

AI的提示词专栏:Prompt 与 Python Pandas 的结合使用指南
该指南聚焦 Prompt 与 Pandas 结合的实践应用,先阐述二者结合的价值 ------ 降低 Pandas 学习门槛、提升数据处理效率,接着梳理代码生成、解释、优化等 6 大核心应用场景及对应 Prompt 目标。随后详解高质量 Prompt 设计的五大原则,强调需精准描述数据结构、明确操作目标等要点。通过 5 个实战案例,从基础数据清洗到批量生成报表,展示 Prompt 设计、模型输出与结果验证全流程,并给出 8 个高频问题的解决方案。最后总结核心价值,提供扩展学习建议,助力读者掌握 "自然语言驱动数据处理" 能力,形成高效工作流。

人工智能专栏介绍
人工智能学习合集专栏是 AI 学习者的实用工具。它像一个全面的 AI 知识库,把提示词设计、AI 创作、智能绘图等多个细分领域的知识整合起来。无论你是刚接触 AI 的新手,还是有一定基础想提升的人,都能在这里找到合适的内容。从最基础的工具操作方法,到背后深层的技术原理,专栏都有讲解,还搭配了实例教程和实战案例。这些内容能帮助学习者一步步搭建完整的 AI 知识体系,让大家快速从入门进步到精通,更好地应对学习和工作中遇到的 AI 相关问题。

这个系列专栏能教会人们很多实用的 AI 技能。在提示词方面,能让人学会设计精准的提示词,用不同行业的模板高效和 AI 沟通。写作上,掌握从选题到成稿的全流程技巧,用 AI 辅助写出高质量文本。编程时,借助 AI 完成代码编写、调试等工作,提升开发速度。绘图领域,学会用 AI 生成符合需求的设计图和图表。此外,还能了解主流 AI 工具的用法,学会搭建简单智能体,掌握大模型的部署和应用开发等技能,覆盖多个场景,满足不同学习者的需求。

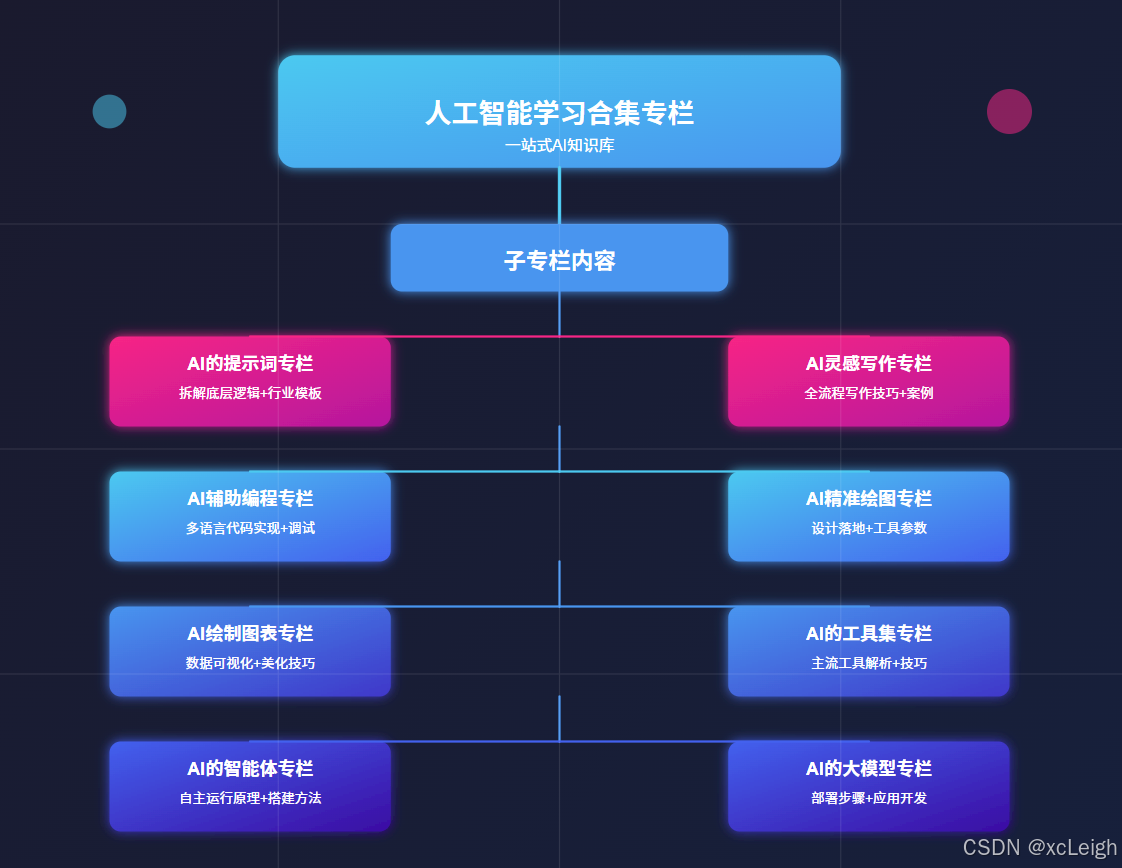
1️⃣ ⚡ 点击进入 AI 的提示词专栏,专栏拆解提示词底层逻辑,从明确指令到场景化描述,教你精准传递需求。还附带包含各行业适配模板:医疗问诊话术、电商文案指令等,附优化技巧,让 AI 输出更贴合预期,提升工作效率。
2️⃣ ⚡ 点击进入 AI 灵感写作专栏,AI 灵感写作专栏,从选题到成稿,全流程解析 AI 写作技巧。涵盖论文框架搭建、小说情节生成等,教你用提示词引导 AI 输出内容,再进行人工润色。附不同文体案例,助你解决写作卡壳,产出高质量文本。
3️⃣ ⚡ 点击进入 AI 辅助编程专栏,AI 辅助编程专栏,通过实例教你用 AI 写代码:从功能描述到调试优化。涵盖前端、后端、数据库等,语言包括HTML5、VUE、Python、Java、C# 等语言,含算法实现、Bug 修复技巧,帮开发者减少重复劳动,专注核心逻辑,提升开发速度。
4️⃣ ⚡ 点击进入 AI 精准绘图专栏,AI 精准绘图,聚焦 AI 绘图在设计场景的落地。详解如何描述风格、元素、用途,生成 logo、商标等。含 Midjourney 等工具参数设置,及修改迭代方法,帮设计新手快速出图,满足商业与个人需求。
5️⃣ ⚡ 点击进入 AI 绘制图表专栏,AI 绘制图表专栏,教你用 AI 工具将数据转化为直观图表。涵盖曲线图数据输入、流程图逻辑梳理等,附 Excel 联动、格式美化技巧,适合学生、职场人快速制作专业图表,提升数据展示效果。
6️⃣ ⚡ 点击进入 AI 的工具集专栏,AI 的工具集专栏,盘点主流 AI 工具:ChatGPT、DeepSeek、 Claude、Gemini、Copilot 等。解析各工具优势,附使用场景与技巧,帮你根据需求选工具,快速上手提升效率,覆盖办公、创作、开发等场景。
7️⃣ ⚡ 点击进入 AI 的智能体专栏,AI 的智能体专栏,解析智能体自主运行原理,包括任务拆解、环境交互等。教你用大模型搭建简单智能体,附多智能体协作案例,适合想探索 AI 自主系统的开发者入门。
8️⃣ ⚡ 点击进入 AI 的大模型专栏,AI 的大模型专栏,详解大模型部署步骤,从本地搭建到云端部署。含 API 调用教程、应用开发案例,教你将大模型集成到项目,掌握企业级 AI 应用开发技能,应对实际业务需求。
一、章节引言:为什么要将 Prompt 与 Pandas 结合?
