兵器谱------深度学习、强化学习与 NLP 在安全中的典型应用场景
引言:
如果说传统的网络安全是基于规则的"冷兵器"时代,那么人工智能的介入则将我们推向了"热核武器"时代。
曾经,我们靠正则表达式和特征码构筑防线,但在黑客的加壳、混淆与多态攻击面前,这些防线脆弱得如同马其顿方阵面对坦克集群。本章将带你走进 AI 安全兵器谱的核心:看 深度学习 如何利用空间、时间与逻辑维度,对未知威胁进行降维打击;看 自然语言处理(NLP) 如何读懂代码与情报背后的深意;看 强化学习(RL) 如何在攻防博弈中,推演出如同棋局般的制胜策略。
这是一个从"感知智能"向"决策智能"惊险一跃的历程。欢迎来到智能攻防的新纪元。
第一章:从"特征码"到"特征空间"的范式革命
在正式介绍具体的AI模型之前,我们必须先解决一个认知层面的问题:为什么我们需要在网络安全中引入这些复杂的数学模型?
对于初学者而言,你可能习惯了使用Snort写一条规则,或者在WAF中配置一个正则表达式。这种基于签名(Signature-based)的防御逻辑清晰、误报率低,长期以来一直是安全界的定海神针。然而,面对当今的网络威胁,这种逻辑正在失效。
为什么?因为黑客学会了"多态"。
一个恶意软件可以通过加壳、混淆、指令重排,生成无数个哈希值完全不同但功能一致的变种。如果你还在用传统的特征码去匹配,就像是用一把固定的钥匙去试千万把锁,效率极其低下。
这里就是AI登场的高光时刻。
AI,特别是深度学习,不再关注"它长得是否完全一样",而是关注"它在数学空间中的距离是否足够近"。
想象一下,我们将所有的良性软件和恶意软件都映射到一个高维的数学空间中(比如1024维空间)。在这个空间里,所有的勒索软件虽然代码不同,但它们的"特征向量"会聚集成一团云;所有的正常办公软件会聚集成另一团云。深度学习模型的工作,就是在这个高维空间中,画出一道极其复杂的、非线性的超平面(Hyperplane),将这两团云分开。
这就解释了为什么AI能防住"未知威胁":只要你的行为特征落在了那个超平面的"恶意侧",哪怕我从未见过你的MD5,我依然判定你是恶意的。
接下来,我们将走进兵器谱的第一层,看看深度学习中的重装坦克------卷积神经网络(CNN)。
第二章:天眼------卷积神经网络(CNN)与"看得见"的恶意代码
2.1 当恶意代码变成一张画
提到卷积神经网络(CNN),即使是初学者可能也听说过它在图像识别领域的赫赫战名(如ImageNet竞赛)。它能一眼认出图片里是猫还是狗。但是,这和网络安全有什么关系?难道我们要让AI去监控摄像头的画面吗?
