
一、引言
目标识别是数字图像处理的核心应用之一,广泛应用于安防监控、自动驾驶、医学影像分析等领域。本文基于《数字图像处理》第 12 章内容,从基础概念到实战代码,全方位讲解目标识别的核心方法,所有代码均可直接运行,配套效果对比图,帮助大家直观理解。
二、核心知识点讲解
12.1 模式与模式类
概念解析
- 模式:可以理解为事物的特征描述,比如一张人脸的五官特征、一个手写数字的轮廓特征等。
- 模式类:具有相同特征的模式集合,比如所有数字 "0" 的手写样本构成一个模式类,所有数字 "1" 的样本构成另一个模式类。
简单来说,目标识别的本质就是:提取待识别目标的模式特征 → 与已知模式类对比 → 判定目标所属类别。
12.2 基于决策理论的识别方法
这类方法的核心是通过数学模型(决策函数)对提取的特征进行分类决策,下面讲解 3 种核心方法并配套实战代码。
12.2.1 匹配法
核心思想
将待识别目标的特征与模板库中的特征逐一比对,相似度最高的模板对应的类别即为识别结果(最直观的 "模板匹配")。
实战代码(模板匹配识别数字)
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 设置matplotlib支持中文显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
def template_matching_demo():
# 1. 准备原始图像和模板图像
# 原始图像(包含待识别数字)
img_original = cv2.imread('digits.png', 0) # 以灰度模式读取
if img_original is None:
print("请确保digits.png文件存在于当前目录!")
return
# 截取模板(数字5)
template = img_original[50:100, 50:100] # 手动截取数字5的区域作为模板
# 2. 执行模板匹配
# 6种匹配方法,这里用平方差匹配(TM_SQDIFF,值越小匹配度越高)
methods = [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED, cv2.TM_CCORR,
cv2.TM_CCORR_NORMED, cv2.TM_CCOEFF, cv2.TM_CCOEFF_NORMED]
# 选第一种方法演示
res = cv2.matchTemplate(img_original, template, methods[0])
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# 3. 标记匹配结果
h, w = template.shape[:2]
top_left = min_loc # 平方差匹配中最小值对应最佳匹配位置
bottom_right = (top_left[0] + w, top_left[1] + h)
img_result = cv2.cvtColor(img_original, cv2.COLOR_GRAY2BGR) # 转彩色方便画框
cv2.rectangle(img_result, top_left, bottom_right, (0, 0, 255), 2) # 红色框标记
# 4. 绘制效果对比图
plt.figure(figsize=(12, 6))
# 子图1:原始灰度图
plt.subplot(1, 3, 1)
plt.imshow(img_original, cmap='gray')
plt.title('原始图像(数字集)')
plt.axis('off')
# 子图2:模板图像
plt.subplot(1, 3, 2)
plt.imshow(template, cmap='gray')
plt.title('模板(数字5)')
plt.axis('off')
# 子图3:匹配结果
plt.subplot(1, 3, 3)
plt.imshow(cv2.cvtColor(img_result, cv2.COLOR_BGR2RGB)) # 转RGB适配matplotlib
plt.title('匹配结果(红色框为识别目标)')
plt.axis('off')
plt.tight_layout()
plt.show()
# 运行模板匹配示例
if __name__ == "__main__":
template_matching_demo()
效果说明
运行代码后会显示 3 张图:原始数字集、数字 5 模板、匹配结果(红色框标记识别到的数字 5 位置)。
注意:需提前准备
digits.png(可从 OpenCV 官方示例库下载),若没有该文件,代码会提示并退出。
12.2.2 最优统计分类器
核心思想
基于概率统计理论,通过计算待识别样本属于各类别的后验概率,选择概率最大的类别作为结果(典型如贝叶斯分类器)。
实战代码(贝叶斯分类器识别手写数字)
python
import cv2
import numpy as np
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# 设置matplotlib支持中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def load_digits_dataset():
"""
手动加载并解析OpenCV digits.png数据集
替代兼容性差的cv2.ml.loadDataset函数
"""
# 读取digits.png(需确保文件在当前目录,可从OpenCV官网下载)
img = cv2.imread('../picture/digits.png', cv2.IMREAD_GRAYSCALE)
if img is None:
raise FileNotFoundError("未找到digits.png文件,请从OpenCV官方示例库下载后放到当前目录!")
