目录
[一. 自动化工程构建-make/Makefile](#一. 自动化工程构建-make/Makefile)
[1.1 基本概念](#1.1 基本概念)
[1.2 基本使用](#1.2 基本使用)
[1.3 如何理解](#1.3 如何理解)
[1.4 推导过程及深入理解](#1.4 推导过程及深入理解)
[1)make / makefile:具体是如何形成可执行程序的呢?(推导的过程)](#1)make / makefile:具体是如何形成可执行程序的呢?(推导的过程))
[1.5 语法拓展](#1.5 语法拓展)
[二. Linux第一个系统程序-进度条](#二. Linux第一个系统程序-进度条)
[2.1 两个储备知识](#2.1 两个储备知识)
[2.1.1 回车换行](#2.1.1 回车换行)
[2.1.2 缓冲区(暂时先了解)](#2.1.2 缓冲区(暂时先了解))
[2.2 倒计时程序编写](#2.2 倒计时程序编写)
[2.3 编写进度条 --- 多文件](#2.3 编写进度条 --- 多文件)
[三. 版本控制器-Git](#三. 版本控制器-Git)
[3.1 版本控制器](#3.1 版本控制器)
[3.2 Git简史](#3.2 Git简史)
[3.3 安装git](#3.3 安装git)
[3.4 在gitee上创建项目](#3.4 在gitee上创建项目)
[3.5 git三板斧](#3.5 git三板斧)
[3.6 关于冲突的问题?](#3.6 关于冲突的问题?)
[四. 调试器-gdb/cgdb](#四. 调试器-gdb/cgdb)
[4.1 什么样的程序才能调试?](#4.1 什么样的程序才能调试?)
[4.2 调试的本质是什么?找到问题(辅助工具)](#4.2 调试的本质是什么?找到问题(辅助工具))
[4.3 cgbd调试技巧](#4.3 cgbd调试技巧)
[4.4 常见使用总结](#4.4 常见使用总结)
[4.5 三种常见的debug技巧](#4.5 三种常见的debug技巧)
一. 自动化工程构建-make/Makefile
1.1 基本概念
- 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作
- makefile带来的好处就是------"自动化编译",一旦写好,只需要一个make命令,整个工程完全 自动编译,极大的提高了软件开发的效率。
- make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile 都成为了一种在工程方面的编译方法。
- make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
1.2 基本使用
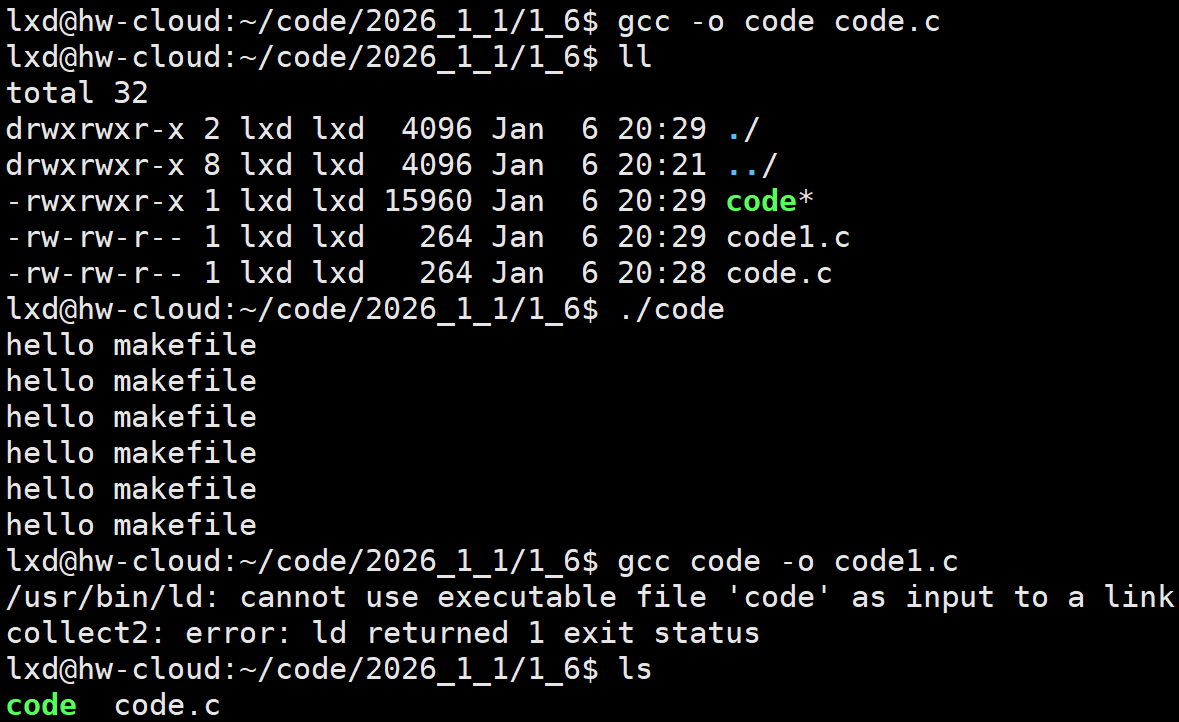
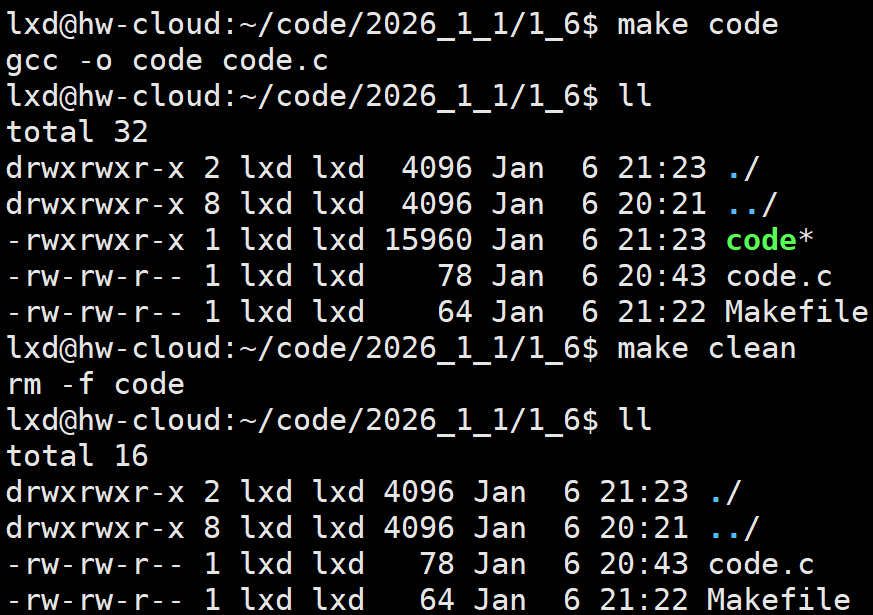
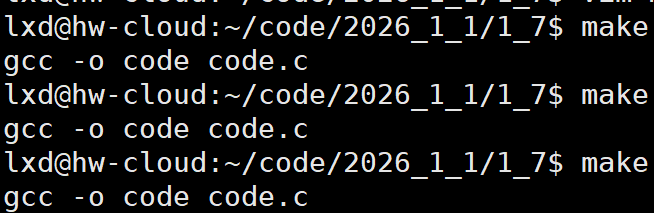
原本我们是已经写code.c,然后备份了一个code1.c,将code.c编译为可执行程序code,如果我们修改了源代码之后(不修改也一样),却在编译时,将源代码文件与要生成的可执行程序写反了,我们就会发现报错之后,我们的源文件code1.c也消失了
Makefile内部

执行make命令,就会自动扫描当前路径下的Makefile,根据刚才写的两行语法,推导出要生成code要调用的gcc命令,帮我形成.暂时理解为把gcc命令写在文件中,后面把特殊符号学了用处比较大
清理项目
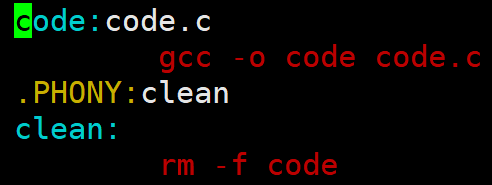
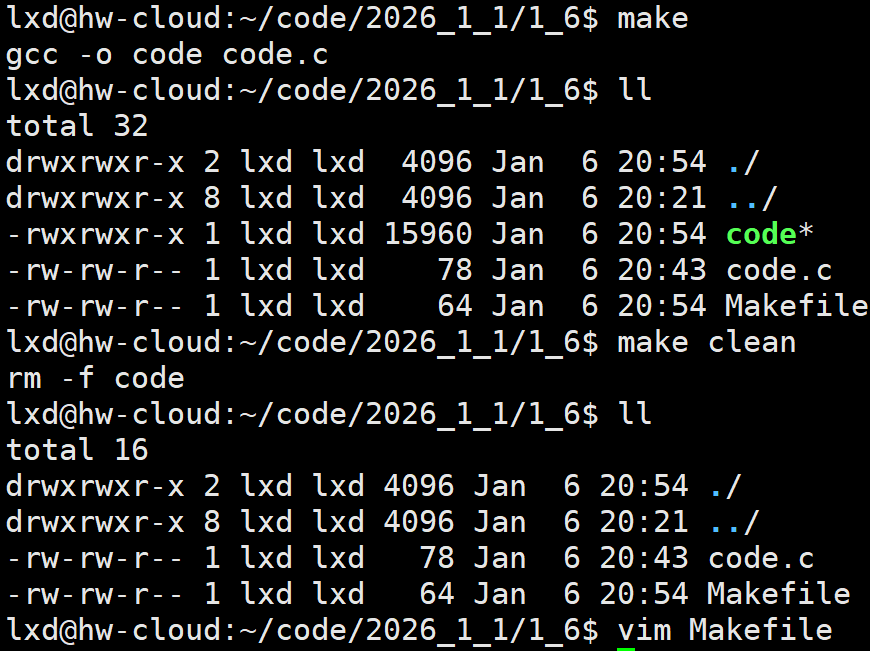
Makefile能够帮助我们(快速进行代码编译)构建工程和自动化清理工程的工具
1.3 如何理解
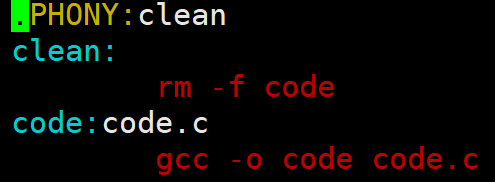
【Makefile文件内部本质是依赖关系和依赖方法的集合】
code:目标文件 code.c:依赖文件列表
第一行:依赖关系【code这个可执行程序是依赖code.c的,用code.c要形成code】
第二行:依赖方法【具体会怎么依赖的、怎么形成的,用gcc命令形成的】
第二行:依赖列表,可以为空(依赖关系为空)
即使依赖关系为空,依赖方法也要被执行
顺序颠倒一下:
写好了Makefile,命令行执行执行make时,它会从上到下扫描这个文件;默认形成的是从上向下遇到的第一个目标文件!!且执行一组依赖关系和依赖方法
有多个目标文件,要明确形成哪个目标文件:(不指明,默认形成第一个)
默认我们把形成可执行程序的这个动作放在最前面
make 目标文件 (如果make一个不存在的文件就会报错)
综上:上面讲解了依赖关系/依赖方法、目标文件/依赖文件列表、Makefile的默认行为
1.4 推导过程及深入理解
1)make / makefile:具体是如何形成可执行程序的呢?(推导的过程)
makefile:脚本语言,不需要编译,写好之后自动就能运行(Makefile本质是一个文件)。
当我们执行make时,make命令会在当前目录下查看一个文件M/makefile,make命令会将makefile从上到下依次解析。
**make是如何工作的?**在默认的方式下,也就是我们只输入make命令。那么:
- make会在当前目录下找名字叫"Makefile"或"makefile"的文件。
