#define ADD(a,b) a + b;
//错误,宏函数后面不能加分号;况且在调用宏函数时写入的是表达式,会出现运算符优先级的问题
int main()
{
int ret1 = ADD(1, 2);
//如果仍然带着分号,这个表达式展开就会是:
int ret1 = 1 + 2;; //会出现两个分号。
return 0;
}
问题一是不能加分号,在去掉分号后仍然有错误:
cpp复制代码
#define ADD(a,b) a + b
int main()
{
int ret1 = ADD(1, 2);
//这里没有问题
int ret2 = ADD(1, 2) * 3;//但是这里就出现问题了
//原本应该计算3*3=9,这里是1+2*3 = 7,由于优先级,所以结果不同
return 0;
}
所以,宏函数的表达式应该带上括号 ( a + b )。
3)坑3:
cpp复制代码
//#define ADD(a,b) (a + b)
//错误,调用该宏的时候写入的是表达式,仍然会出现运算符优先级的问题,如:
#define ADD(a,b) (a + b)
int main()
{
int ret2 = ADD(1, 2) * 3;
cout << ret2 << endl;//这里就没问题了,结果为9
//但是在下面的场景仍然会出错:
int x = 0, y = 1;
int ret3 = ADD(x | y, x & y);
cout << ret3 << endl;//仍然会出现运算符优先级的问题
//展开之后:int ret3 = x | y + x & y;
