一、网络通信的底层逻辑:协议栈与封装
咱们先想个问题:你在浏览器输入网址,数据是怎么传到服务器的?答案就是"分层协作"------就像快递公司送货,收件员(应用层)打包,分拣员(传输层)贴地址,运输员(网络层)选路线,快递车(物理层)送货,每层只干自己的活,不越界。
1. Linux 网络协议栈分层
- 应用层 :给数据"定格式",比如 HTTP 协议规定网页请求长啥样,常见的还有 SSH、FTP;
- 传输层 :给数据"标进程",用端口号区分同一台电脑上的不同程序(比如 80 端口是浏览器,3306 是 MySQL),核心是 TCP 和 UDP;
- 网络层 :给数据"标主机",用 IP 地址定位目标电脑,比如 192.168.1.1;
- 数据链路层 :给数据"标节点",用 MAC 地址(网卡物理地址)在局域网内传输;
- 物理层 :纯硬件传输,比如网线传电信号、光纤传光信号。
在Socket网络编程(IPv4场景)中,sockaddr_in结构体的sin_addr字段以32位二进制形式存储IP地址,但我们日常习惯用"点分十进制字符串"(如192.168.1.1)表示IP,因此需要借助地址转换函数实现两种格式的互转,这是网络编程中绑定IP、解析地址的基础操作:
补充知识点
1. 字符串转in_addr(用于程序中使用IP)
需引入头文件<arpa/inet.h>,常用函数包括:
inet_aton(const char *strptr, struct in_addr *addrptr):
将点分十进制字符串(如
"192.168.1.1")转为in_addr结构体,成功返回1,失败返回0;
inet_addr(const char *strptr):
直接返回转换后的32位整数形式IP(本质是
in_addr_t类型),但无法区分"转换失败"与"0.0.0.0";
inet_pton(int family, const char *strptr, void *addrptr):
更通用的函数(支持IPv4/IPv6),
family传AF_INET表示IPv4,将字符串转为二进制地址存入addrptr。
2. in_addr转字符串(用于打印/展示IP)
常用函数:
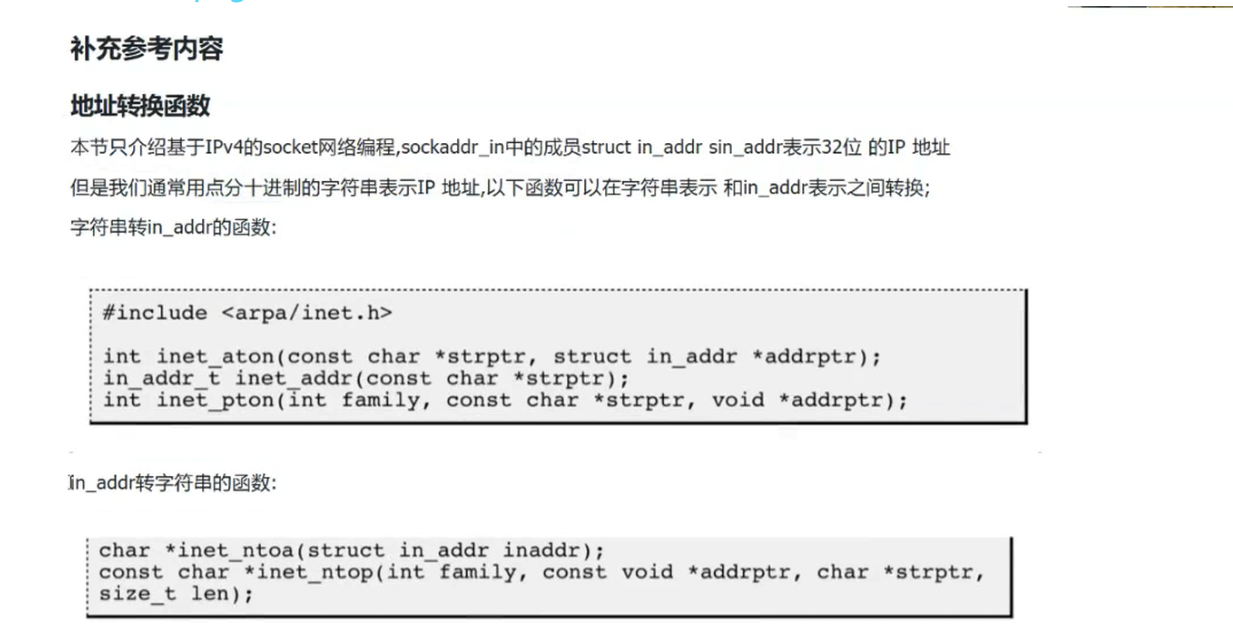