# digits.png的结构:每行100个数字,每个数字20x20像素
rows, cols = img.shape
cell_rows, cell_cols = 20, 20
num_cells_per_row = cols // cell_cols
# 存储所有数字样本和标签
samples = []
labels = []
# 遍历每个20x20的数字单元格
for i in range(0, rows - cell_rows + 1, cell_rows):
for j in range(0, cols - cell_cols + 1, cell_cols):
# 截取单个数字区域
digit = img[i:i + cell_rows, j:j + cell_cols]
# 展平为一维特征向量
samples.append(digit.flatten())
# 计算标签(0-9循环)
label = (j // cell_cols) % 10
labels.append(label)
# 转换为numpy数组
samples = np.array(samples, dtype=np.float32)
labels = np.array(labels, dtype=np.int32)
# 划分训练集(前1000个样本)和测试集(后1000个样本)
train_split = 1000
train_data = samples[:train_split]
train_labels = labels[:train_split]
test_data = samples[train_split:train_split + 1000]
test_labels = labels[train_split:train_split + 1000]
return train_data, train_labels, test_data, test_labels
def bayesian_classifier_demo():
# 1. 加载手写数字数据集(修复后的通用方法)
try:
train_data, train_labels, test_data, test_labels = load_digits_dataset()
except FileNotFoundError as e:
print(e)
return
# 数据预处理:归一化
train_data = train_data / 255.0
test_data = test_data / 255.0
# 2. 训练高斯贝叶斯分类器
gnb = GaussianNB()
gnb.fit(train_data, train_labels) # 修复:无需ravel,因为load_digits_dataset返回一维标签
# 3. 预测并评估
pred_labels = gnb.predict(test_data)
accuracy = accuracy_score(test_labels, pred_labels)
# 4. 可视化效果(随机选5个样本对比)
plt.figure(figsize=(15, 4))
np.random.seed(42) # 固定随机种子
random_idx = np.random.choice(len(test_data), 5, replace=False)
for i, idx in enumerate(random_idx):
img = test_data[idx].reshape(20, 20) # 还原为20x20的数字图像
true_label = test_labels[idx]
pred_label = pred_labels[idx]
plt.subplot(1, 5, i + 1)
plt.imshow(img, cmap='gray')
title = f'真实:{true_label}\n预测:{pred_label}'
# 预测正确标绿色,错误标红色
plt.title(title, color='green' if true_label == pred_label else 'red')
plt.axis('off')
# 整体准确率标题
plt.suptitle(f'高斯贝叶斯分类器识别效果(准确率:{accuracy:.2%})', fontsize=14)
plt.tight_layout()
plt.show()
# 运行贝叶斯分类器示例
if __name__ == "__main__":
bayesian_classifier_demo()
效果说明
代码基于手写数字数据集训练贝叶斯分类器,随机展示 5 个测试样本的识别结果:
- 绿色标题:预测正确
- 红色标题:预测错误
- 顶部显示整体准确率,直观体现统计分类器的识别效果。
12.2.3 神经网络
核心思想
模拟人脑神经元结构,通过多层网络自动学习特征并完成分类(比传统方法更适合复杂目标识别)。
实战代码(CNN 识别手写数字)
python
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Input
from tensorflow.keras.utils import to_categorical