并不全是。在安全领域,CNN最令人拍案叫绝的应用之一,是将二进制恶意代码"可视化"。
【原理深解】
计算机文件本质上是一串0和1的字节流。如果我们把一个.exe文件看作是一个字节数组,比如一个大小为64KB的文件,我们可以把它重塑(Reshape)成一个256 \\times 256的矩阵。
在这个矩阵中,每一个字节(0-255)对应一个像素点的灰度值:0是黑色,255是白色。于是,一个枯燥的二进制文件,瞬间变成了一张灰度图片。
神奇的事情发生了:
- 勒索软件的图片纹理,通常表现出高熵值的混乱噪点,但在某些加密算法段落会有特定的条纹。
- 蠕虫病毒可能会有大量重复的各种纹理,代表其自我复制的代码段。
- 正常软件通常有清晰的区块结构,那是代码段、数据段和资源段的整齐排列。
这就是CNN的用武之地。 CNN最擅长提取图像中的局部相关性(Local Correlation)和平移不变性(Translation Invariance)。
- 局部相关性:恶意代码的功能往往由一小段连续的字节码决定,这在图像上表现为一个小纹理。CNN的卷积核(Convolution Kernel)就像一个放大镜,滑过整张图片,专门寻找这种特定的纹理特征。
- 平移不变性:黑客可能会在恶意代码前插入一段无用的垃圾指令(NOP Sled),导致恶意代码在文件中的位置后移。对于基于位置特征的传统算法这是灾难,但对于CNN来说,无论特征纹理出现在图片的左上角还是右下角,卷积核都能把它"抓"出来。
2.2 实战兵器:MalConv 及其变体
在学术界和工业界,一个经典的案例是MalConv模型。这是一个端到端的深度学习模型,它甚至不需要我们将文件转换成图片,而是直接将原始的字节流(Raw Bytes)作为输入。
如果说图像化是 2D 卷积的应用,那么 MalConv 则证明了 1D 卷积 直接处理原始字节序列的强大能力。它跳过了'可视化'的步骤,直接在二进制流上提取特征。
它的架构极具启发性:
- 嵌入层(Embedding Layer):将每个字节(0-255)映射为一个8维的向量。这就像给每个字符赋予了数学意义。
- 卷积层(Convolution Layer):使用一维卷积,同时捕捉字节序列中的局部特征。
- 全局池化(Global Pooling):无论文件多大,都提取出最显著的特征值。
- 全连接层(Fully Connected Layer):分类器,输出是"良性"还是"恶意"的概率。
【给专业人士的启示】
虽然CNN在静态恶意代码检测上表现优异,但在实际工程中,我们面临着对抗样本(Adversarial Examples)的严峻挑战。
黑客发现,只需在恶意文件的末尾(Overlay)追加一些精心计算的字节(这些字节不会被执行,不影响功能),就能改变生成的"图像"的梯度方向,从而欺骗CNN模型,让其误判为良性。
这引发了安全界的新一轮军备竞赛:对抗训练(Adversarial Training)。现在的先进模型在训练时,会故意引入这些加了扰动的样本,强迫模型学会忽略那些无用的填充字节,专注于核心的代码逻辑纹理。
此外,CNN不仅用于恶意代码,还被广泛用于钓鱼网页检测。通过截取网页的屏幕截图,CNN可以识别出那些伪装成微软登录界面或银行主页的视觉特征(Logo布局、颜色搭配),即使攻击者混淆了HTML源码,视觉上的相似性是无法掩盖的。
第三章:时之砂------循环神经网络(RNN/LSTM)与流量的脉搏
面对这种序列数据,CNN 显得有些力不从心,而传统的 RNN(循环神经网络)虽然能处理序列,却容易在长序列中迷失方向(即梯度消失问题 )。这时候,我们需要其进阶版------长短期记忆网络(LSTM)。如果说CNN处理的是"空间"上的特征(文件结构、图像),那么在网络安全中,还有另一半壁江山需要处理"时间"上的特征。这就是网络流量(Network Traffic)。
网络攻击往往不是一个孤立的瞬间动作,而是一个序列(Sequence)。
- 一次SQL注入攻击,是HTTP请求参数中的一串字符序列。
- 一次APT组织的横向移动,是一系列先后发生的登录、扫描、传输行为。
- 一个DGA(域名生成算法)生成的域名,是一串看似随机的字符序列。
面对这种序列数据,CNN显得有些力不从心,因为它是"健忘"的,它处理当前输入时并不记得上一个输入是什么。这时候,我们需要循环神经网络(RNN)及其进阶版长短期记忆网络(LSTM)。
3.1 DGA 域名的克星
僵尸网络(Botnet)为了防止被封锁,不会硬编码C2(命令与控制)服务器的IP地址,而是使用DGA算法每天生成成千上万个随机域名(如 agbfkwjeb.com)。
对于人类安全分析师来说,一眼就能看出 google.com 是正常的,而 xkyz123.com 是可疑的。但在AI眼里,这两者怎么区分?