inet_ntoa(struct in_addr inaddr):将in_addr结构体转为点分十进制字符串,但返回的是静态缓冲区,多线程场景下可能被覆盖;inet_ntop(int family, const void *addrptr, char *strptr, size_t len):更安全的通用函数(支持IPv4/IPv6),需手动传入缓冲区strptr存储结果,避免线程安全问题。
这些函数是网络编程中"IP格式互转"的核心工具,比如在bind()绑定IP前,需用inet_pton将字符串IP转为in_addr格式;在打印客户端IP时,需用inet_ntop将二进制地址转为可读字符串。
2. 数据封装与解封装(推导过程)
- 应用层:我要发"访问百度"的请求,生成原始数据;
- 传输层:给数据加个头,写上源端口(我电脑的临时端口)和目的端口(百度的 80 端口),变成"报文段";
- 网络层:再加个头,写上我电脑的 IP 和百度的 IP,变成"数据报";
- 数据链路层:再加个头和尾,写上我网卡的 MAC 和路由器的 MAC,变成"以太网帧";
- 物理层:把帧变成电信号,通过网线发出去;
- 接收方反向操作:拆帧→拆数据报→拆报文段→拿到原始数据。
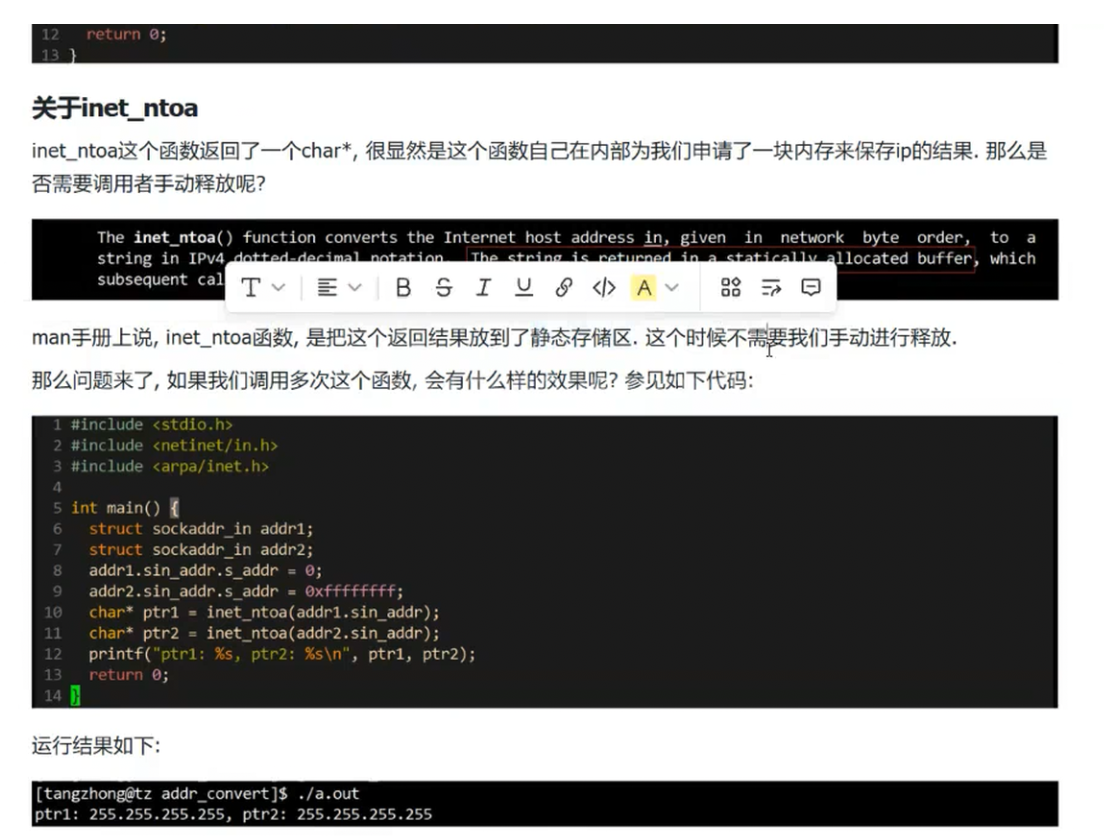
这是 C++ 网络编程中封装 IP 与端口处理 的InetAddr类代码:
类内包含
struct sockaddr_in _addr(存储网络字节序的地址信息)、std::string _ip(点分十进制 IP
字符串)、uint16_t _port(主机字节序的端口);
第一个构造函数:
接收struct sockaddr_in(网络字节序),通过ntohs()将网络字节序的端口转为主机字节序,通过inet_ntoa()将网络字节序的 IP 转为字符串格式;
第二个构造函数:
接收 IP 字符串和主机字节序的端口,通过inet_pton()将 IP 字符串转为网络字节序的in_addr,通过htons()将主机字节序的端口转为网络字节序。
bash
#include <arpa/inet.h>
#include <string>
#include <cstdint>
class InetAddr {
public:
// 构造函数1:从sockaddr_in(网络字节序)初始化
InetAddr(const struct sockaddr_in& addr)
: _addr(addr) {
// 网络字节序端口 -> 主机字节序
_port = ntohs(addr.sin_port);
// 网络字节序IP -> 点分十进制字符串
_ip = inet_ntoa(addr.sin_addr);
}
// 构造函数2:从IP字符串(主机序)和端口(主机序)初始化
InetAddr(const std::string& ip, uint16_t port)
: _ip(ip), _port(port) {
// 初始化sockaddr_in结构体
memset(&_addr, 0, sizeof(_addr));
_addr.sin_family = AF_INET; // IPv4协议族
// 主机字节序端口 -> 网络字节序
_addr.sin_port = htons(port);
// 点分十进制IP字符串 -> 网络字节序
inet_pton(AF_INET, ip.c_str(), &_addr.sin_addr);
}
// 获取主机字节序的端口
uint16_t Port() const {
return _port;
}
// 获取点分十进制的IP字符串
std::string Ip() const {
return _ip;
}
// 获取sockaddr_in结构体(网络字节序)
const struct sockaddr_in& GetSockAddr() const {
return _addr;
}
private:
struct sockaddr_in _addr; // 网络字节序的地址结构体
std::string _ip; // 主机序:点分十进制IP字符串
uint16_t _port; // 主机序:端口号
};二、网络定位核心:IP 地址与端口
咱们 analogy 一下:IP 地址就像小区地址(比如北京市朝阳区XX小区),端口号就像门牌号(3号楼2单元501)。只有同时知道这两个,快递员(数据)才能准确送到你家(目标进程)。
1. IP 地址
- 作用:定位"主机"(电脑、服务器、路由器);
- 格式:IPv4 是 32 位二进制,比如 192.168.1.1(日常用点分十进制表示);IPv6 是 128 位,解决地址不够用的问题。
