第八章 记忆与检索
学习笔记
本章的主要目标是增加memory system和rag功能
那为什么智能体需memory和rag
(1)局限一:无状态导致的对话遗忘
上下文丢失:在长对话中,早期的重要信息可能会因为上下文窗口限制而丢失
个性化缺失:Agent无法记住用户的偏好、习惯或特定需求
学习能力受限:无法从过往的成功或失败经验中学习改进
一致性问题:在多轮对话中可能出现前后矛盾的回答
(2)局限二:模型内置知识的局限性
知识时效性:大模型的训练数据有时间截止点,无法获取最新信息
专业领域知识:通用模型在特定领域的深度知识可能不足
事实准确性:通过检索验证,减少模型的幻觉问题
可解释性:提供信息来源,增强回答的可信度
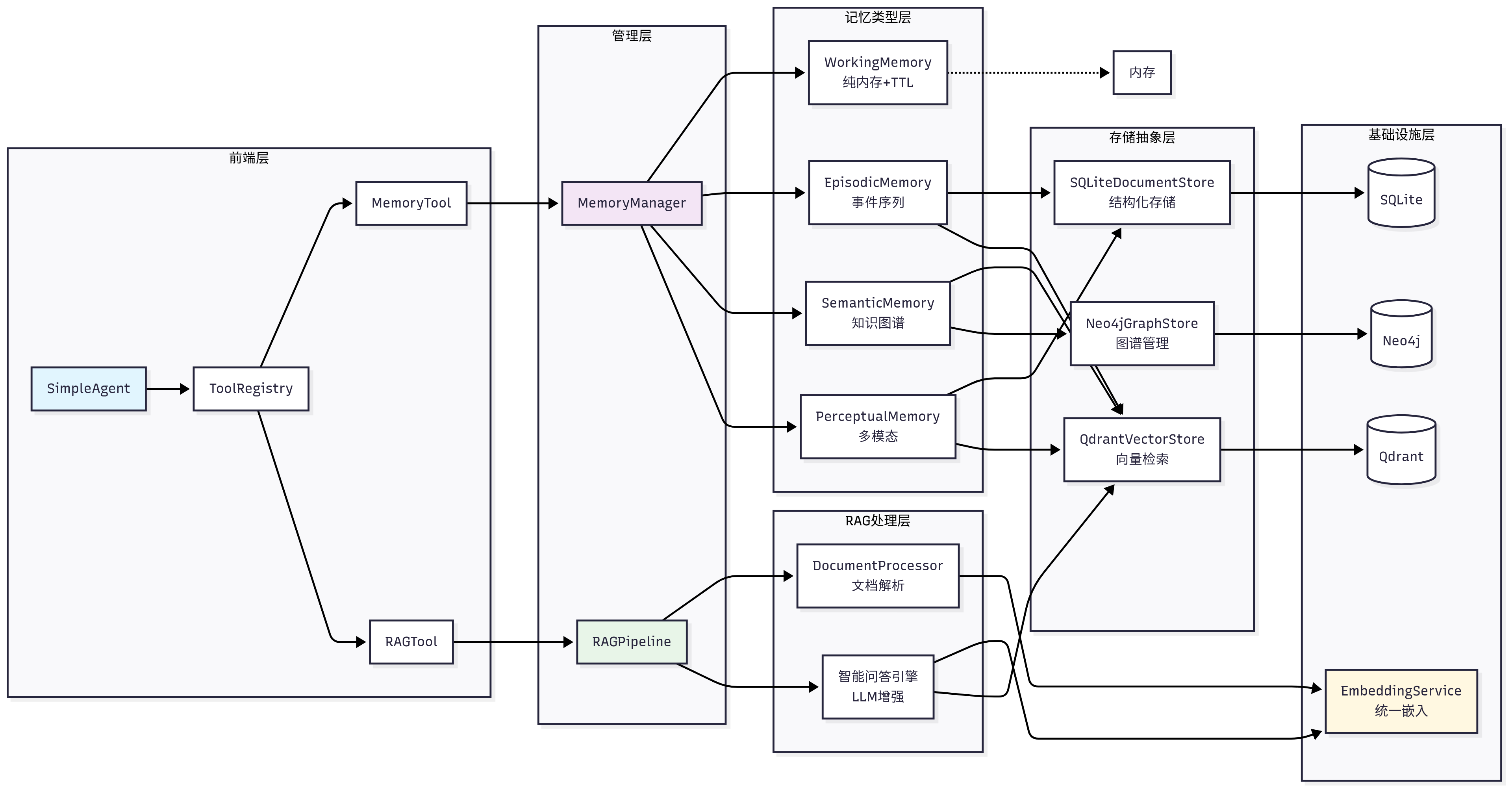
在实现上,我们将记忆和RAG设计为两个独立的工具:memory_tool负责存储和维护对话过程中的交互信息,rag_tool则负责从用户提供的知识库中检索相关信息作为上下文,并可将重要的检索结果自动存储到记忆系统中。
HelloAgents记忆系统
├── 基础设施层 (Infrastructure Layer)
│ ├── MemoryManager - 记忆管理器(统一调度和协调)
│ ├── MemoryItem - 记忆数据结构(标准化记忆项)
│ ├── MemoryConfig - 配置管理(系统参数设置)
│ └── BaseMemory - 记忆基类(通用接口定义)
├── 记忆类型层 (Memory Types Layer)
│ ├── WorkingMemory - 工作记忆(临时信息,TTL管理)
│ ├── EpisodicMemory - 情景记忆(具体事件,时间序列)
│ ├── SemanticMemory - 语义记忆(抽象知识,图谱关系)
│ └── PerceptualMemory - 感知记忆(多模态数据)
├── 存储后端层 (Storage Backend Layer)
│ ├── QdrantVectorStore - 向量存储(高性能语义检索)
│ ├── Neo4jGraphStore - 图存储(知识图谱管理)
│ └── SQLiteDocumentStore - 文档存储(结构化持久化)
└── 嵌入服务层 (Embedding Service Layer)
├── DashScopeEmbedding - 通义千问嵌入(云端API)
├── LocalTransformerEmbedding - 本地嵌入(离线部署)
└── TFIDFEmbedding - TFIDF嵌入(轻量级兜底)
HelloAgents RAG系统
├── 文档处理层 (Document Processing Layer)
│ ├── DocumentProcessor - 文档处理器(多格式解析)
│ ├── Document - 文档对象(元数据管理)
│ └── Pipeline - RAG管道(端到端处理)
├── 嵌入表示层 (Embedding Layer)
│ └── 统一嵌入接口 - 复用记忆系统的嵌入服务
├── 向量存储层 (Vector Storage Layer)
│ └── QdrantVectorStore - 向量数据库(命名空间隔离)
