文章:Generalizing Vision-Language Models with Dedicated Prompt Guidance
代码:https://github.com/TL-UESTC/GuiDG
单位:电子科技大学
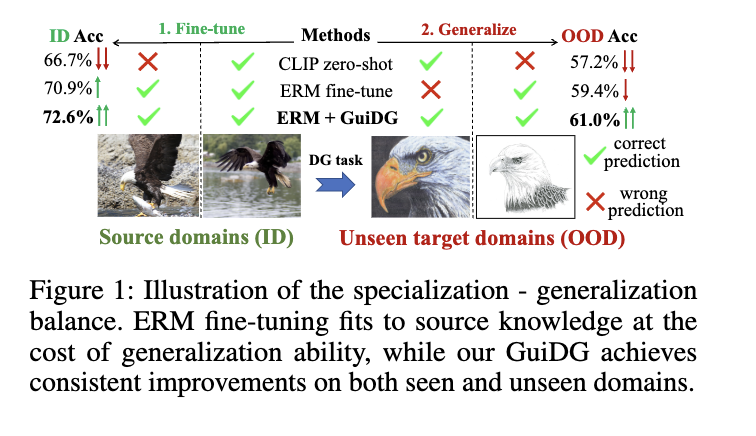
一、问题背景:模型的"专精"与"泛化"难两全
视觉语言模型(比如大家熟知的CLIP)凭借海量预训练数据,具备了不错的零样本识别能力------即使没专门训练过某个类别,也能大致认出。但当它们需要适配具体下游任务时,问题就来了:
-
直接微调整个模型,容易过度"讨好"训练数据(比如只学真实照片的特征),遇到新场景(如艺术画、手绘)就"水土不服";
-
为了保留泛化能力而限制微调,又会导致模型在特定任务上精度不足,难以满足实际需求。
简单说,现有方法大多用一个"全能模型"应对所有场景,却始终无法解决"专"与"博"的核心矛盾,这也成为制约视觉语言模型落地的关键瓶颈。
二、方法创新:两步走!"专家组队"破解泛化难题
GuiDG框架的核心思路很简单:与其让一个模型"单打独斗",不如组建一支"专业团队"------让不同专家各司其职,再用智能模块整合意见。整个过程分为两步:
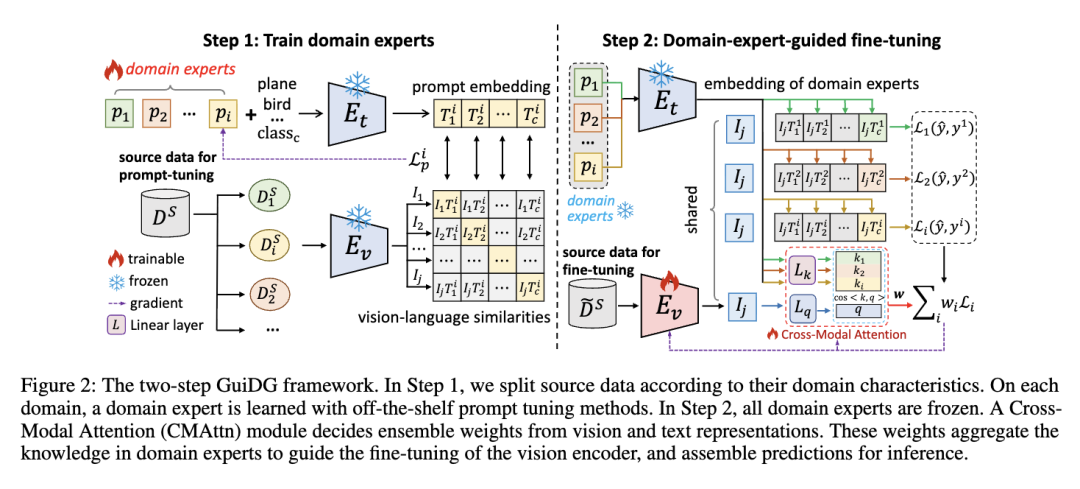
1. 第一步:培养"领域专家"
先把训练数据按场景拆分(比如分成"真实照片""卡通""素描"等领域),给每个领域单独训练一个"小专家"。
-
不用重新训练整个大模型,只通过"提示调优"调整不到1%的参数,既高效又能精准捕捉领域特性;
-
每个专家只专注自己的领域,比如"真实照片专家"专攻真实物体识别,"卡通专家"吃透卡通形象特征,实现"术业有专攻"。
2. 第二步:智能整合专家意见
设计一个轻量级的"跨模态注意力模块(CMAttn)",相当于团队的"智能裁判":
-
它会根据输入的图片和文字信息,自动判断哪个专家的意见更靠谱,给靠谱的专家加权,不靠谱的减权;
-
训练时,"裁判"和模型的视觉编码器一起优化,越练越精准,最终能动态应对各种没见过的新场景。