2. 端口号
- 作用:定位"主机上的进程",是 16 位整数(0-65535),分三类:
- 知名端口(0-1023):系统预留,比如 80=HTTP(网页)、443=HTTPS(加密网页)、22=SSH(远程登录);
- 注册端口(1024-49151):应用程序注册使用,比如 3306=MySQL(数据库);
- 动态端口(49152-65535):客户端临时用,通信结束就释放。
3. 关键结论
"IP+端口"= 唯一通信端点(比如 192.168.1.1:80),数据就是靠这个"地址"找到目标的。
在网络编程中,inet_ntoa是将网络字节序 IP(in_addr)转为点分十进制字符串的常用函数,但它存在一个容易踩坑的特性:返回的字符串存储在静态缓冲区中。
从man手册的说明可知,inet_ntoa会在内部申请一块静态存储区来保存转换后的 IP 字符串,因此调用者不需要手动释放内存。但这个设计会带来 "覆盖问题"------ 如果多次调用inet_ntoa,后续调用的结果会覆盖前一次的返回值。
三、Linux 网络管理必备工具
学网络不能光看书,得会用工具"看"网络------就像医生用听诊器看病,咱们用这些命令看网络状态、查问题。
| 工具 | 核心功能 | 常用命令示例 | 推导过程(为什么这么用) |
|---|---|---|---|
| ip addr | 查看/配置 IP 地址 | ip addr add 192.168.1.100/24 dev eth0 |
给 eth0 网卡加 IP,/24 是子网掩码(表示局域网内有 254 台设备) |
| ip route | 查看/配置路由表 | ip route add default via 192.168.1.1 |
设置默认网关(所有外网数据都走 192.168.1.1 路由器) |
| ping | 测试主机连通性(基于 ICMP 协议) | ping -c 4 www.baidu.com |
发 4 个测试包,看是否能收到回复(通不通)、延迟多少 |
| ss/netstat | 查看网络连接状态 | ss -tulnp(t=TCP,u=UDP,l=监听,n=数字显示,p=进程) |
比如查"哪个进程占用了 80 端口",排查端口冲突 |