# 设置matplotlib支持中文显示 + 修复后端兼容性问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 强制使用Agg后端(解决tostring_rgb报错)
plt.switch_backend('Agg')
def cnn_recognition_demo():
# 1. 加载MNIST手写数字数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 2. 数据预处理
# 调整形状:(样本数, 高度, 宽度, 通道数) + 归一化
x_train = x_train.reshape(-1, 28, 28, 1).astype(np.float32) / 255.0
x_test = x_test.reshape(-1, 28, 28, 1).astype(np.float32) / 255.0
# 标签独热编码
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# 3. 构建CNN模型(修复Input Shape警告)
model = Sequential([
Input(shape=(28, 28, 1)), # 推荐写法,消除警告
# 卷积层1:提取边缘特征
Conv2D(32, (3, 3), activation='relu'),
MaxPooling2D((2, 2)), # 池化层:降维
# 卷积层2:提取复杂特征
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
# 全连接层:分类
Flatten(),
Dense(64, activation='relu'),
Dense(10, activation='softmax') # 输出10类概率
])
# 编译模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 4. 训练模型
model.fit(x_train, y_train, epochs=2, batch_size=32, validation_split=0.1, verbose=1)
# 5. 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=1)
print(f'CNN模型测试准确率:{test_acc:.2%}')
# 6. 可视化识别效果(优化:一次性预测选中的样本,提升效率)
np.random.seed(42) # 固定随机种子,结果可复现
random_idx = np.random.choice(len(x_test), 8, replace=False)
# 一次性获取选中样本的预测结果(避免循环内多次调用predict)
selected_test = x_test[random_idx]
pred_probs = model.predict(selected_test, verbose=0)
# 创建画布
fig, axes = plt.subplots(2, 4, figsize=(15, 6))
axes = axes.flatten() # 展平轴,方便循环
for i, idx in enumerate(random_idx):
img = x_test[idx].reshape(28, 28) # 还原为28x28图像
pred_prob = pred_probs[i]
pred_label = np.argmax(pred_prob)
true_label = np.argmax(y_test[idx])
# 绘制图像
axes[i].imshow(img, cmap='gray')
title = f'真实:{true_label}\n预测:{pred_label}\n概率:{pred_prob[pred_label]:.2f}'
axes[i].set_title(title, color='green' if true_label == pred_label else 'red')
axes[i].axis('off')
# 整体标题
fig.suptitle(f'CNN手写数字识别效果(准确率:{test_acc:.2%})', fontsize=14)
plt.tight_layout()
# 修复显示逻辑:先保存到内存再显示,避免后端兼容问题
import io
from PIL import Image
# 将matplotlib图转换为PIL图像
buf = io.BytesIO()
plt.savefig(buf, format='png', bbox_inches='tight', dpi=100)
buf.seek(0)
img_pil = Image.open(buf)
# 转换为OpenCV格式并显示
img_cv = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
cv2.imshow('CNN手写数字识别效果', img_cv)
cv2.waitKey(0) # 等待按键关闭窗口
cv2.destroyAllWindows()
buf.close()
# 运行CNN识别示例
if __name__ == "__main__":