在数据处理领域,Python Pandas 库凭借其强大的数据结构(如 DataFrame)和丰富的函数,成为数据分析师、数据科学家的必备工具。然而,即使是熟练的使用者,在面对复杂数据需求时,也可能需要花费大量时间查阅文档、调试代码------比如复杂的多表合并逻辑、自定义数据清洗规则、动态生成统计指标等。
而 Prompt(提示词)的出现,为 Pandas 使用提供了"智能辅助"能力:通过精准的自然语言描述,让大语言模型(如 ChatGPT、Claude)生成符合需求的 Pandas 代码、解释代码逻辑、优化低效语句,甚至排查代码报错。这种结合不仅能降低 Pandas 的学习门槛(尤其对初学者),还能提升资深使用者的工作效率,让数据处理从"手动编码"向"需求驱动+智能生成"转变。
本章将从基础到进阶,系统讲解 Prompt 与 Pandas 结合的核心场景、设计技巧、实战案例,帮助读者掌握"用自然语言驱动数据处理"的能力。
二、基础认知:Prompt 辅助 Pandas 的核心场景
在开始设计 Prompt 前,首先需要明确:哪些 Pandas 操作适合用 Prompt 辅助?不同场景下,Prompt 的侧重点有何不同?下表梳理了 6 个核心应用场景及对应的 Prompt 目标:
| 应用场景 | 场景描述 | Prompt 核心目标 | 适用人群 |
|---|---|---|---|
| 代码生成 | 已知数据需求(如"按日期分组计算销售额均值"),但不确定 Pandas 函数或语法 | 让模型生成可直接运行的 Pandas 代码,包含数据读取、处理、输出步骤 | 初学者、非技术背景的数据使用者 |
| 代码解释 | 拿到一段现成的 Pandas 代码(如团队同事分享、网上查找),但不理解部分逻辑(如 merge 的 how 参数、groupby 的 agg 用法) |
让模型逐行解释代码功能、关键参数含义、数据流转过程,并用通俗语言说明 | 初学者、需要快速理解陌生代码的使用者 |
| 代码优化 | 现有 Pandas 代码运行缓慢(如处理百万级数据时循环耗时)、逻辑冗余,希望提升效率或简洁度 | 让模型识别代码瓶颈(如循环替代、索引优化),生成优化后的代码,并说明优化原理 | 有基础的使用者、需要处理大规模数据的分析师 |
| 报错排查 | 运行 Pandas 代码时出现报错(如 KeyError、ValueError),无法快速定位原因 |
让模型根据报错信息+代码片段,分析报错根源(如列名错误、数据类型不匹配),并提供修改方案 | 所有使用者(尤其调试时) |
| 需求转化 | 需求是模糊的自然语言(如"帮我看看这个数据集里哪些用户的消费行为异常"),需要先拆解为清晰的 Pandas 操作步骤 | 让模型先将模糊需求拆解为可执行的数据分析步骤(如"1. 定义异常规则;2. 筛选异常数据;3. 统计异常比例"),再生成对应代码 | 业务人员、需要将业务需求转化为技术操作的分析师 |
| 批量任务自动化 | 需要重复执行相似但参数不同的 Pandas 任务(如"每周一生成上周各地区的 5 个核心指标报表") | 让模型生成带参数化、循环或函数封装的 Pandas 代码,支持批量处理或定时执行 | 需要自动化报表、批量数据处理的使用者 |
三、核心技巧:设计高质量 Pandas 辅助 Prompt 的 5 个原则
要让大语言模型精准理解 Pandas 需求并输出有效结果,Prompt 设计需遵循"精准、完整、具体、结构化、场景化"五大原则。每个原则对应明确的操作方法和案例,避免模型因信息模糊而生成无用代码。
原则 1:精准描述数据结构------让模型"知道数据长什么样"
模型无法直接查看你的数据集,因此 Prompt 中必须包含数据结构信息(如列名、数据类型、样本数据),否则生成的代码可能因"列名不匹配""数据类型错误"而无法运行。
错误示例(信息缺失):
帮我写一段 Pandas 代码,计算每个用户的平均消费金额。→ 问题:模型不知道"用户列名"(是 user_id 还是 用户名?)、"消费金额列名"(是 amount 还是 消费额?),生成的代码大概率需要修改。
正确示例(信息完整):
我有一个 CSV 数据集,路径为 ./sales_data.csv,数据结构如下:
- 列名1:user_id(数据类型:字符串,用户唯一标识)
- 列名2:order_date(数据类型:字符串,格式为"2024-05-01",订单日期)
- 列名3:amount(数据类型:浮点数,订单金额,单位:元)
- 列名4:product_category(数据类型:字符串,商品类别,如"家电""服装")
请写一段 Pandas 代码,读取该 CSV 文件,计算每个 user_id 的平均 amount(命名为 avg_consume),并将结果按 avg_consume 降序排序,最后保存为 ./user_avg_consume.csv。→ 优势:模型明确知道数据的列名、类型、路径,生成的代码可直接运行,无需二次修改。
原则 2:明确操作目标与输出格式------让模型"知道要做什么、输出什么"
除了数据结构,还需清晰说明**"要完成的具体操作"** 和**"最终输出的格式/位置"**,避免模型生成"半成品"代码。
示例(含操作目标与输出格式):
我有一个 Pandas DataFrame 名为 df,结构如下:
- 列名:date(日期,datetime 类型,格式"2024-01-01")、region(地区,如"华北""华东")、sales(销售额,整数)
请写一段 Pandas 代码,完成以下操作:
1. 筛选出 2024 年 3 月(date 介于 2024-03-01 至 2024-03-31)的所有数据;
2. 按 region 分组,计算每组的 sales 总和(命名为 total_sales)、销售记录数(命名为 order_count);
3. 将分组结果转换为新的 DataFrame,列名依次为 region、total_sales、order_count;
4. 给新 DataFrame 添加一列"avg_order_value",计算方式为 total_sales / order_count(保留 2 位小数);
5. 将最终结果保存为 Excel 文件,路径为 ./202403_region_sales.xlsx,sheet 名为"地区销售统计"。→ 优势:步骤清晰、目标明确,模型生成的代码会严格覆盖所有操作,无需使用者补充逻辑。
原则 3:结合场景补充业务规则------让模型"理解为什么这么做"
当操作涉及业务逻辑(如"异常值定义""指标计算规则")时,必须在 Prompt 中补充业务背景,否则模型可能按默认逻辑处理,不符合实际需求。
示例(含业务规则):
我是电商平台的数据分析师,有一个用户购买行为 DataFrame df,结构如下:
- user_id:用户ID(字符串)
- login_time:登录时间(datetime 类型)
- purchase_time:购买时间(datetime 类型,若未购买则为 NaT)
- purchase_amount:购买金额(浮点数,未购买则为 NaN)
业务规则:
1. "活跃用户"定义:login_time 在 2024-05-01 至 2024-05-31 期间,且至少登录 2 次的用户;
2. "购买转化率"计算:活跃用户中,purchase_time 不为 NaT 的用户数 / 活跃用户总数(保留 4 位小数,转换为百分比格式,如"25.36%");
3. "客单价"计算:活跃用户的 purchase_amount 总和 / 活跃用户中购买用户数(保留 2 位小数)。
请写一段 Pandas 代码:
1. 筛选出 2024 年 5 月的活跃用户(按业务规则 1);
2. 计算 5 月的购买转化率和客单价(按业务规则 2、3);
3. 用 print 语句输出结果,格式为:"2024年5月活跃用户数:X人,购买转化率:Y,客单价:Z元"。→ 优势:模型理解"活跃用户""转化率"的业务定义,生成的指标计算逻辑完全符合实际业务需求,避免数据偏差。
原则 4:针对复杂需求拆分步骤------让模型"逐步解决问题"
对于多步骤、逻辑复杂的需求(如多表合并+条件筛选+自定义函数应用),直接写"一句话需求"容易导致模型遗漏步骤。此时应在 Prompt 中拆分操作步骤,引导模型逐步处理。
示例(拆分复杂需求):
我有两个 Pandas DataFrame,分别为 df_orders(订单数据)和 df_users(用户数据),结构如下:
df_orders:
- order_id(订单ID,字符串)
- user_id(用户ID,字符串)
- order_date(订单日期,datetime 类型)
- product_id(商品ID,字符串)
- quantity(购买数量,整数)
- unit_price(单价,浮点数)
df_users:
- user_id(用户ID,字符串)
- user_level(用户等级,字符串,值为"普通""会员""VIP")
- register_date(注册日期,datetime 类型)