| tcpdump/Wireshark | 网络抓包分析 | tcpdump -i eth0 port 80 |
捕获 eth0 网卡 80 端口的所有数据,分析报文是否正常 |
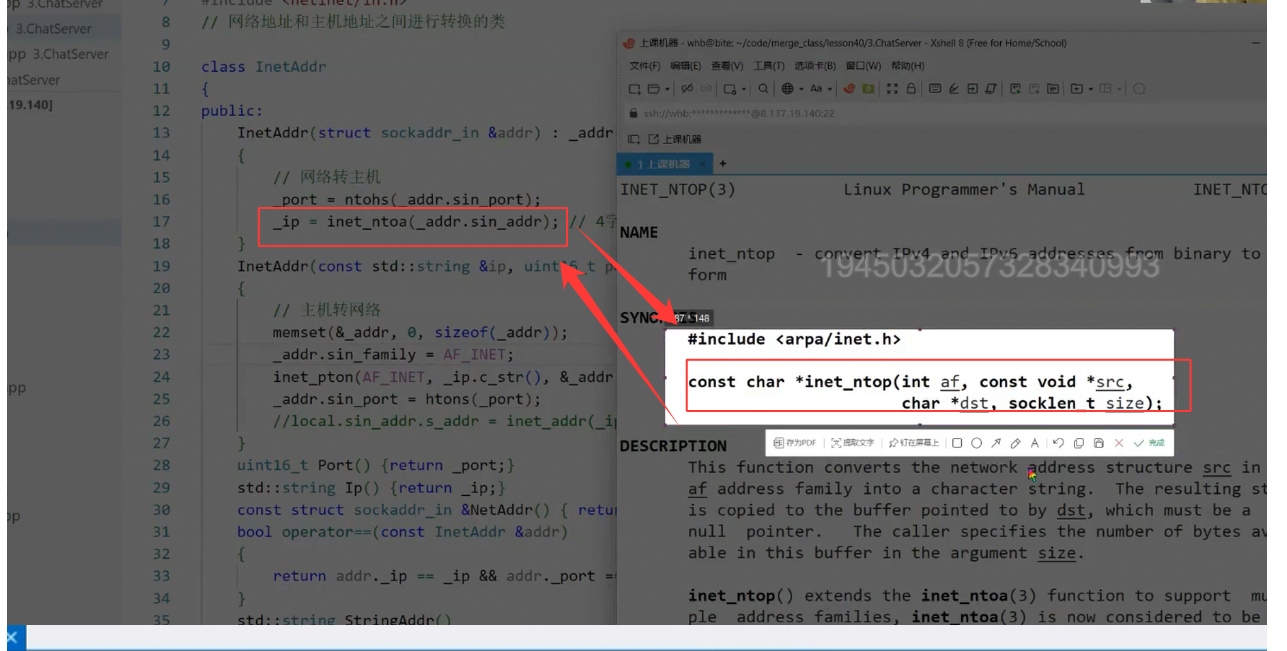
用更安全的inet_ntop替代inet_ntoa,原代码中_ip = inet_ntoa(addr.sin_addr)存在 "静态缓冲区覆盖" 问题,因此改用inet_ntop(需手动传入缓冲区);
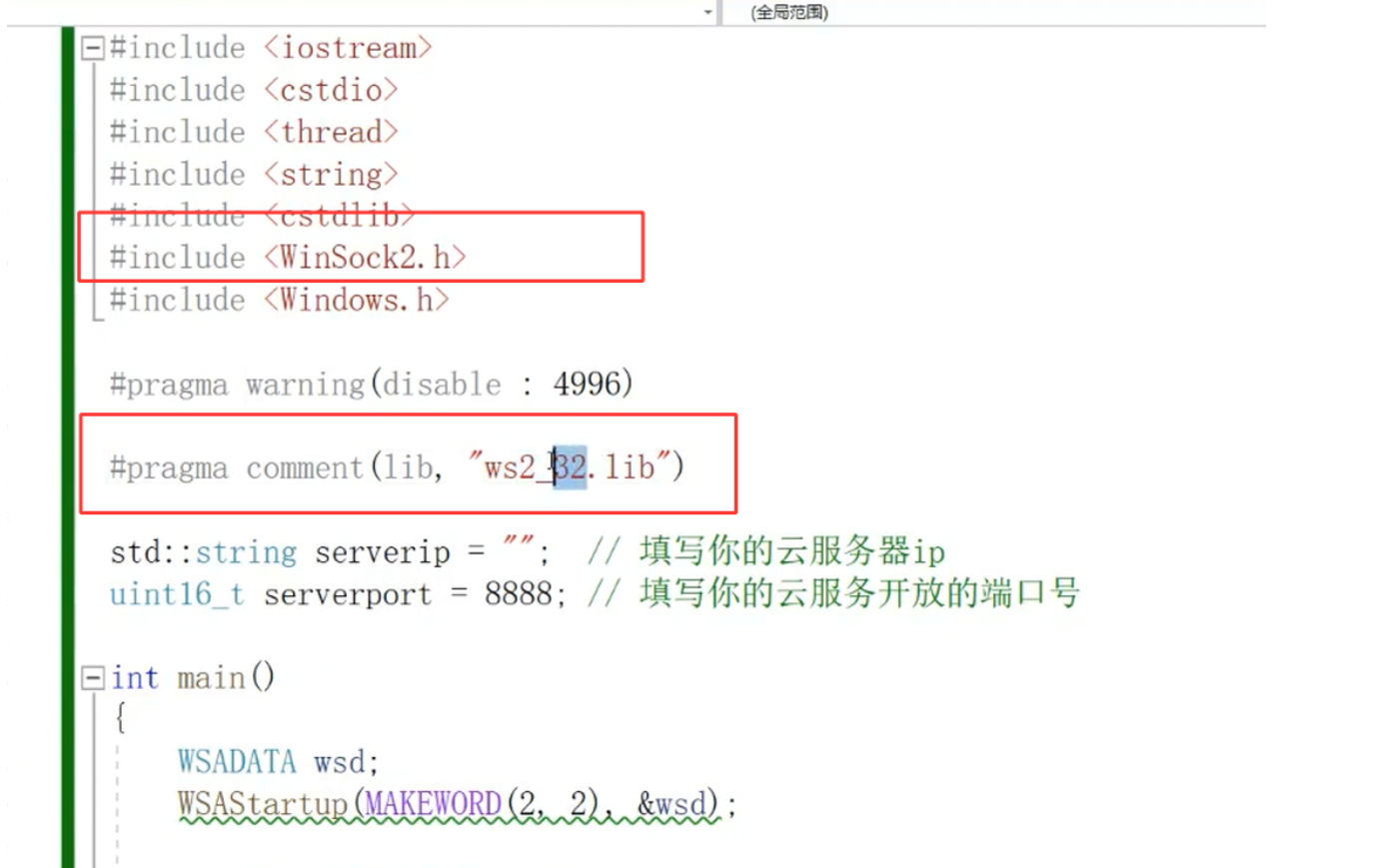
这是 Windows 平台下网络编程的头文件与链接配置:
需引入WinSock2.h头文件(Windows 套接字 2 的 API 定义),并通过#pragma comment(lib, "ws2_32.lib")显式链接ws2_32.lib库(Windows 套接字的实现库);
同时需要调用WSAStartup(MAKEWORD(2, 2), &wsd)初始化套接字库
(这是 Windows 平台独有的步骤,Linux 无需此操作);
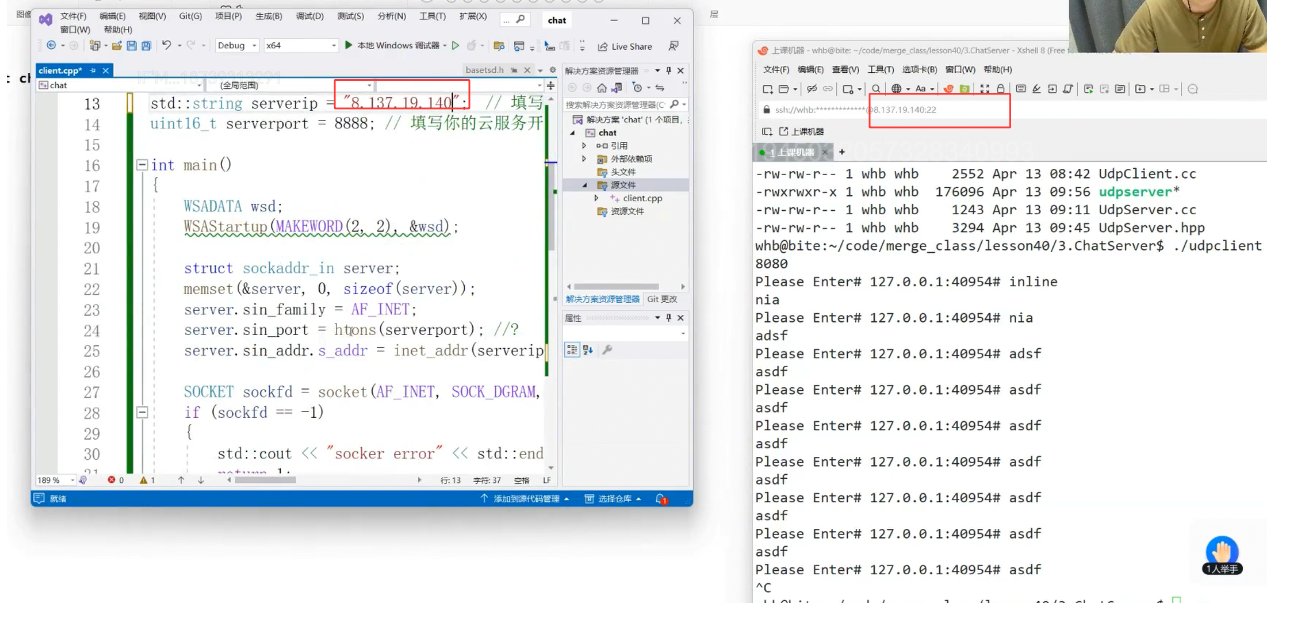
左侧是 Windows 客户端代码:填写服务器 IP(如13.19.146.147)和端口(8888),通过socket创建 UDP
套接字,通过sendto向服务器发送数据; 右侧是 Linux
服务器的运行日志:显示客户端(127.0.0.1:40954)发送的消息(如inline"nia""asdf"),说明跨平台的 UDP
通信已成功建立;
四、TCP 协议核心:可靠传输的六大机制(重点中的重点)
TCP 是互联网的"顶梁柱",咱们刷网页、发消息、转账,都靠它保证数据不丢、不错、不乱。它的核心就是"六大机制",咱们一个个拆,推导它为什么要这么设计。
1. TCP 报文结构(所有机制的基础)
TCP 报文就像"包裹",由"固定头部(20 字节)+ 选项 + 数据"组成,核心字段必须懂:
- 序号/确认号:保证可靠、有序;
- 窗口大小:控制发送速率(流量控制);
- 标志位:SYN(请求建立连接)、ACK(确认收到数据)、FIN(请求关闭连接)、RST(重置连接)。
bash
