前言:
承接上文,我继续总结关于YOLOv5的源码在实际操作使用中时的一些常见方法,和相应的一些小案例。
1.网络源码原理
yolov5s.yaml(定义 "蓝图")→ parse_model方法(解析 "蓝图")→ common.py(提供 "砖块")
YOLOv5网络为例
1.models/yolov5s.yaml
目标网络的主体架构
2.models/common.py
自定义网络模块(组件)实现文件
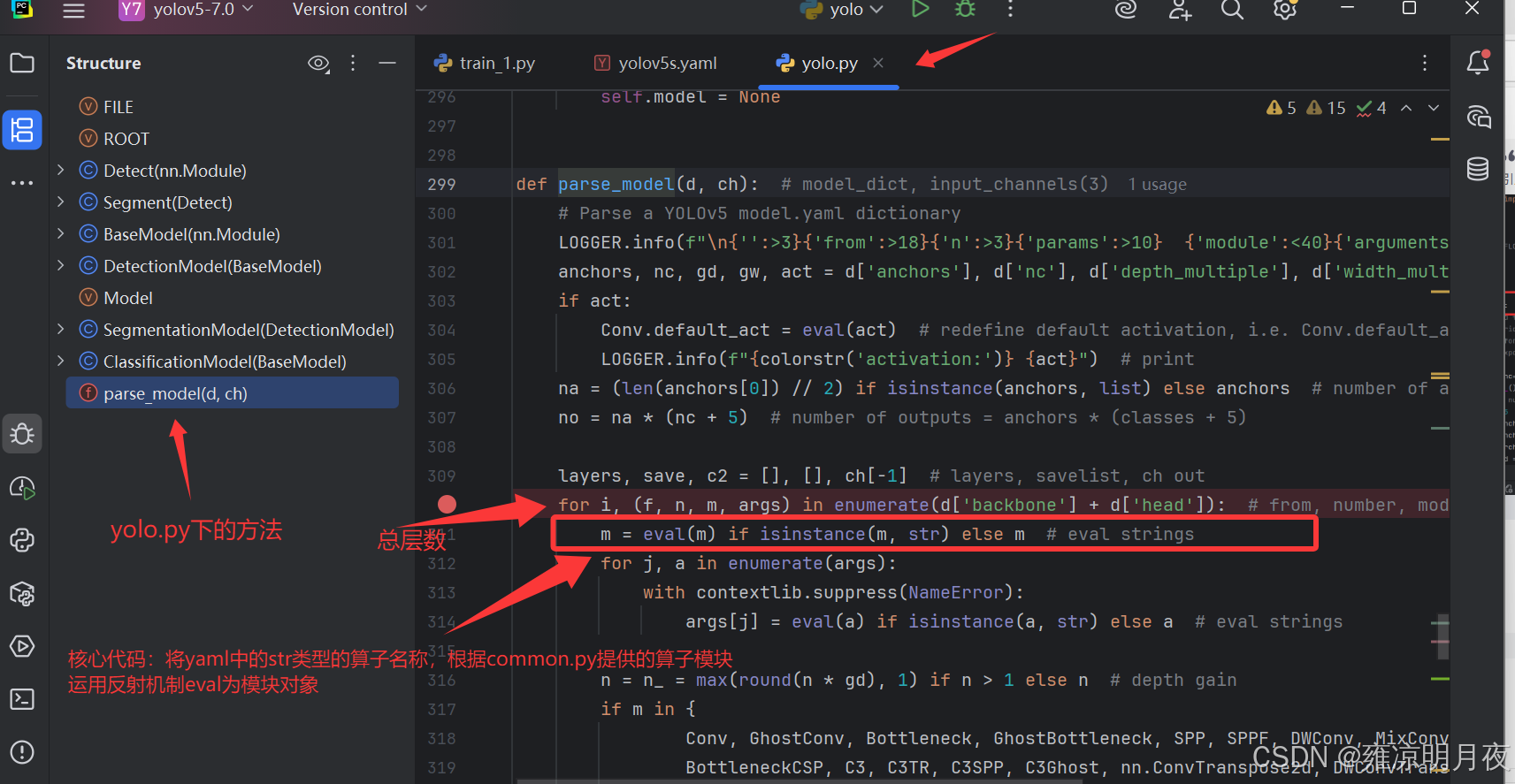
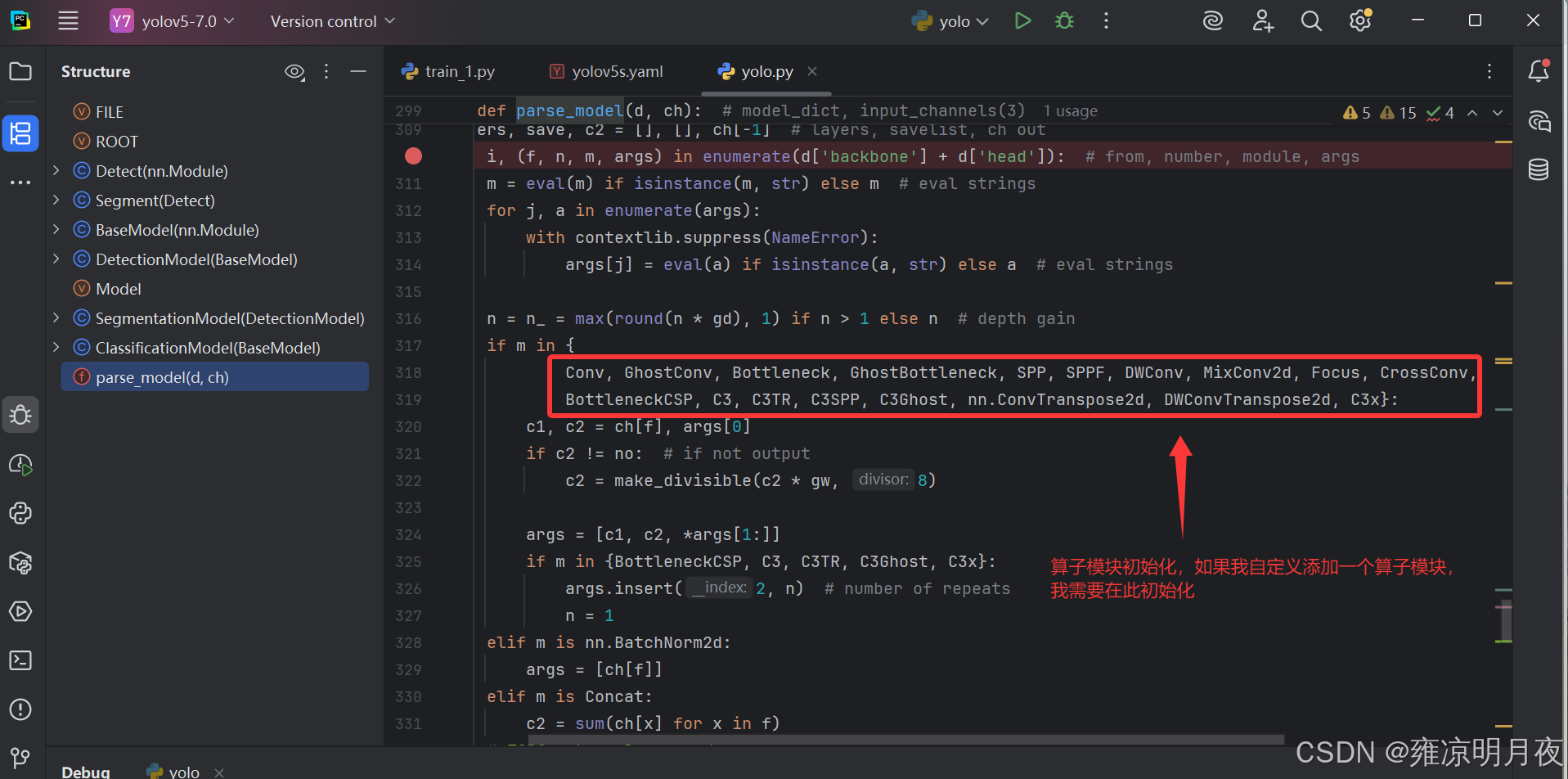
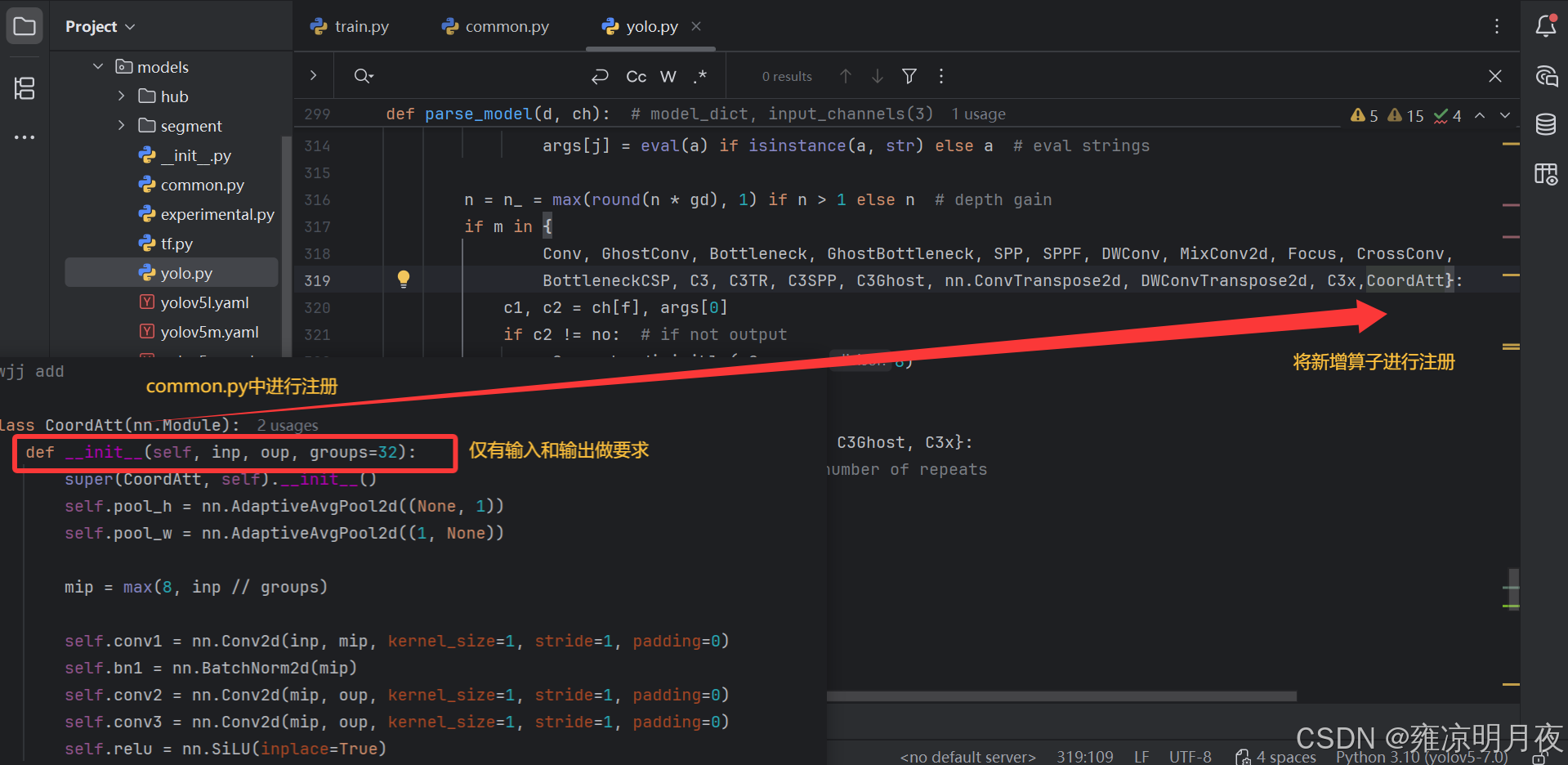