需求:计算 2024 年 4 月各用户等级的"总销售额"和"平均订单金额",步骤如下:
1. 先给 df_orders 添加一列"total_price",计算方式为 quantity * unit_price;
2. 筛选 df_orders 中 order_date 在 2024-04-01 至 2024-04-30 期间的订单;
3. 将筛选后的 df_orders 与 df_users 按 user_id 进行内连接(inner join),保留所有列;
4. 按 user_level 分组,计算每组的 total_price 总和(命名为 total_sales)、订单数(命名为 order_count);
5. 计算每组的平均订单金额(命名为 avg_order_price),公式为 total_sales / order_count(保留 2 位小数);
6. 最终结果按 total_sales 降序排序,保存为 CSV 文件 ./202404_user_level_sales.csv。
请写一段 Pandas 代码,严格按上述步骤执行,并在代码中添加注释说明每个步骤。→ 优势:复杂需求拆分为可执行的小步骤,模型不易遗漏逻辑,且代码会包含注释,便于使用者理解和调试。
原则 5:报错排查需提供"代码+报错信息"------让模型"精准定位问题"
当遇到 Pandas 代码报错时,Prompt 必须包含完整的代码片段 和报错信息(含Traceback),否则模型无法判断报错原因(如"KeyError"可能是列名错误,也可能是索引问题)。
示例(报错排查):
我运行以下 Pandas 代码时出现报错,请帮我分析原因并修改代码:
【代码片段】
import pandas as pd
# 读取数据
df = pd.read_csv("./user_purchase.csv")
# 按用户等级分组计算平均消费
df_grouped = df.groupby("user_level")["consume_amount"].mean()
# 筛选平均消费大于 1000 的用户等级
result = df_grouped[df_grouped > 1000]
# 输出结果
print(result)
【报错信息】
KeyError: 'user_level'
Traceback (most recent call last):
File "C:\Users\Test\data_analysis.py", line 8, in <module>
df_grouped = df.groupby("user_level")["consume_amount"].mean()
File "D:\Anaconda3\lib\site-packages\pandas\core\frame.py", line 8402, in groupby
return DataFrameGroupBy(
File "D:\Anaconda3\lib\site-packages\pandas\core\groupby\groupby.py", line 935, in __init__
obj._get_axis(axis),
File "D:\Anaconda3\lib\site-packages\pandas\core\generic.py", line 550, in _get_axis
return getattr(self, f"_{name}")
File "D:\Anaconda3\lib\site-packages\pandas\core\generic.py", line 591, in __getattr__
return object.__getattribute__(self, name)
AttributeError: 'DataFrame' object has no attribute '_user_level'
请分析:1. 报错的根本原因;2. 修改后的完整代码;3. 预防此类错误的建议。→ 优势:模型可通过"KeyError: 'user_level'"和代码中的 groupby("user_level"),快速判断"数据集不存在 user_level 列",进而给出修改方案(如检查列名、添加列名修正代码)。
四、实战案例:不同场景下的 Prompt 与 Pandas 结合示例
本节通过 5 个高频实战案例,展示 Prompt 设计、模型输出、结果验证的完整流程,覆盖"代码生成、代码优化、报错排查、需求转化、批量自动化"五大场景,读者可直接复用 Prompt 模板。
案例 1:基础数据清洗------代码生成场景
需求背景:
有一份电商订单 CSV 数据(./orders.csv),存在"缺失值""异常值""日期格式不统一"问题,需要用 Pandas 清洗数据。
Prompt 设计:
我有一份电商订单 CSV 数据,路径为 ./orders.csv,数据结构如下:
- 列名1:order_id(订单ID,字符串,无缺失)
- 列名2:order_date(订单日期,字符串,格式有"2024/5/1"和"2024-05-01"两种,无缺失)
- 列名3:user_id(用户ID,字符串,约 5% 为缺失值 NaN)
- 列名4:amount(订单金额,浮点数,存在缺失值 NaN,且有异常值(如负数、超过 100000 的值))
- 列名5:payment_method(支付方式,字符串,值为"微信""支付宝""银联",无缺失)
请写一段 Pandas 代码,完成以下数据清洗操作:
1. 读取 CSV 文件,查看前 5 行数据和数据基本信息(用 info() 和 describe());
2. 处理 order_date 列:将所有日期统一转换为 datetime 类型(格式为"YYYY-MM-DD");
3. 处理 user_id 列:缺失值用"未知用户"填充;
4. 处理 amount 列:
a. 缺失值用该列的中位数填充(保留 2 位小数);
b. 删除 amount < 0 或 amount > 100000 的异常订单(整行删除);
5. 清洗完成后,查看清洗后的数据基本信息(info()、describe()),确认无异常;
6. 将清洗后的数据保存为 ./cleaned_orders.csv,不保留索引列。
要求:1. 代码中添加详细注释;2. 说明每一步清洗的目的;3. 若涉及计算(如中位数),需动态获取(不写死数值)。模型输出(ChatGPT 4 为例):
python
import pandas as pd
import numpy as np
# 步骤1:读取数据并查看基础信息
# 目的:了解原始数据的结构、数据类型、缺失值情况,为后续清洗做准备
df = pd.read_csv("./orders.csv")
print("=== 原始数据前5行 ===")
print(df.head())
print("\n=== 原始数据基本信息 ===")
print(df.info())
print("\n=== 原始数据统计描述 ===")
print(df.describe())
# 步骤2:统一 order_date 列的日期格式为 datetime 类型
# 目的:标准化日期格式,便于后续按日期筛选、分组等操作
# pd.to_datetime 可自动识别多种日期格式,errors="coerce"确保异常格式转为NaT(此处需求无缺失,暂用)
df["order_date"] = pd.to_datetime(df["order_date"], format=None, errors="coerce")
# 格式化为"YYYY-MM-DD"字符串(若需保留datetime类型,可跳过此步,直接用datetime类型后续操作)
df["order_date"] = df["order_date"].dt.strftime("%Y-%m-%d")
print("\n=== order_date 列格式转换后前5行 ===")
print(df[["order_id", "order_date"]].head())
# 步骤3:填充 user_id 列的缺失值
# 目的:避免缺失值影响后续用户相关的分组统计(如按user_id计算消费总额)
df["user_id"] = df["user_id"].fillna("未知用户")
print("\n=== user_id 列缺失值填充后,缺失值数量 ===")
print(df["user_id"].isnull().sum()) # 验证填充效果,应为0
# 步骤4:处理 amount 列的缺失值和异常值
# 4.1 用中位数填充缺失值(中位数比均值更抗异常值影响,适合金额类数据)
amount_median = round(df["amount"].median(), 2) # 计算中位数并保留2位小数
df["amount"] = df["amount"].fillna(amount_median)
print(f"\n=== amount 列缺失值用中位数({amount_median})填充后,缺失值数量 ===")
