目录
文章目录
深度学习常用的框架
随着深度学习技术的快速发展,各类深度学习框架不断涌现。这些框架对底层数学运算、模型训练流程以及硬件加速进行了高度封装,大大降低了深度学习的使用门槛。目前,深度学习领域中应用最为广泛的框架主要包括 PyTorch、TensorFlow、Keras、MXNet 等。
不同框架在设计理念和应用场景上各有侧重。有的框架更注重灵活性和科研友好性,适合算法研究与模型实验;有的框架则强调工程化和部署能力,更适合大规模工业应用。因此,在实际使用过程中,开发者通常需要根据项目需求、学习成本以及社区支持情况来选择合适的深度学习框架。
总体而言,掌握至少一种主流深度学习框架,已经成为学习和应用深度学习技术的基础前提。
提示:以下是本篇文章正文内容,下面案例可供参考
PyTorch认识(手写数字识别案例)
利用mnist数据集实现神经网络的图像识别。
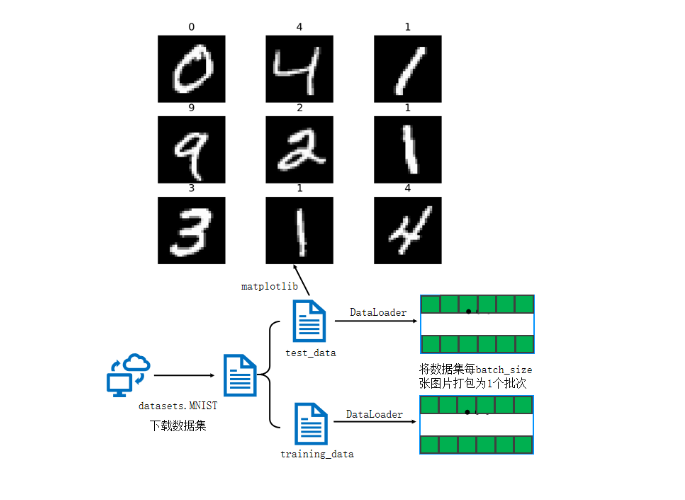
数据集加载与预处理
在深度学习任务中,数据集的质量直接影响模型的训练效果。因此,在模型训练之前,对数据集进行合理的加载与预处理是非常关键的一步。本实验采用 MNIST 手写数字数据集,该数据集包含 0~9 共十类手写数字,具有规模适中、结构清晰的特点,常被用于深度学习入门与算法验证。
在数据加载阶段,通常借助深度学习框架中提供的数据接口完成数据的下载与读取。以 PyTorch 为例,可通过内置的数据集模块快速完成训练集和测试集的加载,同时支持按批次(Batch)读取数据,为后续模型训练提供便利。
在数据预处理阶段,主要包括数据格式转换和归一化操作。原始图像数据通常以像素值形式存储,需要将其转换为张量格式,并对像素值进行归一化处理,以加快模型收敛速度并提升训练稳定性。此外,通过随机打乱数据顺序,可以减少模型对数据排列顺序的依赖,从而提高模型的泛化能力。
下载训练数据集
python
training_data = datasets.MNIST( #跳转到函数的内部源代码,pycharm按下ctrl + 鼠标点击
root="data", #表示下载的手写数字 到哪个路径。60000
train=True, #读取下载后的数据中的训练集
download=True, #如果你之前已经下载过了,就不用下载
transform=ToTensor(), )#张量,图片是不能直接传入神经网络模型
下载测试数据集
python
test_data = datasets.MNIST( #跳转到函数的内部源代码,pycharm按下ctrl + 鼠标点击
root="data", #表示下载的手写数字 到哪个路径。60000
train=False, #读取下载后的数据中的训练集
download=True, #如果你之前已经下载过了,就不用下载
transform=ToTensor(), )#Tensor是在深度学习中提出并广泛应用的数据类型
#Numpy数组只能在CPU上运行。Tensor可以在GPU上运行。这在深度学习应用中可以显著提高计算速度。
print(len(training_data))创建数据DataLoader
python
# batch_size:将数据集分为多份,每一份为batch_size个数据
# 优点:可以减少内存的使用,提高训练速度
train_dataloader = DataLoader(training_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
for X,y in test_dataloader:#X是表示打包好的每一个数据包
print(f"Shape of X[N,C,H,W]:{X.shape}")#
print(f"Shape of y: f{y.shape} {y.dtype}")
break神经网络模型构建
python
class NeuralNetwork(nn.Module): #通过调用类的形式来使用神经网络,神经网络的模型,nn.mdoule
def __init__(self): #python基础关于类,self类自己本身
super().__init__() #继承的父类初始化
self.flatten = nn.Flatten() #展开,创建一个展开对象flatten
self.hidden1 = nn.Linear(28*28,128) #第1个参数:有多少个神经元传入进来,第2个参数:有多少个数据传出去
self.hidden2 = nn.Linear(128,256) #第1个参数:有多少个神经元传入进来,第2个参数:有多少个数据传出去
self.out = nn.Linear(256,10) #输出必须和标签的类别相同,输入必须是上一层的神经元个数
def forward(self,x): #前向传播,你得告诉它 数据的流向 是神经网络层连接起来,函数名称不能改
x = self.flatten(x) #图像进行展开
x = self.hidden1(x)
x = torch.relu(x) #激活函数,torch使用的relu函数
x = self.hidden2(x)
x = torch.relu(x)
x = self.out(x)
return x
model = NeuralNetwork().to(device) #把刚刚创建的模型传入到GPU
print(model)
优化器与损失函数选择
