文章目录
- defer是什么
- defer的使用形式
- defer的底层结构
- defer的执行过程
- defer面试与分析
- 1、defer的底层数据结构是怎样的
- [2、循环体中能用defer调用吗? 会有什么问题,为什么?](#2、循环体中能用defer调用吗? 会有什么问题,为什么?)
- 3、defer能修改返回值吗,defer与return的先后关系是怎样的?
- 4、多个defer的执行顺序是怎样的?
defer是什么
defer是go语言的一个关键字,用来修饰函数,其作用是让defer后面跟的函数或者方法调用能够延迟到当前所在函数return或者panic的时候再执行。
defer的使用形式
go
defer func(args)defer在使用的时候,只需要在其后面加上具体的函数调用即可,这样就会注册一个延迟执行的函数func,并且会把函数名和参数都确定,等到从当前函数退出的时候再执行
defer的底层结构
进行defer 函数调用的时候其实会生成一个_defer结构,一个函数中可能有多次defer调用,所以会生成多个这样的_defer结构,这些_defer结构链式存储构成一个_defer链表,当前goroutine的_defer指向这个链表的头节点
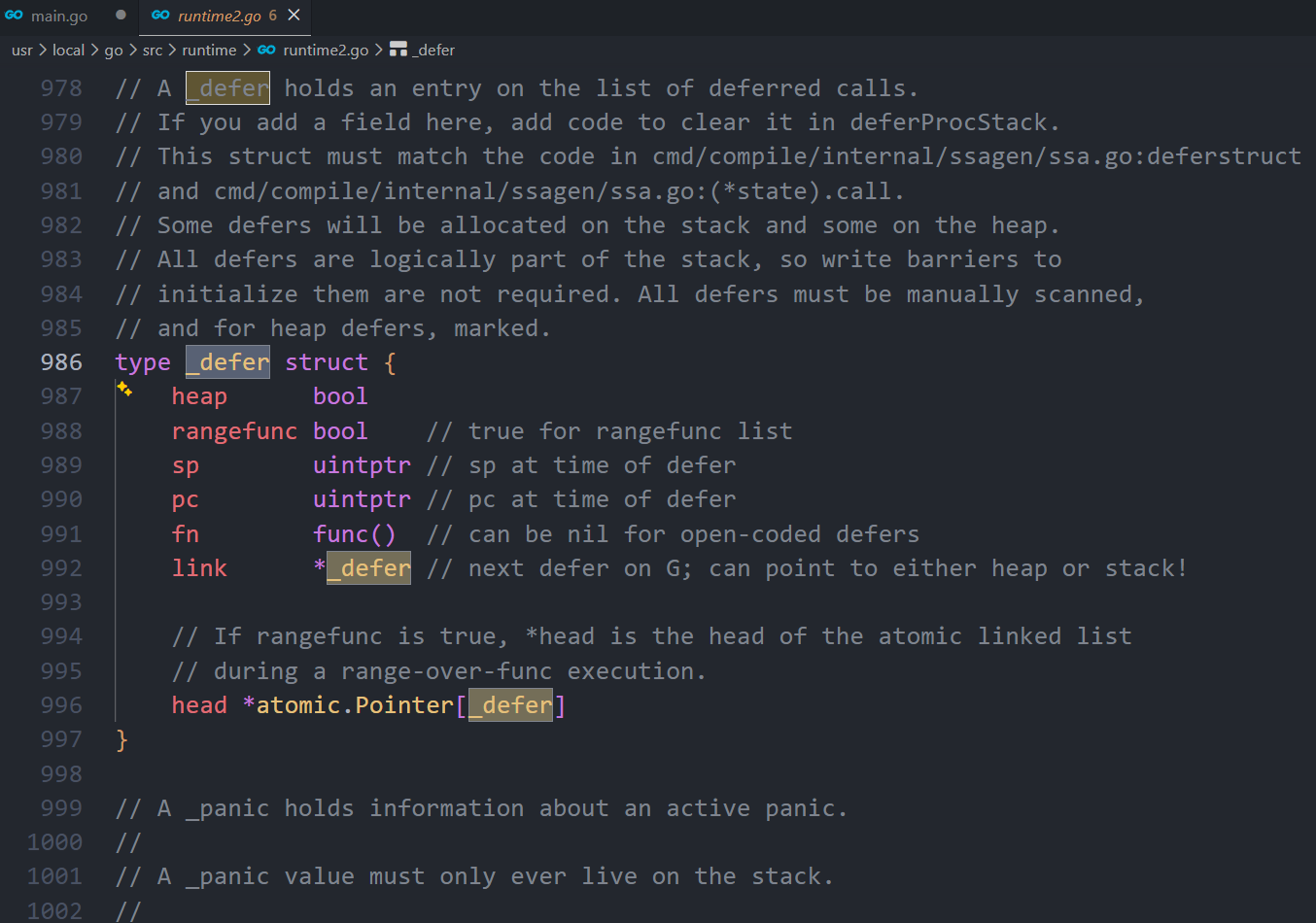
_defer 的结构定义在src/src/runtime/runtime2.go中,源码如下:
go
// A _defer holds an entry on the list of deferred calls.
// If you add a field here, add code to clear it in deferProcStack.
// This struct must match the code in cmd/compile/internal/ssagen/ssa.go:deferstruct
// and cmd/compile/internal/ssagen/ssa.go:(*state).call.
// Some defers will be allocated on the stack and some on the heap.
// All defers are logically part of the stack, so write barriers to
