作者: 闵加坤 | 淘天集团价格平台开发工程师
业务介绍
淘天价格力团队作为平台价格治理的核心部门,承载着淘宝天猫全域商品价格管理的重要职责。团队掌握着淘内外所有商品的全量价格信息,包括商品原价、券后价等多维度价格数据,每日增量数据规模达亿级以上。
在电商大促上下线时(如618、双11),价格变动 频率会呈现数倍增长,这些海量数据不仅体量大,而且具有高时效性、强关联性和复杂变化特征。在大促常态化 的现状下,行业运营急需高时效性的数据看板以便及时发现问题,并且需要商品维度、店铺维度等多维圈选能力,及时圈选出符合要求的数据并进行处理或分析。Hologres Dynamic Table完美契合业务需求。
Hologres Dynamic Table介绍
视图是基于表的虚拟表,不存储数据只存储查询逻辑,每次访问时动态执行SQL,返回最新结果,主要帮助我们简化复杂查询。如果没有视图,那么对于以下查询,需要我们自己保存到一个地方,查询时执行完整SQL。
SELECT region, SUM(amount) as total_sales
FROM orders
WHERE status = 'completed';如果有视图,我们可以把查询托管给视图,直接查询视图,可以简化使用。
-- 创建视图
CREATE VIEW sales_summary AS
SELECT region, SUM(amount) as total_sales
FROM orders
WHERE status = 'completed';
-- 查询视图
SELECT * FROM sales_summary;视图虽然帮我们管理了SQL的定义,但是复杂逻辑SQL的执行通常很耗费时间 。将视图的查询结果实际保存 下来就是物化视图 。物化视图的结果需要定期更新 以保证数据新鲜度。所以物化视图就是预定义SQL + 物化结果 + 周期更新。
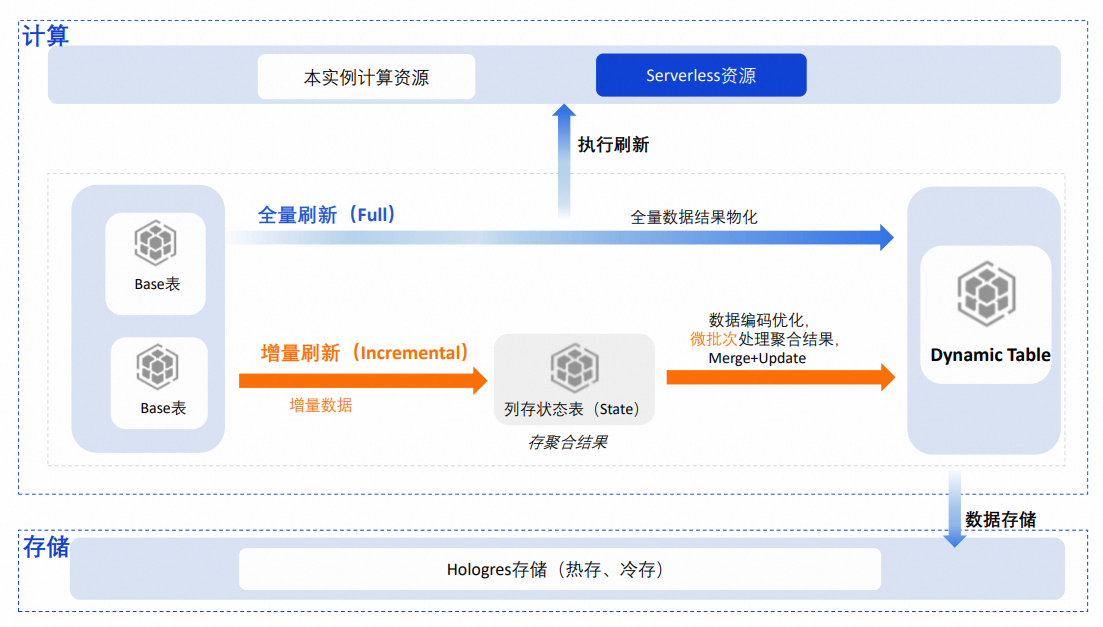
Hologres Dynamic Table与物化视图类似,架构如下,提供全量刷新与增量刷新两种刷新模式。