在神经网络训练过程中,优化器和损失函数的选择对模型性能和收敛速度具有重要影响。损失函数用于衡量模型预测结果与真实标签之间的差异,而优化器则根据损失值对模型参数进行更新,从而不断提升模型的预测能力。
在手写数字识别任务中,由于该问题属于多分类问题,常用的损失函数为交叉熵损失函数(CrossEntropyLoss)。该损失函数能够有效衡量模型输出的类别概率分布与真实标签之间的差异,且在 PyTorch 中已对 Softmax 操作进行了封装,使用时无需额外添加输出层的归一化函数,简化了模型设计过程。
在优化器方面,常用的选择包括随机梯度下降(SGD)和 Adam 优化器。其中,Adam 优化器结合了动量法和自适应学习率的优点,能够在训练初期加快收敛速度,并在一定程度上减少对学习率参数的敏感性。因此,在实际实验中,Adam 优化器被广泛应用于各类深度学习任务,尤其适合初学者进行模型训练。
通过合理搭配损失函数与优化器,可以使模型在训练过程中更加稳定、高效地收敛,为后续的模型评估和结果分析提供良好基础。
优化器
合理选择优化器能够显著提升神经网络的训练效果。在本实验中所采用的优化器具有以下优点:
首先,优化器能够自动根据损失函数的变化对模型参数进行更新,使模型逐步向误差更小的方向收敛,避免了人工调整参数带来的复杂性。
其次,以 Adam 优化器为代表的自适应优化方法,可以根据不同参数的梯度变化动态调整学习率,使模型在训练初期具有较快的收敛速度,同时在训练后期保持较好的稳定性,有效减少震荡和梯度消失等问题。
此外,优化器对超参数的依赖相对较小,尤其适合深度学习初学者使用,在无需复杂调参的情况下,也能获得较为理想的训练效果。
综上所述,合理使用优化器不仅能够提高模型训练效率,还能增强模型的稳定性和鲁棒性,为模型性能的提升提供重要保障。
损失函数
损失函数用于衡量模型预测结果与真实标签之间的差异,是指导神经网络训练的重要依据。在模型训练过程中,损失值的大小直接反映了模型当前的学习效果,训练目标即是通过不断迭代,使损失函数的值逐渐减小。
python
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.005)激活函数与梯度问题解决
激活函数的主要作用是为神经网络引入非线性能力,使模型能够学习和拟合复杂的数据分布。如果神经网络中仅包含线性变换,无论网络层数有多深,其表达能力都会受到极大限制。
在早期的神经网络中,Sigmoid 激活函数被广泛使用,但其在深层网络中容易引发梯度消失问题。Sigmoid 函数的导数取值范围较小,在反向传播过程中,梯度在多层连乘后会逐渐趋近于 0,从而导致靠近输入层的参数几乎无法更新,严重影响模型的训练效果。
Sigmoid 函数表达式为:
σ(x) = 1 / (1 + e^(-x))
其导数为:
σ'(x) = σ(x) * (1 - σ(x))
由于 σ(x) ∈ (0, 1),因此:
σ'(x) ∈ (0, 0.25]
梯度消失与梯度爆炸本质上都源于反向传播过程中的连乘效应。
梯度消失:
如果反向传播过程中连乘因子大部分 < 1,
则最终梯度 → 0,参数更新几乎停止
梯度爆炸:
如果反向传播过程中连乘因子大部分 > 1,
则梯度 → +∞,导致训练不稳定
针对深层网络中普遍存在的梯度消失问题,可以采用以下方法进行改进:
使用 ReLU、tanh、PReLU、RReLU、Maxout 等激活函数替代 Sigmoid
合理设置学习率与网络深度
ReLU 激活函数的表达式为:
f(x) = max(0, x)
其导数为:
f'(x) = 1, x > 0
f'(x) = 0, x ≤ 0
当输入大于 0 时,ReLU 的导数恒为 1,能够保证梯度在反向传播过程中稳定传播,从而有效缓解梯度消失问题。因此,ReLU 已成为目前深度学习中最常用的激活函数之一。
模型训练与测试
训练
python
def train(dataloader, model, loss_fn, optimizer):
model.train()
batch_size_num = 1
for X,y in dataloader:
X,y = X.to(device), y.to(device)
pred = model.forward(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_value = loss.item()
if batch_size_num % 100 == 0:
print(f"loss: {loss_value:>7f} [number:{batch_size_num}]")
batch_size_num += 1测试
python
def Test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X,y in dataloader:
X,y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred,y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test result: \n Accuracy:{(100*correct)}%, Avg loss:{test_loss}")循环训练和输出
python
epochs = 10
for t in range(epochs):
print(f"epoch {t+1}\n---------------")