LSTM在这里展现了惊人的能力。
我们可以把域名看作是一个字符序列。LSTM模型会按顺序读取每一个字符,并预测下一个字符出现的概率。
- 在英语单词中,q 后面大概率跟着 u,元音和辅音交替出现。这符合自然语言的统计规律。
- 在DGA生成的随机域名中,字符的组合是混乱的,打破了这种概率规律。
【深度解析】
通过训练一个基于LSTM的字符级语言模型(Character-level Language Model),我们可以计算一个域名的困惑度(Perplexity)。
如果一个域名让模型感到"很困惑"(即字符组合完全出乎模型的预料),那么它极大概率是DGA生成的。
相比于传统的基于信息熵(Entropy)的检测方法,LSTM不仅能检测出纯随机字符,甚至能检测出基于字典拼接的DGA(比如 red-blue-sky-net.com),因为它能学习到单词级别的语义搭配概率。
3.2 加密流量中的侧信道幽灵
TLS 1.3的普及让网络流量全面加密。对于防火墙(NGFW)和入侵检测系统(IDS)来说,这简直是噩梦------传统的深度包检测(DPI)失效了,因为看不见Payload(载荷)。
但是,黑客能加密内容,却无法加密"行为模式"。
这就好比两个人用加密方言打电话,虽然听不懂他们在说什么,但我们可以通过语速、停顿时间、谁先说话、说了多久,来判断他们是在吵架还是在谈生意。
利用LSTM或GRU(门控循环单元)处理加密流量的元数据序列:
- 包长度序列(Packet Length Sequence):请求包通常较小,响应包通常较大。
- 到达时间间隔序列(Inter-arrival Time, IAT):机器发包的节奏非常均匀,而人的操作有随机停顿。
- 方向序列:出站与入站的交替模式。
实战案例:
思科(Cisco)开源的Joy项目和相关的学术研究表明,仅通过分析加密流量的前20个数据包的大小和时间序列,配合LSTM模型,就能以超过95%的准确率识别出流量中是否包含恶意软件的通信,甚至能区分出是哪个家族的恶意软件(如Dridex还是TrickBot)。
这是因为不同的恶意软件在C2握手时的协议实现细节(指纹)是不同的,这种时序上的指纹被LSTM敏锐地捕捉到了。
第四章:因果之网------图神经网络(GNN)与攻击路径溯源
如果说序列模型(RNN)是在听"脉搏",那么图神经网络(GNN)就是在看"经络"。在复杂的内网环境或大型软件系统中,攻击行为不再是线性的,而是网状交织的。
4.1 挖掘代码的"灵魂图谱"
传统的漏洞扫描只能看到文字层面的错误,而 GNN 可以将源代码转化为控制流图(CFG)或数据流图(DFG)。
- 原理: GNN 通过"消息传递"机制,让每个节点(如一个函数或变量)吸收邻居节点的特征。
- 实战: 在二进制分析中,黑客即便修改了指令顺序或混淆了变量名,只要程序的逻辑拓扑结构(比如判断语句和循环跳转的指向关系)没变,GNN 就能精准识别出这段代码携带的恶意基因。
4.2 内网横向移动的"天罗地网"
在 APT 攻击中,攻击者从 A 登录到 B,再通过 B 访问数据库 C。这种行为单独看任何一个节点都是合法的,但在全局关系图中,它展现出一种异常的"子图结构"。 利用 图注意力网络(GAT),安全系统可以自动从数百万个登录关系中,识别出那条极其隐蔽、指向核心资产的异常链路。
第五章:照妖镜------自编码器(AutoEncoder)与异常检测
在上述的CNN和LSTM应用中,我们大多假设了一个前提:我们拥有大量的"黑样本"(恶意数据)和"白样本"(正常数据)来进行有监督学习(Supervised Learning)。
但在网络安全的真实战场上,最可怕的往往是0-day攻击------那些从未出现过、没有任何标签的攻击。如果我们只训练模型认识已知的攻击,那么对于新型攻击,模型将视而不见。
这时候,我们需要一种无监督学习(Unsupervised Learning)的兵器:自编码器(AutoEncoder, AE)。
5.1 "重构"即防御
自编码器的逻辑非常哲学:如果你能完美地复述一句话,说明你听懂了这句话;如果你复述得支支吾吾,说明这句话超出了你的认知。
AutoEncoder包含两个部分:
- 编码器(Encoder):将输入数据压缩成一个低维的向量(Latent Space)。
- 解码器(Decoder):尝试将这个低维向量还原回原始数据。
在安全中的应用逻辑是这样的:
我们只收集企业内部正常的业务流量或系统日志(白样本),扔进AutoEncoder里疯狂训练。目标是让模型的重构误差(Reconstruction Error)最小化。
换句话说,我们教会了模型"什么是正常"。
模型学习并建模了正常流量的潜在分布(Latent Distribution)。它不是在死记硬背,而是理解了正常业务的'骨架'。
检测阶段:
当一个新的流量进来时,无论它是正常的还是恶意的,我们都强制让模型去"压缩再还原"它。
- 如果是正常流量 ,因为它符合模型学过的规律,还原出来的结果和原始输入几乎一样,重构误差很小。
- 如果是攻击流量 (比如一次从未见过的SQL注入,或者异常的各种扫描),因为它不符合正常规律,模型在压缩还原过程中会丢失大量信息,还原出来的东西面目全非,重构误差巨大。
只要监控这个"重构误差",一旦超过阈值,就触发告警。
5.2 案例:Web应用防火墙(WAF)的进化
传统的WAF依靠正则规则库。一旦规则库没更新,新的绕过技巧(Bypass)就能穿透防御。
基于AutoEncoder的智能WAF不依赖任何攻击规则。它只学习什么是"合法的HTTP请求"。
比如,它学习到了特定URL参数通常是数字ID,或者特定的User-Agent分布。
当攻击者试图利用Log4j漏洞(${jndi:ldap://...})进行攻击时,虽然模型从没见过Log4j攻击,但它发现这个请求的结构、字符分布与平时见过的正常请求大相径庭,重构误差瞬间飙升。
这种异常检测(Anomaly Detection) 机制,是应对0-day攻击最有效的防线之一。虽然它容易产生误报(比如业务突然上线了新功能),但它保证了防御的底线------绝不漏过任何未知的异常。
第六章:迷雾与枷锁------AI 安全的工程现实
当我们看完了深度学习的"海陆空"编队后,必须直面一个残酷的真相:AI 并不是安全领域的银弹。在实验室 99% 的准确率,到了真实的生产环境可能会遭遇断崖式下跌。
- 黑盒之困(Explainability): 当 AI 拦截了一个关键业务请求,如果它不能给出具体的理由(是哪个包、哪个字段导致的问题),安全运营人员将面临"不敢阻断"的尴尬局面。XAI(可解释性 AI)是我们必须要攻克的防线。
- 概念漂移(Concept Drift): 攻击者是活的。今天的恶意软件特征,明天换个混淆器就变了。这种动态环境导致 AI 模型极易"过期"。
- 算力与时延的博弈: 在微秒级吞吐的防火墙上运行庞大的神经网络是不现实的。我们必须在模型的"深度"与响应的"速度"之间,寻找那个极其危险的平衡点。
第七章:通天塔------NLP 与大语言模型(LLM)的认知革命
在网络安全的世界里,语言(Language)无处不在。
源代码是语言(C/C++、Python),汇编指令是语言(Assembly),网络协议是语言(HTTP、TCP),甚至黑客在暗网论坛交流的威胁情报也是语言(自然语言)。
传统的安全工具在处理这些"语言"时,本质上是在做关键词匹配。
- 静态分析工具(SAST)在代码里搜 strcpy 判定溢出风险。
- 威胁情报平台(TIP)在报告里搜 IP 地址和哈希值。
这种方法没有"语义理解"。工具不知道 strcpy 在特定上下文里是否安全,也不知道那份情报报告是在说"攻击了这个IP"还是"这个IP是攻击者"。
自然语言处理(NLP),特别是基于 Transformer 架构的大语言模型(LLM),彻底打破了巴别塔。 它让机器第一次真正"读懂"了代码和情报背后的逻辑。
7.1 灵魂机制:注意力(Attention)与代码语义
要理解 NLP 在安全中的爆发,必须理解 Transformer 的核心------自注意力机制(Self-Attention)。
在安全语境下,我们可以这样通过数学直觉来理解 Attention:
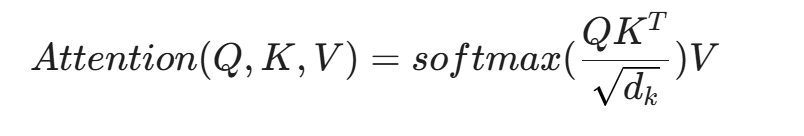
- Q (Query): 当前分析的代码片段(比如一个变量赋值)。
- K (Key): 代码中的其他所有片段(函数定义、条件判断、API调用)。
- V (Value): 这些片段的实际特征值。
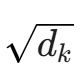 是缩放因子,防止内积过大导致梯度消失,确保模型训练的稳定性。
是缩放因子,防止内积过大导致梯度消失,确保模型训练的稳定性。
当模型分析一段恶意代码时,它不仅仅是顺序读取。通过 Attention 机制,模型在处理第 100 行的 exec() 函数时,能够"注意到"第 5 行定义的变量 cmd,即使中间隔了 95 行无关代码。模型会计算出第 5 行与第 100 行之间存在极强的语义关联权重(Attention Weight)。
这种能力解决了传统 RNN 在长序列代码分析中的"遗忘"问题。对于混淆过的恶意脚本(Obfuscated Script),变量名可能被改成了随机字符,结构被打乱,但数据流(Data Flow)和控制流(Control Flow)的依赖关系通过 Attention 机制被精准捕捉。
7.2 实战兵器一:代码大模型(Code LLMs)与漏洞挖掘
基于 BERT(双向编码器)或 GPT(生成式预训练变换器)架构的代码模型(如 CodeBERT、StarCoder、Codex),正在重塑应用安全(AppSec)。
7.2.1 语义级静态分析(SAST 2.0)
传统的 SAST 误报率极高,因为它不懂逻辑。
Code LLM 通过预训练,学习了数十亿行代码的"语法"与"语义"。
- 微调(Fine-tuning) :我们将标注好的漏洞代码库(如 NIST SAMATE、CWE 数据集)喂给模型,让它学习"缓冲区溢出"或"SQL 注入"在代码结构上的高维特征表示(Embedding)。
- 检测逻辑 :当扫描新代码时,模型不再匹配正则,而是计算这段代码的 Embedding 与已知漏洞模式的 Embedding 之间的余弦相似度(Cosine Similarity)。
案例:微软的研究表明,利用深度学习模型检测代码中的"Use-After-Free"(释放后重用)漏洞,能够发现传统静态工具完全忽略的复杂路径漏洞,因为模型"理解"了指针的生命周期。
7.2.2 自动化修复(Automated Program Repair, APR)
发现漏洞只是第一步,修复才是闭环。
利用 LLM 的生成能力(Generation),我们可以构建一个自动补丁机器人。
- 输入:含有漏洞的函数代码。
- Prompt:"这段代码存在 XSS 漏洞,请在不改变业务逻辑的前提下修复它。"
- 输出:经过转义处理的安全代码。
这并非科幻。GitHub Copilot 和众多商业化安全插件已经具备了这种能力。虽然目前还需要人工审核(Human-in-the-loop),但它将安全工程师从繁琐的修复工作中解放了出来。
7.3 实战兵器二:威胁情报(CTI)的知识图谱化
每天,全球产生数以万计的安全博客、白皮书、推特(X)预警。没有任何分析师能读完它们。
NLP 技术中的命名实体识别(NER)和关系抽取(Relation Extraction)是自动化的关键。
7.3.1 从非结构化文本到 IOC
假设有一段文本:"APT28 组织利用名为 Zebrocy 的恶意软件攻击了东欧某外交机构,C2 服务器 IP 为 1.2.3.4。"
NLP 模型的处理流程:
- NER:识别出 APT28 (Threat Actor), Zebrocy (Malware), 东欧某外交机构 (Victim), 2.3.4 (IP Address)。
- 关系抽取:识别出 (APT28) --uses--> (Zebrocy),(Zebrocy) --connects_to--> (1.3.4)。
- 图谱构建:将这些三元组存入图数据库(Neo4j),自动更新安全知识图谱。
7.3.2 攻击归因(Attribution)
基于风格测量学(Stylometry),NLP 甚至可以分析黑客编写的钓鱼邮件或勒索信的语言指纹。
- 用词习惯、拼写错误模式、语法结构偏好。
- 这能帮助分析师判断:这是那个俄语系的组织干的,还是英语系的新手模仿的?
7.4 阴暗面:WormGPT 与黑客的武器化
技术永远是双刃剑。我们在用 LLM 防御,黑客也在用 LLM 进攻。
- WormGPT / FraudGPT:这些是在暗网上流传的、移除了安全护栏(Jailbroken)的大模型。它们可以毫无道德负担地编写勒索软件、生成完美的钓鱼邮件。
- 多语言混淆:黑客利用 LLM 将恶意代码从 Python 重写为 Go,再重写为 Rust,每一次重写都彻底改变了代码的哈希值和语法结构,让传统杀毒软件瞬间失效。
第八章:策士------强化学习(RL)与博弈的艺术
如果说 NLP 是"静态"的知识处理,那么强化学习(Reinforcement Learning, RL) 就是"动态"的决策优化。
在网络安全中,攻防双方本质上是在进行一场不完全信息下的动态博弈。
- 状态(State):网络当前的拓扑、漏洞、流量情况。
- 动作(Action):攻击者的扫描、利用;防御者的封禁、隔离。
- 奖励(Reward):攻击成功得正分;被发现扣分。
RL 的核心在于Agent(智能体)通过与Environment(环境)的交互,试错(Trial and Error),最终学习到一个最优策略(Optimal Policy),以最大化长期奖励。
8.1 进攻侧:自动化渗透测试 Agent
传统的漏洞扫描器(如 Nessus)是死板的,只会按列表挨个测试。而人类渗透测试专家(Pentester)是灵活的,他们会根据服务器的响应调整策略。
RL 旨在训练出像人类一样的自动化渗透 Agent。
8.1.1 建模过程:MDP(马尔可夫决策过程)
我们将渗透测试建模为一个 MDP:
- 状态空间 (S):Agent 当前已知的网络信息(开放端口、操作系统指纹、已获取的 Shell 权限)。
- 动作空间 (A):Nmap 扫描、Metasploit 模块利用、SQLMap 注入、提权操作。
- 奖励函数 (R) :
- 发现新主机:+10
- 发现新服务:+20
- 获取 Shell:+1000
- 被防火墙拦截:-50 (惩罚,教会 Agent 隐蔽)
8.1.2 算法选型:DQN 与 PPO
- DQN (Deep Q-Network):通过深度神经网络来拟合 Q 表(动作价值函数)。Agent 输入当前网络状态,网络输出每个攻击动作的预期价值。
- 分层强化学习 (Hierarchical RL):由于渗透测试动作空间太大(成千上万个 Exploit),通常采用分层策略。上层 Agent 决定大方向(如"先扫描 Web 服务"),下层 Agent 执行具体操作(如"运行 SQL 注入脚本")。
8.1.3 实战案例:DeepExploit 与 IAPTS
DeepExploit 是一个经典的开源项目,它结合了 Metasploit 和强化学习。它能自动识别目标状态,选择最可能的 Exploit 进行攻击。如果攻击成功,它会获得奖励并记住所用策略;如果失败,它会尝试其他路径。
训练有素的 RL Agent 甚至能发现人类专家忽视的攻击路径组合(Attack Chain),例如:"先通过一个低危的信息泄露漏洞获取用户名,再结合暴力破解弱口令,最后利用 sudo 提权"。
8.2 防御侧:移动目标防御(MTD)与动态调度
传统的防御是静态的:IP 不变,端口不变,规则不变。这让攻击者有足够的时间去侦察。
移动目标防御(Moving Target Defense, MTD) 旨在让网络环境"动"起来,增加攻击者的攻击成本。
8.2.1 什么时候"动"?