全量刷新就是在周期到来时进行一次全量刷新覆盖,相当于Insert Overwrite。
增量刷新每次只处理增量数据,原理为在底层创建一个列存state表,存储中间状态(类似Flink state)。增量数据先以微批次方式做内存态聚合,再与state表合并,最后提交时以BulkLoad写入动态表。
在 Hologres V3.1中 Dynamic Table 的能力如下。
|------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------|
| 备注 | 提供auto模式,若Query支持增量刷新则优先选择增量刷新,否则退化为全量刷新 ||
| 文档 | 声明式数据处理自动数据流转-Dynamic Table-实时数仓 Hologres-阿里云 ||
| 刷新模式 | 增量刷新 | 全量刷新 |
| 技术实现 | 微批次增量处理 | INSERT OVERWRITE |
| 刷新触发 | 定时/手动 ||
| 最小可配置间隔 | 1分钟 ||
| 增量机制 | Binlog:处理CDC数据 Stream:文件级别处理增量数据,读取性能比Binlog高。 | 无(全量) |
| 基表类型 | 内表、动态表、Paimon外表 | 内表、动态表、Paimon外表、ODPS外表、DLF外表 |
| Join支持 | ✅ 完整Join支持 ||
| 聚合函数 | ✅ 支持 ||
| 索引配置 | ✅ 支持 ||
| 窗口函数 | ❌ 不支持 | ✅ 支持 |
| IN子查询 | ❌ 不支持 | ✅ 支持 |
| 查询改写 | ❌ 不支持 ||
| 分区支持 | ✅ 物理/逻辑分区 ||
| 分区刷新 | 配置范围 ||
| 历史分区回刷 | ✅ 手动回刷 ||
| 计算资源 | Local/Serverless Serverless是实例资源上额外的资源,最大4096core,可为动态表设置可用core。 ||
| 资源隔离 | 实例资源/Serverless隔离 ||
| Query变更:新增列、修改计算逻辑 | ✅ 支持 ||