此外,研究者还构建了一个全新的测试集ImageNet-DG,结合ImageNet及其多个变体,专门用来检验模型在少样本场景下的泛化能力,解决了现有测试集场景单一的问题。
三、实验结果:多项 benchmark 验证,性能稳步提升
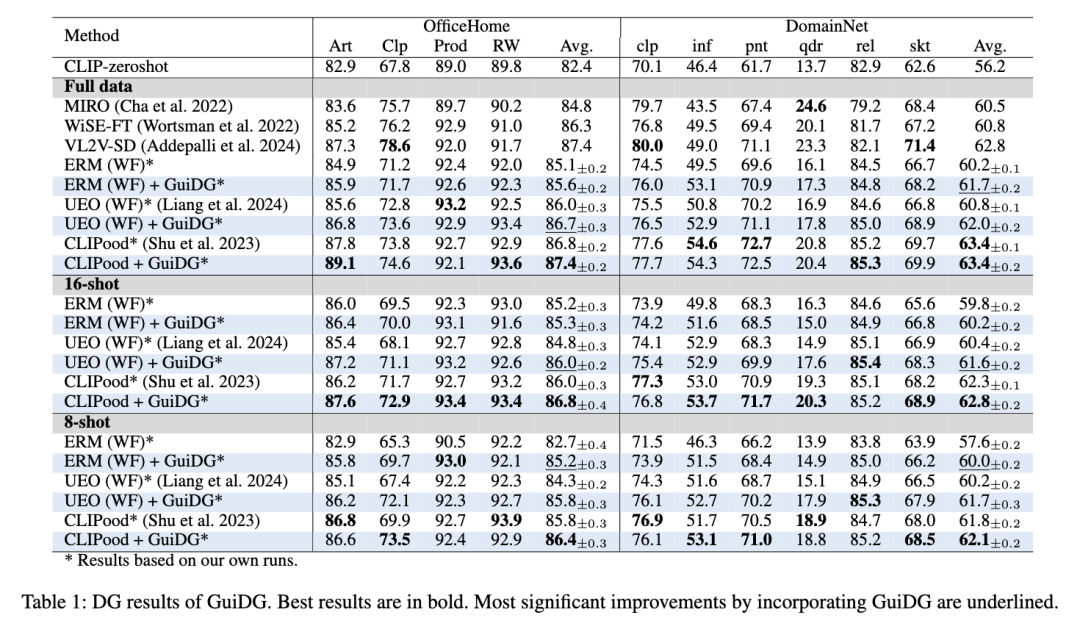
GuiDG在多个主流测试集(OfficeHome、PACS、VLCS等)和新构建的ImageNet-DG上都进行了验证,结果十分亮眼:
-
全数据训练场景下,GuiDG在所有测试集上都超越了现有主流方法,平均准确率提升1-3个百分点;
-
少样本场景(8-shot、16-shot)中,优势更明显------8-shot的GuiDG性能甚至超过了16-shot的传统方法,充分证明了其数据效率;
-
即使在单源数据训练(无明确领域标签)的极端场景下,GuiDG依然能稳定优于基线模型,展现了强大的适应性。
以ImageNet-DG测试集为例,GuiDG让基线模型的平均准确率提升了1.5-2.5个百分点,在最难的"自然对抗样本"(人类都难识别的图片)识别任务中,提升效果尤为显著。
四、优势与局限:亮点突出,仍有优化空间
核心优势
-
效率高:仅新增约1M参数(占模型总参数不到1%),训练成本低,易部署;
-
兼容性强:可与现有微调方法(如UEO、CLIPood)无缝结合,直接提升现有模型性能;
-
泛化稳:从理论上证明了"专家组队"比"全能模型"泛化风险更低,少样本场景下表现突出。
现存局限
-
依赖领域划分:多源数据场景下需要明确的领域标签,无标签时需手动拆分伪领域,增加了少量操作成本;
-
极端场景表现有限:当目标领域与所有源领域差异极大时,性能提升幅度会缩小;
-
仅适配分类任务:目前主要针对图像分类,尚未扩展到检测、分割等更复杂的视觉任务。
五、一句话总结
GuiDG通过"培养领域专家+智能整合意见"的两步策略,在几乎不增加计算成本的前提下,完美平衡了视觉语言模型的"专精性"与"泛化性",为下游任务适配提供了高效且可靠的新方案。