// initialize them are not required. All defers must be manually scanned,
// and for heap defers, marked.
type _defer struct {
// 标记位,标志当前defer结构是否是分配在堆上
heap bool
rangefunc bool // true for rangefunc list
// 调用方的sp寄存器指针,即栈指针
sp uintptr // sp at time of defer
// 调用方的程序计数器指针
pc uintptr // pc at time of defer
// defer注册的延迟执行的函数
fn func() // can be nil for open-coded defers
// defer链表
link *_defer // next defer on G; can point to either heap or stack!
// If rangefunc is true, *head is the head of the atomic linked list
// during a range-over-func execution.
head *atomic.Pointer[_defer]
}
底层存储如下图:
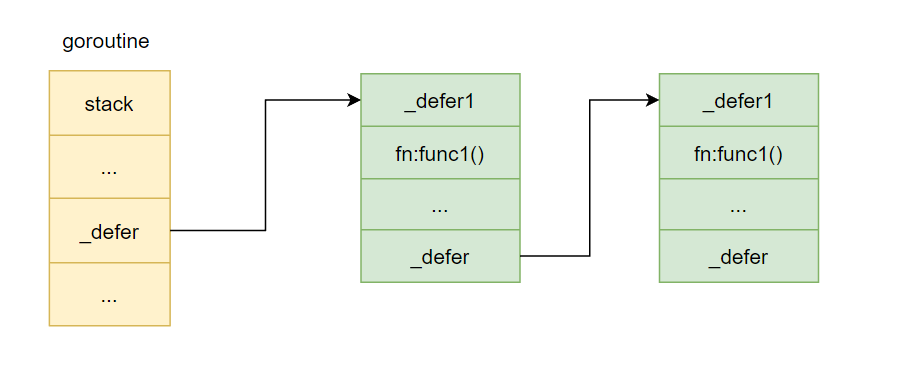
defer函数在注册的时候,创建的_defer结构会依次插入到_defer链表的表头,在当前函数return的时候,依次从_defer链表的表头取出_defer结构执行里面的fn函数
头插法(push 到链表头),所以 defer 的执行顺序是 后进先出 LIFO
defer的执行过程
在探究defer的执行过程之前,先简单看一下go语言程序的编译过程,go语言程序由.go文件编译成最终的二进制机器码主要有以下结果步骤
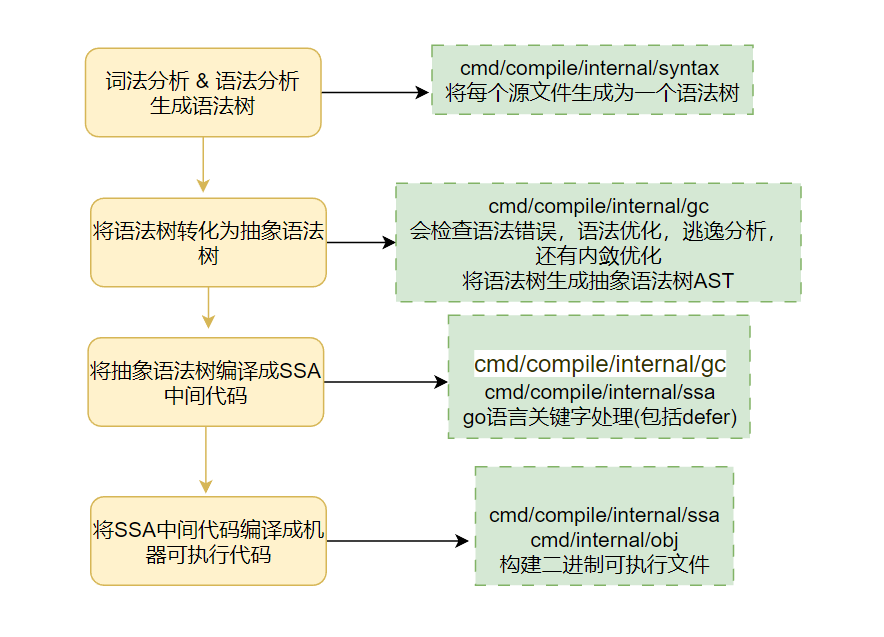
defer关键字的处理在生成SSA中间代码阶段,编译器遇到defer 语句的时候,会插入两种函数:
-
defer内存分配函数:deferproc(堆分配)或 deferprocStack(栈分配)
-
执行函数:deferreturn
下面分别看一下这两种函数的执行过程
defer的处理逻辑在cmd/compile/internal/ssagen/ssa.go文件中的state.stmt()方法中,由于源码过长,这里只贴部分重要代码:
