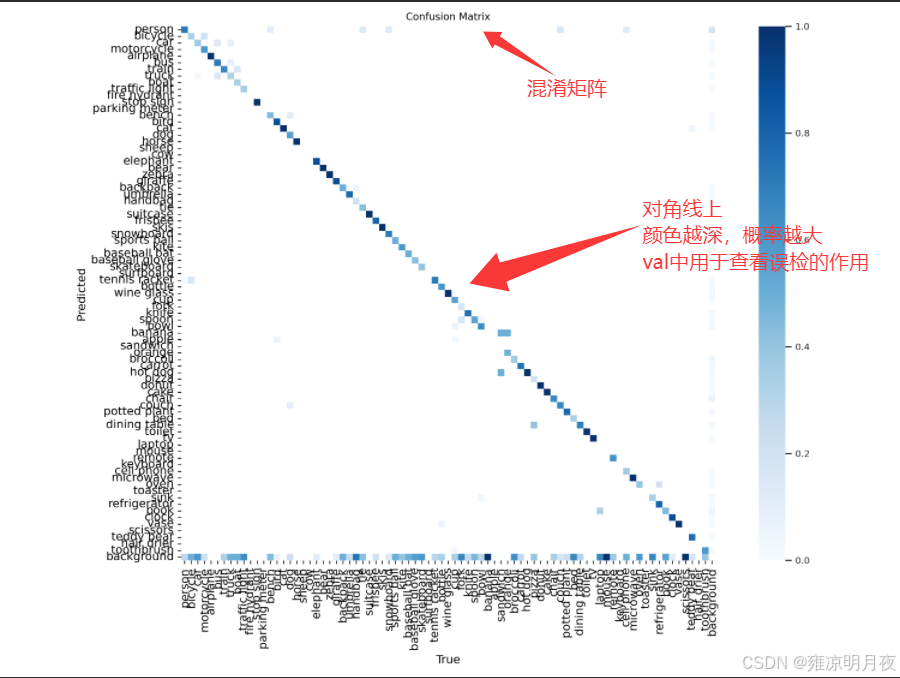
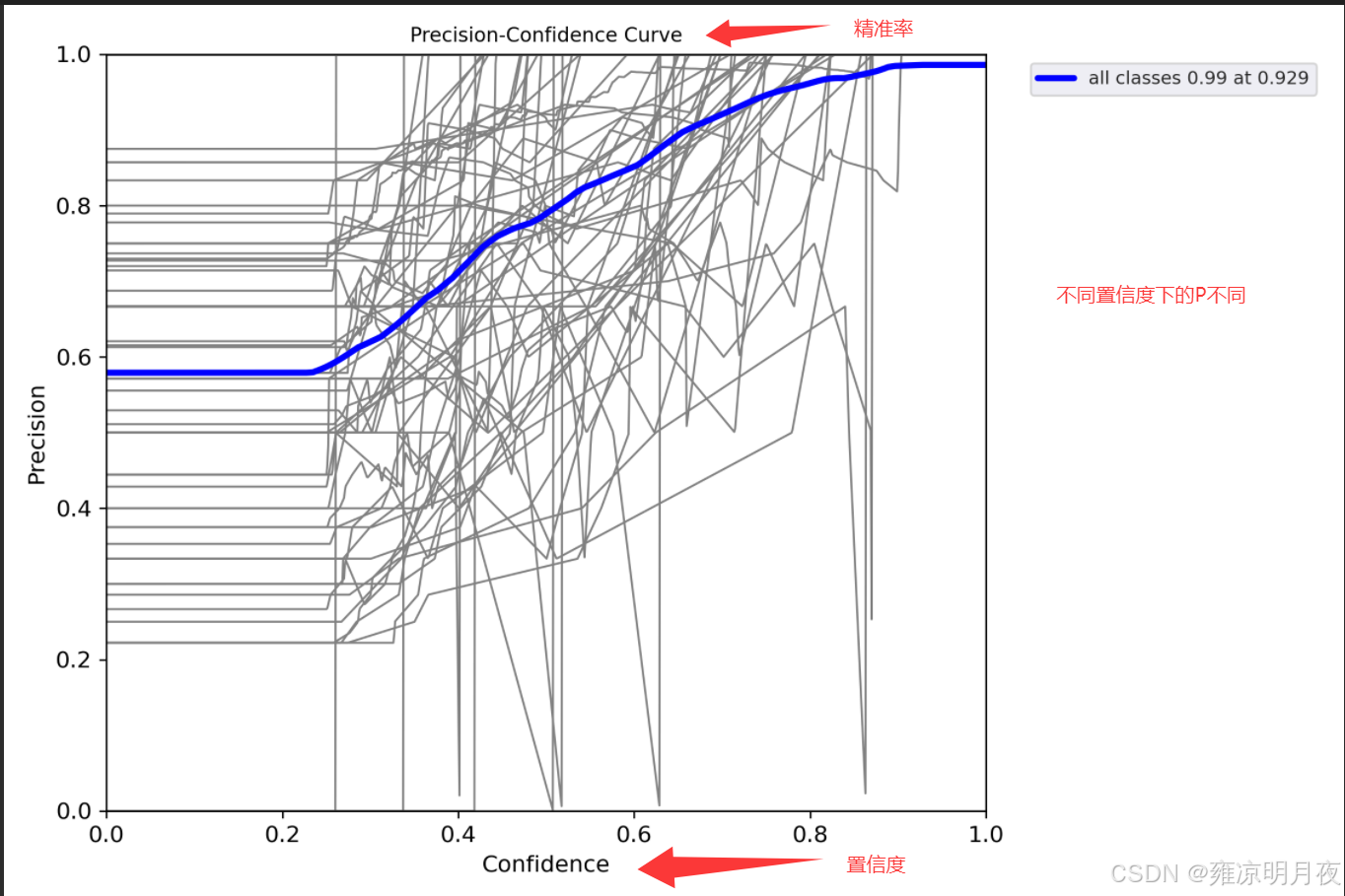
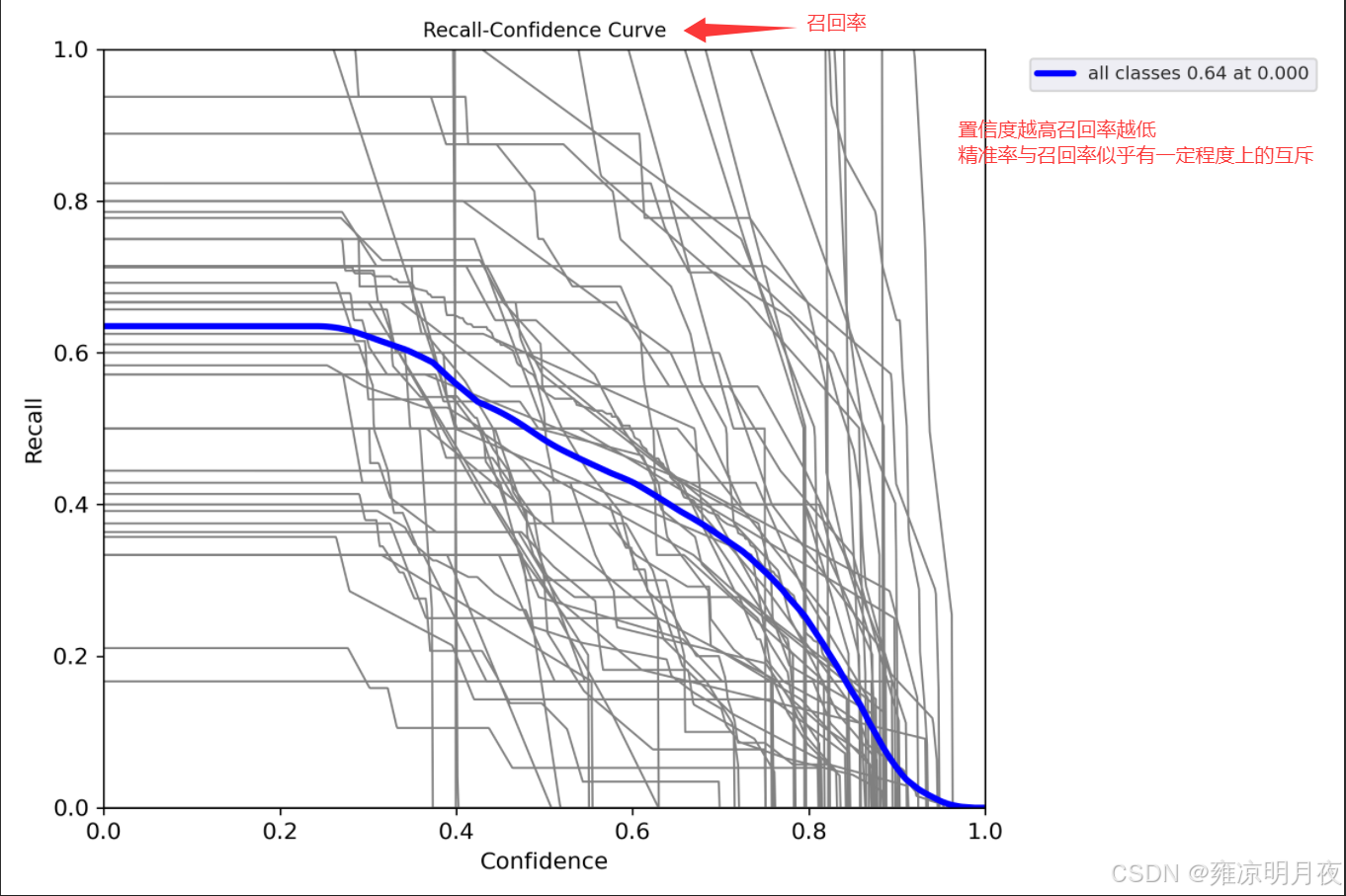
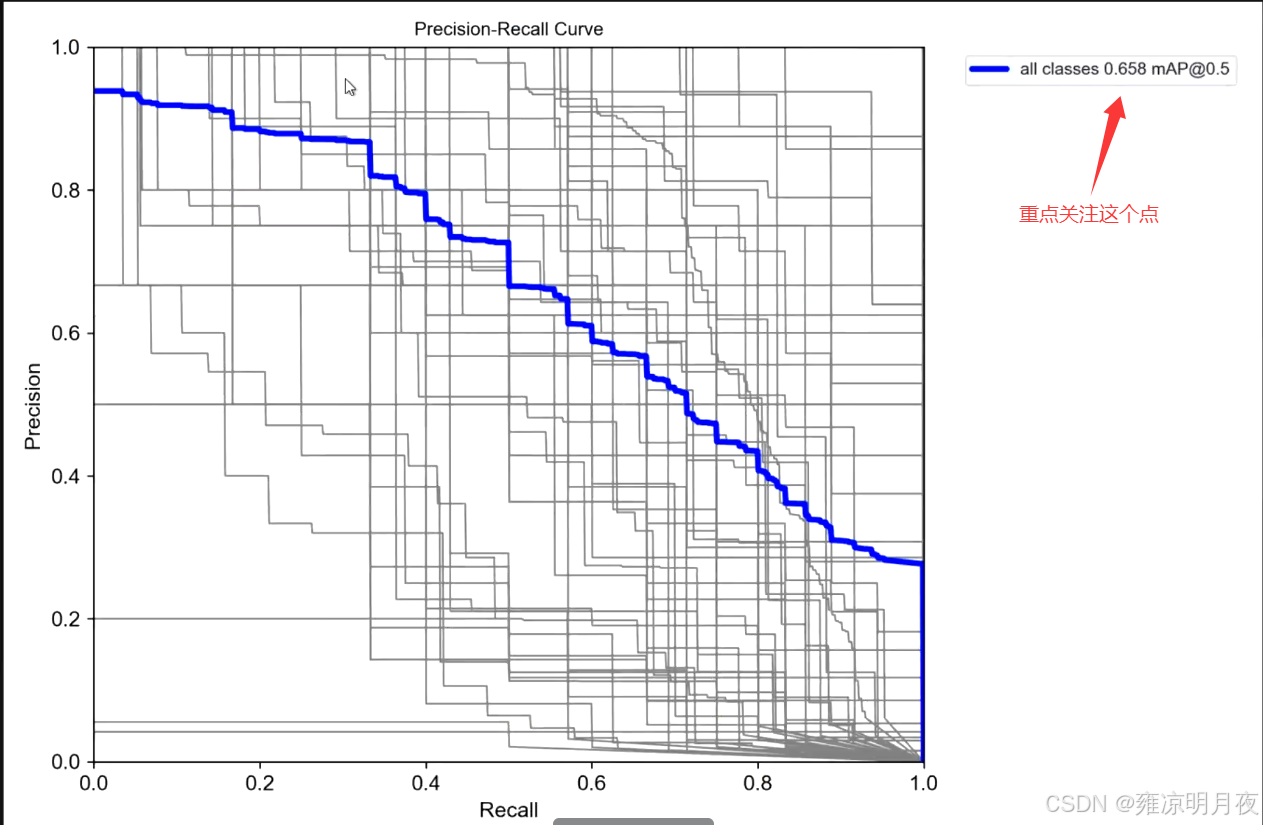
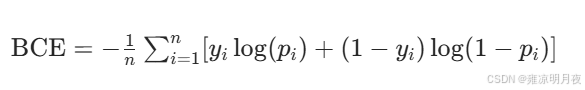def parse_opt(known=False):
"""Parse command-line arguments for YOLOv5 training, validation, and testing.
Args:
known (bool, optional): If True, parses known arguments, ignoring the unknown. Defaults to False.
Returns:
(argparse.Namespace): Parsed command-line arguments containing options for YOLOv5 execution.
Examples:
```python
from ultralytics.yolo import parse_opt
opt = parse_opt()
print(opt)
```
Links:
- Models: https://github.com/ultralytics/yolov5/tree/master/models
- Datasets: https://github.com/ultralytics/yolov5/tree/master/data
- Tutorial: https://docs.ultralytics.com/yolov5/tutorials/train_custom_data
"""
parser = argparse.ArgumentParser()
"""
argparse:专门管理参数的库
default = 填充具体值
root 是根目录
"""
#初始预训练权重
parser.add_argument("--weights", type=str, default=ROOT / "yolov5s.pt", help="initial weights path")
#添加模型配置文件
model_path = r"/root/wjj/yolov5/models/yolov5s.yaml"
"""
模型配置文件,此处的default是要修改为自己配置的文件
#/root/wjj/yolov5/models/yolov5s.yaml
weight 和 cfg规则
1.当weights不为空时,cfg为空则加载weights中的模型文件
2.当weights为空时,cfg不为空,但此时不预训练权重
3.当weights与cfg模型的结构一样时,就是给cfg赋初值weights
4.当weights与cfg不一样时,取交集权重。
***能够继承大模型的初始权重***
***什么时候用初始权重,什么时候不用初始权重***
生活场景使用
工业场景:可以尝试先用,也可以不用
⭐训练技巧:先训练中度模型M权重例20层,将M权重作为weights初始加进cfg中
此时cfg是小的权重,因为取交集的原因会权重迁移。从大模型中学习小模型。
"""
parser.add_argument("--cfg", type=str, default=model_path, help="model.yaml path")
#⭐配置训练数据源
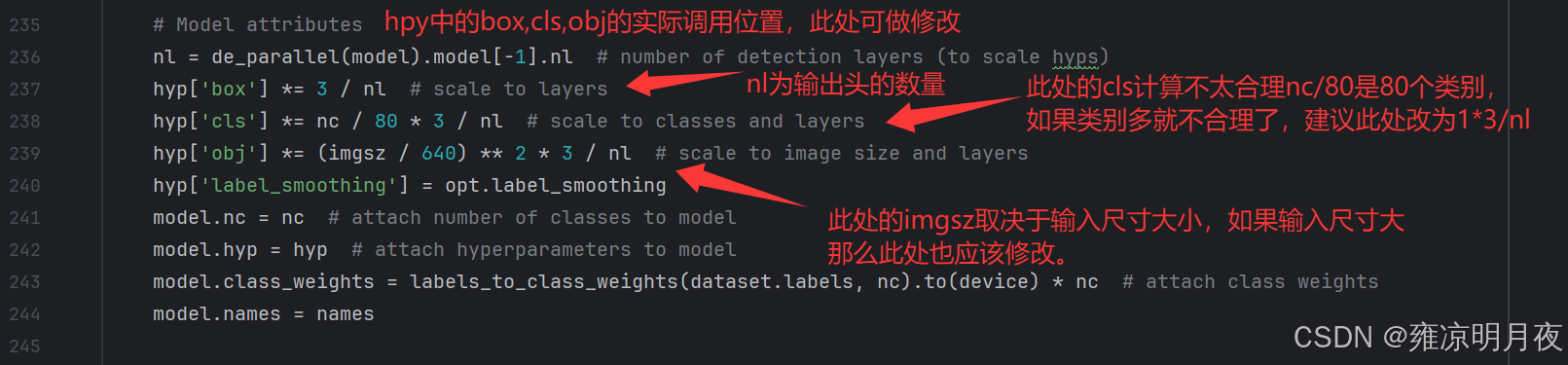
parser.add_argument("--data", type=str, default=ROOT / "data/coco128.yaml", help="dataset.yaml path")
#⭐训练集参数文件地址,之前学习的超参数都在这里
parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/hyp.scratch-low.yaml", help="hyperparameters path")
#⭐训练epochs次数epochs = 100,300
parser.add_argument("--epochs", type=int, default=1, help="total training epochs")
#⭐batch 8 ,16,32,64
parser.add_argument("--batch-size", type=int, default=1, help="total batch size for all GPUs, -1 for autobatch")
#⭐训练的输入尺寸640,输出头20,40,80。取决于图大小一般最大也是1280
parser.add_argument("--imgsz", "--img", "--img-size", type=int, default=640, help="train, val image size (pixels)")
#矩形训练,不常用
parser.add_argument("--rect", action="store_true", help="rectangular training")
'''
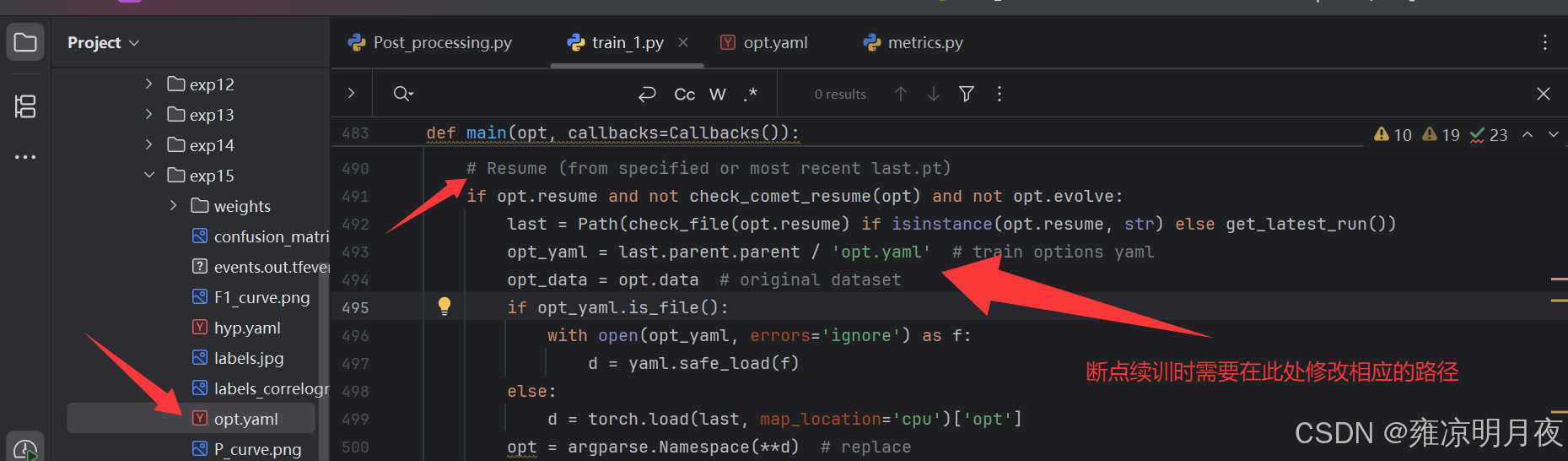
⭐是否在 上一轮的基础上继续训练
1.如果训练到一般停止了想要接着训练则需要将默认参数修改且将上述的weights权重也修改,默认路径修改为为暂停时的权重路径
default=True
path_new = r"/root/wjj/yolov5/runs/train/exp3/weights/last.pt"
parser.add_argument("--weights", type=str, default=path_new, help="initial weights path")
2.如果开启了resume,此时我们修改.py中的参数是无效的,则需要取上述运行到一般的exp3文件修改参数值
修改该文件下面两个其中一个,可以试试
/root/wjj/yolov5/runs/train/exp3/opt.yaml
/root/wjj/yolov5/runs/train/exp3/hyp.yaml
'''
parser.add_argument("--resume", nargs="?", const=True, default=False, help="resume most recent training")
parser.add_argument("--nosave", action="store_true", help="only save final checkpoint")
# 训练后有验证则关闭验证
parser.add_argument("--noval", action="store_true", help="only validate final epoch")
#不进行自动聚类anchor
parser.add_argument("--noautoanchor", action="store_true", help="disable AutoAnchor")
parser.add_argument("--noplots", action="store_true", help="save no plot files")
parser.add_argument("--evolve", type=int, nargs="?", const=300, help="evolve hyperparameters for x generations")
parser.add_argument(
"--evolve_population", type=str, default=ROOT / "data/hyps", help="location for loading population"
)