- 如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到code这个文件,并把这个文件作为最终的目标文件。
- 如果 code 文件不存在,或是 myproc 所依赖的后面的 code.o 文件的文件修改时间要 比 code 这个文件新(可以用 touch 测试),那么,他就会执行后面所定义的命令来生成 code 这个文件。
- 如果 code 所依赖的 code.o 文件不存在,那么 make 会在当前文件中找目标为 code.o 文件的依赖性,如果找到则再根据那一个规则生成 code.o 文件。(这有点像一 个堆栈的过程)
- 当然,你的C文件和H文件是存在的啦,于是 make 会生成 code.o 文件,然后再用 code.o 文件实现 make 的终极任务,也就是执行文件 code 了。
- 这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
- 在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。
- make只管文件的依赖性,即:如果在我找了依赖关系之后,冒号后面的文件还是不在,那么对不起,我就不工作啦。
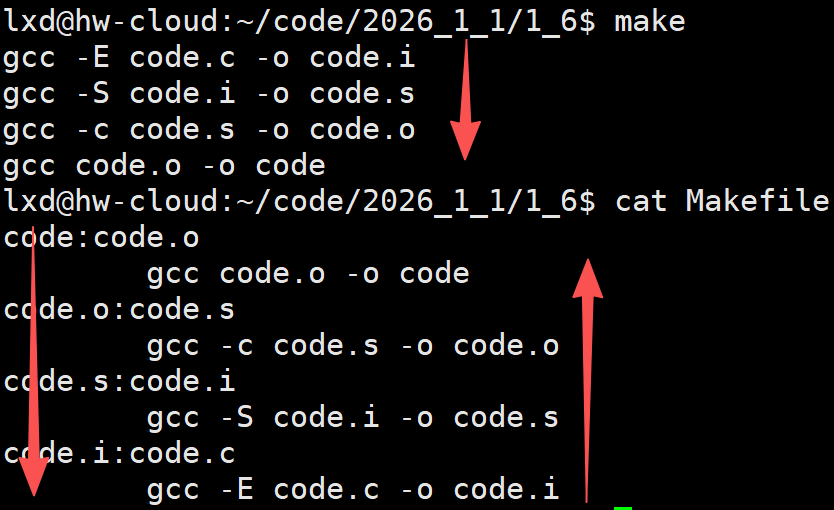
依赖关系写的时候是从上往下写的,但是推导的时候,会自动的推导回来
make命令内部,维护一个栈结构!! 执行make时发现code.o不存在,就不会形成code,这条命令就不能执行,那么这条命令就会入栈;直到有出口,就会依次出栈
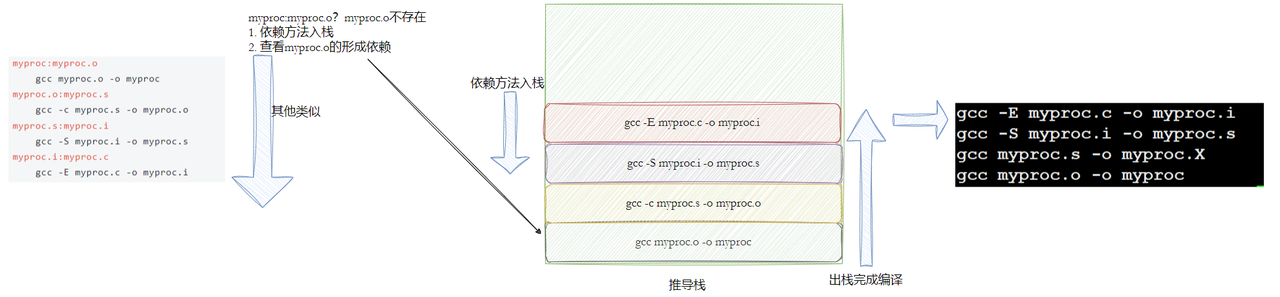
当前目录下code.o不存在,首先make(本质也是用C语言写的)会将依赖方法push入栈,然后去找code.o,code.o依赖code.s,但是当前面目录下也不存在code.s,所以会将依赖方法push入栈,再去找code.s,找到code.s,发现他依赖code.i,但是目录中也不存在code.i,所以依旧会将依赖方法push入栈,然后去找code.i;找到code.i对应的依赖关系,发现他依赖code.c,code.c已经存在,它所对应的依赖方法也会入栈;语法推导就已经完成了,然后做命令执行,依次弹栈,执行命令。就将临时文件和目标可执行程序全部都生成了
以上过程称为Makefie的语法推导过程【最核心的一点是: 它会利用一个栈结构,对当前依赖关系中依赖文件列表不存在时,将当前依赖方法入栈,直到推导到出口,再将所有入栈的方法依次弹栈执行,就可以完成语法推导】(makefile默认形成第一个自己遇到的目标文件)
(**注:**这里分步骤写编译过程为了体现推导过程,真实编译时不会这么干)
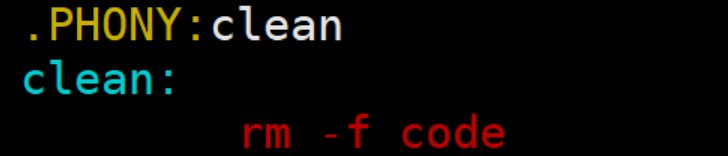
2)清理工程(研究清理的过程)【主要是.PHONY的作用】
- 像clean这种,没有被第一个目标文件直接或间接关联,那么它后面所定义的命令将不会被自动执行,不过,我们可以显示要make执行。即命令------"make clean",以此来清除所有的目标文件,以便重编译。
- 但是一般我们这种clean的目标文件,我们将它设置为伪目标,用 .PHONY 修饰,伪目标的特性 是,总是被执行的。

makefle中依赖文件列表,可以为空!依赖方法可以是任何Linux命令
Q:.PHONY 是什么?
A:相当于Makefile的修饰词,形容我们后续跟的clean是一个伪目标,告诉make它是一个伪目标;伪目标也是目标,也要有依赖关系和依赖列表。
伪目标表达的含义:修饰的目标文件,它对应的依赖方法,总是被执行
Q:什么是不总被执行?
A:make执行一次依赖方法后就不让你再次执行了。
code不被.PHONY修饰时:第一次编译成功后,后面就不让你在编译了
会显示code已经是最新的了

被.PHOMY修饰时,总是被执行的,即每一次都会执行

最佳实践: clean用.PHONY,形成工程目标可执行,不建议用.PHONY修饰;为什么?
gcc编译代码的时候,代码如果没有被编译过,或者曾经被修改过,make+gcc才会进行更新编译!(这时的编译称为有效编译 )提高编译效率
整个编译的过程只会对被修改够的代码进行编译,如果没有被修改过,那么就不会对它进行编译
如果项目当中有100个源文件,我们修改了其中的5-6个,如果每次比编译都要将这些所有的源文件进行编译,那么效率就会非常低,因此,我们只需将这几个修改过的源代码进行编译就可以与其他老的.o文件链接,形成可执行程序就可以了,不需要我们将所有的源文件重新编译,没有被修改的源文件就不需要再被编译了,这就提高了编译效率。所以在形成可执行程序时,不建议用.PHONY修饰code,就是要让gcc形成程序时维持不总被执行的特性,它只会编译新文件
因为我们已经用code.c编译形成code了,我们没有修改它,所以它已经是最新的,不需要再编译了;除非你将code.c修改了,修改之后系统识别到code.c是一个新文件了,再次make,才会将它编译
用.PHONY修饰对应的目标文件时,它代表的就是不要管新旧,直接调用方法;加上.PHONY,就必须得关心code.c是新的还是旧的,如果没有被修改过,就不需要再编译了
.PHONY本质是什么? 让make忽略源文件和可执行目标文件的M时间对比
Q:make如何知道code.c是否需要被重新编译?
