
【作者主页】Francek Chen
【专栏介绍】⌈ ⌈ ⌈大数据技术原理与应用 ⌋ ⌋ ⌋专栏系统介绍大数据的相关知识,分为大数据基础篇、大数据存储与管理篇、大数据处理与分析篇、大数据应用篇。内容包含大数据概述、大数据处理架构Hadoop、分布式文件系统HDFS、分布式数据库HBase、NoSQL数据库、云数据库、MapReduce、Hadoop再探讨、数据仓库Hive、Spark、流计算、Flink、图计算、数据可视化,以及大数据在互联网领域、生物医学领域的应用和大数据的其他应用。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/BigData_principle_application。
文章目录
-
- 一、Hadoop简介
- 二、Hadoop发展简史
- 三、Hadoop的特性
- 四、Hadoop的应用现状
- [五、Apache Hadoop版本演变](#五、Apache Hadoop版本演变)
一、Hadoop简介
Hadoop 是 Apache 软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。Hadoop 是基于 Java 语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中。Hadoop 的核心是分布式文件系统 HDFS(Hadoop Distributed File System)和 MapReduce。HDFS 是针对谷歌文件系统(Google File System,GFS)的开源实现,是面向普通硬件环境的分布式文件系统,具有较高的读写速度、很好的容错性和可伸缩性,支持大规模数据的分布式存储,其冗余数据存储的方式很好地保证了数据的安全性。MapReduce 是针对谷歌 MapReduce 的开源实现,允许用户在不了解分布式系统底层细节的情况下开发并行应用程序,采用 MapReduce 来整合分布式文件系统上的数据,可保证分析和处理数据的高效性。借助于 Hadoop,程序员可以轻松地编写分布式并行程序,将其运行于廉价计算机集群上,完成海量数据的存储与计算。
Hadoop 被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力。几乎所有主流厂商都围绕 Hadoop 提供开发工具、开源软件、商业化工具和技术服务,如谷歌、雅虎、微软、思科、淘宝等,都支持 Hadoop。
二、Hadoop发展简史
Hadoop 这个名称朗朗上口,至于为什么要取这样一个名字,其实并没有深奥的道理,只是追求名称简短、容易发音和记忆而已。很显然,小孩子是这方面的高手,大名鼎鼎的"Google"就是小孩子给取的名字,Hadoop 同样如此,它是小孩子给"一头吃饱了的棕黄色大象"取的名字。Hadoop 后来的很多子项目和模块的命名方式都沿用了这种风格,如 Pig 和 Hive 等。

图1 Hadoop的标志
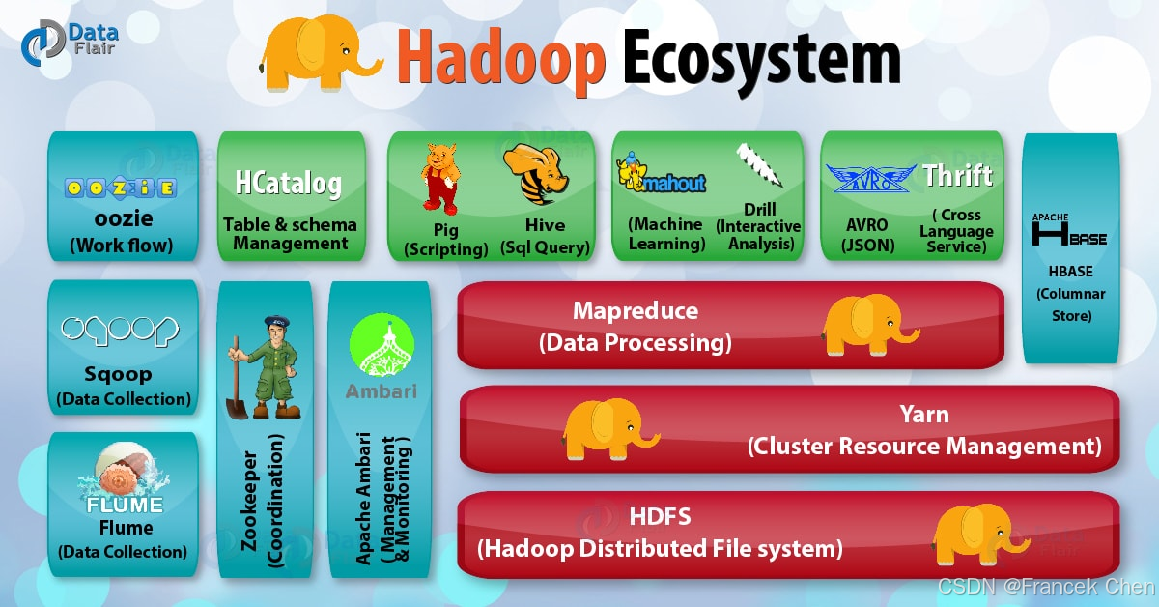
图2 Hadoop生态圈
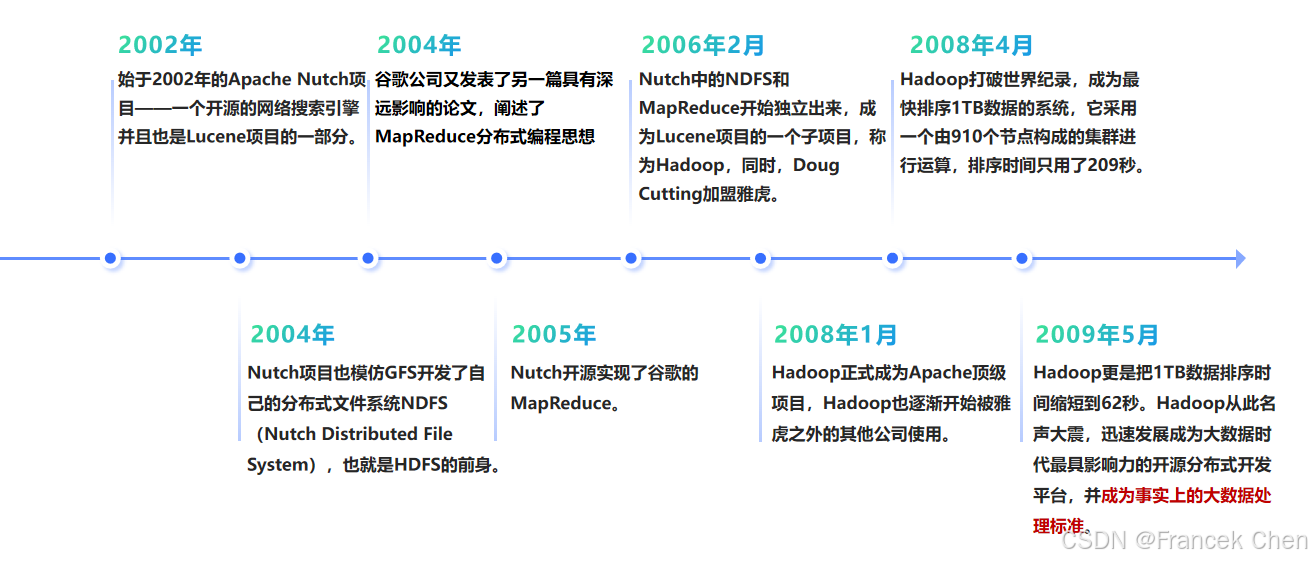
Hadoop 最初是由 Apache Lucene 项目的创始人 Doug Cutting 开发的文本搜索库。发展简史如下。
三、Hadoop的特性
Hadoop 是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性:
- 高可靠性。采用冗余数据存储方式,即使一个副本发生故障,其他副本也可以保证正常对外提供服务。
- 高效性。作为并行分布式计算平台,Hadoop 采用分布式存储和分布式处理两大核心技术,能够高效地处理 PB 级数据。
- 高可扩展性。Hadoop 的设计目标是可以高效稳定地运行在廉价的计算机集群上,可以扩展到数以千计的计算机节点上。
- 高容错性。采用冗余数据存储方式,自动保存数据的多个副本,并且能够自动将失败的任务进行重新分配。
- 成本低。Hadoop 采用廉价的计算机集群,成本比较低,普通用户也很容易用自己的 PC 搭建 Hadoop 运行环境。
- 运行在 Linux 操作系统上。Hadoop 是基于 Java 开发的,可以较好地运行在 Linux 操作系统上。
- 支持多种编程语言。Hadoop 上的应用程序也可以使用其他语言编写,如 C++。
四、Hadoop的应用现状
Hadoop 凭借其突出的优势,已经在各个领域得到了广泛的应用,而互联网领域是其应用的主阵地。
2007 年,雅虎公司在 Sunnyvale 总部建立了 M45------一个包含了 4000 个处理器和 1.5 PB 容量的 Hadoop 集群系统。此后,包括卡内基梅隆大学、加州大学伯克利分校、康奈尔大学和马萨诸塞大学阿默斯特分校、斯坦福大学、华盛顿大学、密歇根大学、普渡大学等 12 所大学加入该集群系统的研究,推动了开放平台下的开放源码发布。
国内采用 Hadoop 的公司主要有百度、淘宝、网易、华为、中国移动等,其中,淘宝的 Hadoop 集群比较大。据悉,淘宝 Hadoop 集群拥有 2860 个节点,清一色基于英特尔处理器的 x86 服务器,其总存储容量达到 50PB,实际使用容量超过 40PB,日均作业数高达 15 万,服务于阿里巴巴集团各部门,数据源于各部门产品的线上数据库(Oracle、MySQL)备份、系统日志以及爬虫数据等,每天在 Hadoop 集群运行各种 MapReduce 任务,如数据魔方、量子统计、推荐系统、排行榜等。
作为全球最大的中文搜索引擎公司,百度对海量数据的存储和处理要求是非常高的。因此,百度选择了 Hadoop,主要用于日志的存储和统计、网页数据的分析和挖掘、商业分析、在线数据反馈、网页聚类等。百度公司目前拥有 3 个 Hadoop 集群,计算机节点数量在 700 个左右,并且规模还在不断增加中,每天运行的 MapReduce 任务在 3000 个左右,处理数据约 120 TB/天。
华为是 Hadoop 的使用者,也是 Hadoop 技术的重要推动者。由雅虎成立的 Hadoop 公司 Hortonworks 曾经发布一份报告,用来说明各个公司对 Hadoop 发展的贡献。其中,华为公司在 Hadoop 重要贡献公司名单内,排在谷歌和思科公司的前面,说明华为公司也在积极参与开源社区的建设。
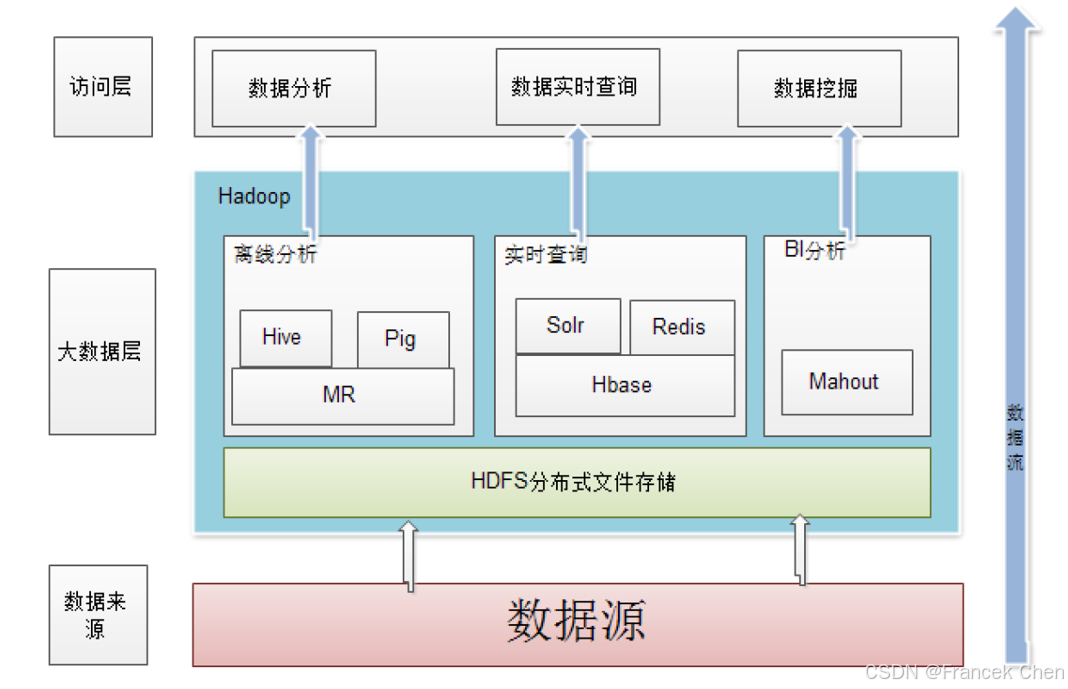
图3 Hadoop在企业中的应用架构
五、Apache Hadoop版本演变
Apache Hadoop 版本分为三代,分别是 Hadoop 1.0、Hadoop 2.0 和 Hadoop 3.0。第一代 Hadoop 包含 0.20.x、0.21.x 和 0.22.x 三大版本,其中,0.20.x 最后演化成 1.0.x,变成了稳定版,而 0.21.x 和 0.22.x 增加了 HDFS HA 等重要的新特性。第二代 Hadoop 包含 0.23.x 和 2.x 两大版本,它们完全不同于 Hadoop 1.0,是一套全新的架构,均包含 HDFS Federation 和 YARN(Yet Another Resource Negotiator)两个系统。Hadoop 2.0 是基于 JDK 1.7 开发的,而 JDK 1.7 在 2015 年 4 月已停止更新,于是 Hadoop 社区基于 JDK1.8 重新发布了一个新的 Hadoop 版本,也就是 Hadoop 3.0。因此,到了 Hadoop 3.0 以后,JDK 版本的最低依赖从 1.7 变成了 1.8。Hadoop 3.0 中引入了一些重要的功能和优化,包括 HDFS 可擦除编码、多名称节点支持、任务级别的 MapReduce 本地优化、基于 cgroup 的内存和磁盘 IO 隔离等。