parser.add_argument("--resume_evolve", type=str, default=None, help="resume evolve from last generation")
parser.add_argument("--bucket", type=str, default="", help="gsutil bucket")
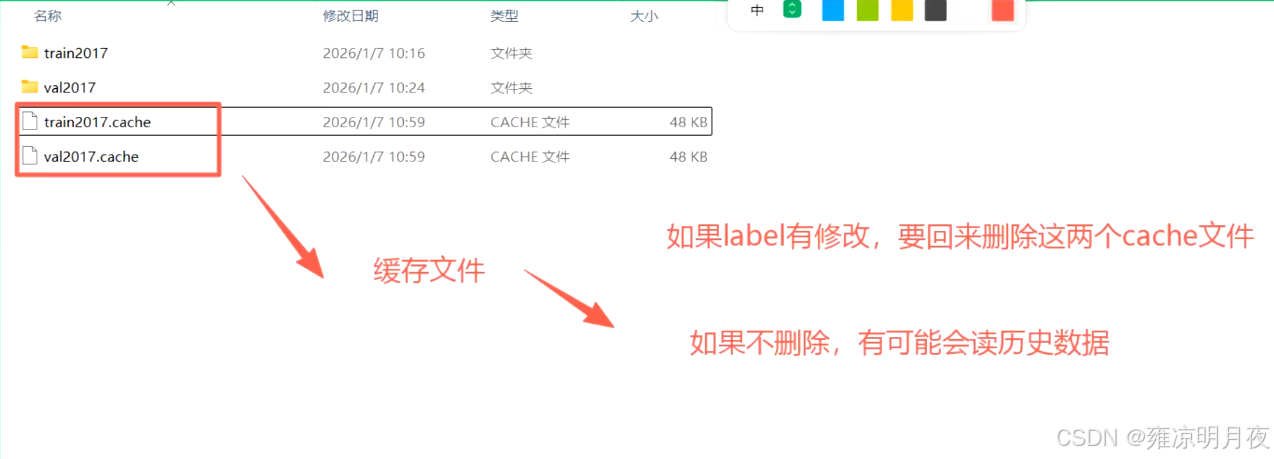
parser.add_argument("--cache", type=str, nargs="?", const="ram", help="image --cache ram/disk")
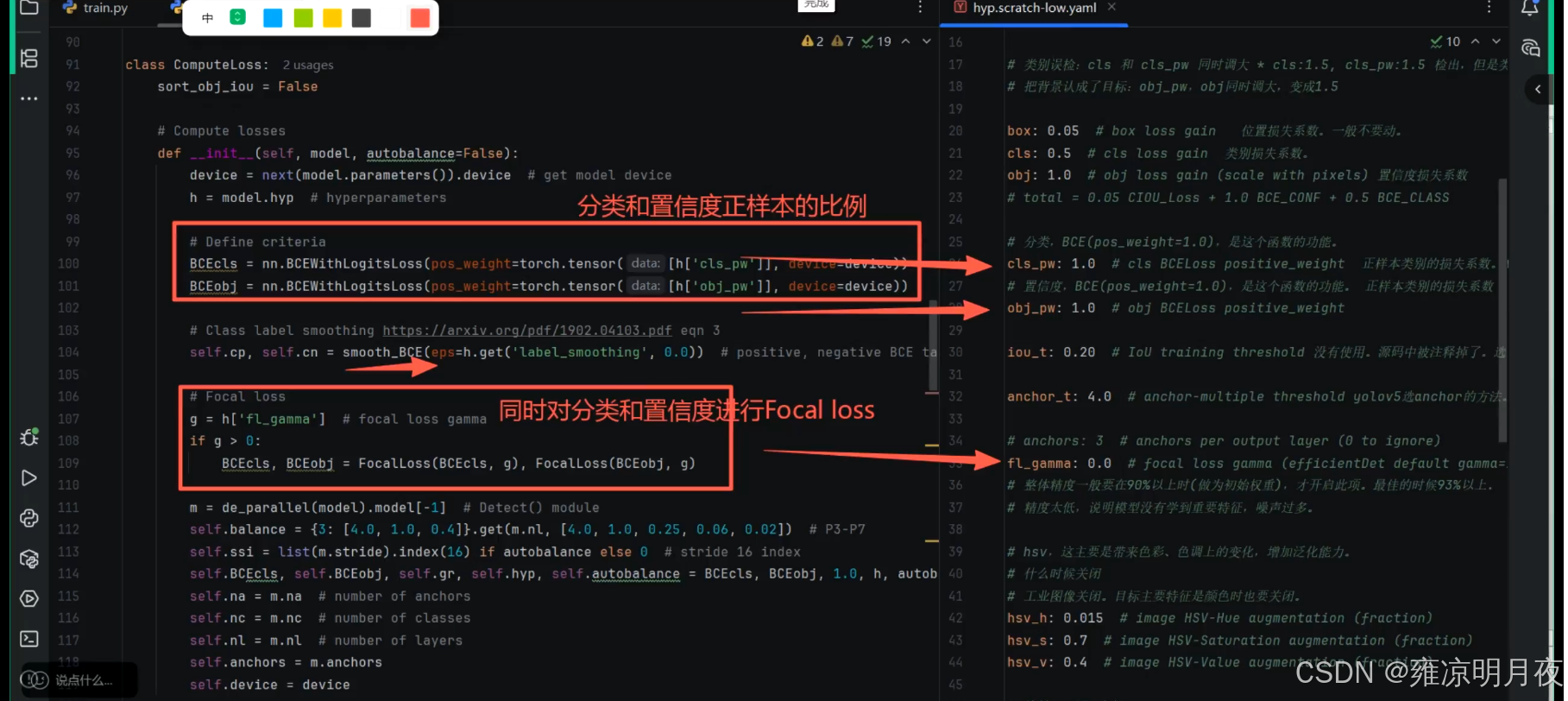
"""
⭐自动对于类别不平衡时,BCE有自动平衡,自动平衡系数,小样本更聚焦
1.针对数据少的给予更大的权重loss
一般都是true
"""
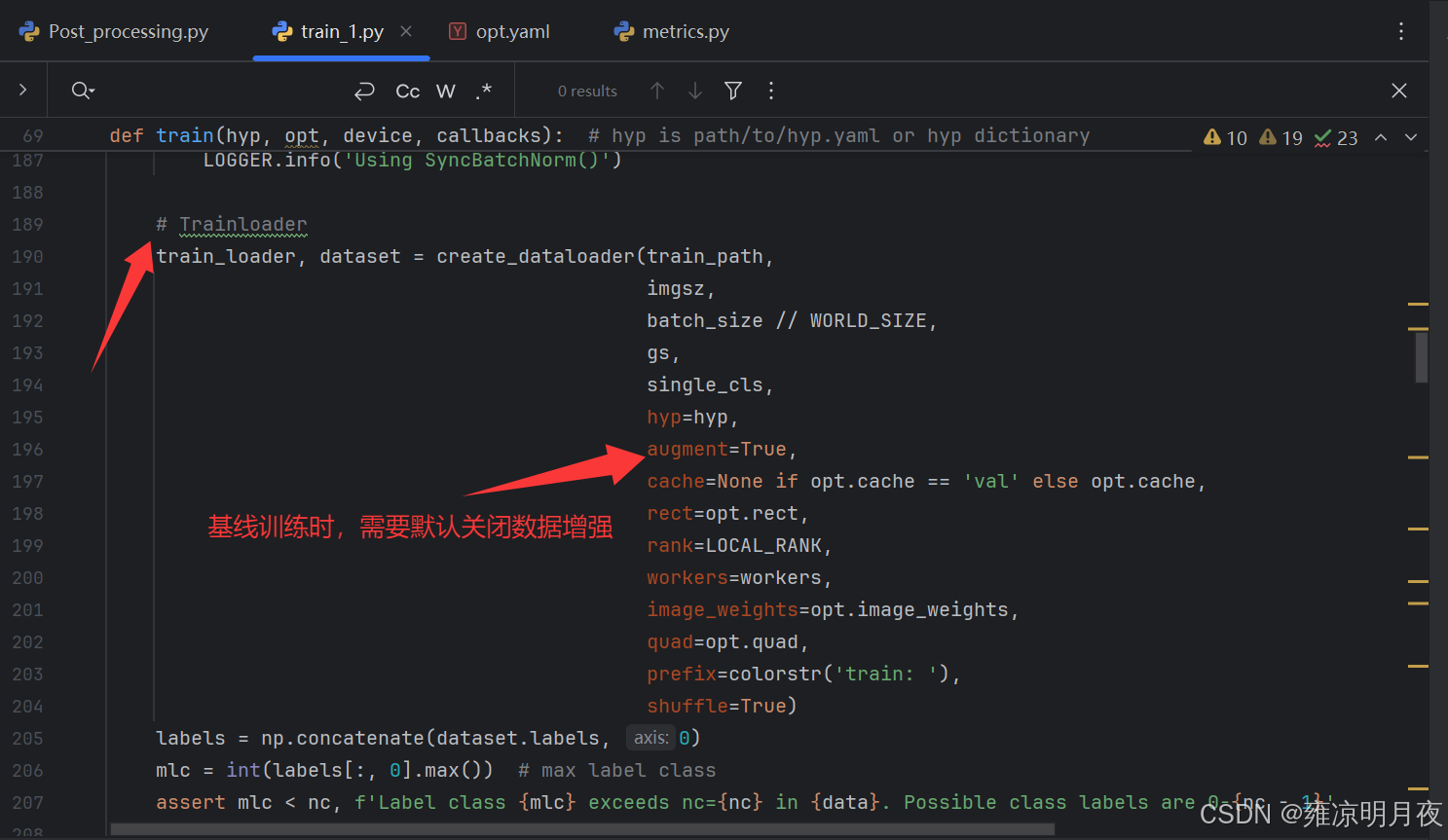
parser.add_argument("--image-weights", action="store_true", help="use weighted image selection for training")
#代表多块显卡0,1,2代表三块显卡
parser.add_argument("--device", default="", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")
"""
⭐是否开启多尺度训练
640标准
最小320,最大960
0.5 ,1 ,1.5
"""
parser.add_argument("--multi-scale", action="store_true", help="vary img-size +/- 50%%")
#单类训练
parser.add_argument("--single-cls", action="store_true", help="train multi-class data as single-class")
#优化器选择
parser.add_argument("--optimizer", type=str, choices=["SGD", "Adam", "AdamW"], default="SGD", help="optimizer")
#多卡训练才开启
parser.add_argument("--sync-bn", action="store_true", help="use SyncBatchNorm, only available in DDP mode")
"""
⭐多进程读数据,需要开启4-8之间
"""
parser.add_argument("--workers", type=int, default=8, help="max dataloader workers (per RANK in DDP mode)")
parser.add_argument("--project", default=ROOT / "runs/train", help="save to project/name")
parser.add_argument("--name", default="exp", help="save to project/name")
parser.add_argument("--exist-ok", action="store_true", help="existing project/name ok, do not increment")
parser.add_argument("--quad", action="store_true", help="quad dataloader")
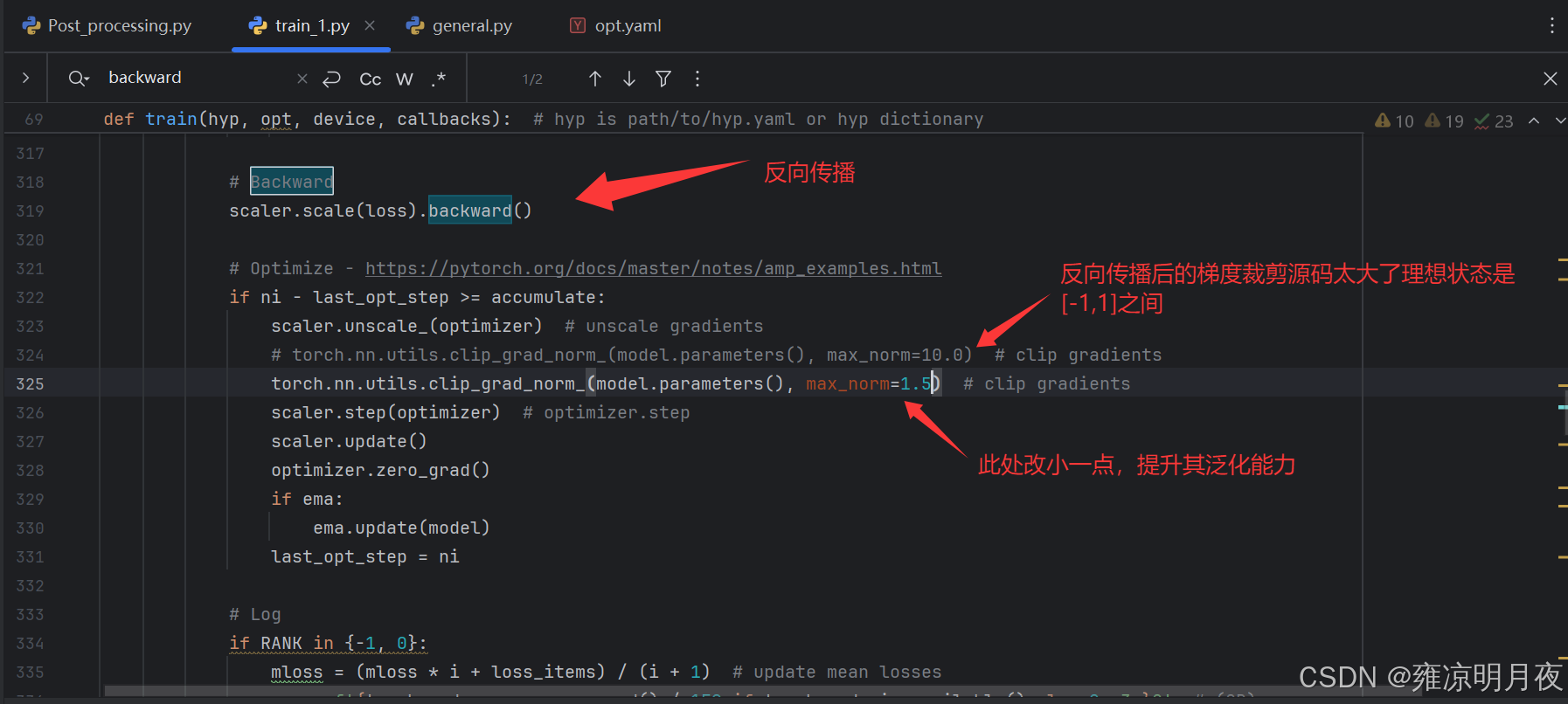
#是都开启余弦退火
parser.add_argument("--cos-lr", action="store_true", help="cosine LR scheduler")