A:只要code.c的Modify时间比可执行程序文件新。说明code.c最近被修改过,这时就会重新编译。
永远都是先有源文件.c,才有可执行文件。所以code.c所对应的Modify时间一定比code的Modify时间晚。因为源文件比编译后的文件还要老,没必要再用code.c形成code了。如果你修改了code.c,那么code的时间就会变得比code老了,gcc发现了这一点,这时再去make就能够编译了
不想修改文件就可以让它重新编译,可以直接touch刷新时间,这样就又能编译了
每个文件都有他自己的三个时间: stat code.c
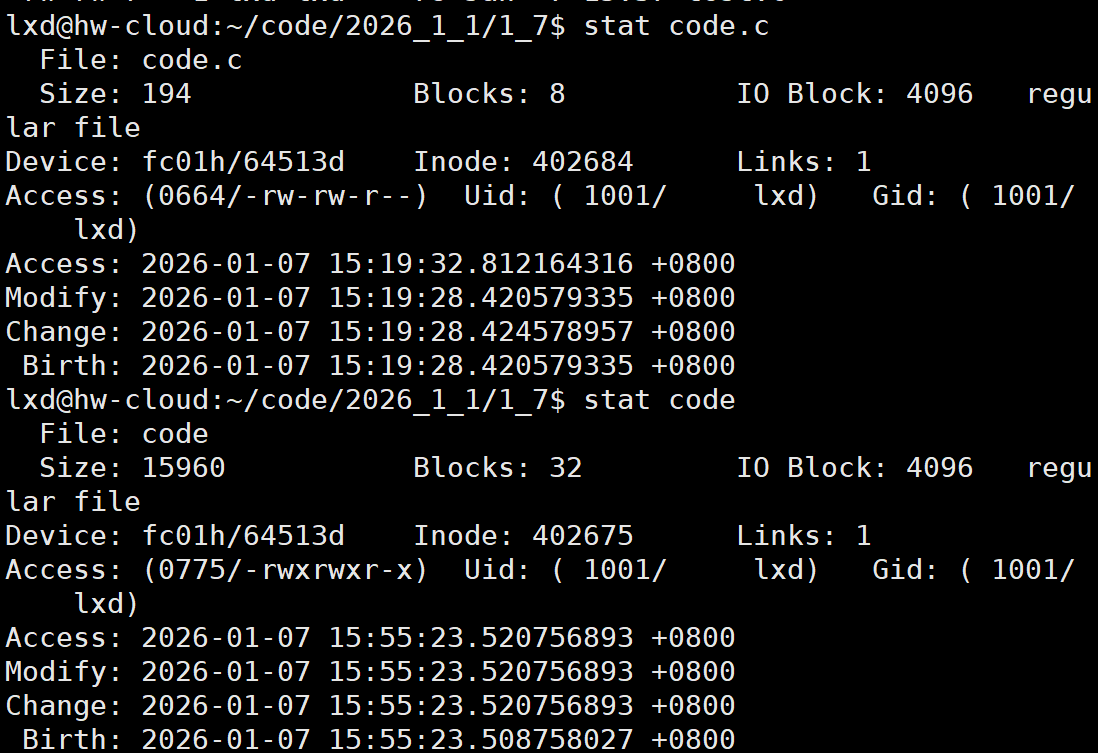
称为ACM时间:
- Access:最近被访问的时间(注:并不是访问一次就修改一次时间)
- Modify:最近被修改(或被创建)的时间
- Chang:最近被改变的时间
修改 VS 改变
对文件的内容 做修改,称为Modify(修改)
对文件的属性作修改称为Change(改变)(chmod)
【文件的内容改了,属性自然也就变了】所以更改文件内容时,一般C和M同时都会变化
读取文件的内容是一个高频的动作,如果查看一次就修改Access时间,会给系统带来很大的IO负担。所以一般一个文件被查看了好几次,才会更新它的Access时间。
**综上:**Access时间不是实时更新的,而是按一定的策略更新的,和系统有关
touch命令还有一个作用:更新ACM时间,一次全部都更新了
你的源文件有没有被修改 --- 指标 --- 文件的Modify时间!
(注:Makefile用 # 注释,vim用双引号注释)
3)Makefile的最佳实践和使用语法
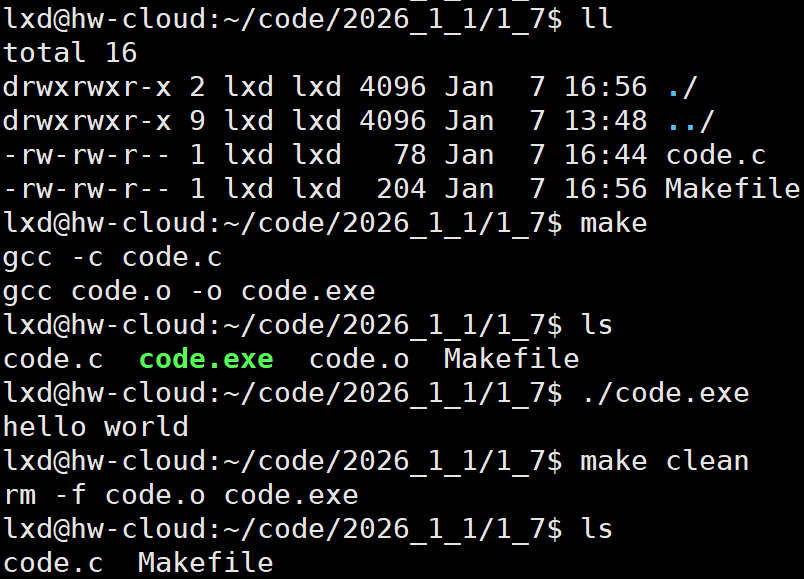
**最佳实践:**把所有的源文件编译成.o文件,然后链接形成可执行程序
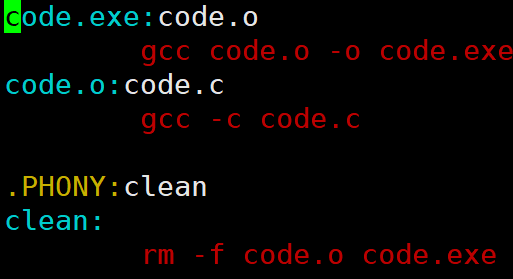
gcc -c 默认形成同名 .o文件
1.5 语法拓展
- $@:表示上面依赖关系的目标文件(冒号左侧)
- $^:表示上面依赖关系中的所有依赖文件列表(冒号右侧的所有内容)
- $<:将依赖文件列表依次拿下来执行依赖方法
Makefile中可以定义变量 (等号左右两边不建议带空格)【类似C/C++中的宏】Makefile的主体内容全部符号化,就可以只改变变量就可以达到控制形成目标文件,改变依赖文件列表的过程
$(Bin),make在扫描时就会将Bin替换为code.exe
依赖方法可以有多个
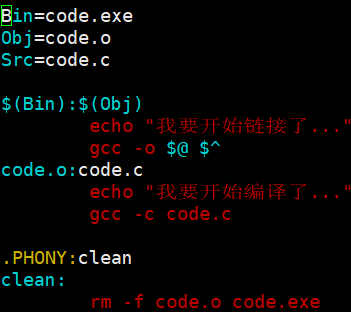
makefile执行任何命令,默认会把命令显示出来
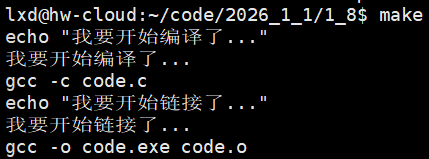
不要显示echo命令,直接把字符串打印出来
禁止对执行的指令进行回显,前面加上@
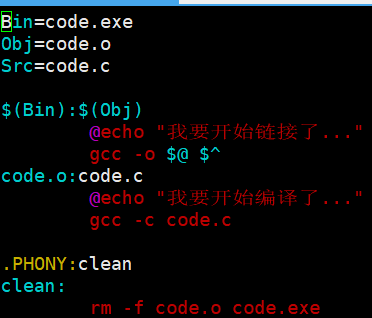
在执行命令前带@,不要把命令执行的过程回显出来,方便我们后续对makefile的输出进行定制化输出
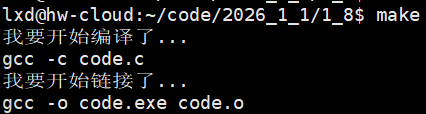
怎么定制化输出呢?
