
在人工智能领域,让模型具备**"看几个例子就能学会新任务"** 的能力,一直是研究者追求的目标。这种在自然语言处理中已趋成熟的上下文学习 (In-Context Learning) ,如今正被深入应用于视觉世界,催生出视觉上下文学习(Visual In-Context Learning, VICL)。
然而,当前主流方法多遵循**"检索-提示"** 范式,往往只挑选最相似的一个示例作为指导。这好比学画时只临摹一幅最像的作品,却忽略了其他视角、风格各异的佳作,无形中丢弃了宝贵的多样性信息。
虽然已有研究尝试将多个示例融合成单一提示 ,但简单的聚合如同将多种颜料混成一色,反而让模型失去了分辨、权衡不同线索的机会。真正的突破,需要一种更精巧的"多面融合"机制。
目录
一、视觉上下文学习:从"单例模仿"到"多例融合"
视觉上下文学习的目标,是让模型仅通过观察几个给定的视觉示例,就能理解和完成新的视觉任务。例如,给定几张分割好的"猫"的图片,模型就能自动对新图片中的猫进行分割。
传统方法如 MAE-VQGAN 使用单一最相似的图像-标签对作为提示。后续研究如 Prompt-Self、VPR、Partial2Global 等虽在提示选择与排序上做了优化,但依然只选一个。
CONDENSER 方法迈出了重要一步:它将前 K 个示例融合成一个 更完整的提示。但问题依然存在------简单压缩会丢失多样性,模型无法对不同来源的信息进行权衡与比较。
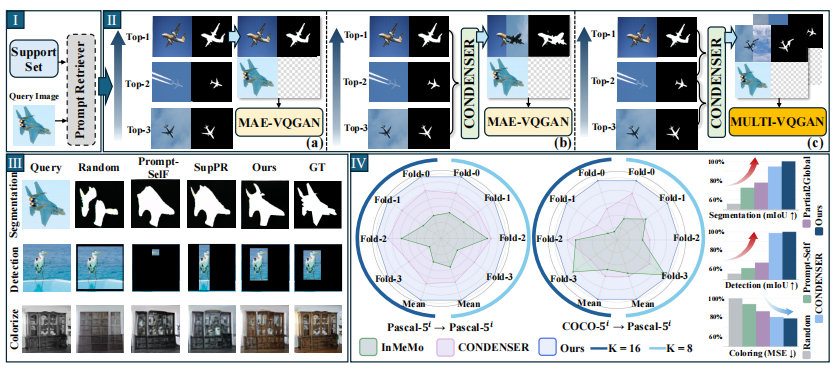
二、核心创新:多提示分组选择与多分支融合架构
该研究的核心思路是:不压缩,而是协作。其框架包含两大关键创新:
多提示分组选择(MPGS)
受解耦表示学习启发,研究团队提出根据示例与查询图像的相似度,将 Top-K 个支持示例分为三组:
-
**整体组:**包含所有支持对,提供完整上下文。
-
**高相似组:**由最相关的几个示例组成,提供与查询直接相关的细粒度线索。
-
低相似组: 由相似度较低的示例组成,提供多样性 与对比信息,增强模型鲁棒性,防止过拟合。
这种分组策略显式地保留并利用了互补的上下文信息。
多分支VQGAN融合架构(MULTI-VQGAN)
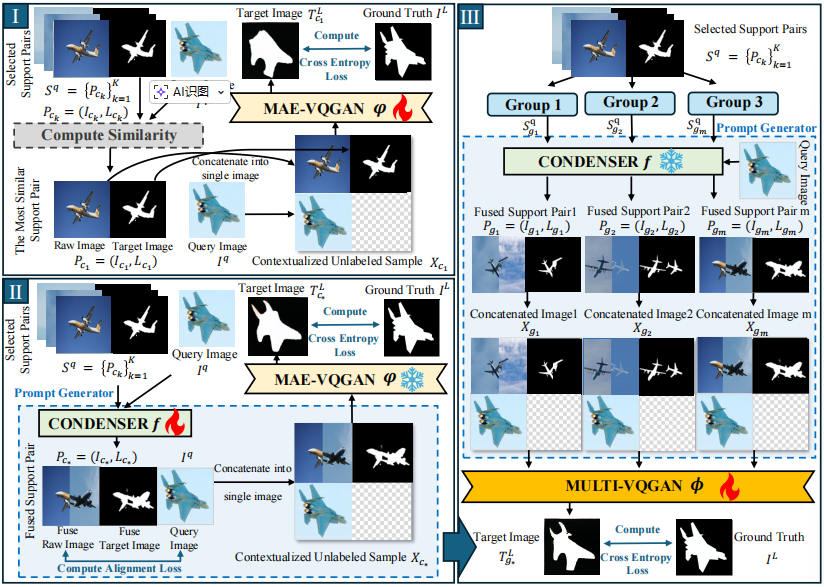