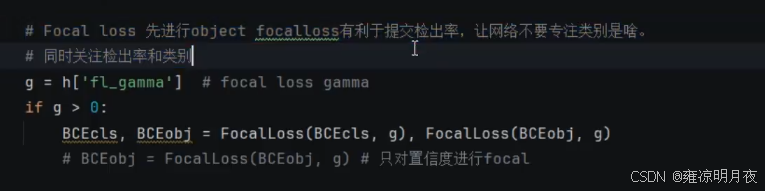
#标签平滑,防止过拟合,降低gt的标准(给标签一个怀疑尺度)
parser.add_argument("--label-smoothing", type=float, default=0.0, help="Label smoothing epsilon")
"""
⭐早停轮次,val毫无进展就早停,可修改参数
"""
parser.add_argument("--patience", type=int, default=100, help="EarlyStopping patience (epochs without improvement)")
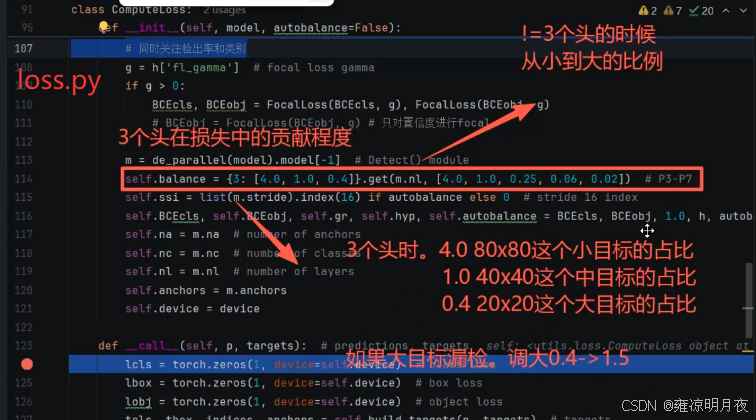
"""
⭐冻结训练:
0代表不冻结,10代表冻结前10层
1,3,5代表冻结下标为1,3,5层
两个作用:
1.有针对性的训练
2.微调,best.pt已经97%,再来10张漏检,整个模型训练有风险,这是就可以针对此数据集进行微调
"""
parser.add_argument("--freeze", nargs="+", type=int, default=[0], help="Freeze layers: backbone=10, first3=0 1 2")
parser.add_argument("--save-period", type=int, default=-1, help="Save checkpoint every x epochs (disabled if < 1)")
parser.add_argument("--seed", type=int, default=0, help="Global training seed")
parser.add_argument("--local_rank", type=int, default=-1, help="Automatic DDP Multi-GPU argument, do not modify")
# Logger arguments
parser.add_argument("--entity", default=None, help="Entity")
parser.add_argument("--upload_dataset", nargs="?", const=True, default=False, help='Upload data, "val" option')
parser.add_argument("--bbox_interval", type=int, default=-1, help="Set bounding-box image logging interval")
parser.add_argument("--artifact_alias", type=str, default="latest", help="Version of dataset artifact to use")
# NDJSON logging
parser.add_argument("--ndjson-console", action="store_true", help="Log ndjson to console")
parser.add_argument("--ndjson-file", action="store_true", help="Log ndjson to file")
return parser.parse_known_args()[0] if known else parser.parse_args()
detect.py训练集的参数注解
python复制代码
def parse_opt():
"""Parse command-line arguments for YOLOv5 detection, allowing custom inference options and model configurations.
