有评论在看专栏《7天读懂MYSQL》时,对MVCC有疑惑,今天就写一篇MVCC详解,开搞!
1. MVCC概述
1.1 什么是MVCC
MVCC(Multi-Version Concurrency Control,多版本并发控制)是InnoDB存储引擎实现事务隔离级别的核心机制,它通过为每行数据维护多个版本,使读操作无需加锁,从而实现高并发下的数据一致性。
1.2 为什么需要MVCC
在传统锁机制下:
- 读操作需要获取共享锁,阻塞写操作
- 写操作需要获取排他锁,阻塞所有其他操作
- 高并发场景下,锁竞争导致性能急剧下降
MVCC解决的核心问题:
- 实现"无锁读":读操作直接访问数据的历史版本,无需等待
- 提升并发性能:读操作不阻塞写操作,写操作不阻塞读操作
- 保障事务隔离性:为
READ COMMITTED和REPEATABLE READ提供实现基础
2、⭐MVCC的核心数据结构
2.1 隐藏字段
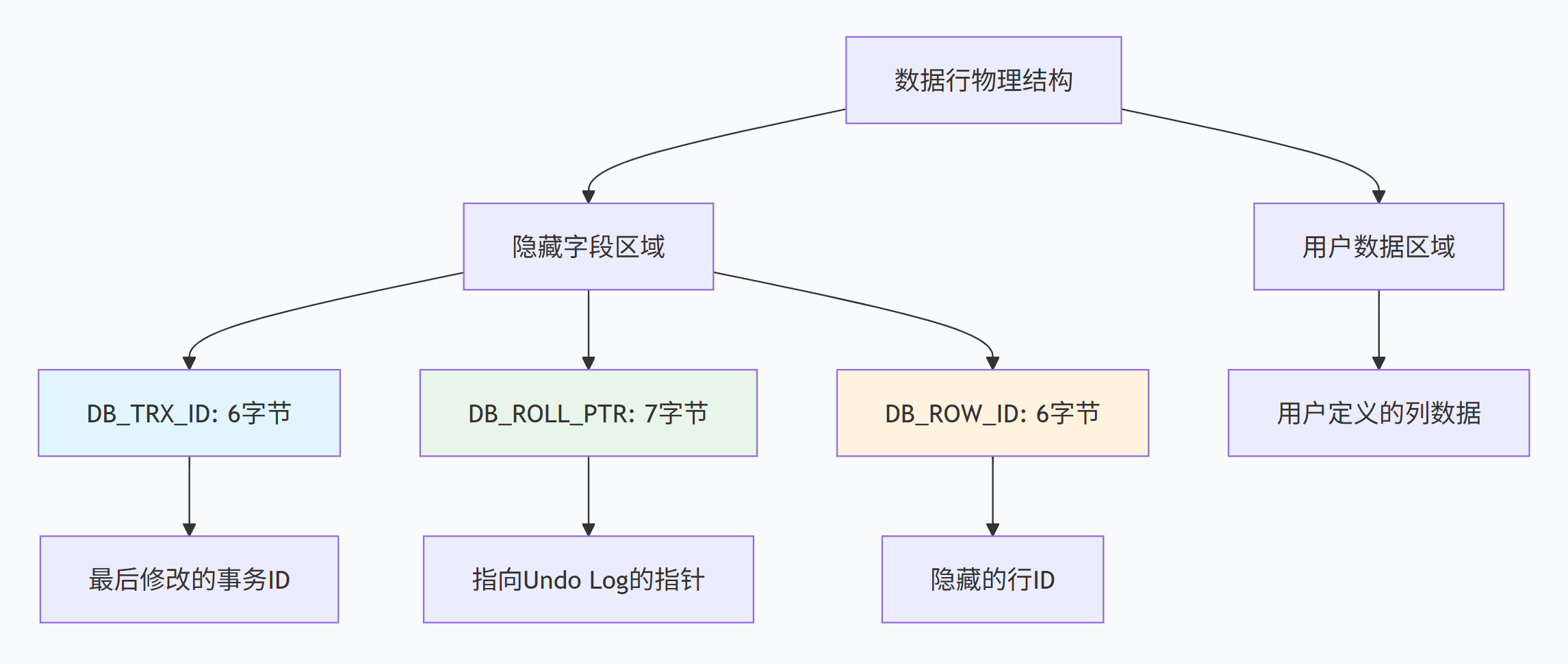
InnoDB在每行数据中添加三个隐藏字段来支持MVCC:
-
