一、简介
本系列为Langgraph文章,最终以实现企业级项目。

💟 我们已经上线了一版本初稿,欢迎各位体验 https://ai.sofreight.com/ 💟
💟 本文教学带上了该初版Agent的部分业务教学,欢迎阅览 💟
该系列文章,以官方文档路径撰写,深入浅出并配以自己理解,配以GIF动图演示、适当扩展延伸官方案例以及源码讲解
当然如果你需要你也可以查看官方文档
最终实战项目目标:构建一个Agents Framework(智能代理框架) 多智能体协作企业系统
本文如若有错误地方,烦请指正,另外方便的话,麻烦点个赞关注一下,谢谢
- 📊 Agent-Graph:每个业务 Agent 以状态图形式编排节点、条件边与循环边;
- 🔧 工具体系:自动发现与注册工具,支持函数调用(tool calling),可扩展MCP服务;
- 🗄️ 记忆/持久化:使用 Postgres 作为 LangGraph 的 checkpointer 与 store,Redis缓存prompt;
- 📋 统一注册中心:自动发现、注册并预编译 Agent 图与工具;
- 💪 滚动窗口摘要算法压缩上下文,用户画像,短期记忆,长期记忆混合
- 🌐 API 网关:FastAPI 路由聚合,提供通用 chat、agents、session 等接口;
- 🔄 可插拔 LLM:通过模型工厂与配置驱动,统一管理多厂商 LLM。
- 🌀 prompt缓存:redis加载prompt,prompt-web热更新管理
- 👁️🗨️ RAG 向量数据库,与工程结合,结构化,非结构化管理检索,召回
- 🥰 下一步引导功能,猜你想要功能
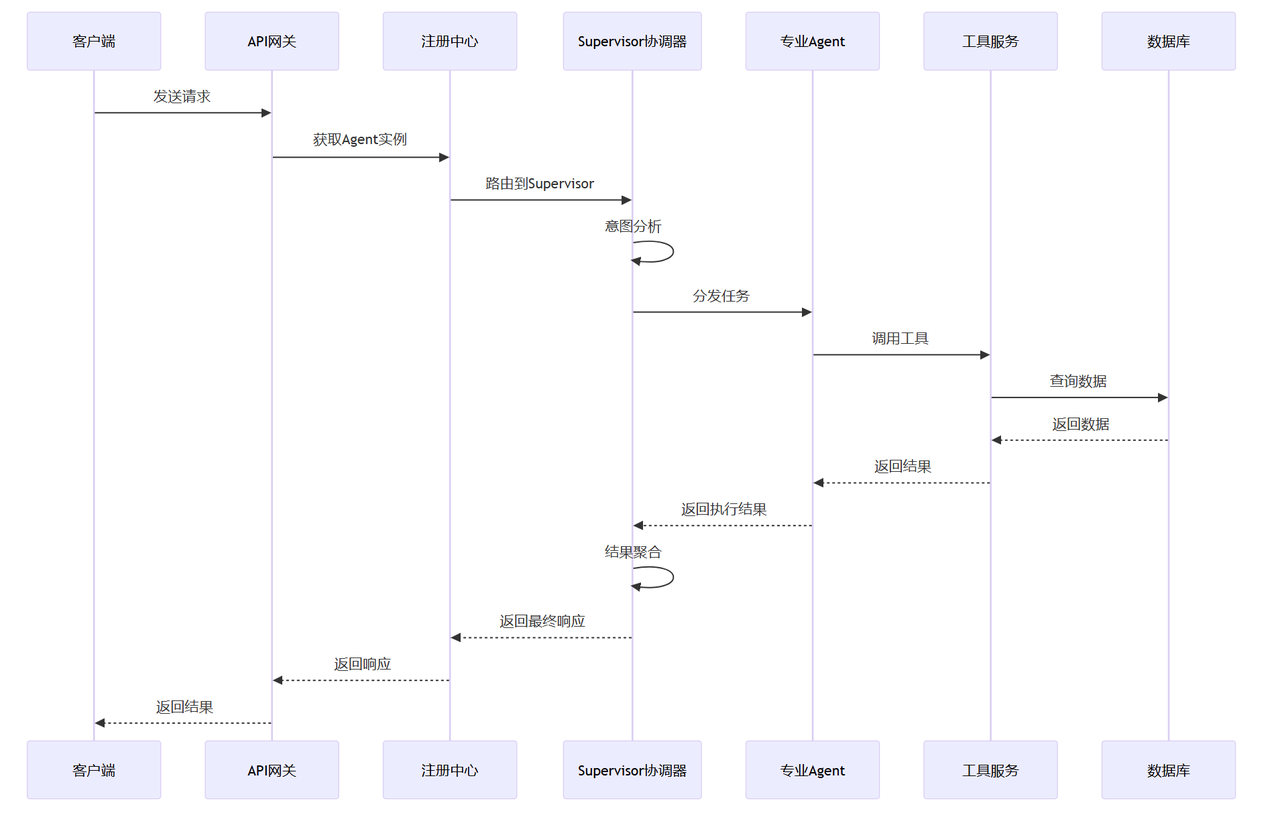
❤本系列文章,配套项目源码地址❤
https://github.com/wenwenc9/langgraph-tutorial-wenwenc9
Langgraph系列文章
01|Langgraph | 从入门到实战 | 基础篇
02|Langgraph | 从入门到实战 | workflow与Agent
03|Langgraph | 从入门到实战 | 进阶篇 | 持久化
langchain的系列文章(相信我把Langchain全部学一遍,你能深入理解AI的开发)
01|LangChain | 从入门到实战-介绍
02|LangChain | 从入门到实战 -六大组件之Models IO
03|LangChain | 从入门到实战 -六大组件之Retrival
04|LangChain | 从入门到实战 -六大组件之Chain
05|LangChain | 从入门到实战 -六大组件之Memory
06|LangChain | 从入门到实战 -六大组件之Agent
二、Langgraph 流式传输意义
本章节对应的项目地址吗,希望能给我一个小星星,欢迎各位交流:
https://github.com/wenwenc9/langgraph-tutorial-wenwenc9/tree/main/Langgraph_Learning/2-进阶
流式传输(Streaming)在 LangGraph 中具有重要的实际意义,主要体现在以下几个方面
| 维度 | 核心价值 |
|---|---|
| 🎯 用户体验 | 即时反馈,降低感知延迟 |
| ⚡ 性能优化 | 降低内存占用,提升并发能力 |
| 🔍 可观测性 | 实时监控,快速调试 |
| 💰 成本控制 | 节省 API 调用,优化资源使用 |
| 🚀 生产就绪 | 支持大规模、长时运行的应用 |
用一个简单的代码来体验流式传输:
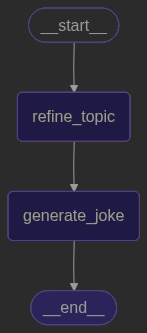
- 使用 stream 方法调用图
- 创建了两个节点
refine_topic跟generate_joke,串行执行
python
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
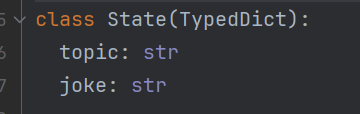
class State(TypedDict):
topic: str
joke: str
def refine_topic(state: State):
return {"topic": state["topic"] + " and cats","name":"wenwenc9"}
def generate_joke(state: State):
return {"joke": f"This is a joke about {state['topic']}"}
graph = (
StateGraph(State)
.add_node(refine_topic)
.add_node(generate_joke)
.add_edge(START, "refine_topic")
.add_edge("refine_topic", "generate_joke")
.add_edge("generate_joke", END)
.compile()
)输出内容如下:
python
{'refine_topic': {'topic': 'ice cream and cats'}}
{'generate_joke': {'joke': 'This is a joke about ice cream and cats'}}三、流式中的不同模式
我们在前面使用了stream方法,传入了stream_mode="updates" ,我们还有别的模式方法
将以下一个或多个流模式作为列表传递给 stream 或 astream 方法
| 模式 | 描述 |
|---|---|
| values | 在图的每一步之后流式传输状态的全部值。 |
| updates | 在图的每一步之后流式传输状态的更新。如果在同一步骤中进行了多个更新(例如,运行了多个节点),则这些更新将分别流式传输。 |
| custom | 从你的图节点内部流式传输自定义数据。 |
| messages | 从任何调用 LLM 的图节点流式传输 2 元组(LLM 令牌、元数据)。 |
| debug | 在整个图执行过程中尽可能流式传输信息。 |
LangGraph 的 stream_mode 参数让你选择性地获取图执行过程中的不同类型数据,支持单模式和多模式组合
下面我将逐一的讲解,依然使用上面那个基础的图graph 图代码
1、updates模式
- 流式传输每一步节点返回的状态更新。
- 流式传输的输出包括节点的名称以及更新内容。
- 具体是每个节点为对象
其实就是打印每个节点,对于操作base_state对应键
python
for chunk in graph.stream(
{"topic": "ice cream"},
stream_mode="updates",
):
for node, update in chunk.items():
print(f"节点 {node} 更新: {update}")输出
python
节点 refine_topic 更新: {'topic': 'ice cream and cats'}
节点 generate_joke 更新: {'joke': 'This is a joke about ice cream and cats'}我们前面创建了 两个节点
refine_topic更新状态机的joke跟一个name

generate_joke更新状态机的joke

所以看到了具体每个节点操作状态机字段的更新内容,其中name并非在状态机是无法看到的
2、values模式
可以在每一步之后流式传输图的全状态,每个节点涉及到 base_state 更新的都会打印出来
其实也就是,整个base_state的变化监控
python
for chunk in graph.stream(
{"topic": "ice cream"},
stream_mode="values",
):
print(chunk)输出
python
{'topic': 'ice cream'}
{'topic': 'ice cream and cats'}
{'topic': 'ice cream and cats', 'joke': 'This is a joke about ice cream and cats'}从输入到,2个节点处理后的内容都看到
3、custom模式
前面咱了解了updates跟values,这些都是对base_state状态机的操作打印
在真实的业务中,我们时常会让AI调用XX工具,然后用户等待过程不会那么枯燥
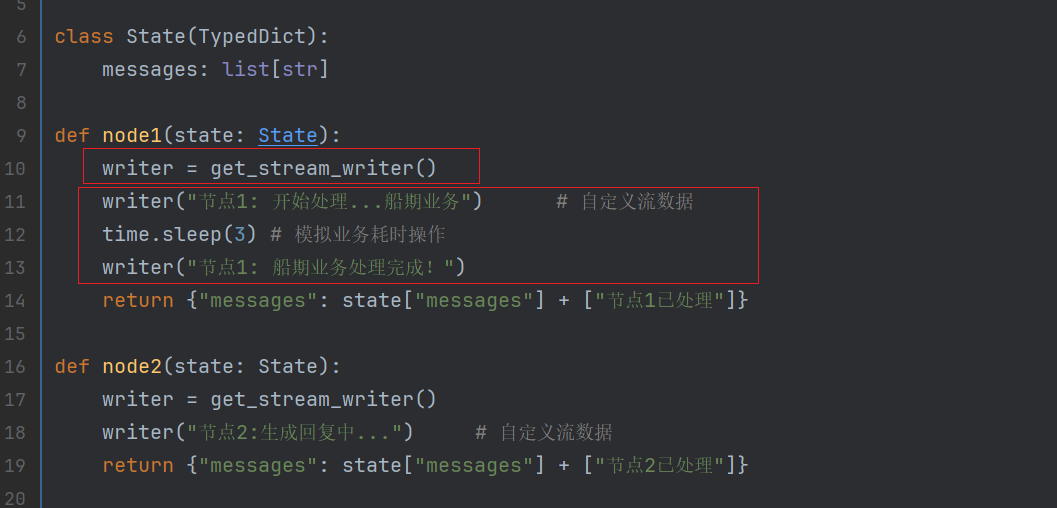
在Langgraph中,有custom自定义的模式,我们配合get_stream_writer 方式可以实现
python
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.config import get_stream_writer
import time
class State(TypedDict):
messages: list[str]
def node1(state: State):
writer = get_stream_writer()
writer("节点1: 开始处理...船期业务") # 自定义流数据
time.sleep(3) # 模拟业务耗时操作
writer("节点1: 船期业务处理完成!")
