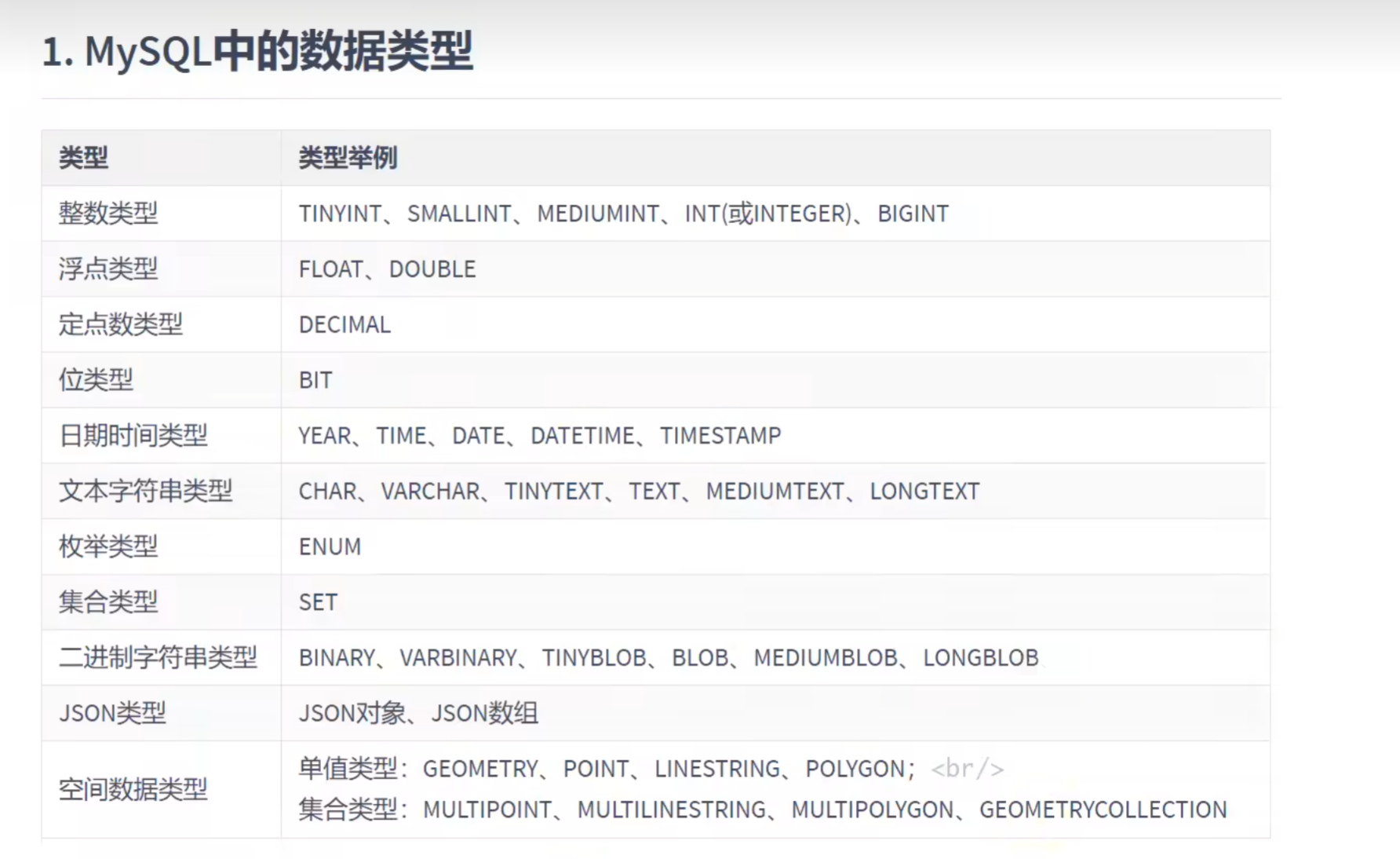
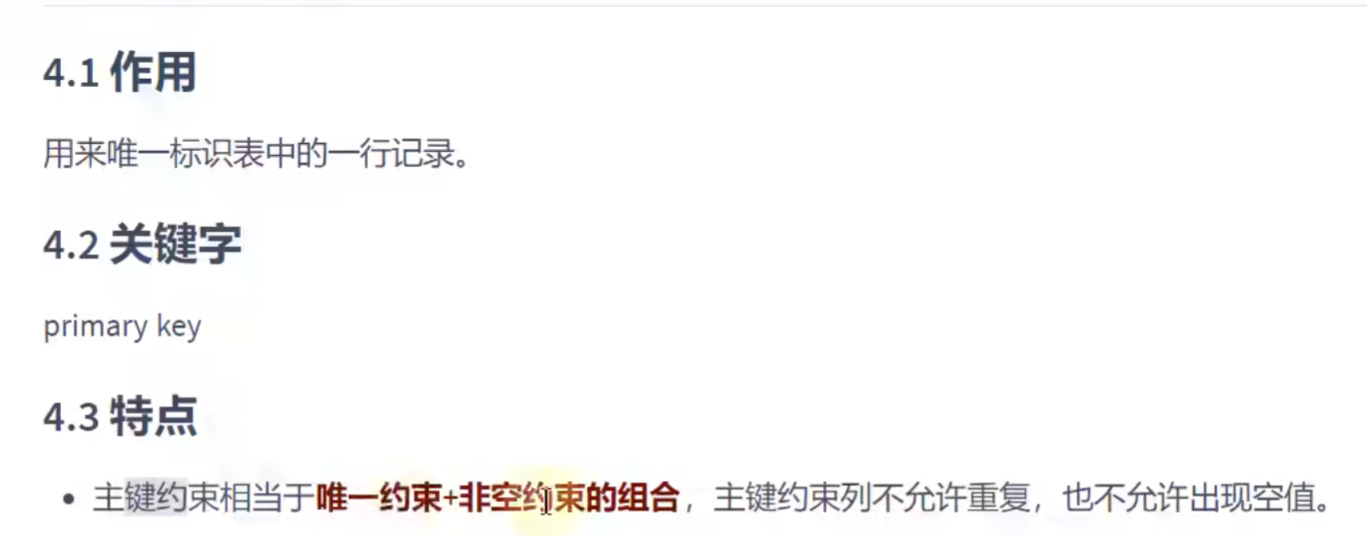
MySQL中的数据类型:
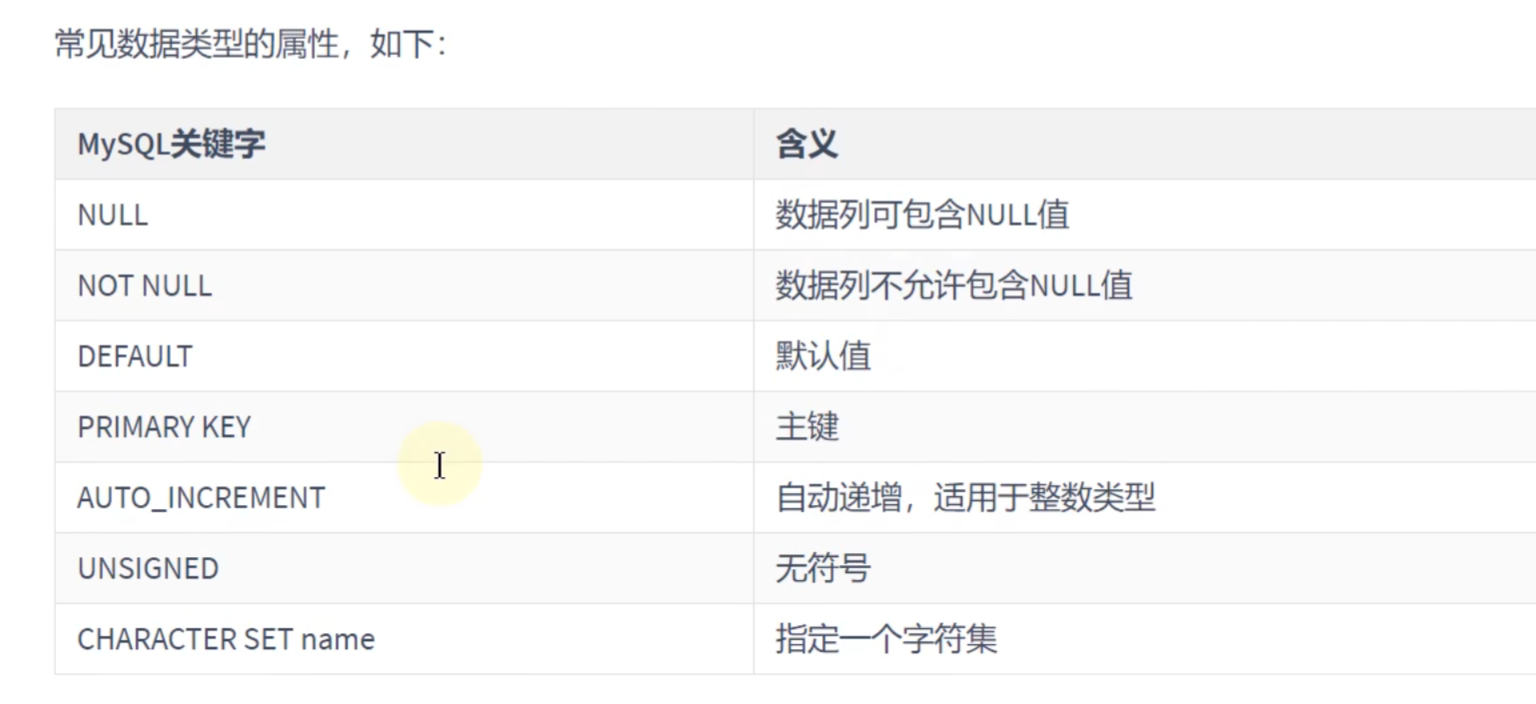
常见数据类型的属性:
整数类型:
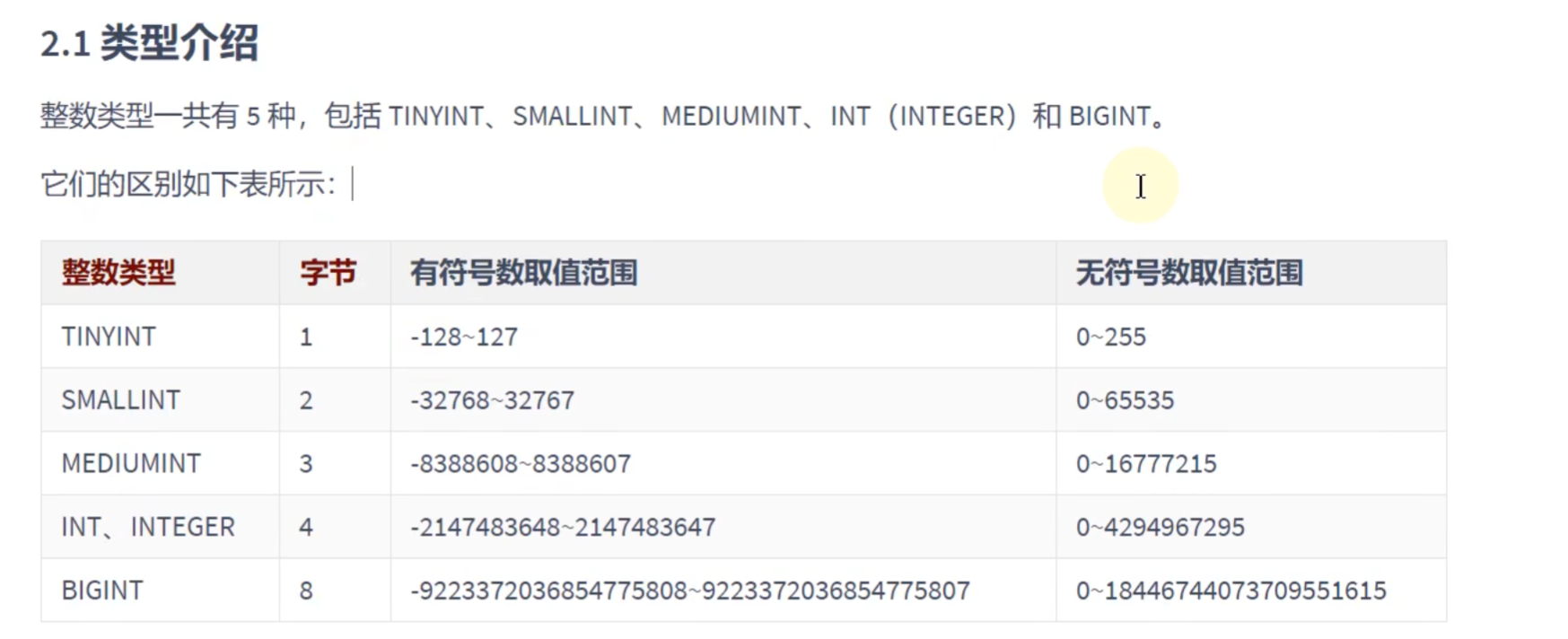
只要添加的数据大小超过了整数类型的取值范围,就会报错
可选属性:

说明:如果存储的数据值超过了显示宽度,但是没有超过数据类型的存储范围,数据依旧是原来的数据,不会被截断或者报错


浮点型类型:




定点数:

位类型:BIT


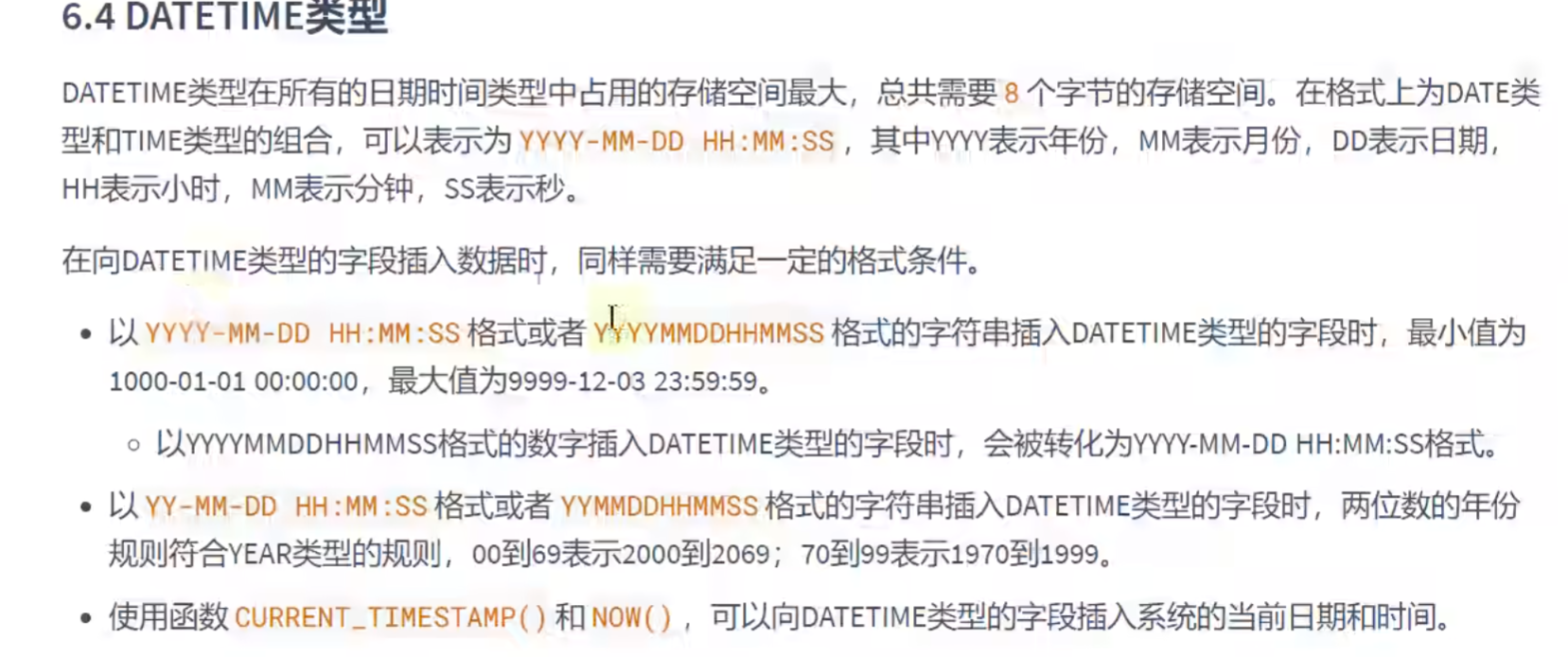
日期与时间类型:

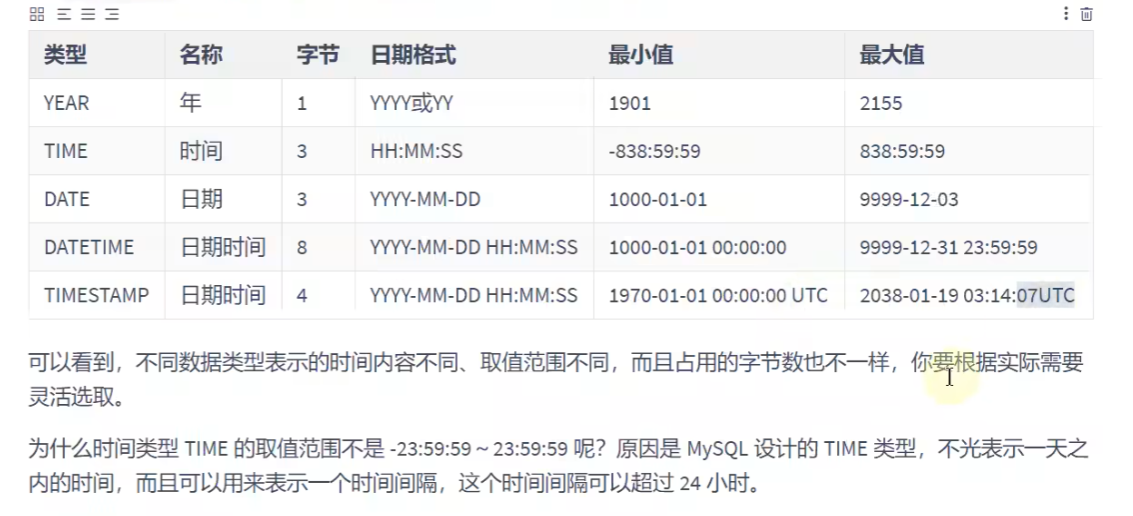
YEAR类型:

DATE类型:

TIME类型:

DATEATIME类型:年月日加上时分秒
TIMESTAMP类型:

datetime和timestamp类型的区别:

文本字符串类型:
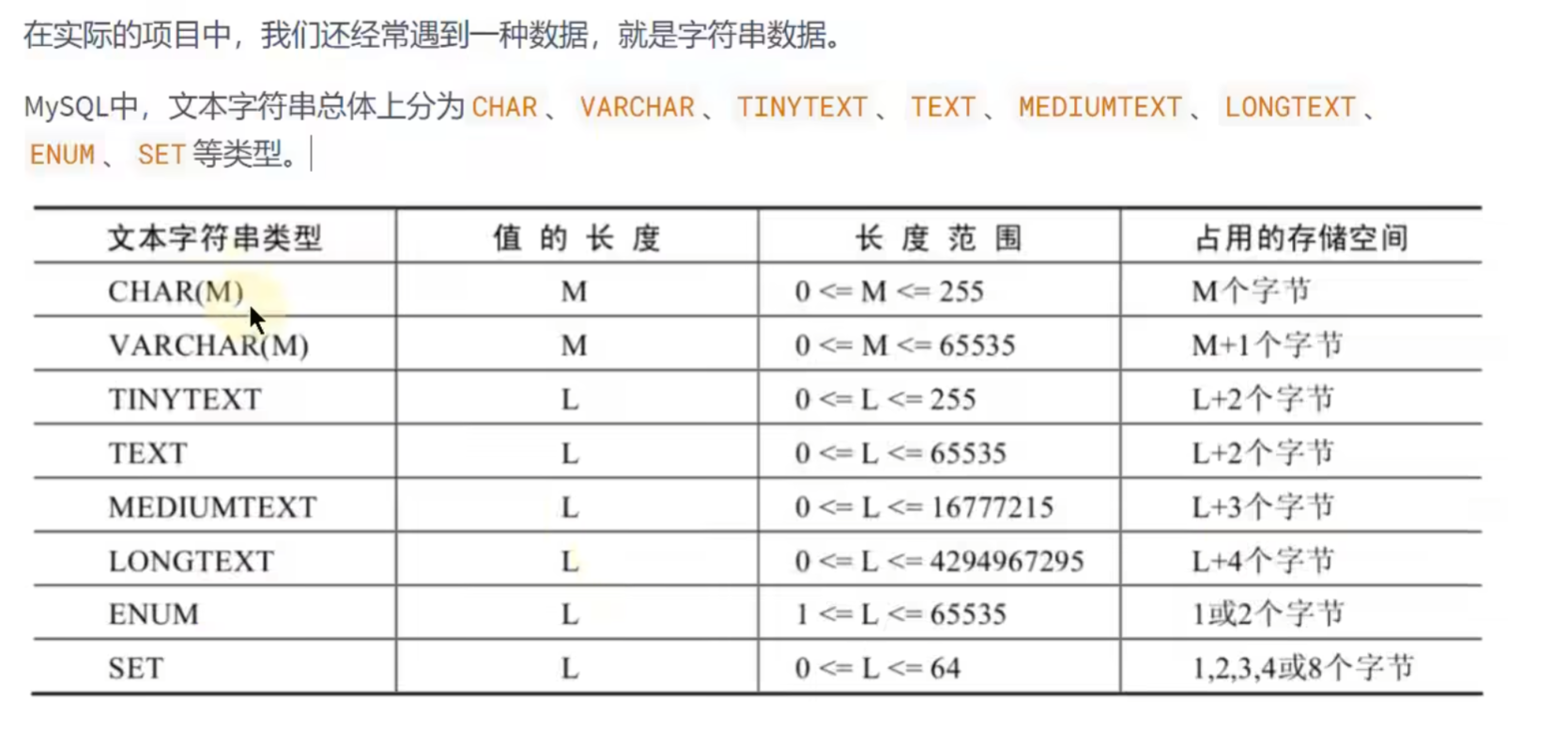

可变长度的意思就是是根据实际长度来确定的,如果给的长度是20,但是实际长度只有15,那么长度就是15
char类型:

varchar类型:

varchar定义时,括号里的数字必须写出来
varchar和char对比:

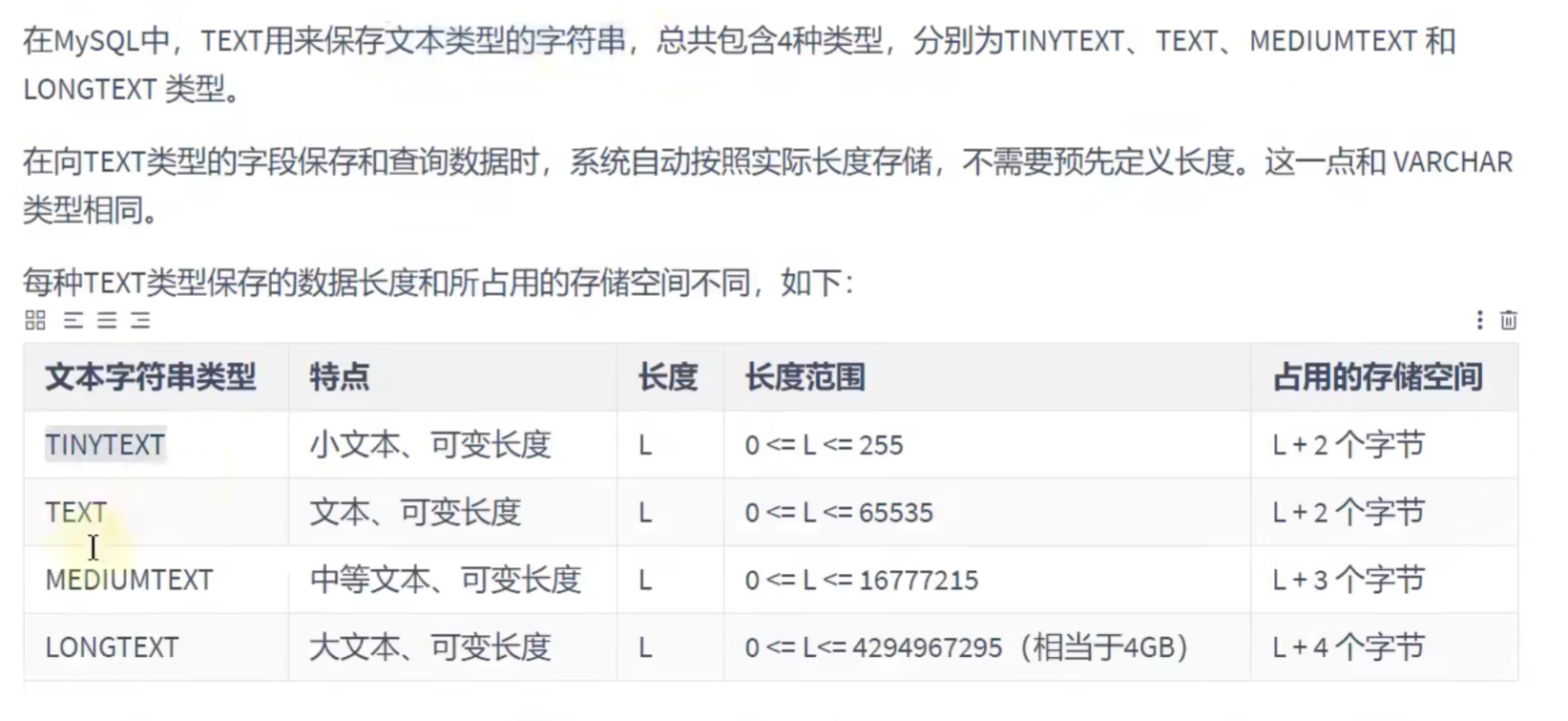
TEXT类型:

枚举类型:
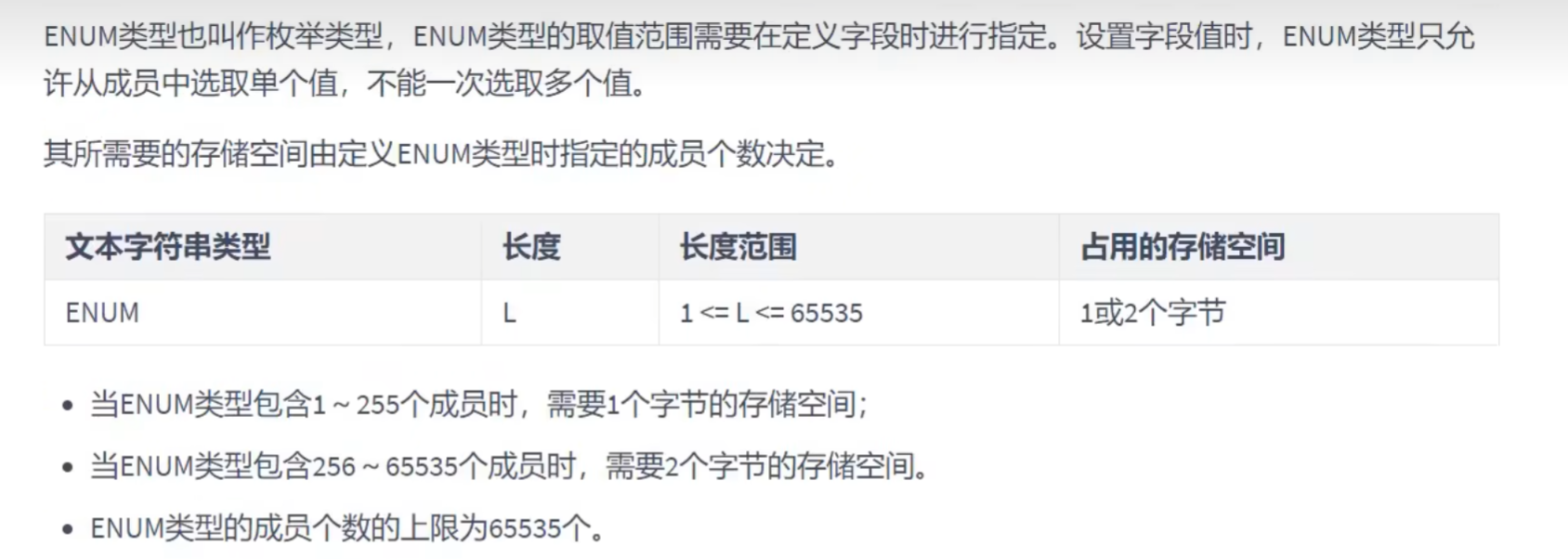
只能从给定的字符当中选择添加的,而且不能多选,一次只能选一个。
没有限制非空值的话,可以添加null值
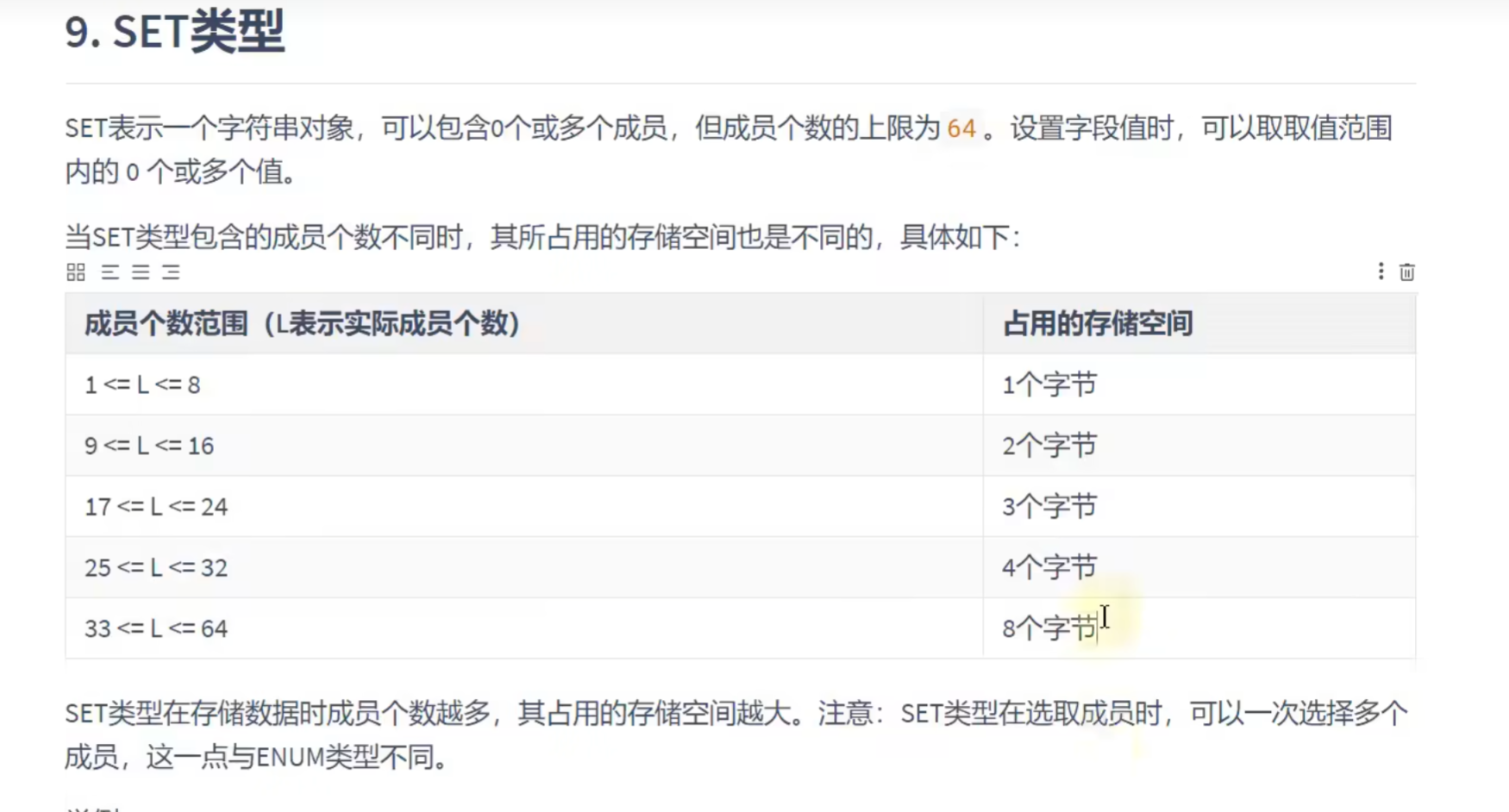
SET类型:

二进制字符串类型:

BINARY和VARBINARY类型:


BLOB类型:

text和blob的使用注意事项:

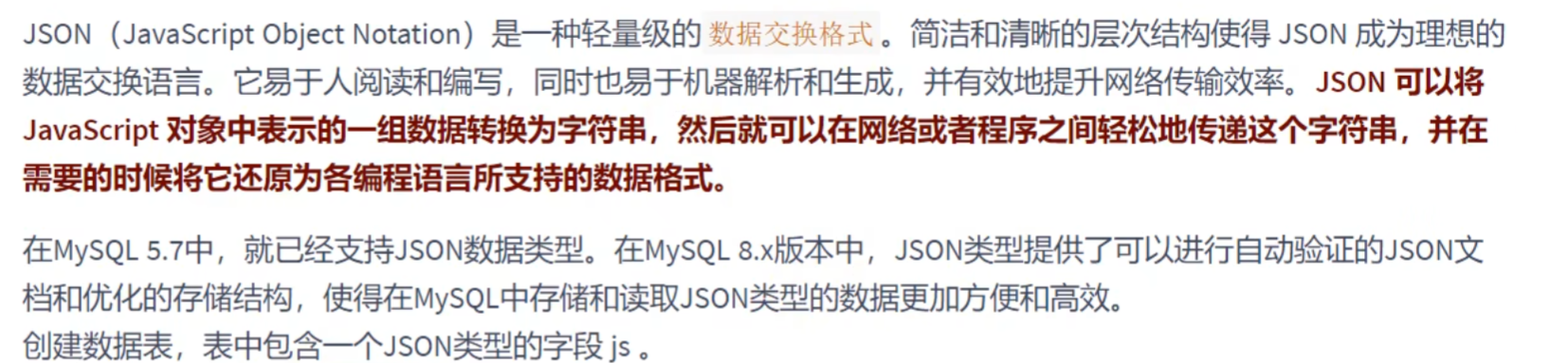
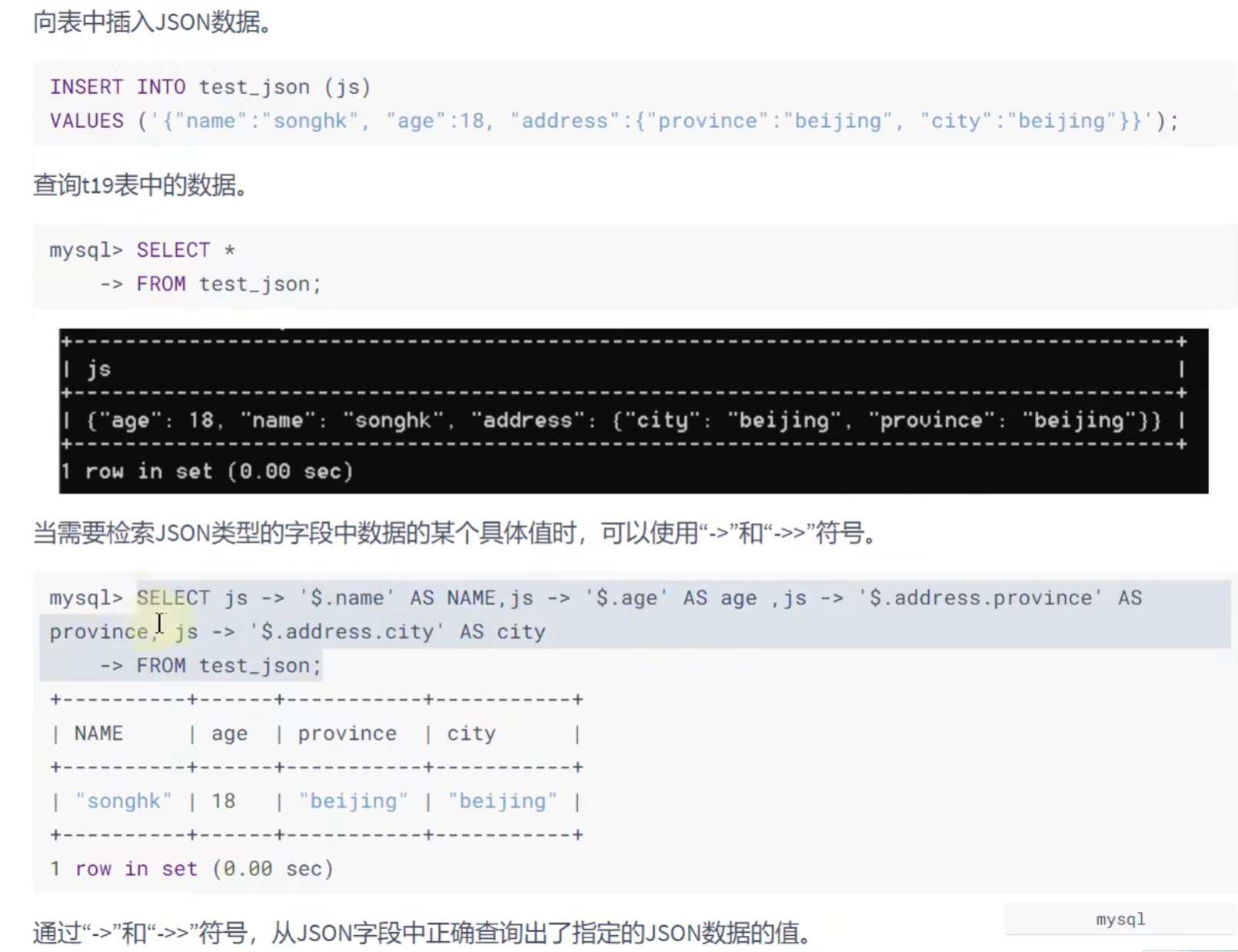
JSON类型:
空间类型:

小结:

约束






非空约束的使用:
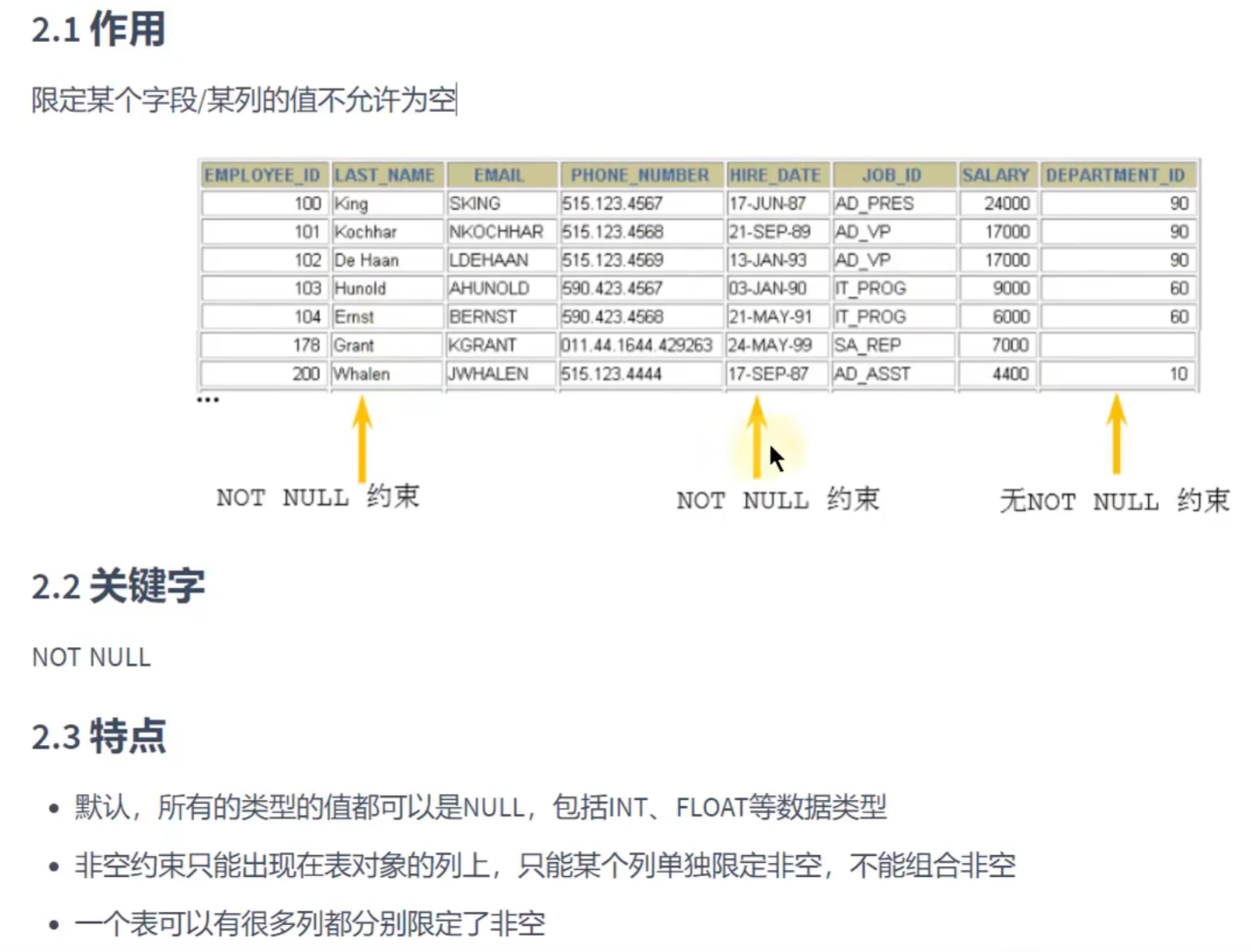
空字符串不等于NULL,0也不等于NULL
举例:
# 非空约束的使用:
# 创建表的时候添加
CREATE TABLE test1(
id INT NOT NULL,
last_name VARCHAR(15) NOT NULL,
email VARCHAR(25),
salary DECIMAL(10,2)
);
# ALTER TABLE时添加约束
ALTER TABLE test1
MODIFY email VARCHAR(25) NOT NULL;
# 在ALTER TABLE的时候删除约束
ALTER TABLE test1
MODIFY email VARCHAR(25) NULL; # 只需要把not删掉就好not null只能使用列级约束
唯一性约束的使用:


# 唯一性约束的使用:
# 在创建表的时候添加约束
CREATE TABLE test2(
id INT UNIQUE, # 列级约束
last_name VARCHAR(25),
email VARCHAR(25) UNIQUE,
salary DECIMAL(10,2),
#表级约束
CONSTRAINT uk_test2_email UNIQUE(email)
);
#在创建唯一性约束的时候,如果不给唯一约束命名,就默认和列名一致
#可以向声明为unique的字段上添加null值,而且可以多次添加
# 在ALTER TABLE的时候添加约束
# 方式一:
ALTER TABLE test2
ADD CONSTRAINT uk_test2_sal UNIQUE(salary);
# 方式三
ALTER TABLE test2
MODIFY last_name VARCHAR(25) UNIQUE;
ALTER TABLE test2
ADD `password` INT;
# 复合的唯一性约束
CREATE TABLE `USER`(
id INT,
`name` VARCHAR(15),
`password` VARCHAR(25),
#表级约束
CONSTRAINT uk_user_name_pwd UNIQUE(`name`,`password`) # 这个唯一性约束是作用在name和passwo这个整体上的,只要这两个不完全一样,那就可以添加成功
);
INSERT INTO `USER`
VALUES(1,'Tom','abc');
INSERT INTO `USER`
VALUES (2,'Toml','abc');删除唯一性约束:

# 删除唯一性索引
ALTER TABLE test2
DROP INDEX uk_test2_sal;
ALTER TABLE test2
DROP INDEX id;主键约束的使用:

# 主键约束
# 在创建表的时候添加约束
CREATE TABLE test3(
id INT PRIMARY KEY,# 列级约束
last_name VARCHAR(15),
salary DECIMAL(10,2),
email VARCHAR(25)
);
#表级约束
CREATE TABLE test4(
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2),
email VARCHAR(25),
CONSTRAINT pk_test5_id PRIMARY KEY(id) # MySQL中的主键名总是primary,就算自己命名也没用
);
# 如果是多列组合的复合主键约束,那么这些列都不允许为空值,并且组合的值不允许重复
# 在ALTER TABLE时添加约束
CREATE TABLE test6(
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2),
email VARCHAR(25)
);
DESC test6;
ALTER TABLE test6
ADD PRIMARY KEY (id);
# 如何删除约束
ALTER TABLE test6
DROP PRIMARY KEY;自增列约束:

区别 1:重启 MySQL 后,自增 ID 会不会 "倒回去"(最核心、最容易踩坑)
这是 5.7 和 8.0 最本质的区别,用 "领号机" 的例子就能懂:
- MySQL 5.7:自增 ID 的 "领号机" 只把当前号记在脑子里(内存),没写在纸上。比如你往表里插了 3 条数据,ID 是 1、2、3,然后删掉了 ID=3 的行,此时领号机显示下一个号是 4。但如果重启 MySQL,领号机 "失忆" 了,会重新数表里的 ID(只剩 1、2),然后把下一个号改成 3。结果:再插数据时,ID 会变成 3(相当于复用了删掉的 ID),如果你的业务里用这个 ID 关联了其他数据,就会出主键冲突、数据错乱的问题。
- MySQL 8.0:自增 ID 的 "领号机" 会把当前号写在纸上(持久化到 redo log 日志)。同样的操作:删了 ID=3 的行,领号机显示下一个号是 4,重启后领号机看纸上的记录,还是会保留 "下一个号是 4",不会倒回去。结果:再插数据时,ID 是 4,不会复用删掉的 ID,彻底避免了主键冲突的坑。
区别 2:多人同时插数据时,速度快不快(锁机制优化)
自增 ID 需要保证不重复,所以得加 "锁",5.7 和 8.0 的锁不一样:
- MySQL 5.7:如果批量插数据(比如一次插 100 条、或者从其他表导数据),会把整个表锁住,其他人想插数据只能等你插完,并发插数据时速度很慢。
- MySQL 8.0:优化了锁的方式,批量插数据时不会锁整个表,只是提前把需要的 ID 分配好,其他人可以同时插数据,高并发场景下速度能快很多。
区别 3:其他小细节(不用深钻,知道就行)
- 5.7 对自增相关的参数(比如步长、起始值)没严格校验,不小心设成 0 或负数也能保存,容易出问题;8.0 会直接提示参数非法,不让你设错。
- 5.7 的自增信息存在多个地方(文件 + 内存),容易乱;8.0 统一存在数据字典里,更稳定。
总结(记这 3 句话就行)
-
核心坑点:5.7 重启后自增 ID 会倒回去复用已删 ID,8.0 不会,数据更安全;
-
性能差异:8.0 批量插数据时并发速度比 5.7 快很多;
-
稳定性:8.0 对自增参数和存储的管理更严格,不容易出问题。
自增长列:只作用在主键上
CREATE TABLE test7(
id INT PRIMARY KEY AUTO_INCREMENT,
last_name VARCHAR(15)
);INSERT INTO test7(last_name)
VALUES('妄竹');这个时候的id就会自动增加
SELECT * FROM test7;
在ALTER TABLE时候添加
CREATE TABLE test8(
id INT PRIMARY KEY,
last_name VARCHAR(15)
);
ALTER TABLE test8
MODIFY id INT AUTO_INCREMENT;在ALTER TABLE时候删除
ALTER TABLE test8
MODIFY id INT;
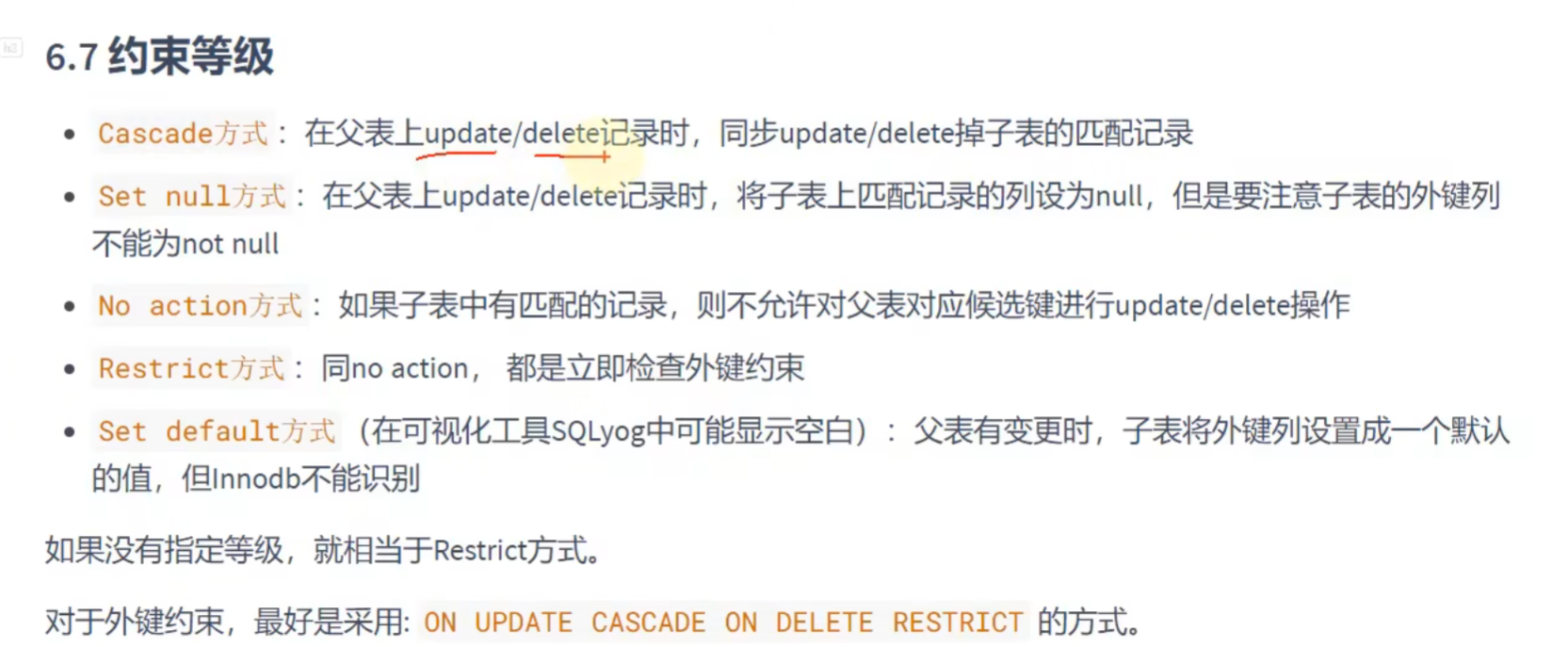
外键约束的使用(开发时一般不用外键):



举例:
# 外键约束
# 在creat table时添加
# 先创建主表(父表),再创建从表(子表)
# 先创建主表
CREATE TABLE dept1(
dept_id INT PRIMARY KEY,
dept_name VARCHAR(15)
);
# 再创建从表
CREATE TABLE emp11(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
emp_name VARCHAR(15),
department_id INT,
#表级约束
CONSTRAINT fk_emp1_dept_id FOREIGN KEY (department_id) REFERENCES dept1(dept_id)
);
# 主表中要有主键,这样从表才能关联
# 而且如果父表中的主键已经被子表关联,那么就不能直接删除/修改主键记录,这样会导致子表外键无对应主键
# 在ALTER TABLE时添加外键约束
CREATE TABLE dept2(
dept_id INT PRIMARY KEY,
dept_name VARCHAR(15)
);
CREATE TABLE emp12(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
emp_name VARCHAR(15),
department_id INT
);
ALTER TABLE emp12
ADD CONSTRAINT fk_emp2_dept_id FOREIGN KEY(department_id) REFERENCES dept2(dept_id);删除外键约束:


CHECK约束:
# CHECK约束
CREATE TABLE test10(
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2) CHECK(salary > 2000) # 这个检查约束的作用就是确保工资都大于2000
);
INSERT INTO test10
VALUES(1,'Tom',2500);# 添加成功
INSERT INTO test10
VALUES(2,'Toml',1500);# 添加失败DEFAULT约束:

# default约束
CREATE TABLE test11(
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2) DEFAULT(2000)
);
# 在ALTER TABLE时添加DEFAULT约束
ALTER TABLE test11
MODIFY salary DECIMAL(10,2) DEFAULT 2500;
课后练习:
# 约束课后练习
# 练习一:
CREATE DATABASE test04_emp;
USE test04_emp;
CREATE TABLE emp2(
id INT,
emp_name VARCHAR(15)
);
CREATE TABLE dept2(
id INT,
dept_name VARCHAR(15)
);
DESC emp2;
DESC dept2;
# 向表emp2的id列添加primiary key约束
ALTER TABLE emp2
ADD PRIMARY KEY(id);
# 向表dept2的id列中添加primary key约束
ALTER TABLE dept2
ADD PRIMARY KEY(id);
# 向表emp2中添加列dept_id,并在其中定义foreign key约束,与之相关联的列时dept2表中的id
ALTER TABLE emp2
ADD dept_id INT;
ALTER TABLE emp2
ADD CONSTRAINT fk_emp2_deptid FOREIGN KEY(dept_id) REFERENCES dept2(id);
# 练习2:
USE test01_library;
DESC books;
# 给id加主键和自增约束
ALTER TABLE books
MODIFY id INT PRIMARY KEY AUTO_INCREMENT;
# 给其他的字段加非空约束
ALTER TABLE books
MODIFY `NAME` VARCHAR(50) NOT NULL;
ALTER TABLE books
MODIFY authors VARCHAR(100) NOT NULL;
ALTER TABLE books
MODIFY price FLOAT NOT NULL;
ALTER TABLE books
MODIFY pubdate YEAR NOT NULL;
ALTER TABLE books
MODIFY num INT(11) NOT NULL;
# 练习3:
# 创建数据库test04_company
CREATE DATABASE test04_company CHARACTER SET 'utf8';
USE test04_company;
# 在此数据库中创建两个表
CREATE TABLE offices(
officeCode INT(10) PRIMARY KEY UNIQUE,
city VARCHAR(50) NOT NULL,
address VARCHAR(50),
country VARCHAR(50) NOT NULL,
postalCode VARCHAR(15) UNIQUE
);
DESC offices;
CREATE TABLE employees(
employeeNumber INT(11) PRIMARY KEY AUTO_INCREMENT,
lastName VARCHAR(50) NOT NULL,
firstName VARCHAR(50) NOT NULL,
mobile VARCHAR(25) UNIQUE,
officeCode INT(10) NOT NULL,
jonTitle VARCHAR(50) NOT NULL,
birth DATETIME NOT NULL,
note VARCHAR(255),
sex VARCHAR(5),
CONSTRAINT fk_emp_offs FOREIGN KEY(officeCode) REFERENCES offices(officeCode)
);
# 将表employees的mobile字段修改到officeCode字段后面
ALTER TABLE employees
MODIFY mobile VARCHAR(25) AFTER officeCode;
# 将表employees的birth字段改名为employee_birth
ALTER TABLE employees
CHANGE birth employee_birth DATETIME NOT NULL;
# 修改sex字段,数据类型为char(1),非空约束
ALTER TABLE employees
MODIFY sex CHAR(1) NOT NULL;
# 删除字段note
ALTER TABLE employees
DROP COLUMN note;
# 增加字段名favoriate_activity,数据类型为varchar(100)
ALTER TABLE employees
ADD favoriate_avtivity VARCHAR(100);
# 将表employees名称修改为employees_info
RENAME TABLE employees
TO employees_info;视图:
常见的数据库对象:


视图的理解:


创建视图:
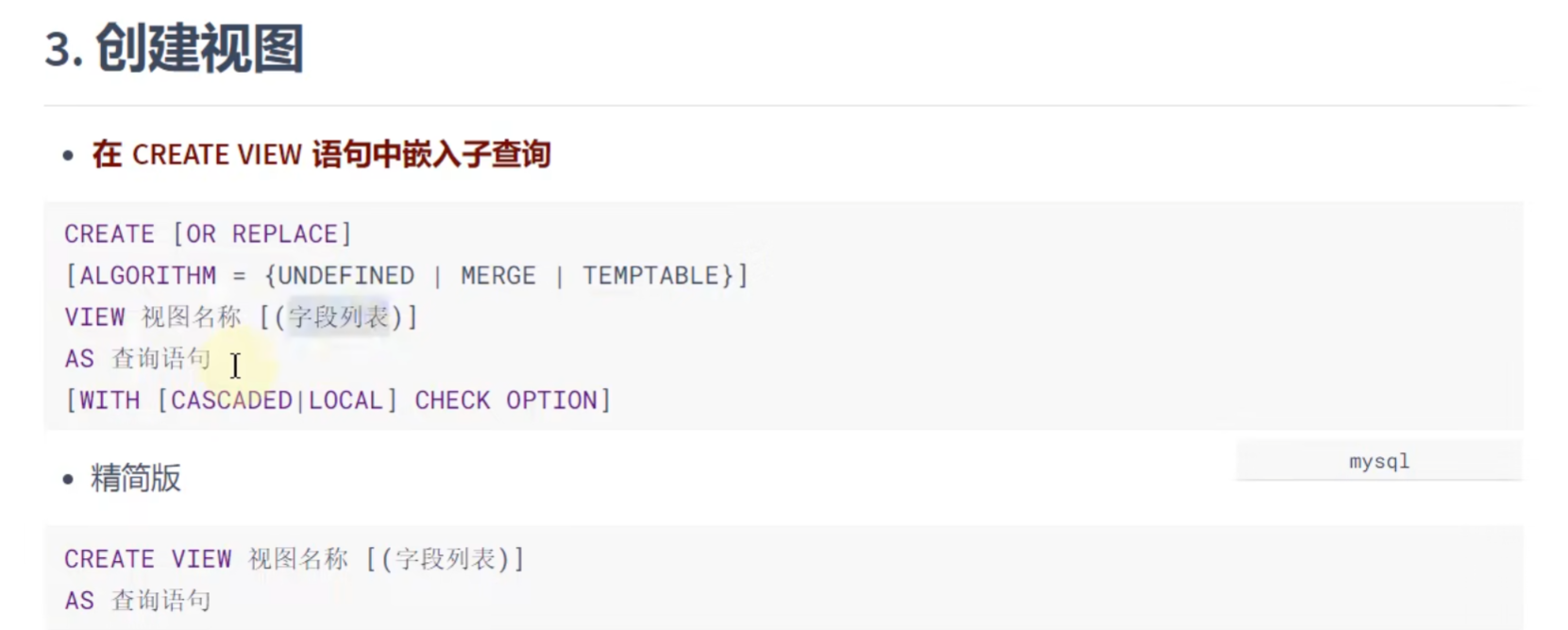
# 如何创建视图
# 针对于单表
# 情况1
CREATE VIEW vu_emp1
AS
SELECT employee_id,last_name,salary # 写出视图中含有的字段
FROM emps;
CREATE VIEW vu_emp2
AS
SELECT employee_id emp_id,last_name lname,salary # 查询语句中字段的别名会作为视图中字段的名称出现
FROM emps
WHERE salary > 8000;
# 确定视图中字段名的方式2:
CREATE VIEW vu_emp3(emp_id,NAME,month_sal)# 小括号内的字段和select语句中的字段是一一对应的
AS
SELECT employee_id,last_name,salary
FROM emps
WHERE salary > 8000;
# 情况2:视图中的字段在基表中可能没有对应的字段
CREATE VIEW vu_emp_sal
AS
SELECT departmnet_id,AVG(salary) avg_sal
FROM emps
WHERE department_id IS NOT NULL
GROUP BY department_id;
# 针对于多表
CREATE VIEW vu_emp_dept
AS
SELECT e.employee_id,e.department_id,d.department_name
FROM emps e JOIN depts d
ON e.department_id = d.department_id;
# 就是多表的查询多了一个创建视图的步骤
SELECT *
FROM vu_emp_dept;
# 利用视图对数据进行格式化
CREATE VIEW vu_emp_dept1
AS
SELECT CONCAT(e_last_name,'(',d.department_name,')') emp_info
ON e.department_id = d.department_id;
# 基于视图创建视图
CREATE VIEW vu_emp4
AS
SELECT employee_id,last_name
FROM vu_emp1;查看视图:
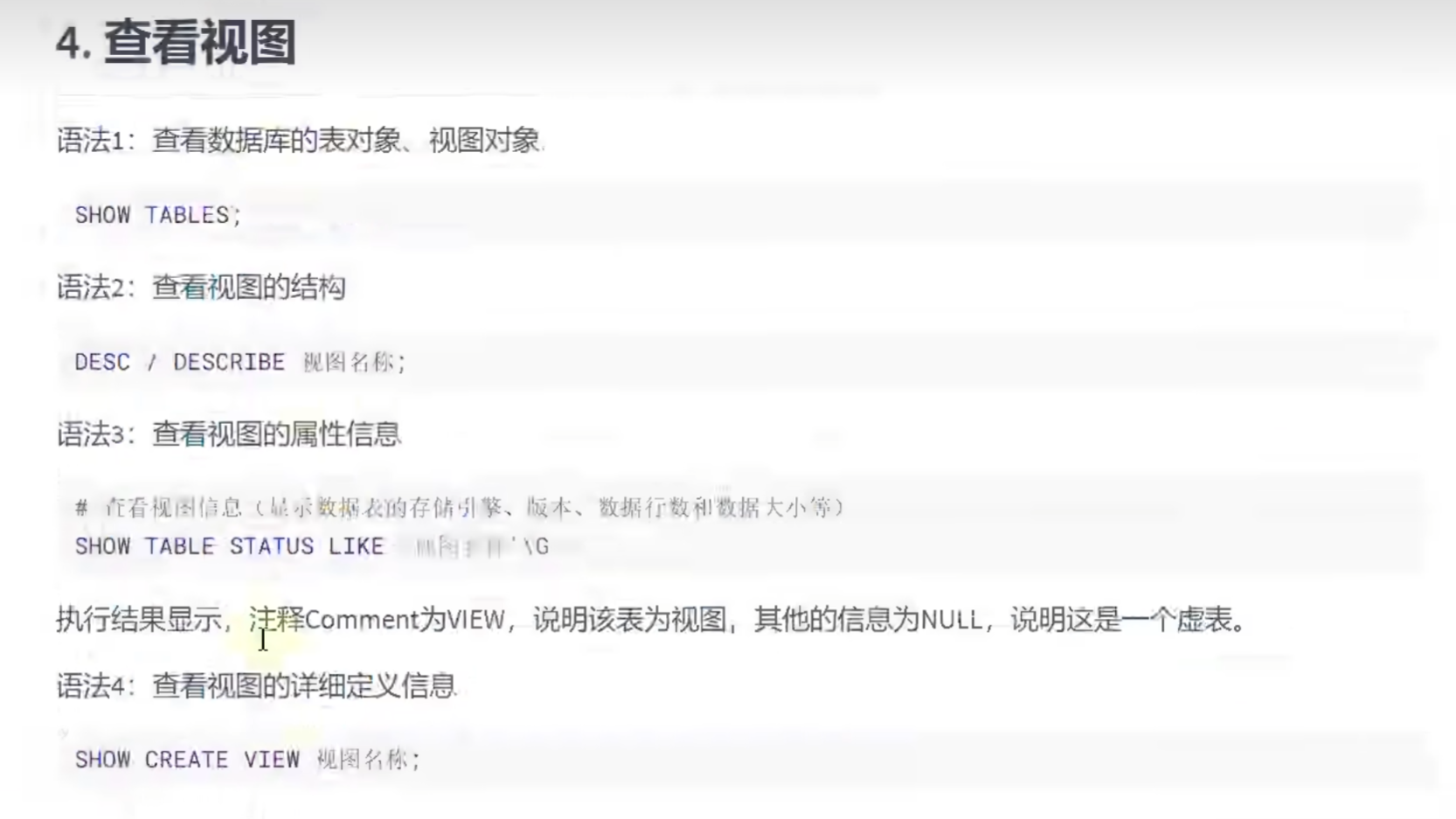
# 查看视图
# 查看数据库的表对象,视图对象
SHOW TABLES;
# 查看视图结构
DESC vu_emp1;
# 查看视图的属性信息
SHOW TABLE STATUS LIKE 'vu_emp1'
# 查看视图的详细定义信息
SHOW CREATE VIEW vu_emp1;更新视图的数据和视图的删除
# 更新视图中的数据
UPDATE vu_emp1
SET salary = 20000
WHERE employee_id = 101;
# 更新视图的数据之后,表的数据也会更新
UPDATE emps
SET salary = 10000
WHERE employee_id = 101;
# 同样的,修改了表的数据后,视图的数据也会更新

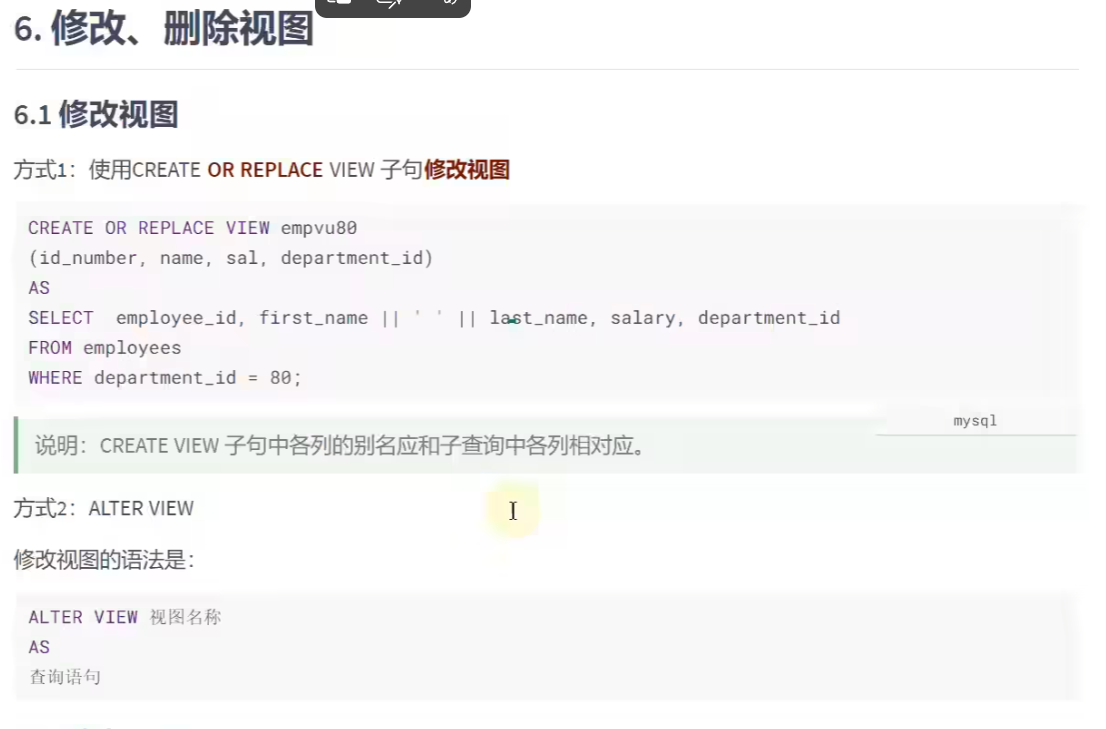
修改视图:
# 更新视图中的数据
UPDATE vu_emp1
SET salary = 20000
WHERE employee_id = 101;
# 更新视图的数据之后,表的数据也会更新
UPDATE emps
SET salary = 10000
WHERE employee_id = 101;
# 同样的,修改了表的数据后,视图的数据也会更新
# 修改视图
# 方式一
CREATE OR REPLACE VIEW vu_emp1
AS
SELECT employee_id,last_name,salary,email
FROM emps
WHERE salary > 10000;
# 方法二
ALTER VIEW vu_emp1
AS
SELECT employee_id,last_name,salary,email,hire_date
FROM emps;
# 6.删除视图
DROP VIEW vu_emp4;
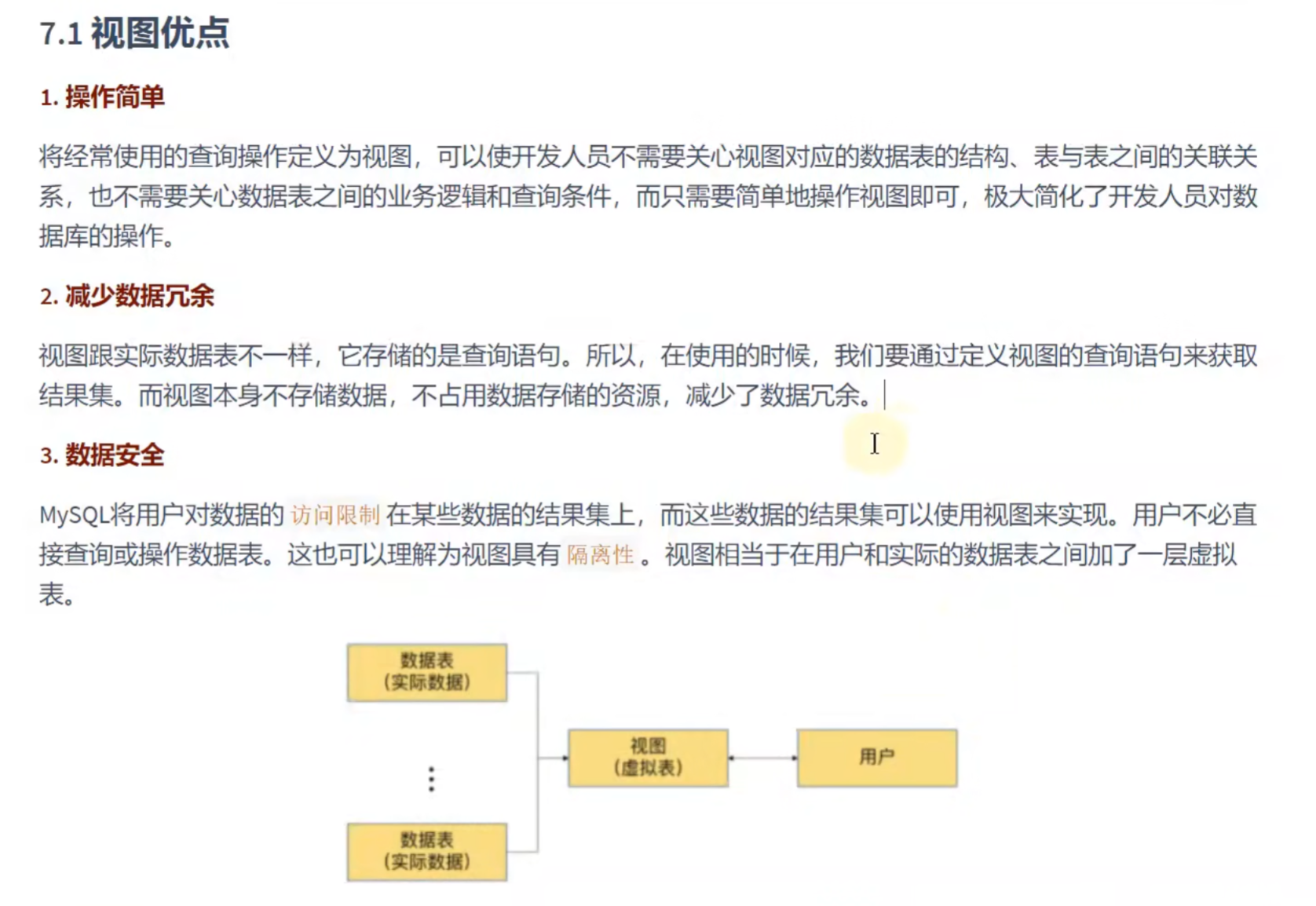
DROP VIEW IF EXISTS vu_emp2,vu_emp3;总结:


课后练习:
# 视图练习
# 1.使用表emps创建视图employee_vu,其中包括姓名(LAST_NAME),员工号(EMPLOYEE_ID),部门号(DEPARTMENT_ID)
CREATE VIEW employee_vu
AS
SELECT last_name,employee_id,department_id
FROM emps
# 显示视图结构
DESC employee_vu;
# 查询视图中的全部内容
SELECT *
FROM employee_vu;
# 将视图中的数据限定在部门号是80的范围内
CREATE OR REPLACE VIEW employee_vu
AS
SELECT last_name,employee_id,department_id
FROM emps
WHERE department_id = 80;
# 练习2:
# 1创建视图emp_v1.要求查询电话号码以011开头的员工姓名和工资,邮箱
CREATE VIEW emp_v1
AS
SELECT last_name,salary,email
FROM emps
WHERE phone_number LIKE '011%';
# 2.要求将视图emp_v1修改为查询电话号码以011开头且邮箱中包含e字符的员工姓名和邮箱,电话号码
CREATE OR REPLACE emp_v1
AS
SELECT last_name,email,phone_number
FROM emps
WHERE phone_number LIKE '011%'
AND email LIKE '%e%';
# 3.向emp_v1插入一条数据,可以吗
# 不一定,添加的数据需要符合创造视图的表的约束
# 4.修改emp_v1中员工的工资,每人涨薪1000
UPDATE emp_v1
SET salary = salary + 1000;
# 5,删除emp_v1中姓名为Olsen的员工
DELETE FROM emp_v1
WHERE `NAME` = 'Olsen';
# 6.创建视图emp_v2,要求查询部门的最高工资高于12000的部门id和其最高工资
CREATE OR REPLACE VIEW emp_v2(department_id,max_sal)
AS
SELECT department_id,MAX(salary)
FROM emp s
GROUP BY department_id
HAVING MAX(salary) > 12000;
# 7.向emp_v2中插入一条数据,是否可以
# 同理,不可以
# 8.删除刚才的emp_v2和emp_v1
DROP VIEW emp_v1,emp_v2;存储过程和函数:

可以先简单理解为把sql语句封装到客户端内存起来,然后通过简短的语句调用这个sql语句,就和函数差不多

分类:

创建存储过程:
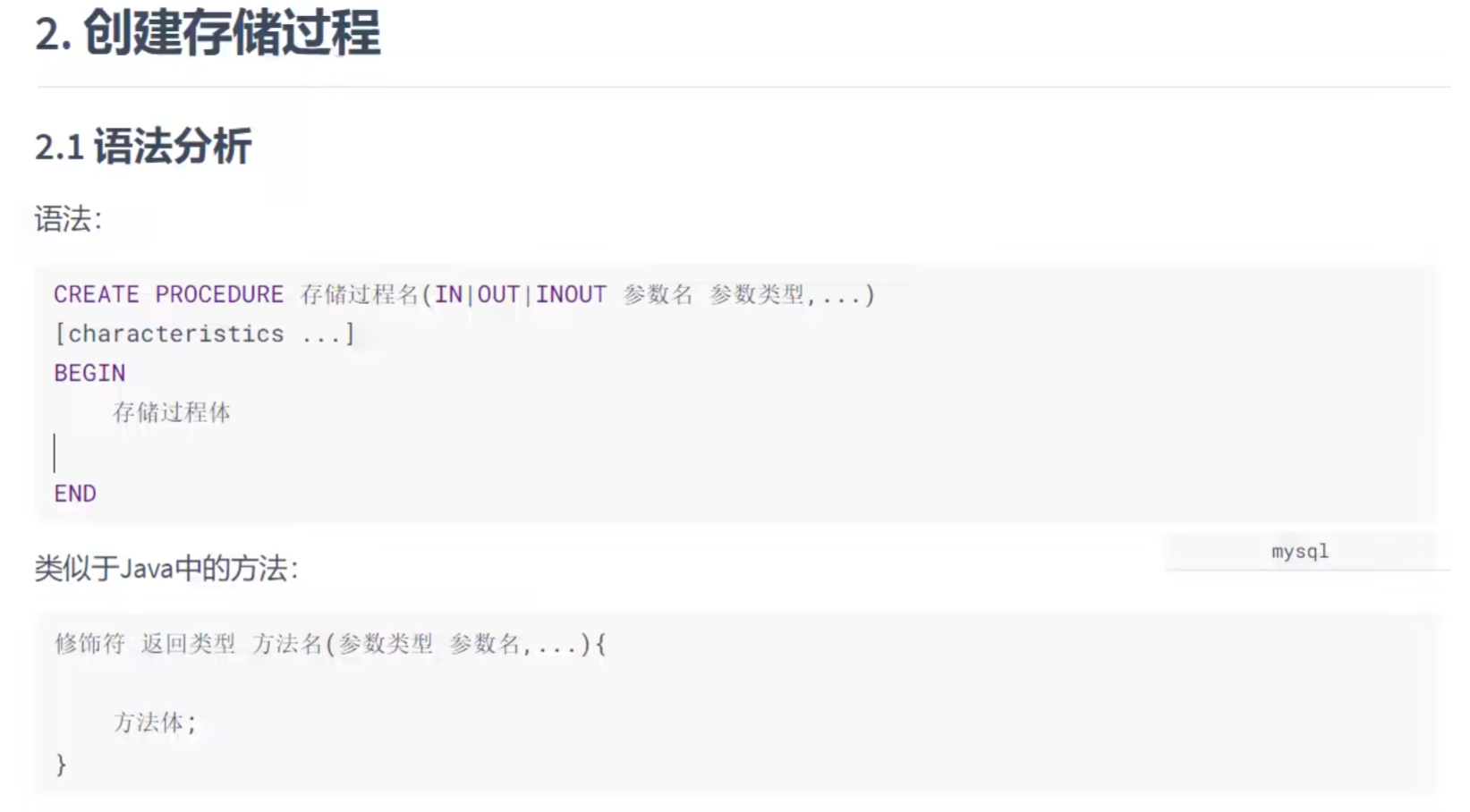



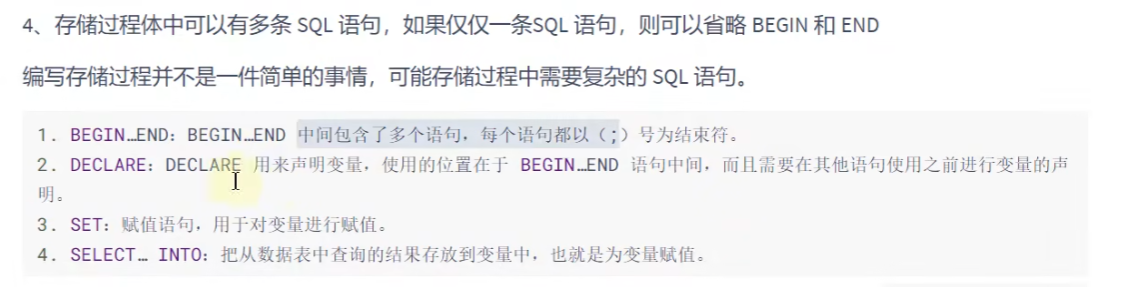
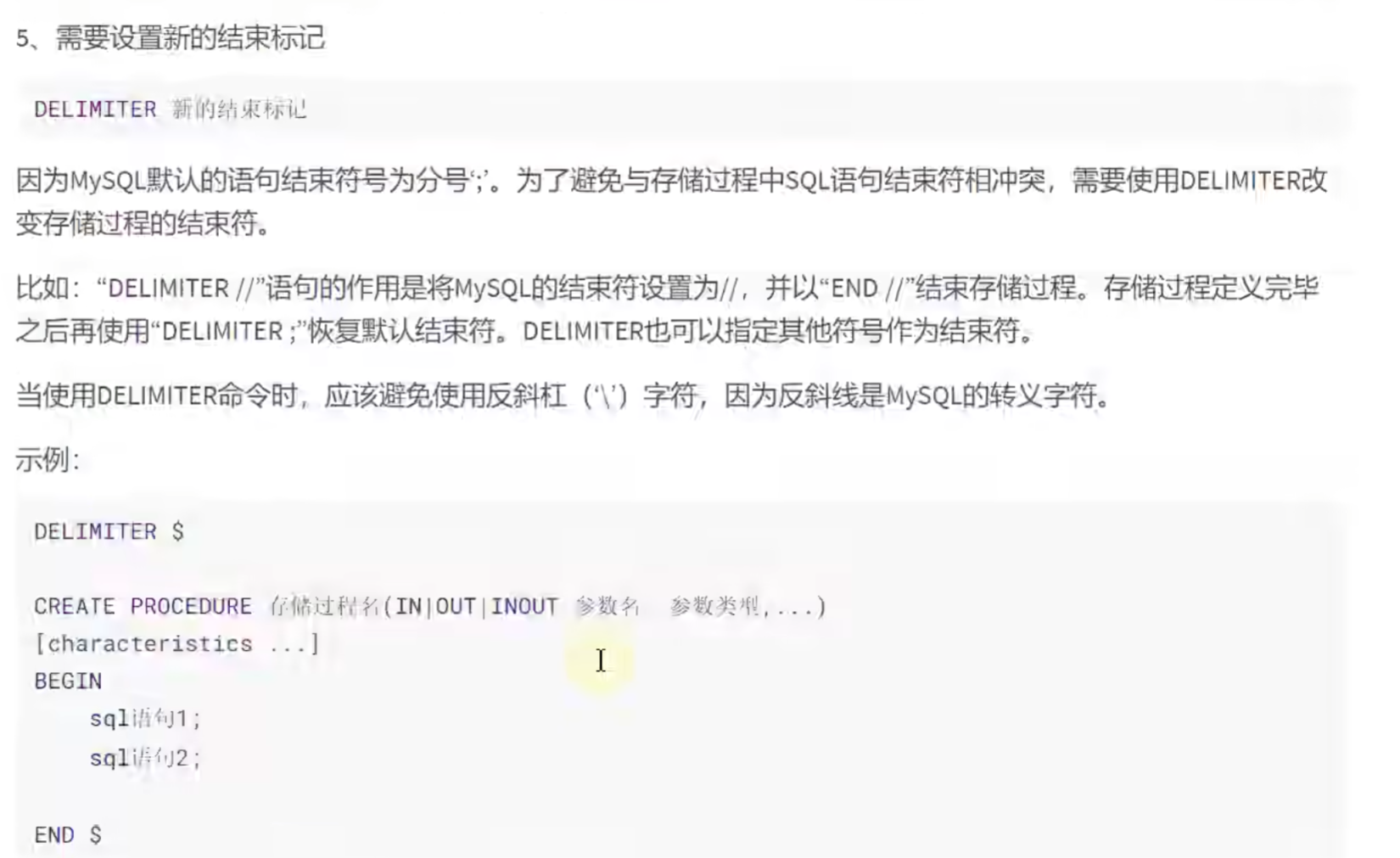
delimiter就是设置新的结束标记,如果不设置就会默认;为结束标记,那么being后面如果碰到;
就被识别为结束了
举例:
# 1.创建存储过程
CREATE DATABASE dbtest15;
USE dbtest15;
CREATE TABLE employees(id INT)
AS
SELECT *
FROM atguigudb.employees;#(没有这个表的数据,假设有这张表)
CREATE TABLE departments
AS
SELECT *
FROM atguigudb.departments;#(也是假设有这张表)
# 1.创建存储过程select_all_data
DELIMITER $
CREATE PROCEDURE select_all_data()
BEGIN
SELECT * FROM employees;
END $
delimiter ;
# 存储过程的调用
CALL select_all_data();
# 2.创建存储过程avg_employee_salary(),返回所有员工的平均工资
delimiter $
CREATE PROCEDURE avg_employee_salary()
BEGIN
SELECT AVG(salary)
FROM employees;
END $
delimiter ;
#调用
CALL avg_employee_salary();
# 3.创建存储过程show_max_salary(),用来查看emps表的最高薪资
delimiter $
CREATE PROCEDURE show_max_salary()
BEGIN
SELECT MAX(salary)
FROM emps;
END $
delimiter ;
# 调用
CALL show_max_salary();
# 类型二:带out
# 创建存储过程show_min_salary(),查看'emps'表的最低薪资,并将最低薪资通过ms输出
delimiter $
CREATE PROCEDURE show_min_salary(OUT ms DOUBLE)#这个参数的类型要和表里数据类型一致
BEGIN
SELECT MIN(salary) INTO ms
FROM emps;
END $
delimiter ;
# 调用
CALL show_min_salary(@ms);
# 创建存储过程show_someone_salary(),查看emps表中某个员工的薪资,并用in参数empname输入员工姓名
delimiter $
CREATE PROCEDURE show_someone_salary(IN empname VARCHAR(20))
BEGIN
SELECT salary FROM employees
WHERE last_name = empname;
END $
delimiter ;
# 调用
CALL show_someone_salary('Abel');
#方式二
SET @empname = 'Abel';
CALL show_someone_salary(@empname);
# 创建存储过程show_someone_salary(),查看'enps'表的某个员工的薪资,并用in参数empname输入员工姓名,用out参数empsalary输出员工薪资
delimiter $
CREATE PROCEDURE show_someone_salary(IN empname VARCHAR(20),OUT empsalary DECIMAL(10,2))
BEGIN
SELECT salary INTO empsalary
FROM emps
WHERE `NAME` = empname;
END $
delimiter ;
# 调用
SET @empname = 'Abel';
CALL show_someone_salary2(@empname,@empsalary);
# 类型五:带INOUT
# 创建存储过程show_mgr_name(),查询某个员工领导的姓名,并用inout参数empname输入员工姓名,输出领导的姓名
delimiter $
CREATE PROCEDURE show_mgr_name(INOUT empname VARCHAR(25))
BEGIN
SELECT last_name
FROM employees
WHERE employee_id = (SELECT manager_id
FROM employees
WHERE last_name = empname);
END $
delimiter ;
# 调用
SET @empname = 'Abel';
CALL show_mgr_name(@empname);存储函数的创建和调用:
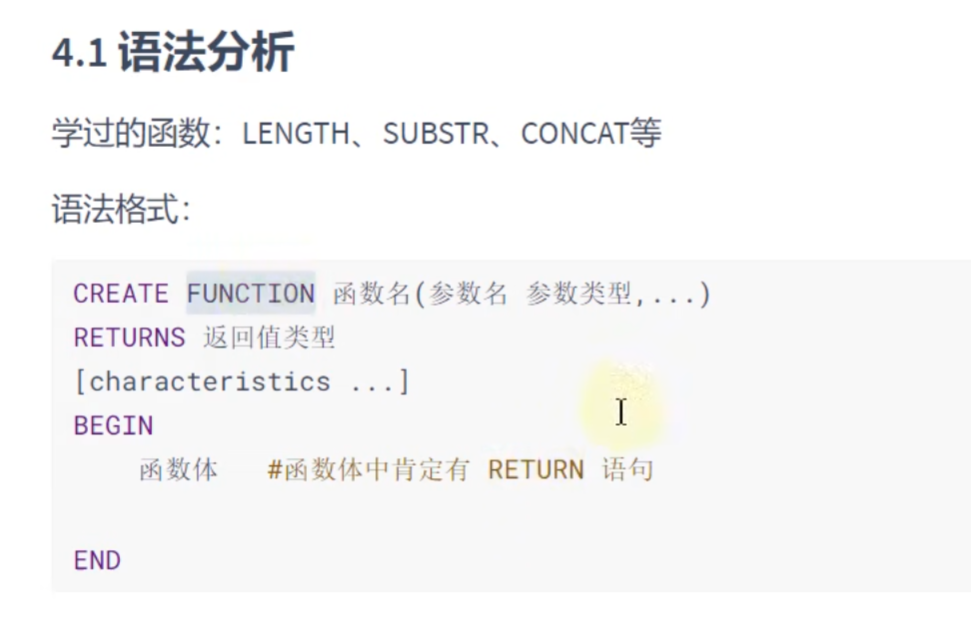


调用:

举例:
# 创建存储函数,名称为email_by_id(),参数传入emp_id,该函数查询emp_id的email并返回,数据类型为字符串型
# 创建函数前执行此语句,保证函数能创建成功
SET GLOBAL log_bin_trust_function_creators = 1;
delimiter $
CREATE FUNCTION email_by_id(emp_id INT)
RETURNS VARCHAR(25)
BEGIN
RETURN (SELECT email FROM employees WHERE employee_id = emp_id);
END $
delimiter ;
# 调用
SELECT email_by_id(101);
# 创建存储函数count_by_id(),参数传入dept_id,该函数查询dept_id部门的员工人数,并返回,数据类型为整型
SET GLOBAL log_bin_trust_function_creators = 1;
delimiter $
CREATE FUNCTION count_by_id(dept_id INT)
RETURNS INT
BEGIN
RETURN (SELECT COUNT(*) FROM employees WHERE department_id = dept_id);
END $
delimiter ;
# 调用
SET @dept_id = 30;
SELECT count_by_id(@dept_id);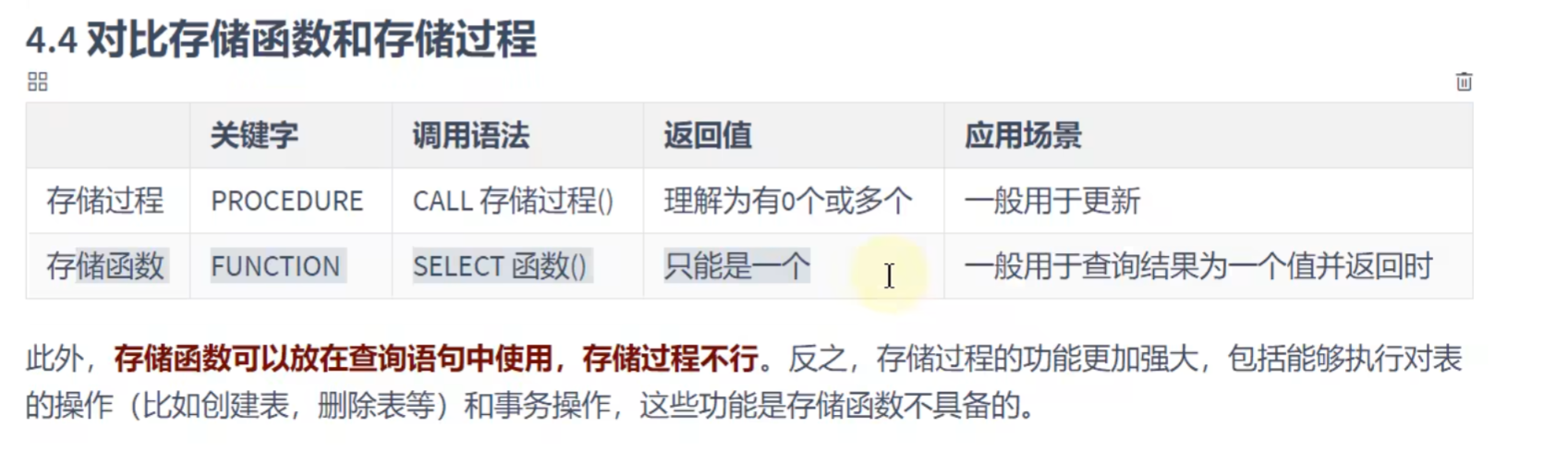
存储过程与函数的查看修改和删除:
查看:
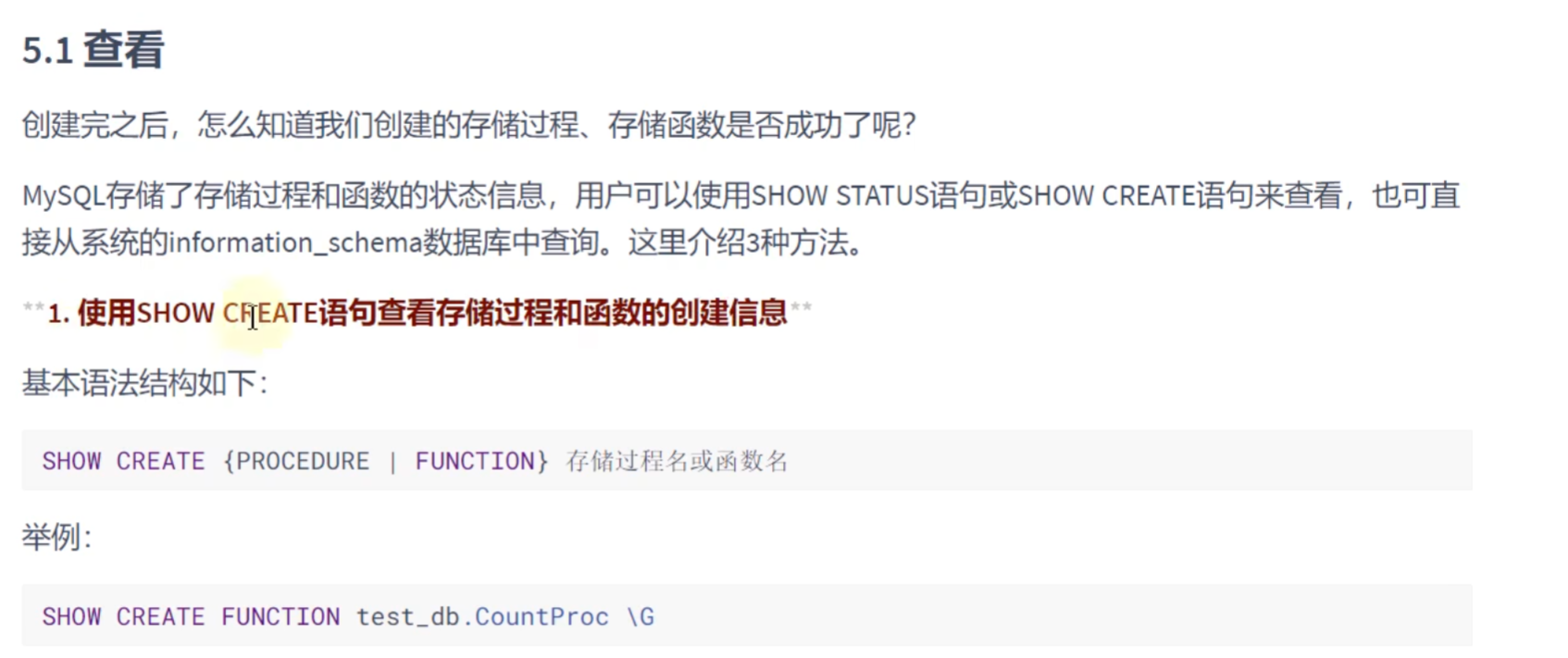
SHOW CREATE PROCEDURE show_mgr_name;
SHOW CREATE FUNCTION count_by_id();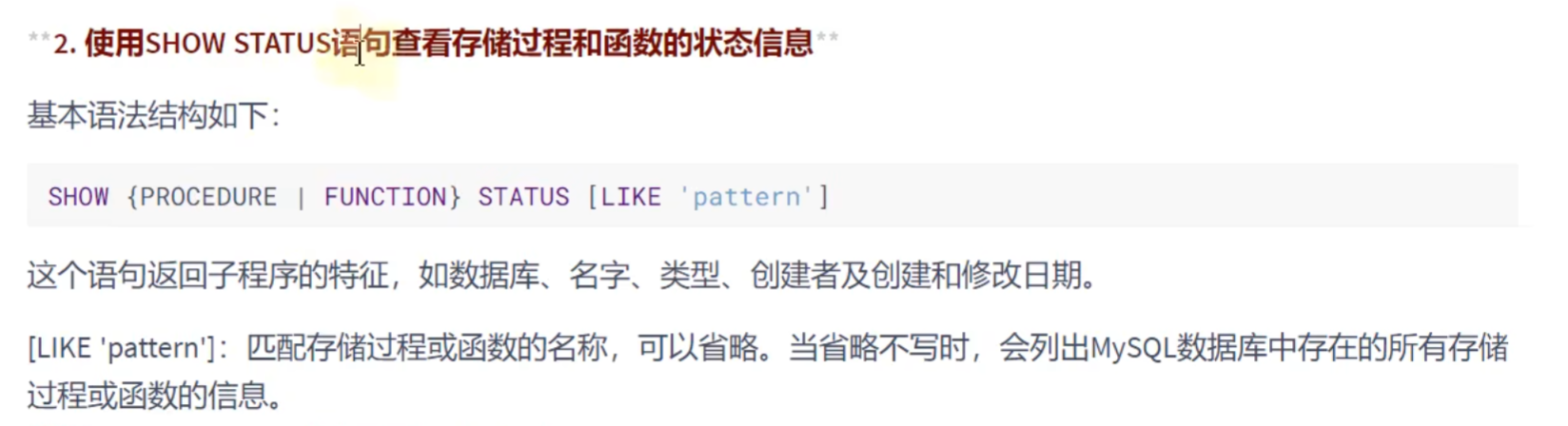
SHOW PROCEDURE STATUS;
SHOW PROCEDURE STATUS LIKE 'show_max_salary';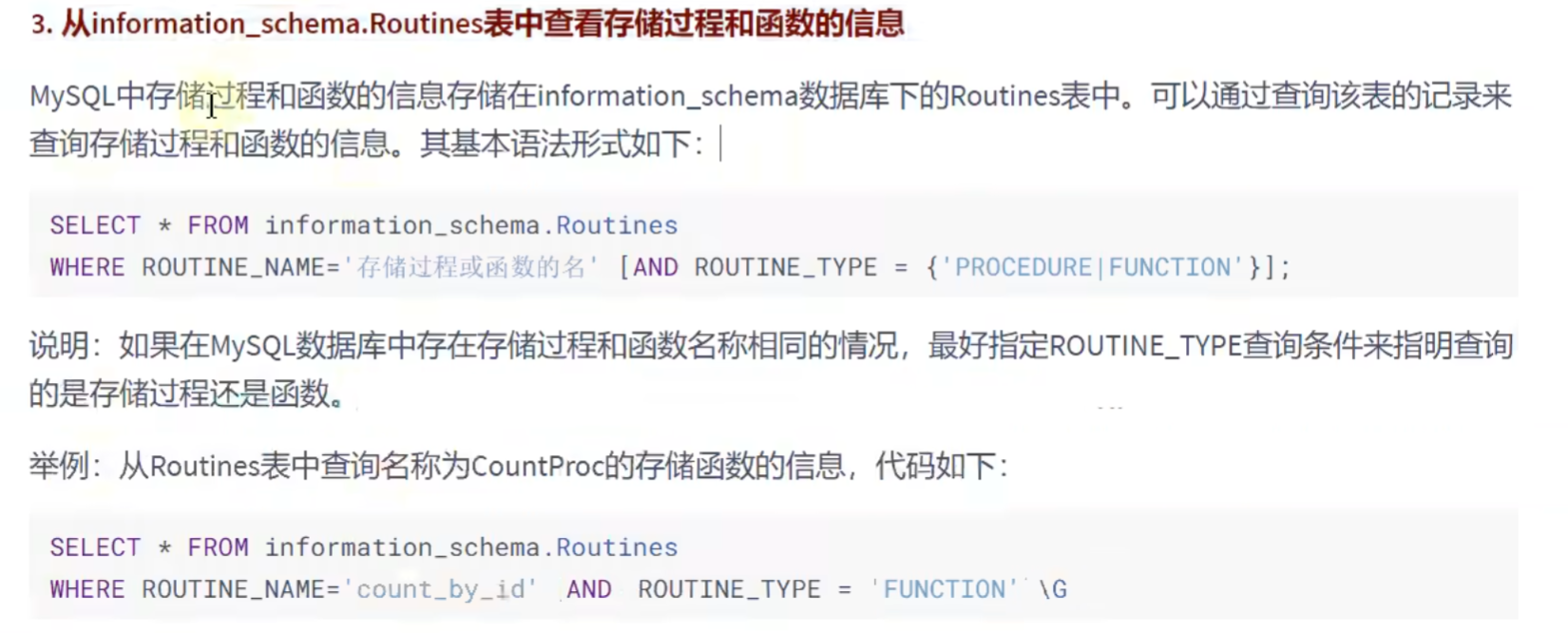
SELECT * FROM information_schema.ROUTINES
WHERE ROUTINE_NAME = 'email_by_id';修改:
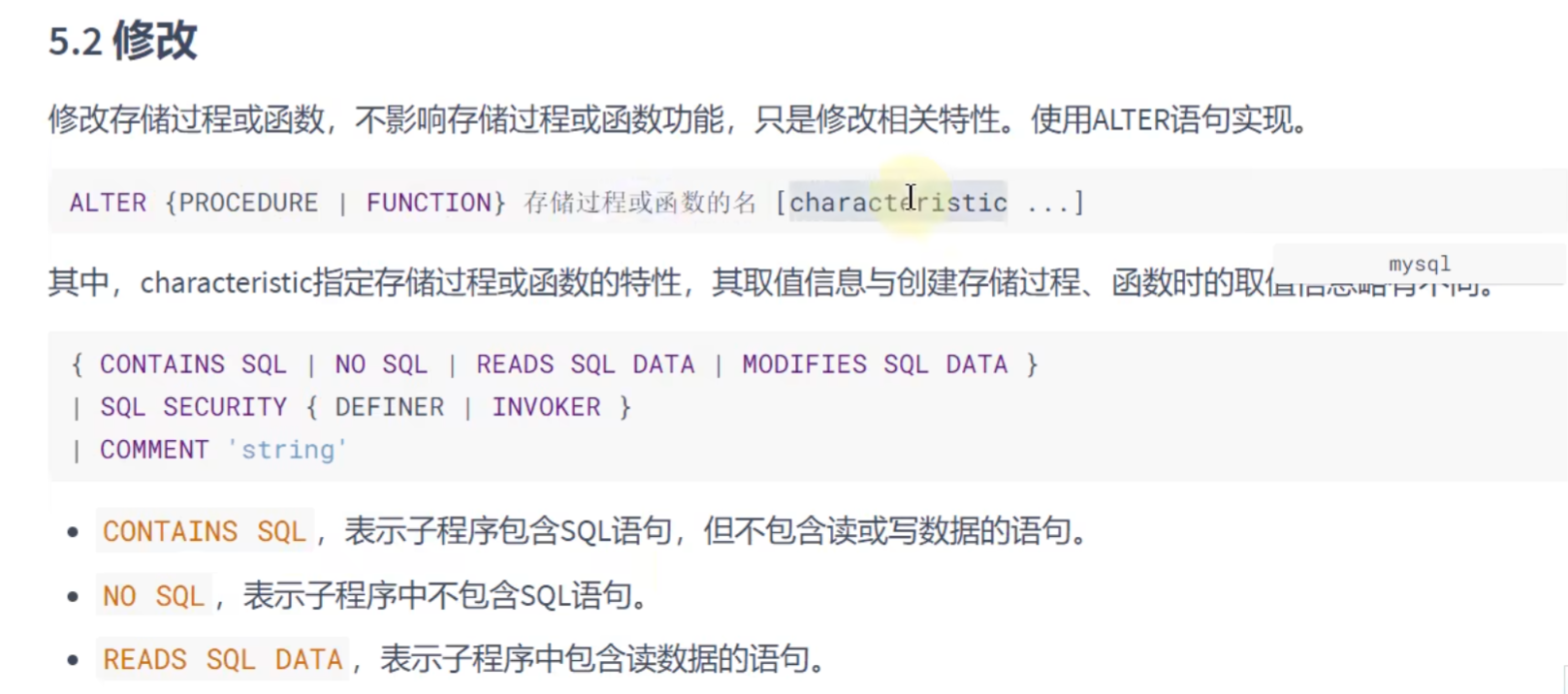
这个修改只是修改相关特性,不修改函数体
ALTER PROCEDURE show_max_salary
SQL SECURITY INVOKER
COMMENT '查询最高工资';删除:

# 删除
DROP FUNCTION IF EXISTS count_by_id;
DROP PROCEDURE IF EXISTS show_min_salary;
课后练习:
# 课后练习
CREATE DATABASE test15_pro_func;
USE test15_pro_func;
# 1.创建存储过程insert_user(),实现传入用户名和密码,插入到adimin表中
CREATE TABLE admin(
id INT PRIMARY KEY AUTO_INCREMENT,
user_name VARCHAR(15) NOT NULL,
pwd VARCHAR(25) NOT NULL
);
delimiter $
CREATE PROCEDURE inser_user(IN user_name VARCHAR(15),IN pwd VARCHAR(25))
BEGIN
INSERT INTO admin(user_name,pwd)
VALUES (user_name,pwd);
END $
delimiter ;
SELECT * FROM admin;
# 调用
CALL inser_user('Tom','abc123');
# 2.创建存储过程get_phone(),实现传入女神编号,返回女神姓名和女生电话
CREATE TABLE beauty(
id INT PRIMARY KEY AUTO_INCREMENT,
`NAME` VARCHAR(15) NOT NULL,
phone VARCHAR(15) UNIQUE,
birth DATE
);
INSERT INTO beauty(`NAME`,phone,birth)
VALUES
('朱茵','123442421','1982-02-12'),
('孙燕姿','124235345','1980-12-09'),
('田福映','2341412345','1989-02-03'),
('邓紫棋','15421354112','1987-09-21'),
('六拖影','12454345','1989-04-22'),
('绫波丽','1234234523','2006-03-10');
SELECT * FROM beauty;
DROP PROCEDURE IF EXISTS get_phone;
delimiter $
CREATE PROCEDURE get_phone(IN in_id INT,OUT `NAME` VARCHAR(15),OUT phone VARCHAR(15))
BEGIN
SELECT b.`NAME`,b.phone INTO `NAME`,phone
FROM beauty b
WHERE b.id = in_id;
END $
delimiter ;
SHOW PROCEDURE STATUS LIKE 'get_phone';
# 调用
CALL get_phone(3,@name,@phone);
SELECT @name,@phone;
# 创建存出过程date_diff(),实现传入两个女神生日,返回日期间隔大小
delimiter $
CREATE PROCEDURE date_diff(IN birth1 DATE,IN birth2 DATE,OUT diff INT)
BEGIN
SELECT DATEDIFF(birth1,birth2) INTO diff;
END $
delimiter ;
# 调用
SET @birth1 = '1982-02-12';
SET @birth2 = '2006-03-10';
CALL date_diff(@birth2,@birth1,@diff);
SELECT @diff;
# 4.创建存储过程format_date(),实现传入一个数据,格式化成xx年xx月并返回
delimiter $
CREATE PROCEDURE format_date(IN my_date DATE,OUT str_date VARCHAR(25))
BEGIN
SELECT DATE_FORMAT(my_date, '%y年%m月%d日') INTO str_date;
END $
delimiter ;
# 调用
CALL format_date(CURDATE(),@str);
SELECT @str;
# 5.创建一个存储过程beauty_limit(),根据传入的起始索引和条目数,查询女神表的记录
delimiter $
CREATE PROCEDURE beauty_limit(IN num1 INT,IN num2 INT)
BEGIN
SELECT * FROM beauty LIMIT num1,num2;
END $
delimiter ;
# 调用
CALL beauty_limit(2,3);
# 创建inout模式参数的存储过程
# 6.传入a和b两个值,最终a和b都翻倍并返回
delimiter $
CREATE PROCEDURE double_number(INOUT a INT,INOUT b INT)
BEGIN
SET a = a * 2;
SET b = b * 2;
END $
delimiter ;
# 调用
SET @a = 22,@b = 44;
CALL double_number(@a,@b);
SELECT @a,@b;
# 7.删除2题目5的存储过程
DROP PROCEDURE IF EXISTS beauty_limit;
# 8.查看题目6存储过程的信息
SHOW CREATE PROCEDURE double_number;
SHOW PROCEDURE STATUS LIKE 'douber_number';
#存储函数的练习
USE tset15_pro_func;
CREATE TABLE employees
AS
SELECT * FROM atguigudb.`employees`;
CREATE TABLE departments
AS
SELECT * FROM atguigudb.`departments`;
# 1.创建函数get_count(),返回公司的员工个数
SET GLOBAL log_bin_trust_function_creators = 1;
delimiter $
CREATE FUNCTION get_count()
RETURNS INT
BEGIN
RETURN (SELECT COUNT(*) FROM employees));
END $
delimiter ;
# 调用
SELECT get_count();
# 2.创建函数ename_salary(),根据员工姓名,返回他的工资
delimiter $
CREATE FUNCTION ename_salary(emp_name VARCHAR(15))
RETURNS DOUBLE
BEGIN
RETURN (SELECT salary FROM employees WHERE last_name = empname);
END$
delimiter ;
# 调用
SELECT ename_salary('Abel');
# 创建函数dept_sal(),根据部门名,返回该部门的平均工资
SET GLOBAL log_bin_trust_function_creators = 1;
delimiter $
CREATE FUNCTION dept_sal(department_name VARCHAR(15))
RETURNS DOUBLE
BEGIN
RETURN (
SELECT AVG(salary)
FROM employees e JOIN departments d
ON e.department_id = d.department_id
WHERE d.department_name = e.department_name;
);
END $
delimiter ;
# 调用
SELECT dept_sal('Marketing');
# 4。创建函数add_float(),实现传入两个float,返回两个之和
SET GLOBAL log_bin_trust_function_creators = 1;
delimiter $
CREATE FUNCTION add_float(f1 FLOAT,f2 FLOAT)
RETURNS FLOAT
BEGIN
RETURN (SELECT f1 + f2);
END $
delimiter ;
# 调用
SELECT add_float(12.2,2.3);变量:

系统变量:
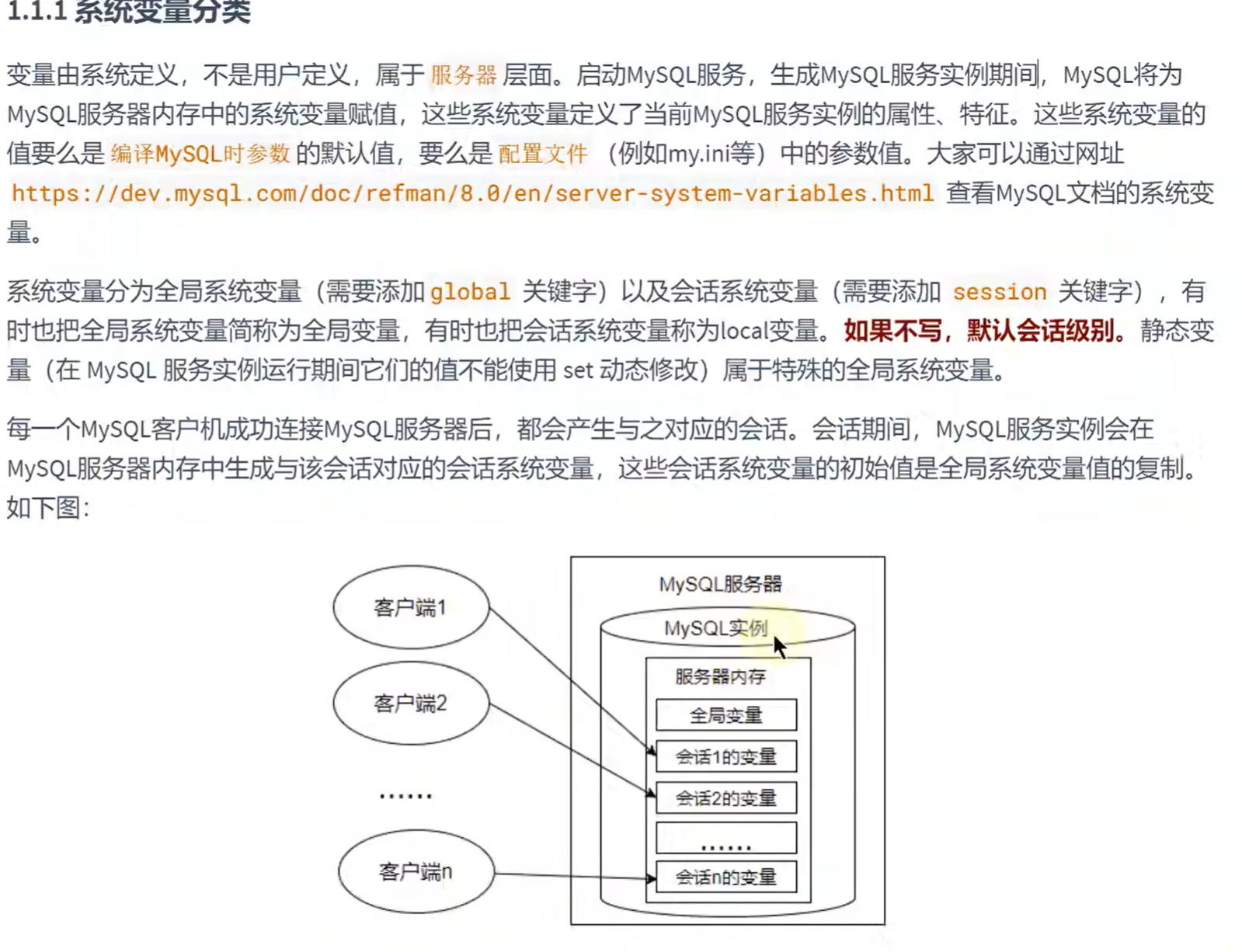

查看变量:(用show)

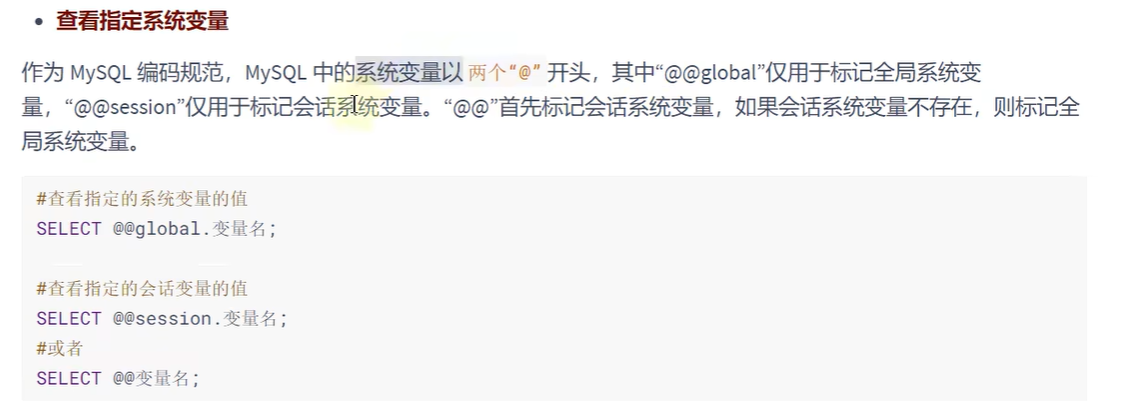
查看指定系统变量:(用select)
修改系统变量的值:
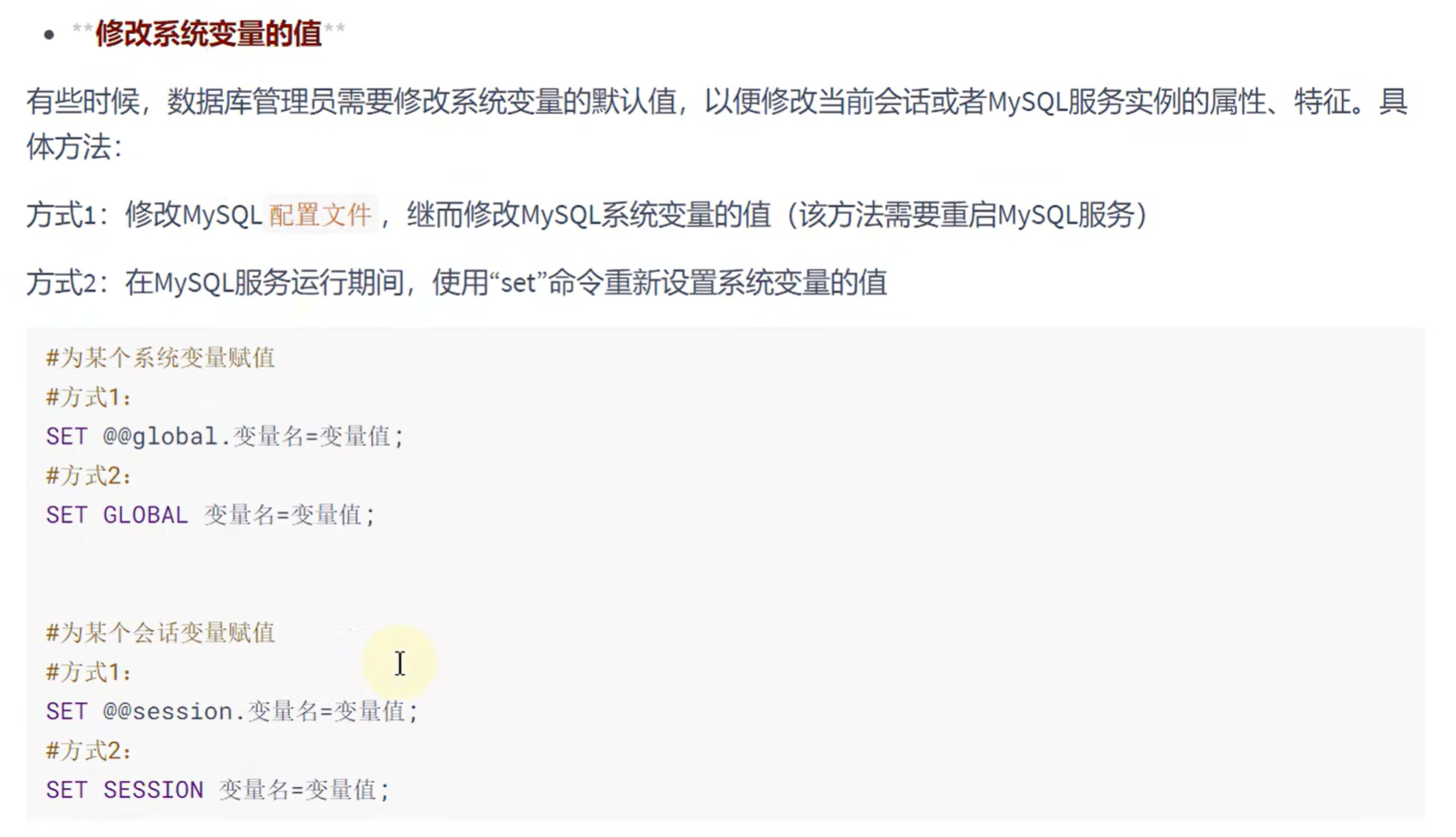
方式二只对当前的数据库起作用,如果重启数据库后,系统变量会变成原来的值
会话级别的变量修改同理
修改会话级别的变量只针对当前会话有效,如果重启一个会话,那么就会重新变成默认值
用户变量:

变量的定义:

局部变量:

# 会话用户变量:
CREATE DATABASE dbtest16;
USE dbtest16;
CREATE TABLE employees
AS
SELECT * FROM atlguigudb.employees;
CREATE TABLE departments
AS
SELECT * FROM atguigudb.departments;
# 假设这两张表存在
#测试
SET @m1 = 1;
SET @m2 = 2;
SET @sum = @m1 + @m2;
SELECT @sum;
# 方式2:
SELECT @count := COUNT(*) FROM employees;
SELECT @count;
SELECT AVG(salary) INTO @avg_sal
FROM employees;
SELECT @avg_sal;
#局部变量
# 局部变量必须 1:使用declare声明,
# 2:声明并使用在begin END中(就是使用在存储过程和函数中)
# 3.declare的方式声明局部变量必须声明在begin中的首行位置
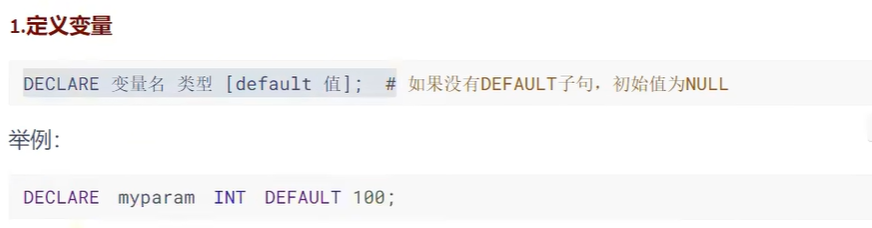
# 声明格式:
# DECLARE 变量名 类型 [default 值]; 如果没有DEFAULT子句,初始值为NULL
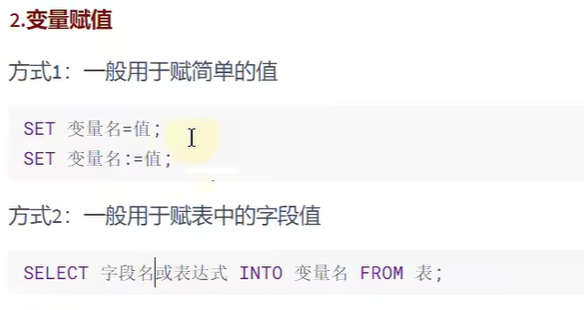
# 赋值方式:
# 1:set 变量名 = 值
# 或者 set 变量名 := 值
# 2:select 字段名或表达式INTO 变量名 from 表;
# 4:使用select局部变量名
# 举例
delimiter $
CREATE PROCEDURE test_var()
BEGIN
DECLARE a INT DEFAULT 0;
DECLARE b INT;
DECLARE emp_name VARCHAR(25);
#赋值
SET a = 1;
SET b := 2;
SELECT last_name INTO emp_name FROM employees WHERE employee_id = 101;
# 使用
SELECT a,b,emp_name;
END $
delimiter ;
# 调用存出过程
CALL test_var();练习:
# 练习1:声明局部变量,并分别赋值employees表中employee_id为102的last_name和salary
delimiter $
CREATE PROCEDURE test_var1()
BEGIN
DECLARE emp_name VARCHAR(25);
DECLARE emp_salary DOUBLE(10,2) DEFAULT 0.0;
SELECT last_name INTO emp_name FROM employees WHERE employee_id = 102;
SELECT salary INTO emp_salary FROM employees WHERE employee_id = 102;
SELECT emp_name,emp_salary;
END $
delimiter ;
CALL test_var1();
# 练习2:声明两个变量,求和并打印(分别使用会话用户变量,局部变量的方式来实现)
SET @v1 = 10;
SET @v2 = 20;
SET @result = @v1 + @v2;
SELECT @result;
###################################################################
delimiter $
CREATE PROCEDURE test_var3()
BEGIN
DECLARE a,b INT DEFAULT 0;
DECLARE sum INT DEFAULT 0;
SET a = 10;
SET b = 25;
SET sum = a + b;
SELECT sum;
END $
delimiter ;
CALL test_var3();
# 练习3:创建存储过程different_salary查询某员工和他领导的薪资差距,并用IN参数emp_id接收员工id,用out参数dif_salary输出薪资差距待遇
delimiter $
CREATE PROCEDURE different_salary(IN emp_id INT,OUT dif_salary DOUBLE)
BEGIN
DECLARE emp_salary INT; # 记录员工的工资
DECLARE mgr_id INT; # 记录管理者的id
DECLARE mgr_salary DOUBLE; # 记录管理者的工资
SELECT salary INTO emp_salary FROM employees WHERE employee_id = emp_id;
SELECT manager_id INTO mgr_id FROM employees WHERE employee_id = emp_id;
SELECT salary INTO mgr_salary FROM employees WHERE employee_id = mgr_id;
SET dif_salary = mgr_salary - emp_salary;
SELECT dif_salary;
END $
delimiter ;
SET @dif_salary = 0;
CALL different_salary(11,@dif_salary);
SELECT @dif_salary;对比用户会话变量和局部变量:

程序出错的处理机制:
定义条件(给错误取名字):

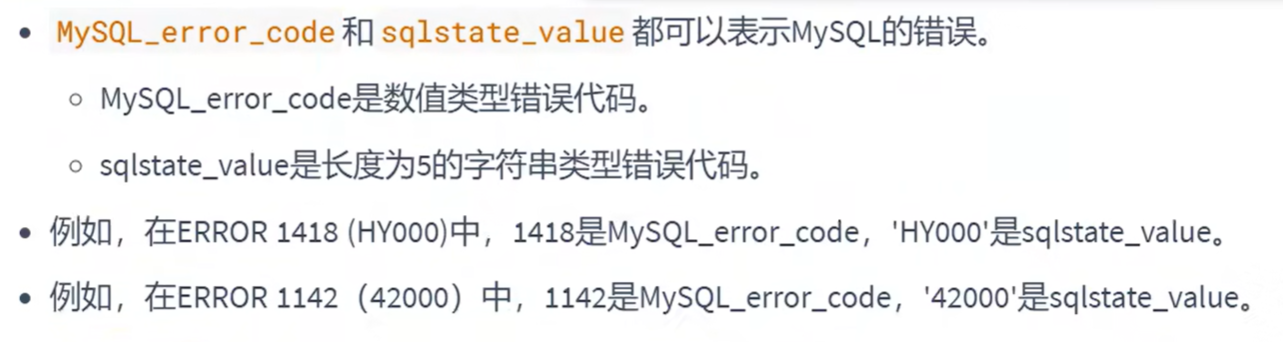
错误码的说明:
举例:
# 定义条件(就是给错误取个名字)
# 方式一:使用MySQL_error_code
DECLARE Field_Not_Be_NULL CONDITION FOR 1048; #使用这种方式直接在for后面接四个数字就可以
# 方式二:使用sqlstate_value
DECLARE Field_Not_Be_NULL CONDITION FOR SQLSTATE '23000'; # 这种方式是五个数字,并且for后面要加sqlstate这个修饰词
# 举例 : 定义ERROR 1148(42000)错误,名称为command_not_allowed
DECLARE command_not_allowed CONDITION FOR 1148;
DECLARE command_not_allowed CONDITION FOR SQLSTATE '42000';定义处理程序:

处理方式,错误类型,处理语句:


定义处理程序方式:
# 定义处理程序方式:
# 方法一:捕获sqlstate_value
DECLARE CONTINUE HANDLER FOR SQLSTATE '42S02' SET @info = 'NO_SUCH_TABLE';
# 方法二:捕获mysql_error_value
DECLARE CONTINUE HANDLER FOR 1146 SET @info = 'NO_SUCH_TABLE';
# 方法三:先定义条件,再调用
DECLARE no_such_table CONDITION FOR 1146;
DECLARE CONDITION HANDLER FOR NO_SUCH_TABLE SET @info = 'NO_SUCH_TABLE';
# 方法四:使用SQLWARNING
DECLARE EXIT HANDLER FOR SQLWARNING SET @info = 'ERROR';
# 方法五:使用NOT FOUND
DECLARE EXIT HANDLER FOR NOT FOUND SET @info = 'NO_SUCH_TABLE';
# 方法六:使用SQLEXCEPRION
DECLARE EXIT HANDLER FOR SQLEXCEPTION SET @info = 'ERROR';举例:
# 案例的处理;
delimiter $
CREATE PROCEDURE UpdateDataNoCondition()
BEGIN
# 声明处理方式
DECLARE CONTINUE HANDLER FOR 1048 SET @prc_value = -1;
SET @x = 1;
UPDATE employees SET email = NULL WHERE last_name = 'Abel';
SET @x = 2;
UPDATE employees SET email = 'aabbel' WHERE last_name = 'Abel';
SET @x = 3;
END $
delimiter ;
# 调用处理过程
CALL UpdateDataNoCondition();
# 定义存储过程
delimiter $
CREATE PROCEDURE InserDataWithCondition()
BEGIN
DECLARE EXIT HANDLER FOR 1062 SET @pro_value = -1;
SET @x = 1;
INSERT INTO departments(department_name) VALUES('测试');
SET @x = 2;
INSERT INTO departments(department_name) VALUES('测试');
SET @x = 3;
END $
delimiter;
CALL InserDataWithCondition();流程控制:

分支:
IF结构:
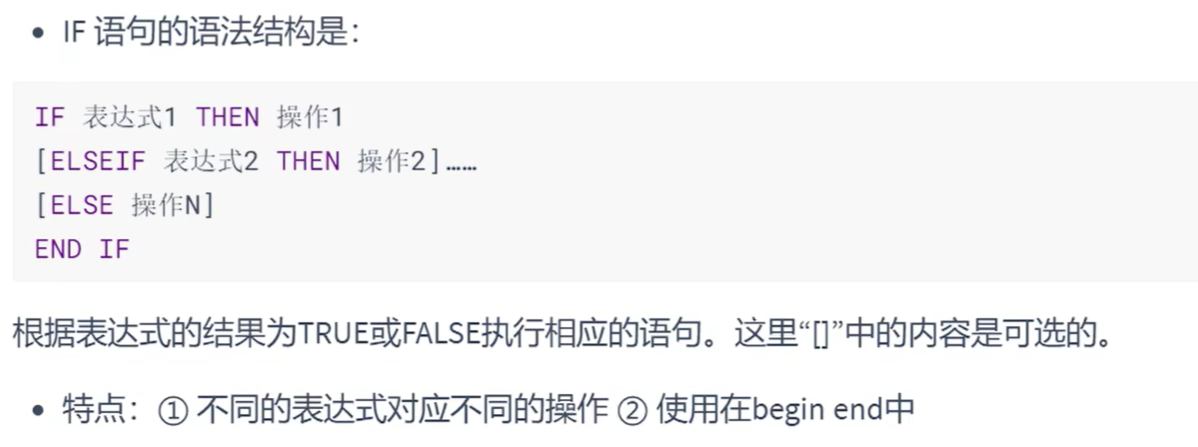
#举例:
delimiter $
CREATE PROCEDURE test_if()
BEGIN
#DECLARE stu_name VARCHAR(15);
#IF stu_name IS NULL
#THEN SELECT 'stu_name is null';
#END IF;
#DECLARE email VARCHAR(25) DEFAULT('aaa');
#IF email IS NULL THEN
#SELECT 'email is null';
#ELSE
#SELECT 'email is not null';
DECLARE age INT DEFAULT 233;
IF age > 350
THEN SELECT '金丹';
ELSEIF age > 150
THEN SELECT '筑基';
ELSEIF age > 100
THEN SELECT '练气';
ELSE SELECT '凡人';
END IF;
END $
delimiter ;
CALL test_if();练习:
# 练习:声明存储过程update_salary_by_eid1,定义in参数emp_id,输入员工编号,判断员工薪资,如果低于8000元并且入职时间超过5年,就涨薪500,否则不变
delimiter $
CREATE PROCEDURE update_salary_by_eid1(IN emp_id INT)
BEGIN
DECLARE emp_sal DOUBLE;#员工的工资
DECLARE emp_hire DATE;#员工入职的时间
SELECT salary INTO emp_sal FROM employees WHERE employee_id = emp_id;
SELECT hire_date INTO emp_hire FROM employees WHERE employee_id = emp_id;
IF emp_sal < 8000 AND DATEDIFF(CURDATE(),emp_hire) > 5 * 365
THEN UPDATE employees SET salary = salary + 500 WHERE employee_id = emp_id;
END IF;
END $
delimiter ;
CALL update_salary_by_eid1(104);
# 声明存储过程update_salary_by_eid3,定义in参数emp_id,输入员工编号,判断该员工薪资如果低于9000元,就更新为9000元,如果薪资大于等于9000元且低于10000元的,但是奖金比例为null的,就更新奖金比例为0.01,其他涨薪100元
delimiter $
CREATE PROCEDURE update_salary_by_eid3(IN emp_id INT)
BEGIN
DECLARE emp_salary DOUBLE;
DECLARE bouns DOUBLE;
SELECT salary INTO emp_salary FROM employees WHERE employee_id = emp_id;
SELECT commission_pct INTO bouns FROM employees WHERE employee_id = emp_id;
IF emp_salary < 9000
THEN UPDATE employees SET salary = 9000 WHERE employee_id = emp_id;
ELSEIF emp_salary >=9000 AND emp_salary < 10000 AND bouns IS NULL
THEN UPDATE employees SET commission_pct = 0.01 WHERE mployee_id = emp_id;
ELSE UPDATE employees SET salary = salary + 100 WHERE employee_id = emp_id;
END IF;
END $
delimiter ;
CALL update_salary_by_eid3(102);CASE结构:

注意:一个是值,一个是判断条件
演示:
# case结构
delimiter $
CREATE PROCEDURE test_case()
BEGIN
# 演示情况一
# DECLARE var INT DEFAULT 2;
# CASE var
# WHEN 1 THEN SELECT 'var = 1';
# WHEN 2 THEN SELECT 'var = 2';
# WHEN 3 THEN SELECT 'var = 3';
# END CASE;
# 演示情况二
DECLARE var1 INT DEFAULT 10;
CASE
WHEN var1 >= 100 THEN SELECT '三位数';
WHEN var1 >= 10 THEN SELECT '两位数';
ELSE SELECT '个位数';
END CASE;
END $
delimiter ;
CALL test_case();题目:
# 举例2:声明存储过程update_salary_ny_eid4,定义in参数emp_id,输入员工编号
# 判断该员工薪资如果低于9000元,就更新薪资为9000,薪资如果大于9000且低于10000的,但是奖金比例为null的,就更新奖金比例为0.01,其他的涨薪100
delimiter $
CREATE PROCEDURE update_salary_ny_eid4(IN emp_id INT)
BEGIN
DECLARE emp_salary DOUBLE;
DECLARE bouns DOUBLE;
SELECT salary INTO emp_salary FROM employees WHERE employee_id = emp_id;
SELECT commission_pct INTO bouns FROM employees WHERE employee_id = emp_id;
CASE
WHEN emp_salary < 9000 THEN UPDATE employees SET salary = 9000 WHERE employee_id = emp_id;
WHEN emp_salary < 10000 AND bouns IS NULL THEN UPDATE employees SET commission_pct = 0.01 WHERE employee_id = emp_id;
ELSE UPDATE employees SET salary = salary + 100 WHERE employee_id = emp_id;
END CASE;
END $
delimiter ;
# 练习3:声明存储过程update_salary_by_eid5,定义in参数emp_id,输入员工编号,
#判断员工的入职年限,如果是0年,薪资涨50,如果是1年,薪资涨100;
# 如果是2年,薪资涨200.如果是三年,薪资涨300,;如果是四年,就涨400,其他涨500
delimiter $
CREATE PROCEDURE update_salary_by_eid5(IN emp_id INT)
BEGIN
DECLARE emp_hire DATE;
DECLARE emp_salary DOUBLE;
SELECT hire_date INTO emp_hire FROM employees WHERE employee_id = emp_id;
CASE TIMESTAMPDIFF(YEAR,emp_hire,CURRENT_DATE())
WHEN 0 THEN UPDATE employees SET salary = salary + 50 WHERE employee_id = emp_id;
WHEN 1 THEN UPDATE employees SET salary = salary + 100 WHERE employee_id = emp_id;
WHEN 2 THEN UPDATE employees SET salary = salary + 200 WHERE employee_id = emp_id;
WHEN 3 THEN UPDATE employees SET salary = salary + 300 WHERE employee_id = emp_id;
WHEN 4 THEN UPDATE employees SET salary = salary + 400 WHERE employee_id = emp_id;
ELSE UPDATE employees SET salary = salary + 500 WHERE employee_id = emp_id;
END CASE;
END $
delimiter ;循环:
LOOP结构:
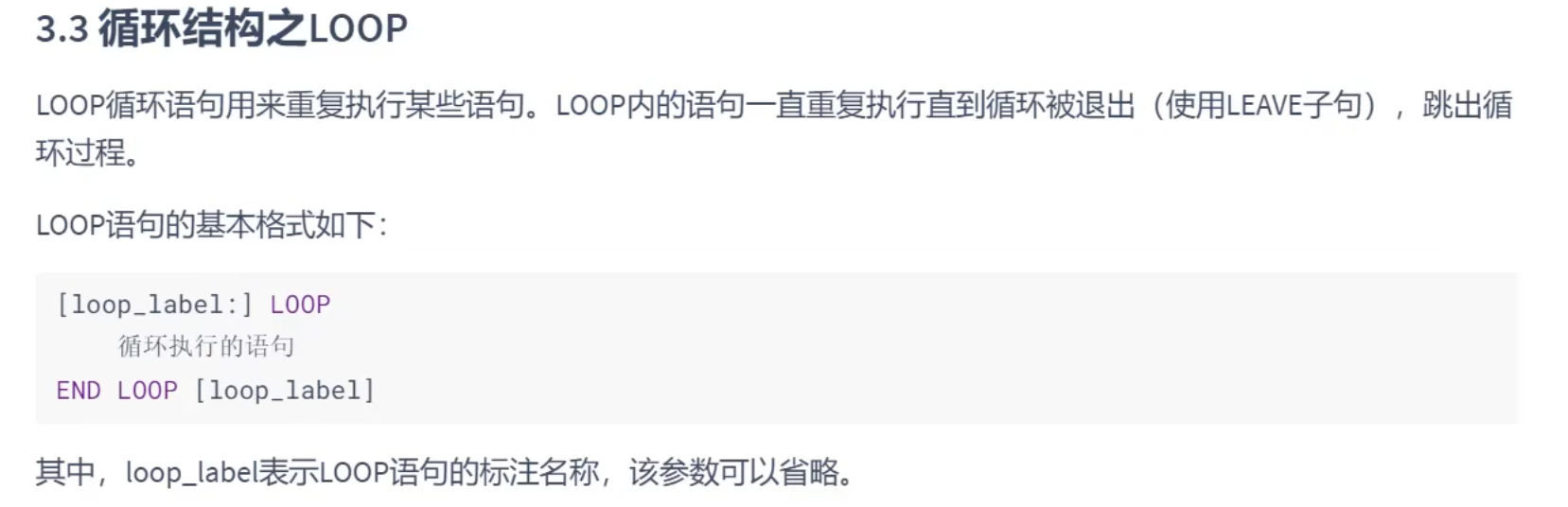

# 举例2
delimiter $
CREATE PROCEDURE update_salary_loop(OUT num INT)
BEGIN
DECLARE avg_sal DOUBLE;
DECLARE loop_count INT DEFAULT 0;
SELECT AVG(salary) INTO avg_sal FROM employees;
loop_label:LOOP
# 判断结束的条件
IF avg_sal >= 12000
THEN LEAVE loop_label;
END IF;
UPDATE employees SET salary = salary * 1.1;
SELECT AVG(salary) INTO avg_sal FROM employees;
SET loop_count = loop_count + 1;
END LOOP loop_label;
SET num = loop_count;
END$
delimiter ;
CALL update_salary_loop(@num);
SELECT @num;WHILE结构:

前面中括号的部分可以省略
举例:
# while循环
# 举例:
delimiter $
CREATE PROCEDURE test_while()
BEGIN
DECLARE num INT DEFAULT 1;
WHILE num <= 10 DO
SET num = num + 1;
END WHILE;
SELECT num;
END$
delimiter ;
CALL test_while();练习:

# 练习:
delimiter $
CREATE PROCEDURE update_salary_while(OUT num INT)
BEGIN
DECLARE avg_sal DOUBLE;
DECLARE while_count INT DEFAULT 0;
SELECT AVG(salary) INTO avg_sal FROM employees;
WHILE avg_sal > 5000 DO
UPDATE employees SET salary = salary * 0.9;
SET while_count = while_count + 1;
SELECT AVG(salary) INTO avg_sal FROM employees;
END WHILE;
SET num = while_count;
END $
delimiter ;
CALL update_salary_while(@num);
SELECT @num;REPEAT结构:
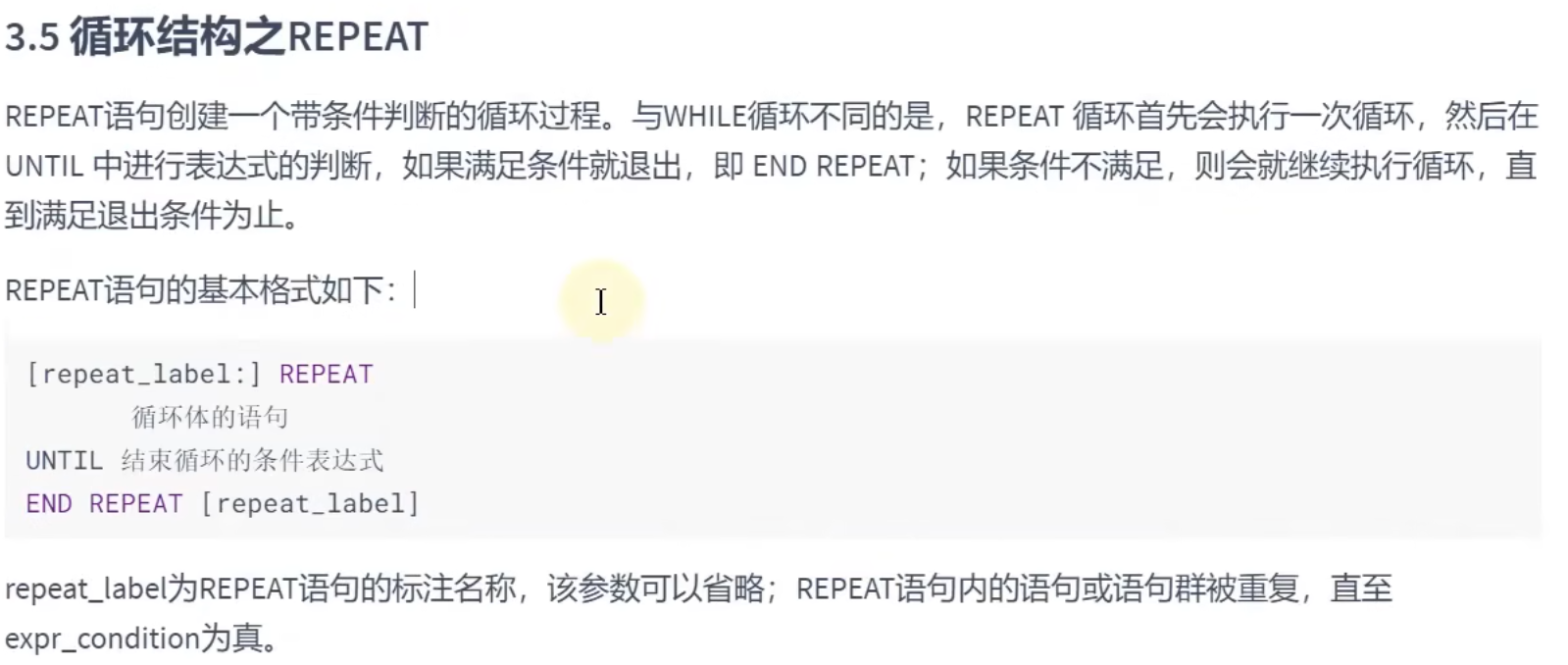
同样的,前面中括号的部分可以省略
举例·:
# 举例:
delimiter $
CREATE PROCEDURE test_repeat()
BEGIN
DECLARE num INT DEFAULT 1;
REPEAT
SET num = num + 1;
UNTIL num = 10 END REPEAT;
SELECT num;
END $
delimiter ;
CALL test_repeat();练习:

delimiter $
CREATE PROCEDURE update_salary_repeat(OUT num INT)
BEGIN
DECLARE avg_sal DOUBLE;
DECLARE repeat_count INT DEFAULT 0;
SELECT AVG(salary) INTO avg_sal FROM employees;
REPEAT
UPDATE employees SET salary = salary * 1.15;
SELECT AVG(salary) INTO avg_sal FROM employees;
SET repeat_count = repeat_count + 1;
UNTIL avg_sal >= 13000 # 这个地方不加分号
END REPEAT;
SELECT num = repeat_count;;
END$
delimiter ;
CALL update_salary_repeat(@num);
SELECT @num;LEAVE和ITERATE的使用:

练习:

delimiter $
CREATE PROCEDURE leave_begin(IN num INT)
begin_label:BEGIN
IF num <= 0 THEN LEAVE begin_label;
ELSEIF num = 1 THEN SELECT AVG(salary) FROM employees;
ELSEIF num = 2 THEN SELECT MIN(salary) FROM employees;
ELSE SELECT MAX(salary) FROM employees;
END IF;
SELECT COUNT(*) FROM employees;
END $
delimiter ;
CALL leve_begin();
while_label:WHILE TRUE DO
IF avg_sal <= 10000 THEN
LEAVE while_label;
END IF;
UPDATE employees SET salary = salary * 0.9;
SELECT AVG(salary) INTO avg_sal FROM employees;
SET while_count = while_count + 1;
END WHILE;
SET num = while_count;
END $
delimiter ;
CALL leave_while(@num);
SELECT @num;ITERATE的使用:
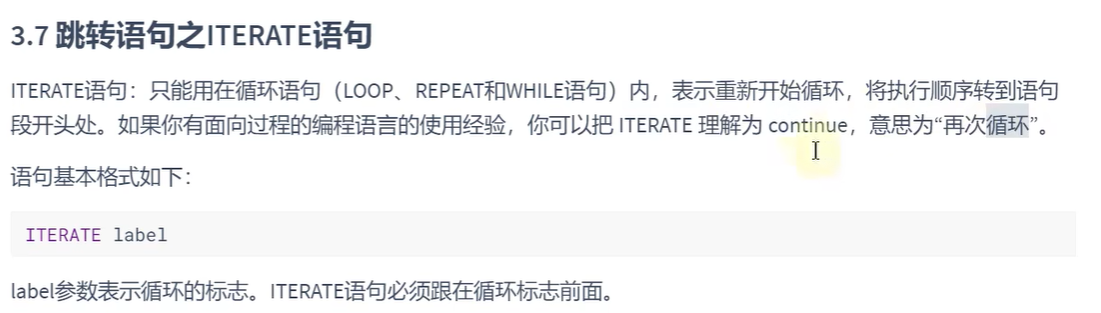

delimiter $
CREATE PROCEDURE test_iterate()
BEGIN
DECLARE num INT DEFAULT 0;
loop_label:LOOP
# 赋值
SET num = num + 1;
IF num < 10
THEN ITERATE loop_label;
ELSEIF num > 15
THEN LEAVE loop_label;
END IF;
END LOOP;
END $
delimiter ;游标的使用:

使用游标的步骤:
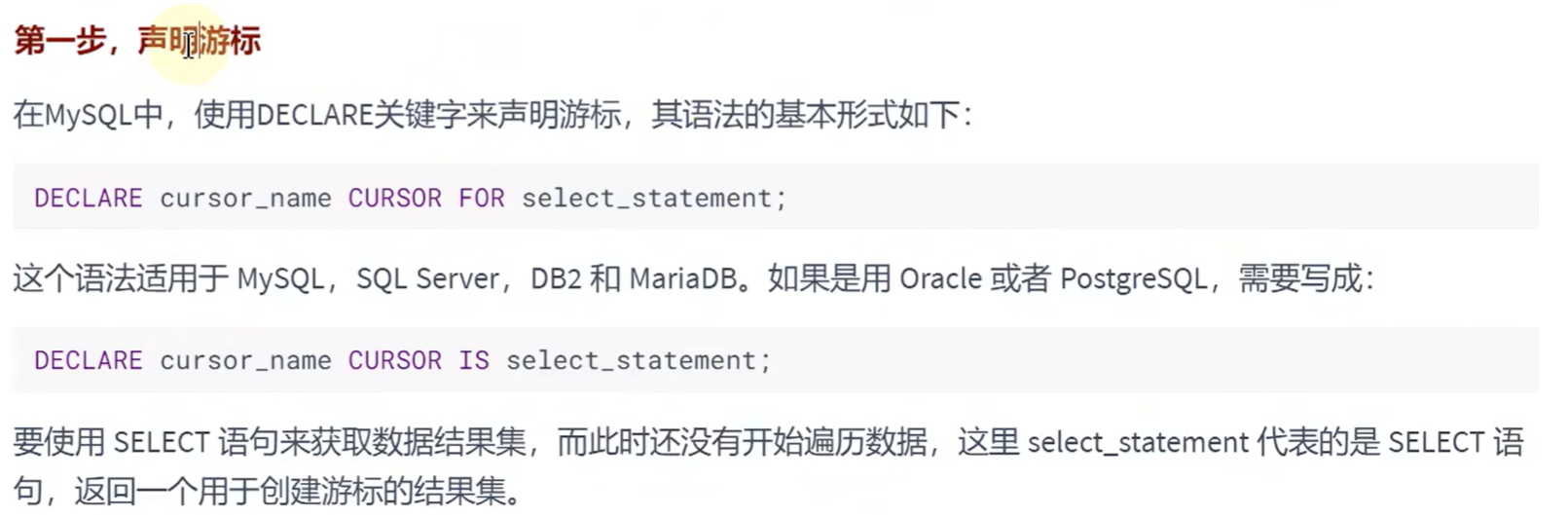

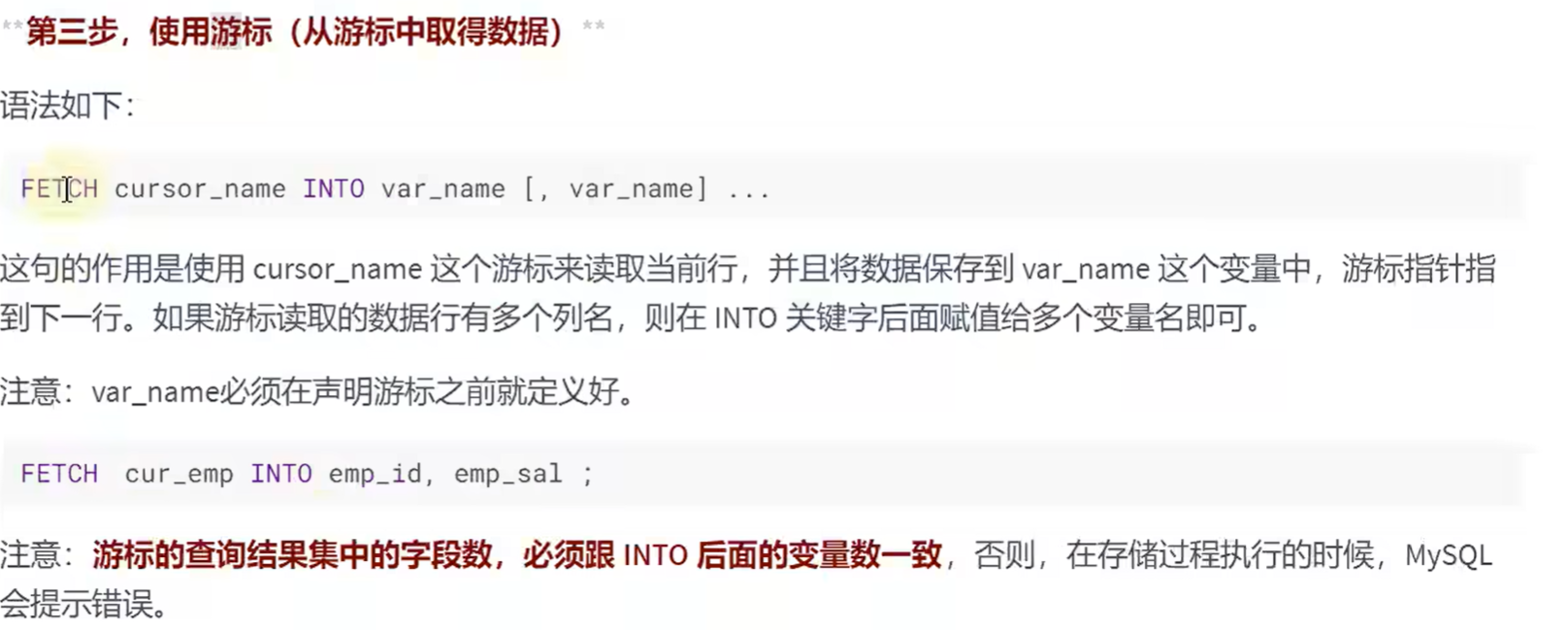

举例:

delimiter $
CREATE PROCEDURE get_count_by_limit_total_salary(IN limit_total_salary DOUBLE,OUT total_count INT)
BEGIN
# 声明局部变量
DECLARE sum_sal DOUBLE DEFAULT 0.0;# 记录累加的工资总额
DECLARE emp_sal DOUBLE; # 记录每个员工的工资
DECLARE emp_count INT DEFAULT 0; #记录累加的人数
# 声明游标
DECLARE emp_coursor CURSOR FOR SELECT salary FROM employees ORDER BY salary DESC;
# 打开
OPEN emp_coursor;
REPEAT
# 使用
FETCH emp_cursor INTO emp_sal;
SET sum_sal = sum_sal + emp_sal;
SET emp_count = emp_count + 1;
UNTIL sum_sal >= limit_total_salary;
END REPEAT;
SET total_count = emp_count;
# 关闭
CLOSE emp_coursor;
END $
delimiter ;
CALL get_count_by_limit_total_salary(30000,@total_count);
SELECT @total_count;
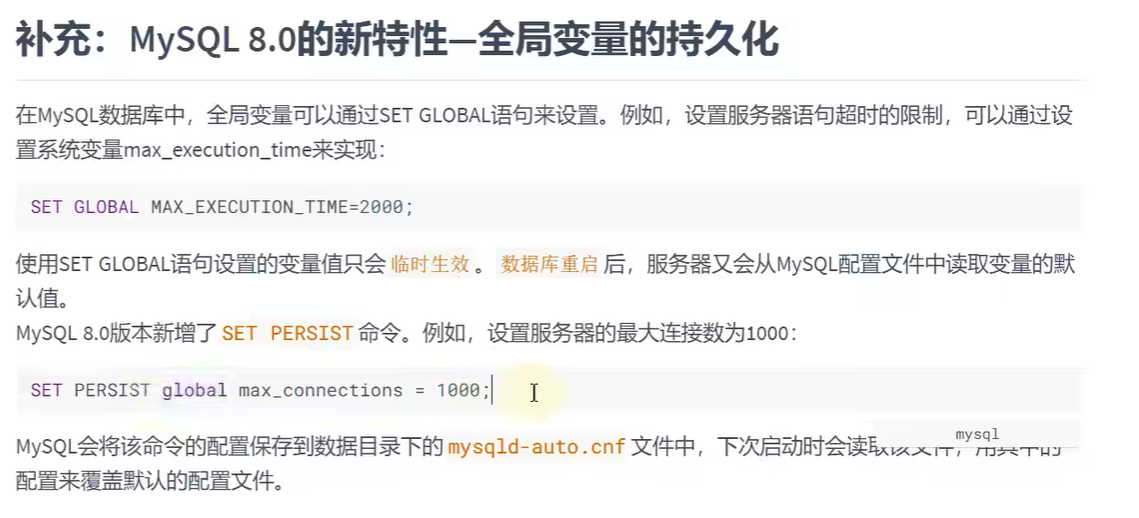
全局变量的持久化:
练习:

# 1
delimiter $
CREATE FUNCTION get_count()
RETURNS INT
DETERMINISTIC
BEGIN
DECLARE emp_num INT;
SELECT COUNT(*) INTO emp_num
FROM employees
RETURN emp_num;
END $
delimiter ;
# 2
delimiter $
CREATE FUNCTION ename_salary(emp_name VARCHAR(25))
RETURNS DOUBLE
DETERMINISTIC
BEGIN
DECLARE emp_salary DOUBLE;
SELECT salary INTO emp_salary
FROM employees
WHERE =employee_name = emp_name;
RETURN emp_salary;
END $
delimiter ;
# 3
delimiter $
CREATE FUNCTION dept_sal(depart_name VARCHAR(25))
RETURNS DOUBLE
BEGIN
DECLARE avg_sal DOUBLE;
SELECT AVG(salary) INTO avg_sal
FROM employees
WHERE department_name = depart_name;
RETURN avg_sal;
END$
delimiter ;
# 4
delimiter $
CREATE FUNCTION add_float(f1 FLOAT,f2 FLOAT)
RETURN FLOAT
BEGIN
DECLARE sum FLOAT;
SET sum = f1 + f2;
RETURN sum;
END $
delimiter ;
# 4.创建函数test_if_case(),实现传入成绩,如果成绩>90,返回a,如果成绩大于80,返回b,如果成绩大于60,返回c,否则为d
#要求:分别使用if和case结构实现
# if结构
delimiter $
CREATE FUNCTION test_if_case(number DOUBLE)
RETURNS CHAR(1)
BEGIN
DECLARE statue CHAR;
IF number > 90 THEN
SET statue = 'a';
ELSEIF number > 80 THEN
SET statue = 'b';
ELSEIF number > 60 THEN
SET statue = 'c' ;
ELSE SET statue = 'd' ;
END IF;
RETURN statue;
END $
delimiter ;
SELECT test_if_case(45);
# case结构
delimiter $
CREATE FUNCTION test_if_case2(score DOUBLE)
RETURNS CHAR
BEGIN
DECLARE score_level CHAR;
CASE
WHEN score > 90 THEN SET score_level = 'A';
WHEN score > 80 THEN SET score_level = 'b';
WHEN score > 60 THEN SET score_level = 'c';
ELSE SET score_level = 'D';
END CASE;
END $
delimiter ;
#创建存储过程test_if_pro(),传入工资值,如果工资值<3000,则删除工资为此值的员工,如果3000<=工资<=5000,则修改此工资值的员工涨薪100,否则张工资50
delimiter $
CREATE PROCEDURE test_if_pro(IN emp_sal DOUBLE)
BEGIN
IF emp_sal < 3000
THEN DELETE FROM employees WHERE salary = emp_sal;
ELSEIF emp_sal >= 3000 AND emp_sal <= 5000
THEN UPDATE employees SET salary = salary + 100 WHERE salary = emp_sal;
ELSE UPDATE employees SET salary = salary + 50 WHILE salary = emp_sal;
END IF;
END $
delimiter ;
# 创建存储过程insert_data(),传入参数in的int类型变量insert_count,实现向admin表中批量插入insert_count条记录
CREATE TABLE admin(
id INT PRIMARY KEY AUTO_INCREMENT,
user_name VARCHAR(25) NOT NULL,
user_pwd VARCHAR(35) NOT NULL
);
delimiter $
CREATE PROCEDURE insert_data(IN insert_count INT)
BEGIN
DECLARE init_count INT DEFAULT 1;
WHILE init_count <= insert_count DO
INSERT INTO admin(user_name,user_pwd)
VALUES (
CONCAT('atguigu_',init_count,ROUND(RAND() * 1000000)),
CONCAT('pwd_',ROUND(RAND() * 1000000) * 100000)
);
SET init_count = init_count + 1;
END WHILE;
END $
delimiter ;
CALL insert_data(100);
SELECT *
FROM admin;
# 1创建存储过程update_salary(),参数1为in的int变量dept_id,表示部门id.参数二为in的int变量change_sal_count,表示要调整薪资的员工个数,查询指定id部门的员工信息,按照salary升序排列,
# 根据hire_date的情况,调整前change_sal_count个员工的薪资
delimiter $
CREATE PROCEDURE update_salary(IN dept_id INT,IN change_sal_count INT)
BEGIN
# 声明变量
DECLARE emp_id INT;#记录员工id
DECLARE emp_hire_date DATE;#记录员工入职时间
DECLARE init_count INT DEFAULT 1;#用于表示循环结构的初始化条件
DECLARE add_sal_rate DOUBLE;#用于记录涨薪的比例
# 声明游标
DECLARE emp_curser CURSOR FOR SELECT employee_id,hire_date FROM employees
WHERE department_id = dept_id ORDER BY salary ASC;
# 打开游标
OPEN emp_cursor ;
WHERE init_count <= change_sal_count DO
#使用游标
FETCH emp_cursor INTO emp_id,emp_hire_date;
IF (YEAR(emp_hire_date) < 1995)
THEN SET add_sal_rate = 1.2;
ELSEIF(YEAR(emp_hire_date) <= 1998)
THEN SET add_sal_rate = 1.15;
ELSEIF(YEAR(emp_hire_date) <= 2001)
THEN SET add_sal_rate = 1.1;
ELSE
THEN SET add_sal_rate = 1.05;
END IF;
UPDATE employees SET salary = salary * add_sal_rate
WHERE employee_id = emp_id;
END WHILE;
SET init_count = init_count + 1;
#关闭游标
CLOSE emp_cursor;
END $
delimiter ;触发器:

简单来说,触发器的作用就是确保操作全部都能执行,保证数据的完整性
创建触发器:
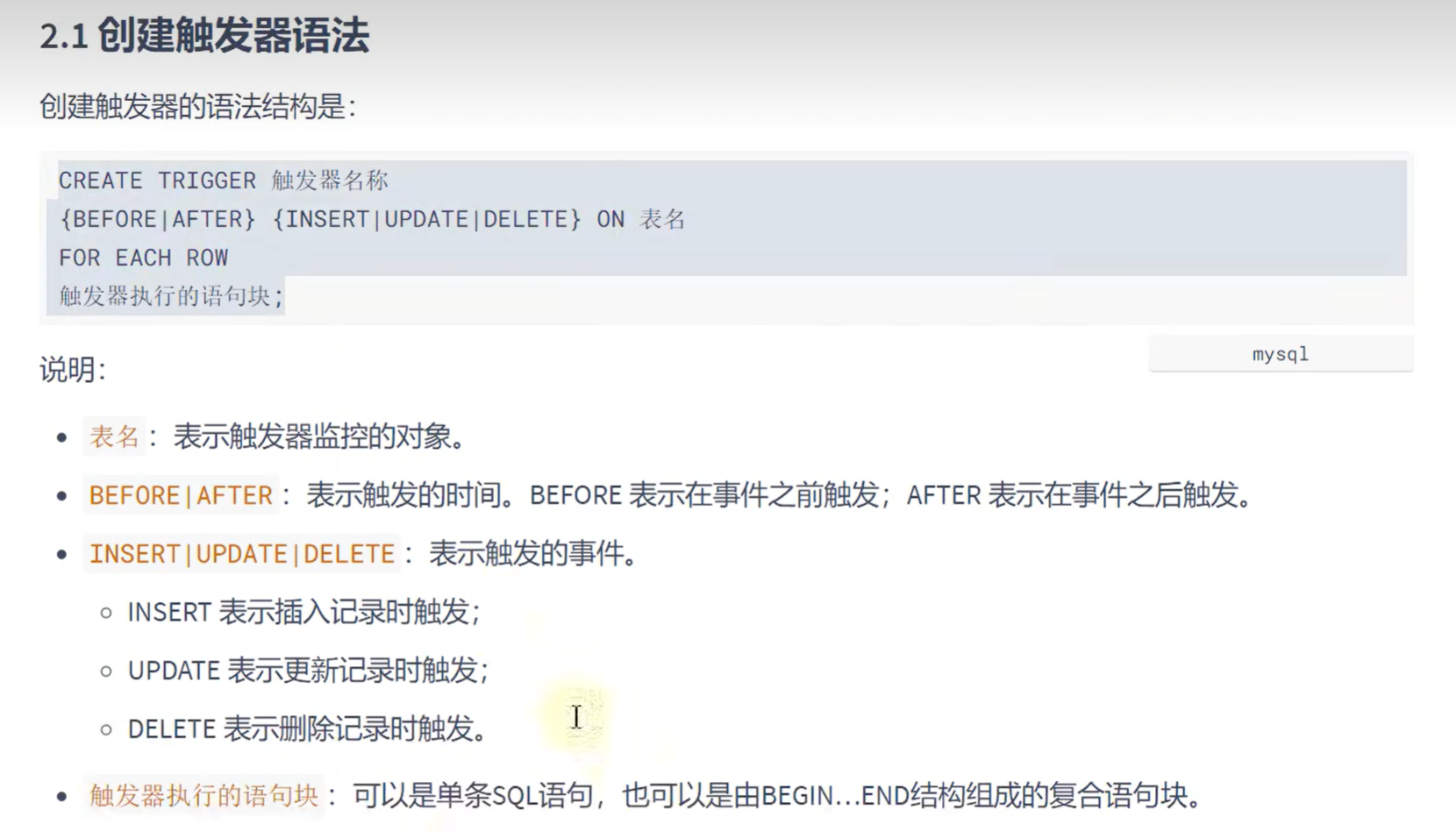
举例:
CREATE TABLE tset_trigger(
id INT PRIMARY KEY AUTO_INCREMENT,
t_note VARCHAR(30)
);
CREATE TABLE test_trigger_log(
id INT PRIMARY KEY AUTO_INCREMENT,
t_log VARCHAR(30)
);
#创建触发器before_insert。向test_trigger数据表插入数据之前,向test_trigger_log数据表中插入before_insert的日志信息
delimiter $
CREATE TRIGGER before_insert
BEFORE INSERT ON tset_trigger
FOR EACH ROW
BEGIN
INSERT INTO test_trigger_log(t_log)
VALUES('before insert...');
END $
delimiter ;
#测试
INSERT INTO tset_trigger(t_note)
VALUES('Tom ...');
SELECT *
FROM test_trigger_log;练习:
# 创建名为after_insert的触发器,向test_trigger数据表插入数据之后,向test_trigger_log数据表中插入after_insert的日志信息
delimiter $
CREATE TRIGGER after_insert
AFTER INSERT ON tset_trigger
FOR EACH ROW
BEGIN
INSERT INTO test_trigger_log(t_log)
VALUES('after_insert...');
END $
delimiter ;
INSERT INTO tset_trigger(t_note)
VALUES('Jerry ...');
# 定义触发器salary_check_trigger,基于员工表employees的insert事件,在insert之前检查将要添加的新员工薪资是否大于他领导的薪资,如果大于领导薪资,则报sqlstate------value为'HY000'
#的错误,从而使得添加失败
CREATE TABLE employees
AS
SELECT *
FROM atguigudb.employees;
CREATE TABLE departments
AS
SELECT *
FROM atguigudb.departmetns;
delimiter $
CREATE TRIGGER salary_check_trigger
BEFORE INSERT ON employees
FOR EACH ROW
BEGIN
DECLARE mgr_sal DOUBLE;
SELECT salary INTO mgr_sal FROM employees WHERE employee_id = NEW.manager_id;
IF NEW.salary > mgr_sal
THEN SIGNAL SQLSTATE 'HY000' SET MESSAGE_TEXT = '薪资高于领导薪资错误';
END IF;
END$
delimiter ;查看触发器:
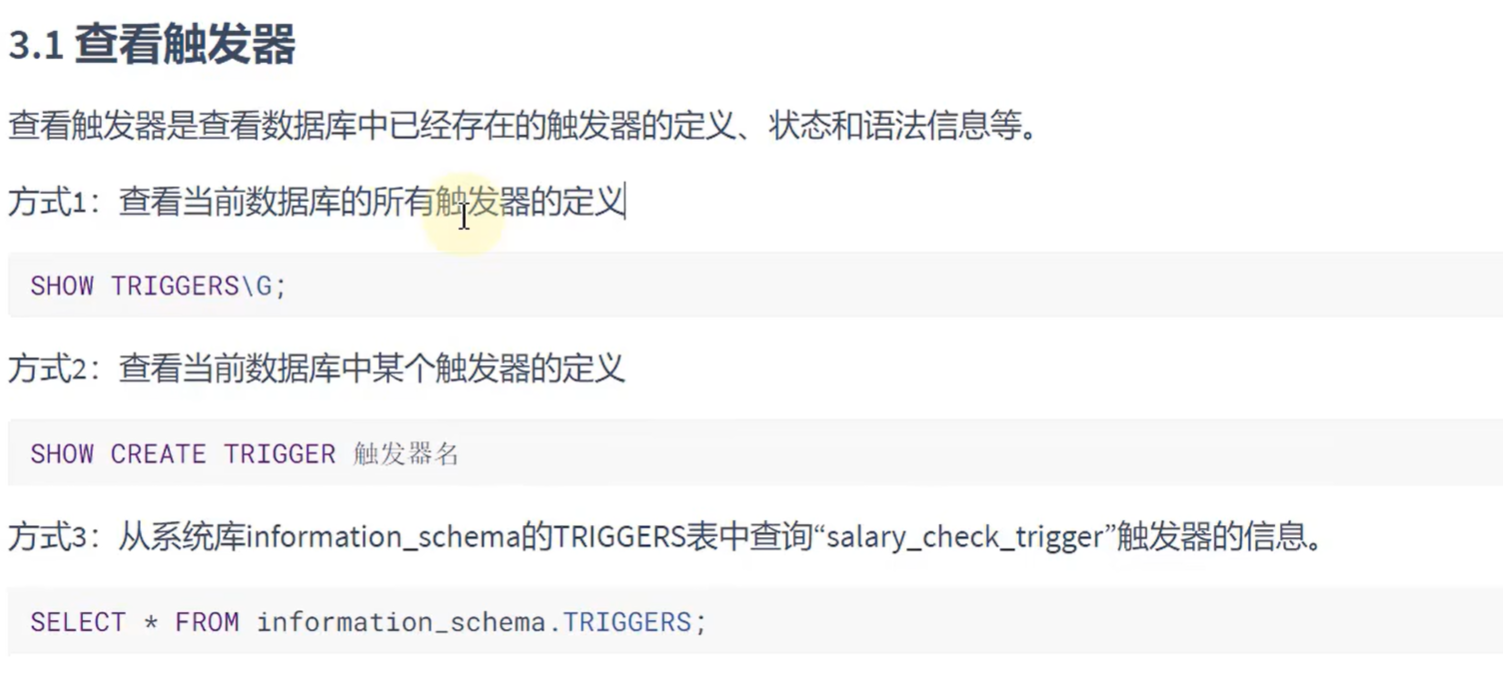
删除触发器:

新特性:


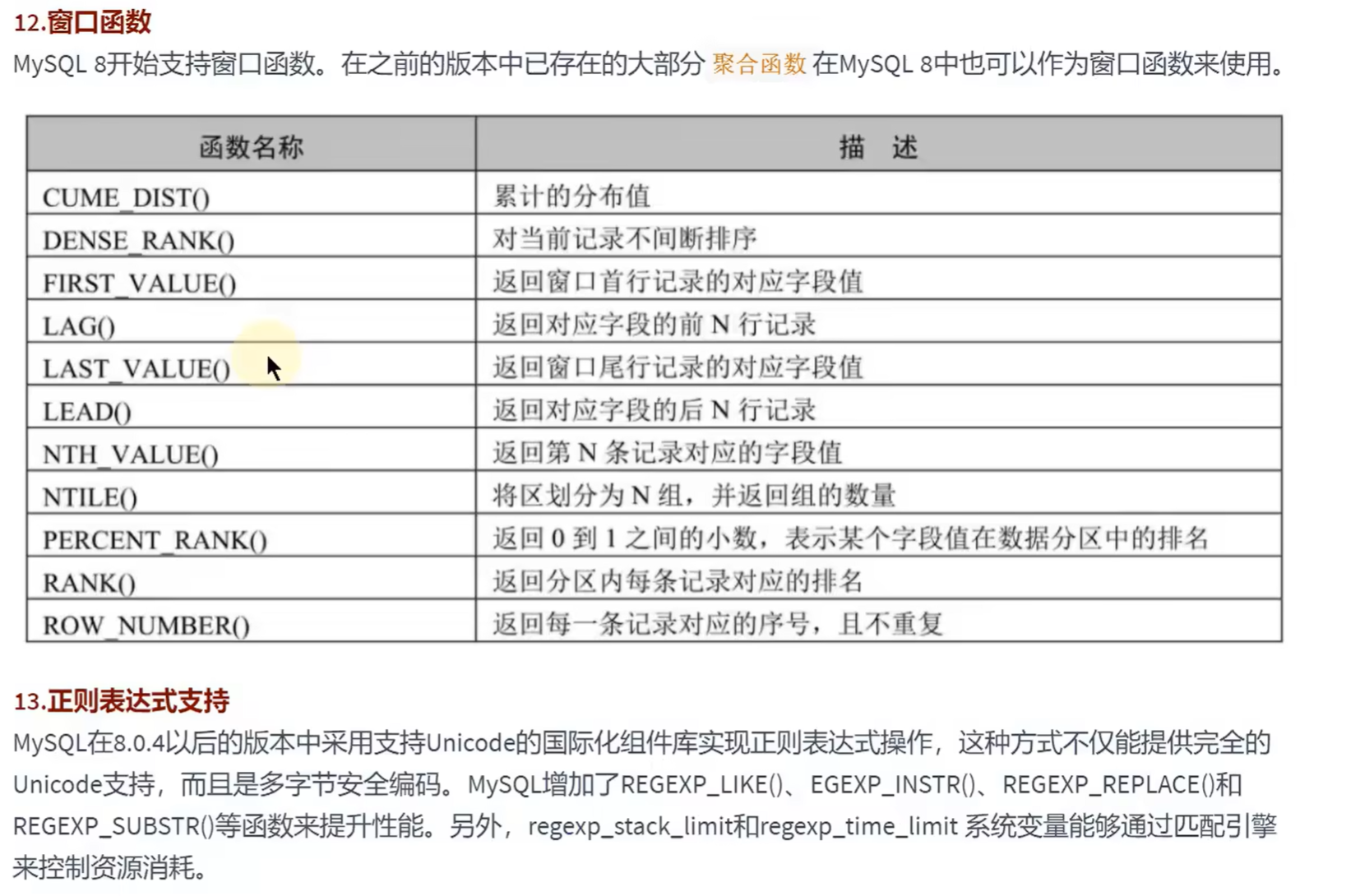

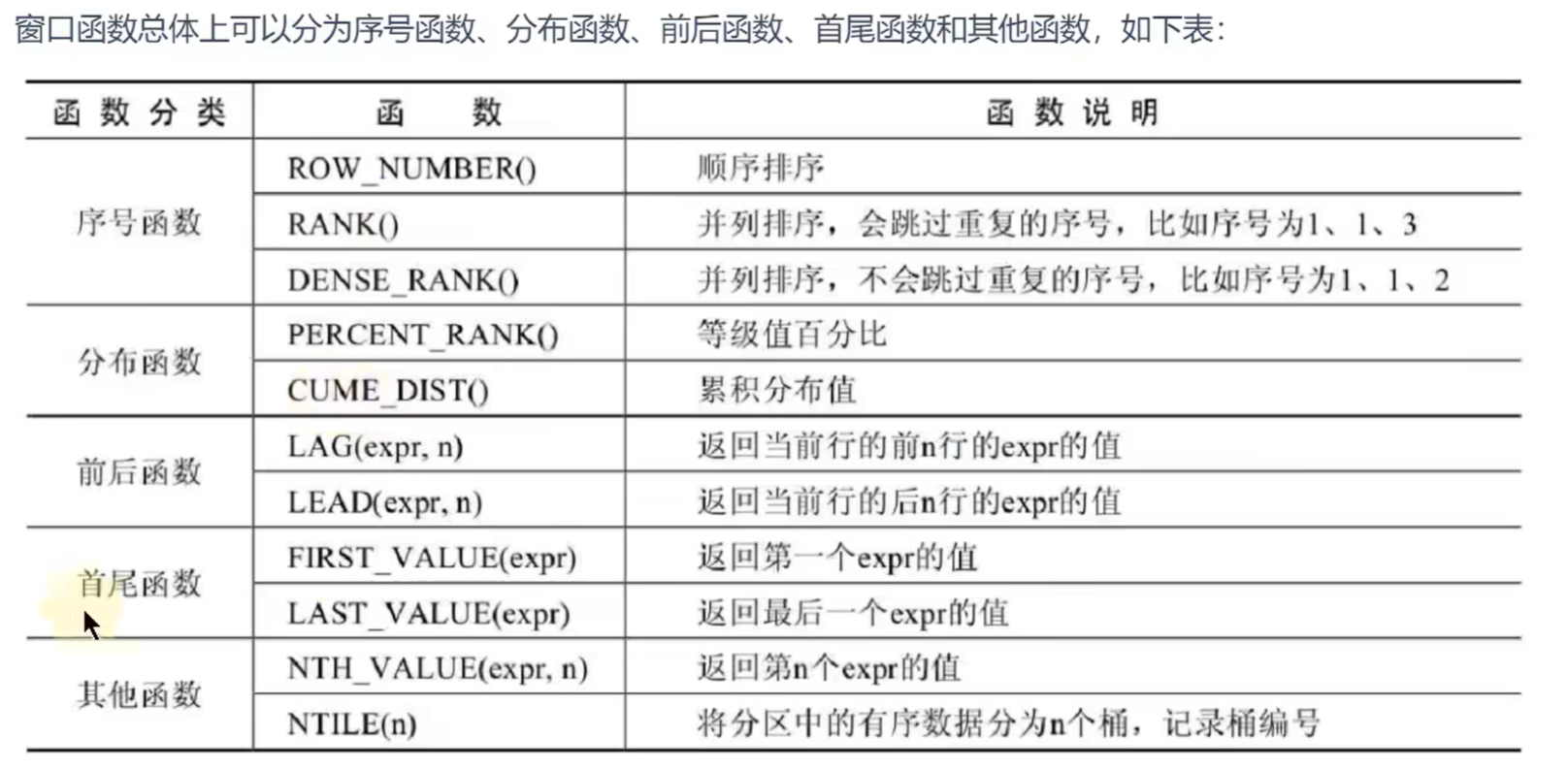
窗口函数:
简单来说就是把所有记录按规定的字段分组,但是和order by不同的是,窗口函数只是把同一个组的字段放在一起,不会合到一起去。



CREATE TABLE goods(
id INT PRIMARY KEY AUTO_INCREMENT,
category_id INT,
category VARCHAR(15),
NAME VARCHAR(30),
price DECIMAL(10,2),
stock INT,
upper_time DATETIME
);
INSERT INTO goods (category_id, category, NAME, price, stock, upper_time)
VALUES
(1, '女装/女士精品', 'T恤', 39.90, 1000, '2020-11-10 00:00:00'),
(1, '女装/女士精品', '连衣裙', 79.90, 2500, '2020-11-10 00:00:00'),
(1, '女装/女士精品', '上衣', 89.90, 1500, '2020-11-10 00:00:00'),
(1, '女装/女士精品', '牛仔裤', 89.90, 3500, '2020-11-10 00:00:00'),
(1, '女装/女士精品', '百褶裙', 29.90, 500, '2020-11-10 00:00:00'),
(1, '女装/女士精品', '呢绒外套', 399.90, 1200, '2020-11-10 00:00:00'),
(2, '户外运动', '自行车', 399.90, 1000, '2020-11-10 00:00:00'),
(2, '户外运动', '山地自行车', 1399.90, 2500, '2020-11-10 00:00:00'),
(2, '户外运动', '登山杖', 59.90, 1500, '2020-11-10 00:00:00'),
(2, '户外运动', '骑行装备', 399.90, 3500, '2020-11-10 00:00:00'),
(2, '户外运动', '运动外套', 799.90, 500, '2020-11-10 00');
SELECT * FROM goods;
#序号函数
# 查询goods数据表中每个商品分类下价格降序排列的各个商品信息
SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
id,category_id,category,`NAME`,price,stock
FROM goods;
# 查询goods数据表中每个商品分类下价格最高的3种商品信息
SELECT *
FROM(
SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
id,category_id,category,`NAME`,price,stock
FROM goods
) t
WHERE row_num <=3;
# 使用rank函数获取goods数据表中各类别的价格从高到低排序的个商品信息
SELECT RANK() OVER( PARTITION BY category_id ORDER BY price DESC) AS row_num,
id,category_id,category,`NAME`,price,stock
FROM goods;
SELECT DENSE_RANK() OVER( PARTITION BY category_id ORDER BY price DESC) AS row_num,
id,category_id,category,`NAME`,price,stock
FROM goods;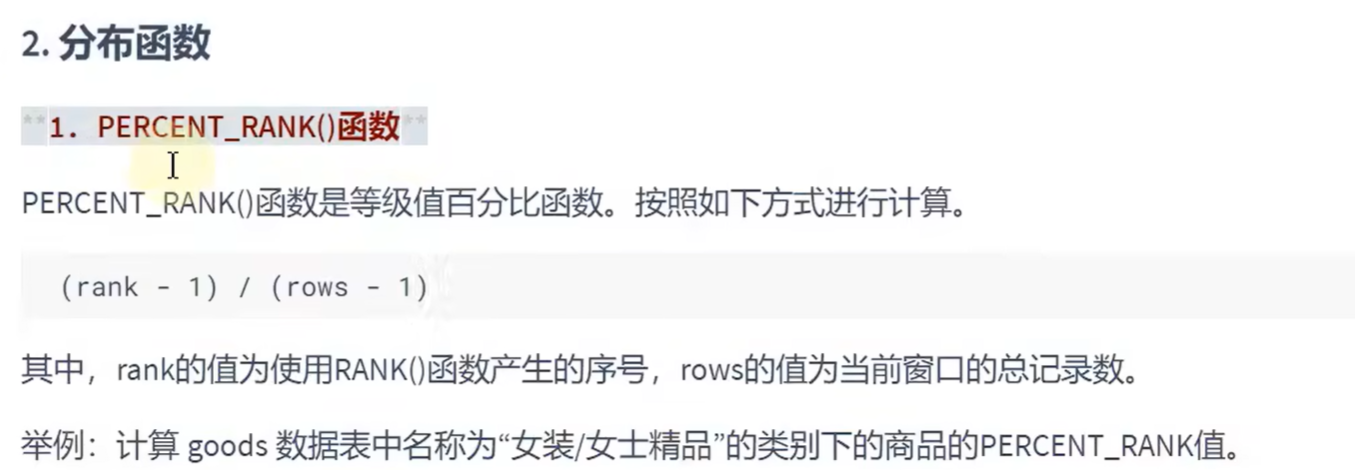
SELECT
RANK() OVER w AS r,
PERCENT_RANK() OVER w AS pr,
id,
category_id,
category,
NAME,
price,
stock
FROM goods
WHERE category_id = 1
WINDOW w AS (PARTITION BY category_id ORDER BY price DESC);
SELECT
CUME_DIST() OVER (PARTITION BY category_id ORDER BY price ASC) AS cd,
id,
category,
NAME,
price
FROM goods;
SELECT
id,
category,
NAME,
price,
pre_price,
price - pre_price AS diff_price
FROM (
SELECT
id,
category,
NAME,
price,
LAG(price, 1) OVER w AS pre_price
FROM goods
WINDOW w AS (PARTITION BY category_id ORDER BY price)
) t;
SELECT
id,
category,
NAME,
behind_price,
price,
behind_price - price AS diff_price
FROM (
SELECT
id,
category,
NAME,
price,
LEAD(price, 1) OVER w AS behind_price
FROM goods
WINDOW w AS (PARTITION BY category_id ORDER BY price)
) t;

SELECT
id,
category,
NAME,
price,
NTH_VALUE(price, 2) OVER w AS second_price,
NTH_VALUE(price, 3) OVER w AS third_price
FROM goods
WINDOW w AS (PARTITION BY category_id ORDER BY price);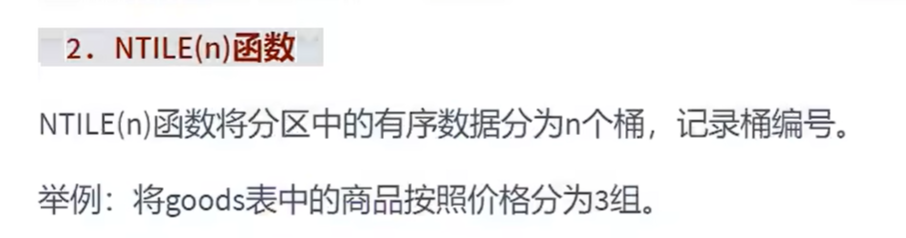

共用表表达式:
简单来说就是为了提高代码的可读性,可以把一层子查询的结果单独作为一个变量,这样可读性就变高了。
二、CTE 的核心作用
1️⃣ 提高 SQL 可读性(最常见用途)
问题:
子查询嵌套多层时,SQL 难读、难维护。
使用 CTE 前:
SELECT *
FROM (
SELECT user_id, COUNT(*) cnt
FROM orders
GROUP BY user_id
) t
WHERE cnt > 5;使用 CTE 后:
WITH order_count AS (
SELECT user_id, COUNT(*) cnt
FROM orders
GROUP BY user_id
)
SELECT *
FROM order_count
WHERE cnt > 5;✅ 逻辑更清晰
✅ 查询步骤更像"写程序"
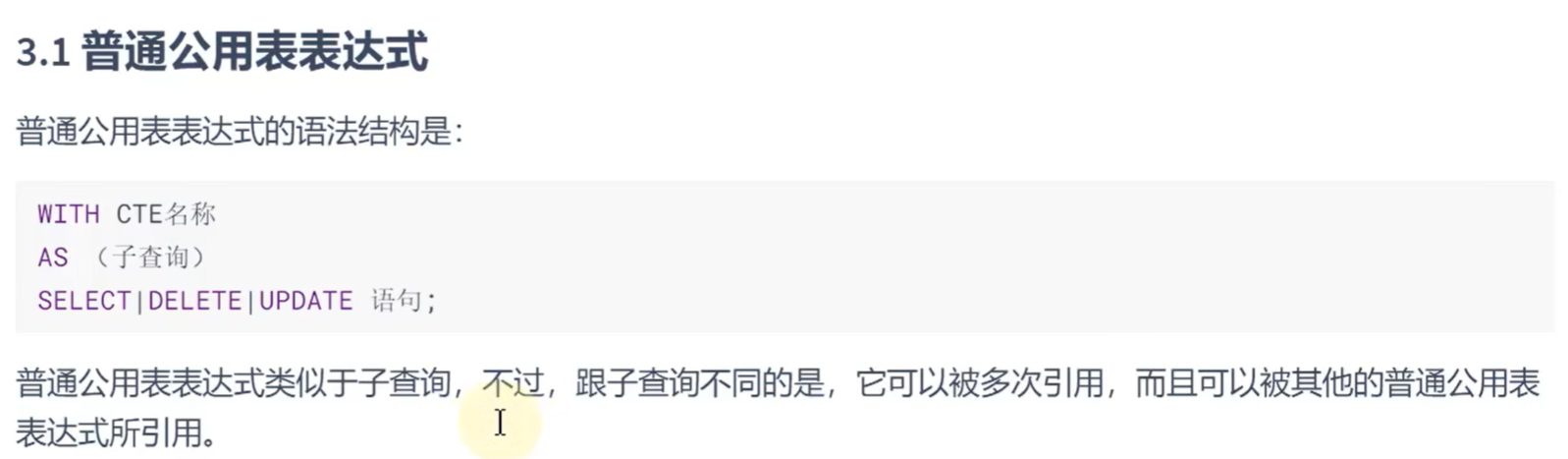
普通共用表表达式:
举例:
#查询员工所在部门的详细信息
WITH cte_emp
AS
(
SELECT DISTINCT department_id FROM employees
)# distinct的作用是去重
SELECT *
FROM departments d JOIN cte_emp e
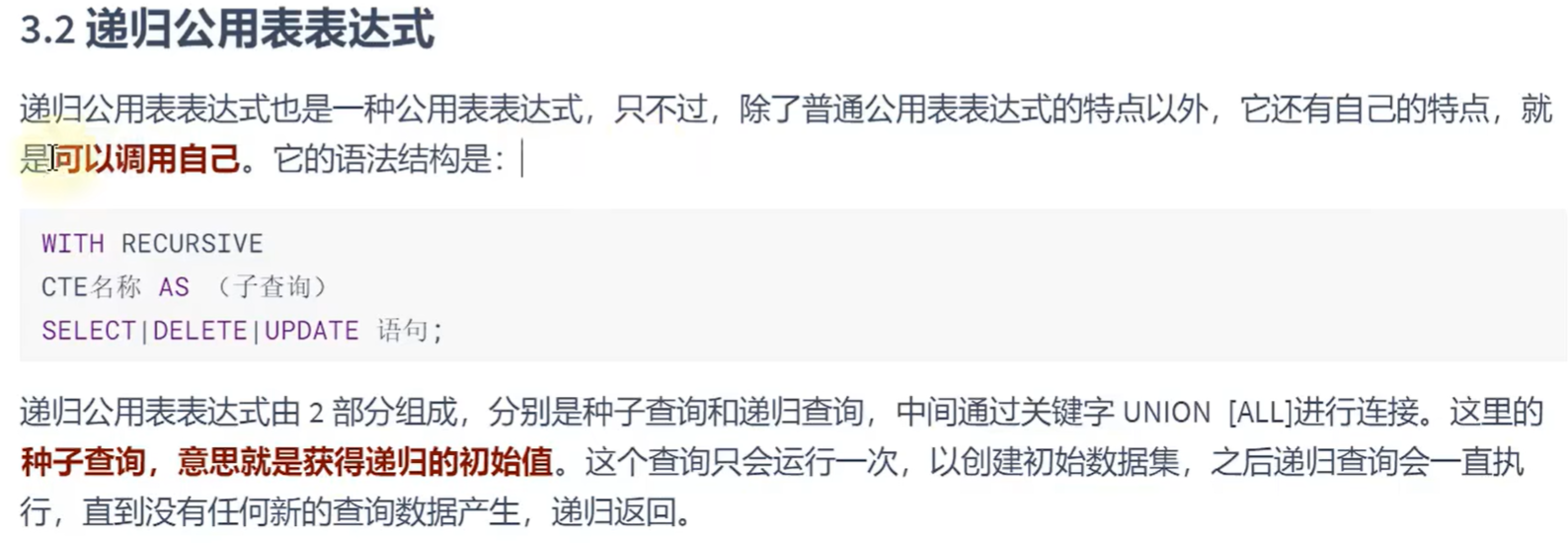
ON d.department_id = e.department_id;递归共用表表达式:
找出公司employes表中所有的下下属
WITH RECURSIVE cte AS (
-- 起始成员:从 employee_id = 100 开始
SELECT
employee_id,
last_name,
manager_id,
1 AS n
FROM employees
WHERE employee_id = 100
UNION ALL
-- 递归成员:查找以下级员工
SELECT
a.employee_id,
a.last_name,
a.manager_id,
n + 1
FROM employees AS a
JOIN cte
ON a.manager_id = cte.employee_id
)
SELECT
employee_id,
last_name
FROM cte
WHERE n >= 3;