第 8 行:nocopy(const nocopy &) = delete; ------ 禁用拷贝构造函数,防止通过已有对象创建新的拷贝对象;
第 9 行:const nocopy& operator= (const nocopy &) = delete; ------ 禁用拷贝赋值运算符,防止对象间的赋值拷贝;
类的构造、析构函数保留默认实现(空函数),仅限制拷贝行为。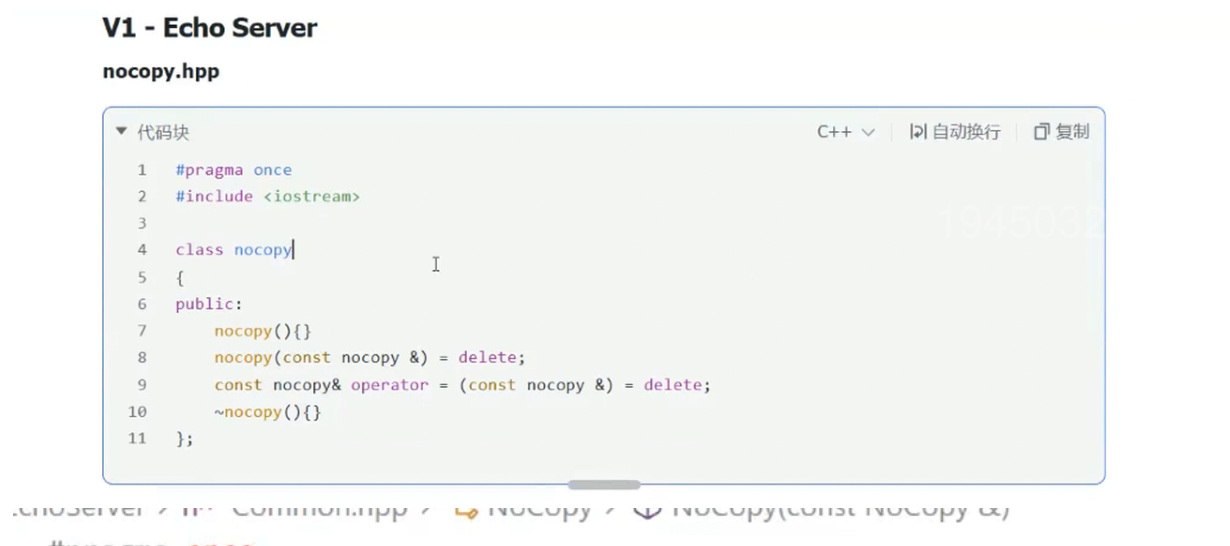
2. 连接管理:三次握手(建立连接)
为什么是三次握手?不是两次或四次?咱们推导一下:
- 第一次:客户端说"我要连你"(发 SYN);
- 第二次:服务器说"我收到了,我也连你"(发 SYN+ACK);
- 第三次:客户端说"我收到你的回复了,开始传数据吧"(发 ACK)。
如果只有两次:服务器不知道客户端有没有收到自己的"同意",万一客户端没收到,服务器还一直等,浪费资源;
如果四次:多余了,三次已经能确认"双方都能发、都能收",再多加一次纯浪费时间。
三次握手流程(记死!):
- 客户端 → 服务器:SYN(序号 x,意思是"我要连接");
- 服务器 → 客户端:SYN+ACK(序号 y,确认号 x+1,意思是"我同意连接,我的序号是 y");
- 客户端 → 服务器:ACK(确认号 y+1,意思是"我收到你的序号了,咱们开始吧")。
最终双方状态:ESTABLISHED(已建立连接)。
bash
该构造函数接收一个端口号port,完成struct sockaddr_in(IPv4 地址结构体)的初始化:
清空结构体:通过memset(&_addr, 0, sizeof(_addr))初始化地址结构体,避免随机值;
指定协议族:_addr.sin_family = AF_INET表示使用 IPv4 协议;
绑定所有本地 IP:_addr.sin_addr.s_addr = INADDR_ANY是核心设置 ------ 表示绑定当前主机的所有可用网卡 IP(而非某一个特定 IP);
端口字节序转换:_addr.sin_port = htons(_port)将主机字节序的端口转换为网络字节序(网络通信的统一格式)。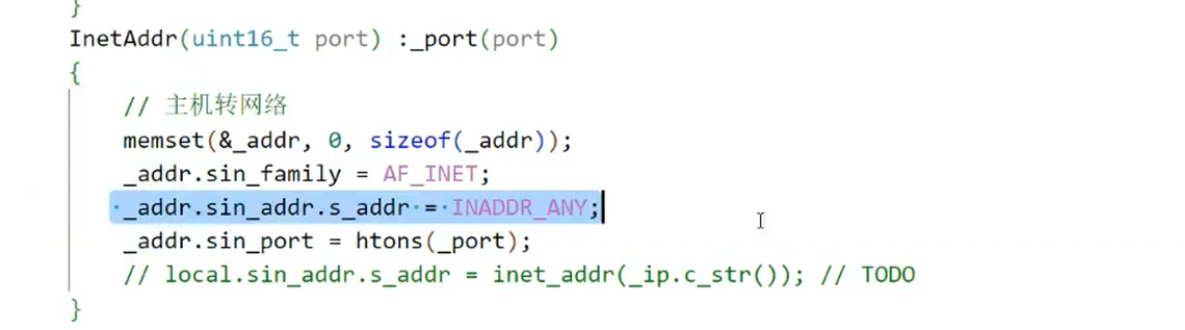
3. 连接管理:四次挥手(关闭连接)