Args:
--weights (str | list[str], optional): Model path or Triton URL. Defaults to ROOT / 'yolov5s.pt'.
--source (str, optional): File/dir/URL/glob/screen/0(webcam). Defaults to ROOT / 'data/images'.
--data (str, optional): Dataset YAML path. Provides dataset configuration information.
--imgsz (list[int], optional): Inference size (height, width). Defaults to [640].
--conf-thres (float, optional): Confidence threshold. Defaults to 0.25.
--iou-thres (float, optional): NMS IoU threshold. Defaults to 0.45.
--max-det (int, optional): Maximum number of detections per image. Defaults to 1000.
--device (str, optional): CUDA device, i.e., '0' or '0,1,2,3' or 'cpu'. Defaults to "".
--view-img (bool, optional): Flag to display results. Defaults to False.
--save-txt (bool, optional): Flag to save results to *.txt files. Defaults to False.
--save-csv (bool, optional): Flag to save results in CSV format. Defaults to False.
--save-conf (bool, optional): Flag to save confidences in labels saved via --save-txt. Defaults to False.
--save-crop (bool, optional): Flag to save cropped prediction boxes. Defaults to False.
--nosave (bool, optional): Flag to prevent saving images/videos. Defaults to False.
--classes (list[int], optional): List of classes to filter results by, e.g., '--classes 0 2 3'. Defaults to
None.
--agnostic-nms (bool, optional): Flag for class-agnostic NMS. Defaults to False.
--augment (bool, optional): Flag for augmented inference. Defaults to False.
--visualize (bool, optional): Flag for visualizing features. Defaults to False.
--update (bool, optional): Flag to update all models in the model directory. Defaults to False.
--project (str, optional): Directory to save results. Defaults to ROOT / 'runs/detect'.