3.models/yolo.py 中的parse_model方法
parse_model方法的核心职责是解析yaml配置文件,构建对应的网络模型结构,其中 "通过eval()方法将 yaml 中的字符串算子反射到common.py中的对象" 是其中的关键步骤反射机制 eval strings
修改模型添加算子则需要注意以下三点:1.in_c和out_c的对应关系
2.上述需要注册算子
3.层级关系也需要调整
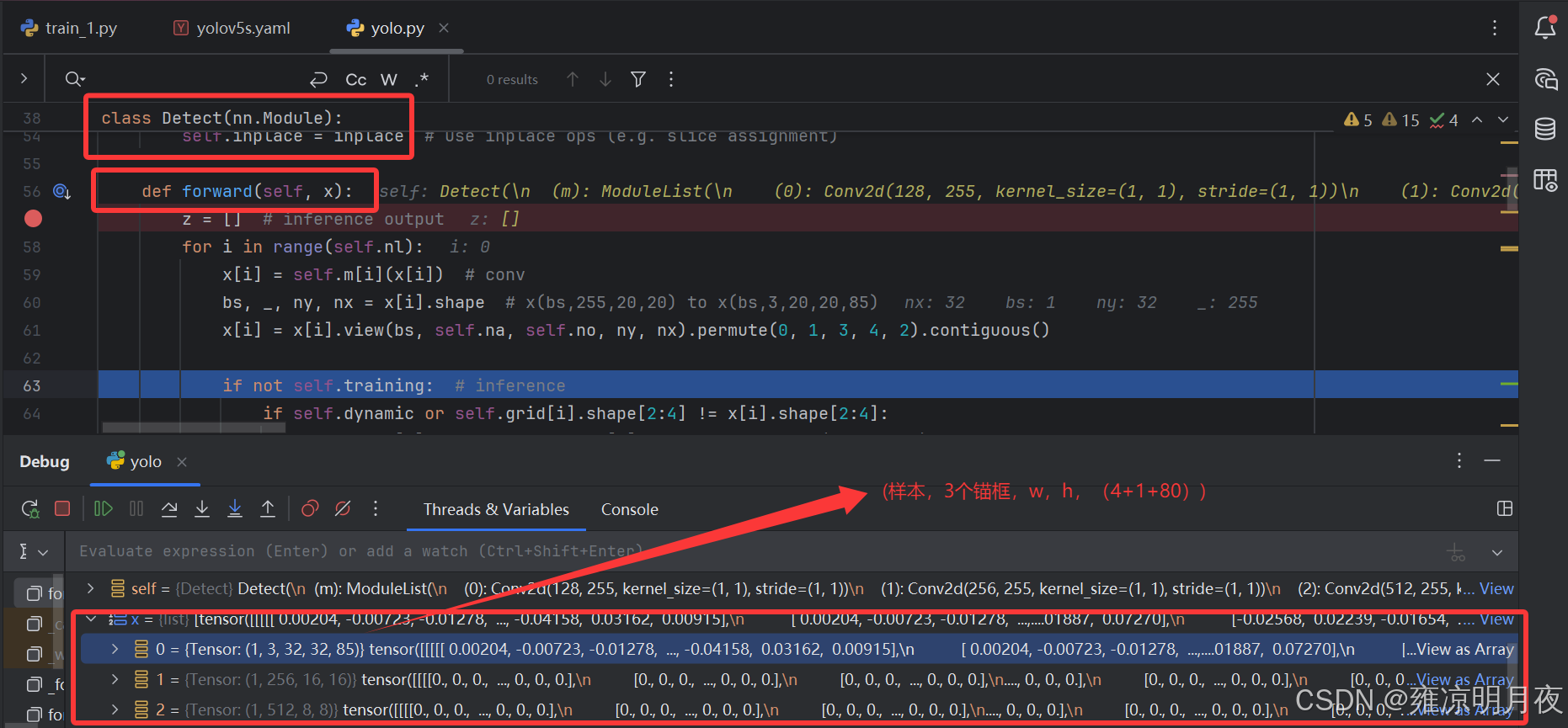
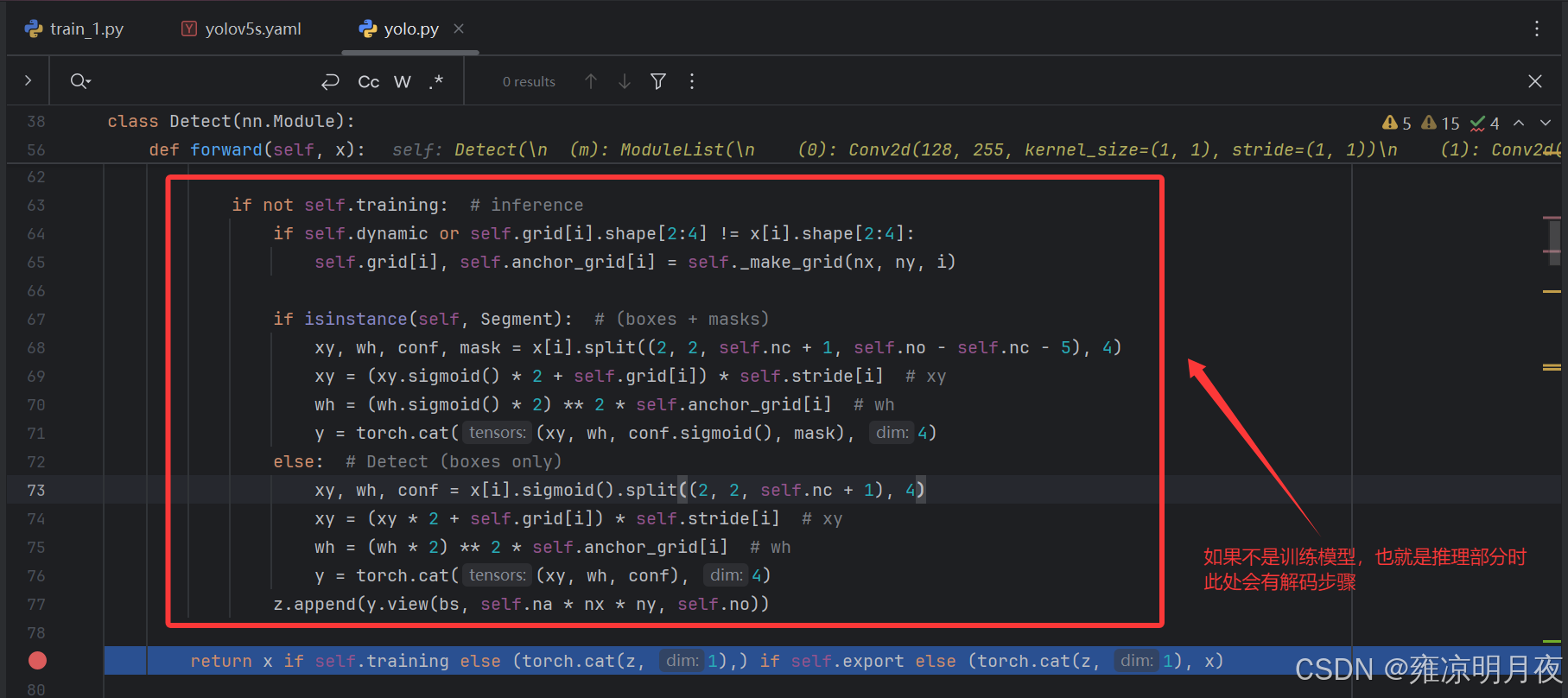
Detect模块中的前向传播 + 推理时的解码过程