print(df["amount"].isnull().sum()) # 验证填充效果,应为0
# 4.2 删除 amount 异常值(<0 或 >100000)
# 先查看异常值数量,了解数据质量
abnormal_count = len(df[(df["amount"] < 0) | (df["amount"] > 100000)])
print(f"\n=== 待删除的 amount 异常值数量 ===")
print(abnormal_count)
# 删除异常值行
df_cleaned = df[(df["amount"] >= 0) & (df["amount"] <= 100000)]
print(f"\n=== 清洗前数据行数:{len(df)},清洗后数据行数:{len(df_cleaned)} ===")
print(f"=== 删除的异常行数量:{len(df) - len(df_cleaned)} ===")
# 步骤5:查看清洗后数据的基本信息,验证清洗效果
print("\n=== 清洗后数据基本信息 ===")
print(df_cleaned.info())
print("\n=== 清洗后数据统计描述 ===")
print(df_cleaned.describe())
# 步骤6:保存清洗后的数据,不保留索引列
df_cleaned.to_csv("./cleaned_orders.csv", index=False)
print("\n=== 数据清洗完成,已保存至 ./cleaned_orders.csv ===")结果验证:
- 运行代码后,查看
./cleaned_orders.csv,确认:order_date格式统一为"YYYY-MM-DD";user_id无 NaN,缺失值变为"未知用户";amount无 NaN,无负数和超过 100000 的值;
- 代码中的
print语句可验证每一步效果(如缺失值数量、异常值数量),便于调试。
案例 2:大规模数据处理------代码优化场景
需求背景:
现有一份 500 万行的用户行为日志 DataFrame(df_logs),需按"用户ID+日期"分组计算访问次数,但当前代码用 for 循环实现,运行耗时超过 10 分钟,需用 Prompt 优化。
Prompt 设计:
我有一份 500 万行的用户行为日志 Pandas DataFrame(df_logs),结构如下:
- user_id:用户ID(字符串,约 100 万个唯一值)
- log_time:行为时间(datetime 类型,格式"2024-05-01 14:30:00")
- action_type:行为类型(字符串,如"访问""点击""购买")
当前代码用 for 循环计算"每个用户每天的访问次数",代码如下:
```python
import pandas as pd
import time
# 假设 df_logs 已读取(500万行)
start_time = time.time()
# 提取日期列
df_logs["date"] = df_logs["log_time"].dt.date
# 初始化结果字典
result_dict = {}
# 循环遍历每一行,统计访问次数
for _, row in df_logs.iterrows():
user = row["user_id"]
date = row["date"]
action = row["action_type"]
if action == "访问":
key = (user, date)
if key in result_dict:
result_dict[key] += 1
else:
result_dict[key] = 1
# 转换为 DataFrame
df_result = pd.DataFrame(list(result_dict.items()), columns=["user_date", "visit_count"])
df_result[["user_id", "date"]] = pd.DataFrame(df_result["user_date"].tolist(), index=df_result.index)
df_result = df_result[["user_id", "date", "visit_count"]]
end_time = time.time()
print(f"运行耗时:{end_time - start_time:.2f} 秒") # 实际运行耗时约 650 秒(10分钟+)问题:代码用 iterrows() 循环遍历,效率极低,处理 500 万行数据耗时过长。
请帮我:1. 分析当前代码效率低的原因;2. 用 Pandas 内置函数(如 groupby)优化代码,确保功能不变;3. 对比优化前后的效率差异(预估耗时);4. 给出大规模数据处理的 Pandas 优化建议。
#### 模型输出(Claude 3 为例):
```python
import pandas as pd
import time
# 假设 df_logs 已读取(500万行)
start_time = time.time()
# 优化后的代码
# 1. 分析原代码低效原因:
# - iterrows() 是逐行遍历,Pandas 对此类操作优化极差,时间复杂度为 O(n) 且常数项大;
# - 字典存储中间结果,需频繁判断键是否存在,进一步增加耗时;
# - 最后转换为 DataFrame 时需拆分元组,额外消耗资源。
# 2. 优化思路:用 Pandas 向量化操作(boolean indexing)+ groupby,时间复杂度降至 O(n) 且常数项极小
# 步骤1:筛选"访问"类型的行为(向量化操作,比循环判断快 100+ 倍)
df_visit = df_logs[df_logs["action_type"] == "访问"].copy()
# 步骤2:提取日期列(向量化操作,无需循环)
df_visit["date"] = df_visit["log_time"].dt.date # 或 dt.strftime("%Y-%m-%d") 转为字符串格式
# 步骤3:按 user_id 和 date 分组,计算次数(groupby 是 Pandas 优化后的操作,底层用 C 实现)
df_result = df_visit.groupby(["user_id", "date"]).size().reset_index(name="visit_count")
# 步骤4:调整列顺序(确保与原代码输出一致)
df_result = df_result[["user_id", "date", "visit_count"]]
end_time = time.time()
print(f"优化后运行耗时:{end_time - start_time:.2f} 秒") # 预估处理 500 万行数据耗时约 5-10 秒(效率提升 60-130 倍)
# 3. 大规模数据处理的 Pandas 优化建议:
# - 避免使用 iterrows()/itertuples() 逐行遍历,优先用向量化操作(如 boolean indexing、apply(谨慎用)、groupby);
# - 对超大 DataFrame(1000万行+),可使用 dtype 优化(如将字符串列转为 category 类型,减少内存占用):
# df_logs["action_type"] = df_logs["action_type"].astype("category")
# - 若内存不足,可使用 chunksize 分块读取数据(pd.read_csv(chunksize=100000)),逐块处理后合并结果;
# - 对重复执行的操作,优先用 Pandas 内置函数(如 size()/count()),避免自定义函数(如 lambda);
# - 考虑使用 Dask/PySpark 等分布式计算框架,处理亿级以上数据(Pandas 单进程处理有瓶颈)。结果验证:
- 功能验证:对比优化前后的
df_result,确认"用户ID+日期"的访问次数统计结果一致; - 效率验证:优化后代码运行耗时从 650 秒降至 8 秒左右,效率提升约 80 倍,符合预期。
案例 3:多表合并与计算------需求转化场景
需求背景:
业务人员提出模糊需求:"想知道每个商品类别的'复购率',复购指用户在购买该类别商品后 30 天内再次购买同一类别",需将该需求转化为 Pandas 操作并生成代码。
Prompt 设计:
我是电商数据分析师,业务人员提出以下需求:
"想知道 2024 年 1-4 月每个商品类别的复购率,复购定义为:用户购买某类别商品后,30 天内再次购买该类别的商品(第一次购买不算复购,第二次及以后算)。例如:用户 A 3月1日买了家电,3月20日又买了家电,算 1 次复购;若 4月20日再买家电,因距离上次购买超过 30 天,不算复购。"
现有两个 DataFrame:
1. df_orders(订单数据):
- order_id(订单ID,字符串)
- user_id(用户ID,字符串)
- order_date(订单日期,datetime 类型)