--name (str, optional): Sub-directory name for saving results within --project. Defaults to 'exp'.
--exist-ok (bool, optional): Flag to allow overwriting if the project/name already exists. Defaults to False.
--line-thickness (int, optional): Thickness (in pixels) of bounding boxes. Defaults to 3.
--hide-labels (bool, optional): Flag to hide labels in the output. Defaults to False.
--hide-conf (bool, optional): Flag to hide confidences in the output. Defaults to False.
--half (bool, optional): Flag to use FP16 half-precision inference. Defaults to False.
--dnn (bool, optional): Flag to use OpenCV DNN for ONNX inference. Defaults to False.
--vid-stride (int, optional): Video frame-rate stride, determining the number of frames to skip in between
consecutive frames. Defaults to 1.
Returns:
argparse.Namespace: Parsed command-line arguments as an argparse.Namespace object.
Examples:
```python
from ultralytics import YOLOv5
args = YOLOv5.parse_opt()
```
"""
parser = argparse.ArgumentParser()
#自己加的
path_best_pt = r"/root/wjj/yolov5/runs/train/exp3/weights/best.pt"
"""
⭐detect.py中将自己加的训练权重赋值上去即可
parser.add_argument("--weights", nargs="+", type=str, default = path_best_pt, help="model path or triton URL")
"""
parser.add_argument("--weights", nargs="+", type=str, default=ROOT / "yolov5s.pt", help="model path or triton URL")
"""
⭐图片/视频流都可以,作为资源检测
"""
parser.add_argument("--source", type=str, default=ROOT / "data/images", help="file/dir/URL/glob/screen/0(webcam)")
parser.add_argument("--data", type=str, default=ROOT / "data/coco128.yaml", help="(optional) dataset.yaml path")
"""
⭐推理尺寸:可以不等于训练尺寸
"""
parser.add_argument("--imgsz", "--img", "--img-size", nargs="+", type=int, default=[640], help="inference size h,w")
#置信度
parser.add_argument("--conf-thres", type=float, default=0.25, help="confidence threshold")
#nms去重置信度
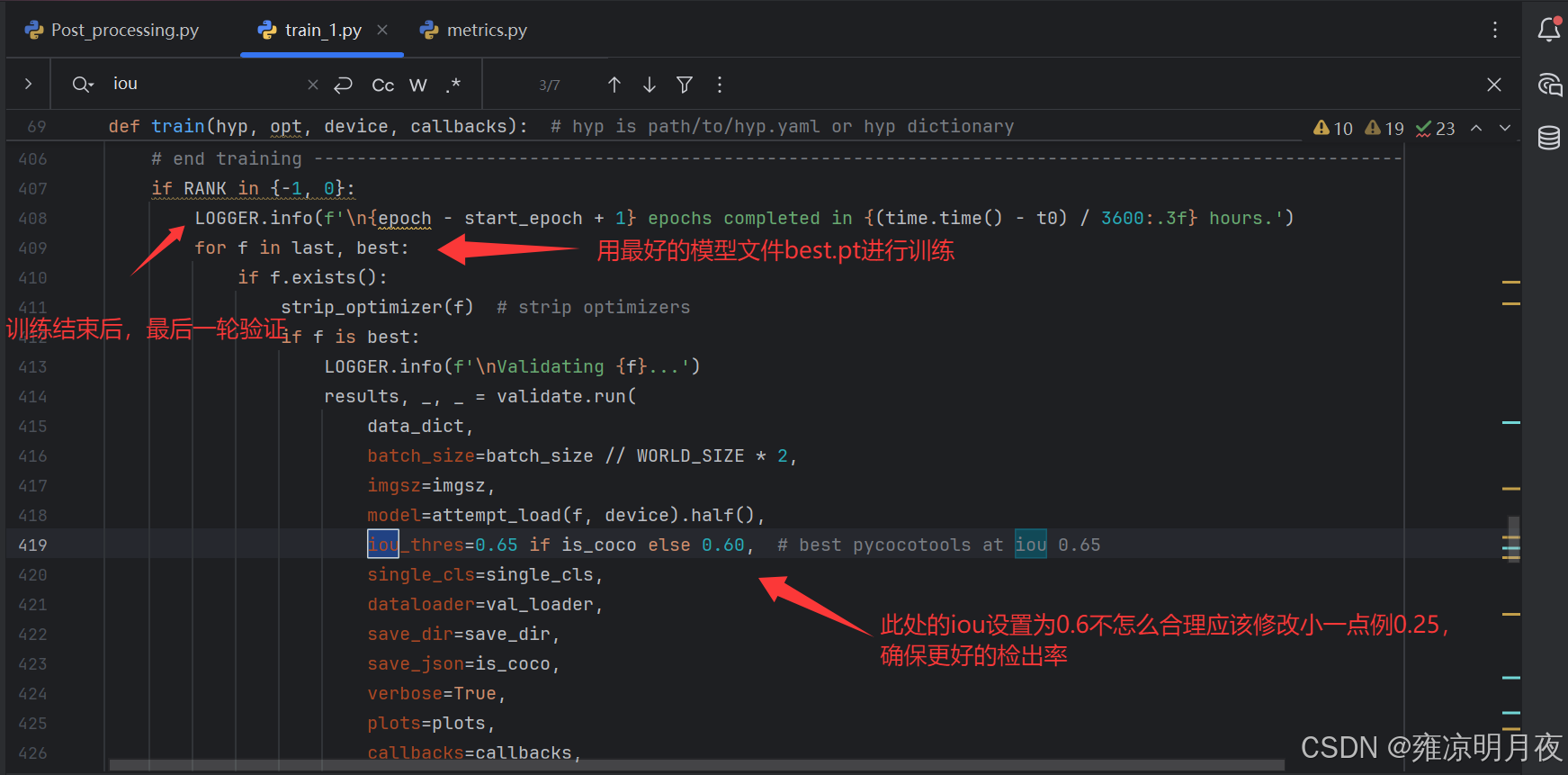
parser.add_argument("--iou-thres", type=float, default=0.45, help="NMS IoU threshold")
#最多一张图有1000个目标
parser.add_argument("--max-det", type=int, default=1000, help="maximum detections per image")
#设备
parser.add_argument("--device", default="", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")
parser.add_argument("--view-img", action="store_true", help="show results")
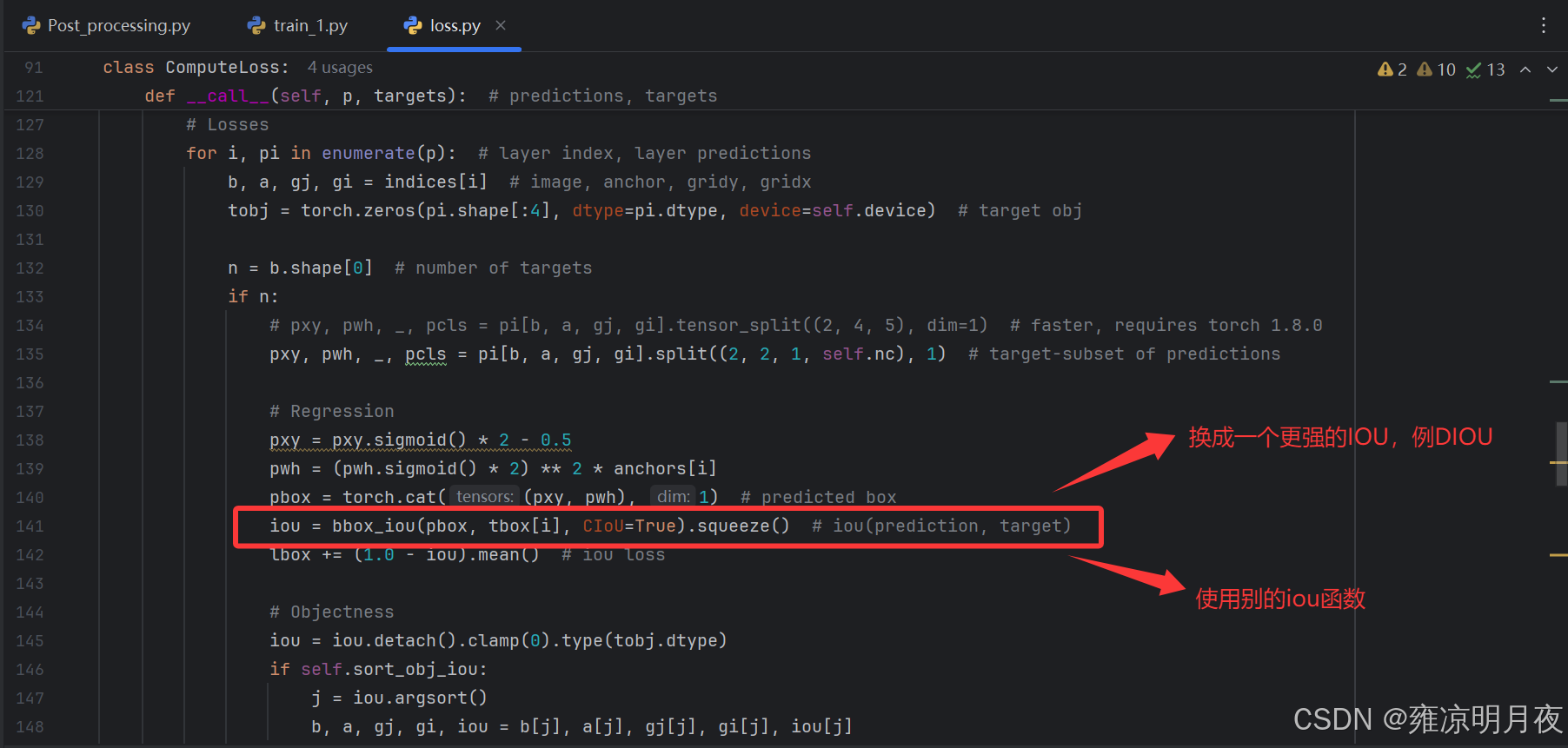
"""
⭐⭐⭐及其重要
能否将预测结果保存为yolo格式标签标签
1000张训练得到ai模型
将后面的2000张做预测,得到其他2000张的标签
用labeling,重新打开预测的标签查看是否正确
1.必须手动设置classes.txt
parser.add_argument("--save-txt", action="store_true",default = True, help="save results to *.txt")
"""
parser.add_argument("--save-txt", action="store_true", help="save results to *.txt")