TCP 是"全双工"通信(双方可以同时发数据),所以关闭连接要分两步:先关我的发送通道,再关你的发送通道------这就是四次挥手的原因。
四次挥手流程:
- 主动方 → 被动方:FIN(意思是"我没数据要发了,关我的发送通道");
- 被动方 → 主动方:ACK(意思是"我收到了,你的通道关了");
- 被动方 → 主动方:FIN(意思是"我也没数据要发了,关我的发送通道");
- 主动方 → 被动方:ACK(意思是"我收到了,你的通道也关了")。
笔记重点:主动方最后会进入 TIME_WAIT 状态,等 60 秒(Linux 默认)------防止最后一个 ACK 丢了,对方没收到还要重发 FIN。
4. 可靠性保障:序号、确认与重传
网络是不可靠的(数据会丢、会乱序),TCP 怎么保证可靠?就靠"序号"和"确认号":
- 序号:给每个字节编个号(比如"第 1-100 字节"),接收方按序号拼数据,乱序也能排好,重复的直接丢;
- 确认号:接收方告诉发送方"我已经收到第 100 字节了,下次给我发第 101 字节及以后的";
- 重传:如果发送方没收到确认,就重新发------要么等超时(超时重传),要么收到 3 个重复确认(快速重传,更高效)。
示例推导:
- 发送方发"序号 1-100"的数据包;
- 接收方收到后,回"确认号 101"(意思是 1-100 收到了);
- 如果发送方没收到确认,等超时了就重发;
- 如果接收方收到"1-100""151-200",没收到"101-150",就一直回"确认号 101",发送方收到 3 个重复确认,就知道"101-150 丢了",立即重发。
5. 流量控制:滑动窗口
如果发送方发得太快,接收方缓冲区满了,数据就会丢------滑动窗口就是"让发送方慢下来":接收方告诉发送方"我还能装多少数据"(窗口大小),发送方只发窗口内的数据。
推导过程:
- 接收方缓冲区还能装 1000 字节,就给发送方发"窗口大小 1000";
- 发送方最多发 1000 字节,不能多发;
- 接收方处理了 500 字节,缓冲区空出 500,就更新窗口大小为"1500",发送方就能多传 500 字节;
- 窗口会跟着接收方的处理速度"动态滑动",既不浪费带宽,又不丢数据。
6. 拥塞控制:适应网络状态