└── 智能问答层 (Intelligent Q&A Layer)
├── 多策略检索 - 向量检索 + MQE + HyDE
├── 上下文构建 - 智能片段合并与截断
└── LLM增强生成 - 基于上下文的准确问答
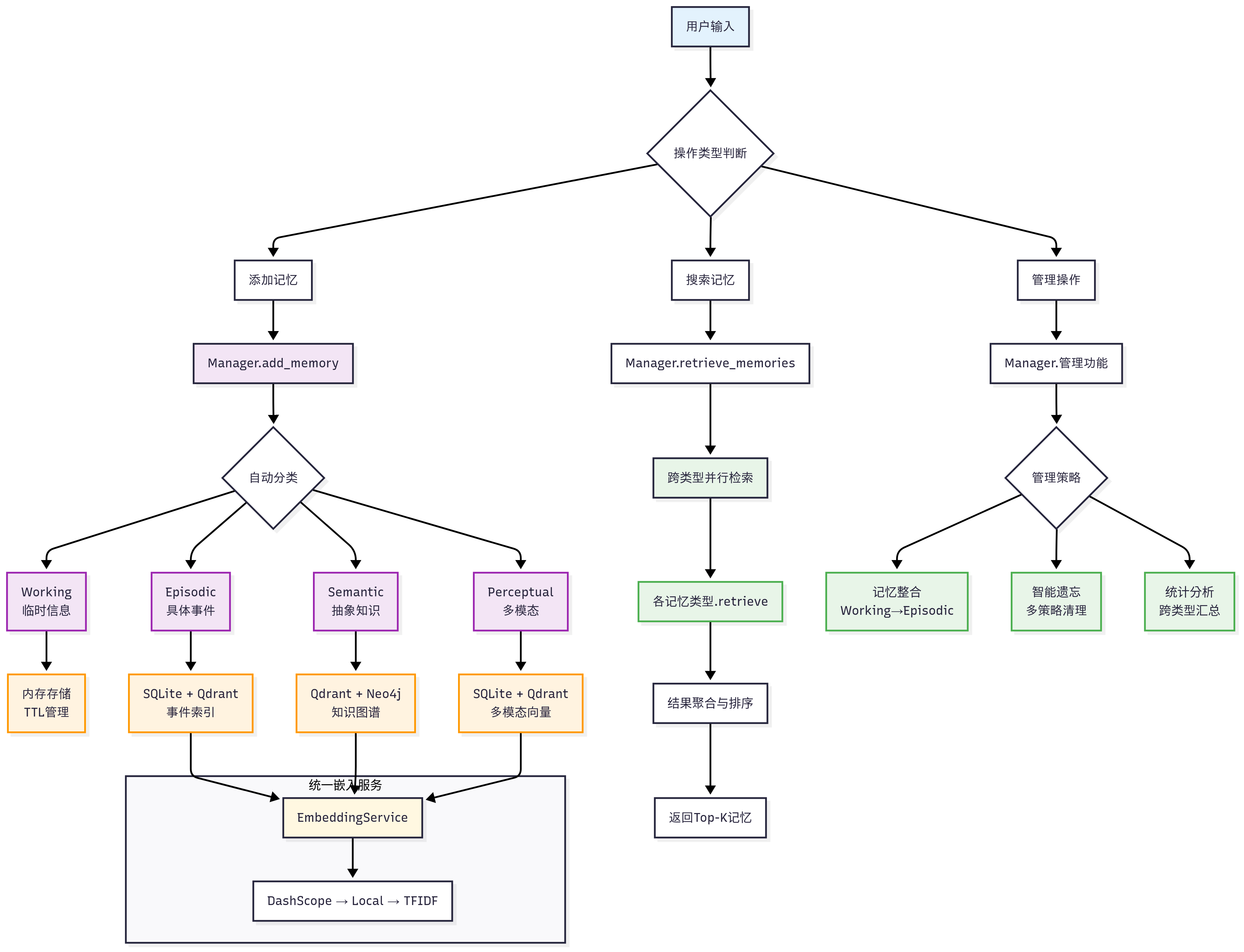
这张图描述的是一个 "带多类型记忆系统的 Agent 记忆子系统":把用户输入先判断成「要不要写入记忆 / 要不要检索记忆 / 要不要做管理维护」,然后走不同的流水线;并且把记忆分成 Working / Episodic / Semantic / Perceptual 四类,各自用不同的存储与检索方式,但底层共享同一个 EmbeddingService。
最上面是:
用户输入 → 操作类型判断 →(三分支)
添加记忆(写入)
搜索记忆(检索/召回)
管理操作(清理、整合、统计等维护)
这三条是记忆系统最核心的"写、读、管"。
- 添加记忆(写入链路)
路径是:
添加记忆 → Manager.add_memory → 自动分类 → 写入不同记忆类型
1.1 Manager.add_memory 在做什么
它是写入入口:接收一段文本/多模态输入(比如一句话、图片描述等),然后做三件事:
规范化:补齐 user_id、时间戳、来源(对话/工具/外部文件)等元数据
抽取/计算特征:包括 embedding(语义向量)、可能还有实体(人名/地点/技能)
路由分发:根据"自动分类"结果写入不同记忆桶
1.2 自动分类:为什么要分 4 类
图里分成四种记忆(紫色框):
A. Working(临时信息)
适合:短期上下文、临时约定、当前任务状态
例:"接下来三轮对话都用中文回答"、"我现在在调试 qdrant"
存储:内存存储 + TTL 管理(橙色框写着 TTL)
特点:快、轻,但会过期
检索:一般直接用 key/规则,或简单相似度(取决于实现)
B. Episodic(具体事件)
适合:发生过的具体经历/对话事实(带时间、场景)
例:"2026-01-18 我说我叫张三,我是 Python 开发者"
存储:SQLite + Qdrant(事件索引)
SQLite:落盘保存原文、时间、标签、可审计
Qdrant:保存向量,用于"语义相似"检索最近似事件
特点:可回溯、可按时间过滤、也可语义召回
C. Semantic(抽象知识)
适合:从多次对话中沉淀出的稳定事实、偏"知识图谱"的东西
例:张三 -> 职业 -> Python开发者,张三 -> 熟悉 -> FastAPI
存储:Qdrant + Neo4j(知识图谱)
Qdrant:解决"语义近似召回"(你换个说法也能找到)
Neo4j:解决"关系查询/多跳推理"(谁-是什么-什么)
特点:可解释、可结构化推理(路径查询、关系约束)
D. Perceptual(多模态)
适合:图片/点云/音频等多模态信息的"感知记忆"
存储:SQLite + Qdrant(多模态向量)
SQLite:存原始引用(文件路径、hash、元信息)
Qdrant:存跨模态 embedding 向量(图里叫"多模态向量")
特点:支持"以文搜图""以图搜图"这类检索(取决于 embedding 模型能力)
