【论文阅读】π0.5: a Vision-Language-Action Model with Open-World Generalization
- [1 发表时间与团队](#1 发表时间与团队)
- [2 问题背景和核心思路](#2 问题背景和核心思路)
- [3 具体设计](#3 具体设计)
-
- [3.1 模型设计(分层推理链)](#3.1 模型设计(分层推理链))
- [3.2 数据设计](#3.2 数据设计)
- [4 实验](#4 实验)
- [5 结论](#5 结论)
1 发表时间与团队
- 发表时间:2025年4月22日。
- 团队:Physical Intelligence(由机器人学大牛 Sergey Levine、Chelsea Finn、Karol Hausman 等人领导)。
2 问题背景和核心思路
-
问题背景:现有的机器人模型(VLA)在受控实验室表现良好,但在复杂的真实家庭环境中面临泛化性差、无法处理长程任务(如 15 分钟的家务)以及无法理解复杂指令的挑战。
-
核心思路:通过异构任务联合训练(Co-training),将互联网海量常识(Web Data)、跨本体机器人知识(Cross-Embodiment)与目标机器人的移动操作数据结合。通过层次化推理(感知 → \to → 规划 → \to → 执行)来实现"开箱即用"的泛化能力。
3 具体设计
3.1 模型设计(分层推理链)
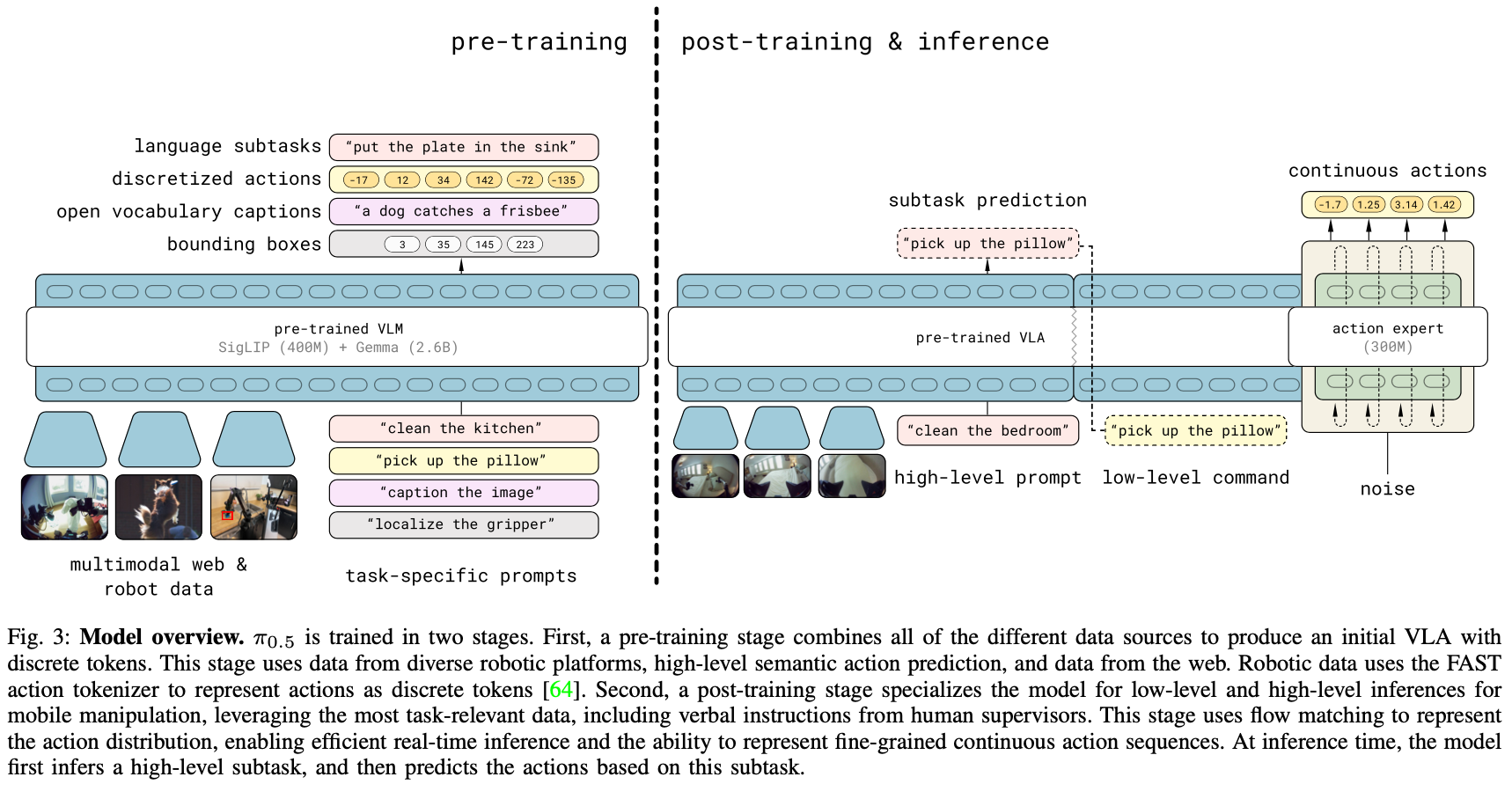
模型在处理每一帧画面时,遵循一套严密的"思维链"预测顺序:
-
感知层(Bounding Box):首先在画面中圈出相关物体。这利用了 Web 数据中学到的物体常识,为后续操作定位。
-
规划层(Subtask Labels):预测当前的语义子任务(如"打开微波炉")。这利用了手动标注的步进式指令知识。
-
执行层(Action Expert):
- 双轨道预测:模型同时预测离散 Token(用于对齐语义和加速训练)和连续动作流(通过 Flow Matching 实现)。
- 冗余输出:同时预测关节角度和末端执行器位姿。末端位姿用于跨机型泛化,关节角度用于直接、安全的物理执行。
- 动作专家:在后训练阶段引入的专用权重,负责将高层指令转化为丝滑的物理轨迹。
3.2 数据设计

- 离散化统一:所有数据(动作、坐标、文本、检测框)都被转化为 FAST Token,使机器人能像 LLM 处理文本一样处理动作。
- 数据阶段化:预训练阶段:加入大量 CE(跨本体) 数据,让模型成为"杂家",理解各种物体的物理交互。
- 后训练阶段:去掉 CE 数据以减少噪音,专注目标机器人的 MM(移动操作) 数据。加入专家标注的 VI(口头指令),教模型如何"分步骤"拆解长任务。
4 实验
- 真实世界评测(In-the-wild):大胆地在三个从未见过的私人家庭中进行测试,模型在无需微调的情况下,能持续执行 10-15 分钟的复杂任务。
- 评估标准(Progress-based):不采用二元成功率,而是根据完成步骤的百分比打分,更客观地衡量模型在长程任务中的鲁棒性。
- 代表性验证(Mock vs Real):证明了实验室模拟环境(Mock Env)的效果与真实环境(Real Env)具有强相关性,验证了实验结论的可靠性。
- 环境规模效应:通过控制变量实验证明,即便数据量相同,训练时见过的房子越多(多样性高),模型的泛化能力越强,且 100 个环境仍未达到上限。
5 结论
π 0.5 \pi_{0.5} π0.5 证明了:
- 结构化推理(先找物体、再想步骤、后动手)是解决长程任务的最优解。
- 异构联合训练能让机器人具备"物理常识",实现跨场景的零样本泛化。
- 分阶段训练策略(先泛化、后聚焦)是训练高性能机器人的有效路径。