目录
[1.1 基本概念](#1.1 基本概念)
[1.2 特点](#1.2 特点)
[1.3 适用场景](#1.3 适用场景)
[2.1 基本概念](#2.1 基本概念)
[2.2 词频统计原理WordCount](#2.2 词频统计原理WordCount)
[2.2 执行过程](#2.2 执行过程)
[2.3 运行模式](#2.3 运行模式)
1.MapReduce概述
1.1 基本概念
MapReduce设计初衷是来解决大规模网页数据的并行处理,MapReduce程序被分为Map阶段和Reduce阶段。Map阶段是把计算任务分发到各个节点运算,得到部分结果之后,由Reduce阶段进行最终结果的汇总,这也是MapReduce命名的一个由来。MapReduce的核心思想是分而治之,并行运算。 map把计算任务分发到各个节点运算,每个节点在运算的过程中是并行运算。另外,MapReduce属于移动计算,而非移动数据,即数据不动,把计算任务移动上去,计算跟着数据走。
1.2 特点
计算跟着数据走
良好的扩展性:计算能力随着节点数增加,近似线性递增
高容错
状态监控
适合海量数据的离线批处理
降低了分布式编程的门槛
1.3 适用场景
适用场景【离线批处理】
数据统计,如:网站的PV、UV统计
搜索引擎构建索引
海量数据查询
复杂数据分析算法实现
不适用场景【非离线批处理】
OLTP,要求毫秒或秒级返回结果
流计算,流计算的输入数据集是动态的,而MapReduce是静态的
DAG计算,多个作业存在依赖关系,后一个的输入是前一个的输出,构成有向无环图DAG,每个MapReduce作业的输出结果都会落盘,造成大量磁盘IO,导致性能非常低下
2.MapReduce原理
2.1 基本概念
-
Job:作业是客户端请求执行的一个工作单元,包括输入数据、MapReduce程序、配置信息
-
Task:任务是将作业分解后得到的细分工作单元,分为Map Task和Reduce Task
-
Split(切片):输入数据被划分成等长的小数据块,称为输入切片(Input Split),简称切片。Split是逻辑概念,仅包含元数据信息,如:数据的起始位置、长度、所在节点等。每个Split交给一个Map任务处理,Split的数量决定Map任务的数量。Split的划分方式由程序设定,Split与HDFS Block没有严格的对应关系,Split的大小默认等于Block大小,Split越小,负载越均衡,但集群的开销越大。