go
case ir.ODEFER: // 如果节点defer节点
n := n.(*ir.GoDeferStmt)
if base.Debug.Defer > 0 {
var defertype string
if s.hasOpenDefers {
defertype = "open-coded" // 开放编码
} else if n.Esc() == ir.EscNever {
defertype = "stack-allocated" // 栈分配
} else {
defertype = "heap-allocated" // 堆分配
}
base.WarnfAt(n.Pos(), "%s defer", defertype)
}
if s.hasOpenDefers { // 如果可以开放编码,即内联实现
s.openDeferRecord(n.Call.(*ir.CallExpr)) // 就使用开放编码这种方式
} else {
d := callDefer // 否则先默认使用堆分配的模式
if n.Esc() == ir.EscNever { // 没有内存逃逸,使用栈分配的方式实现
d = callDeferStack
}
s.callResult(n.Call.(*ir.CallExpr), d)
}从上述代码可以看出,defer的是现有三种实现方式,在栈上分配内存,在堆上分配内存以及使用开放编码的方式。
会优先使用内联方式,当内联不满足,且没有发生内存逃逸的情况下,使用栈分配的方式,这两种情况都不符合的情况下在使用堆分配,这样做的好处是提升性能。
_defer内存分配
defer 的实现方式由编译器决定:优先使用 open-coded defer;如果不能开放编码,则根据逃逸分析决定 _defer 记录是栈上分配还是堆上分配。是否堆分配取决于 defer 记录及其捕获的环境/参数是否会逃逸,而不是简单取决于被 defer 的函数"是否简单"或"函数内部是否动态分配"。
在上面的分析中我们可以看出在不同的情况下,_defer结构分配在不同的地方,可能分配在堆上也可能分配在栈上,这两种分配方式调用的函数是不同的,堆上分配实际调用的是 runtime.deferproc 函数,栈上分配内存调用的是 runtime.deferprocStack 函数,下面分别来看看这两个函数都做了些什么工作?