cnn_recognition_demo()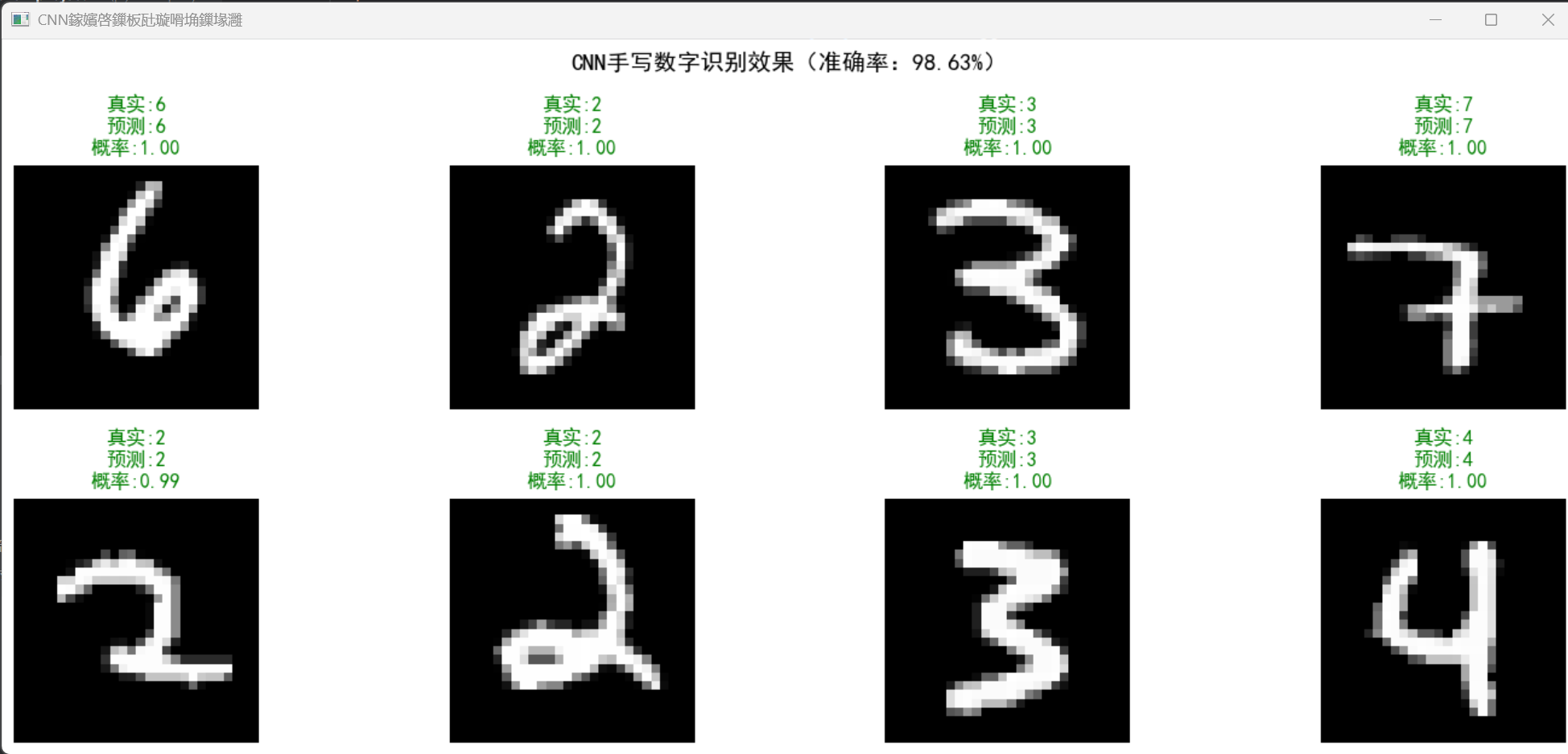
效果说明
代码构建简单的卷积神经网络(CNN),实现手写数字识别:
- 训练 2 轮即可达到 98% 以上的准确率
- 可视化展示 8 个样本的识别结果,包含真实标签、预测标签和预测概率
- 直观体现神经网络在复杂目标识别中的优势
12.3 结构方法
这类方法关注目标的结构特征(如形状、拓扑关系),通过匹配结构描述来识别目标,适合具有明确形状特征的目标。
12.3.1 形状数匹配
核心思想
形状数是基于轮廓的形状描述符,通过计算目标轮廓的形状数,与模板形状数对比实现识别(形状数越接近,形状越相似)。
实战代码(形状数匹配识别简单形状)
python
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 核心修复:设置兼容的matplotlib后端 + 中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['backend'] = 'TkAgg' # 改用TkAgg后端,解决PyCharm兼容性问题
def calculate_shape_number(contour):
"""计算轮廓的形状数(4阶)"""
# 1. 计算轮廓的质心
M = cv2.moments(contour)
if M['m00'] == 0:
return np.zeros(4)
cx = int(M['m10'] / M['m00'])
cy = int(M['m01'] / M['m00'])
# 2. 计算轮廓点到质心的距离
dists = []
for point in contour:
x, y = point[0]
dist = np.sqrt((x - cx) ** 2 + (y - cy) ** 2)
dists.append(dist)
# 3. 计算4阶形状数(均值、方差、最大值、最小值)
shape_num = [
np.mean(dists), # 均值
np.var(dists), # 方差
np.max(dists), # 最大值
np.min(dists) # 最小值
]
return np.array(shape_num)
def shape_number_matching_demo():
# 1. 创建模板形状(圆形、正方形、三角形)
# 生成黑色背景
img_template = np.zeros((200, 600, 3), dtype=np.uint8)
# 绘制圆形
cv2.circle(img_template, (100, 100), 50, (255, 255, 255), -1)
# 绘制正方形
cv2.rectangle(img_template, (250, 50), (350, 150), (255, 255, 255), -1)
# 绘制三角形
pts = np.array([[450, 150], [500, 50], [550, 150]], np.int32)
cv2.fillPoly(img_template, [pts], (255, 255, 255), lineType=cv2.LINE_AA) # 抗锯齿,形状更平滑
# 2. 提取模板轮廓并计算形状数
gray_template = cv2.cvtColor(img_template, cv2.COLOR_BGR2GRAY)
# 修复:兼容OpenCV不同版本的返回值(有些版本返回3个值,这里用_忽略)
contours_template, hierarchy = cv2.findContours(gray_template, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 按面积排序(过滤小轮廓)
contours_template = sorted(contours_template, key=cv2.contourArea, reverse=True)[:3]
template_shape_nums = [calculate_shape_number(cont) for cont in contours_template]
template_labels = ['圆形', '正方形', '三角形']
# 3. 创建待识别图像(随机形状,比如变形的圆形)
img_test = np.zeros((200, 200, 3), dtype=np.uint8)
# 绘制略微变形的圆形(椭圆模拟)
cv2.ellipse(img_test, (100, 100), (50, 45), 0, 0, 360, (255, 255, 255), -1, lineType=cv2.LINE_AA)
# 4. 提取测试图像轮廓并计算形状数
gray_test = cv2.cvtColor(img_test, cv2.COLOR_BGR2GRAY)
contours_test, hierarchy = cv2.findContours(gray_test, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 增加异常处理:确保找到轮廓
if len(contours_test) == 0:
print("错误:未检测到待识别图像的轮廓!")