return {"messages": state["messages"] + ["节点1已处理"]}
def node2(state: State):
writer = get_stream_writer()
writer("节点2:生成回复中...") # 自定义流数据
return {"messages": state["messages"] + ["节点2已处理"]}
# 构建最小图
graph = (
StateGraph(State)
.add_node("node1", node1)
.add_node("node2", node2)
.add_edge(START, "node1")
.add_edge("node1", "node2")
.add_edge("node2", END)
.compile()
)
graph创建了2个节点,并且模拟业务的部分,并且模拟业务耗时3s
我们单独使用custom方式
python
inputs = {"messages": ["你好世界"]}
# 同时流式传输更新和自定义数据
for chunk in graph.stream(inputs, stream_mode="custom"):
# print(f"模式: {mode}")
print(f"数据: {chunk}")
print("---")输出内容如下
python
数据: 节点1: 开始处理...船期业务
---
数据: 节点1: 船期业务处理完成!
---
数据: 节点2:生成回复中...
---现在我们将指定模式为多模式方式 stream_mode=["updates","values","custom"]
python
inputs = {"messages": ["你好世界"]}
# 同时流式传输更新和自定义数据
for chunk in graph.stream(inputs, stream_mode=["updates","values","custom"]):
# print(f"模式: {mode}")
print(f"数据: {chunk}")
print("---")输出内容如下
python
数据: ('custom', '节点1: 开始处理...船期业务')
---
数据: ('custom', '节点1: 船期业务处理完成!')
---
数据: ('updates', {'node1': {'messages': ['你好世界', '节点1已处理']}})
---
数据: ('values', {'messages': ['你好世界', '节点1已处理']})
---
数据: ('custom', '节点2:生成回复中...')
---
数据: ('updates', {'node2': {'messages': ['你好世界', '节点1已处理', '节点2已处理']}})
---
数据: ('values', {'messages': ['你好世界', '节点1已处理', '节点2已处理']})
---可以看到,多模式的列表传输下,响应的chunk为元组,并且能看到更多功能
4、messages模式
聊天界面常用、逐字显示AI回复
使用 messages 流模式,从您的任何部分(包括节点、工具、子图或任务)流式传输大型语言模型(LLM)输出字节串 。
这个功能要求为langchain所定义的 messages 标准消息载体对象,自己点开代码看看
langchain_core.messages
下面案例创建2个节点,来模拟业务
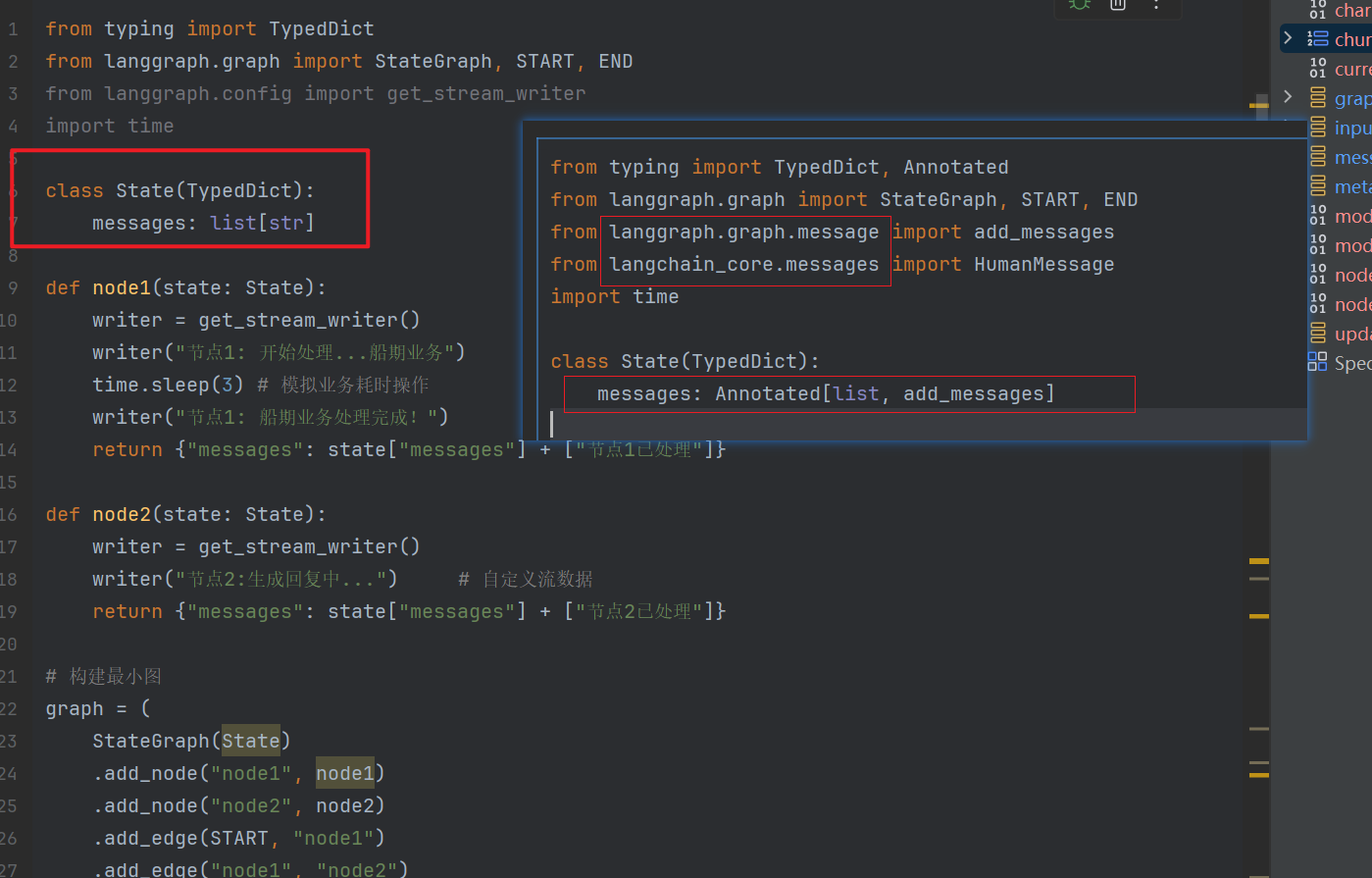
python
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_core.messages import HumanMessage
import time
class State(TypedDict):
messages: Annotated[list, add_messages]
def node1(state: State):
"""节点1:模拟流式生成分析结果"""
text = "正在分析船期查询...上海到洛杉矶航线分析完成!"
# 关键:返回 AIMessage,LangGraph 会自动处理流式
return {"messages": [AIMessage(content=text)]}
def node2(state: State):
"""节点2:模拟流式生成船期结果"""
text = """
船期查询结果:
1. 马士基航运 - 1月20日开船
2. 中远海运 - 1月22日开船
3. 长荣海运 - 1月25日开船
查询完成!"""