堆上分配
先看deferproc 函数,在堆上分配内存,go 1.13 之前只有这个函数,说明go 1.13 之前,_defer只能在堆上分配。
src/runtime/panic.go
go
// Create a new deferred function fn, which has no arguments and results.
// The compiler turns a defer statement into a call to this.
func deferproc(fn func()) {
// 获取goroutine,defer在哪个goroutine中执行
gp := getg()
if gp.m.curg != gp {
// go code on the system stack can't defer
throw("defer on system stack")
}
// 在堆中创建一个_defer对象
d := newdefer()
// 将这个新建的defer对象加入到goroutine的defer链表头部
d.link = gp._defer
gp._defer = d
d.fn = fn
d.pc = sys.GetCallerPC()
// We must not be preempted between calling GetCallerSP and
// storing it to d.sp because GetCallerSP's result is a
// uintptr stack pointer.
d.sp = sys.GetCallerSP()
}重点看一下newdefer()这个函数
go
// Each P holds a pool for defers.
// Allocate a Defer, usually using per-P pool.
// Each defer must be released with freedefer. The defer is not
// added to any defer chain yet.
func newdefer() *_defer {
var d *_defer
mp := acquirem()
// 获取逻辑处理器P
pp := mp.p.ptr()
// p的本地defer缓存池为空且全局defer缓存池不为空,从全局defer缓存池取出一个defer结构加入到p的本地defer缓存池
if len(pp.deferpool) == 0 && sched.deferpool != nil {
lock(&sched.deferlock)
for len(pp.deferpool) < cap(pp.deferpool)/2 && sched.deferpool != nil {
d := sched.deferpool
sched.deferpool = d.link
d.link = nil
pp.deferpool = append(pp.deferpool, d)
}
unlock(&sched.deferlock)
}
// p的本地defer缓存池取出一个defer结构
if n := len(pp.deferpool); n > 0 {
d = pp.deferpool[n-1]
pp.deferpool[n-1] = nil
pp.deferpool = pp.deferpool[:n-1]
}
releasem(mp)
mp, pp = nil, nil
// p的本地defer缓存池和全局defer缓存池都没有可用的defer结构,在堆上创建一个
if d == nil {
// Allocate new defer.
d = new(_defer)
}
d.heap = true
return d
}可以看出堆上defer的创建思想借助了内存复用,用到了内存池的思想,创建defer的过程是:优先在P的本地和全局的defer缓存池里找到一个可用的defer结构返回,找不到在去堆上创建
栈上分配
下面看一下 runtime.deferprocStack 函数,在栈上分配_defer,这个函数是go 1.13 之后引入的,优化defer性能的,显然在栈上分配的效率更高。
runtime.deferprocStack 源码如下:
go
// deferprocStack queues a new deferred function with a defer record on the stack.
// The defer record must have its fn field initialized.
// All other fields can contain junk.
// Nosplit because of the uninitialized pointer fields on the stack.
//
//go:nosplit
// 在调用这个函数之前,defer结构已经在栈上创建好,这里只是作为参数传进来赋值
func deferprocStack(d *_defer) {
// 获取goroutine,defer在哪个goroutine中执行
gp := getg()
if gp.m.curg != gp {
// go code on the system stack can't defer
throw("defer on system stack")
}
// fn is already set.
// The other fields are junk on entry to deferprocStack and
// are initialized here.
// 堆上分配为false
d.heap = false
d.rangefunc = false
d.sp = sys.GetCallerSP()
d.pc = sys.GetCallerPC()
// The lines below implement:
// d.panic = nil
// d.fd = nil
// d.link = gp._defer
// d.head = nil
// gp._defer = d
// But without write barriers. The first three are writes to
// the stack so they don't need a write barrier, and furthermore
// are to uninitialized memory, so they must not use a write barrier.