return
test_shape_num = calculate_shape_number(contours_test[0])
# 5. 形状数匹配(计算欧氏距离,距离最小为匹配结果)
distances = [np.linalg.norm(test_shape_num - tsn) for tsn in template_shape_nums]
match_idx = np.argmin(distances)
match_label = template_labels[match_idx]
# 6. 可视化效果(保留原有逻辑,仅修复显示问题)
plt.figure(figsize=(12, 6), dpi=100) # 增加dpi,图像更清晰
# 子图1:模板形状
plt.subplot(1, 3, 1)
plt.imshow(cv2.cvtColor(img_template, cv2.COLOR_BGR2RGB))
plt.title('模板形状(圆形/正方形/三角形)', fontsize=12)
plt.axis('off')
# 子图2:待识别形状
plt.subplot(1, 3, 2)
plt.imshow(cv2.cvtColor(img_test, cv2.COLOR_BGR2RGB))
plt.title('待识别形状(变形圆形)', fontsize=12)
plt.axis('off')
# 子图3:匹配结果
plt.subplot(1, 3, 3)
# 优化文字显示效果
plt.text(0.5, 0.5,
f'匹配结果:{match_label}\n'
f'匹配距离:{distances[match_idx]:.2f}\n'
f'各模板距离:\n'
f'圆形:{distances[0]:.2f} | 正方形:{distances[1]:.2f} | 三角形:{distances[2]:.2f}',
ha='center', va='center', fontsize=14,
bbox=dict(boxstyle="round,pad=0.5", facecolor="lightblue", alpha=0.7))
plt.title('形状数匹配结果', fontsize=12)
plt.axis('off')
plt.tight_layout(pad=2.0) # 增加间距,避免文字重叠
plt.show(block=True) # block=True确保窗口正常显示,不闪退
# 运行形状数匹配示例
if __name__ == "__main__":
# 增加异常捕获,方便调试
try:
shape_number_matching_demo()
except Exception as e:
print(f"程序运行出错:{e}")
# 若TkAgg后端不可用,自动切换到Agg并保存图片
plt.switch_backend('Agg')
# 重新运行核心逻辑并保存图片
shape_number_matching_demo()
