 'expandable_segments:True' |
显存防碎片化。允许 CUDA 内存分配器创建可扩展的内存段,防止在显存有剩余但碎片化严重时出现 OOM 错误。 |
| IMAGE_MAX_TOKEN_NUM | 1024 |
图像 Token 限制。限制单张图片被编码后的最大 Token 数,防止高分辨率图片撑爆显存。 |
| VIDEO_MAX_TOKEN_NUM | 128 |
视频 Token 限制。限制视频数据编码后的最大 Token 数量。 |
| FPS_MAX_FRAMES | 16 |
视频帧数限制。如果是视频数据,最多抽取 16 帧进行训练。 |
| NPROC_PER_NODE | 1 |
进程数。每个节点启动的进程数,通常设为 1 代表单卡或单进程控制。 |
| CUDA_VISIBLE_DEVICES | 0 |
显卡指定。只让脚本看到并使用 ID 为 0 的第一张显卡。 |
2.2 模型与数据路径 (Model & Data)
--model '/root/autodl-tmp/models/Qwen/Qwen3-VL-2B-Instruct'- 模型路径:指定基础模型的加载路径。
--dataset /root/autodl-tmp/plate/train.jsonl- 训练集:训练数据的绝对路径,通常为 JSONL 格式。
--val_dataset /root/autodl-tmp/plate/val.jsonl- 验证集:用于评估模型效果的数据集路径。
--load_from_cache_file true- 读取缓存 :是否加载预处理后的缓存数据。设为
true可加速二次启动,避免重复 Tokenize。
- 读取缓存 :是否加载预处理后的缓存数据。设为
--split_dataset_ratio 0.01- 切分比例 :若未提供验证集,从训练集中切分 1% 作为验证集(因已指定
val_dataset,此项多为备用)。
- 切分比例 :若未提供验证集,从训练集中切分 1% 作为验证集(因已指定
2.3 训练核心配置 (Training Core)
--train_type lora- 微调方式 :使用 LoRA (Low-Rank Adaptation)。相比全量微调,显存占用极低,训练速度快。
--torch_dtype bfloat16- 计算精度 :使用
bfloat16。在 30系/40系/A100 等显卡上比float16更稳定,不易溢出。
- 计算精度 :使用
--attn_impl sdpa- 注意力机制 :使用 PyTorch 内置的 SDPA (Scaled Dot Product Attention) 进行加速。
--num_train_epochs 1- 训练轮数:所有数据仅训练 1 个 Epoch。
2.4 显存优化策略 (VRAM Optimization)
这是一个极度节省显存的配置方案:
--per_device_train_batch_size 1- 训练 Batch :单卡每次只处理 1 条数据,最大限度降低显存峰值。
--per_device_eval_batch_size 1- 验证 Batch:验证时单卡也只处理 1 条数据。
--gradient_accumulation_steps 2- 梯度累积:累积 2 步梯度更新一次权重。
- 等效 Batch Size = 1 (单卡) × 1 (显卡数) × 2 (累积) = 2。
--gradient_checkpointing true- 梯度检查点 :开启后不保存中间激活值,反向传播时重新计算。显著降低显存占用,但略微拖慢速度。
--freeze_vit true- 冻结视觉塔 :不训练视觉编码器(Vision Transformer)。
--freeze_aligner true- 冻结对齐器 :不训练 连接层(Projector)。结合上一条,意味着仅微调 LLM 部分。
--vit_gradient_checkpointing false- ViT 检查点:因视觉部分已被冻结(不参与计算图),故无需开启此项。
2.5 LoRA 参数详解 (LoRA Config)
--lora_rank 8- 秩 (Rank):LoRA 矩阵的秩。8 是较小的值,参数量少,显存占用低。
--lora_alpha 32- 缩放系数 (Alpha):通常设为 Rank 的 2-4 倍。控制 LoRA 权重对模型的影响程度。
--target_modules all-linear- 目标模块:将 LoRA 挂载到所有的线性层(Q, K, V, O, Gate, Up, Down)。效果通常优于仅挂载 Attention 层。
2.6 数据处理与长度 (Data Processing)
--padding_free false- 无填充模式:关闭 Padding Free。使用常规 Padding 对齐 Batch。
--packing false- 多样本打包:关闭打包。多模态训练中关闭此项较稳妥,防止图片 Token 上下文错位。
--max_length 4096- 最大长度:单条数据(含图片+文本)的最大 Token 数,超过则截断。
2.7 优化器、日志与保存 (Optimizer & Logging)
--learning_rate 1e-4- 学习率 :初始学习率设为
1e-4,LoRA 常用的大于全量微调的学习率。
- 学习率 :初始学习率设为
--warmup_ratio 0.05- 预热比例:前 5% 的 Step 学习率从 0 线性增加,用于稳定初期训练。
--output_dir /root/...- 输出目录:模型权重、日志、配置文件的保存位置。
--logging_steps 5- 日志频率:每 5 步打印一次 Loss。
--eval_steps 100- 评估频率:每 100 步在验证集上评估一次。
--save_steps 100- 保存频率:每 100 步保存一次 Checkpoint。
--save_total_limit 2- 保存数量:最多保留最新的 2 个模型存档,防止硬盘爆满。
2.8 进程设置 (Process)
--dataset_num_proc 4- 预处理进程:使用 4 个 CPU 进程进行数据预处理。
--dataloader_num_workers 4- 数据加载线程:PyTorch DataLoader 使用 4 个子进程加载数据。