// The fourth write does not require a write barrier because we
// explicitly mark all the defer structures, so we don't need to
// keep track of pointers to them with a write barrier.
*(*uintptr)(unsafe.Pointer(&d.link)) = uintptr(unsafe.Pointer(gp._defer))
*(*uintptr)(unsafe.Pointer(&d.head)) = 0
*(*uintptr)(unsafe.Pointer(&gp._defer)) = uintptr(unsafe.Pointer(d))
}Go 在编译的时候在 SSA中间代码阶段,如果判断出_defer需要在栈上分配,则编译器会直接在函数调用栈上初始化 _defer 记录,并作为参数传递给 deferprocStack 函数。
开放编码
再看一下defer的第三种实现方式,开放编码。这种方式是在go1.14 引入的继续优化defer实现性能的方式。在go1.14 中通过代码内联优化,使得函数末尾直接对 defer 函数进行调用,减少了函数调用开销。其主要逻辑位于 cmd/compile/internal/walk/stmt.go文件的 walkStmt()函数和 cmd/compile/internal/ssagen/ssa.go 的 buildssa()函数,函数较长,这里看一下关键代码。
walkStmt()函数:
go
case ir.ODEFER: // 如果节点defer节点
n := n.(*ir.GoDeferStmt)
ir.CurFunc.SetHasDefer(true)
ir.CurFunc.NumDefers++
if ir.CurFunc.NumDefers > maxOpenDefers { // maxOpenDefers = 8
// defer函数的个数多余8个时,不能用开放编码模式
ir.CurFunc.SetOpenCodedDeferDisallowed(true)
}
if n.Esc() != ir.EscNever {
// If n.Esc is not EscNever, then this defer occurs in a loop,
// so open-coded defers cannot be used in this function.
ir.CurFunc.SetOpenCodedDeferDisallowed(true)
}
fallthrough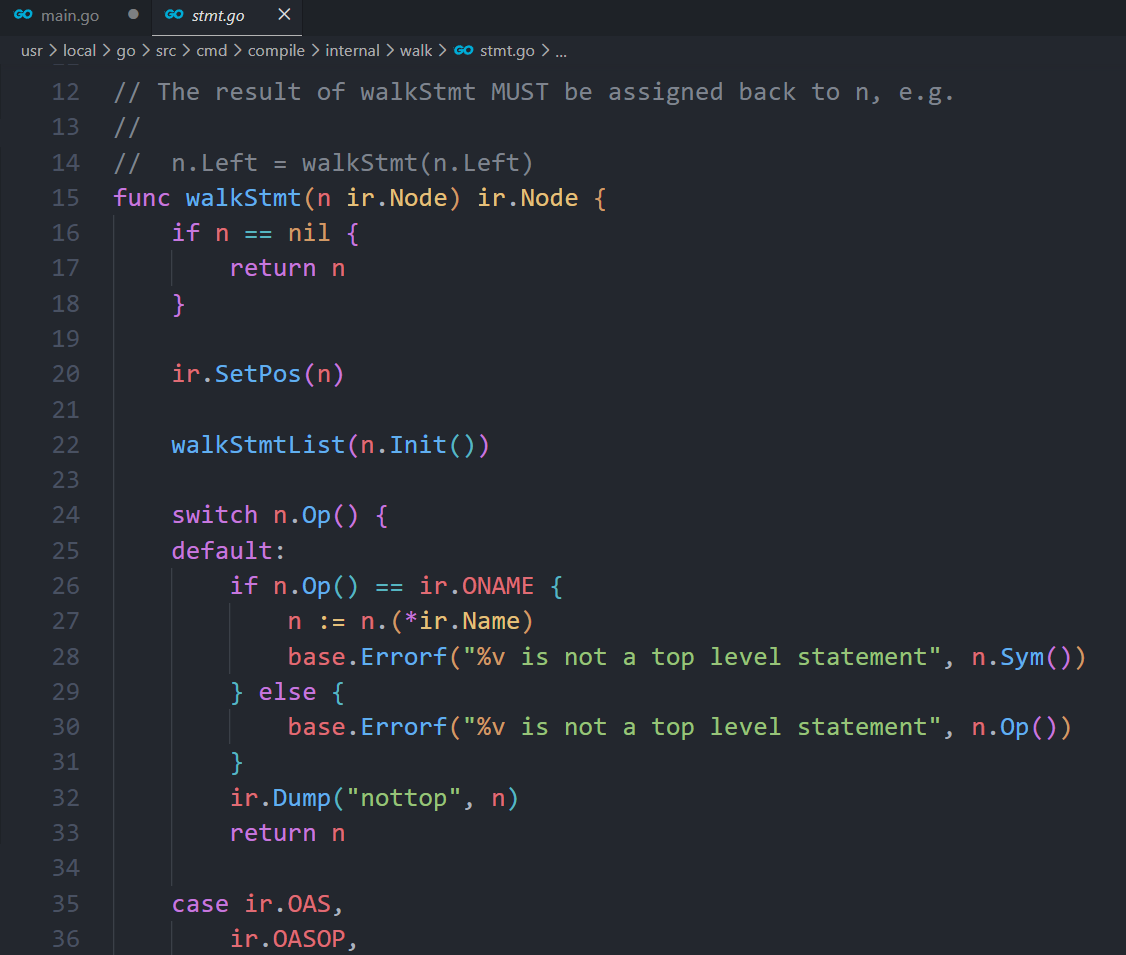
这里分析一下 n.Esc() != ir.EscNever 这个条件:
通过源码注释可以看到,这里其实就是判断defer是否在循环体内,因为 defer 在 for 循环中调用,编译器不确定会执行多少次,会逃逸到堆上,这样defer就只能分配在堆中了 。所以在使用defer 延迟调用的时候,尽量不要在循环中使用,否则可能导致性能问题。
buildssa()函数:
go
// build时候的没有设置-N,允许内联
