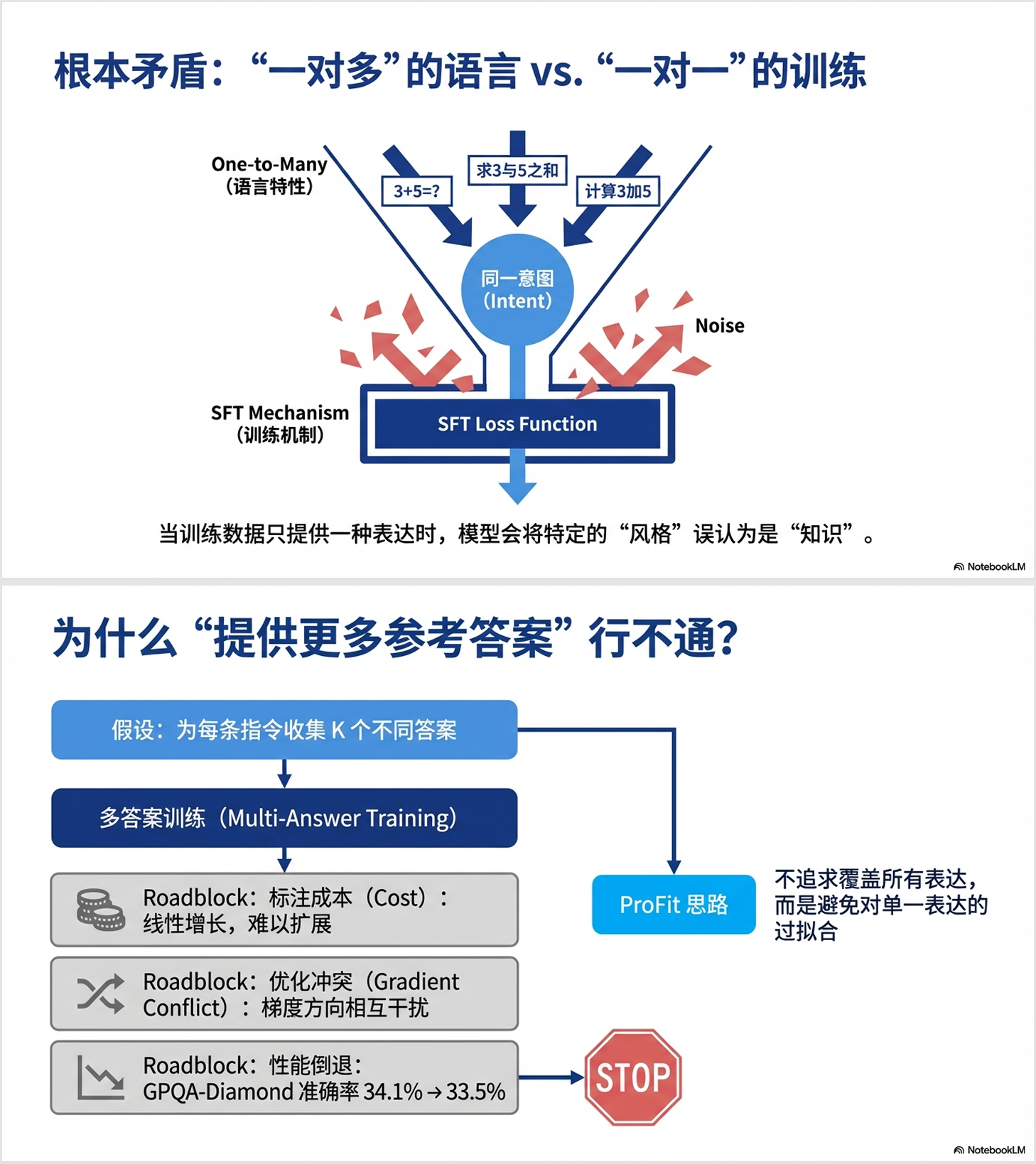
大语言模型(LLM)在完成预训练后,通常需要通过监督微调(SFT)来适配特定的下游任务。然而,传统SFT存在一个被长期忽视的根本性问题:语言的 "一对多"特性 与训练目标的 "一对一"强制对齐之间的矛盾。
什么是"一对多"特性?简单来说,同一个意图可以用多种不同的方式表达。比如:
- "请计算3加5的结果"
- "3+5等于多少?"
- "把3和5相加得到什么?"