2.模型经验修改
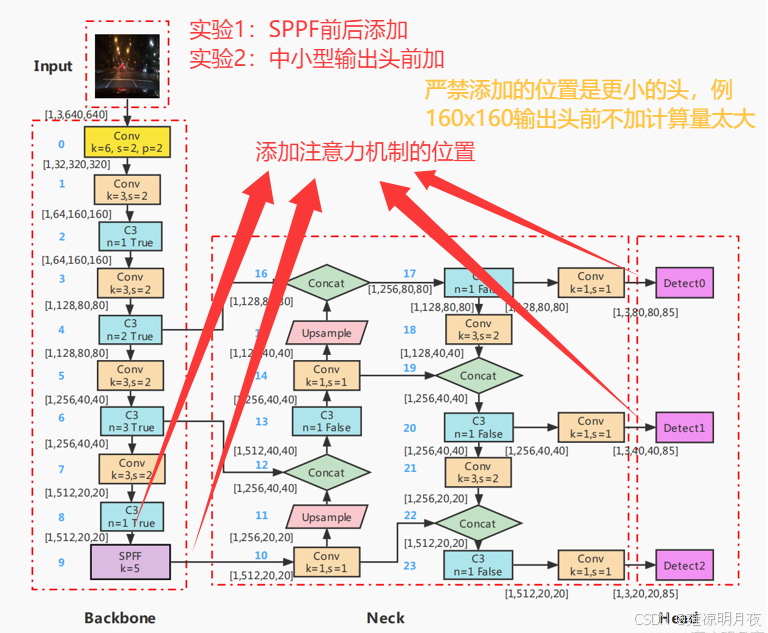
1.网络结构添加注意力
经验添加注意力机制位置试验分析:
试验3:在上采样之前添加注意力机制也可以尝试看看效果怎么样
更小位置的头例:160x160为什么不加注意力机制:
1.计算量太大
2.噪声多易误检
2.模型优化实例
常见模型选用:
1.轻量型人脸检测:yolov3-tiny.yaml
2.大目标输出头:yolo5-p6.yaml (4个头)
3.超大目标选择 :yolov5-p7.yaml (5个头)
1.减少输出头方法
本质:客户数据集主要集中于中小目标,其大目标的输出头20x20作用不大因此删减。
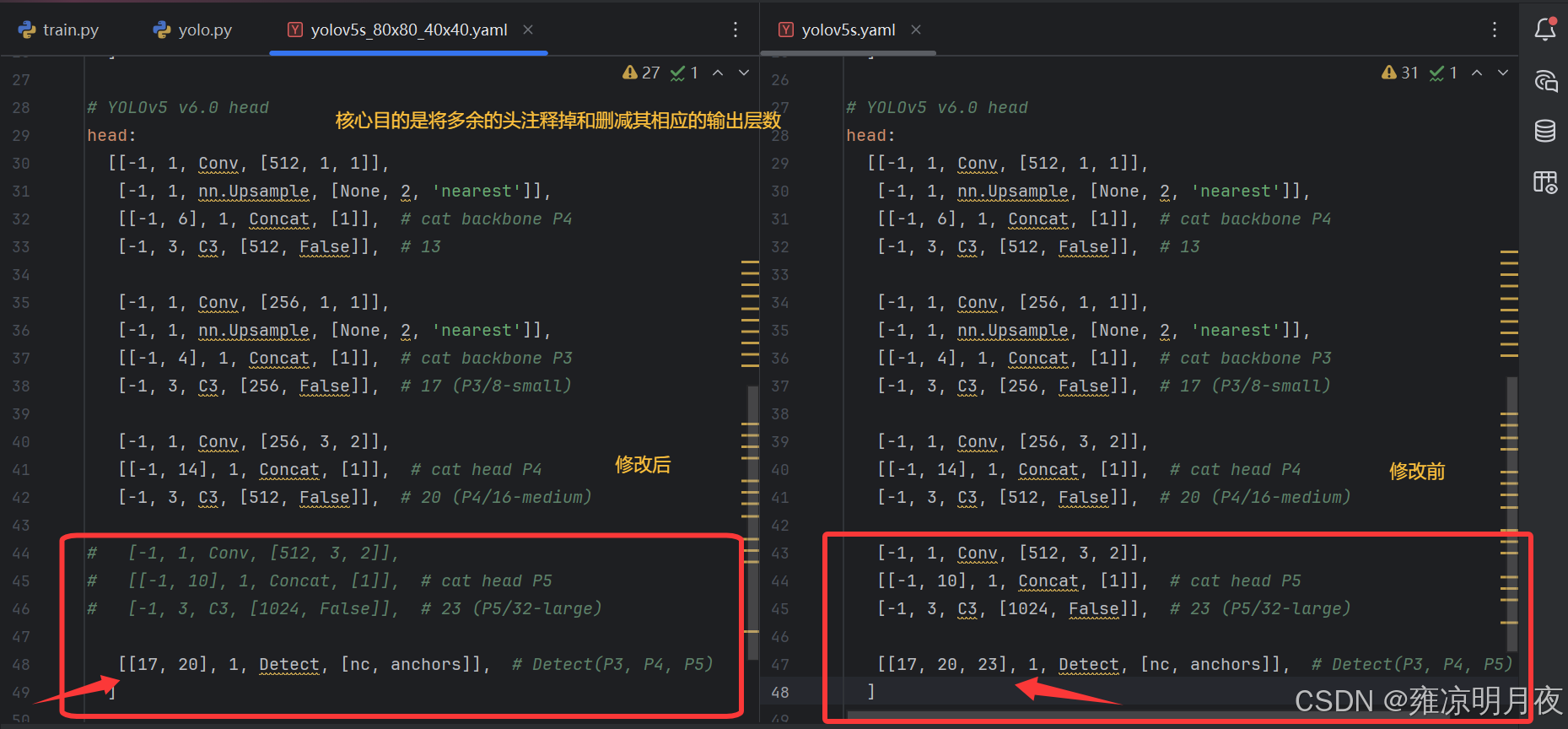
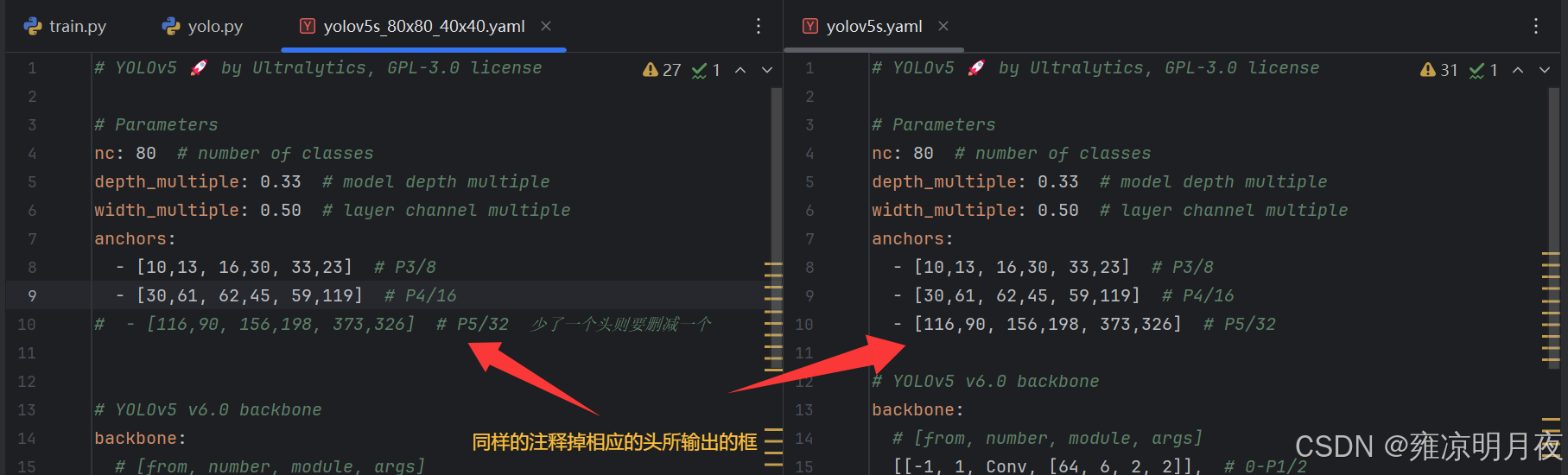
2.添加CA注意力
基于上述修改后(此时仅有两个头)进行2次修改。
1.首先得先在网上找到一个注意力机制的模块将其适配到common.py的算子之中
python
class CoordAtt(nn.Module):
def __init__(self, inp, oup, groups=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // groups)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.conv2 = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv3 = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.relu = nn.SiLU(inplace=True)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.relu(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
x_h = self.conv2(x_h).sigmoid()
x_w = self.conv3(x_w).sigmoid()
x_h = x_h.expand(-1, -1, h, w)
x_w = x_w.expand(-1, -1, h, w)
y = identity * x_w * x_h
return y
#wjj end2.将相应的算子模块注册到yolo.py中(注意算子的参数确定注册位置)
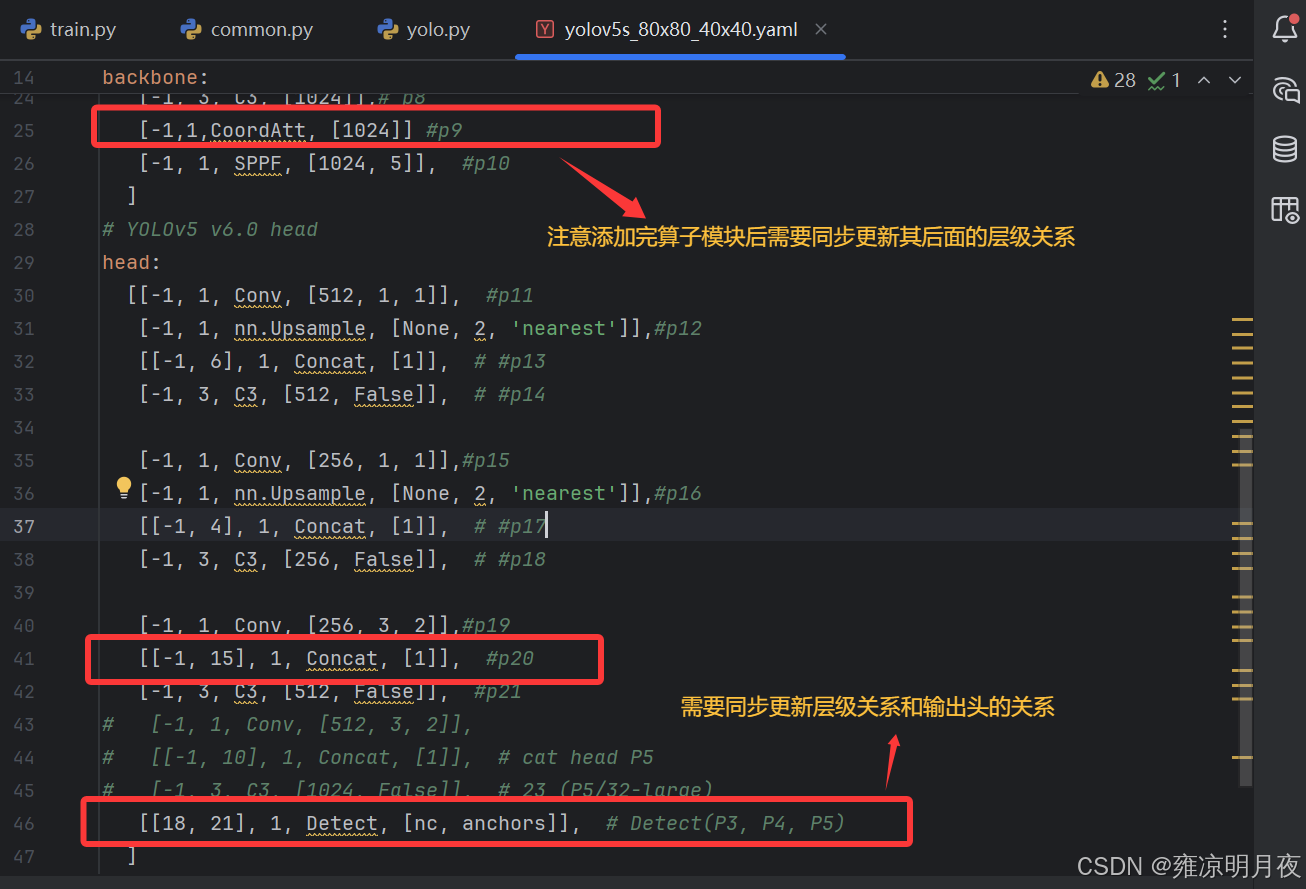
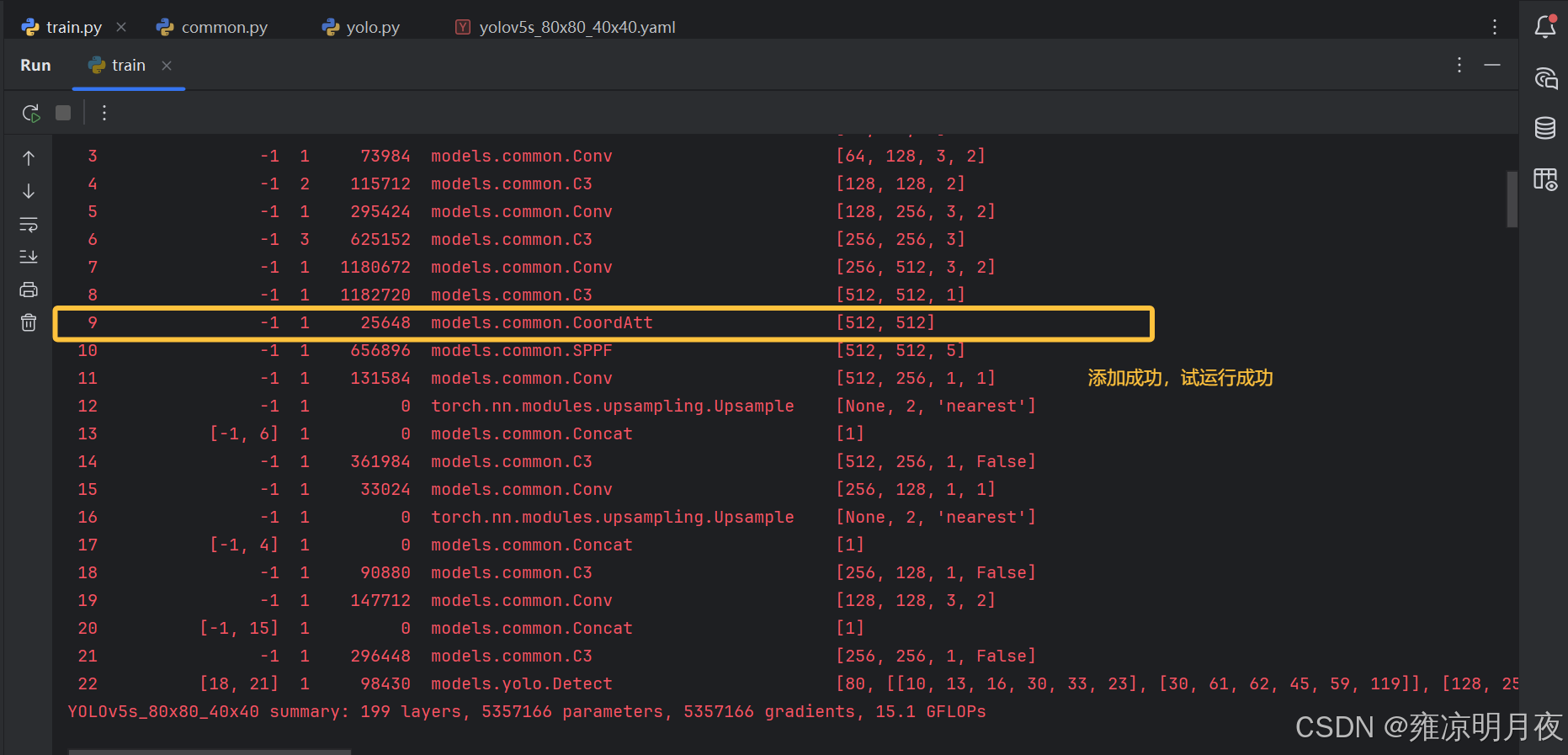
3.在需要执行的yolov5s_80x80_40x40.yaml文件中添加算子且更新其层级关系
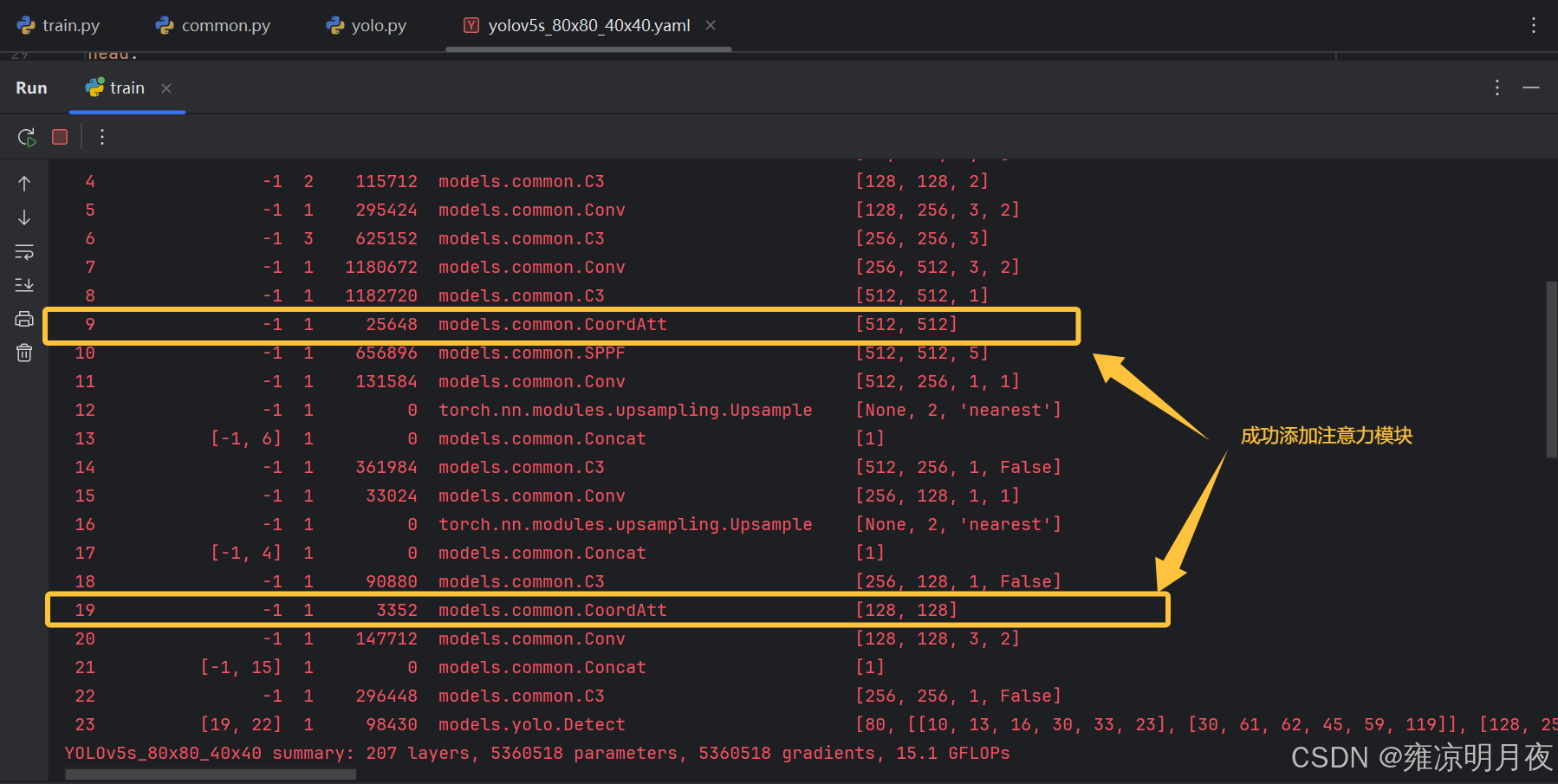