s.hasOpenDefers = base.Flag.N == 0 && s.hasdefer && !s.curfn.OpenCodedDeferDisallowed()
switch {
case base.Debug.NoOpenDefer != 0:
s.hasOpenDefers = false
case s.hasOpenDefers && (base.Ctxt.Flag_shared || base.Ctxt.Flag_dynlink) && base.Ctxt.Arch.Name == "386":
// Don't support open-coded defers for 386 ONLY when using shared
// libraries, because there is extra code (added by rewriteToUseGot())
// preceding the deferreturn/ret code that we don't track correctly.
//
// TODO this restriction can be removed given adjusted offset in computeDeferReturn in cmd/link/internal/ld/pcln.go
s.hasOpenDefers = false
}
if s.hasOpenDefers && s.instrumentEnterExit {
// Skip doing open defers if we need to instrument function
// returns for the race detector, since we will not generate that
// code in the case of the extra deferreturn/ret segment.
s.hasOpenDefers = false
}
if s.hasOpenDefers {
// Similarly, skip if there are any heap-allocated result
// parameters that need to be copied back to their stack slots.
for _, f := range s.curfn.Type().Results() {
if !f.Nname.(*ir.Name).OnStack() {
s.hasOpenDefers = false
break
}
}
}
// defer所在函数返回值个数和defer函数个数乘积不能大于15
if s.hasOpenDefers &&
s.curfn.NumReturns*s.curfn.NumDefers > 15 {
// Since we are generating defer calls at every exit for
// open-coded defers, skip doing open-coded defers if there are
// too many returns (especially if there are multiple defers).