DB_TRX_ID(6字节):记录最后一次修改该行数据的事务ID。这个ID是全局递增的,每个新事务都会获得一个更大的ID。
-
DB_ROLL_PTR(7字节):回滚指针,指向该行数据的上一个版本在Undo Log中的位置。通过这个指针,可以遍历整条版本链。
-
DB_ROW_ID(6字节):当表没有定义主键时,InnoDB会自动生成这个隐藏主键。对于有主键的表,这个字段仍然存在但不一定使用。
2.2 ReadView(读视图)
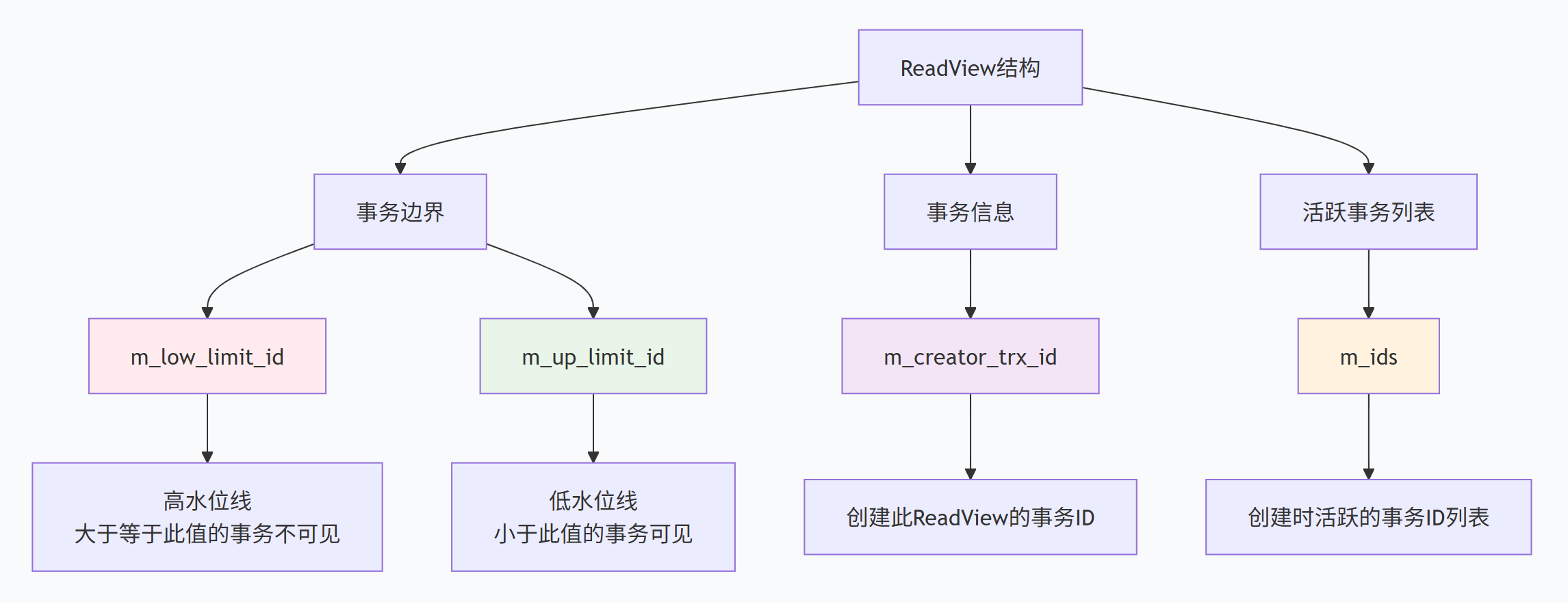
ReadView是MVCC实现快照读的关键数据结构,它定义了事务能看到的数据版本范围。
-
m_low_limit_id:高水位线,事务ID大于等于这个值的事务对当前ReadView不可见
-
m_up_limit_id:低水位线,事务ID小于这个值的事务对当前ReadView可见
-
m_creator_trx_id:创建此ReadView的事务ID
-
m_ids:ReadView创建时,系统中所有活跃(未提交)事务的ID列表
2.3 Undo Log(回滚日志)
Undo Log不仅用于事务回滚,更是MVCC版本链的物理存储。每个修改操作都会创建对应的Undo Log记录。
