本文仅针对图片OCR场景训练。
1.服务器
租赁的AutoDL服务器,配置如下:

使用情况如下:
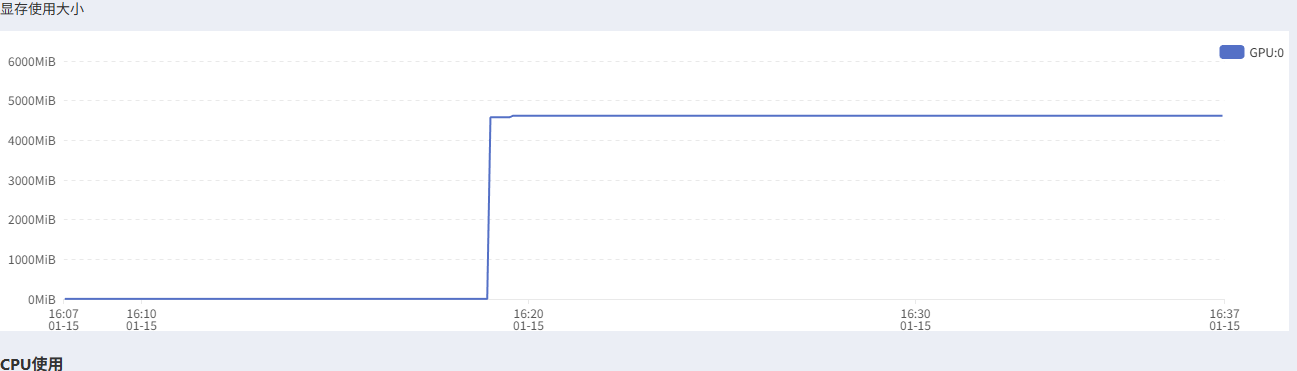

综上,不用租配置太高的显卡。
2.安装运行环境
bash
# 创建python环境
python -m venv qwen3_env
source qwen3_env/bin/activate
# 安装ms-swift
pip install ms-swift[vl]
# 安装modelscope
pip install modelscope
# 安装torchvision、qwen_vl_utils
pip install -U torchvision --index-url https://download.pytorch.org/whl/cu128
pip install "qwen_vl_utils>=0.0.14" "decord" -U
# 下载模型
modelscope download --model Qwen/Qwen3-VL-2B-Instruct --local_dir /root/autodl-tmp/models/Qwen/Qwen3-VL-2B-Instruct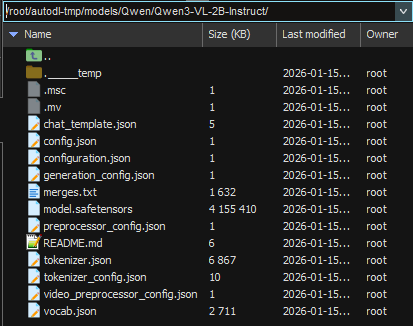
3.准备微调数据
类似下面这样,图片路径、提示词、识别结果。
json
{"images": ["/root/autodl-tmp/plate/images/001.png"],"query": "请识别车牌图像,输出仅包含汉字、字母和数字的纯文本,不含任何其他符号或空格。","response": "301821"}
{"images": ["/root/autodl-tmp/plate/images/002.png"],"query": "请识别车牌图像,输出仅包含汉字、字母和数字的纯文本,不含任何其他符号或空格。","response": "W3L201"}分为训练集、验证集。
4.微调命令
直接在命令行运行
bash
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
IMAGE_MAX_TOKEN_NUM=1024 \
VIDEO_MAX_TOKEN_NUM=128 \
FPS_MAX_FRAMES=16 \
NPROC_PER_NODE=1 \
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model '/root/autodl-tmp/models/Qwen/Qwen3-VL-2B-Instruct' \