//+号的优先级高于 | 和 & 所以这里先执行y+x,跟我们的想法不符
return 0;
}
宏函数的正确写法:
cpp复制代码
//正确写法:
#define ADD(a,b) ((a) + (b))
int main()
{
int ret1 = ADD(1, 2);
cout << ret1 << endl;
int ret2 = ADD(1, 2) * 3;
cout << ret2 << endl;
int x = 0, y = 1;
int ret3 = ADD(x | y, x & y);
cout << ret3 << endl;
//这次这三个结果都正确,符合预期
return 0;
}
//在C++中我们觉得宏函数太麻烦,所以使用inline内联函数代替宏
//正确使用inline函数:
inline int Add(int a, int b)
{
return a + b;
}
3.默认debug版本下,为了方便调试,inline也不展开。要想展开,我们需要完成两设置:
cpp复制代码
#include<iostream>
using namespace std;
//转反汇编看,发现还是有call------还是创建了栈帧,这是为什么
inline int ADD(int a, int b)
{
return a + b;
}
//因为默认debug版本下,为了方便调试,inline也不展开
//我们需要设置一下,这里大家可以自己测试看看
int main()
{
int ret2 = ADD(1, 2) * 3;
cout << ret2 << '\n';
return 0;
}
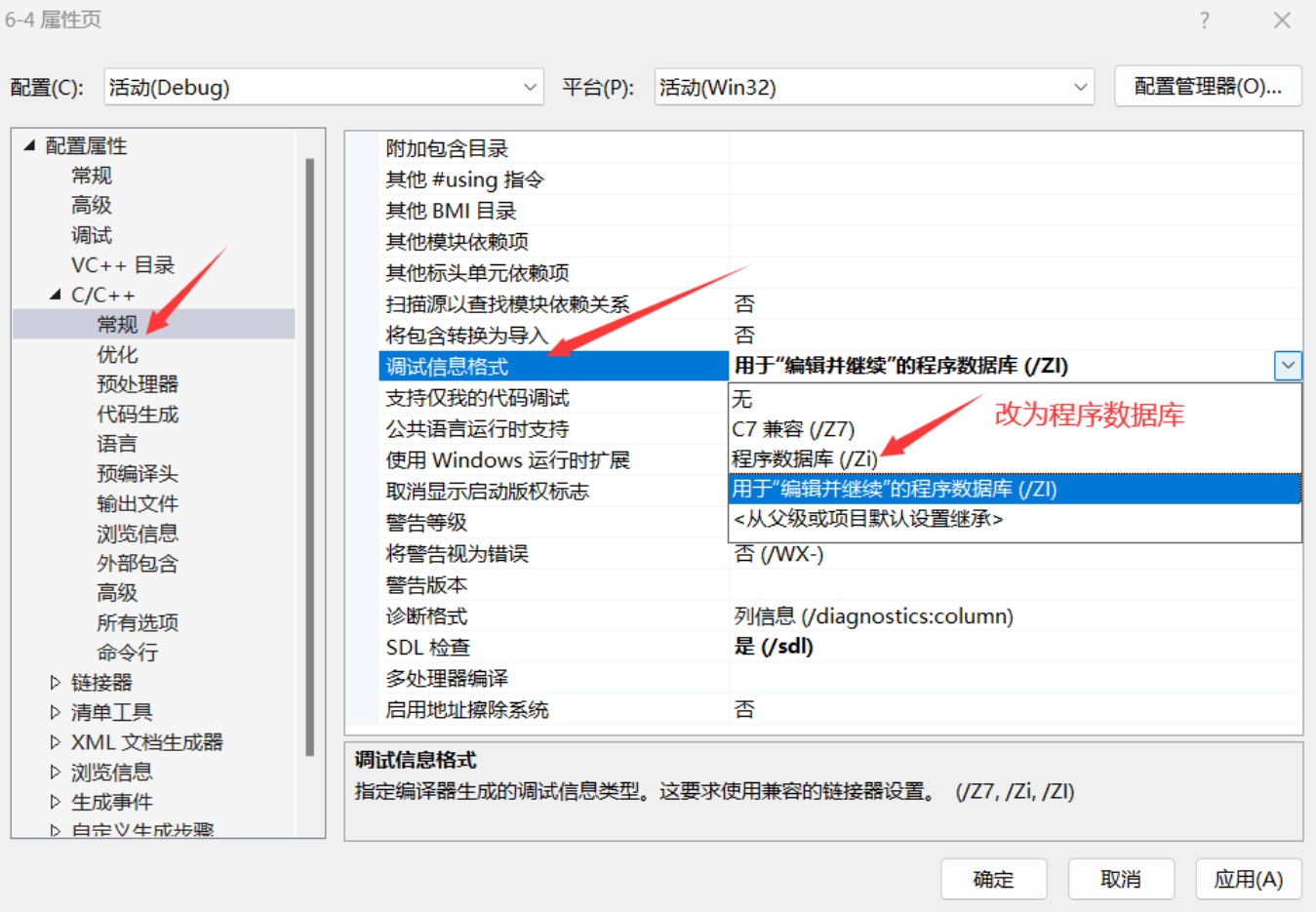
设置步骤:
1.右键单击解决方案资源管理器中的项目,选择"属性 "。
2.在弹出的属性对话框中,找到"C / C++ "选项卡,点击"常规 "。
3.在"调试信息格式 "下拉菜单中,选择"程序数据库(/ Zi) "。
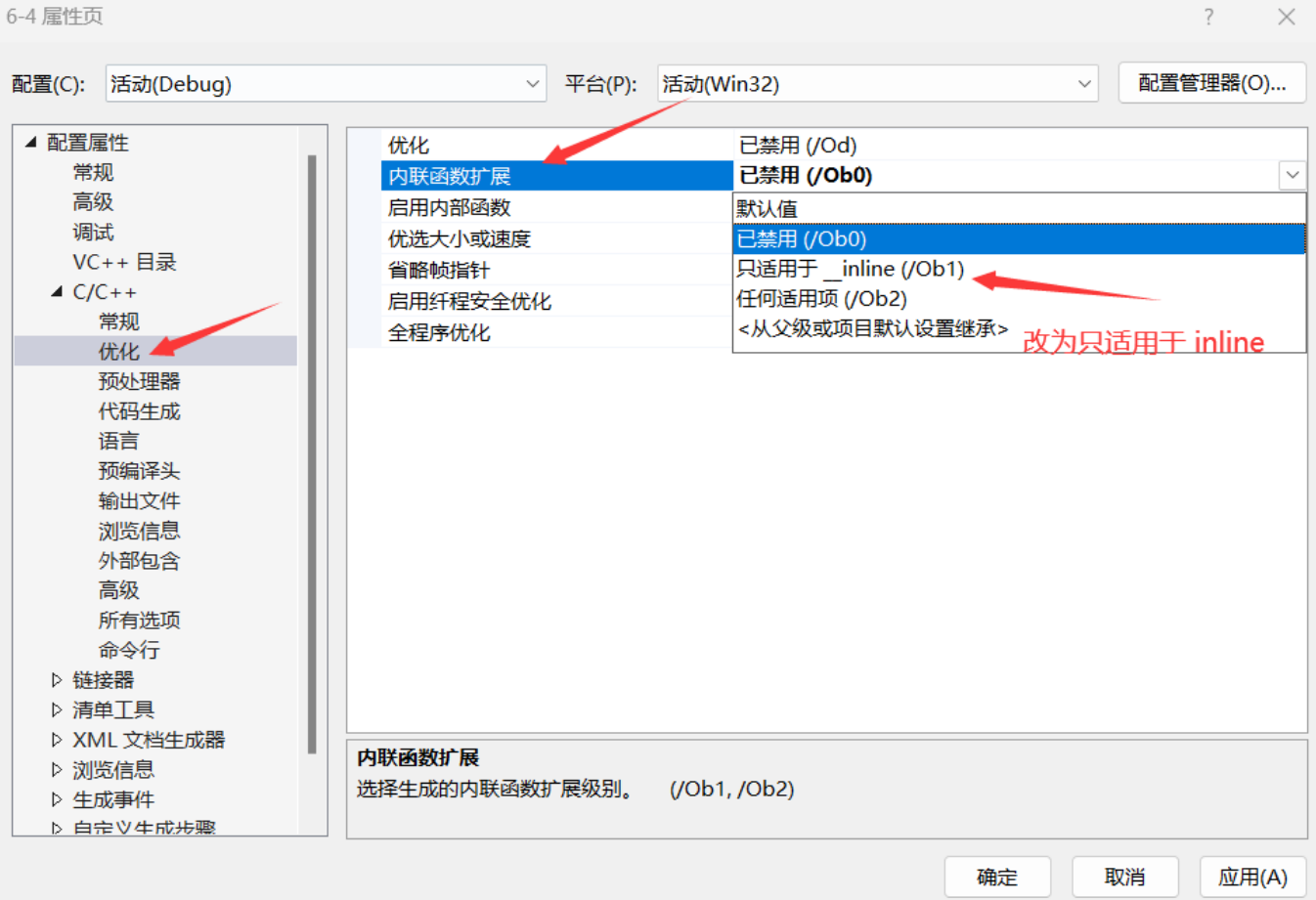
4.接着点击"C / C++"下的"优化 "选项。
5.在"内联函数的扩展 "下拉菜单中,选择"只适用于_inline(/ Ob1)"
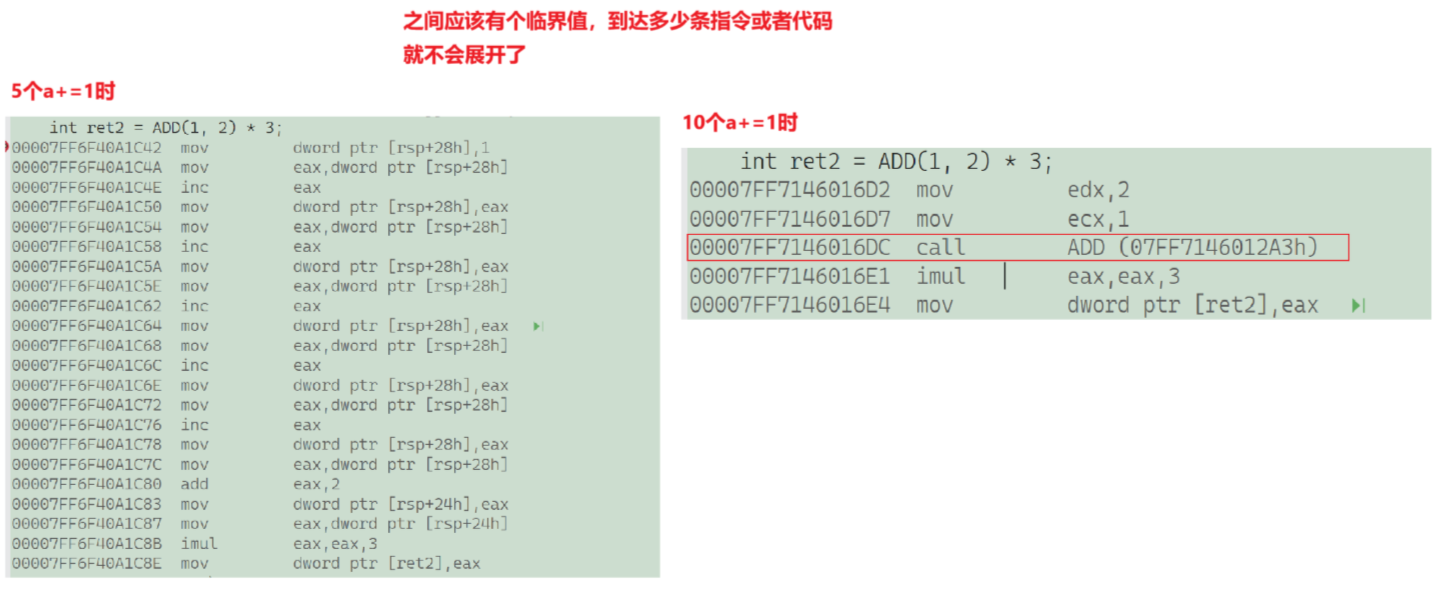
4.inline只是一个建议,展开还是 不展开由编译器说的算,递归和代码多的函数可能就会不展开:
cpp复制代码
#include<iostream>
using namespace std;
inline int ADD(int a, int b)
{
a += 1;
a += 1;
a += 1;
a += 1;
a += 1;
a += 1;
a += 1;
a += 1;
a += 1;
a += 1;
//5个的时候还是可以展开的,10个就不再展开了
return a + b;
}
int main()
{
int ret2 = ADD(1, 2) * 3;
cout << ret2 << '\n';
return 0;
}
#pragma once
#include<iostream>
#include<stdlib.h>
typedef struct SeqList
{
int* arr;
int size;
int capacity;
}SL;
inline void SLInit(SL& pls, int n = 4)
{
pls.arr = (int*)malloc(n * sizeof(int));
pls.size = 0;
pls.capacity = n;
}
void SLPushBack(SL& pls, int x);
int SLFind(SL& pls, int x, int i = 0);
int& SLat(SL& pls, int i);
void SLModify(SL& pls, int i, int x);
SeqList.cpp(这里的SLInit就给注释了)
cpp复制代码
#include"SeqList.h"
//void SLInit(SL& pls,int n)
//{
// pls.arr = (int*)malloc(n * sizeof(int));
// pls.size = 0;
// pls.capacity = n;
//}
void SLPushBack(SL& pls, int x)
{
//...
pls.arr[pls.size++] = x;
}
int SLFind(SL& pls, int x, int i)
{
while (i < pls.size)
{
//...
}
//...
return -1;
}
int& SLat(SL& pls, int i)
{
//...
return pls.arr[i];
}
void SLModify(SL& pls, int i, int x)
{
//...
pls.arr[i] = x;
}