系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、预训练模型
- 二、BERT
-
- [2.1 介绍](#2.1 介绍)
- [2.2 与 RNN 、Bi-LSTM 的不同](#2.2 与 RNN 、Bi-LSTM 的不同)
- [2.3 BERT 的模型规模](#2.3 BERT 的模型规模)
- [2.4 BERT 的输入表示](#2.4 BERT 的输入表示)
- [2.3 BERT 的预训练任务](#2.3 BERT 的预训练任务)
- 总结
前言
一、预训练模型
预训练,本质上是一种大规模的自监督学习过程。
-
预训练模型有着一套 "预训练 + 微调" 的训练范式,属于迁移学习的一种实现。它能够从海量数据中学到的通用语言知识,迁移到数据量有限的特定任务中。
-
在前面的章节中探讨了
Transformer架构,它的结构是由一个编码器和一个解码器组成,而这两部分内部又分别由 N N N 个相同的层堆叠而成。 -
Transformer的提出催生了许多强大的预训练模型。有趣的是,这些后续模型往往只采用了 Transformer 架构的一部分。 -
典型的预训练模型有:
BERT:只采用编码器结构。T5: 编码器-解码器架构。GPT:只采用解码器结构。
二、BERT
- 在 ·BERT· 出现之前,像 ·Word2Vec· 这样的模型能够为词语生成一个固定的向量表示(静态词向量),但无法解决一词多义的问题。
- 例如,"破防" 在"我出了一件破防装备"和"NLP 算法给我学破防了"中的含义完全不同,但在 Word2Vec 中它们的向量是相同的。
2.1 介绍
- BERT(Bidirectional Encoder Representations from Transformers) , 在语言理解 的深层语义方面取得了突破性进展。其核心优势在于其 双向性 Bidirectional 。通过
Transformer 编码器中自注意力机制能够同时关注上下文的特性。 BERT的设计目标是生成动态的、与上下文相关的词向量。它不仅仅是一个词向量生成工具,更是一个强大的预训练语言模型。
2.2 与 RNN 、Bi-LSTM 的不同
Bi-LSTM的"双向"本质上是两个独立的单向 RNN(一个正向,一个反向)的浅层拼接。在计算过程中,正向 RNN并不知道未来的信息,反向 RNN也不知道过去的信息。BERT基于Transformer的自注意力机制,实现了真正的**"深度双向"**。
2.3 BERT 的模型规模
BERT提供了几种不同规模的预训练模型,以适应不同的计算资源和性能需求。
| 模型 | 层数 (L) | 隐藏层大小 (H) | 注意力头数 (A) | 总参数量 |
|---|---|---|---|---|
| BERT-Base | 12 | 768 | 12 | ~1.1 亿 |
| BERT-Large | 24 | 1024 | 16 | ~3.4 亿 |
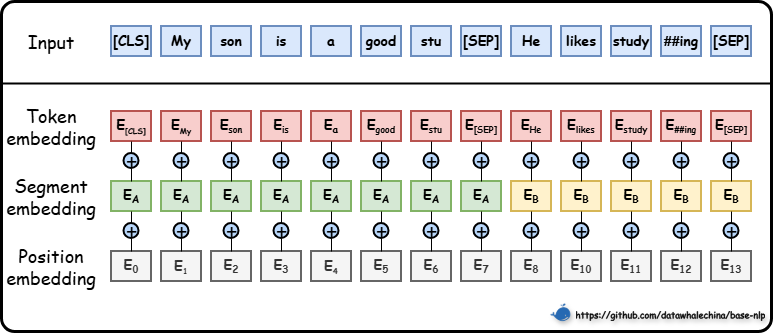
2.4 BERT 的输入表示
- 为了让模型能够处理各种复杂的输入,
BERT的输入表示由三个部分的嵌入向量逐元素相加而成:
I n p u t e m b e d d i n g = T o k e n e m b e d d i n g + P o s i t i o n e m b e d d i n g + S e g m e n t e m b e d d i n g Input_{embedding} = Token_{embedding} + Position_{embedding} + Segment_{embedding} Inputembedding=Tokenembedding+Positionembedding+Segmentembedding
2.3 BERT 的预训练任务
为了让 BERT 真正理解语言,研究人员在其训练过程中引入了两项全新的预训练任务(如图 5-3 所示),这也是它成功的关键。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。