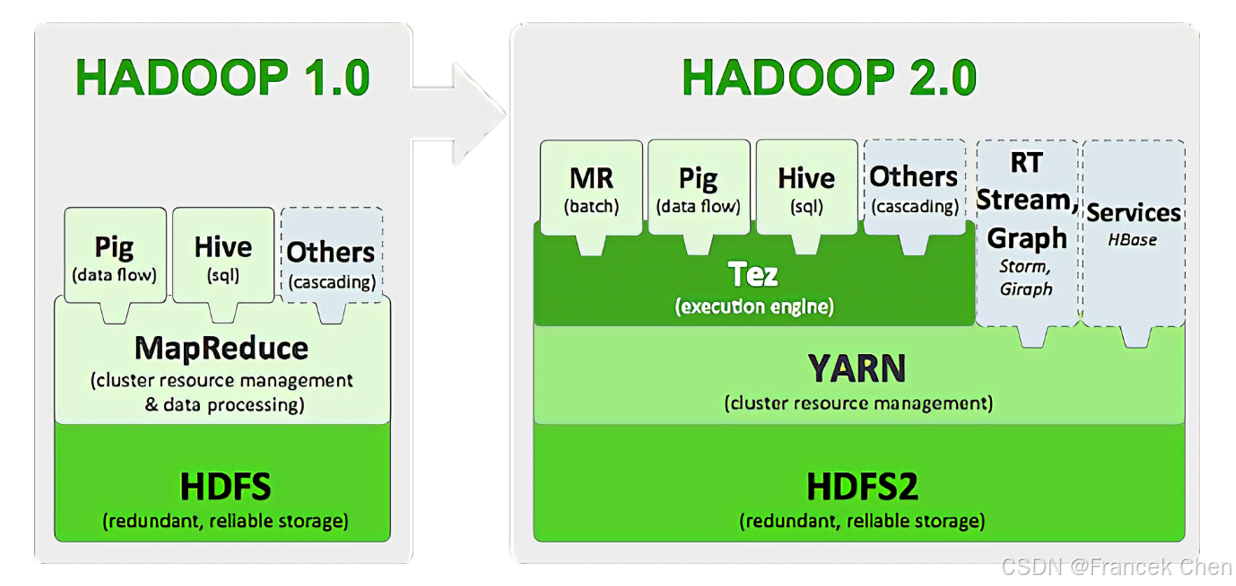
图4 Hadoop 1.0与Hadoop 2.0架构比较
除了免费开源的 Apache Hadoop 以外,还有一些商业公司推出的 Hadoop 的发行版。2008 年,Cloudera 成为第一个 Hadoop 商业化公司,并在 2009 年推出第一个 Hadoop 发行版。此后,很多大公司也加入了使 Hadoop 产品化的行列,比如 MapR、Hortonworks、星环等。2018 年 10 月,Cloudera 和 Hortonworks 宣布合并。一般而言,商业化公司推出的 Hadoop 发行版也是以 Apache Hadoop 为基础,但是前者比后者具有更好的易用性、更多的功能以及更高的性能。
表1 Hadoop各种版本
| 厂商名称 | 开放性 | 易用性 | 平台功能 | 性能 | 本地支持 | 总体评价 |
|---|---|---|---|---|---|---|
| apache | 完全开源、Hadoop就是托管在apache社区里面 | 安装:2,使用:2,维护:2 | Apache是标准的Hadoop平台,所有厂商都是在apache的平台上面进行改进 | 2 | 没有 | 2 |
| cloudera | 与Apache功能同步,部分代码开源 | 安装:5,使用:5,维护:5 | 有自主研发的产品如:impala、navigator等 | 4.5 | 2014年刚进入中国,上海 | 4.5 |
| hortonworks | 与apache功能同步,也是完全开源 | 安装:4.5,使用:5,维护:5 | 是apache hadoop平台的最大贡献者,如Tez | 4.5 | 没有 | 4.5 |
| MapR | 在apache的hadoop版本上面修改很多 | 安装:4.5,使用:5,维护:5 | 在apache平台上面优化很多、从而形成自己的产品 | 5 | 没有 | 3.5 |
| 星环 | 核心组件与apache同步、底层的优化比较多、完全封闭的一个平台 | 安装:5,使用:4,维护:4 | 有自主的Hadoop产品如Inceptor、Hyperbase | 4 | 本地厂商 | 4 |
欢迎 点赞👍 | 收藏⭐ | 评论✍ | 关注🤗