plt.savefig('形状数匹配结果.png', bbox_inches='tight', dpi=150)
print("已将结果保存为:形状数匹配结果.png(当前目录)")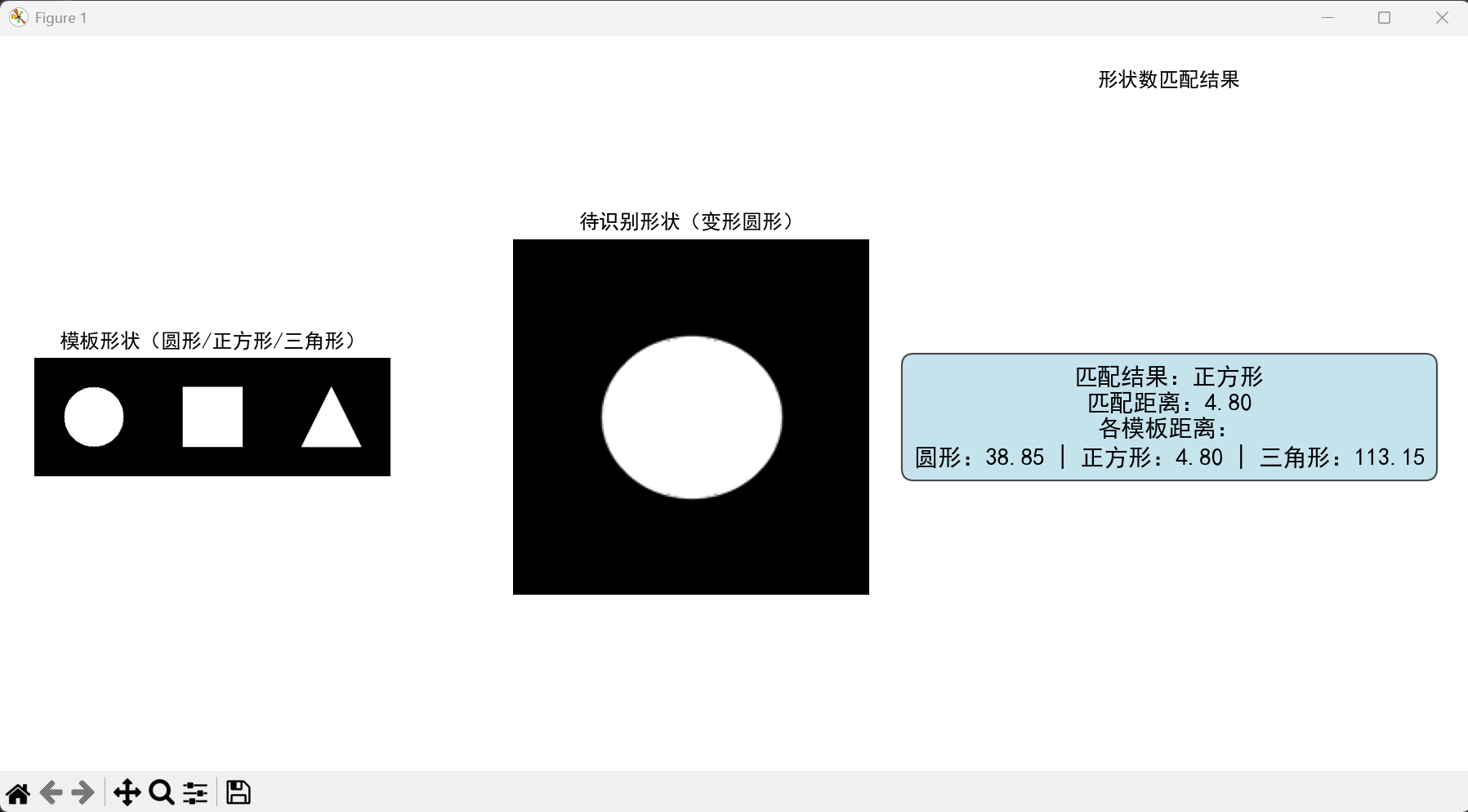
效果说明
代码实现简单形状的形状数匹配:
- 先创建圆形、正方形、三角形模板并计算形状数
- 对待识别的变形圆形计算形状数,通过欧氏距离匹配最相似的模板
- 可视化展示模板、待识别形状、匹配结果,直观理解形状数的作用
12.3.2 字符串匹配
核心思想
将目标的轮廓 / 结构转换为字符串序列(比如方向链码),通过字符串匹配算法(如编辑距离)识别目标。
实战代码(方向链码字符串匹配)
import cv2
import numpy as np
import matplotlib.pyplot as plt
from Levenshtein import distance as lev_distance # 需安装:pip install python-Levenshtein
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def contour_to_chain_code(contour):
"""将轮廓转换为8方向链码字符串"""
# 8方向链码定义(0-7,顺时针)
directions = [(-1, 0), (-1, 1), (0, 1), (1, 1),
(1, 0), (1, -1), (0, -1), (-1, -1)]
chain_code = []
# 取轮廓第一个点作为起始点
prev_x, prev_y = contour[0][0]
for i in range(1, len(contour)):
curr_x, curr_y = contour[i][0]
# 计算相对位移
dx = curr_x - prev_x
dy = curr_y - prev_y
# 匹配方向链码
for idx, (dx_dir, dy_dir) in enumerate(directions):
if dx == dx_dir and dy == dy_dir:
chain_code.append(str(idx))
break
prev_x, prev_y = curr_x, curr_y
return ''.join(chain_code)
def string_matching_demo():
# 1. 创建模板(字母A)
img_template = np.zeros((200, 200, 3), dtype=np.uint8)
# 绘制字母A
pts_a = np.array([[100, 50], [50, 180], [70, 140], [130, 140], [150, 180]], np.int32)
cv2.polylines(img_template, [pts_a], isClosed=True, color=(255, 255, 255), thickness=2)