return {"messages": [AIMessage(content=text)]}
# 构建图
graph = (
StateGraph(State)
.add_node("analyze", node1)
.add_node("query", node2)
.add_edge(START, "analyze")
.add_edge("analyze", "query")
.add_edge("query", END)
.compile()
)
inputs = {"messages": [HumanMessage(content="查询上海到洛杉矶船期")]}
current_node = None
for message, metadata in graph.stream(inputs, stream_mode="messages"):
node_name = metadata.get("langgraph_node", "")
# 节点切换时显示标题
if node_name != current_node:
if current_node:
print("\n")
print(f"[{node_name}] ", end="", flush=True)
current_node = node_name
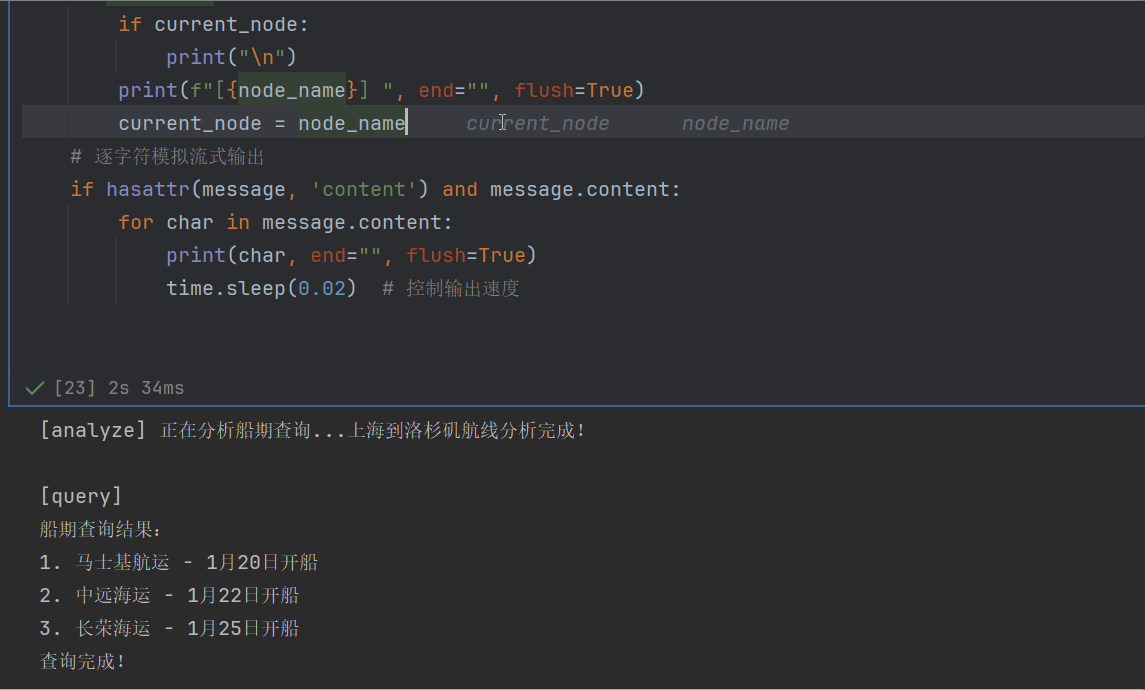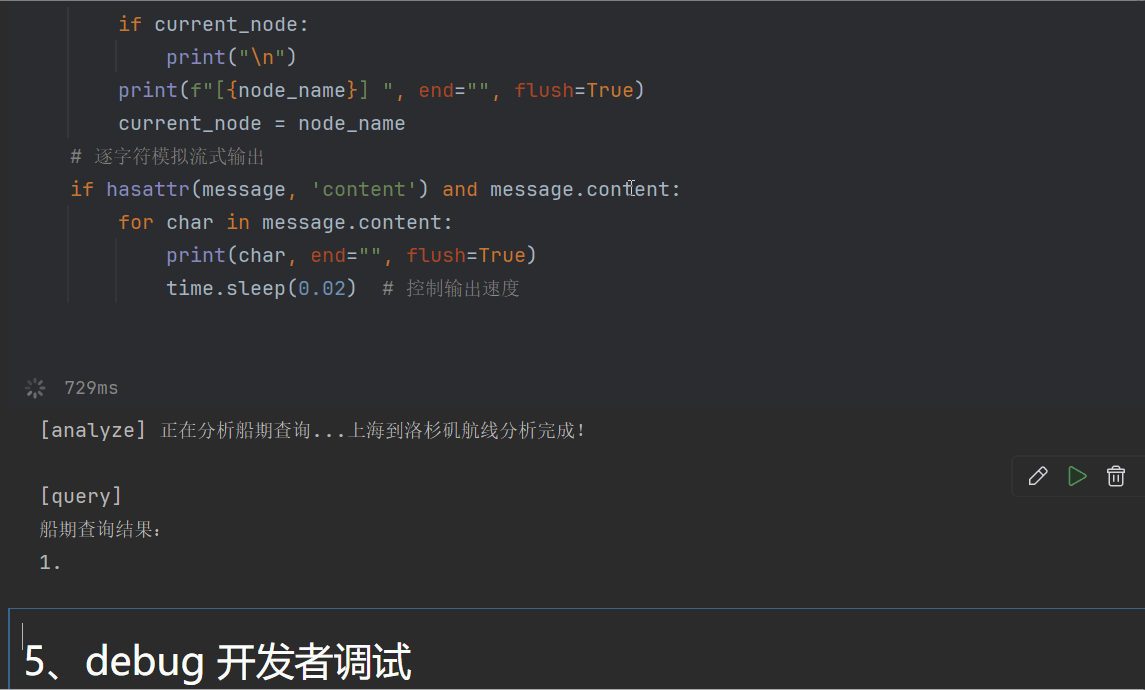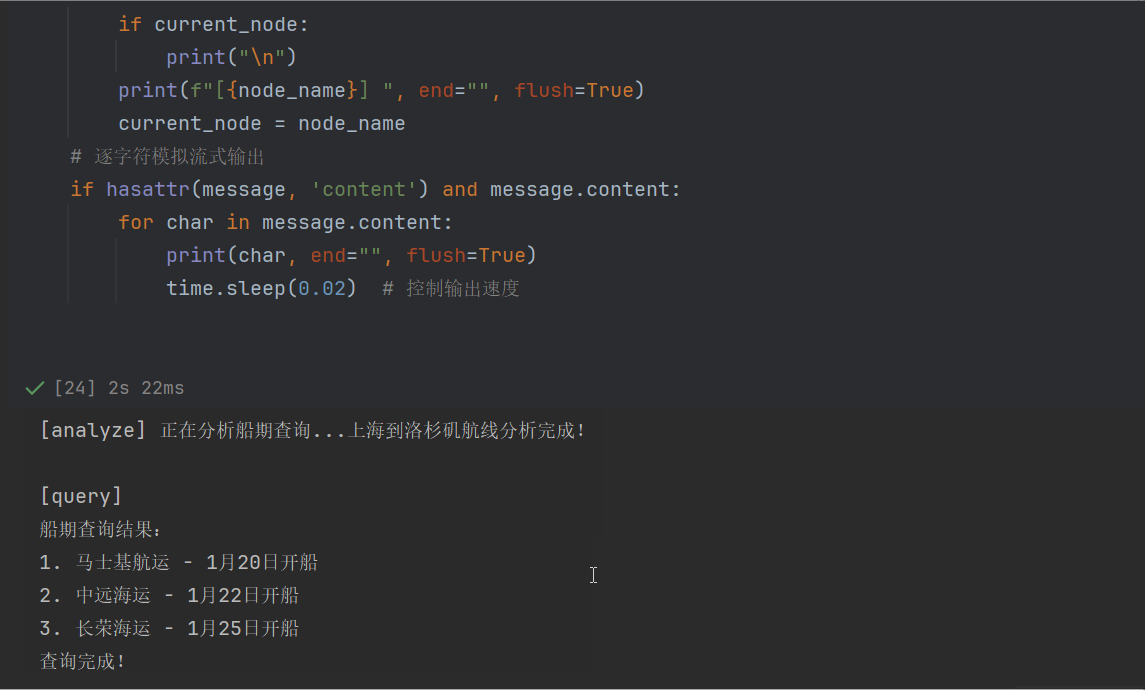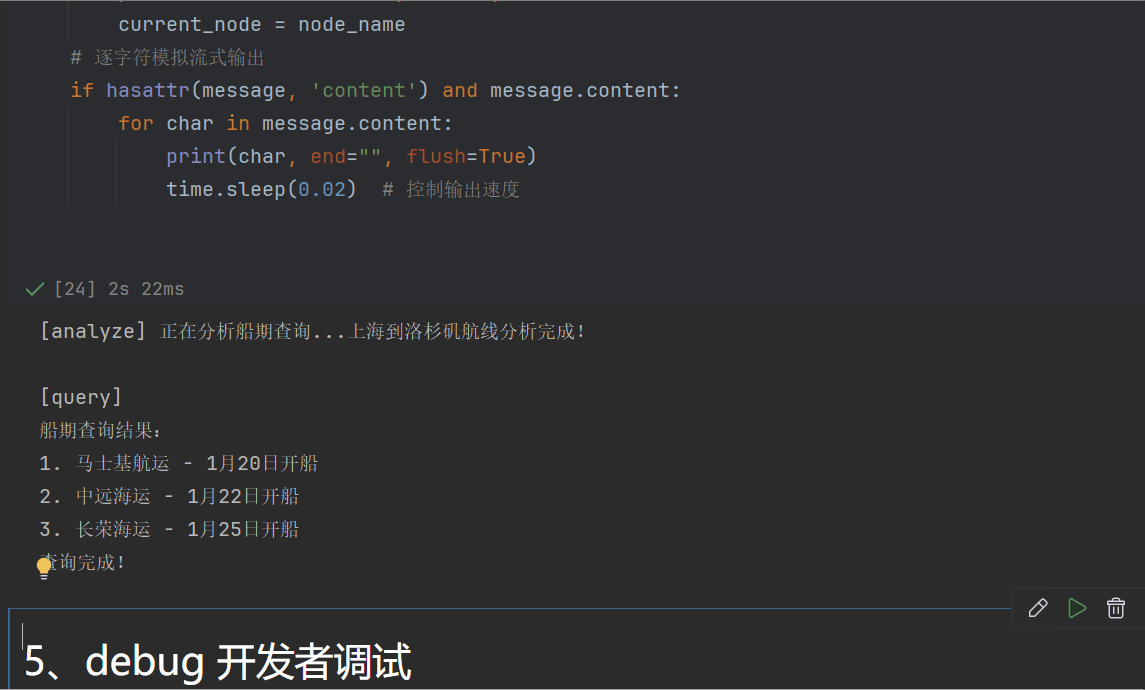
# 逐字符模拟流式输出
if hasattr(message, 'content') and message.content:
for char in message.content:
print(char, end="", flush=True)
time.sleep(0.02) # 控制输出速度运行代码,可以看到一个一个字的蹦出来
请注意,base_state定义的状态机代码,你在上个案例运行messages是不会出结果的,因为不是messages 对象
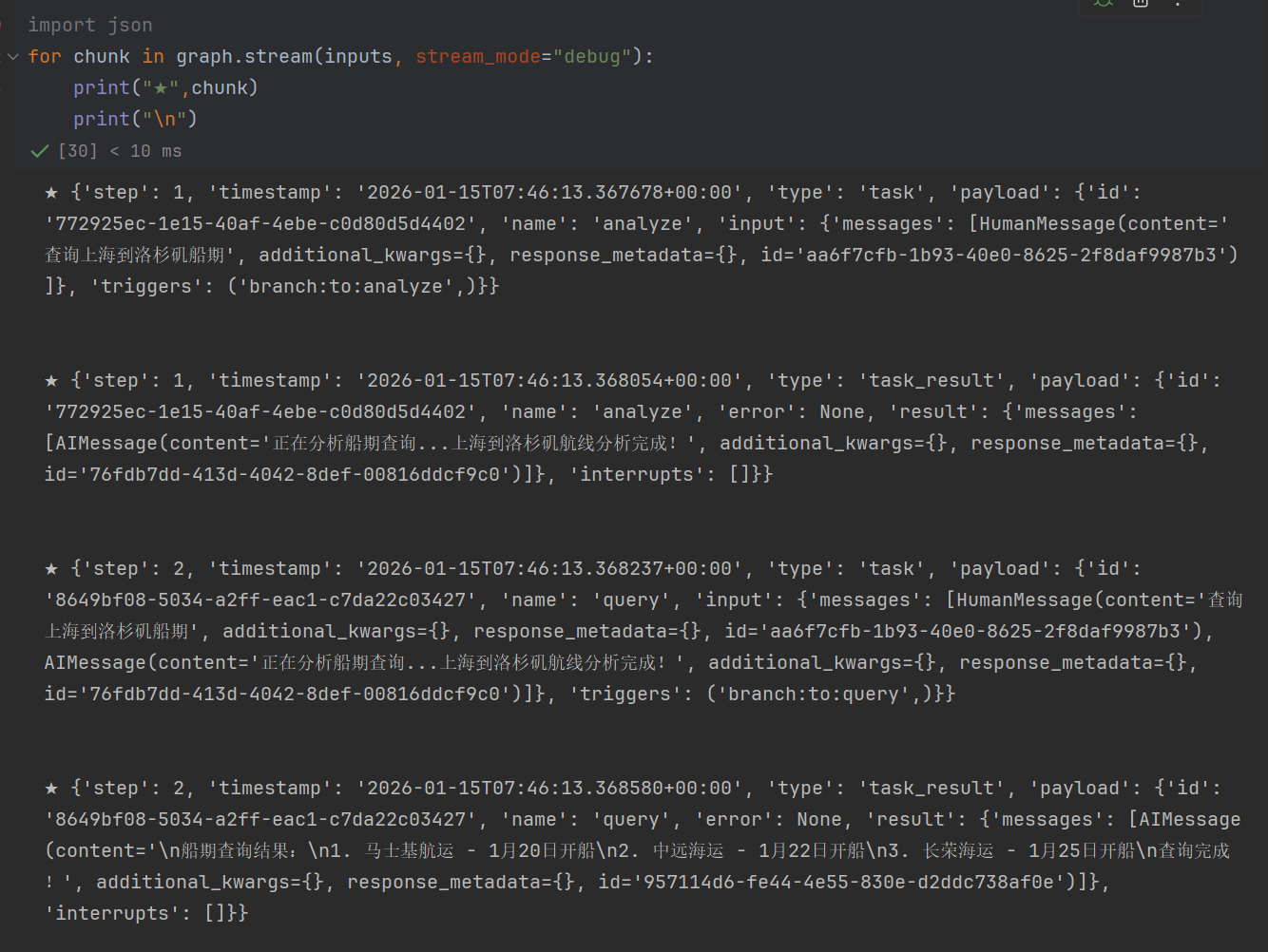
5、debug模式
顾名思义,开发者模式,用于调试使用使用
python
import json
for chunk in graph.stream(inputs, stream_mode="debug"):
print("★",chunk)
print("\n")它能得到,图的每一步执行情况
四、综合案例
下面我将用综合案例,来结合多个模式,并且调用模型进行实现
背景:
-
用户输入一个货物订单号,我们创建一个
search_tool节点模拟检索数据库订单运输进度 -
然后然调用
generate_reply_llm对该订单查询后的结果,美化回复给用户
在这个章节中,演示很早我踩过的坑,真假流式
1、假流式
python
from typing import Annotated
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.config import get_stream_writer
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage
from dotenv import load_dotenv, find_dotenv
import os
import time
from typing import TypedDict
load_dotenv(find_dotenv())
modelName = os.getenv('OPENAI_MODEL')
class State(TypedDict):
messages: Annotated[list, add_messages]
progress: int
def search_tool(state: State):
writer = get_stream_writer()
writer("🔍 正在查询订单数据库...")
writer("📦 找到用户订单 #12345")
writer("✅ 查询完成")
return {"progress": 50}
def generate_reply_llm(state: State):
writer = get_stream_writer()
writer("🤖 豆包 AI 正在生成个性化回复...")
llm = ChatOpenAI(model=modelName)
prompt = f"""
用户查询订单状态,已查询到订单#12345
当前进度: {state['progress']}%
请生成简短友好的客服回复,中文输出。
"""
# 返回 AIMessage 对象,而不是字符串
response = llm.invoke(prompt)
return {"messages": [response]} # 注意:返回 AIMessage 对象
# 构建图
graph = (
StateGraph(State)
.add_node("search", search_tool)
.add_node("reply", generate_reply_llm)
.add_edge(START, "search")
.add_edge("search", "reply")