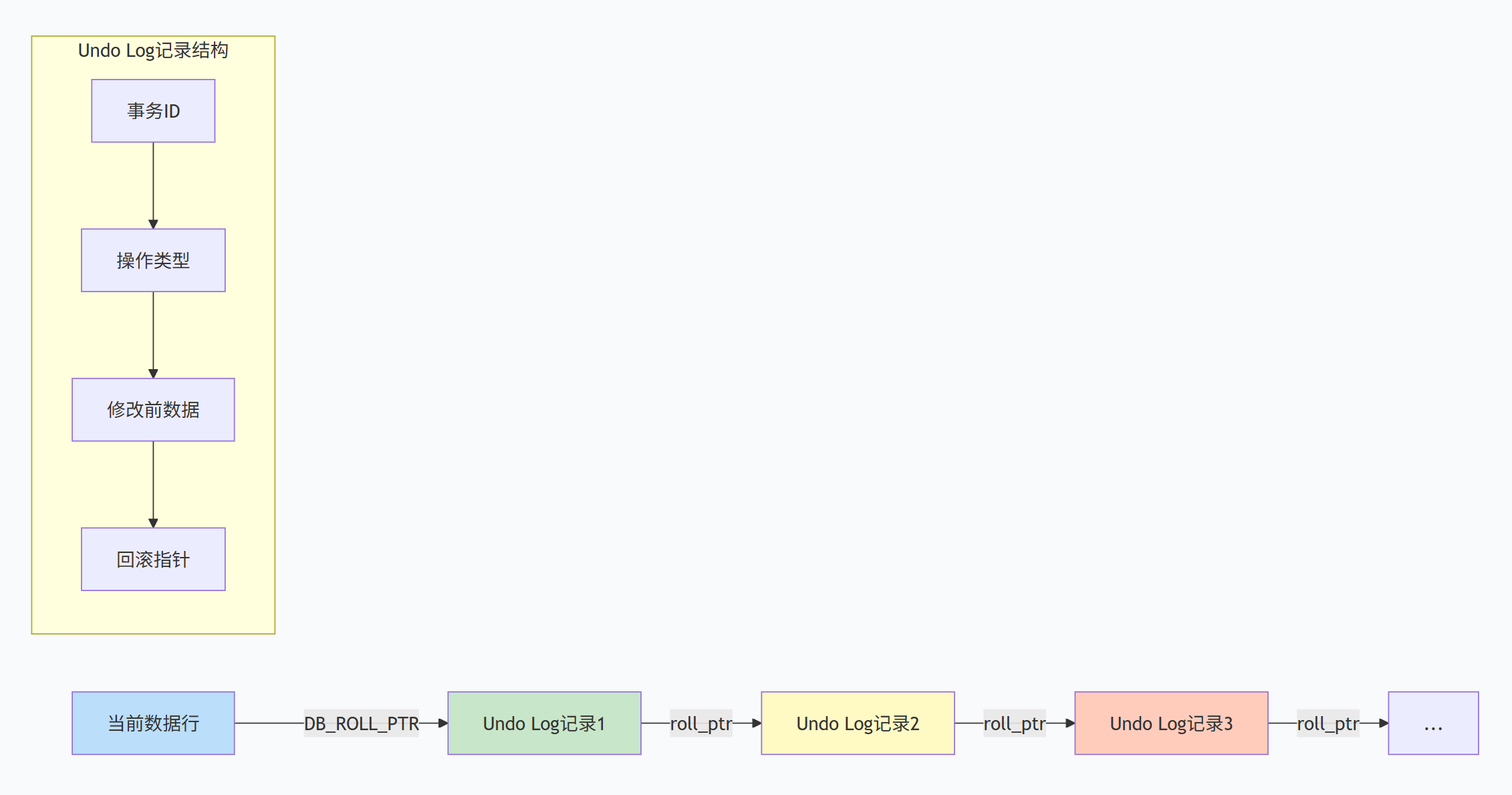
Undo Log的关键特性:
-
类型分类:
-
INSERT Undo Log:记录插入操作,只用于回滚,事务提交后可删除
-
UPDATE/DELETE Undo Log:记录更新/删除操作,用于回滚和MVCC版本链
-
-
版本链构建:
-
每次更新操作都会创建新的Undo Log记录
-
新的Undo Log记录指向上一个版本
-
通过DB_ROLL_PTR可以遍历整个版本链
-
-
生命周期管理:
-
活跃事务引用的版本必须保留
-
不再被任何事务需要的版本由Purge线程清理
-
3、⭐MVCC的工作流程
3.1 快照读的流程(SELECT)
快照读是指普通的SELECT查询,读取数据的历史版本,不需要加锁。
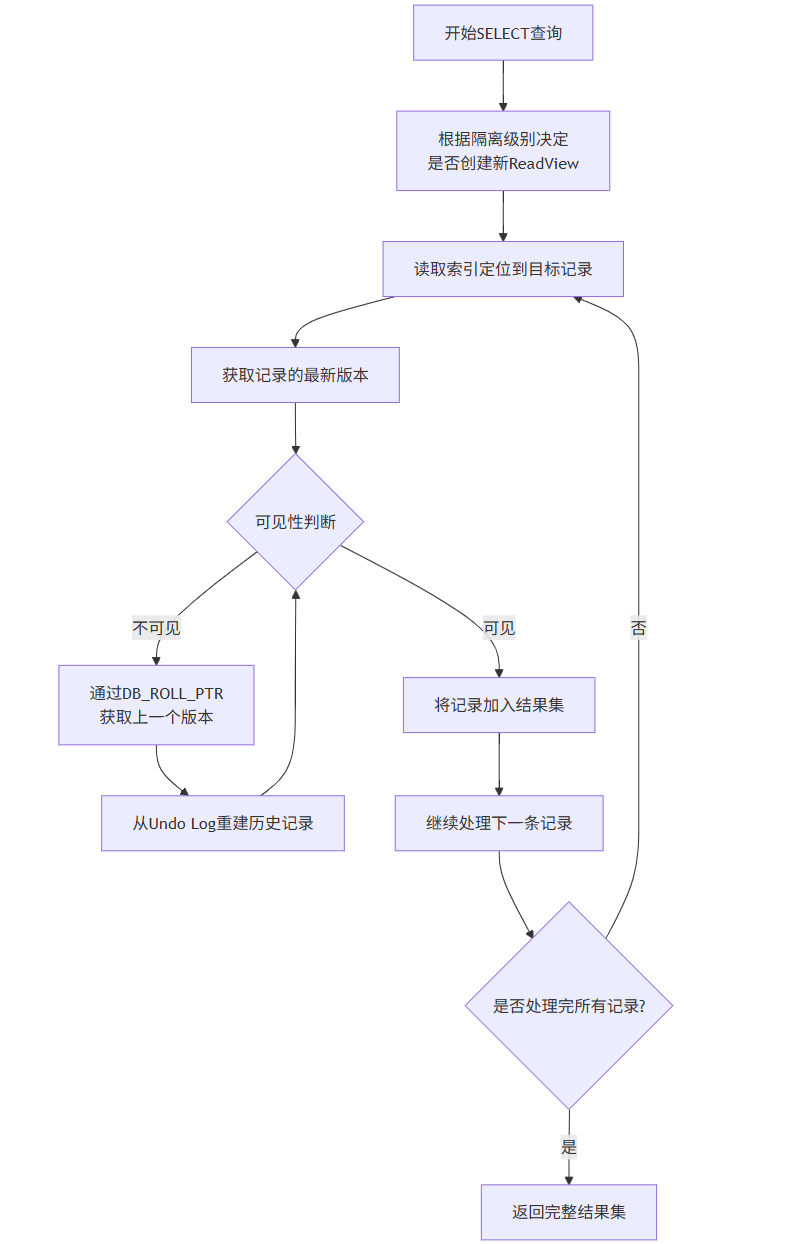
快照读的关键步骤:
ReadView生成:
RC级别:每次SELECT都生成新ReadView
RR级别:第一次SELECT生成ReadView,后续查询复用
版本定位:
通过索引找到目标记录
读取聚簇索引中的最新版本
可见性判断:
使用ReadView的可见性规则判断当前版本是否可见
如果不可见,沿版本链回溯查找可见版本
结果构建:
将可见版本加入结果集
继续处理下一条记录
3.2 当前读的流程(UPDATE/DELETE/INSERT)
当前读需要读取数据的最新版本,并对读取的记录加锁,确保数据的一致性。
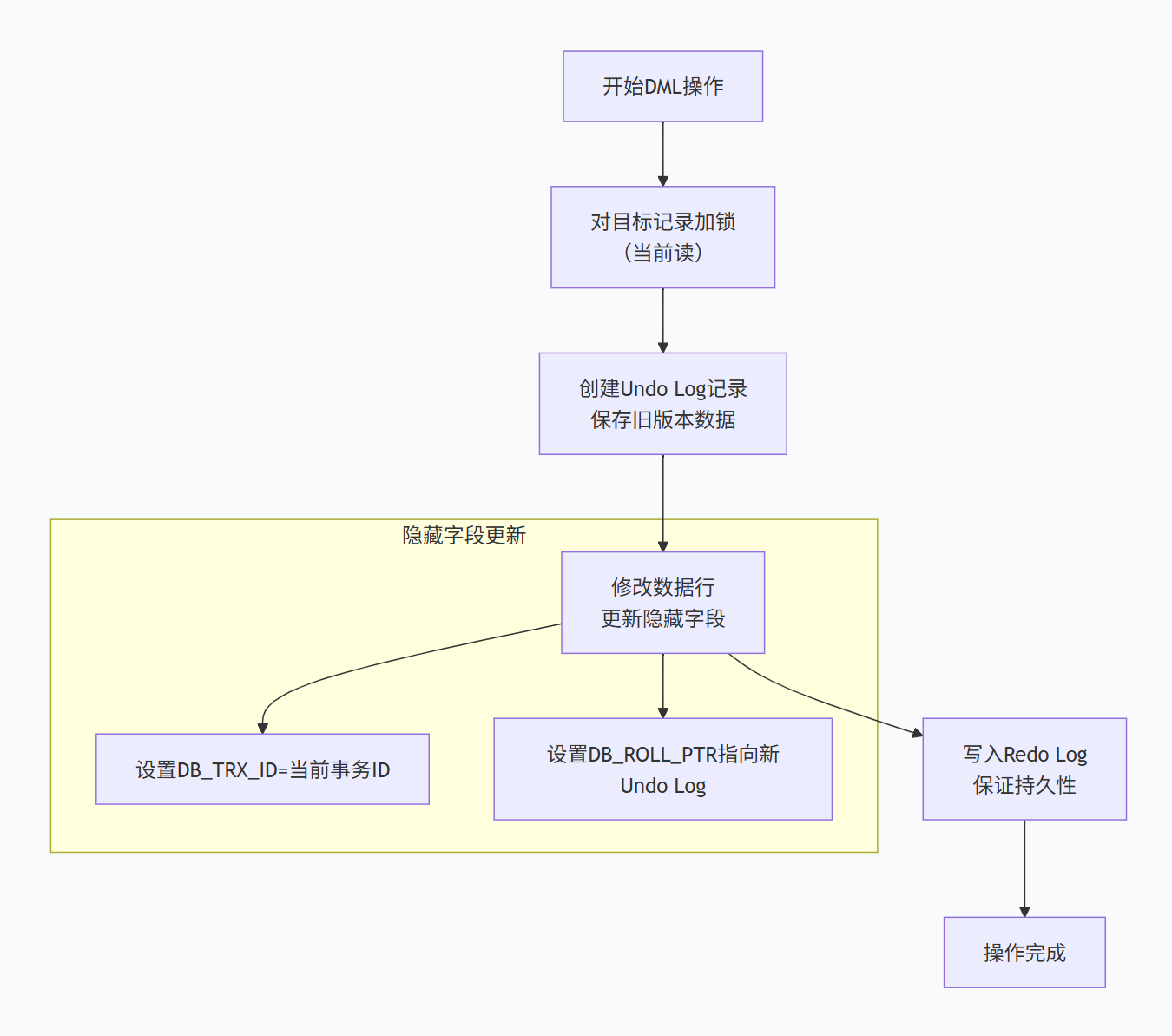
当前读的关键特点:
必须加锁:防止其他事务并发修改同一数据
读取最新版本:忽略历史版本,直接操作当前数据
创建新版本:每次修改都会创建新版本,旧版本进入Undo Log
隐藏字段更新:
DB_TRX_ID设置为当前事务ID
DB_ROLL_PTR指向新创建的Undo Log
4、不同隔离级别下的MVCC
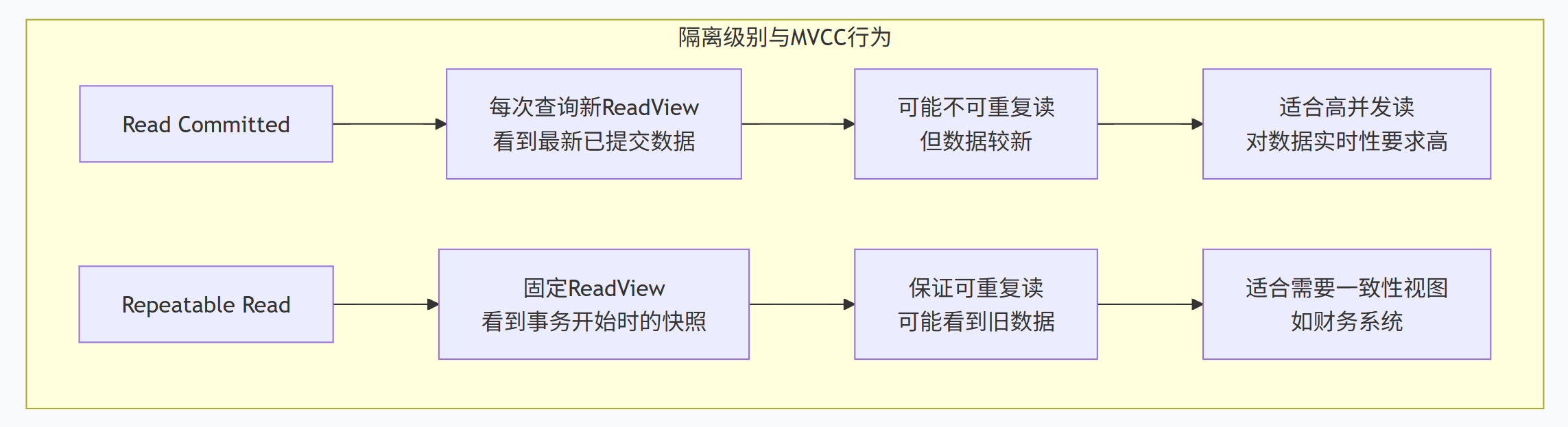
4.1 Read Committed(读已提交)
RC级别下,事务能读取到其他事务已提交的最新数据。
核心特点:
-
每次SELECT都生成新的ReadView
-
能看到其他事务最新提交的修改
-