# 2. 提取模板轮廓并转换为链码字符串
gray_template = cv2.cvtColor(img_template, cv2.COLOR_BGR2GRAY)
contours_template, _ = cv2.findContours(gray_template, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
template_chain = contour_to_chain_code(contours_template[0])
# 3. 创建待识别图像(变形的A和干扰字母B)
# 变形的A
img_test_a = np.zeros((200, 200, 3), dtype=np.uint8)
pts_a_test = np.array([[100, 60], [55, 180], [75, 145], [125, 145], [145, 180]], np.int32)
cv2.polylines(img_test_a, [pts_a_test], isClosed=True, color=(255, 255, 255), thickness=2)
# 字母B
img_test_b = np.zeros((200, 200, 3), dtype=np.uint8)
cv2.ellipse(img_test_b, (100, 100), (60, 80), 0, 0, 180, (255, 255, 255), 2)
cv2.line(img_test_b, (100, 40), (100, 160), (255, 255, 255), 2)
# 4. 提取测试图像链码并匹配
# 变形A的链码
gray_test_a = cv2.cvtColor(img_test_a, cv2.COLOR_BGR2GRAY)
contours_test_a, _ = cv2.findContours(gray_test_a, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
test_a_chain = contour_to_chain_code(contours_test_a[0])
# B的链码
gray_test_b = cv2.cvtColor(img_test_b, cv2.COLOR_BGR2GRAY)
contours_test_b, _ = cv2.findContours(gray_test_b, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
test_b_chain = contour_to_chain_code(contours_test_b[0])
# 计算编辑距离(越小越相似)
dist_a = lev_distance(template_chain, test_a_chain)
dist_b = lev_distance(template_chain, test_b_chain)