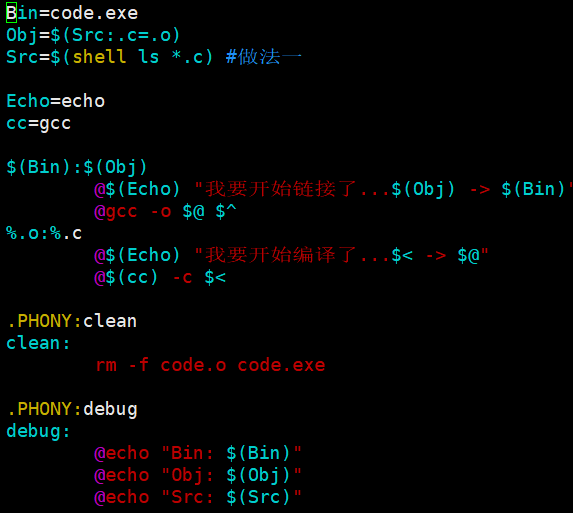
%^代表所有的code.o
%.o : %.c :把当前目录下的所有源文件依次展开(类似通配符*),依次形成同名的.o
\<代表一个一个的源文件,@代表一个一个的目标文件
动态获取所有的源文件:$(shell ls *.c) #做法一
把所有的.c变为.o:$(Src: .c=.o)
完整实现
wildcard是一个函数,自动获取当前目录下所有的.c文件
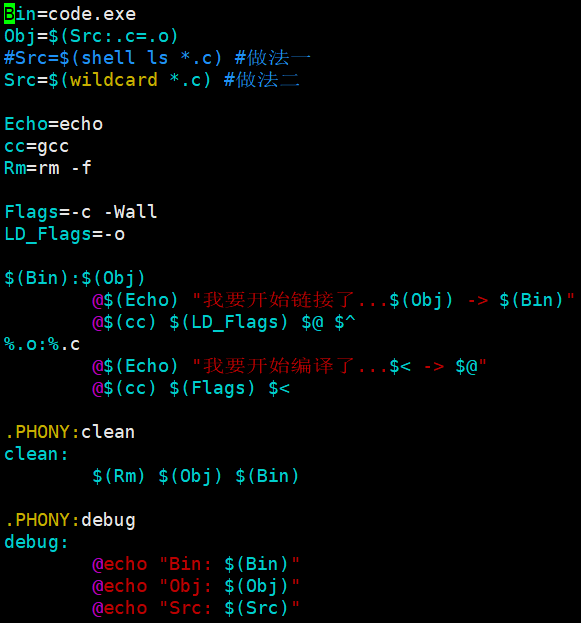
bash
BIN=proc.exe # 定义变量
CC=gcc
# SRC=$(shell ls *.c) # 采用shell命令行方式,获取当前所有.c文件名
SRC=$(wildcard *.c) # 或者使用 wildcard 函数,获取当前所有.c文件名
OBJ=$(SRC:.c=.o) # 将SRC的所有同名.c 替换 成为.o 形成目标文件列表
LFLAGS=-o # 链接选项
FLAGS=-c # 编译选项
RM=rm -f # 引入命令
$(BIN):$(OBJ)
@$(CC) $(LFLAGS) $@ $^ # $@:代表目标文件名。 $^: 代表依赖文件列表
@echo "linking ... $^ to $@"
%.o:%.c # %.c 展开当前目录下所有的.c。 %.o: 同时展开同名.o
@$(CC) $(FLAGS) $< # %<: 对展开的依赖.c文件,一个一个的交给gcc。
@echo "compling ... $< to $@" # @:不回显命令
.PHONY:clean
clean:
$(RM) $(OBJ) $(BIN) # $(RM): 替换,用变量内容替换它
.PHONY:test
test:
@echo $(SRC)
@echo $(OBJ)二. Linux第一个系统程序-进度条
整合之前学过的工具
2.1 两个储备知识
2.1.1 回车换行
Q:回车换行时一回事吗?
A:不是
**回车(\r):**回到当前行的开始
**换行(\r\n等同于C/C++中的\\n):**新起一行
(\n;std::endl)C/C++中回车换行
2.1.2 缓冲区(暂时先了解)
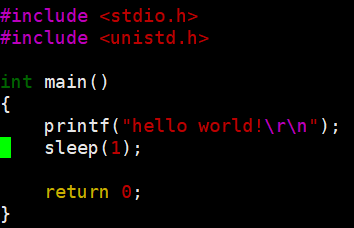
这种是正常情况,先休眠,再打印
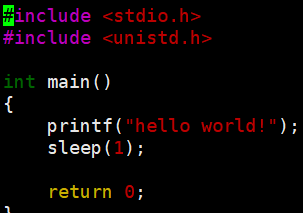
去掉回车换行后,我们观察到先sleep休眠之后,再打印出字符串,但是实际是先执行printf,再执行sleep;因为c语言在执行代码时时从上到下执行的
在sleep期间,printf一定执行完了!只是数据没有被显示出来,在sleep期间hello world字符串在哪里?? 字符串被缓存起来了!没有写到显示器文件上。程序结束时,缓存回自动刷新。
\r\n || \n :回车换行 --> 立即刷新到显示器
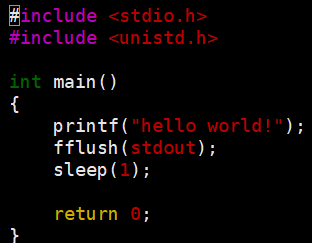
使用fflush(stdout)强制刷新,将字符串从缓冲区刷新到标准输出(stdout)显示器上,这时我们就会发现是先打印出字符串,然后再sleep
2.2 倒计时程序编写
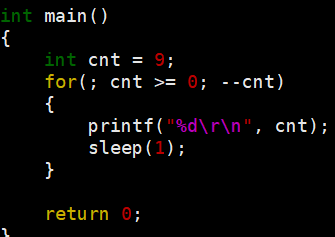
只有\r,不会刷新,只有\n || \r\n才会刷新
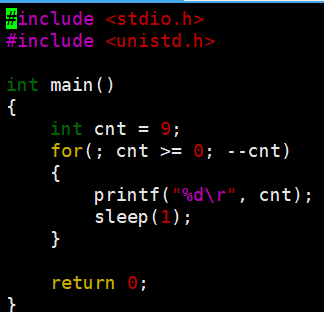
强制刷新
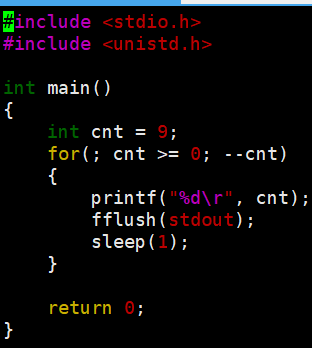
倒计时结束了刷新一下,看到结果

10本质上是两个字符:'1'和'0'
一个数字10是怎么变成两个字符:'1'和'0'的,这是谁做的? printf做的【格式化输出:把10一个4字节整数格式化为两个字符,底层调用的是putc函数,将对应的字符打印到显示器上】
scanf【格式化输入】,在键盘上输10的时候,输的是1字符和0字符,scanf识别到我回车了,它把回车前的字符按整数转成了4字节
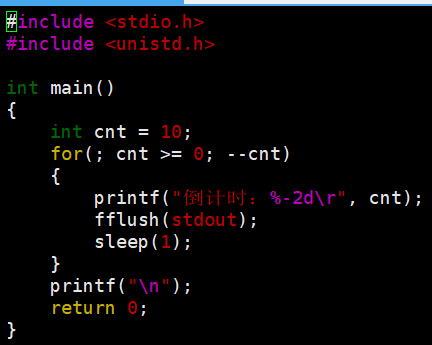
%d :%d后面加一个空格,覆盖掉0(不太好)
**%2d:**输出时一次输出两个字符,有字符就输出,没有字符就用空格作为占位符占住;只有一个字符默认右对齐,把有效数据写在右侧
**"%-2d":**左对齐
2.3 编写进度条 --- 多文件
Makefile
bash
1 Bin=process_bar
2 Cc=gcc
3 Src=$(wildcard *.c)
4 Obj=$(Src:.c=.o)
5
6 $(Bin):$(Obj)
7 @echo "$^ link to $@"
8 @$(Cc) -o $@ $^
9 %.o:%.c
10 @echo "compling $< to $@"
11 @$(Cc) -c $<
12
13 .PHONY:clean
14 clean:
15 @echo "Clean Project ... Done"
16 @rm -f $(Obj) $(Bin)
17
18 .PHONY:Print
19 Print:
20 @echo $(Bin)
21 @echo $(Cc)
22 @echo $(Src)
23 @echo $(Obj)process.h
bash
1 #pragma once
2 #include <stdio.h>
3
4 typedef void (*flush_t)(double total, double current, double speed, const char* userinfo);
5 void Process(double total, double current, double speed, const char* userinfo);process.c
bash
7
8 // Version2版本
9 void Process(double total, double current, double speed, const char* userinfo)
10 {
11 if(current > total)
12 return;
13 // 旋转光标和下载本身有关吗?它只和Process函数是否被调用有关
14 // 为什么定义为static?生命周期变为全局,第一次调用初始化,之后即使函数释放了,他还会被保存起来,下次还能继续用
15 static const char *lable="|/-\\";
16 int size = strlen(lable);
17 static int index = 0;
18 // 绝对不能一次循环就把整个进度走完
19
20 // 1. 计算比率
21 double rate = current * 100.0 / total;
22 char out_bar[SIZE];
23 memset(out_bar, '\0', sizeof(out_bar));
24 // 2. 填充进度字符
25 int i = 0;
26 for(; i < (int)rate; i++)
27 {
28 out_bar[i] = LABLE;
29 }
30 // 3. 刷新进度条(\反斜杠续行)
31 printf("[%-100s][%-5.1lf%%][%c] | %.1lf/%.1lf, speed: %.1lf%s\r",out_bar, rate, lable[index], total, current, speed, userinfo);
32 fflush(stdout);
33 index++;
34 index %= size;
35
36 // 4. 进度条完成,换行
37 if(current >= total)
38 printf("\r\n");
39 }
40
41
42 // 进度条的version1版本
43 // 加一个旋转的光标,告诉用户这个程序没死,可能是网速或其他与原因导致下载或加载比较慢,百分比不更新
44 void ProcessVersion1()
45 {
46 const char *lable = "|/-\\";
47 int len = strlen(lable);
48 int cnt = 0;
49 char out_bar[SIZE];
50 memset(out_bar, '\0', sizeof(out_bar));
51 while(cnt <= 100)
52 {
53 // 这里要打印出%,可以用转移符号\,但是更推荐%%
54 printf("[%-100s][%-3d%%][%c]\r", out_bar, cnt, lable[cnt%len]); // %100s在输出的时候后就将100个空间腾出来,-左对齐;%3d,预留出3个字符的空间,这样中括号的位置就比较稳定了,不会动,-左对齐
55 fflush(stdout); // 让我们输出的信息立即刷新
56 out_bar[cnt] = LABLE;
57 cnt++;
58
59 usleep(100000);
60 }
61 printf("\n");
62 }
63
64 // version1另一种显示形式
65 //void Process()
66 //{
67 // const char *lable[] = {
68 // "load.",
69 // "load..",
70 // "load...",
71 // };
72 // int size = sizeof(lable) / sizeof(lable[0]);
73 // int cnt = 0;
74 // char out_bar[SIZE];
75 // memset(out_bar, '\0', sizeof(out_bar));
76 // while(cnt <= 100)
77 // {
78 // // 这里要打印出%,可以用转移符号\,但是更推荐%%
79 // printf("[%-100s][%-3d%%][%-7s]\r", out_bar, cnt, lable[cnt%size]); // %100s在输出的时候后就将100个空间腾出来,-左对齐;%3d,预留出3个字符的空间,这样中括号的位置就比较稳定了,不会动,-左对齐;%7s,预留7个字符的空间
80 // fflush(stdout); // 让我们输出的信息立即刷新
81 // out_bar[cnt] = LABLE;
82 // cnt++;
83 //
84 // usleep(500000);
85 // }
86 // printf("\n");
87 //}main.c
bash
1 #include "process.h"
2 #include <unistd.h>
3 #include <stdlib.h>
4 #include <time.h>
5
6 // 有一个下载任务
7 double gtotal = 1024.0; // 目标文件的大小
8 double gspeed = 1.0; // 网络速度
9
10 // 回调函数
11 void DownLoad(double total, flush_t cb)
12 {
13 double level[] = {1.0, 0.5, 1.5, 2.5, 5.5, 10};
14 int num = sizeof(level)/sizeof(level[0]);
15
16 double current = 0.0; // 当前下载了多少
17 while(1)
18 {
19 usleep(50000); // 模拟下载
20 double speed = level[rand()%num];
21 current += speed;
22 if(current >= total)
23 {
24 current = total;
25 cb(total, current, speed, "Mb/s"); // 更新进度条
26 break;
27 }
28 else
29 {
30 cb(total, current, speed, "Mb/s"); // 更新进度条
31 }
32 }
33 printf("\n");
34 }
35
36 int main()
37 {
38 // version1
39 //Process(); // 进度条程序
40 //return 0;
41
42 srand(time(NULL));
43 printf("DownLoad:\n");
44 DownLoad(gtotal, Process);
45 printf("DownLoad:\n");
46 DownLoad(102.9, Process);
47 printf("DownLoad:\n");
48 DownLoad(90.8, Process);
49 printf("DownLoad:\n");
50 DownLoad(88.8, Process);
51 printf("DownLoad:\n");
52 DownLoad(66.6, Process);
53
54 return 0;
55 }细节1:如果函数名改了,我们还要改一下main.c中的函数名
用回调函数
细节2:printf输出是时颜色
三. 版本控制器-Git
不知道你工作或学习时,有没有遇到这样的情况:我们在编写各种文档时,为了防止文档丢失,更改失误,失误后能恢复到原来的版本,不得不复制出一个副本,比如:
"报告-v1"
"报告-v2"
"报告-v3"
"报告-确定版"
"报告-最终版"
"报告-究极进化版" ...