可能发生"不可重复读"现象,同一事务中多次查询结果不一致
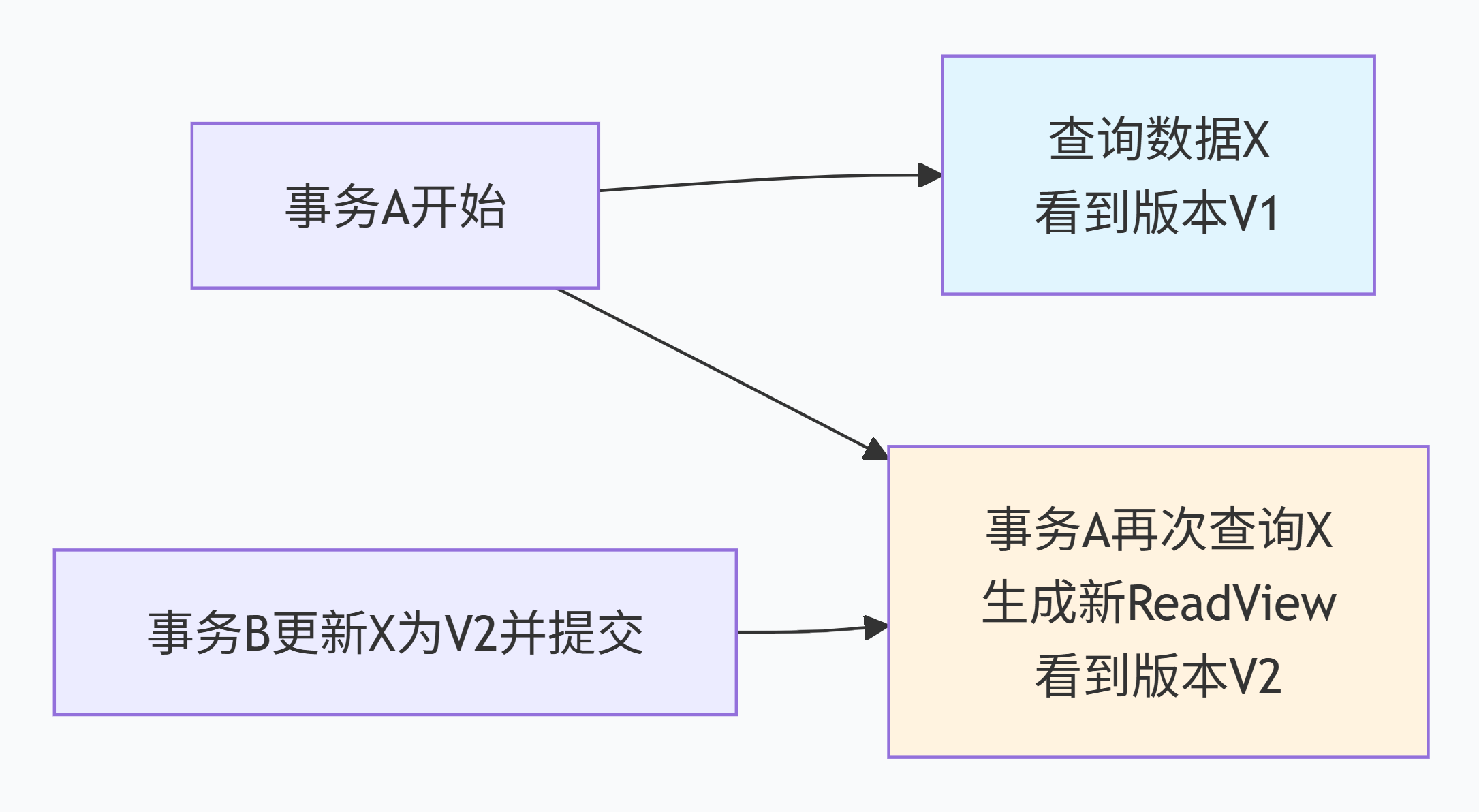
RC级别的ReadView生成:
每次执行SELECT时创建新的ReadView
ReadView反映查询时刻的数据库状态
可能看到查询前已提交的其他事务修改
4.2 Repeatable Read(可重复读)
RR级别下,事务在整个过程中看到的数据保持一致。
核心特点:
-
第一次SELECT时生成ReadView,后续查询复用
-
整个事务期间看到相同的数据快照,同一事务中多次查询结果一致
RR级别的关键机制:
-
ReadView固化:事务第一次查询时生成ReadView,之后一直复用
-
版本链回溯:如果最新版本不可见,沿版本链查找可见的历史版本
-
一致性快照:整个事务期间看到相同的数据状态
4.3 RC与RR下MVCC对比
五、MVCC与锁的协同工作机制
5.1 快照读 vs 当前读
MVCC与锁机制协同工作,为不同类型的操作提供适当的并发控制。
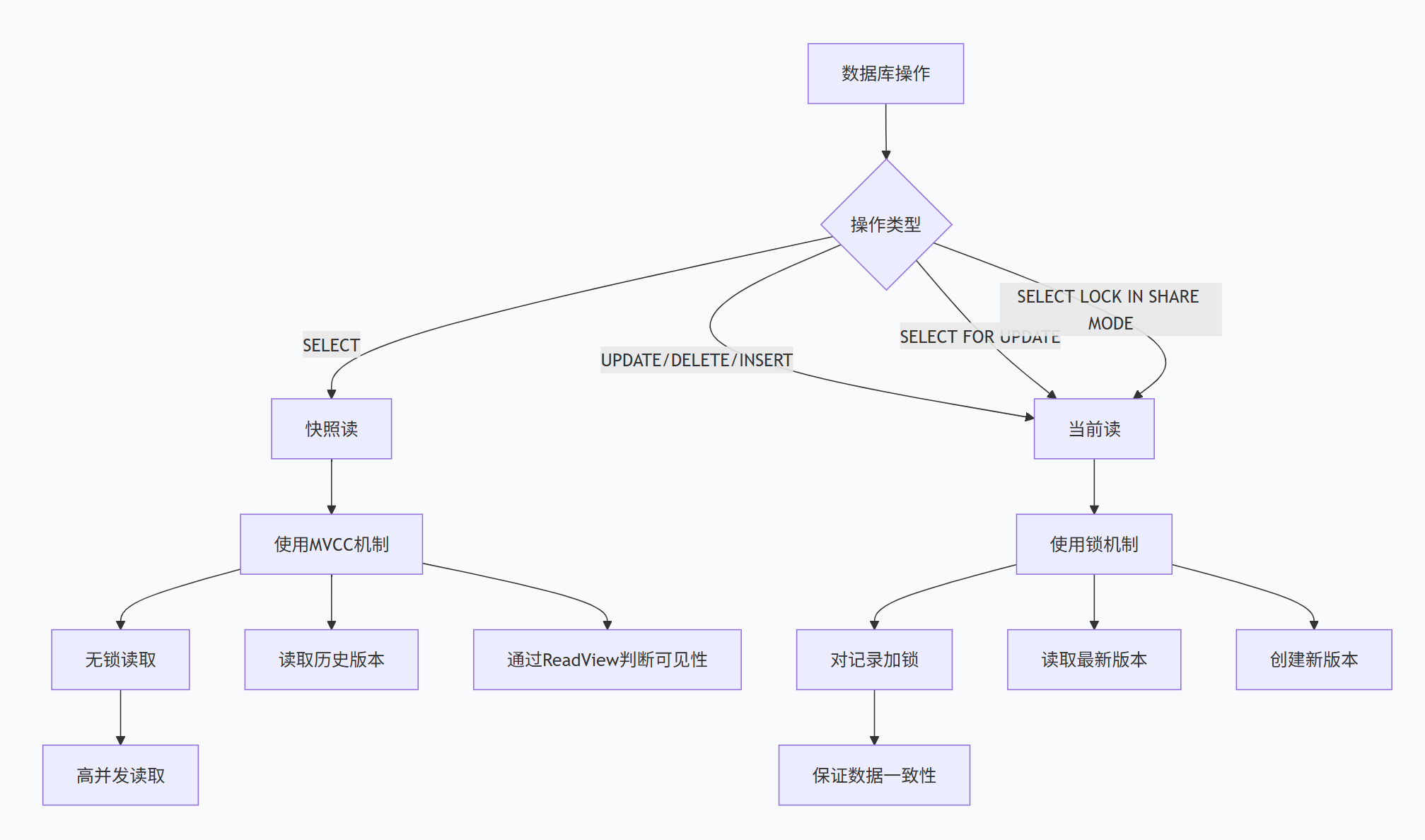
sql