相同策略在80x80头前也添加相应的CA注意力机制
3.添加输出头方法
在上述的基础上我们去掉了20x20的输出头,现在我模拟实际操作添加160x160的输出头
- 锚框适配 :新增对应分辨率的锚框组(如 160×160 头配小锚框
[2,4,5,5,8,10]),删除不需要的锚框组(如删除 20×20 头则删对应 P5 锚框),确保锚框组数与输出头数量一致;- 特征源确认:找到新增头对应的 backbone 特征层(160×160 对应 stride=4 的 P2/4 层);
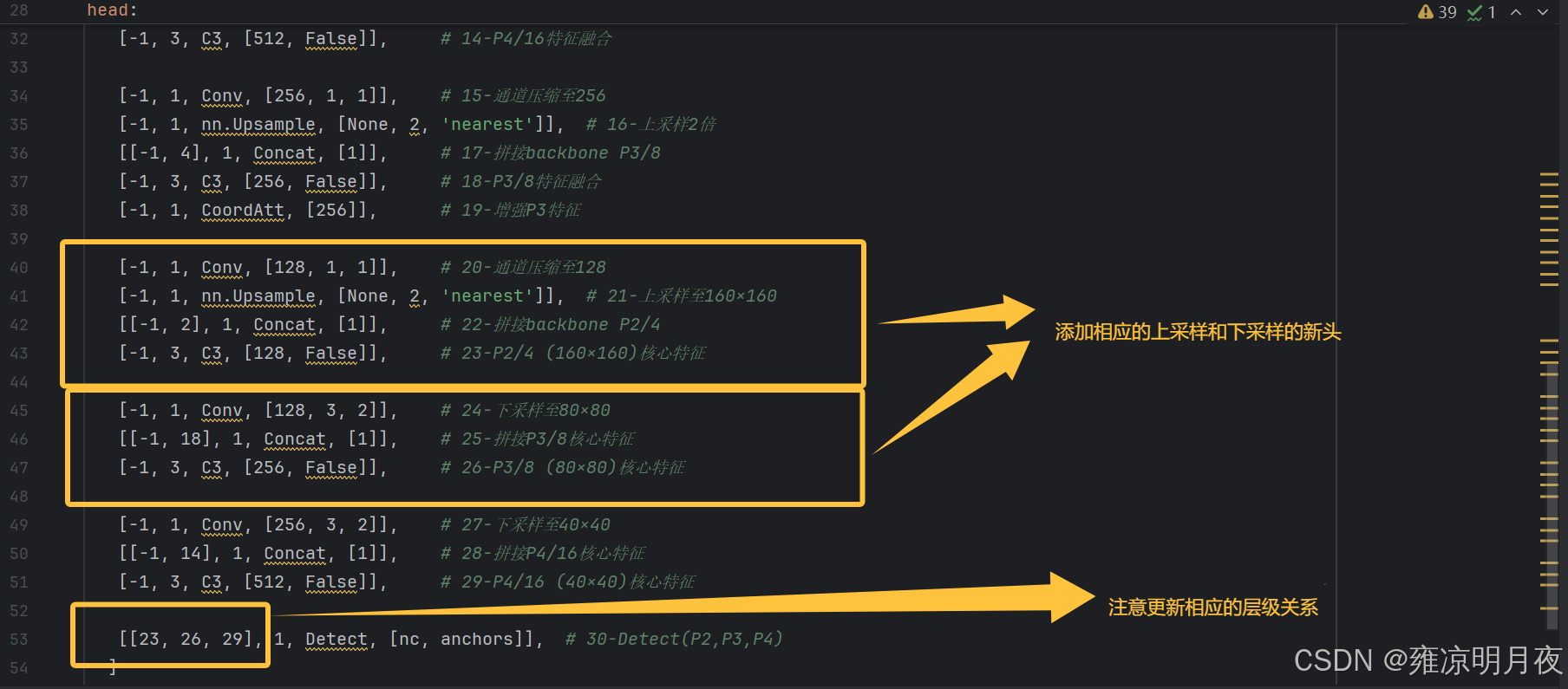
- 分支构建:新增 "通道压缩→上采样→拼接 backbone 特征→C3 融合" 的分支,形成新增头的核心特征层;