.add_edge("reply", END)
.compile()
)运行代码
python
start_time = time.time() # 开始时间
# 初始消息也要用 HumanMessage
inputs = {
"messages": [HumanMessage(content="查询我的订单状态")],
"progress": 0
}
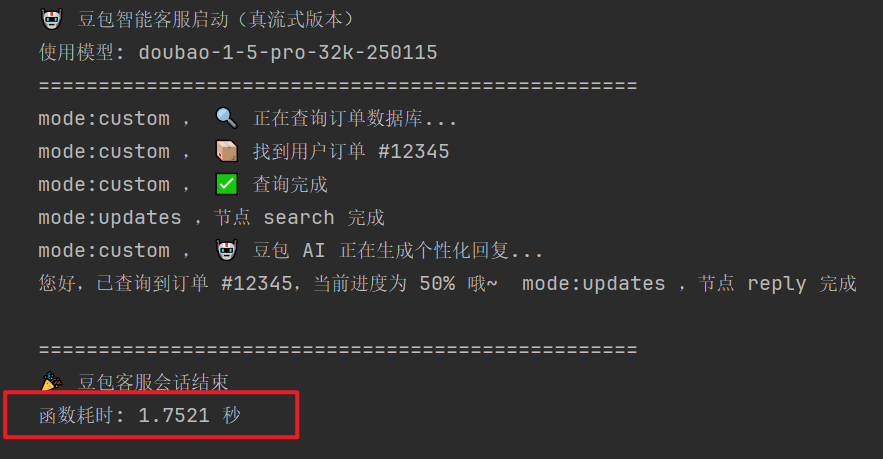
print("🤖 豆包智能客服启动")
print(f"使用模型: {modelName}")
print("=" * 50)
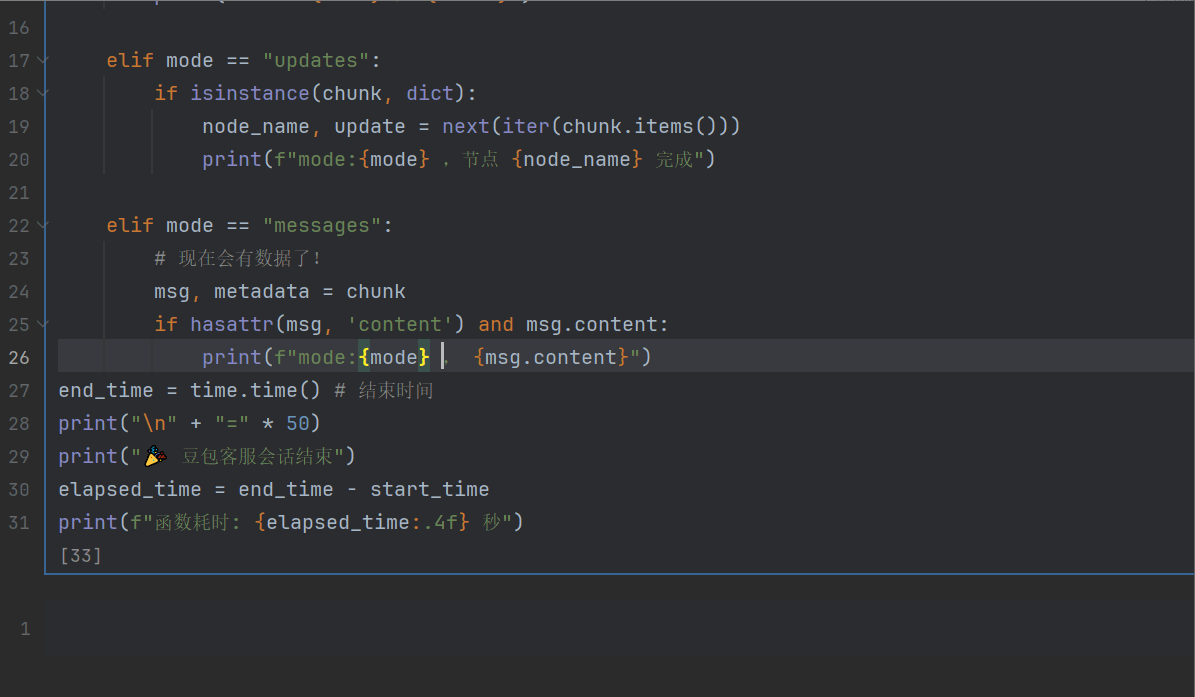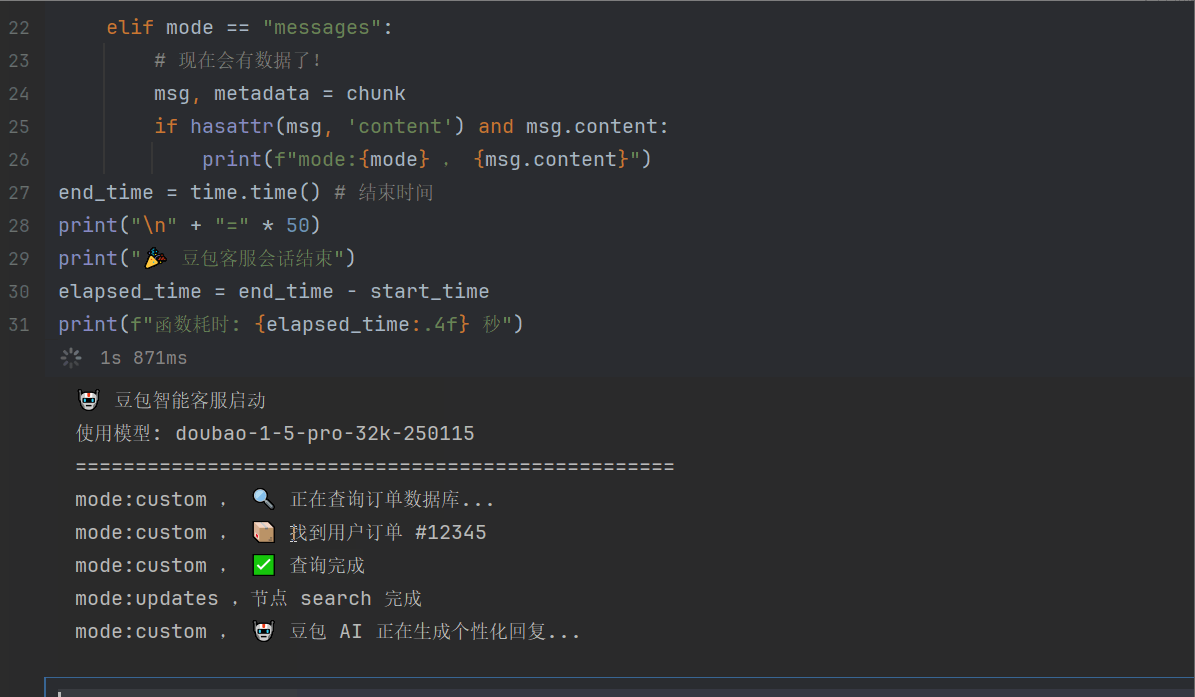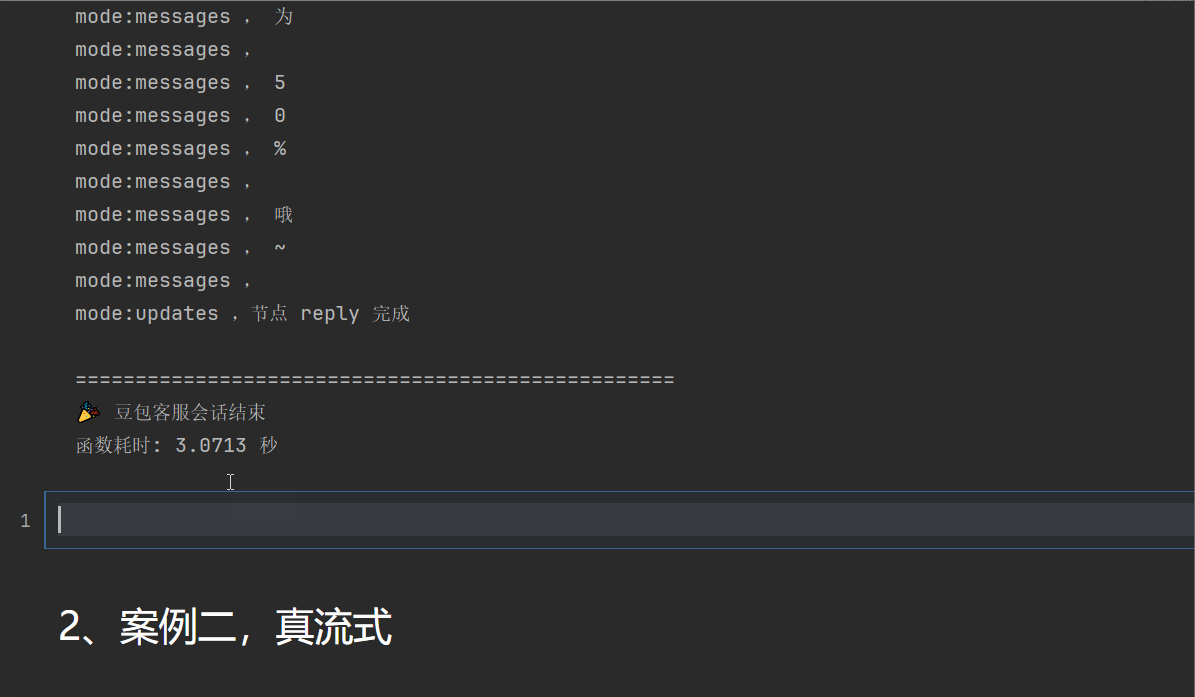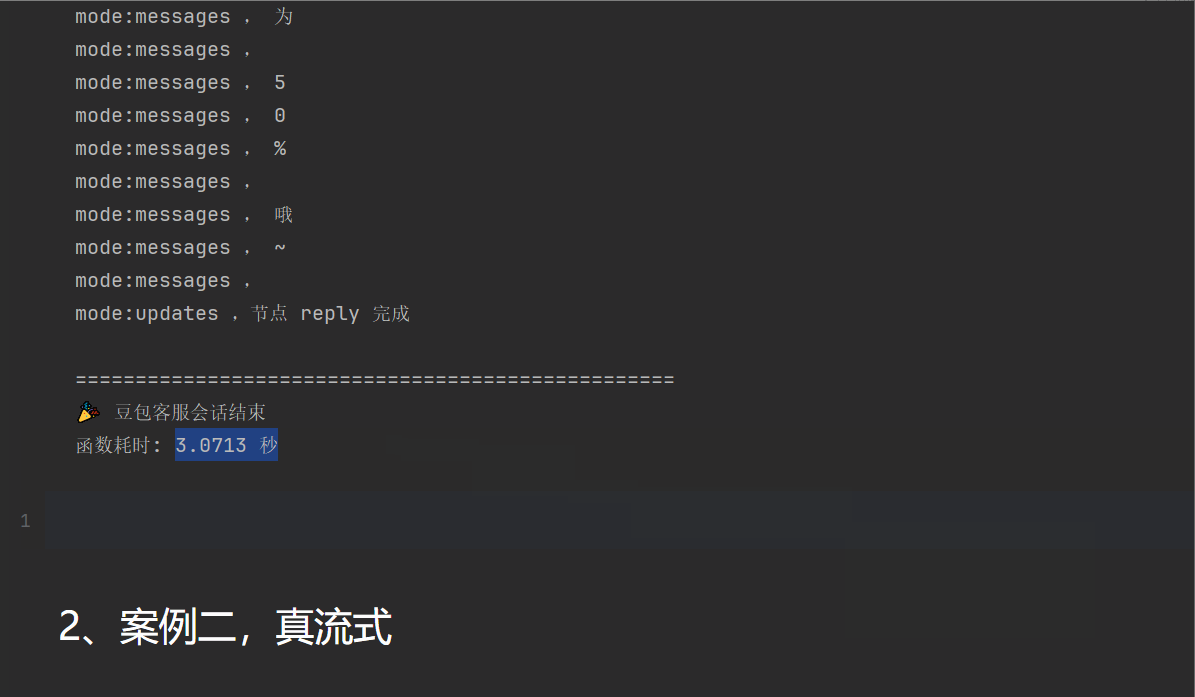
for mode, chunk in graph.stream(inputs, stream_mode=["custom", "messages", "updates"]):
if mode == "custom":
print(f"mode:{mode} , {chunk}")
elif mode == "updates":
if isinstance(chunk, dict):
node_name, update = next(iter(chun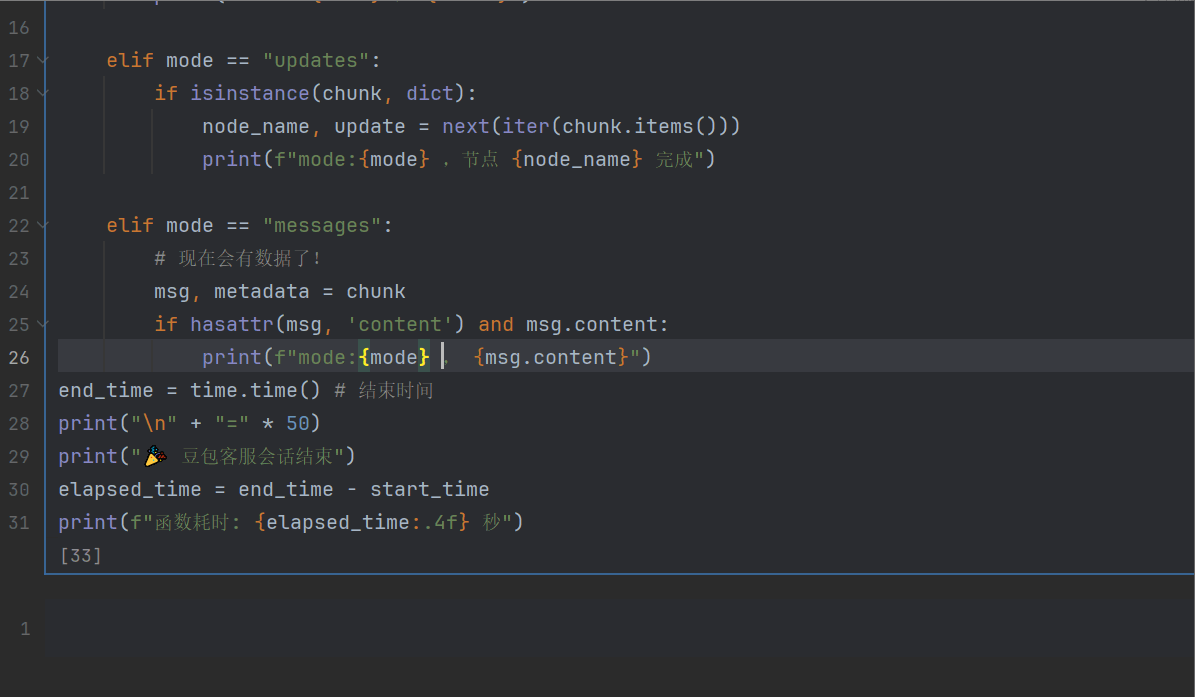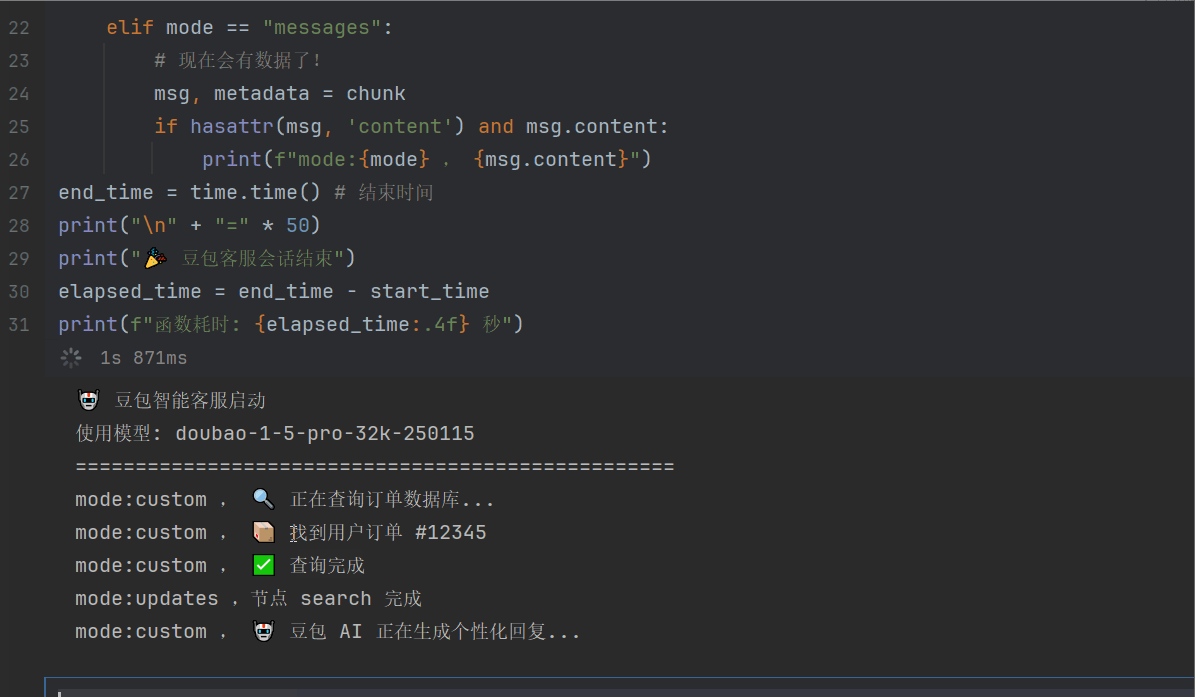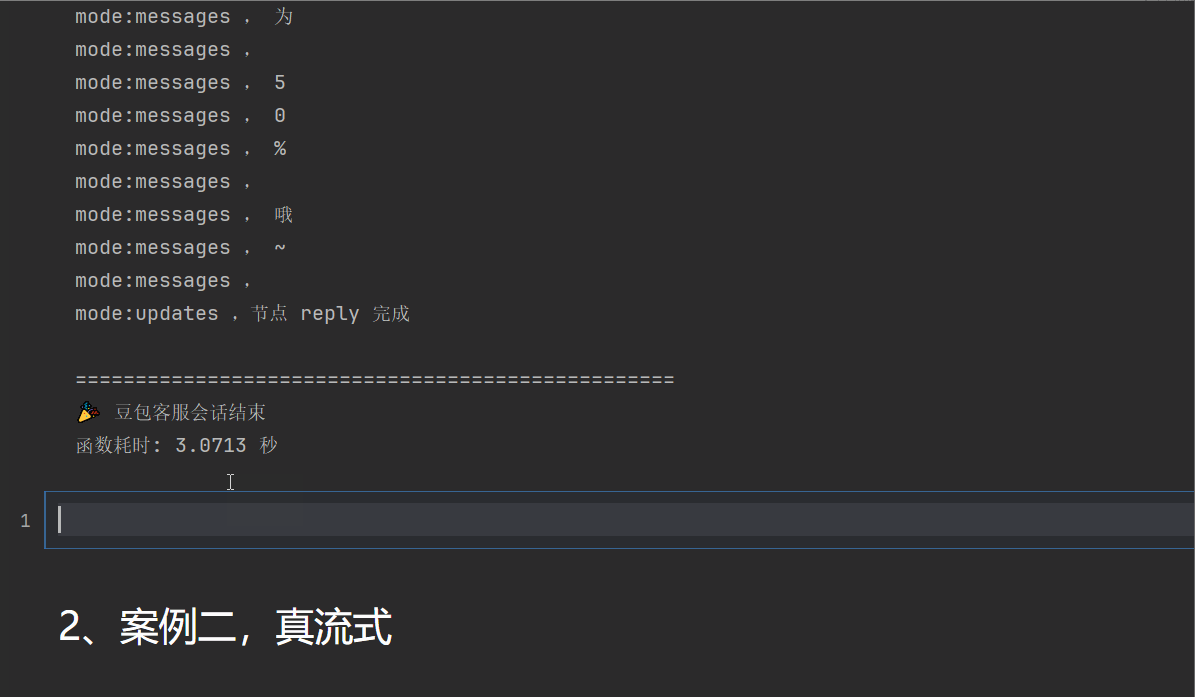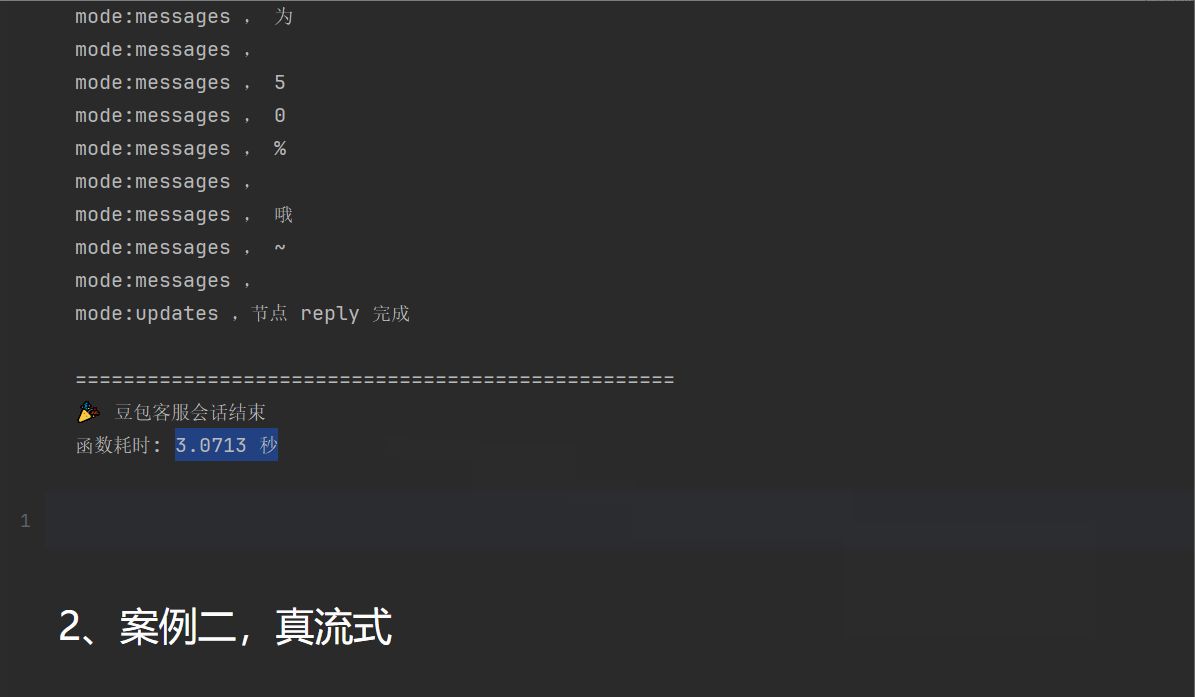
k.items()))
print(f"mode:{mode} ,节点 {node_name} 完成")
elif mode == "messages":
# 现在会有数据了!
msg, metadata = chunk
if hasattr(msg, 'content') and msg.content:
print(f"mode:{mode} , {msg.content}")
end_time = time.time() # 结束时间
print("\n" + "=" * 50)
print("🎉 豆包客服会话结束")
elapsed_time = end_time - start_time
print(f"函数耗时: {elapsed_time:.4f} 秒")可以看到,耗时3秒钟,可以看到一个一个字蹦出来,但是是真的吗?