- EmbeddingService:四类记忆的"统一底座"
图最下方大框:统一嵌入服务 EmbeddingService,并写了一个降级链路:
DashScope → Local → TFIDF
意思是:整个系统生成向量时不关心你用哪个 embedding 提供方,由 EmbeddingService 统一封装,并能在失败时降级:
DashScope(云端 embedding 服务,优先用)
Local(本地 embedding 模型兜底)
TFIDF(再兜底:当没有神经 embedding 时,用传统向量化保证"还能检索")
关键点:Qdrant 的检索质量几乎完全取决于 embedding。
embedding 一致性也很重要:同一套 collection 尽量用同一类向量空间,否则相似度会乱。
- 搜索记忆(检索链路)
路径是:
搜索记忆 → Manager.retrieve_memories → 跨类型并行检索 → 各记忆类型 .retrieve → 结果聚合与排序 → 返回 Top-k
3.1 Manager.retrieve_memories 的职责
它是统一检索入口,通常会做:
把用户 query 做 embedding(走 EmbeddingService)
给每种记忆类型构造检索请求(不同类型不同策略)
并行检索(图中写"跨类型并行检索")
把多路结果融合重排("结果聚合与排序")
输出 Top-k 给 Agent(用于拼上下文或直接回答)
3.2 "各记忆类型 .retrieve" 各自怎么查
典型做法(与你图一致):
Working.retrieve:直接查内存 + TTL 未过期;可能按最近写入优先
Episodic.retrieve:Qdrant 语义 topK + SQLite 补全文本/时间(也可按时间窗口过滤)
Semantic.retrieve:
Qdrant:先语义召回相关"概念/事实片段"
Neo4j:再做结构化查询(比如"张三 IS_A 什么"),或者用召回结果做图扩展(多跳)
Perceptual.retrieve:Qdrant 多模态向量检索 + SQLite 找到对应媒体引用
3.3 结果聚合与排序(很关键)
因为每路返回的"分数"不可直接比较(向量相似度、图匹配置信度、时间衰减等),所以要融合:
常见融合策略:
归一化分数:把不同检索的 score 映射到统一区间
加权:例如 Semantic 权重大于 Episodic,Working 最高但只在 TTL 内
去重:同一事实可能既在 episodic 又在 semantic
时间衰减:事件越近越重要;抽象知识越稳定越不衰减
最终返回 Top-k 记忆 供 LLM 使用。
- 管理操作("管"的链路)
路径是:
管理操作 → Manager.管理功能 → 管理策略 → 三类策略分支
图里绿色框写了 3 个:
4.1 记忆整合:Working → Episodic
含义:把"短期工作记忆"里重要的东西沉淀成长期事件记忆。
例
Working 中反复出现、或被标记重要的信息 → 写入 Episodic(落 SQLite + 向量库)
或者把一段任务过程的多个 Working 状态,汇总成一次 Episodic 事件
目的:避免 Working 无限膨胀,同时让关键上下文可长期回忆。