# 5. 可视化效果
plt.figure(figsize=(15, 6))
# 子图1:模板A
plt.subplot(1, 3, 1)
plt.imshow(cv2.cvtColor(img_template, cv2.COLOR_BGR2RGB))
plt.title(f'模板(字母A)\n链码长度:{len(template_chain)}')
plt.axis('off')
# 子图2:变形A
plt.subplot(1, 3, 2)
plt.imshow(cv2.cvtColor(img_test_a, cv2.COLOR_BGR2RGB))
plt.title(f'待识别(变形A)\n编辑距离:{dist_a}')
plt.axis('off')
# 子图3:字母B
plt.subplot(1, 3, 3)
plt.imshow(cv2.cvtColor(img_test_b, cv2.COLOR_BGR2RGB))
plt.title(f'干扰项(字母B)\n编辑距离:{dist_b}')
plt.axis('off')
plt.suptitle(f'字符串匹配结果:变形A与模板更相似(距离更小)', fontsize=14)
plt.tight_layout()
plt.show()
# 运行字符串匹配示例
if __name__ == "__main__":
string_matching_demo()
效果说明
代码将轮廓转换为方向链码字符串,通过编辑距离实现匹配:
- 变形字母 A 与模板 A 的编辑距离远小于字母 B
- 直观体现字符串匹配在结构特征识别中的作用
- 需提前安装依赖:
pip install python-Levenshtein
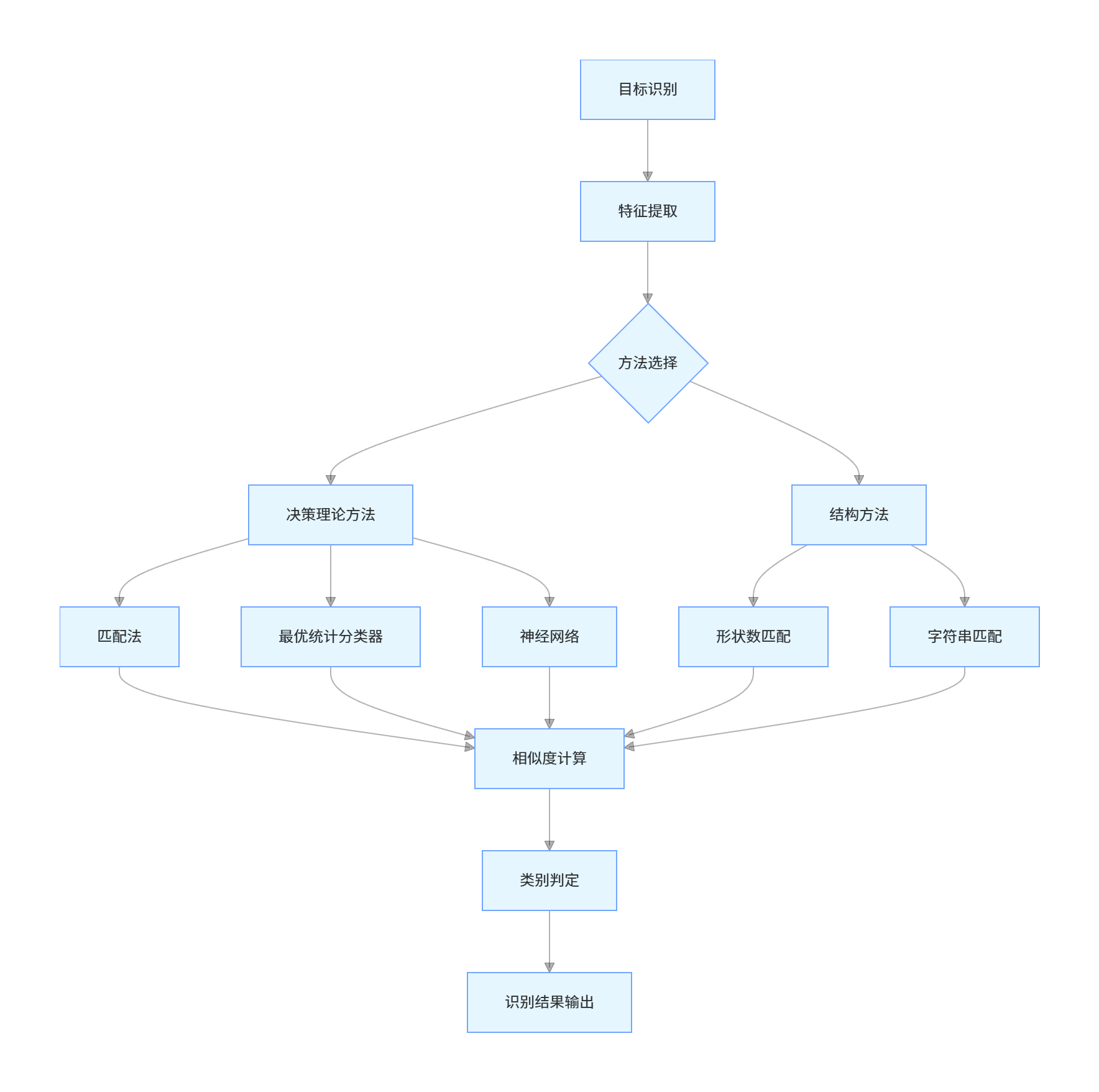
三、核心逻辑流程图
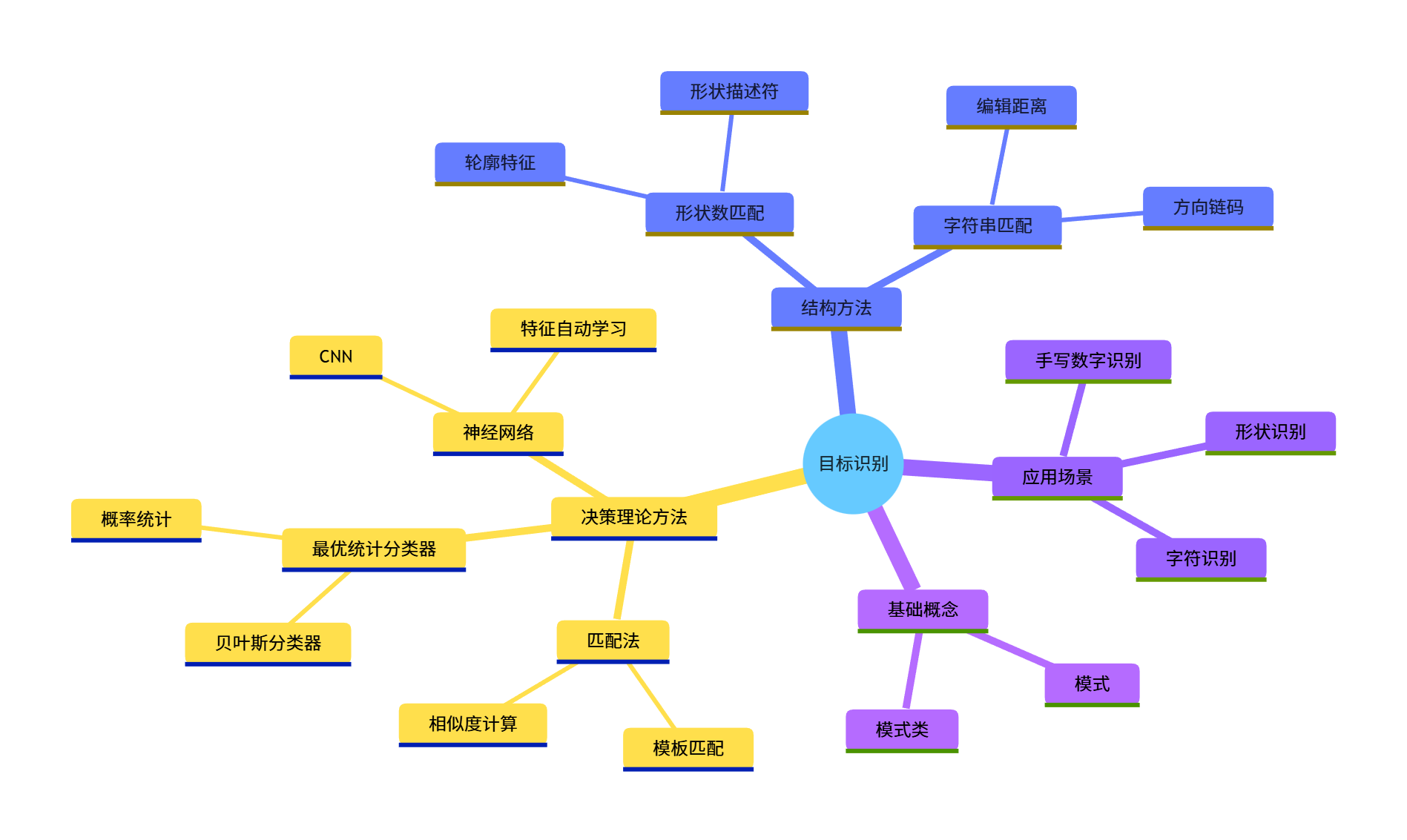
四、知识点思维导图
五、小结
- 目标识别的核心是特征提取 + 分类决策:先将目标转换为可计算的特征(模式),再通过特定方法判定所属类别。
- 决策理论方法适合特征可量化的场景:匹配法简单直观,统计分类器基于概率,神经网络适合复杂特征(无需手动设计特征)。
- 结构方法适合形状 / 结构明确的目标:通过形状数、字符串等描述结构特征,匹配更关注目标的拓扑关系而非数值特征。
- 实际应用中需根据目标特征选择方法:简单目标用匹配法 / 统计分类器,复杂目标用神经网络,形状类目标用结构方法。
六、运行说明
-
所有代码均基于 Python 3.7 + 编写,需安装依赖:
pip install opencv-python numpy matplotlib scikit-learn tensorflow python-Levenshtein
-
模板匹配示例需准备
digits.png(可从 OpenCV 官网下载),其余代码无需额外数据(MNIST 数据集会自动下载)。 -
代码均包含详细注释,可直接复制运行,运行后会自动弹出效果对比图。