那么为什么叫假流式呢?,尽管,我们调用图的时候,使用了stream
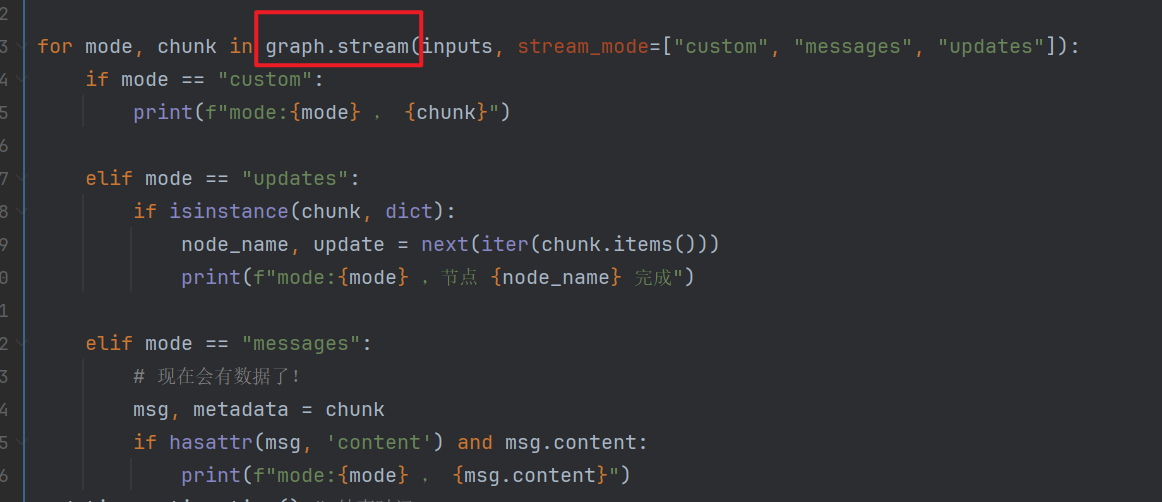
但是,在replay节点,调用模型是的时候,使用了invoke ,这个是让模型执行完成后整体得到messages
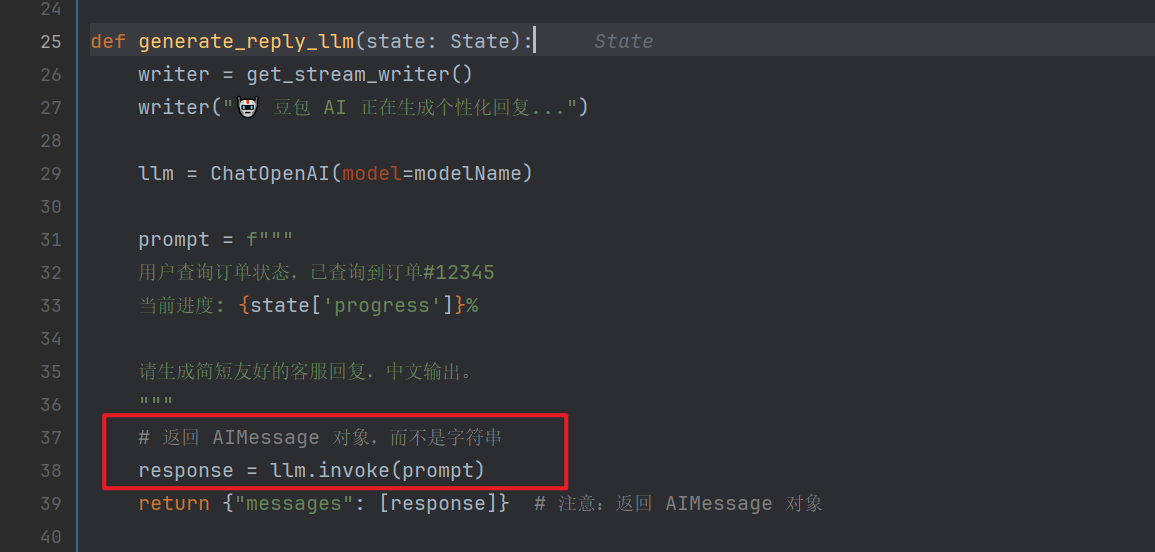
实际上是在节点中,进行response = llm.invoke ,该方法为模型最后的回复,并非真正的流式
只不会在 for chunk 的时候,判断了为messages,然后底层是自动会拆成字节
python
# LangGraph 内部伪代码
def _emit_message_events(node_output):
if "messages" in node_output:
for msg in node_output["messages"]:
# 即使是完整消息,也会作为 "流事件" 发出
yield ("messages", (msg, metadata))2、真流式
python
from typing import Annotated, Generator
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.config import get_stream_writer
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage
from dotenv import load_dotenv, find_dotenv
import os
from typing import TypedDict
import time
load_dotenv(find_dotenv())
modelName = os.getenv('OPENAI_MODEL')
class State(TypedDict):
messages: Annotated[list, add_messages]
progress: int
def search_tool(state: State):
writer = get_stream_writer()
writer("🔍 正在查询订单数据库...")
writer("📦 找到用户订单 #12345")
writer("✅ 查询完成")
return {"progress": 50}
def generate_reply_llm(state: State) -> Generator:
"""🔑 真流式节点 - 使用生成器逐令牌输出"""
writer = get_stream_writer()
writer("🤖 豆包 AI 正在生成个性化回复...")