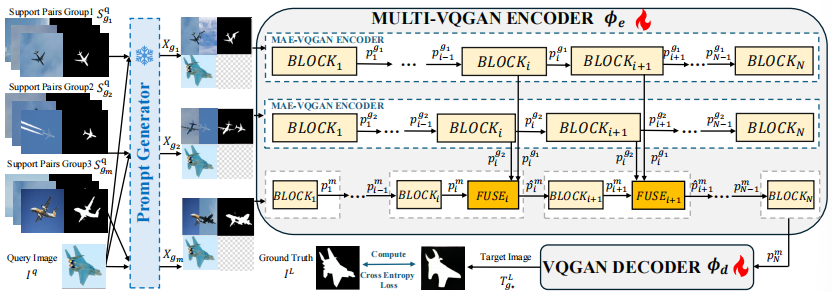
研究团队设计了全新的 MULTI-VQGAN 架构来处理这三组信息。其核心是一个多分支编码器:
-
主干分支处理整体组信息。
-
两个辅助分支分别处理高、低相似组信息。
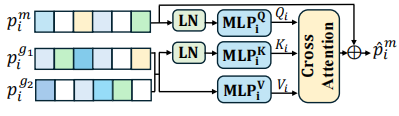
关键创新在于分层融合机制 。在主干网络的一系列中间层中,引入可学习的FUSE模块 。该模块利用交叉注意力机制,动态地将两个辅助分支的引导特征整合到主干特征中,实现层次化的特征融合。
三、实验效果:全面领先,泛化能力出众
研究团队在前景分割、单目标检测、图像上色三个任务上进行了全面测试。
量化结果显优势
在PASCAL-5ⁱ数据集上的实验表明,该方法在K=8和K=16两种设置下,性能均全面超越包括CONDENSER在内的现有方法。在分割任务上实现了5.6% 的显著性能提升。
更值得一提的是其强大的跨域泛化能力。在COCO-5ⁱ数据集上训练,然后在PASCAL-5ⁱ上测试的挑战性设置中,该方法同样表现最优,证明了其学到的表示具有高度的可迁移性。
消融实验验真章
通过系统的消融实验,研究团队验证了各个组件的必要性:
-
使用双分支(高/低相似组)效果最佳,单纯增加分支数量无益。
-
用整体组作为主干分支至关重要。
-
FUSE模块中的独立Q/K/V投影、交叉注意力、残差连接协同作用,缺一不可。
-
在编码器的中层进行融合(如第8至14层)能最好地平衡高层结构控制与低层细节优化。
定性结果更直观

可视化结果显示,该方法在复杂场景 中能更好地保持物体结构的完整性和细节的清晰度,检测框更紧致准确,上色效果更自然连贯。
总结
这项研究推动视觉上下文学习从**"选择或压缩提示"** 迈向**"协作融合提示"** 的新阶段。通过创新的多提示分组策略 (MPGS) 和分层多分支融合架构 (MULTI-VQGAN),模型能够充分利用多个示例中的互补信息,从而做出更鲁棒、更准确的预测。
广泛的实验证明,该方法在多种任务和跨域场景下均具有优越的泛化能力。这不仅为视觉上下文学习提供了新思路,也为构建更通用、更强大的视觉基础模型奠定了坚实基础。
未来,这种**"多面协作"**的融合范式有望扩展到更多视觉乃至多模态任务中,让人工智能的上下文学习能力更接近人类的"举一反三"。