-
Map阶段(映射):由若干Map任务组成,任务数量由Split数量决定,输入为Split切片(key-value),输出中间计算结果(key-value)
-
Reduce阶段(化简):由若干Reduce任务组成,任务数量由程序指定,输入是Map阶段输出的中间结果(key-value),输出最终结果(key-value)
-
Shuffle阶段(洗牌):Map、Reduce阶段的中间环节,负责执行Partition(分区)、Sort(排序)、Spill(溢写)、Merge(合并)、抓取(Fetch)等工作。Partition决定了Map任务输出的每条数据放入哪个分区,交给哪个Reduce任务处理。Reduce任务的数量决定了Partition数量,Partition编号 = Reduce任务编号 ="key hashcode % reduce task number"(哈希取模),避免和减少Shuffle是MapReduce程序调优的重点。
2.2 词频统计原理WordCount
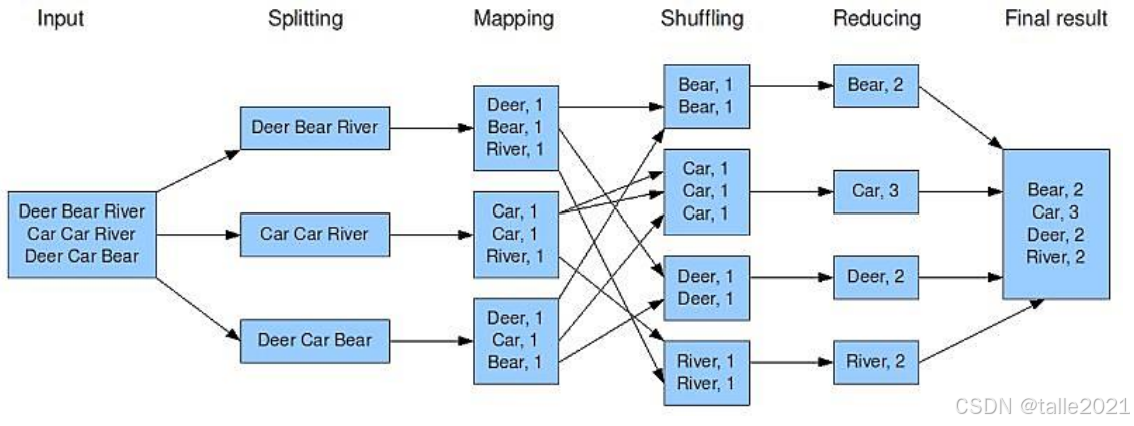
下面以词频统计的例子来了解MapReduce的运行原理,词频统计是统计一个英文文本里面单词出现的频率,比如下图的英文文本里有9个词,"Dear"出现了两次,"Car"出现了三次。
做词频统计时,拿到英文文本后,对这个英文文本进行split切分成多个数据块。如果这个英文文本是存到HDFS上,HDFS会自动完成split操作。如果没有存到HDFS上,MapReduce会调用split切分,切分也是默认按128M一块拆分成多个数据块, 拆分后每个数据块会起一个Maptask。下图的英文文本被拆分成三个数据块,所以启动了三个Maptask,Maptask在运行的过程中会把结果处理成key-value形式,一个key带一个value。在MapTask中,每一行文本按照空格进行拆分,把单词作为Key,Value值是单词出现的次数,这样map这一块就得到部分结果,得到部分结果后把Key相同的数据分发到同一个Reduce节点进行累加聚合,得到最终的词频统计结果,再做一个相应的输出。