每个版本有各自的内容,但最终会只有一份报告需要被我们使用 。 但在此之前的工作都需要这些不同版本的报告,于是每次都是复制粘贴副本,产出的文件就越来越 多,文件多不是问题,问题是:随着版本数量的不断增多,你还记得这些版本各自都是修改了什么 吗? 文档如此,我们写的项目代码,也是存在这个问题的!!
3.1 版本控制器
为了能够更方便我们管理这些不同版本的文件,便有了版本控制器。所谓的版本控制器,就是能让你 了解到一个文件的历史,以及它的发展过程的系统。通俗的讲就是一个可以记录工程的每一次改动和 版本迭代的一个管理系统,同时也方便多人协同作业。
目前最主流的版本控制器就是 Git【global information tracker"(全局信息跟踪器)】 。Git 可以控制电脑上所有格式的文件,例如 doc、excel、dwg、 dgn、rvt等等。对于我们开发人员来说,Git 最重要的就是可以帮助我们管理软件开发项目中的源代码文件!
1. git的历史
只会对修改进行备份说明
为每个人创建的文件夹是仓库
版本管理、网络通信
git是一个CS(客户端/服务端)一体的,去中心化的,分布式的版本控制器
2. 理解git的版本控制? git? github&&Gitee?
git:具有版本控制功能,具有网络同步功能
git -> 小乌龟 (客户端图形化界面)
基于git的 github 和 gitee (本地仓库和远端仓库同步的网站)
3.2 Git简史
同生活中的许多伟大事物一样,Git 诞生于一个极富纷争大举创新的年代。
Linux 内核开源项目有着为数众多的参与者。 绝大多数的 Linux 内核维护工作都花在了提交补丁和保存归档的繁琐事务上(1991-2002年间)。 到 2002 年,整个项目组开始启用一个专有的分布式版本 控制系统 BitKeeper 来管理和维护代码。
到了 2005 年,开发 BitKeeper 的商业公司同 Linux 内核开源社区的合作关系结束,他们收回了 Linux 内核社区免费使用 BitKeeper 的权力。 这就迫使 Linux 开源社区(特别是 Linux 的缔造者 Linus Torvalds)基于使用 BitKeeper 时的经验教训,开发出自己的版本系统。 他们对新的系统制订了若干目标:
- 速度
- 简单的设计
- 对非线性开发模式的强力支持(允许成千上万个并行开发的分支)
- 完全分布式
- 有能力高效管理类似 Linux 内核一样的超大规模项目(速度和数据量)
自诞生于 2005 年以来,Git 日臻成熟完善,在高度易用的同时,仍然保留着初期设定的目标。 它的速度飞快,极其适合管理大项目,有着令人难以置信的非线性分支管理系统。
3.3 安装git
bash
sudo yum/apt install -y git3.4 在gitee上创建项目
1)注册账号(不再多说)
2)创建仓库
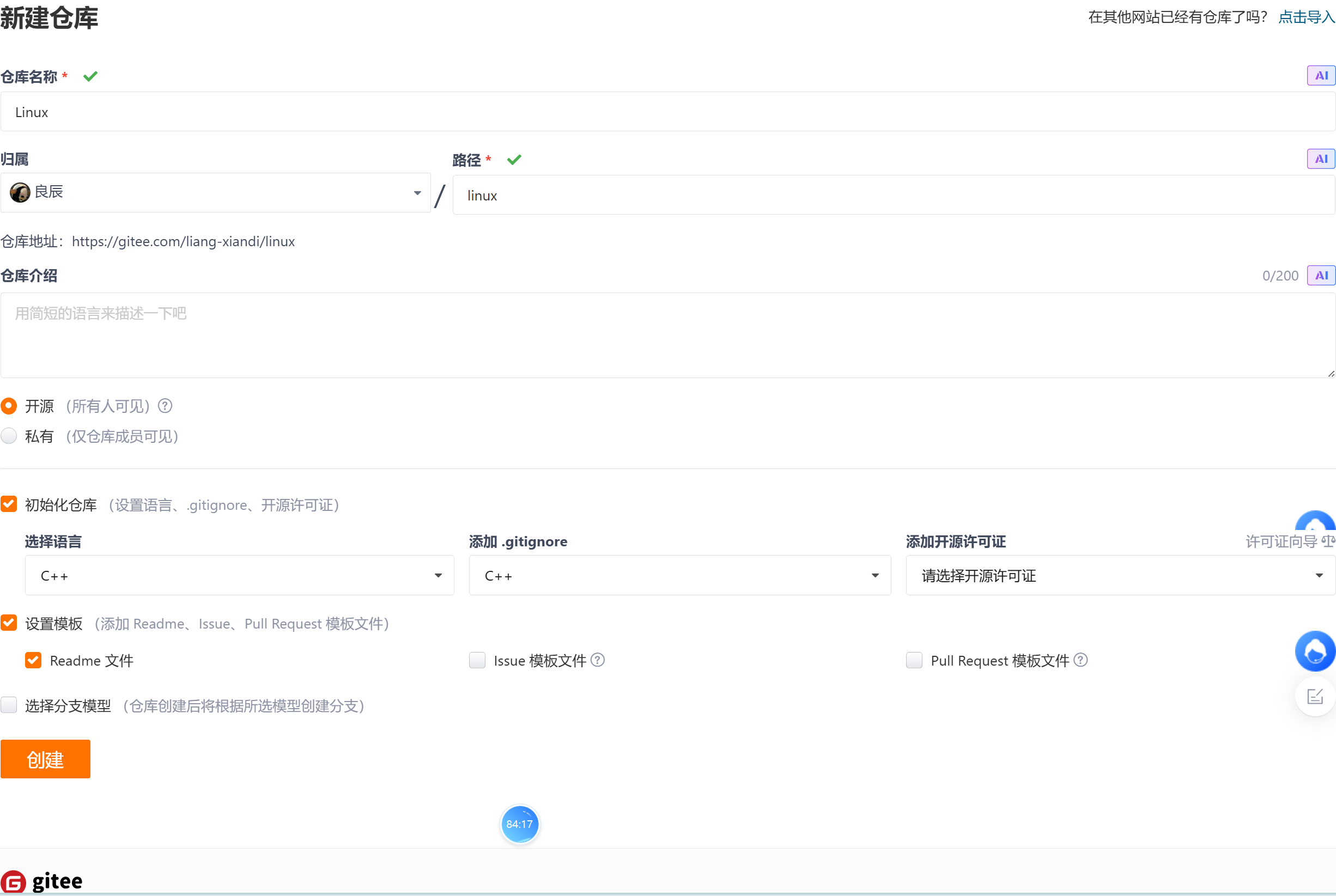
把远端仓库拉取到本地,那远端的链接克隆下来
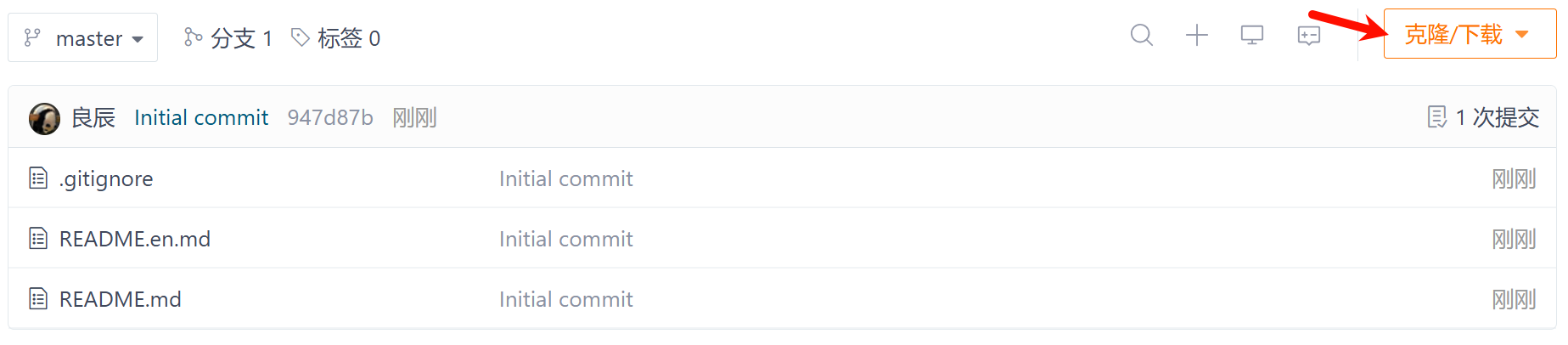
推荐选择https操作比较简便
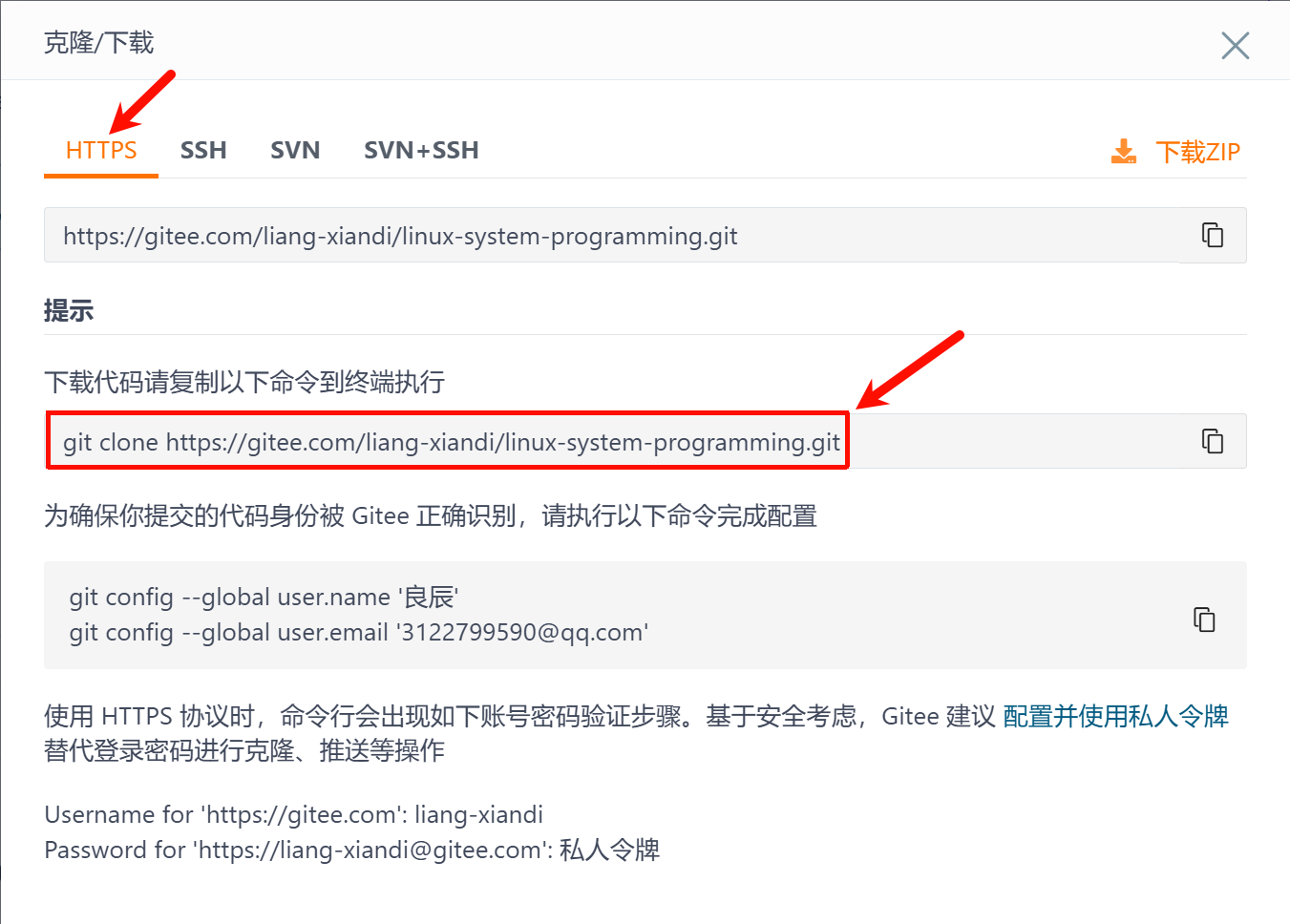
克隆到本地(仓库就是一个目录)

要在命令行中执行这两句代码,配置用户名和邮箱,这样提交代码时就不会报错了
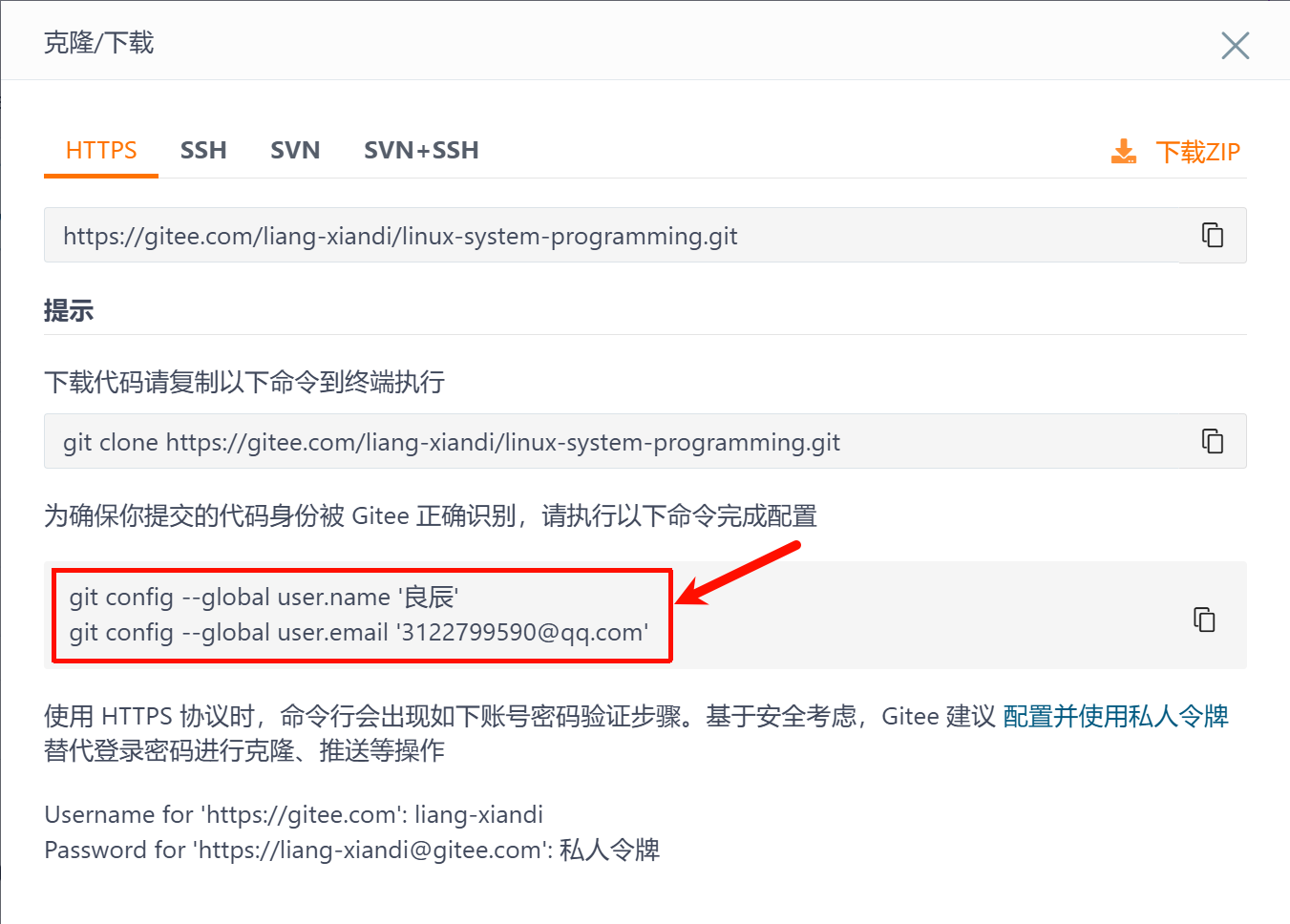

如果不执行会出现问题:提交代码时会说,你的gitee没有配置用户名和邮箱,请先配置这两个才能使用git

所有修改记录都在.git目录下
狭义上讲,.git才是真正意义上的仓库
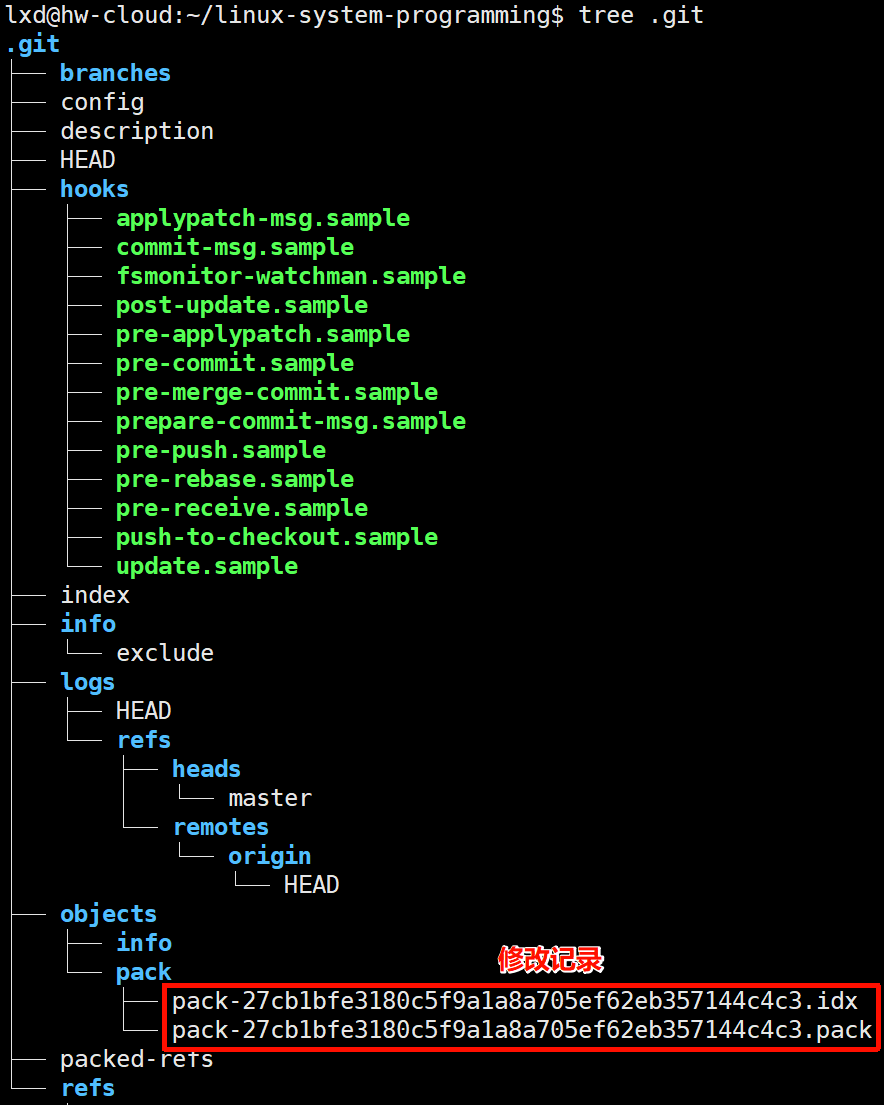
提交代码之后,多了修改记录
修改其中的一个文件
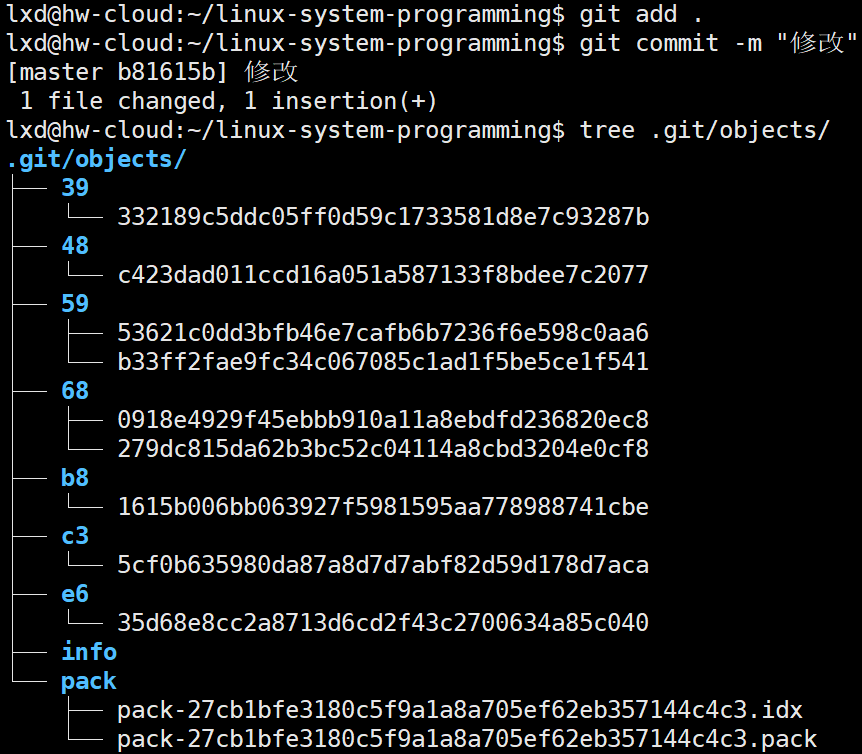
这里显示当前目录是干净的,告诉为我们已经对本地的软件作对应的管理了
**git status:**产看当前状态
push到对应的远端
3) 删除仓库
3.5 git三板斧
1. git add .
把源文件修改信息添加到本地仓库中的暂存区
2. git commit -m "XXX" 【-m选项必须带,不带会报错】双引号中的内容成为提交日志
把源文件修改信息提交到本地仓库中(确认提交,再将它从暂存区提交到版本链中)会被永久记录下来