// Open-coded defers are most important for improving performance
// for smaller functions (which don't have many returns).
s.hasOpenDefers = false
}
总结一下:在go1.14之后,go会优先采用内联的方式处理defer函数调用,但是需要满足以下几个条件:
• build编译的时候没有设置 -N
• defer 函数个数没有超过 8 个
• defer所在函数返回值个数和defer函数个数乘积不超过15
• defer没有出现在循环语句中
defer函数执行
在给defer分配好内存之后 ,剩下的就是执行了。在函数退出的时候,deferreturn 来执行defer链表上的各个defer函数。函数源码如下:
go
// deferreturn runs deferred functions for the caller's frame.
// The compiler inserts a call to this at the end of any
// function which calls defer.
func deferreturn() {
var p _panic
p.deferreturn = true
// 遍历goroutine的defer链表
p.start(sys.GetCallerPC(), unsafe.Pointer(sys.GetCallerSP()))
for {
fn, ok := p.nextDefer()
if !ok {
break
}
// 执行函数调用
fn()
}
}
// start initializes a panic to start unwinding the stack.
//
// If p.goexit is true, then start may return multiple times.
func (p *_panic) start(pc uintptr, sp unsafe.Pointer) {
gp := getg()
// Record the caller's PC and SP, so recovery can identify panics
// that have been recovered. Also, so that if p is from Goexit, we
// can restart its defer processing loop if a recovered panic tries
// to jump past it.
p.startPC = sys.GetCallerPC()
p.startSP = unsafe.Pointer(sys.GetCallerSP())
if p.deferreturn {
// 获取调用栈的栈顶指针
p.sp = sp
// 开放编码模式 内联处理
if s := (*savedOpenDeferState)(gp.param); s != nil {
// recovery saved some state for us, so that we can resume
// calling open-coded defers without unwinding the stack.
gp.param = nil
p.retpc = s.retpc
p.deferBitsPtr = (*byte)(add(sp, s.deferBitsOffset))
p.slotsPtr = add(sp, s.slotsOffset)
}
return
}
p.link = gp._panic
gp._panic = (*_panic)(noescape(unsafe.Pointer(p)))
// Initialize state machine, and find the first frame with a defer.
//
// Note: We could use startPC and startSP here, but callers will
// never have defer statements themselves. By starting at their
// caller instead, we avoid needing to unwind through an extra
// frame. It also somewhat simplifies the terminating condition for
// deferreturn.
p.lr, p.fp = pc, sp
p.nextFrame()
}
// nextDefer returns the next deferred function to invoke, if any.
//
// Note: The "ok bool" result is necessary to correctly handle when
// the deferred function itself was nil (e.g., "defer (func())(nil)").
func (p *_panic) nextDefer() (func(), bool) {
gp := getg()
if !p.deferreturn {
if gp._panic != p {
throw("bad panic stack")
}
if p.recovered {
mcall(recovery) // does not return
throw("recovery failed")
}
}
// The assembler adjusts p.argp in wrapper functions that shouldn't
// be visible to recover(), so we need to restore it each iteration.
p.argp = add(p.startSP, sys.MinFrameSize)
for {
for p.deferBitsPtr != nil {
bits := *p.deferBitsPtr
// Check whether any open-coded defers are still pending.
//
// Note: We need to check this upfront (rather than after
// clearing the top bit) because it's possible that Goexit
// invokes a deferred call, and there were still more pending
// open-coded defers in the frame; but then the deferred call
// panic and invoked the remaining defers in the frame, before
// recovering and restarting the Goexit loop.
if bits == 0 {
p.deferBitsPtr = nil
break
}
// Find index of top bit set.
i := 7 - uintptr(sys.LeadingZeros8(bits))
// Clear bit and store it back.
bits &^= 1 << i
*p.deferBitsPtr = bits
return *(*func())(add(p.slotsPtr, i*goarch.PtrSize)), true
}
Recheck:
if d := gp._defer; d != nil && d.sp == uintptr(p.sp) {
if d.rangefunc {
deferconvert(d)
popDefer(gp)
goto Recheck
}
// 非内联模式
// 获取defer的执行函数
fn := d.fn
p.retpc = d.pc
// Unlink and free.
popDefer(gp)
return fn, true
}
if !p.nextFrame() {
return nil, false
}
}
}
// popDefer pops the head of gp's defer list and frees it.
func popDefer(gp *g) {
d := gp._defer
// defer上的函数指针置空
d.fn = nil // Can in theory point to the stack
// We must not copy the stack between the updating gp._defer and setting
// d.link to nil. Between these two steps, d is not on any defer list, so
// stack copying won't adjust stack pointers in it (namely, d.link). Hence,
// if we were to copy the stack, d could then contain a stale pointer.