这三句话表达的是完全相同的意图,但传统SFT会强制模型只学习其中一种表达方式。如果训练数据中只有第一种表达,模型就会被"惩罚"为没有生成"请计算"这样的特定词汇------即使它给出了正确答案。
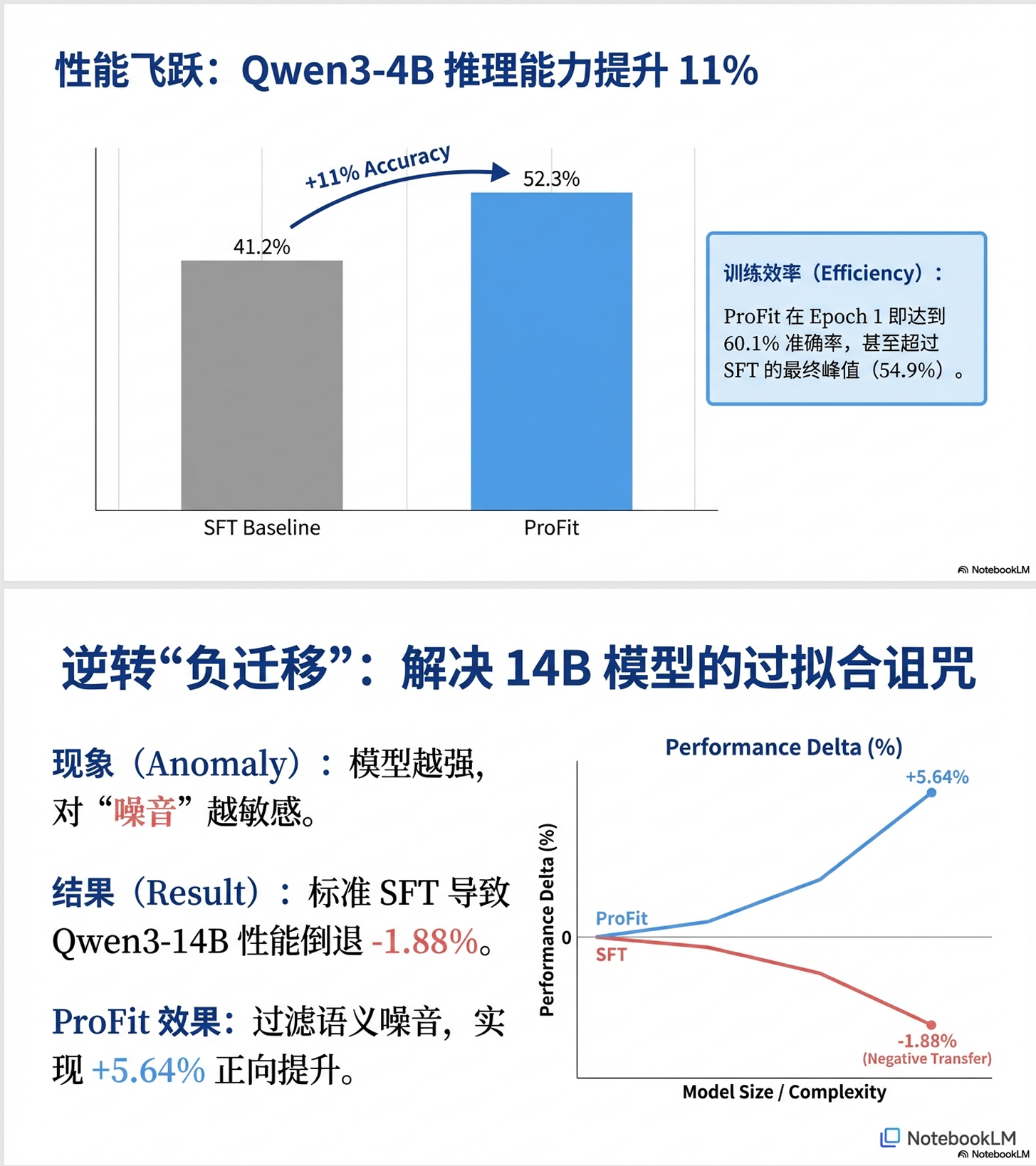
对此,来自清华和港大的研究院提出了 Profit 训练方案,让模型更高效精准地学习
论文标题:ProFit: Utilizing High-Value Signals in SFT via Probability-Guided Token Selection
论文地址 :https://arxiv.org/pdf/2601.09195