# 🔑 启用流式输出
llm = ChatOpenAI(model=modelName, streaming=True)
prompt = f"""
用户查询订单状态,已查询到订单#12345
当前进度: {state['progress']}%
请生成简短友好的客服回复,中文输出。
"""
# 逐令牌
full_content = ""
for chunk in llm.stream(prompt):
# 每个令牌都作为独立的 AIMessage 发出
# 注意! 这个会影响sate messages 这个键,最后一次的输出
# yield {"messages": [AIMessage(content=chunk.content)]}
# writer({"messages": chunk}) # 走 custom 通道,实时推送
full_content += chunk.content
return {"messages": [AIMessage(content=full_content)]}
# 构建图
graph = (
StateGraph(State)
.add_node("search", search_tool)
.add_node("reply", generate_reply_llm) # 生成器节点
.add_edge(START, "search")
.add_edge("search", "reply")
.add_edge("reply", END)
.compile()
)对于replay节点进行改造,使用stream方式并且 yield 出去每个 chunk
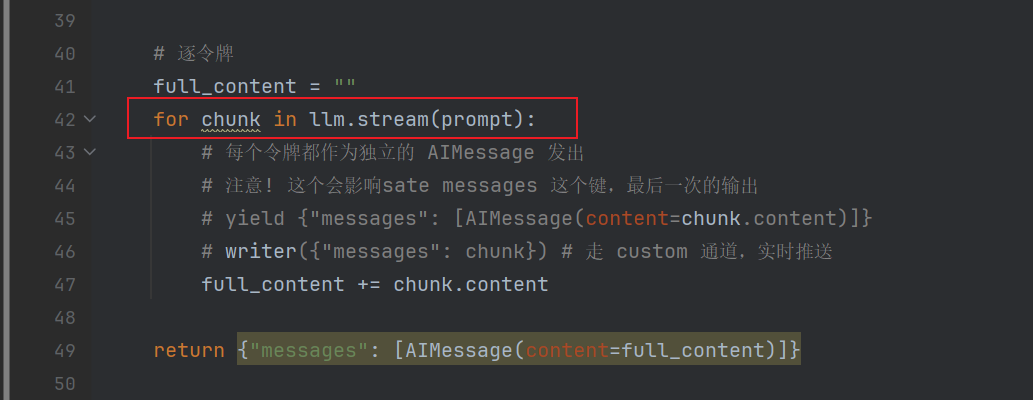
运行代码
python
start_time = time.time() # 开始时间
inputs = {
"messages": [HumanMessage(content="查询我的订单状态")],
"progress": 0
}
print("🤖 豆包智能客服启动(真流式版本)")
print(f"使用模型: {modelName}")
print("=" * 50)
for mode, chunk in graph.stream(inputs, stream_mode=["custom", "messages", "updates"]):
if mode == "custom":
print(f"mode:{mode} , {chunk}")
elif mode == "updates":
if isinstance(chunk, dict):
node_name, update = next(iter(chunk.items()))
print(f"mode:{mode} ,节点 {node_name} 完成")
elif mode == "messages":
# 🔑 现在会逐令牌输出(打字机效果)
msg, metadata = chunk
if hasattr(msg, 'content') and msg.content:
print(msg.content, end="", flush=True) # 不换行,逐字输出
end_time = time.time() # 结束时间
print("\n" + "=" * 50)
print("🎉 豆包客服会话结束")
elapsed_time = end_time - start_time
print(f"函数耗时: {elapsed_time:.4f} 秒")输出,可以看到速度上面,为1S左右,而前面的假流式,为3S左右
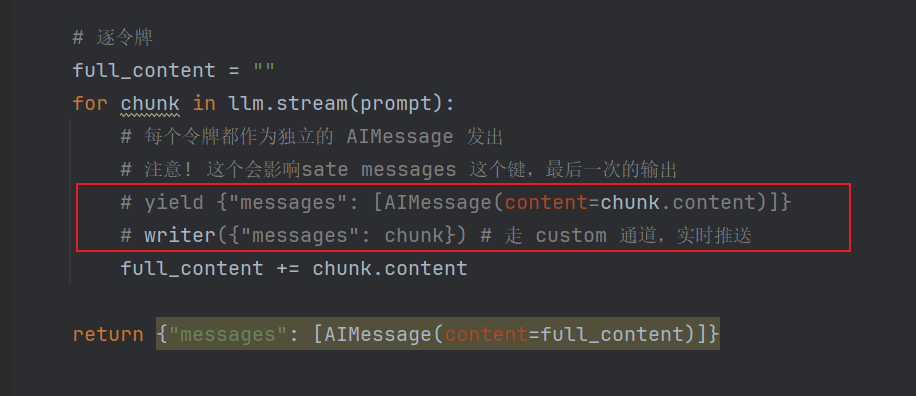
在代码中我预留了二个部分,即模型流式生成的时候,将内容发送出去
yield方式,会更新state会更新,但是是最后一条writer方式,会走custom模式
所以 yield用的不好的人不要用
一般,采用下面2个方式
- stream_mode模式带上
messages,你不用做任何yield writer也能看到流式内容 - stream_mode模式带上
custom,配合writer产生自定义一些内容
只要节点函数里出现了 yield,它就变成生成器节点;这类节点的"最终 return {...}"通常不会被当作一次 state update 合并进 checkpoint。最终落到 get_state() 里的,往往是最后一次 yield 的那条更新,是残缺的messages
五、子图流式
我们前面的章节都是一个图进行流式传输,本节说明图的子图进行流式传输
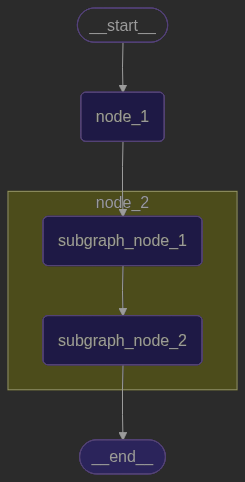
定义一个父图、定义一个子图,共计4个节点
-
父图状态机仅有一个键
foo -
子图状态机有2个键
foo跟bar -
父图有两个节点、
node_1、node_2 -
字图有两个节点、
subgraph_node_1跟subgraph_node_2
为了直观,我们采用updates模式只打印对应节点操作base_state字段的情况
python
from langgraph.graph import START, StateGraph
from typing import TypedDict
# ==================== 定义子图 ====================
# 子图状态:定义子图内部节点之间传递的数据结构
class SubgraphState(TypedDict):
foo: str # 注意:这个键与父图状态共享(父图也有 foo 字段)
bar: str # 子图特有的字段(父图没有)
def subgraph_node_1(state: SubgraphState):
"""
子图的第一个节点
功能:初始化 bar 字段
"""
print(" 🔹 [子图节点1] 执行中...")