// 遍历下一个defer结构
gp._defer = d.link
d.link = nil
// After this point we can copy the stack.
if !d.heap {
return
}
mp := acquirem()
pp := mp.p.ptr()
if len(pp.deferpool) == cap(pp.deferpool) {
// Transfer half of local cache to the central cache.
var first, last *_defer
for len(pp.deferpool) > cap(pp.deferpool)/2 {
n := len(pp.deferpool)
d := pp.deferpool[n-1]
pp.deferpool[n-1] = nil
pp.deferpool = pp.deferpool[:n-1]
if first == nil {
first = d
} else {
last.link = d
}
last = d
}
lock(&sched.deferlock)
last.link = sched.deferpool
sched.deferpool = first
unlock(&sched.deferlock)
}
*d = _defer{}
// 释放defer结构,优先归还到defer缓冲池中
pp.deferpool = append(pp.deferpool, d)
releasem(mp)
mp, pp = nil, nil
}
当 go函数的 return 关键字执行的时候,触发 call 调用 deferreturn 函数,deferreturn函数的执行逻辑也很简单,就是遍历goroutine上的defer链表,从表头开始遍历,依次取出defer结构执行defer结构中的函数执行。
总结:
-
遇到defer关键字,编译器会在编译阶段注册defer函数的时候插入 deferproc() 函数或者 deferprocStack 函数,在return之前插入deferreturn()函数
-
defer函数的执行顺序是LIFO的,因为每次创建的defer结构都是插入到goroutine的defer链表表头
-
defer结构的有三种实现方式,堆上分配,栈上分配还有内联实现
非内联模式defer结构上的fn字段就是对应的defer执行函数 而内联模式直接将defer函数展开在函数里面 你可以看到非内联模式调用的是defer结构里面的fn函数 而内联模式是直接运行的栈帧某段代码(defer函数展开的内容)

defer面试与分析
1、defer的底层数据结构是怎样的
回顾这个图:
每个 defer 语句都对应一个_defer 实例,多个实例使用指针连接起来形成一个单链表,保存在 goroutine 数据结构中,每次插入_defer 实例,均插入到链表的头部,函数结束再一次从头部取出,从而形成后进先出的效果
2、循环体中能用defer调用吗? 会有什么问题,为什么?
循环体中不要使用defer调用语句,一方面是会影响性能,另一方面是可能会发生一些意想不到的结果
首先,在循环中使用defer可能会发生内存逃逸(逃逸就是"编译器不敢放栈上,只能放堆上",代价通常是更多分配和 GC,性能会变差。),这样defer有可能分配到堆上,相比于栈上分配和内联方式,是性能最差的一种内存分配方式,会导致程序的性能问题
另外,可能会带来一些系统问题。比如在一个循环中,用defer函数来操作文件,如下:
go
for _, filename := range filenames {
f, err := os.Open(filename)
if err != nil {
return err
}
defer f.Close()
}这段代码很可能会用尽所有文件描述符。因为 defer 语句不到函数的最后一刻是不会执行的,也就是说文件始终得不到关闭
3、defer能修改返回值吗,defer与return的先后关系是怎样的?
defer可以修改返回值,当函数的返回值是非匿名的,有显示返回值的时候,defer可以修改返回值。函数的返回其实不是一个原子操作,可以理解为三个步骤:
-
设置返回值
-
执行defer语句
-
将结果返回
4、多个defer的执行顺序是怎样的?
后进先出,类似于栈,先调用的defer语句后执行
之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!