train(train_dataloader, model, loss_fn, optimizer)
print("Done!")
Test(test_dataloader, model, loss_fn)完整代码
python
# import torch
# print(torch.__version__)
'''
MNIST包含70000张手写数字图像:60000用于训练,10000用于测试
图像是灰度的,28×28像素的,并且居中的,以减少预处理和加快运行
'''
import torch
from torch import nn #导入神经网络模块
from torch.utils.data import DataLoader #数据包管理工具,打包数据
from torchvision import datasets #封装了很多与图像相关的模型,数据集
from torchvision.transforms import ToTensor #数据转换,张量,将其他类型的数据转换为tensor张量,numpy array
'''下载训练数据集(包含训练图片+标签)'''
training_data = datasets.MNIST( #跳转到函数的内部源代码,pycharm按下ctrl + 鼠标点击
root="data", #表示下载的手写数字 到哪个路径。60000
train=True, #读取下载后的数据中的训练集
download=True, #如果你之前已经下载过了,就不用下载
transform=ToTensor(), #张量,图片是不能直接传入神经网络模型
) #对于pytorch库能够识别的数据一般是tensor张量
'''下载测试数据集(包含训练图片+标签)'''
test_data = datasets.MNIST( #跳转到函数的内部源代码,pycharm按下ctrl + 鼠标点击
root="data", #表示下载的手写数字 到哪个路径。60000
train=False, #读取下载后的数据中的训练集
download=True, #如果你之前已经下载过了,就不用下载
transform=ToTensor(), #Tensor是在深度学习中提出并广泛应用的数据类型
) #Numpy数组只能在CPU上运行。Tensor可以在GPU上运行。这在深度学习应用中可以显著提高计算速度。
print(len(training_data))
# '''展示手写数字图片,把训练集中的59000张图片展示'''
# from matplotlib import pyplot as plt
# figure = plt.figure()
# for i in range(9):
# img,label = training_data[i+59000] #提取第59000张图片
#
# figure.add_subplot(3,3,i+1) #图像窗口中创建多个小窗口,小窗口用于显示图片
# plt.title(label)
# plt.axis("off") #plt.show(I) 显示矢量
# plt.imshow(img.squeeze(),cmap="gray") #plt.imshow()将Numpy数组data中的数据显示为图像,并在图形窗口中显示
# a = img.squeeze() #img.squeeze()从张量img中去掉维度为1的,如果该维度的大小不为1,则张量不会改变
# plt.show()
'''创建数据DataLoader(数据加载器)'''
# batch_size:将数据集分为多份,每一份为batch_size个数据
# 优点:可以减少内存的使用,提高训练速度
train_dataloader = DataLoader(training_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
for X,y in test_dataloader:#X是表示打包好的每一个数据包
print(f"Shape of X[N,C,H,W]:{X.shape}")#
print(f"Shape of y: f{y.shape} {y.dtype}")
break
'''判断当前设备是否支持GPU,其中mps是苹果m系列芯片的GPU'''
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device") #字符串的格式化,CUDA驱动软件的功能:pytorch能够去执行cuda的命令
# 神经网络的模型也需要传入到GPU,1个batch_size的数据集也需要传入到GPU,才可以进行训练
''' 定义神经网络 类的继承这种方式'''
class NeuralNetwork(nn.Module): #通过调用类的形式来使用神经网络,神经网络的模型,nn.mdoule
def __init__(self): #python基础关于类,self类自己本身
super().__init__() #继承的父类初始化
self.flatten = nn.Flatten() #展开,创建一个展开对象flatten
self.hidden1 = nn.Linear(28*28,128) #第1个参数:有多少个神经元传入进来,第2个参数:有多少个数据传出去
self.hidden2 = nn.Linear(128,256) #第1个参数:有多少个神经元传入进来,第2个参数:有多少个数据传出去