3. git push
前两个操作已经将修改提交到本地仓库了,git push本地和远端仓库同步(重点是将.git中的内容同步到对方的.git中)
需要填入用户名密码. 同步成功后, 刷新 gitee 页面就能看到代码改动了
写的代码不能直接弄到本地仓库,有一个临时区域

将修改记录提交到暂存区,叫做git add .
为什么要有暂存区?因为我有可能会后悔,如果后悔了,可以在这里这里撤销掉,更多的是一个容错处理
git log: 拉取提交信息**(逆序的)所有提交记录**

Q:.gitignore是什么?
A:过滤掉特定后缀的文件,让对应的临时文件不会被git管理
4. 其他相关命令
git log/status/pull
3.6 关于冲突的问题?
Windows克隆仓库
问题1:两个人在同一个仓库新建文件
pull:把远端仓库同步到本地
如果远端和本地仓库不一致,需要先pull一下,远端同步到本地,然后再push推送到远端
保证远端仓库给任何人用,都用最新的
如果push是冲突了,就说明你的本地仓库已经不是最新的了!
强制代码同步!!
问题2:两个人修改了同一份代码也会产生冲突
当你修改代码时候,push的时候会报错,它会自动将两份代码合并,需要两个程序员商量如如何解决
比较好的办法:一人一个目录
四. 调试器-gdb/cgdb
4.1 什么样的程序才能调试?
- 程序的发布方式有两种, debug 模式和 release 模式, Linux gcc/g++ 出来的二进制程序,默认是 release 模式。
- 要使用gdb调试,必须在源代码生成二进制程序的时候, 加上 -g 选项,如果没有添加,程序无法被 编译
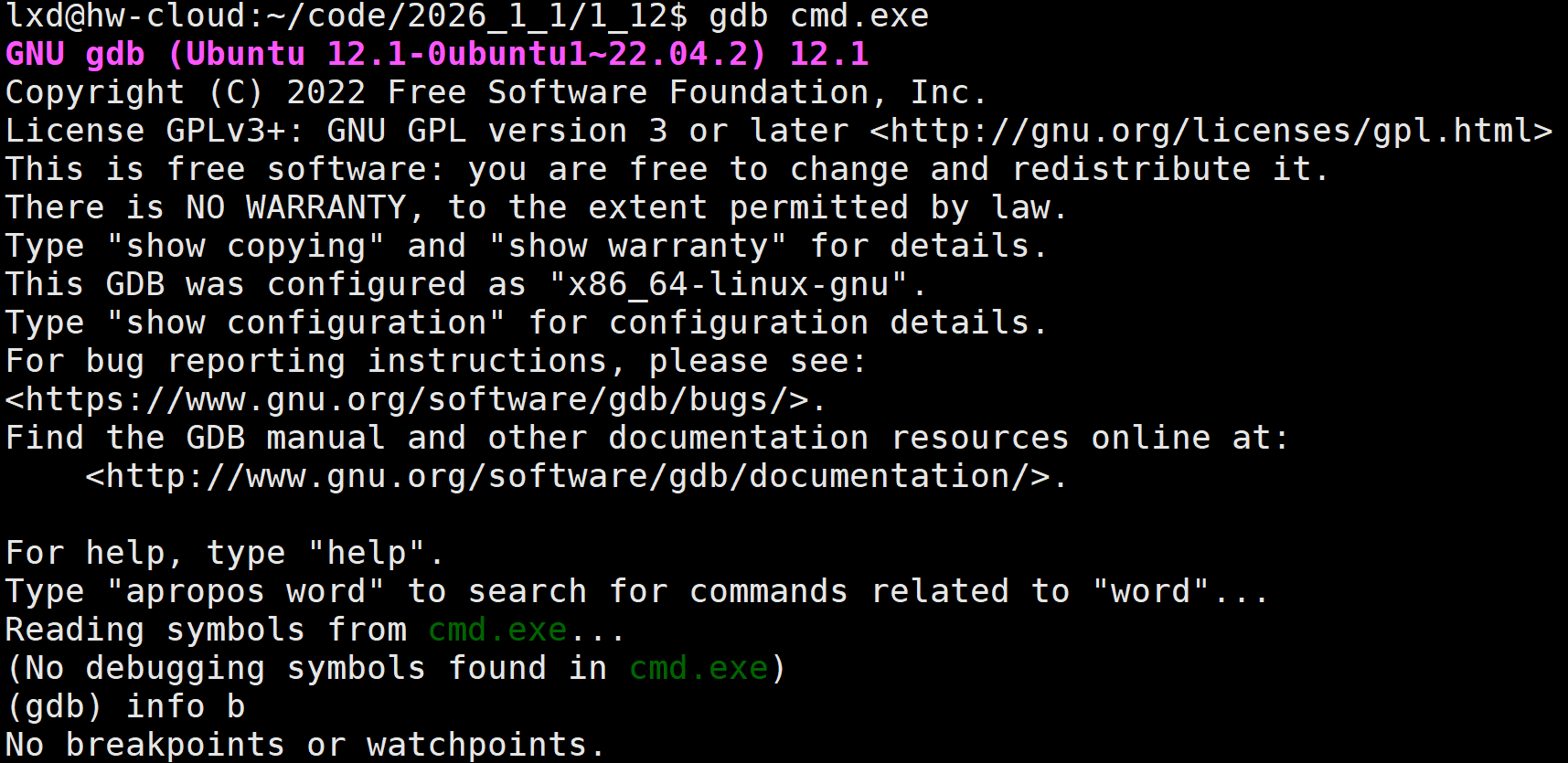
默认形成的可执行程序没有调试信息
gcc、g++编译程序,默认都是以release方式发布的
如何改为debug版本? 加上-g选项
程序的发布方式:
-
debug方式(开发阶段自测)
-
release方式(提交给测试者去测,普通人用)
release版本程序的体积比debug版本小,-g:给形成的可执行程序内部添加调试信息!!