-- 快照读(Snapshot Read):使用MVCC,无锁
SELECT * FROM users WHERE age > 20;
-- 当前读(Current Read):使用锁机制
SELECT * FROM users WHERE age > 20 FOR UPDATE;
SELECT * FROM users WHERE age > 20 LOCK IN SHARE MODE;
-- DML操作内部使用当前读
UPDATE users SET status = 'active' WHERE age > 20;
DELETE FROM users WHERE age > 20;5.2 Next-Key Lock:防止幻读的锁机制
在RR隔离级别下,InnoDB使用Next-Key Lock来防止幻读现象。
幻读问题:
-
事务A读取某个范围的数据
-
事务B在该范围内插入新数据并提交
-
事务A再次读取,发现多出了"幻影行"
Next-Key Lock的组成:
-
记录锁(Record Lock):锁定索引记录
-
间隙锁(Gap Lock):锁定索引记录之间的间隙
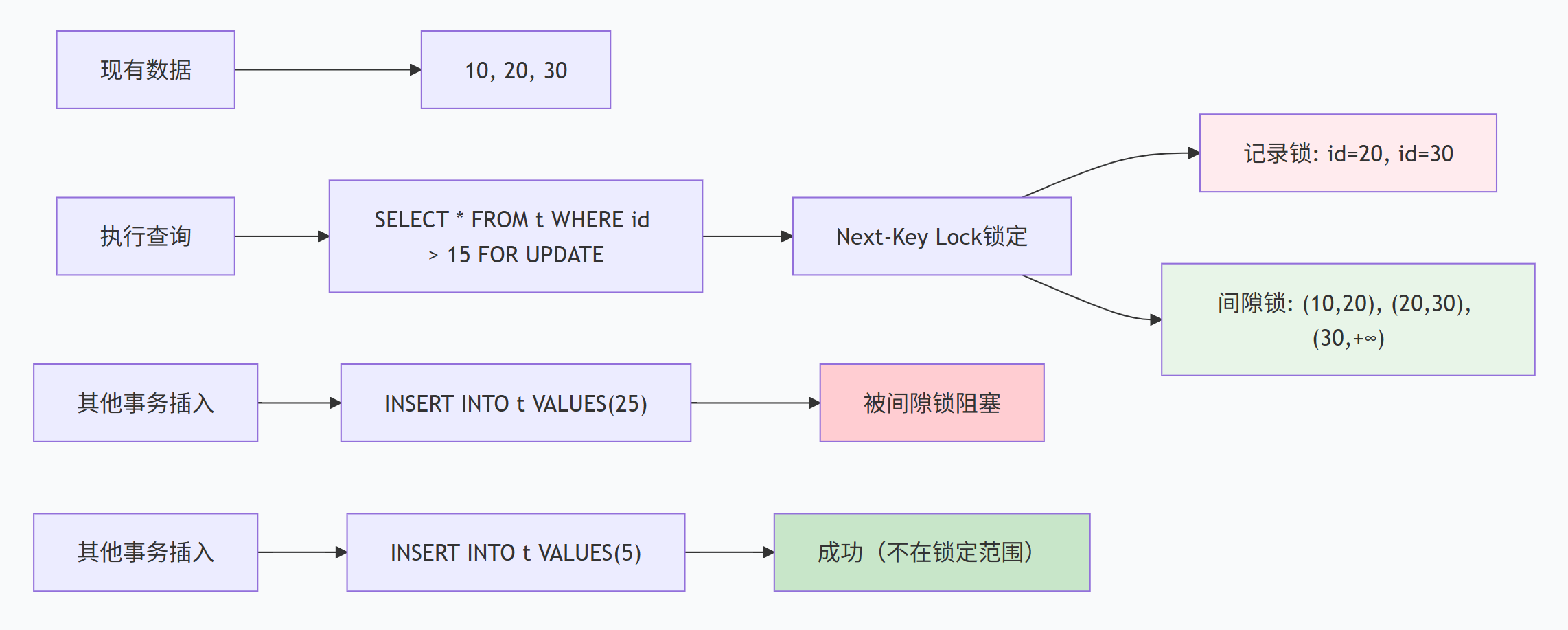