--dataset /root/autodl-tmp/plate/train.jsonl \
--val_dataset /root/autodl-tmp/plate/val.jsonl \
--load_from_cache_file true \
--split_dataset_ratio 0.01 \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--attn_impl sdpa \
--padding_free false \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--freeze_aligner true \
--packing false \
--gradient_checkpointing true \
--vit_gradient_checkpointing false \
--gradient_accumulation_steps 2 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 4096 \
--output_dir /root/autodl-tmp/loras/Qwen/Qwen3-VL-2B-Instruct \
--warmup_ratio 0.05 \
--dataset_num_proc 4 \
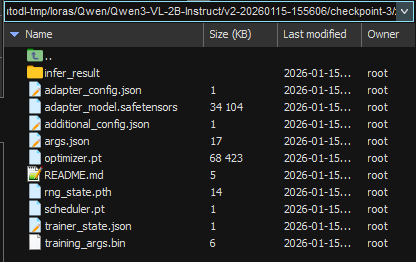
--dataloader_num_workers 4微调的lora模型:
5.推理
bash
CUDA_VISIBLE_DEVICES=0 \
IMAGE_MAX_TOKEN_NUM=1024 \
VIDEO_MAX_TOKEN_NUM=128 \
FPS_MAX_FRAMES=16 \
swift infer \
--adapters /root/autodl-tmp/loras/Qwen/Qwen3-VL-2B-Instruct/v2-20260115-155606/checkpoint-3/ \
--stream true出现"<<<"后,先输入"ocr",再按照提示输入图片路径,如下图所示:
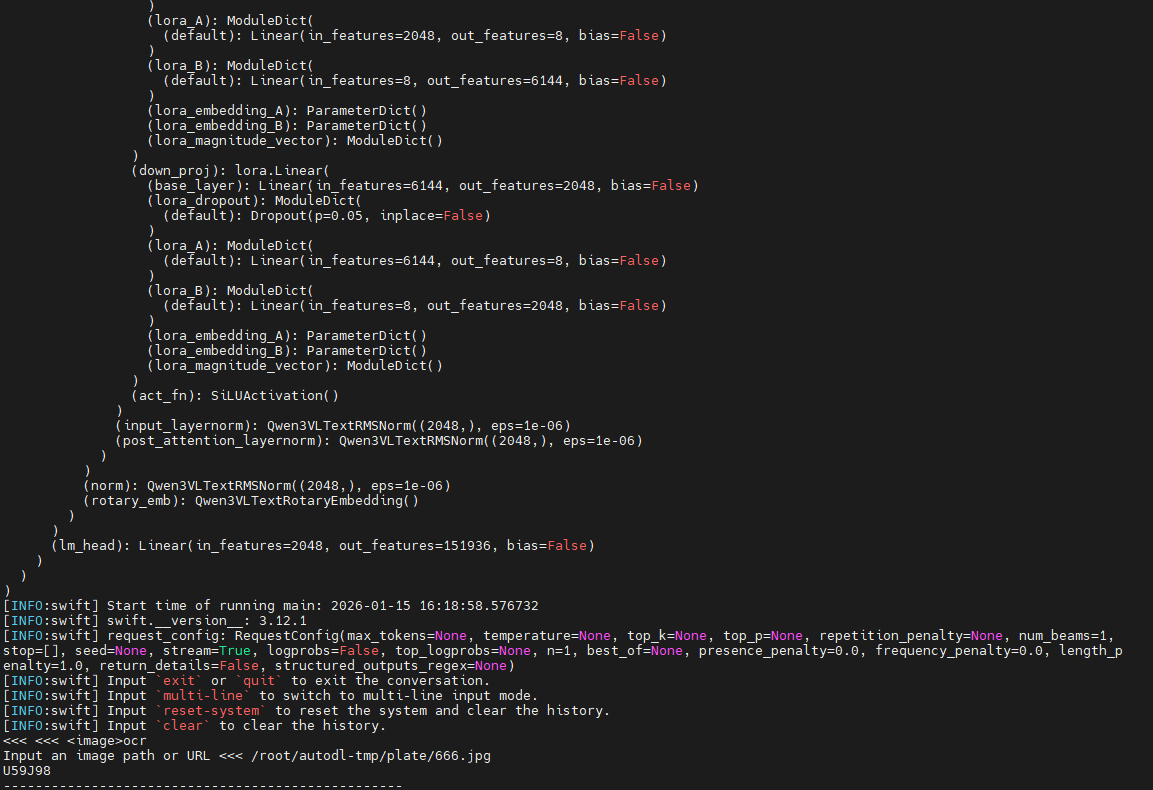
6.其它说明
- 仅为演示,数据较少,实际项目中要多准备些数据。
- 相关资源:https://pan.baidu.com/s/1PDSd03mF0k-GxrI7alHyVQ?pwd=sp6r