readelf -S:读取二进制可执行程序的格式

有调试时信息才能调试,所以要用gdb调试,编译时要加-g选项
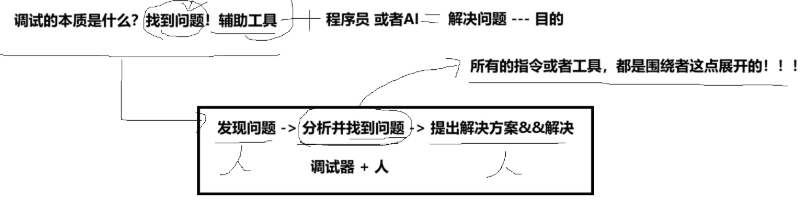
4.2 调试的本质是什么?找到问题(辅助工具)
目的 --- 解决问题
4.3 cgbd调试技巧
断点可以让我们的程序停下来
Q:断点的本质?
A:区域化的执行代码!进而找到问题:查找问题,二分查找确定问题的范围(找到问题的工具)
断点是可以被"使能"(enable or disable的)【对已经存在的断点打开和关闭(这个断点生效还是不生效)】
在debug时保留调试痕迹,除非百分百确认这个问题解决了再将所有的断点删掉,这样即使问题复现了,我们还可以调试
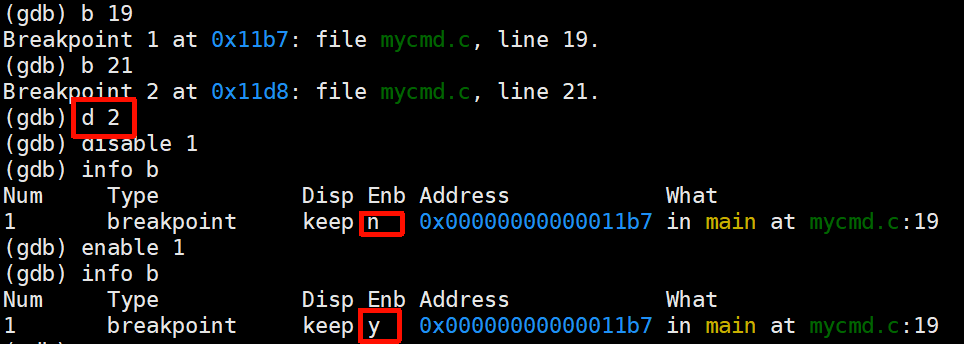
小结论:在一个调试周期中,断点的编号是一个线性递增的数字
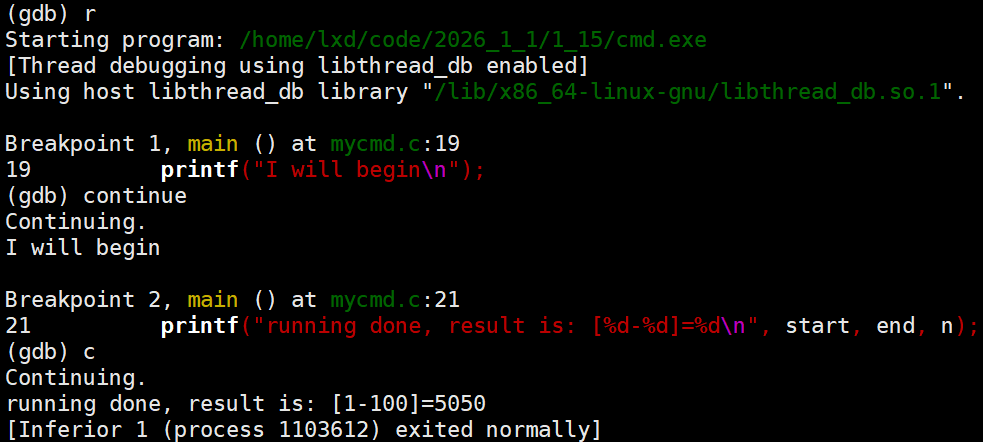
r:开始调试
c(continue)到下一个断点(如果后面没有断点那么直接巡行到程序结束)

b后面跟函数名:在当前函数的入口处(第一行)打断点
在调试的过程中,再次r,即可重新从头调试
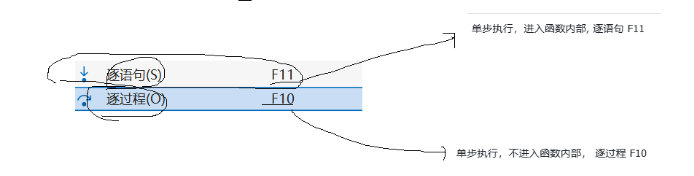
n(next):逐过程
s(step):逐语句
Q:n/s的本质是什么?
A:代码在小范围内局部性执行,帮助我们确认对应的问题
综上:在进行代码调试时,用断点确大范围,用n/s确定小范围,这样就能精细的判断出是什么问题
p:临时看一下这个变量
display:常显示变量值的变化(相当于监视窗口)
undisplay:取消常显示
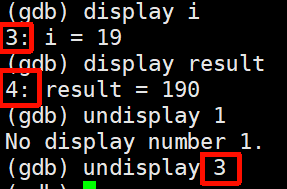
取消常显示时,后面要跟对应的编号(和删除断点类似)
陷入一个循环出不来了,可以在循环外打一个断点,然后c一下
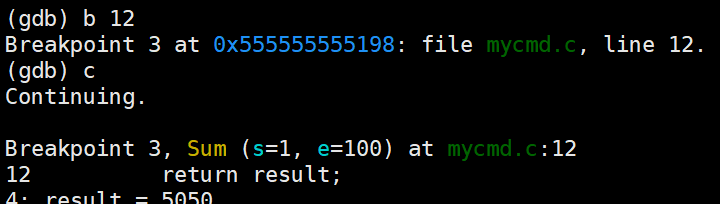
更直接的做法,until 行号:跳转到指定行
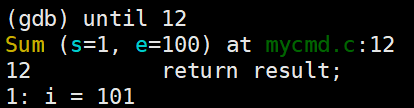
三个细节:
- until不能跨函数,只能在一个函数内部跳转到想要跳转的位置。(如果超出函数范围行号,即跨出了函数,就默认把这个函数跑完了)
- until只能向下跳,如果要向上跳,就默认把这个函数执行完
- 如果until 行号,当前行号是空行,那么gdb会自动跳转到距离当前行号最近的有效代码行处
进入一个函数之后,直接将这个函数全部跑完,跑完之后立马停下来的方法:
until、打断点
更简单的做法:finish:执行当前函数,执行完之后立即停止
小结:

s/n:精细化查找
display/undisplay/p:查看变量内容
4.4 常见使用总结
- 开始: gdb binFile
- 退出: ctrl + d 或 quit 调试命令
| 命令 | 作用 | 样例 |
|---|---|---|
| list/l | 显示源代码,从上次位置开始,每次列出10行 | list/l 10 |
| list/l 函数名 | 列出指定函数的源代码 | list/l main |
| list/l 文件名:行号 | 列出指定文件的源代码 | list/l mycmd.c:1 |
| r/run | 从程序开始连续执行 | run |
| n/next | 单步执行,不进入函数内部(逐过程 F10) | next |
| s/step | 单步执行,进入函数内部(逐语句 F11) | step |
| break/b 文件名:行号 | 在指定行号设置断点 | break 10 break test.c:10 |
| break/b 函数名 | 在函数开头设置断点 | break main |
| info break/b | 查看当前所有断点的信息 | info break |
| finish | 执行到当前函数返回,然后停止 | finish |
| print/p 表达式 | 打印表达式的值 | print start-end |
| p 变量 | 打印指定变量的值 | p x |
| set var 变量=值 | 修改变量的值 | set var i=10 |
| continue/c | 从当前位置开始连续执行程序 | continue |
| delete/d breakpoints | 删除所有断点 | delete breakpoints |
| delete/d breakpoints n | 删除序号为n的断点 | delete breakpoints 1 |
| disable breakpoints | 禁用所有断点 | disable breakpoints |
| enable breakpoints | 启用所有断点 | enable breakpoints |
| info/i breakpoints | 查看当前设置的断点列表 | info breakpoints |
| display 变量名 | 跟踪显示指定变量的值(每次停止时自动显示) | display x |
| undisplay 编号 | 取消对指定编号的变量的跟踪显示 | undisplay 1 |
| until 行号 | 执行到指定行号 | until 20 |
| backtrace/bt | 查看当前执行栈的各级函数调用及参数 | backtrace |
| info/i locals | 查看当前栈帧的局部变量值 | info locals |
| quit | 退出GDB调试器 | quit |
4.5 三种常见的debug技巧
1.watch (主要场景:监视指针!)
1.对比变量变化的前后关系
2.监视不能改变的变量
2.set var(确定并验证问题原因)
最大价值:可以直接在调试期间更改变量值,进而兑现我们对某些问题原因的猜测,直接去验证它
3.条件断点
1)新增一个条件断点
2)给已经存在的断点增加条件
总结
如有不足或改进之处,欢迎大家在评论区积极讨论,后续我也会持续更新Linux相关的知识。文章制作不易,如果文章对你有帮助,就点赞收藏关注支持一下作者吧,让我们一起努力,共同进步!