Next-Key Lock的工作机制:
锁定范围:锁定查询涉及的所有记录和间隙
防止插入:其他事务无法在锁定范围内插入新记录
允许读取:快照读仍可使用MVCC访问数据
范围控制:只锁定必要的范围,最小化对并发的影响
6. MVCC的深度误区与实战解决方案
误区1:MVCC可以解决幻读问题
真相 :MVCC在RR级别下保证了可重复读 ,但不能解决幻读。
解决方案:
- 使用
SELECT FOR UPDATE(当前读)触发Next-Key Lock- 通过间隙锁防止新行插入
误区2:MVCC完全避免锁竞争
错误认知:MVCC让所有操作都无锁,不会产生锁竞争。
事实:
快照读确实无锁,但当前读仍需加锁
写操作之间的锁竞争仍然存在
二级索引更新可能产生额外的锁
解决方案:
合理设计索引,减少锁范围
将大事务拆分为小事务,减少锁持有时间
使用乐观锁机制处理高并发更新
误区3:MVCC不会产生性能问题
错误认知:MVCC只有好处,没有性能代价。
事实:
版本链过深会降低查询性能
Undo Log占用额外存储空间
Purge操作消耗CPU和IO资源
解决方案:
监控版本链深度:
SHOW ENGINE INNODB STATUS避免长事务,减少历史版本保留时间
定期检查Undo Log空间使用情况
误区4:所有SELECT都是快照读
错误认知:所有SELECT语句都使用MVCC机制。
事实:
使用
FOR UPDATE或LOCK IN SHARE MODE的SELECT是当前读在事务中混合使用快照读和当前读可能导致数据不一致
解决方案:
明确区分业务场景,选择合适的读取方式
避免在同一事务中混用两种读取方式
对需要强一致性的查询使用当前读
7. 总结
MVCC的核心价值与深度理解
- MVCC不是简单的"多版本存储" :
- 它是通过
DB_TRX_ID、DB_ROLL_PTR和ReadView的精密配合实现的 - 事务ID是MVCC的基石,版本链是数据结构,ReadView是可见性判断的核心
- 它是通过
- MVCC与隔离级别的关系 :
- RC:每次查询生成新ReadView,看到最新已提交数据
- RR:只在第一次查询生成ReadView,保证可重复读
- MVCC的性能影响 :
- 读不阻塞写,写不阻塞读,提高并发性能
- 但版本链过长会导致性能下降,需要合理调优