如果网络每秒都在变(换 IP、换端口),虽然安全了,但业务也瘫痪了。
这是一个典型的多目标优化问题:既要安全性(Security),又要可用性(Availability)。
8.2.2 RL 驱动的调度策略
我们可以训练一个 RL 防御 Agent:
- 观测:当前的流量特征、IDS 告警级别。
- 动作 :
- 不做改变(保持业务流畅)。
- IP 跳变(Shuffle IP)。
- 操作系统轮转(切换虚拟机镜像)。
- 蜜罐诱导(重定向流量到蜜罐)。
- 奖励 :
- 业务正常运行:+1
- 攻击者探测失败:+10
- 业务中断:-100
通过在模拟环境(如网络靶场)中与攻击 Agent 进行千万次的对抗演练(Self-Play),防御 Agent 能学会极其精妙的策略:
- "平时保持静默,一旦检测到 445 端口有异常扫描,立即对关键数据库服务器进行 IP 跳变,并将原始 IP 映射到高交互蜜罐。"
这种自适应防御(Adaptive Defense),是未来 SOC 自动化响应(SOAR)的终极形态。
8.3 对抗样本:逃逸与反逃逸
在强化学习的加持下,恶意软件的免杀也变成了一场猫鼠游戏。
8.3.1 Gym-Malware:基于 RL 的免杀训练
黑客利用 OpenAI 的 Gym 框架构建了恶意软件环境。
- Agent:恶意代码修改器。
- 动作:添加无用字节、修改节头信息、压缩、加壳、指令替换。
- 环境:VirusTotal 上的反病毒引擎(或是本地部署的杀毒软件)。
- 奖励:如果杀毒软件报毒,奖励为 0;如果杀毒软件判定为绿标(Bypass),奖励为 100。
Agent 不断随机尝试修改策略,最终学会了一套能够绕过特定杀毒软件引擎的"组合拳"。
这给反病毒厂商带来了巨大压力:模型必须具备鲁棒性,必须在训练阶段就引入这些 RL 生成的对抗样本进行对抗训练(Adversarial Training)。
第九章:奇点------Agentic AI 与安全大一统
当我们把 LLM 的"认知能力"与 RL 的"决策能力"结合起来时,我们迎来了当前 AI 安全的最前沿:Agentic AI(智能体 AI)。
这不再是单一的模型,而是一个系统。
它拥有:
- 大脑(LLM):负责规划、推理、理解语境。
- 记忆(Memory):利用向量数据库(Vector DB)存储长期的攻击历史和知识库。
- 双手(Tools):能够调用 Nmap、Wireshark、Python 解释器、防火墙 API。
- 直觉(RL):在关键决策点进行价值评估。
目前的 Security Copilot 大多还是"副驾驶",需要人来发指令。
未来的 Autonomous Security Agent(自主安全智能体) 将是"主驾驶"。
场景构想:自动化的红蓝对抗
- 红队 Agent:被设定目标"获取数据库权限"。它自主制定计划,自主编写钓鱼邮件,自主根据回显调整代码,自主进行横向移动。
- 蓝队 Agent:被设定目标"保障核心资产不丢失"。它自主全流量监控,自主分析异常行为,自主下发封禁策略,自主进行取证溯源。
人类专家在这个过程中,将从"操作员"转变为"裁判员"和"策略制定者"。我们负责定义 Agent 的边界(Guardrails)和价值观(Alignment),防止它们失控。
第十章:工程落地的深渊------挑战与局限
尽管上述技术令人心潮澎湃,但在将它们部署到生产环境之前,作为专栏作者,我有责任泼一盆冷水,揭示那些论文里不会告诉你的"工程深渊"。