流量控制是"端到端"(考虑接收方能力),拥塞控制是"网络级"(考虑网络链路能力)------比如网络堵车了,你还一个劲发数据,只会更堵,所以 TCP 要"根据网络状况调整发送速率"。
核心是"拥塞窗口(cwnd)",发送窗口 = min(cwnd, 接收方窗口),cwnd 动态变化:
- 慢开始:连接刚建立,cwnd 从 1 开始指数增长(1→2→4→8...),直到达到"慢开始阈值(ssthresh)";
- 拥塞避免:达到 ssthresh 后,cwnd 线性增长(每次加 1),避免网络拥塞;
- 快速恢复:如果收到 3 个重复 ACK(说明丢包但网络没堵死),就把 ssthresh 减半,cwnd 设为 ssthresh+3,直接进入拥塞避免(不用再慢开始,提高效率)。
五、TCP vs UDP:协议选择的核心逻辑
TCP 和 UDP 就像"快递"和"对讲机":
- 快递(TCP):慢,但能保证送到,还能按顺序送,适合贵重物品(比如转账、文件传输);
- 对讲机(UDP):快,说出去就完了,不保证对方听到,适合实时性要求高的场景(比如直播、游戏)。
| 特性 | TCP | UDP | 我的选择逻辑 |
|---|---|---|---|
| 连接 | 面向连接(三次握手) | 无连接 | 要可靠就选 TCP,要快就选 UDP |
| 可靠性 | 可靠(重传、确认) | 不可靠(发完即丢) | 转账、登录用 TCP,直播、游戏用 UDP |
| 有序性 | 保证有序 | 不保证有序 | 网页加载要有序(TCP),语音聊天无序也能听(UDP) |
| 速度 | 慢(开销大) | 快(开销小) | 大文件传输用 TCP(不怕慢,怕丢),实时数据用 UDP(不怕丢,怕慢) |
| 适用场景 | HTTP、MySQL、支付 | 直播、游戏、DNS | 记不住就想:"可靠用 TCP,实时用 UDP" |

六、Linux 内核 TCP/IP 与网络编程(新手入门)
咱们写网络程序,本质是"调用内核的接口(socket)",让内核帮我们处理 TCP/IP 细节------就像你打电话,不用管信号怎么传,只需要拨号码、说话就行。
1. 内核协议栈流转路径
应用程序 → socket 层(应用与内核的接口)→ inet 层(处理 TCP/UDP)→ IP 层(处理 IP 地址)→ 数据链路层(处理 MAC 地址)→ 网卡(发送数据)。