4.2 智能遗忘:多策略清理
目的:控制成本、减少噪声、提升召回精度。
典型策略:
TTL 到期直接删(Working)
事件类(Episodic)按"重要度 + 访问频率 + 时间衰减"清理
语义类(Semantic)按"冲突检测 / 过期知识 / 低置信"更新或合并
Perceptual 按"引用是否有效 / 是否重复"清理
4.3 统计分析:跨类型汇总
做可观测性:你记了多少、哪类多、命中率怎样、最近常用哪些实体/关系。
这对调参很有用,比如:
Top-k 召回太多噪声 → 说明 episodic 太"碎"
semantic 图谱边太多太乱 → 需要更强的实体消歧/关系抽取
- 用一个具体例子串起来(最直观)
用户说:
"你好!请记住我叫张三,我是一名Python开发者"
写入
Manager.add_memory 收到文本
自动分类:
"我叫张三/我是Python开发者"更像稳定事实 → Semantic
同时作为一次对话事件也可进 Episodic(看实现)
EmbeddingService 生成向量
写:
Episodic:SQLite 存事件 + Qdrant 存向量
Semantic:Qdrant 存向量 + Neo4j 写 (张三)-:IS_A->(Python开发者)
现在让我们采用自顶向下的方式,从MemoryTool支持的具体操作开始,逐步深入到底层实现。MemoryTool作为记忆系统的统一接口,其设计遵循了"统一入口,分发处理"的架构模式:
def execute(self, action: str, **kwargs) -> str:
"""执行记忆操作
支持的操作:
- add: 添加记忆(支持4种类型: working/episodic/semantic/perceptual)
- search: 搜索记忆
- summary: 获取记忆摘要
- stats: 获取统计信息
- update: 更新记忆
- remove: 删除记忆
- forget: 遗忘记忆(多种策略)
- consolidate: 整合记忆(短期→长期)
- clear_all: 清空所有记忆
"""
if action == "add":
return self._add_memory(**kwargs)
elif action == "search":
return self._search_memory(**kwargs)
elif action == "summary":
return self._get_summary(**kwargs)
# ... 其他操作Copy to clipboardErrorCopied
这种统一的execute接口设计简化了Agent的调用方式,通过action参数指定具体操作,使用**kwargs允许每个操作有不同的参数需求。
现在让我们深入了解四种记忆类型的具体实现,每种记忆类型都有其独特的特点和应用场景:
(1)工作记忆(WorkingMemory)
工作记忆是记忆系统中最活跃的部分,它负责存储当前对话会话中的临时信息。工作记忆的设计重点在于快速访问和自动清理,这种设计确保了系统的响应速度和资源效率。