10.1 数据的高维诅咒与稀疏奖励
在强化学习中,最大的痛点是稀疏奖励(Sparse Reward)。
在渗透测试中,可能尝试了 10,000 次操作才成功拿到一次 Shell。对于 Agent 来说,前 9,999 步都没有得到正反馈,它很难知道哪一步是对的。
解决路径:我们需要设计内在好奇心机制(Intrinsic Curiosity),即只要 Agent 探索到了未知的网络状态,就给予少量奖励,鼓励它去探索,而不仅仅是为了最终结果。
10.2训练集的"特洛伊木马":数据投毒 如果说对抗样本(Adversarial Examples)是在模型上线后通过"障眼法"进行欺骗,那么数据投毒(Data Poisoning)则是从娘胎里就毁掉模型。
- 攻击路径: 黑客通过在训练样本中掺入极少量(甚至不到 1%)的恶意构造样本,在 AI 内部埋下"后门"。
- 清洁标签攻击(Clean-Label Attack): 这是最高级的手段。样本看起来完全正常(比如一个普通的 HTTP 请求),但它携带了特定的"触发器"(Trigger)。只要模型在推理时遇到该触发器,就会无视其任何恶意行为,将其永久判定为良性。
- 防御困局: 在处理千万级规模的安全日志时,人工审计每一条训练数据的成本极高,这让 AI 训练集本身成为了安全脆弱点。
10.3 幻觉(Hallucination)的致命风险
LLM 会一本正经地胡说八道。
在生成安全报告时,如果 LLM 编造了一个不存在的漏洞,或者错误地将正常文件标记为恶意(False Positive),可能会导致严重的业务中断。
解决路径:RAG(检索增强生成)是必选项。一定要让 LLM 基于外挂的、可信的知识库(如 CVE 数据库、企业内部文档)来回答问题,并强制要求其提供引用的来源(Citations)。同时,必须引入确定性校验代码,LLM 生成的 SQL 语句或 Python 脚本,必须先在一个沙箱里跑通,确认无误后才能输出。
10.4 算力与时延
运行一个 70B 参数的 Llama-3 模型,或者进行实时的 RL 推理,需要昂贵的 GPU 资源。
在网络安全中,延迟(Latency)是生与死的界限。WAF 处理一个请求如果超过 10 毫秒,用户体验就会下降。
解决路径:模型蒸馏(Knowledge Distillation)。用一个巨大的教师模型教会一个轻量级的学生模型。在边缘设备(Edge)上部署量化后的小模型,只处理常见威胁,遇到高难度的才回传云端大模型处理。
结语:
至此,我们用近万字的深度剖析,完整扫描了 AI 安全的兵器谱。
- 深度学习(CNN/RNN/AE) :是我们的眼和耳,帮我们在海量数据中实现高精度的模式识别,看见了代码的纹理,听见了流量的节奏。
- 自然语言处理(NLP/LLM) :是我们的脑,帮我们理解非结构化的情报与代码,打破了人类语言与机器语言的隔阂。
- 强化学习(RL) :是我们的手,帮我们在动态的对抗环境中,像AlphaGo一样计算出最优的攻防步数。
未来的路在哪里?
未来的网络安全,将不再是人与人的对抗,也不是人与机器的对抗,而是人+AI"与"人+AI"的混合战争(Centaur War)。
在接下来的模块中,我们将走出理论的兵器库,进入"数据为王"的演练场,去亲手处理那些脏乱差的数据集,去构建我们自己的特征工程流水线。
因为,再好的算法,如果没有高质量的数据喂养,也不过是空中楼阁。
陈涉川
2026年01月20日