return {"bar": "bar"} # 向状态中添加 bar 字段
def subgraph_node_2(state: SubgraphState):
"""
子图的第二个节点
功能:将 foo 和 bar 拼接后更新 foo
"""
print(f" 🔹 [子图节点2] 接收到状态: foo='{state['foo']}', bar='{state['bar']}'")
return {"foo": state["foo"] + state["bar"]} # 更新 foo 字段
# 构建子图
subgraph_builder = StateGraph(SubgraphState)
subgraph_builder.add_node(subgraph_node_1)
subgraph_builder.add_node(subgraph_node_2)
subgraph_builder.add_edge(START, "subgraph_node_1") # 子图入口 → 节点1
subgraph_builder.add_edge("subgraph_node_1", "subgraph_node_2") # 节点1 → 节点2
subgraph = subgraph_builder.compile() # 编译子图
# ==================== 定义父图 ====================
# 父图状态:只包含 foo 字段
class ParentState(TypedDict):
foo: str # 父图的状态字段(会传递给子图)
def node_1(state: ParentState):
"""
父图的节点1
功能:在 foo 前面添加 "hi! " 前缀
"""
print(f"🔷 [父图节点1] 接收到状态: foo='{state['foo']}'")
return {"foo": "hi! " + state["foo"]} # 更新 foo 字段
# 构建父图
builder = StateGraph(ParentState)
builder.add_node("node_1", node_1) # 添加父图节点1
builder.add_node("node_2", subgraph) # 🔑 添加子图作为节点(子图会被当作一个节点)
builder.add_edge(START, "node_1") # 父图入口 → 节点1
builder.add_edge("node_1", "node_2") # 节点1 → 子图节点
graph = builder.compile() # 编译父图
from IPython.display import Image, display
display(Image(graph.get_graph(xray=True).draw_mermaid_png()))运行代码
python
# ==================== 流式执行 ====================
print("=" * 60)
print("🚀 开始流式执行父图(包含子图)")
print("=" * 60)
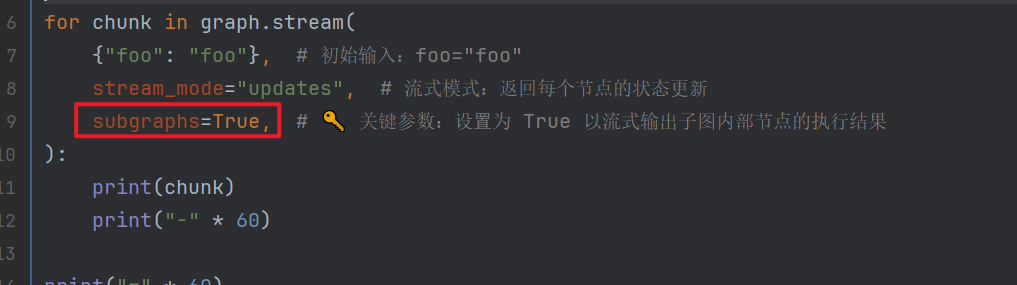
for chunk in graph.stream(
{"foo": "foo"}, # 初始输入:foo="foo"
stream_mode="updates", # 流式模式:返回每个节点的状态更新
subgraphs=True, # 🔑 关键参数:设置为 True 以流式输出子图内部节点的执行结果
):
print(chunk)
print("-" * 60)
print("=" * 60)
print("✅ 执行完成")
print("=" * 60)可以看到,父子图都能进行流式
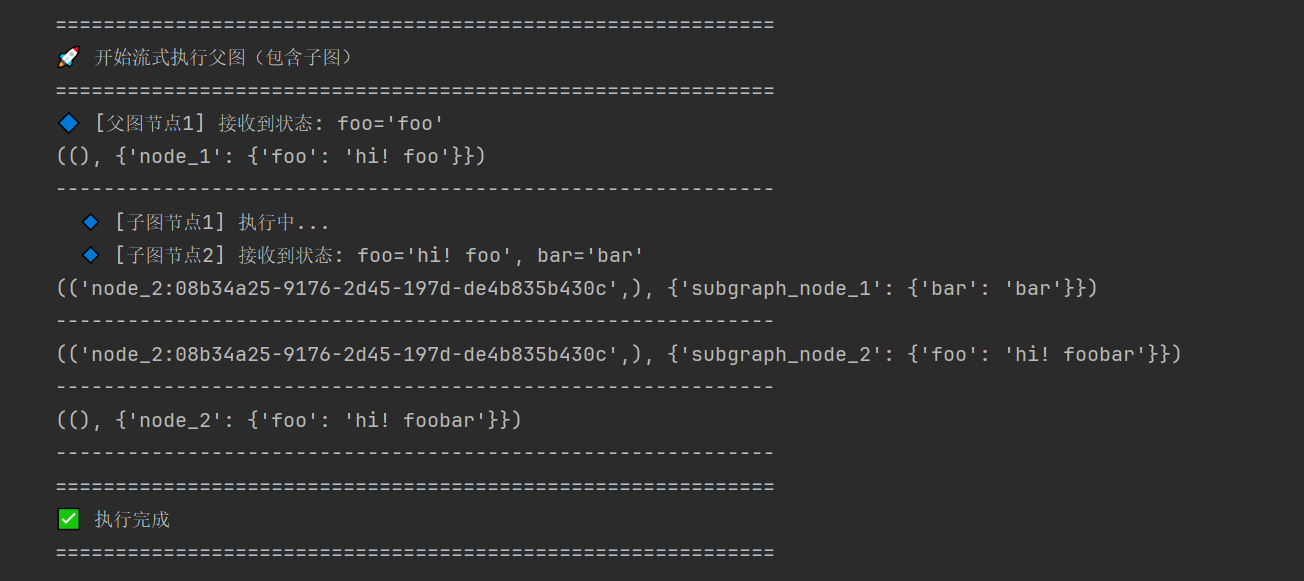
实际上关键点是,stream时候指定subgraphs=True
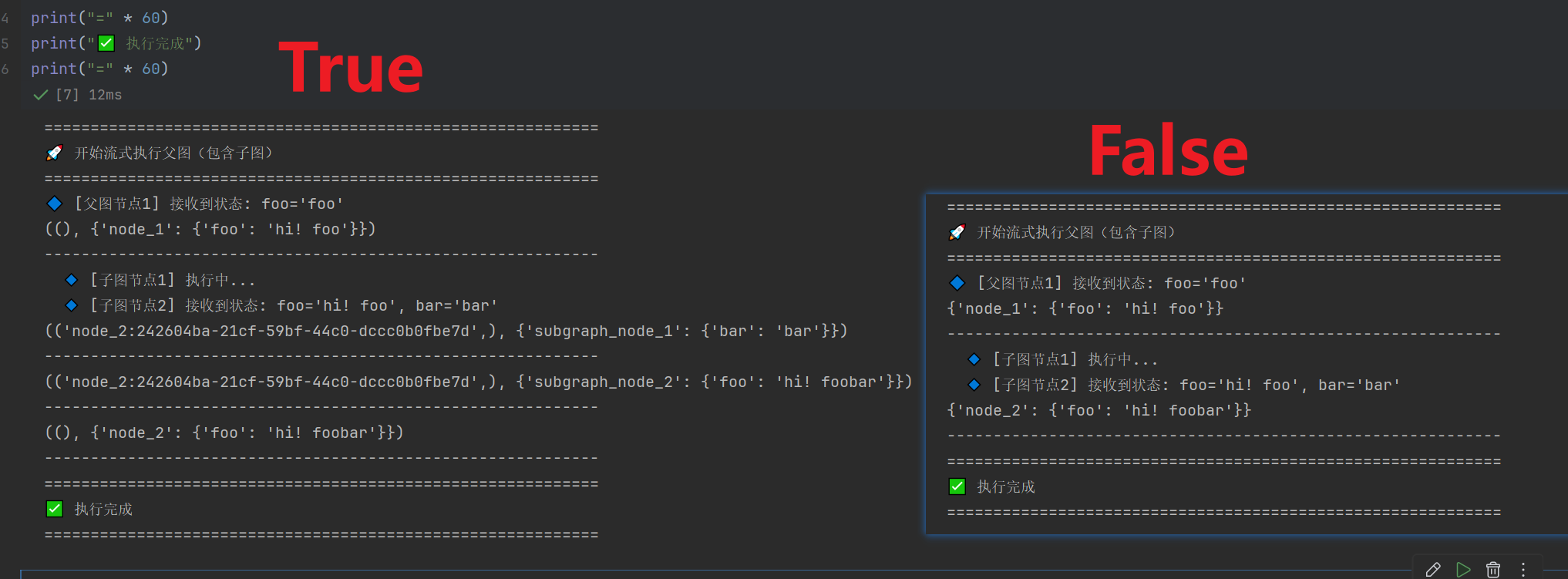
我们也可以,指定subgraphs=False看看输出对比
可以看到,因为是updates模式,很直观的看到关闭的时候,并没有显示子图对于base_state状态机操作的情况,少了2
六、总结
1)流式传输的本质:你到底在"流"什么?
LangGraph 里的 Streaming 不是一个概念,而是几条不同的"数据管道":
- updates:每个节点对 state 做了哪些更新(最适合看业务步骤、看状态机字段变更)。
- values:每一步完整 state 快照(最适合整体观察状态如何演进,但输出更大)。
- custom :节点内部通过
get_stream_writer()主动推送自定义事件(最适合"工具执行中.../进度条/阶段提示")。 - messages:LLM 输出的流式消息事件(最适合聊天 UI 的打字机效果)。
- debug:最全的开发者视角,排查图执行流程非常好用。
2)"真假流式"的工程结论:不要被"看起来在跳字"骗了
很多同学会遇到一种错觉:明明用了 graph.stream(... stream_mode="messages"),也看到文字一段段输出,为什么我还说它是假流式?
关键点是:真流式与否,要看 LLM 是否以 streaming 方式生成,而不是看你在外层是不是用了 stream。
-
假流式(常见误区)
- 节点里用的是
llm.invoke(...):模型先完整生成,再一次性返回完整AIMessage。 - 外层
messages之所以"像在流",往往只是框架把完整消息当事件发出来(或 UI 自己做了逐字渲染),但这不等于模型端在逐 token 产生。
- 节点里用的是
-
真流式(正确做法)
- 节点里用的是
llm.stream(...)/ 模型开启 streaming:模型侧就是增量输出,**TTFB(首 token 延迟)**更低,交互体验更顺。
- 节点里用的是
你在综合案例里测到"真流式更快",本质上就是:首 token 更早到达 + UI 更早开始渲染,用户感知速度明显提升。
3)yield 的坑:它适合"输出事件",不适合"维护最终 messages"
你在文中踩到的坑非常典型,也值得强调成结论:
- 只要节点函数里出现
yield,它就变成生成器节点。 - 在很多实际运行情况下:生成器节点末尾的
return {...}不一定会被当作最终 state 更新持久化。 - 结果就是:
get_state()里经常只保留 最后一次 yield 的那条更新,而 LLM 最后一个 chunk 很可能是空字符串/空格/标点,最终 state 就"残缺"。
所以工程上更推荐的模式是:
- messages 流式给 UI 看 :用
stream_mode="messages"(你不用自己yieldtoken) - custom 流式给 UI 看进度 :用
writer走custom - 最终对话历史入库 :用普通
return一次性写入完整AIMessage
一句话:流式展示 ≠ 流式写 state。把这两件事拆开做,系统最稳。
4)子图流式:subgraphs=True 是关键开关
当你的企业级 Agent 逐渐演进成"父图编排子图"的结构后,流式可观测性会变得更重要。
- 默认情况下,父图把子图当成一个整体节点,你很难看到子图内部每一步做了什么。
- 开启:
graph.stream(..., stream_mode="updates", subgraphs=True)
- 就能把子图内部节点的 updates 也流出来,排查问题时非常直观。
这点对"多 Agent 协作""工具链很长"的项目尤其重要:否则你只看到"子图节点执行了",看不到里面到底卡在哪一步。
5)一张表带走:生产环境怎么选(强烈建议收藏)
| 场景目标 | 推荐 stream_mode | 节点内部推荐写法 | 是否建议用 yield 更新 messages |
结论 |
|---|---|---|---|---|
| 调试业务流程 / 看节点改了哪些字段 | updates / values | 普通 return |
否 | 可观测性最好 |
| 聊天 UI 打字机效果(最常见) | messages | LLM 用 llm.stream(...),节点只 return 完整消息 |
否 | 体验好、state 干净 |
| 工具执行中提示 / 进度条 / 阶段播报 | custom(可叠加 updates) | writer("...") / writer({"delta": ...}) |
否 | 工程最友好 |
| 父图 + 子图需要"看见内部步骤" | updates + subgraphs=True | 子图内部保持可观测输出 | 不建议 | 排障效率提升 |
| 需要"边生成边落盘中间态"(少见) | custom / updates | 单独 buffer 字段保存进度 | 谨慎 | 成本高,非必要不做 |
6)最终落地建议(企业级项目的写法)
- UI 流式渲染 :优先吃
messages(LLM 输出)和custom(工具进度)。 - 对话历史:只保存"完整的一条 AIMessage",不要保存 token 碎片。
- 调试与观测 :开发期把
updates/debug打开,稳定后按需降级。 - 图复杂化后 :务必用
subgraphs=True把子图内部执行链路流出来,否则排查成本指数级上升。