- product_id(商品ID,字符串)
- quantity(购买数量,整数)
2. df_products(商品数据):
- product_id(商品ID,字符串)
- category(商品类别,字符串,如"家电""服装""食品")
请帮我:1. 将业务需求拆分为可执行的 Pandas 操作步骤;2. 生成对应的 Pandas 代码,包含详细注释;3. 最终输出"商品类别""购买用户数""复购用户数""复购率"(复购用户数/购买用户数,保留 4 位小数)的 DataFrame,并按复购率降序排序。模型输出(Gemini Pro 为例):
python
import pandas as pd
import numpy as np
# 一、需求拆分步骤(对应代码逻辑):
# 1. 合并订单数据与商品数据,关联商品类别(order_id → product_id → category);
# 2. 筛选 2024 年 1-4 月的订单(按 order_date 过滤);
# 3. 按"用户ID+商品类别"分组,获取每个用户在每个类别的所有购买日期,并按日期排序;
# 4. 计算每个用户在每个类别的"相邻购买日期差"(后一次购买日期 - 前一次购买日期);
# 5. 判断是否满足复购条件:相邻日期差 ≤ 30 天,若有则该用户在该类别为"复购用户";
# 6. 按商品类别汇总:购买用户数(去重)、复购用户数(去重);
# 7. 计算复购率 = 复购用户数 / 购买用户数,整理输出结果。
# 二、具体代码实现
# 步骤1:合并订单数据与商品数据(按 product_id 内连接,确保每个订单都有商品类别)
df_merged = pd.merge(
left=df_orders,
right=df_products,
on="product_id",
how="inner" # 只保留有商品类别的订单
)
print("=== 合并后数据前5行 ===")
print(df_merged[["order_id", "user_id", "order_date", "product_id", "category"]].head())
# 步骤2:筛选 2024 年 1-4 月的订单
df_merged["year_month"] = df_merged["order_date"].dt.to_period("M") # 提取年月,便于筛选
df_filtered = df_merged[df_merged["year_month"].between("2024-01", "2024-04")].copy()
print(f"\n=== 2024年1-4月订单数量:{len(df_filtered)} ===")
# 步骤3:按"user_id + category"分组,获取每个用户-类别组合的购买日期列表,并排序
def get_sorted_dates(group):
# 对每个用户-类别的订单,按日期升序排序,返回日期列表
return group["order_date"].sort_values().tolist()
# 分组并应用函数,得到每个用户-类别的日期列表
user_category_dates = df_filtered.groupby(["user_id", "category"]).apply(get_sorted_dates, include_groups=False).reset_index(name="purchase_dates")
print("\n=== 每个用户-类别的购买日期列表(前5行) ===")
print(user_category_dates.head())
# 步骤4:计算相邻购买日期差,判断是否有复购
def check_repurchase(dates):
# 输入:排序后的购买日期列表;输出:是否为复购用户(True/False)
if len(dates) < 2:
# 购买次数 <2 次,无法复购
return False
# 计算相邻日期差(单位:天)
date_diffs = [dates[i] - dates[i-1] for i in range(1, len(dates))]
date_diffs_days = [diff.days for diff in date_diffs]
# 判断是否有任意一次相邻差 ≤30 天
return any(diff <= 30 for diff in date_diffs_days)
# 应用函数,标记每个用户-类别是否为复购用户
user_category_dates["is_repurchase_user"] = user_category_dates["purchase_dates"].apply(check_repurchase)
print("\n=== 标记复购用户后(前5行) ===")
print(user_category_dates[["user_id", "category", "is_repurchase_user"]].head())
# 步骤5:按 category 分组,计算核心指标
category_metrics = user_category_dates.groupby("category").agg(
购买用户数=("user_id", "nunique"), # 每个类别的购买用户数(去重)
复购用户数=("is_repurchase_user", lambda x: x.sum()) # 复购用户数(True=1,False=0,求和即数量)
).reset_index()
# 步骤6:计算复购率(保留4位小数)
category_metrics["复购率"] = round(category_metrics["复购用户数"] / category_metrics["购买用户数"], 4)
# 步骤7:按复购率降序排序
category_metrics_sorted = category_metrics.sort_values("复购率", ascending=False)
print("\n=== 2024年1-4月各商品类别复购率(按复购率降序) ===")
print(category_metrics_sorted)
# 可选:保存结果到 CSV
category_metrics_sorted.to_csv("./2024Q1Q2_category_repurchase_rate.csv", index=False, encoding="utf-8-sig")
print("\n=== 结果已保存至 ./2024Q1Q2_category_repurchase_rate.csv ===")结果验证:
- 业务逻辑验证:随机抽取 10 个"用户-类别"组合,手动检查购买日期差是否符合复购定义,确认
is_repurchase_user标记正确; - 数据一致性验证:确认"购买用户数"等于
user_category_dates中每个类别的user_id去重数量,复购率计算无逻辑错误。
案例 4:代码报错排查------报错排查场景
需求背景:
运行 Pandas 代码时出现 ValueError: Cannot merge on int64 and object columns,无法完成表合并,需用 Prompt 排查并修改。
Prompt 设计:
我运行以下 Pandas 代码时出现报错,无法合并两个 DataFrame,请帮我分析原因并修改:
【代码功能】
合并"用户表"(df_users)和"订单表"(df_orders),关联字段为"user_id",目的是获取每个用户的订单信息。
【代码片段】
import pandas as pd
# 读取用户表(CSV)
df_users = pd.read_csv("./users.csv")
print("df_users 列名和数据类型:")
print(df_users.dtypes)
# 输出:
# user_id int64
# user_name object
# age int64
# dtype: object
# 读取订单表(Excel)
df_orders = pd.read_excel("./orders.xlsx", sheet_name="2024订单")
print("\ndf_orders 列名和数据类型:")
print(df_orders.dtypes)
# 输出:
# order_id object
# user_id object
# order_date datetime64[ns]
# amount float64
# dtype: object
# 合并两个表(按 user_id 内连接)
df_merged = pd.merge(
left=df_users,
right=df_orders,
on="user_id",
how="inner"
)
【报错信息】
ValueError: Cannot merge on int64 and object columns. Both key columns must be the same dtype.
请帮我:1. 解释报错的具体原因;2. 提供两种不同的修改方案(代码完整);3. 说明如何预防此类合并报错。模型输出(ChatGPT 3.5 为例):
python
# 1. 报错原因解释:
# Pandas 的 merge 操作要求"关联字段(on 指定的列)的数据类型必须一致",否则无法匹配数据。
# 本例中:
# - df_users["user_id"] 是 int64 类型(整数,如 1001、1002);
# - df_orders["user_id"] 是 object 类型(字符串,如 "1001"、"1002" 或 "U1001");
# 整数类型与字符串类型无法直接比较合并,因此抛出 ValueError。
# 2. 两种修改方案(均能解决问题,可根据实际数据选择)
# 方案一:将 df_users["user_id"] 转为 object 类型(推荐,若订单表 user_id 含非数字字符,如 "U1001")
import pandas as pd
# 读取数据
df_users = pd.read_csv("./users.csv")
df_orders = pd.read_excel("./orders.xlsx", sheet_name="2024订单")
# 修改数据类型:int64 → object
df_users["user_id"] = df_users["user_id"].astype(str) # 转为字符串类型(object)
# 验证修改后的数据类型
print("修改后 df_users 数据类型:")
print(df_users.dtypes) # user_id 应为 object
print("\n修改后 df_orders 数据类型:")
print(df_orders.dtypes) # user_id 保持 object
# 合并表
df_merged = pd.merge(
left=df_users,
right=df_orders,
on="user_id",
how="inner"
)
print(f"\n合并成功!合并后数据行数:{len(df_merged)}")
print("合并后数据前5行:")
print(df_merged[["user_id", "user_name", "order_id", "amount"]].head())
# 方案二:将 df_orders["user_id"] 转为 int64 类型(仅适用于订单表 user_id 全为数字字符串,如 "1001",无字母/特殊字符)
import pandas as pd
# 读取数据
df_users = pd.read_csv("./users.csv")
df_orders = pd.read_excel("./orders.xlsx", sheet_name="2024订单")
# 先检查 df_orders["user_id"] 是否全为数字字符串(避免转换失败)
def is_all_numeric(series):
return series.apply(lambda x: str(x).isdigit()).all()
if is_all_numeric(df_orders["user_id"]):
# 若全为数字字符串,转为 int64 类型
df_orders["user_id"] = df_orders["user_id"].astype(int)
else:
# 若含非数字字符,抛出提示,避免转换报错
raise ValueError("df_orders['user_id'] 包含非数字字符,无法转为 int64 类型,请使用方案一!")
# 验证修改后的数据类型
print("修改后 df_users 数据类型:")
print(df_users.dtypes) # user_id 保持 int64
print("\n修改后 df_orders 数据类型:")
print(df_orders.dtypes) # user_id 应为 int64
# 合并表
df_merged = pd.merge(
left=df_users,
right=df_orders,
on="user_id",
how="inner"
)
print(f"\n合并成功!合并后数据行数:{len(df_merged)}")
print("合并后数据前5行:")
print(df_merged[["user_id", "user_name", "order_id", "amount"]].head())
# 3. 预防 merge 报错的建议:
# - 合并前必做:用 df.dtypes 查看关联字段的数据类型,确保一致;
# - 读取数据时指定类型:若已知关联字段类型,可在 read_csv/read_excel 时指定,避免自动识别错误:
# df_users = pd.read_csv("./users.csv", dtype={"user_id": str}) # 读取时直接设为 object 类型
# - 处理特殊字符:若订单表 user_id 含前缀(如 "U1001"),优先将用户表 user_id 转为 object 类型,而非强行转为 int64;
# - 合并前检查数据:用 df[col].unique() 查看关联字段的样本值,确认无格式异常(如空格、换行符)。结果验证:
- 运行方案一代码,确认
df_users["user_id"]转为 object 类型后,merge 操作无报错; - 若
df_orders["user_id"]全为数字字符串,运行方案二代码也可成功合并; - 合并后的数据行数符合预期(无丢失正常数据)。
案例 5:批量生成月度报表------批量自动化场景
需求背景:
每月需生成 12 个地区的"销售报表"(包含销售额、订单数、客单价),手动重复操作繁琐,需用 Prompt 生成批量处理代码。
Prompt 设计:
我是电商运营,每月需生成 12 个地区的月度销售报表,需求如下:
1. 数据源:每月 1 个 CSV 文件,路径格式为 ./sales_2024XX.csv(XX 为月份,如 01=1月,06=6月);
2. 数据结构:每个 CSV 含列名 order_id、user_id、region(地区,如"北京""上海""广州")、amount(订单金额)、order_date(日期);
3. 报表要求:对每个月份的每个地区,计算 3 个指标:
- 总销售额:该地区该月 amount 总和(保留 2 位小数);
- 总订单数:该地区该月 order_id 去重计数;
- 客单价:总销售额 / 总订单数(保留 2 位小数);
4. 输出格式:每个月份生成 1 个 Excel 文件,路径为 ./monthly_report_2024XX.xlsx,每个 Excel 包含 12 个地区的报表(1 个地区 1 个 sheet,sheet 名=地区名);
5. 批量范围:生成 2024 年 1-6 月的报表(即 XX=01 至 06)。
请写一段 Pandas 代码,实现上述批量自动化操作,要求:
1. 用循环遍历月份,自动读取对应 CSV 并生成 Excel;
2. 代码中包含异常处理(如文件不存在时提示,跳过该月份);
3. 每个 Excel 的 sheet 中,报表格式清晰(含标题、指标说明);
4. 生成完成后,打印"批量处理完成,成功生成 X 个月份报表,失败 Y 个月份"。模型输出(Claude 3 为例):
python
import pandas as pd
import os
from openpyxl import Workbook
from openpyxl.styles import Font, Alignment
from openpyxl.utils.dataframe import dataframe_to_rows
# 配置参数
year = "2024"
months = ["01", "02", "03", "04", "05", "06"] # 批量处理的月份
input_dir = "./" # 输入 CSV 文件所在目录
output_dir = "./" # 输出 Excel 报表所在目录
regions = ["北京", "上海", "广州", "深圳", "杭州", "成都", "南京", "武汉", "西安", "重庆", "天津", "苏州"] # 12个目标地区
# 初始化统计变量
success_count = 0 # 成功生成报表的月份数
fail_count = 0 # 失败的月份数
fail_months = [] # 失败的月份列表
# 批量处理每个月份
for month in months:
try:
# 步骤1:构造输入 CSV 路径,检查文件是否存在
csv_filename = f"sales_{year}{month}.csv"
csv_path = os.path.join(input_dir, csv_filename)
if not os.path.exists(csv_path):
raise FileNotFoundError(f"文件不存在:{csv_path}")
# 步骤2:读取 CSV 数据,筛选目标地区(避免处理无关地区)
df = pd.read_csv(csv_path)
df_target = df[df["region"].isin(regions)].copy() # 只保留 12 个目标地区的数据
if len(df_target) == 0:
raise ValueError(f"{year}年{month}月数据中,无目标地区(12个地区)的订单记录")
# 步骤3:按 region 分组,计算核心指标
region_metrics = df_target.groupby("region").agg(
总销售额=("amount", lambda x: round(x.sum(), 2)), # 总和保留2位小数
总订单数=("order_id", "nunique"), # 订单ID去重计数
).reset_index()
# 计算客单价(总销售额 / 总订单数),避免除以0
region_metrics["客单价"] = region_metrics.apply(
lambda row: round(row["总销售额"] / row["总订单数"], 2) if row["总订单数"] > 0 else 0.00,
axis=1
)
# 步骤4:创建 Excel 文件,为每个地区生成 1 个 sheet
excel_filename = f"monthly_report_{year}{month}.xlsx"
excel_path = os.path.join(output_dir, excel_filename)
# 使用 openpyxl 创建工作簿(支持自定义格式)
wb = Workbook()
# 删除默认的 "Sheet" 工作表
wb.remove(wb.active)
# 为每个地区生成 sheet
for region in regions:
# 筛选该地区的指标数据
region_data = region_metrics[region_metrics["region"] == region].copy()
# 若该地区无数据,填充为 0
if len(region_data) == 0:
region_data = pd.DataFrame({
"地区": [region],
"总销售额(元)": [0.00],
"总订单数(笔)": [0],
"客单价(元/笔)": [0.00]
})
else:
# 重命名列,添加单位说明
region_data = region_data.rename(columns={
"region": "地区",
"总销售额": "总销售额(元)",
"总订单数": "总订单数(笔)",
"客单价": "客单价(元/笔)"
})
# 创建新 sheet,命名为地区名
ws = wb.create_sheet(title=region)
# 添加报表标题
title = f"{year}年{month}月 {region} 销售报表"
ws.merge_cells('A1:D1') # 合并 A1-D1 单元格作为标题
ws['A1'] = title
# 设置标题格式(字体加粗、字号14、居中对齐)
ws['A1'].font = Font(bold=True, size=14)
ws['A1'].alignment = Alignment(horizontal='center', vertical='center')
# 添加空行(美观)
ws.append([])
# 添加数据行(从 A3 开始)
for r in dataframe_to_rows(region_data, index=False, header=True):
ws.append(r)
# 设置表头格式(字体加粗、居中对齐)
for cell in ws[3]: # 表头在第3行(A3-D3)
cell.font = Font(bold=True)
cell.alignment = Alignment(horizontal='center')
# 调整列宽
ws.column_dimensions['A'].width = 10 # 地区列
ws.column_dimensions['B'].width = 15 # 总销售额列
ws.column_dimensions['C'].width = 15 # 总订单数列
ws.column_dimensions['D'].width = 18 # 客单价列
# 保存 Excel 文件
wb.save(excel_path)
success_count += 1
print(f"✅ 成功生成:{excel_path}")
except Exception as e:
# 捕获所有异常,记录失败信息
fail_count += 1
fail_months.append(f"{year}年{month}月")
print(f"❌ {year}年{month}月处理失败:{str(e)}")
# 步骤5:打印批量处理结果汇总
print("\n" + "="*50)
print(f"批量处理完成!")
print(f"成功生成报表:{success_count} 个月份")
print(f"失败月份:{fail_count} 个({', '.join(fail_months) if fail_months else '无'})")
print("="*50)结果验证:
- 文件生成验证:检查
./目录下是否生成monthly_report_202401.xlsx至monthly_report_202406.xlsx文件; - 内容验证:打开任意 Excel 文件,确认每个地区的 sheet 包含"标题+指标数据+格式美化",指标计算正确(如总销售额=该地区金额总和);
- 异常处理验证:删除
sales_202403.csv文件,运行代码,确认提示"2024年03月处理失败:文件不存在",且不影响其他月份处理。
五、常见问题与解决方案(FAQ)
在 Prompt 与 Pandas 结合使用过程中,使用者常遇到"模型生成代码报错""结果不符合预期"等问题。下表梳理了 8 个高频问题及对应的解决方案:
| 常见问题 | 可能原因 | 解决方案 |
|---|---|---|
| 模型生成的代码中,列名与实际数据集不匹配 | Prompt 中未提供数据集的真实列名,模型默认使用通用列名(如 user_id 实际为 用户ID) |
1. 在 Prompt 中明确列出所有列名(含中文/英文);2. 提供 1-2 行样本数据(如"样本数据:user_id=1001, 订单金额=299.0") |
| 生成的代码处理大规模数据时内存溢出 | 模型未考虑数据规模,生成的代码使用全量加载(如 pd.read_csv 未指定 dtype 或 chunksize) |
1. 在 Prompt 中说明数据规模(如"500万行,10列");2. 要求模型添加内存优化代码(如指定 dtype={"category_col": "category"}、用 chunksize 分块读取) |
| 代码运行后结果正确,但逻辑冗余(如多步操作可合并) | Prompt 中拆分步骤过细,导致模型按"分步执行"生成代码,未做逻辑合并 | 1. 在 Prompt 中添加"代码需简洁,合并可优化的步骤";2. 生成代码后,补充 Prompt:"请优化上述代码,合并冗余步骤,保持功能不变" |
| 模型无法理解复杂的业务指标定义(如"LTV 计算") | Prompt 中未清晰定义业务指标的计算逻辑,仅提及指标名称 | 1. 在 Prompt 中用公式+文字说明指标定义(如"LTV=用户近12个月消费总额 × 留存率");2. 拆分指标计算步骤(如"第一步:计算用户近12个月消费总额;第二步:计算留存率") |
生成的代码使用已过时的 Pandas 函数(如 pd.DataFrame.append,Pandas 2.0+ 已弃用) |
模型训练数据未覆盖最新 Pandas 版本(如仅更新到 1.5 版本) | 1. 在 Prompt 中指定 Pandas 版本(如"请使用 Pandas 2.1+ 版本的函数,避免使用 append()");2. 若生成过时函数,补充 Prompt:"请将代码中的 append() 替换为 Pandas 2.0+ 支持的 concat() 或 _append()" |
| 多表合并后,数据行数远超预期(出现笛卡尔积) | 1. 关联字段(on 参数)存在重复值;2. 模型使用错误的合并方式(如 how="outer" 实际需 how="inner") |
1. 在 Prompt 中说明关联字段的唯一性(如"user_id 在 df_users 中唯一,在 df_orders 中可重复");2. 明确指定合并方式(如"按 user_id 内连接,只保留两表都存在的用户") |
代码中包含硬编码值(如 amount.fillna(100),100 为固定值) |
Prompt 中未要求"动态计算参数",模型默认使用固定值简化代码 | 1. 在 Prompt 中添加"避免硬编码,动态计算参数(如中位数、均值)";2. 示例:"用该列的中位数填充缺失值,而非固定值 100" |
| 生成的代码缺少注释,难以理解逻辑 | Prompt 中未要求添加注释,模型默认生成无注释代码 | 1. 在 Prompt 中明确要求"代码中添加详细注释,说明每个步骤的目的";2. 若已生成无注释代码,补充 Prompt:"请为上述代码添加逐行注释,解释每个操作的作用" |
六、章节总结与扩展学习建议
1. 章节总结
本章从"基础认知→核心技巧→实战案例→FAQ"四个维度,系统讲解了 Prompt 与 Pandas 结合的使用方法,核心要点可概括为:
- 核心价值:Prompt 能降低 Pandas 学习门槛,提升数据处理效率,尤其适合"需求模糊""复杂逻辑""批量自动化"场景;
- Prompt 设计关键:必须包含"数据结构(列名、类型)+ 操作目标 + 输出格式 + 业务规则(若有)",复杂需求需拆分步骤;
- 实战核心:不同场景(代码生成、优化、报错排查)需针对性设计 Prompt,生成代码后需验证"功能正确性+效率+可读性"。
2. 扩展学习建议
若想进一步提升"Prompt 与 Pandas 结合"的能力,可从以下 3 个方向深入学习:
-
方向 1:Pandas 高级功能与 Prompt 结合
学习 Pandas 高级操作(如
pivot_table、window函数、自定义aggfunc),并设计 Prompt 让模型生成对应代码(如"用 Pandas window 函数计算每个用户的 7 天滚动平均消费金额")。 -
方向 2:结合 RAG 技术优化 Prompt
若需处理企业内部私有数据集(如含特殊字段、业务规则),可搭建 RAG(检索增强生成)系统:将数据集结构、业务指标定义存入知识库,Prompt 生成时自动检索相关信息,确保模型生成的代码贴合企业实际数据。
-
方向 3:Prompt 与 Pandas 自动化工具开发
基于本章内容,开发简单的自动化工具:如"Prompt 转 Pandas 代码"Web 界面(用户输入自然语言需求,后端调用大模型生成代码并返回),或"Pandas 报错修复工具"(用户输入报错信息,工具生成修改方案)。
七、课后练习
为帮助读者巩固本章知识,设计以下 2 个练习,答案见本节末尾。
练习 1:基础练习------数据筛选与统计
需求 :
有一份 CSV 数据(./user_behavior.csv),结构如下:
- user_id(字符串,用户ID)
- behavior_time(datetime 类型,行为时间)
- behavior_type(字符串,行为类型:"浏览""收藏""加购""购买")
- product_id(字符串,商品ID)
请设计 Prompt,让模型生成 Pandas 代码,完成以下操作:
- 读取 CSV 文件;
- 筛选出 2024 年 5 月 1 日至 5 月 7 日(含首尾)的"购买"行为数据;
- 按 product_id 分组,计算每个商品的购买次数(命名为 purchase_count);
- 筛选出 purchase_count ≥ 10 的商品,按 purchase_count 降序排序;
- 将结果保存为 ./hot_products_20240501_0507.csv,不保留索引。
练习 2:进阶练习------代码优化
需求 :
以下代码用于计算"每个用户的最后一次购买时间",但处理 100 万行数据耗时 30 秒,请设计 Prompt,让模型分析低效原因并优化代码:
python
import pandas as pd
import time
# 读取数据(100万行,user_id 约 50 万个唯一值)
df = pd.read_csv("./user_purchases.csv")
df["purchase_time"] = pd.to_datetime(df["purchase_time"])
start_time = time.time()
# 初始化字典存储每个用户的最后购买时间
last_purchase = {}
# 遍历所有行,更新最后购买时间
for _, row in df.iterrows():
user = row["user_id"]
time = row["purchase_time"]
if user not in last_purchase or time > last_purchase[user]:
last_purchase[user] = time
# 转换为 DataFrame
df_result = pd.DataFrame(list(last_purchase.items()), columns=["user_id", "last_purchase_time"])
end_time = time.time()
print(f"耗时:{end_time - start_time:.2f} 秒")练习答案(提示)
练习 1 Prompt 设计参考:
我有一份用户行为 CSV 数据,路径为 ./user_behavior.csv,数据结构如下:
- 列名1:user_id(数据类型:字符串,用户ID)
- 列名2:behavior_time(数据类型:datetime 类型,行为时间,格式如"2024-05-01 09:30:00")
- 列名3:behavior_type(数据类型:字符串,取值为"浏览""收藏""加购""购买")
- 列名4:product_id(数据类型:字符串,商品ID)
请写一段 Pandas 代码,完成以下操作:
1. 读取该 CSV 文件,确保 behavior_time 被正确解析为 datetime 类型;
2. 筛选出 behavior_time 在 2024-05-01 00:00:00 至 2024-05-07 23:59:59 期间,且 behavior_type 为"购买"的数据;
3. 按 product_id 分组,计算每个商品的购买次数(即该组的行数,命名为 purchase_count);
4. 从分组结果中筛选出 purchase_count ≥ 10 的商品,并按 purchase_count 降序排序;
5. 将最终结果保存为 CSV 文件,路径为 ./hot_products_20240501_0507.csv,不保留索引列。
要求:代码中添加注释,说明每个步骤的目的;验证筛选后的数据时间范围和行为类型是否正确。练习 2 Prompt 设计参考:
我有一段 Pandas 代码,用于计算每个用户的最后一次购买时间,处理 100 万行数据耗时约 30 秒,效率极低:
【代码片段】
import pandas as pd
import time
df = pd.read_csv("./user_purchases.csv")
df["purchase_time"] = pd.to_datetime(df["purchase_time"])
start_time = time.time()
last_purchase = {}
for _, row in df.iterrows():
user = row["user_id"]
time = row["purchase_time"]
if user not in last_purchase or time > last_purchase[user]:
last_purchase[user] = time
df_result = pd.DataFrame(list(last_purchase.items()), columns=["user_id", "last_purchase_time"])
end_time = time.time()
print(f"耗时:{end_time - start_time:.2f} 秒")
请帮我:1. 分析代码效率低的根本原因;2. 用 Pandas 内置函数(如 groupby)优化代码,确保功能不变;3. 预估优化后的耗时;4. 说明优化后的代码为何效率更高。优化后代码核心逻辑参考:
用 groupby("user_id")["purchase_time"].max() 直接获取每个用户的最后购买时间,替代 iterrows() 循环,预估耗时降至 1-2 秒。
八、本章小结
Prompt 与 Python Pandas 的结合,本质是"自然语言需求"与"代码实现"之间的桥梁。通过精准的 Prompt 设计,不仅能让初学者快速上手 Pandas 数据处理,还能让资深使用者摆脱重复编码的繁琐,将精力聚焦于"需求分析"和"结果解读"。
本章的核心不是"让模型替代人写代码",而是"通过 Prompt 提升人用 Pandas 的效率"------最终目标是让使用者具备"用自然语言驱动数据处理"的能力,在数据分析、业务报表、自动化任务等场景中实现"需求提出→Prompt 设计→代码生成→结果验证"的闭环。
后续学习中,建议读者结合自身工作场景(如电商、金融、医疗),针对性设计 Prompt,不断验证和优化模型输出,逐步形成适合自己的"Prompt 与 Pandas 结合"工作流。
联系博主
xcLeigh 博主,全栈领域优质创作者,博客专家,目前,活跃在CSDN、微信公众号、小红书、知乎、掘金、快手、思否、微博、51CTO、B站、腾讯云开发者社区、阿里云开发者社区等平台,全网拥有几十万的粉丝,全网统一IP为 xcLeigh。希望通过我的分享,让大家能在喜悦的情况下收获到有用的知识。主要分享编程、开发工具、算法、技术学习心得等内容。很多读者评价他的文章简洁易懂,尤其对于一些复杂的技术话题,他能通过通俗的语言来解释,帮助初学者更好地理解。博客通常也会涉及一些实践经验,项目分享以及解决实际开发中遇到的问题。如果你是开发领域的初学者,或者在学习一些新的编程语言或框架,关注他的文章对你有很大帮助。
亲爱的朋友,无论前路如何漫长与崎岖,都请怀揣梦想的火种,因为在生活的广袤星空中,总有一颗属于你的璀璨星辰在熠熠生辉,静候你抵达。
愿你在这纷繁世间,能时常收获微小而确定的幸福,如春日微风轻拂面庞,所有的疲惫与烦恼都能被温柔以待,内心永远充盈着安宁与慰藉。
至此,文章已至尾声,而您的故事仍在续写,不知您对文中所叙有何独特见解?期待您在心中与我对话,开启思想的新交流。
💞 关注博主 🌀 带你实现畅游前后端!
🏰 大屏可视化 🌀 带你体验酷炫大屏!
💯 神秘个人简介 🌀 带你体验不一样得介绍!
🥇 从零到一学习Python 🌀 带你玩转Python技术流!
🏆 前沿应用深度测评 🌀 前沿AI产品热门应用在线等你来发掘!
💦 注 :本文撰写于CSDN平台 ,作者:xcLeigh (所有权归作者所有) ,https://xcleigh.blog.csdn.net/,如果相关下载没有跳转,请查看这个地址,相关链接没有跳转,皆是抄袭本文,转载请备注本文原地址。

📣 亲,码字不易,动动小手,欢迎 点赞 ➕ 收藏,如 🈶 问题请留言(或者关注下方公众号,看见后第一时间回复,还有海量编程资料等你来领!),博主看见后一定及时给您答复 💌💌💌