研究团队:清华大学 & 香港大学
项目地址 :https://github.com/Utaotao/ProFit


之前介绍过 Qwen 团队提出的 《Beyond the 80/20 Rule》论文
https://blog.csdn.net/qq_36671160/article/details/148423501
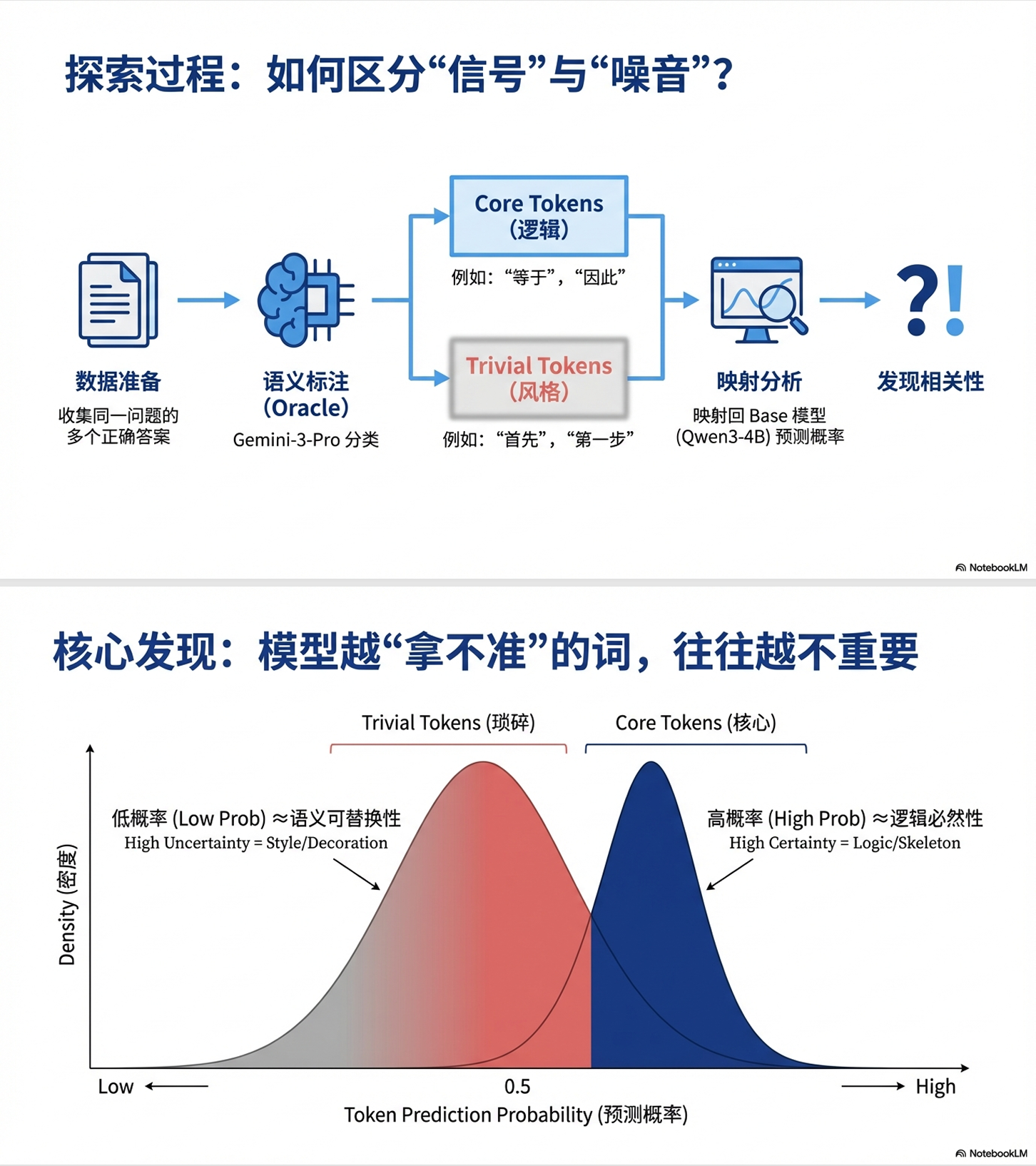
其结论是:在 RL 训练中,LLM 推理能力的提高仅由少数高熵 token 贡献
"高熵"不就意味着低概率吗?两项工作怎么一个让只学低概率 token,另一个让只学高概率 token?
实际上这两项工作并不矛盾,原因在于: