目录
[2.1. 局部 TMR (Local TMR)](#2.1. 局部 TMR (Local TMR))
[2.2. 分布式 TMR (Distributed TMR)](#2.2. 分布式 TMR (Distributed TMR))
[2.3. 全局 TMR (Global TMR)](#2.3. 全局 TMR (Global TMR))
[3.1. 常见的各项指标含义](#3.1. 常见的各项指标含义)
1.三模冗余简介
三模冗余(Triple Modular Redundancy, 简称 TMR )是数字逻辑设计(尤其是航空航天、核工业等高可靠性领域)中一种经典的容错设计技术 。它的核心思想非常简单:"所有事情做三遍,出问题少数服从多数"。通过引入 200% 的硬件冗余(即总共 3 倍的资源),来换取系统在遇到"单粒子翻转(SEU)"或其他硬件故障时的极高可靠性。如果其中一路逻辑出错,另外两路正确的结果会通过"表决器"修正输出。
2.常见的三模冗余模式
2.1. 局部 TMR (Local TMR)
定义: 一份组合逻辑 -> 三份时序单元 (FF) -> 表决器
工作原理:
电路的运算逻辑(组合逻辑)只保留一份。
但是在数据需要保存(写入寄存器/触发器)时,数据被同时写入到 3 个并行的触发器中。
在触发器的输出端,通过一个表决器读取这 3 个值,输出"多数票"的结果。
优点:
- 节省面积: 因为庞大的组合逻辑云没有被复制,只复制了寄存器,资源消耗相对较小。
缺点/风险:
- 防不住组合逻辑错误: 如果前面的那"一份"组合逻辑本身受到了干扰(比如粒子撞击导致与门翻转),那么错误的信号会同时传给 3 个触发器,表决器也就失效了(因为 3 票都是错的)。
适用场景: 主要用于保护状态机(FSM)的状态寄存器,防止状态跑飞。
2.2. 分布式 TMR (Distributed TMR)
定义: 三份组合逻辑 + 三份时序单元 + 表决器
工作原理:
这是最标准的 TMR 形式。从输入端开始,整个数据通路被完全复制成三份(Domain A, Domain B, Domain C)。
每一路都有自己独立的运算逻辑和寄存器。
表决器位置: 通常放在下一级逻辑的输入端,或者反馈回路中。这意味着即使某一路的组合逻辑算错了,或者某一路的触发器翻转了,另外两路正常的逻辑流依然能保证数据正确。
优点:
- 极高的逻辑可靠性: 能够修正组合逻辑产生的瞬态脉冲(SET)和触发器的翻转(SEU)。
缺点:
- 资源消耗大: 逻辑资源(LUT)和寄存器(FF)都需要原来的 3 倍以上(加上表决器)。
注意: 它通常共享同一个全局时钟树。
2.3. 全局 TMR (Global TMR)
定义: 三份组合逻辑 + 三份时序单元 + 三份全局时钟 + 表决器
工作原理:
这是"分布式 TMR"的加强版。
在分布式 TMR 中,如果那根唯一的"全局时钟线"或者"复位线"受到干扰,三路逻辑可能同时挂掉。
全局 TMR 彻底隔离了三个域(Domain),每个域使用"独立的时钟缓冲器(BUFG)"和复位网络。
优点:
- 终极可靠性: 消除了一切"单点故障"(Single Point of Failure)。即使某个时钟树部分损坏,另外两个域依然能正常工作。
缺点:
极其昂贵: FPGA 的全局时钟资源(Global Clock Buffers)非常宝贵且有限,这种方式会消耗大量时钟资源。
时序收敛困难: 处理三个时钟域的对齐和表决器的时序非常复杂。
2.4总结与对比
| 特性 | 局部 TMR | 分布式 TMR | 全局 TMR |
|---|---|---|---|
| 主要保护对象 | 寄存器/状态 (SEU) | 整个数据通路 (SEU + SET) | 整个芯片架构 (含时钟/复位) |
| 资源消耗 (面积) | 低 (1.x 倍) | 高 (>3 倍) | 极高 (>3 倍 + 时钟资源) |
| 抗辐照能力 | 弱 | 强 | 最强 |
| 对时序的影响 | 小 | 中 (表决器引入延时) | 大 (布线拥塞 + 逻辑级数增加) |
特别提示:
引入 TMR(特别是加了表决器 Voter 之后),会在数据路径上插入额外的组合逻辑(多数表决逻辑:)。这会增加路径延时,恶化 Setup/Hold 时序。如果你在做抗辐照设计,加上 TMR 后,你之前遇到的时序违例可能会更加严重,需要更小心的约束和优化。
3.全局TMR前后资源消耗量对比
3.1. 常见的各项指标含义
-
LUT (Look-Up Table, 查找表)
- 功能:实现组合逻辑(如加法、逻辑运算等)的核心单元。
-
FF (Flip-Flop, 触发器)
- 功能:实现时序逻辑(寄存器、存储状态)的单元。
-
IO (Input/Output, 引脚)
- 功能:芯片实际与外部电路连接的物理引脚。
-
BUFG (Global Buffer, 全局时钟缓冲器)
- 功能:用于驱动芯片内部全局时钟网络的资源,确保时钟信号同步。
3.2资源消耗量对比
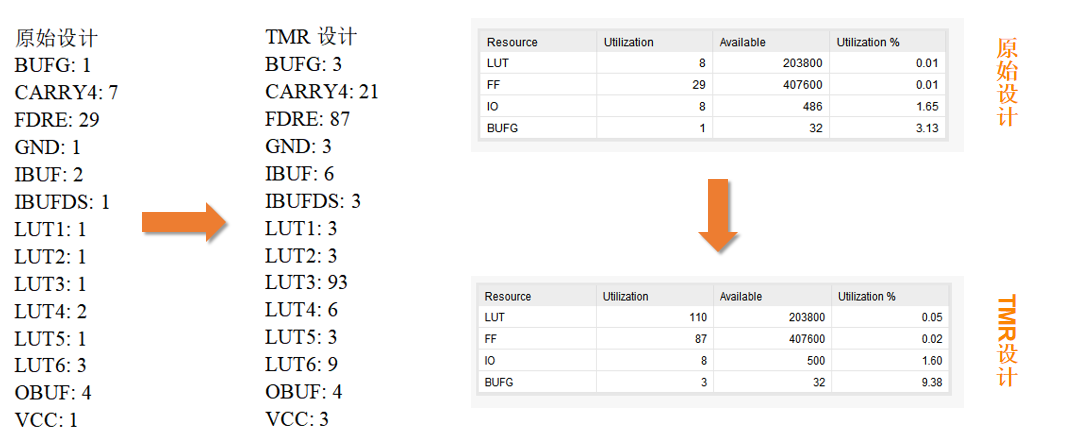
进行全局 TMR(三模冗余) 后,资源占用(LUT)并不是简单的 3 倍关系,从资源利用率图表中可以发现,LUT 的增幅达到了约 13.75 倍 (110 vs 8),而 FF(触发器)和 BUFG(全局时钟缓冲器)则严格遵循了 3 倍 关系(87 vs 29,3 vs 1)。
出现这种情况,主要由以下几个核心原因导致:
(1) 投票器(Voter)的额外开销
TMR 的核心不仅仅是把逻辑复制三份,最关键的是引入了多数表决逻辑(Majority Voters)。
-
同步要求:在 Global TMR 中,为了防止三套逻辑因单点故障产生失步,工具会在每一个寄存器(FF)的反馈路径上插入投票器。
-
三倍投票器 :为了避免"投票器本身"成为单点故障,Xilinx 的 TMR 技术通常会三倍化投票器(即每个原始 FF 对应 3 个投票器)。
-
资源占用推算:一个多数表决器通常占用 1 个 LUT。
-
工程 B 有 29 个 FF。
-
在 TMR 后,这 29 个 FF 对应的投票逻辑就会消耗约
个 LUT。
-
原始逻辑
-
 。
。 -
这与你图中显示的 110 个 LUT 几乎完全吻合。
-
(2). 逻辑优化受限
在没有 TMR 的普通工程中,Vivado 的综合工具(Synthesis)会进行大量的逻辑优化(如逻辑合并、常数传播等),将简单的逻辑压缩到极少的 LUT 中(你的 baseline 仅用了 8 个 LUT,说明逻辑非常简单)。
一旦开启 Global TMR,工具必须强制维持三套逻辑的物理隔离,许多跨模块的优化被禁止,导致逻辑无法像之前那样被高效压缩。
总结分析表
| 资源类型 | 工程 B (Baseline) | 工程 A (TMR) | 倍数关系 | 解释 |
|---|---|---|---|---|
| FF (触发器) | 29 | 87 | 正好 3x | 寄存器是严格按位三倍复制的。 |
| BUFG (时钟) | 1 | 3 | 正好 3x | 时钟网络也进行了三倍冗余,以防止时钟域故障。 |
| LUT (查找表) | 8 | 110 | 约 13.7x | 冗余逻辑(3x) + 投票器逻辑(大头)。 |
结论 :在逻辑非常小的工程中(如你的 Baseline 仅 8 个 LUT),投票器的固定开销会占据主导地位,使得 LUT 的增加倍数远超 3 倍。随着你的设计规模增大,逻辑本身的占比提高,这个比例会逐渐向 3 到 4 倍靠拢。
以上就是本次笔记的内容。