self.out = nn.Linear(256,10) #输出必须和标签的类别相同,输入必须是上一层的神经元个数
def forward(self,x): #前向传播,你得告诉它 数据的流向 是神经网络层连接起来,函数名称不能改
x = self.flatten(x) #图像进行展开
x = self.hidden1(x)
x = torch.relu(x) #激活函数,torch使用的relu函数
x = self.hidden2(x)
x = torch.relu(x)
x = self.out(x)
return x
model = NeuralNetwork().to(device) #把刚刚创建的模型传入到GPU
print(model)
def train(dataloader,model,loss_fn,optimizer):
model.train() #告诉模型,我要开始训练,模型中w进行随机化操作,已经更新w,在训练过程中,w会被修改的
# pytorch提供2种方式来切换训练和测试的模式,分别是:model.train() 和 mdoel.eval()
# 一般用法是:在训练开始之前写上model.train(),在测试时写上model.eval()
batch_size_num = 1
for X,y in dataloader: #其中batch为每一个数据的编号
X,y = X.to(device),y.to(device) #把训练数据集和标签传入cpu或GPU
pred = model.forward(X) # .forward可以被省略,父类种已经对此功能进行了设置
loss = loss_fn(pred,y) # 通过交叉熵损失函数计算损失值loss
# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络
optimizer.zero_grad() # 梯度值清零
loss.backward() # 反向传播计算得到每个参数的梯度值w
optimizer.step() # 根据梯度更新网络w参数
loss_value = loss.item() # 从tensor数据种提取数据出来,tensor获取损失值
if batch_size_num %100 ==0:
print(f"loss: {loss_value:>7f} [number:{batch_size_num}]")
batch_size_num += 1
def Test(dataloader,model,loss_fn):
size = len(dataloader.dataset) #10000
num_batches = len(dataloader) # 打包的数量
model.eval() #测试,w就不能再更新
test_loss,correct =0,0
with torch.no_grad(): #一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候
for X,y in dataloader:
X,y = X.to(device),y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred,y).item() #test_loss是会自动累加每一个批次的损失值
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
a = (pred.argmax(1) == y) #dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号
b = (pred.argmax(1) == y).type(torch.float)
test_loss /= num_batches #能来衡量模型测试的好坏
correct /= size #平均的正确率
print(f"Test result: \n Accuracy:{(100*correct)}%, Avg loss:{test_loss}")
loss_fn = nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为手写字识别一共有十种数字,输出会有10个结果
optimizer = torch.optim.Adam(model.parameters(),lr=0.005) #0.01创建一个优化器,SGD为随机梯度下降算法
# # params:要训练的参数,一般我们传入的都是model.parameters()
# # lr:learning_rate学习率,也就是步长
# # loss表示模型训练后的输出结果与样本标签的差距。如果差距越小,就表示模型训练越好,越逼近真实的模型
# 只跑一轮(可尝试)
# train(train_dataloader,model,loss_fn,optimizer) #训练1次完整的数据。多轮训练
# Test(test_dataloader,model,loss_fn)
epochs = 10
for t in range(epochs):
print(f"epoch {t+1}\n---------------")
train(train_dataloader,model,loss_fn,optimizer)
print("Done!")
Test(test_dataloader,model,loss_fn)