工作记忆采用了纯内存存储方案,配合TTL(Time To Live)机制进行自动清理。这种设计的优势在于访问速度极快,但也意味着工作记忆的内容在系统重启后会丢失。这种特性正好符合工作记忆的定位,存储临时的、易变的信息。
首先尝试使用TF-IDF向量化进行语义检索,如果失败则回退到关键词匹配
TF-IDF 是什么
TF-IDF 是一种把文本变成"向量"的经典方法,全名 Term Frequency--Inverse Document Frequency(词频-逆文档频率)。它的核心思想很朴素:
一段文本里 某个词出现得越多 → 这个词越能代表这段文本(TF)
但如果这个词在所有文档里都很常见(比如"的、是、我们")→ 这个词就没那么"有区分度"(IDF 会把它压低)

也就是词重合度越高,tfidf越高,然后这个重合的词,如果是稀有的词,那这个tfidf值更高

(2)情景记忆(EpisodicMemory)
情景记忆负责存储具体的事件和经历,它的设计重点在于保持事件的完整性和时间序列关系。情景记忆采用了SQLite+Qdrant的混合存储方案,SQLite负责结构化数据的存储和复杂查询,Qdrant负责高效的向量检索。
(3)语义记忆(SemanticMemory)
语义记忆是记忆系统中最复杂的部分,它负责存储抽象的概念、规则和知识。语义记忆的设计重点在于知识的结构化表示和智能推理能力。语义记忆采用了Neo4j图数据库和Qdrant向量数据库的混合架构,这种设计让系统既能进行快速的语义检索,又能利用知识图谱进行复杂的关系推理。
语义记忆的添加过程体现了知识图谱构建的完整流程。系统不仅存储记忆内容,还会自动提取实体和关系,构建结构化的知识表示:
语义记忆的检索实现了混合搜索策略,结合了向量检索的语义理解能力和图检索的关系推理能力: 也就是说,什么是混合检索,就是同时用向量检索和图检索
向量检索就是看语义上最详尽的,选limit*2个,然后图检索就是不是算相似度,而是从 query
中找"锚点",再沿着图里的关系走几步,把"结构上相关"的节点捞出来 然后对这两个的结构就行合并、去重
然后进行多因子打分,这个权重是自己设定的
语义记忆的评分公式为:(向量相似度 × 0.7 + 图相似度 × 0.3) × (0.8 + 重要性 × 0.4)。这种设计的核心思想是:
向量检索权重(0.7):语义相似度是主要因素,确保检索结果与查询语义相关 图检索权重(0.3):关系推理作为补充,发现概念间的隐含关联
重要性权重范围0.8, 1.2:避免重要性过度影响相似度排序,保持检索的准确性
(4)感知记忆(PerceptualMemory)
感知记忆支持文本、图像、音频等多种模态的数据存储和检索。它采用了模态分离 的存储策略,为不同模态的数据创建独立的向量集合,这种设计避免了维度不匹配的问题,同时保证了检索的准确性:
感知记忆的检索支持同模态和跨模态两种模式。同模态检索利用专业的编码器进行精确匹配,而跨模态检索则需要更复杂的语义对齐机制
感知记忆的评分公式为:(向量相似度 × 0.8 + 时间近因性 × 0.2) × (0.8 + 重要性 × 0.4)。感知记忆的评分机制还支持跨模态检索,通过统一的向量空间实现文本、图像、音频等不同模态数据的语义对齐。当进行跨模态检索时,系统会自动调整评分权重,确保检索结果的多样性和准确性。
此外,感知记忆中的时间近因性计算采用了指数衰减模型