parser.add_argument(
"--save-format",
type=int,
default=0,
help="whether to save boxes coordinates in YOLO format or Pascal-VOC format when save-txt is True, 0 for YOLO and 1 for Pascal-VOC",
)
parser.add_argument("--save-csv", action="store_true", help="save results in CSV format")
#是否将预测框box截图截下来
parser.add_argument("--save-conf", action="store_true", help="save confidences in --save-txt labels")
parser.add_argument("--save-crop", action="store_true", help="save cropped prediction boxes")
parser.add_argument("--nosave", action="store_true", help="do not save images/videos")
parser.add_argument("--classes", nargs="+", type=int, help="filter by class: --classes 0, or --classes 0 2 3")
parser.add_argument("--agnostic-nms", action="store_true", help="class-agnostic NMS")
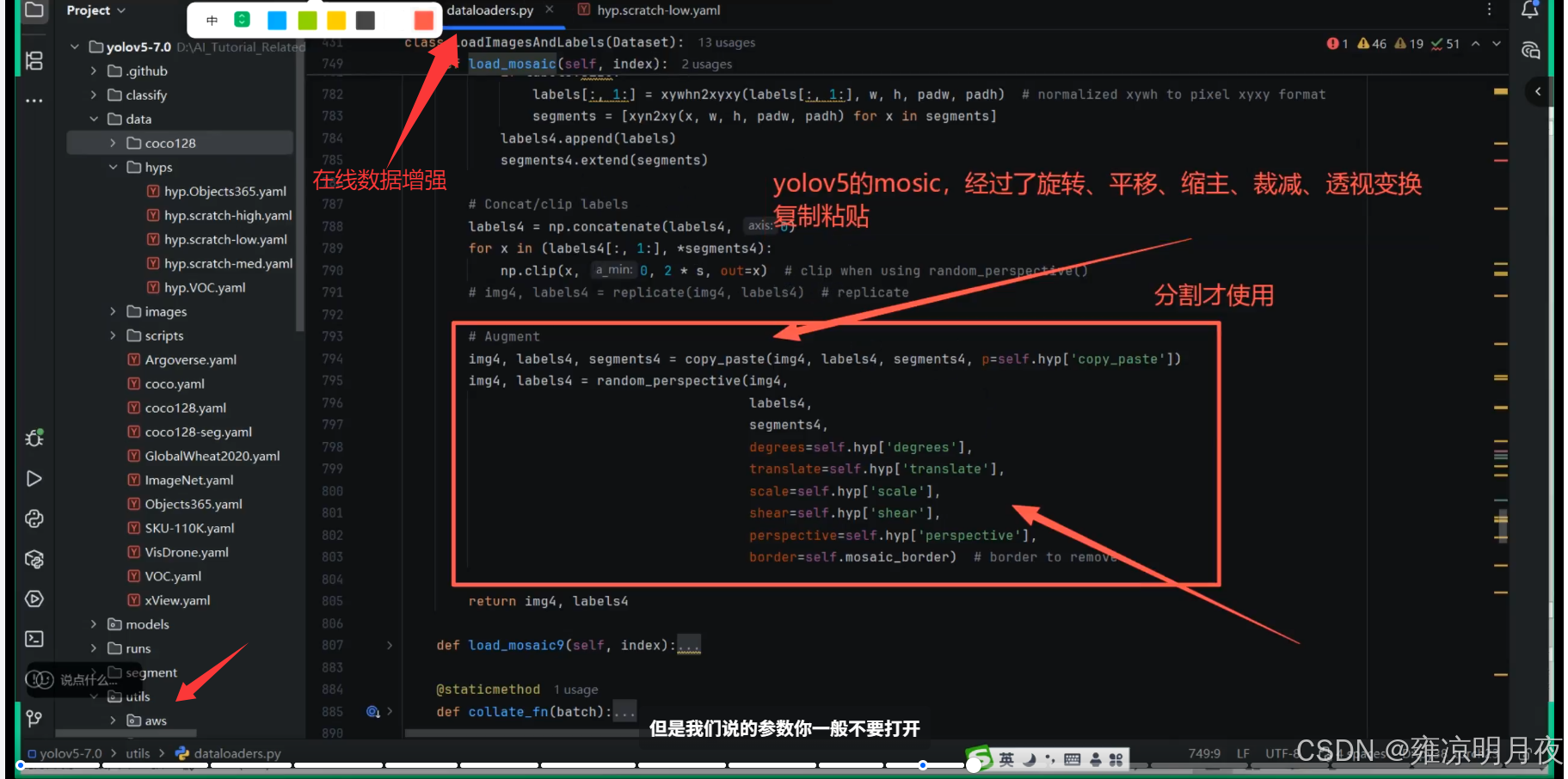
parser.add_argument("--augment", action="store_true", help="augmented inference")
"""
⭐⭐⭐及其重要
将网络层中的特征,每层随机选32个通道保存可视化,cam热力图
parser.add_argument("--visualize", action="store_true",default = True,help="visualize features")
"""
parser.add_argument("--visualize", action="store_true", help="visualize features")
parser.add_argument("--update", action="store_true", help="update all models")
parser.add_argument("--project", default=ROOT / "runs/detect", help="save results to project/name")
parser.add_argument("--name", default="exp", help="save results to project/name")
parser.add_argument("--exist-ok", action="store_true", help="existing project/name ok, do not increment")
parser.add_argument("--line-thickness", default=3, type=int, help="bounding box thickness (pixels)")
parser.add_argument("--hide-labels", default=False, action="store_true", help="hide labels")
parser.add_argument("--hide-conf", default=False, action="store_true", help="hide confidences")
parser.add_argument("--half", action="store_true", help="use FP16 half-precision inference")
parser.add_argument("--dnn", action="store_true", help="use OpenCV DNN for ONNX inference")
parser.add_argument("--vid-stride", type=int, default=1, help="video frame-rate stride")
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(vars(opt))
return opt
val.py训练集的参数注解
python复制代码
def parse_opt():
"""Parse command-line options for configuring YOLOv5 model inference.
Args:
data (str, optional): Path to the dataset YAML file. Default is 'data/coco128.yaml'.
weights (list[str], optional): List of paths to model weight files. Default is 'yolov5s.pt'.
batch_size (int, optional): Batch size for inference. Default is 32.
imgsz (int, optional): Inference image size in pixels. Default is 640.