那实际上最难的部分是中间阶段如何把相同的Key分发到同一个reduce节点,中间要经过shuffle阶段,也叫洗牌阶段。对于map这一块数据,由于Key是字符串,要先把它变成数字,再对这个数字进行哈希取模,比如现在有4个reduce,那数字Key就对4哈希取模,因为除以4取余数只能是0123,也就对应着4个Key,然后分发到不同的reduce节点,这样就保证相同的Key一定会聚合到同一个reduce节点。
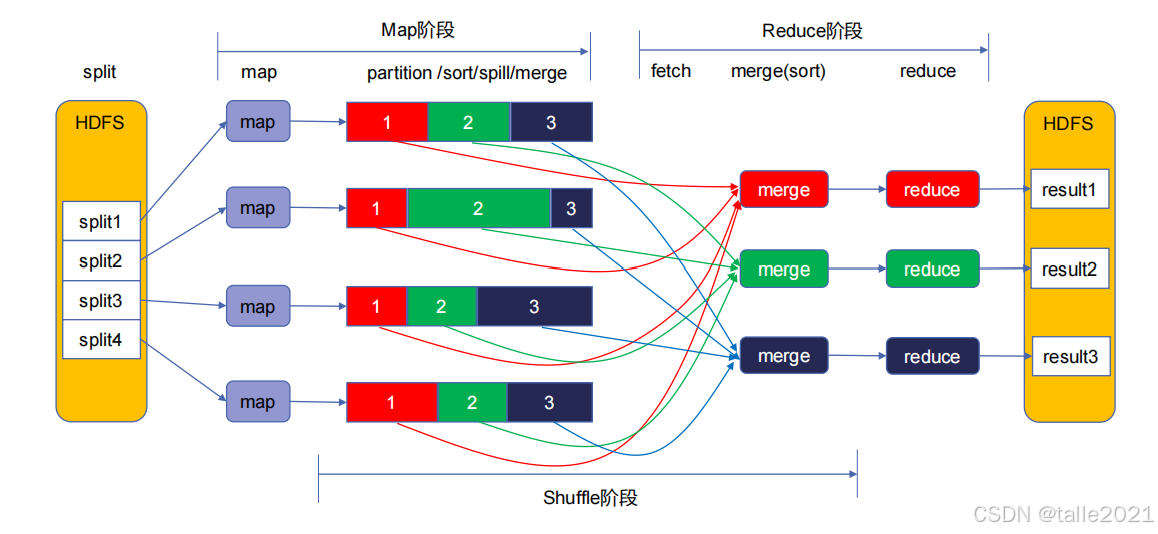
2.2 执行过程
首先文件上传到HDFS,HDFS把文件拆分成了多个block块,每一个block块会启动一个map任务,在MapTask运行的过程中会把结果处理成key-value形式,接着Map要把相同的Key聚合到同一个reduce节点,它要对Key哈希取模,下图有3个reduce就对3进行哈希取模,也就意味着得到的余数是012,每一个map都是这样,数据分完组后,reduce就开始启动fetch线程,从各个map上拉取对应的文件,红色的就拉取红的,绿色的就拉取绿色,因为是从多个map拉取回来,就要对这多个文件合并成一个大的文件。 合并后的大文件要做reduce处理,处理过程一般是对value值做相关的计算处理,比如词频统计是对value值做累加,计算完后输出最终结果,每个reduce都会输出一个结果文件,这些结果文件会存放在同一个数据目录下,目录下的所有的文件加起来就是最终的输出结果。
MapReduce按task是分是只有map task和reduce task,按阶段来分就是map阶段、shuffle阶段、reduce阶段。整个shuffle阶段是由map task和reduce task来共同完成的。在整个MapReduce执行过程中,最慢的是shuffle阶段,因此避免和减少Shuffle是MapReduce程序调优的重点。
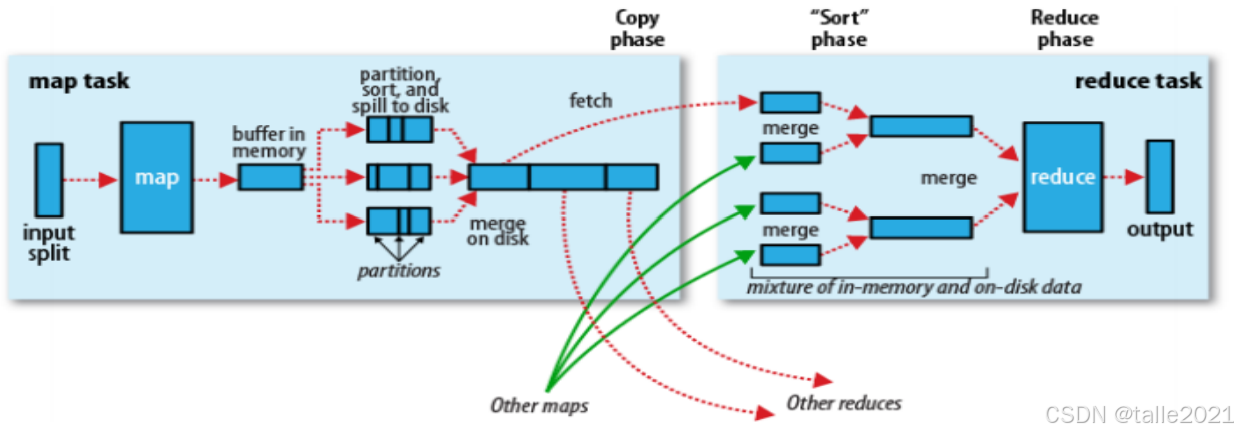
shuffle详解
Map端
Map任务在运算过程中得到的key-value结果会存放到一个内存缓存区Buffer(默认100M),同时进行Partition和Sort【先按"key hashcode % reduce task number"对数据进行分区,分区内再按key排序】,当内存缓存区Buffer的数据量达到阈值(默认80%)时,数据会溢写(Spill)到磁盘的一个临时文件中,在往磁盘里溢写的同时,会对这个文件先分组后排序,分组就是根据reduce的个数进行哈希取模,分成与reduce相同个数的组数,然后在每个组里面给这个数据排序。在处理过程中可能会有多次溢写,生成多个分组有序的小文件,Map任务结束前,会将磁盘里的多个小文件合并(Merge)为一个大的分组有序文件,每个map对应一个输出文件。