- 检测头输入更新 :修改 Detect 层的输入分支索引,匹配新增 / 保留的输出头(如
[[23,26,29], 1, Detect, ...]对应 160/80/40×40 三头);- ✅ 易错点:Concat 拼接时需选 C3 输出的核心特征层,而非注意力层等增强层。
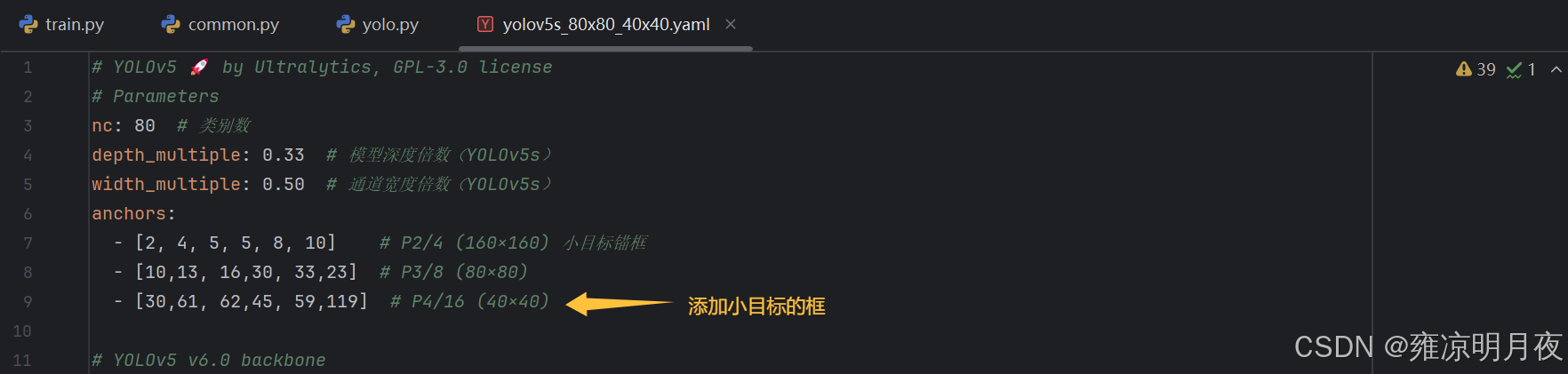
更新时着重注意
✅ 易错点:Concat 拼接时需选 C3 输出的核心特征层,而非注意力层等增强层。
总结
本章承接上一章节,主要做的是在上一章中的yolov5的源码的学习过程中,我们根据实际优化情况总结了一些常见的案例,用于进一步优化我们的网络结构。