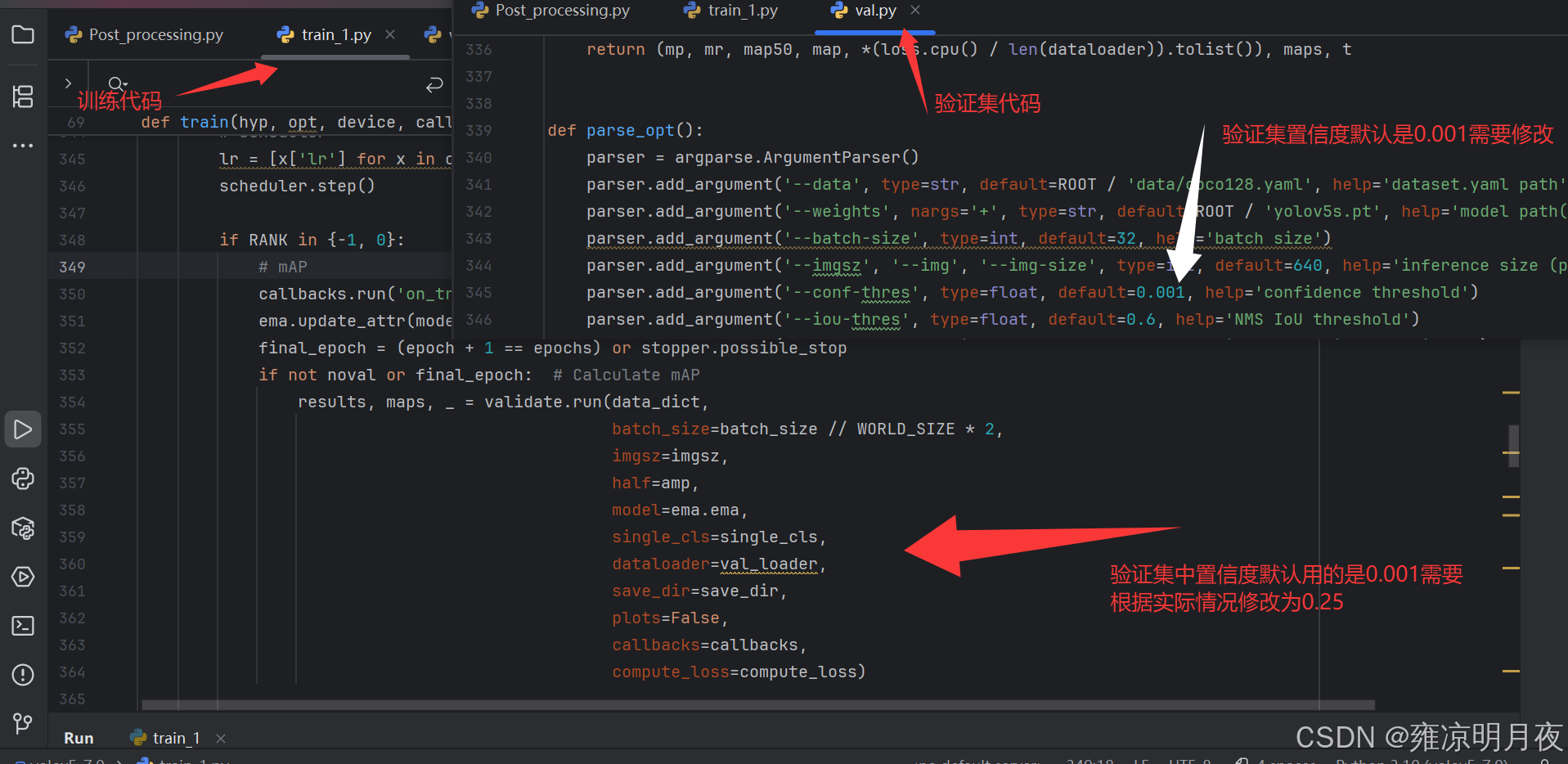
conf_thres (float, optional): Confidence threshold for predictions. Default is 0.001.
iou_thres (float, optional): IoU threshold for Non-Max Suppression (NMS). Default is 0.6.
max_det (int, optional): Maximum number of detections per image. Default is 300.
task (str, optional): Task type - options are 'train', 'val', 'test', 'speed', or 'study'. Default is 'val'.
device (str, optional): Device to run the model on. e.g., '0' or '0,1,2,3' or 'cpu'. Default is empty to let the
system choose automatically.
workers (int, optional): Maximum number of dataloader workers per rank in DDP mode. Default is 8.
single_cls (bool, optional): If set, treats the dataset as a single-class dataset. Default is False.
augment (bool, optional): If set, performs augmented inference. Default is False.
verbose (bool, optional): If set, reports mAP by class. Default is False.
save_txt (bool, optional): If set, saves results to *.txt files. Default is False.
save_hybrid (bool, optional): If set, saves label+prediction hybrid results to *.txt files. Default is False.
save_conf (bool, optional): If set, saves confidences in --save-txt labels. Default is False.
save_json (bool, optional): If set, saves results to a COCO-JSON file. Default is False.
project (str, optional): Project directory to save results to. Default is 'runs/val'.
name (str, optional): Name of the directory to save results to. Default is 'exp'.
exist_ok (bool, optional): If set, existing directory will not be incremented. Default is False.
half (bool, optional): If set, uses FP16 half-precision inference. Default is False.
dnn (bool, optional): If set, uses OpenCV DNN for ONNX inference. Default is False.
Returns:
argparse.Namespace: Parsed command-line options.
Examples:
To validate a trained YOLOv5 model on a COCO dataset:
```python
$ python val.py --weights yolov5s.pt --data coco128.yaml --img 640
```
Different model formats could be used instead of `yolov5s.pt`:
```python
$ python val.py --weights yolov5s.pt yolov5s.torchscript yolov5s.onnx yolov5s_openvino_model yolov5s.engine
```
Additional options include saving results in different formats, selecting devices, and more.
Notes:
- The '--data' parameter is checked to ensure it ends with 'coco.yaml' if '--save-json' is set.
- The '--save-txt' option is set to True if '--save-hybrid' is enabled.
- Args are printed using `print_args` to facilitate debugging.
"""
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, default=ROOT / "data/coco128.yaml", help="dataset.yaml path")
parser.add_argument("--weights", nargs="+", type=str, default=ROOT / "yolov5s.pt", help="model path(s)")
parser.add_argument("--batch-size", type=int, default=32, help="batch size")
parser.add_argument("--imgsz", "--img", "--img-size", type=int, default=640, help="inference size (pixels)")
"""
⭐⭐⭐重要的参数
1.训练过程中的训练集的置信度评价为0.001
需要看业务情况,常见为0.25
"""
parser.add_argument("--conf-thres", type=float, default=0.25, help="confidence threshold")
parser.add_argument("--iou-thres", type=float, default=0.6, help="NMS IoU threshold")
parser.add_argument("--max-det", type=int, default=300, help="maximum detections per image")
parser.add_argument("--task", default="val", help="train, val, test, speed or study")
parser.add_argument("--device", default="", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")
parser.add_argument("--workers", type=int, default=8, help="max dataloader workers (per RANK in DDP mode)")
parser.add_argument("--single-cls", action="store_true", help="treat as single-class dataset")
parser.add_argument("--augment", action="store_true", help="augmented inference")
parser.add_argument("--verbose", action="store_true", help="report mAP by class")
parser.add_argument("--save-txt", action="store_true", help="save results to *.txt")
parser.add_argument("--save-hybrid", action="store_true", help="save label+prediction hybrid results to *.txt")
parser.add_argument("--save-conf", action="store_true", help="save confidences in --save-txt labels")
parser.add_argument("--save-json", action="store_true", help="save a COCO-JSON results file")
parser.add_argument("--project", default=ROOT / "runs/val", help="save to project/name")
parser.add_argument("--name", default="exp", help="save to project/name")
parser.add_argument("--exist-ok", action="store_true", help="existing project/name ok, do not increment")
parser.add_argument("--half", action="store_true", help="use FP16 half-precision inference")
parser.add_argument("--dnn", action="store_true", help="use OpenCV DNN for ONNX inference")
opt = parser.parse_args()
opt.data = check_yaml(opt.data) # check YAML
opt.save_json |= opt.data.endswith("coco.yaml")
opt.save_txt |= opt.save_hybrid
print_args(vars(opt))
return opt