Reduce端
reduce启动fetch线程从各个map输出文件中拉取属于自己的分区数据,拉取后先全部写入Buffer,数据量达到阈值后,溢写到磁盘的一个临时文件中,在处理过程中可能会有多次溢写,生成多个的小文件,数据抓取完成后,将多个临时文件合并为一个Reduce输入文件,文件内数据按key分组排序。接着对这个分组有序的文件进行reduce处理, 处理的时候把Key相同的value值做计算处理,得到最终结果后做一个输出。
整个shuffle过程中大量的落盘,用到内存缓存并不大,也就几百兆的样子,非常省内存,但省内存带来的一个后果就是大量地与磁盘进行交互,文件大量的写磁盘。另外,这些大文件在移动到reduce节点要走网络,大量的数据在网络上传输,效率也很低,这也就是MapReduce慢的原因,一个是大量与磁盘交互,另一个是网络的传输过程。
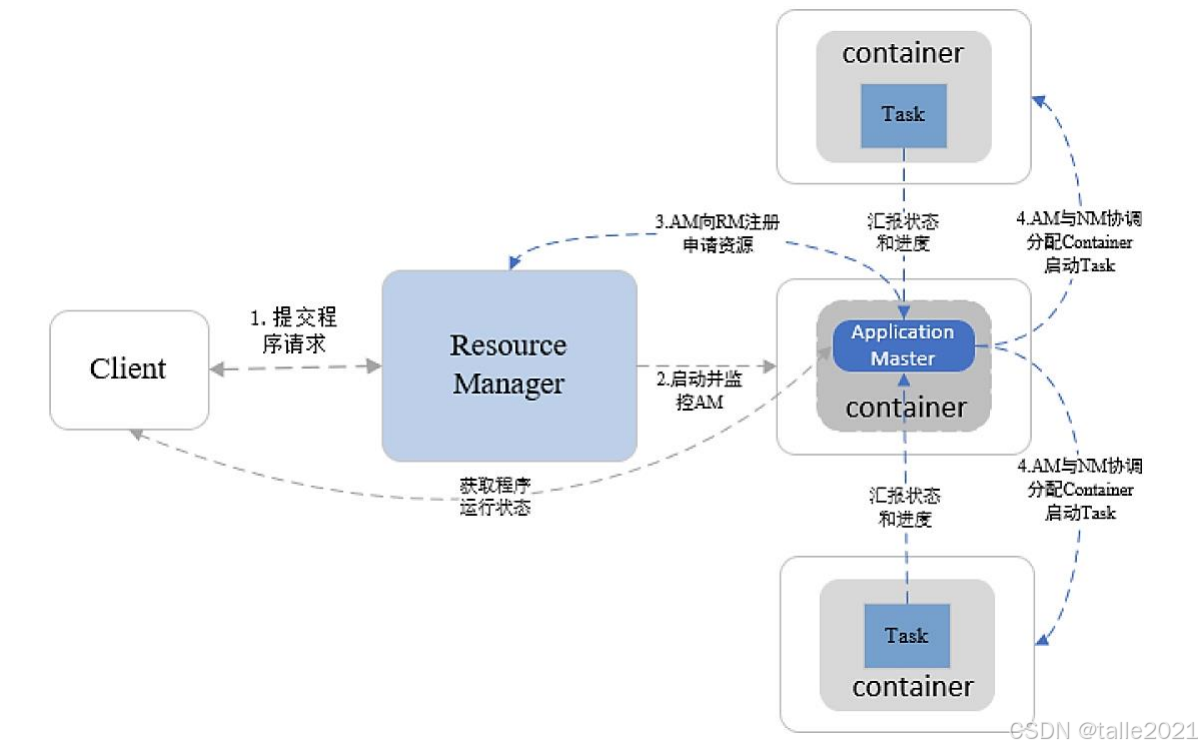
2.3 运行模式
整个MapReduce作业在运行的时候,作业通过客户端提交上来,首先Resource Manager会在所有的从节点里面分配一个container,第一个container运行作业自己的管理进程,也就是Application Master,运行起来之后,Application Master开始解析作业,比如把作业解析成两个task,这两个task可能一个是map task,一个是reduce task。解析出来后就向Resource Manager申请两个task的资源,Resource Manager就会在所有的从节点里分配出两个container资源, 申请出来后,Application Master就把两个task分发到这些container里运算。这些task在运算过程中会实时向Application Master汇报,当application master发现所有的作业运行完,就向Resource Manager申请资源释放。这就是MapReduce在Hadoop 2.X的一个运行模式。