| 主要限制 |  * Stream模式基表只能是列存表 * 若上游表为分区表,无法同时消费 上游表的多个分区。 * 仅支持把刷新模式从增量改为全量,不支持从全量改为增量 | • 资源消耗大 |
* Stream模式基表只能是列存表 * 若上游表为分区表,无法同时消费 上游表的多个分区。 * 仅支持把刷新模式从增量改为全量,不支持从全量改为增量 | • 资源消耗大 |
业务实践
数据圈选
业务背景
价格力团队需要为多个业务场景如商品价格回滚、全网比价等提供灵活的数据圈选能力,要求支持动态的指标组合和筛选条件配置。圈选集创建后,圈选结果也需要随底表数据的变化而变动,不同业务场景可接受的数据变化时间间隔也有所不同。
解决方案
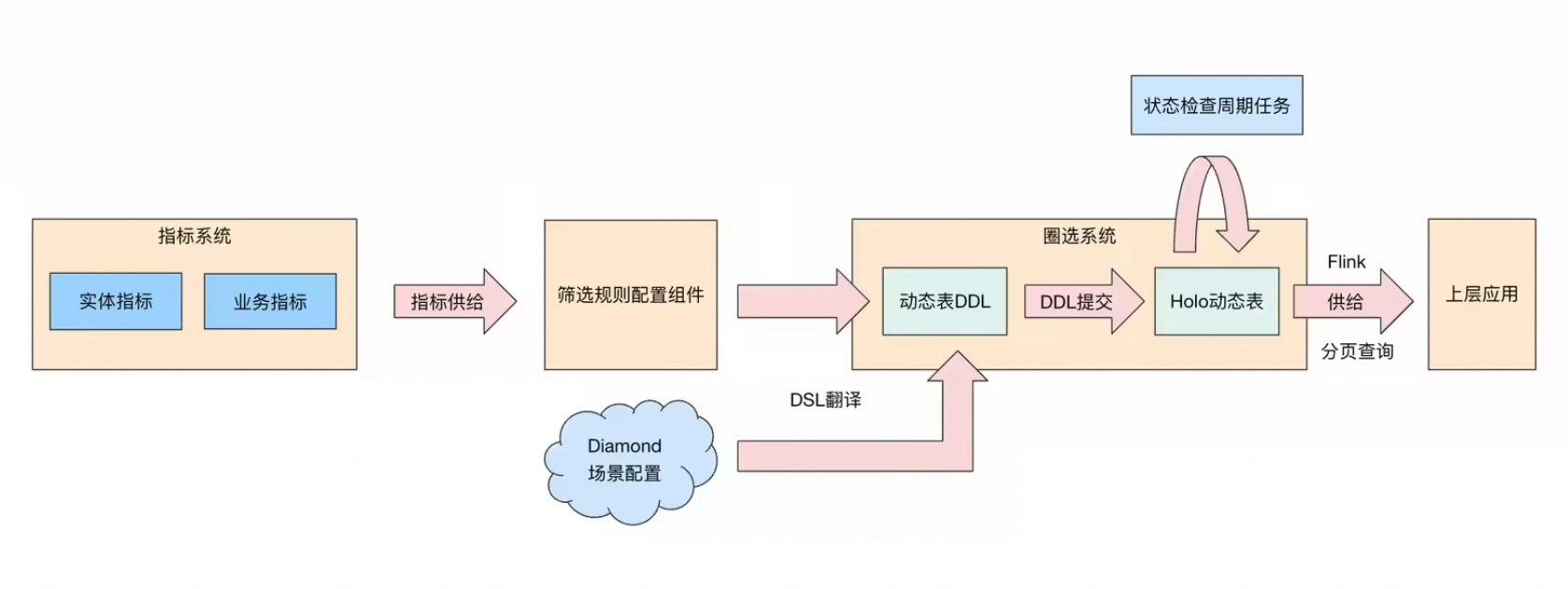
Dynamic Table完美符合场景要求:工程基于不同的筛选规则翻译成相应的DQL,并根据业务场景的需求灵活设置数据新鲜度等配置参数,最终生成完整的Dynamic Table DDL。
指标系统: 指标系统中将表列配置为实体指标。业务指标提供高阶能力如级联指标、聚合、召回计算。
筛选组件: 提供通用筛选配置组件,根据业务场景展示相应指标
业务场景默认配置:Diamond中保存不同业务场景默认配置,包括刷新周期、刷新模式、默认召回条件、默认Join条件等
DDL生成: 将筛选条件与默认条件通过DSL翻译为Hologres Dynamic Table DDL
状态监控: 实现刷新状态检查机制,定期检查动态表刷新状态,区分未完成刷新 和刷新后无数据两种情况
数据供给:动态表第一次刷新完成后,提供Flink 和分页查询两种数据供给方式。若选择Flink,在动态表创建完成后会自动根据默认条件创建Flink任务,通常把数据变更作为消息发送给MetaQ
应用效果
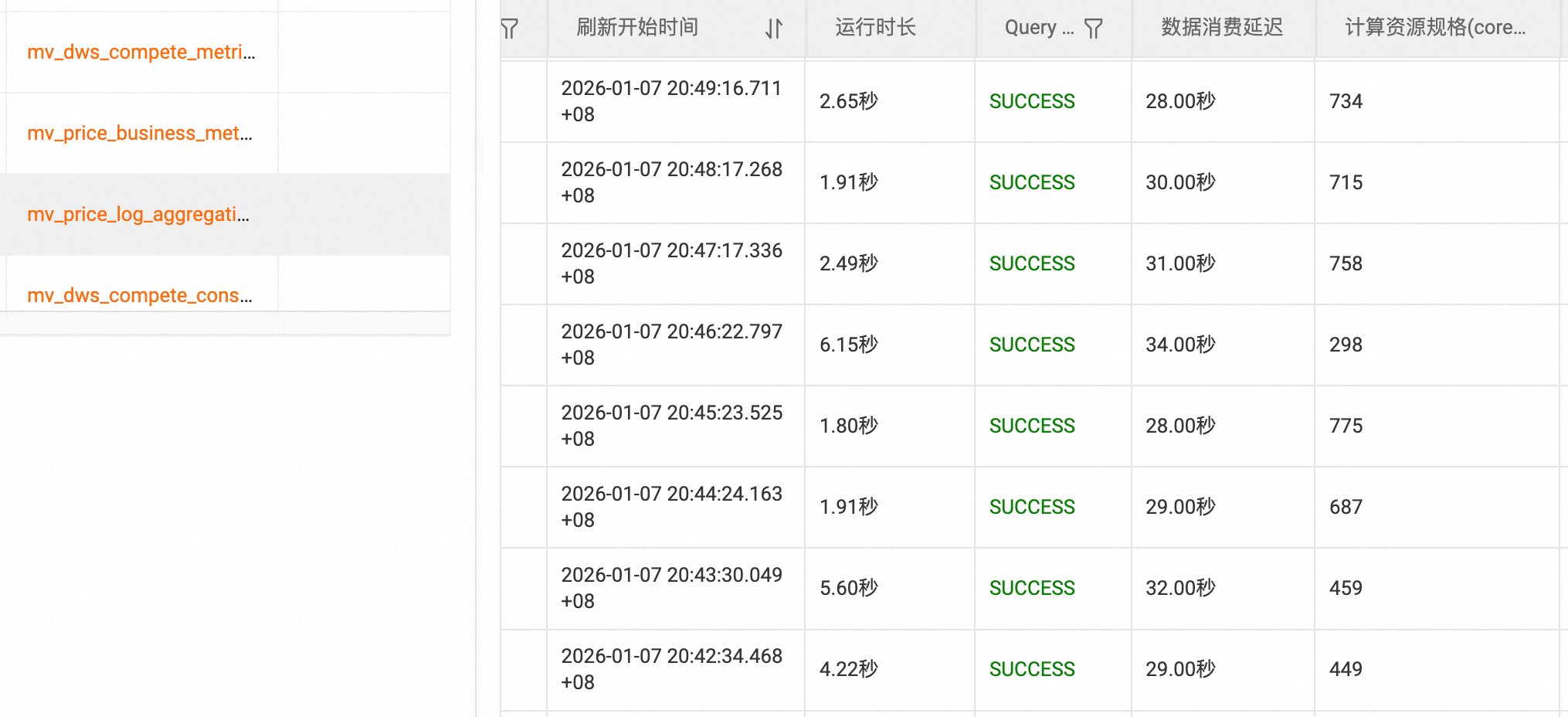
该方案可在秒级 从亿级数据基表中完成Dynamic Table创建及初次数据刷新,已在价格力团队多个业务场景中部署应用,显著提升了数据圈选的灵活性和效率。
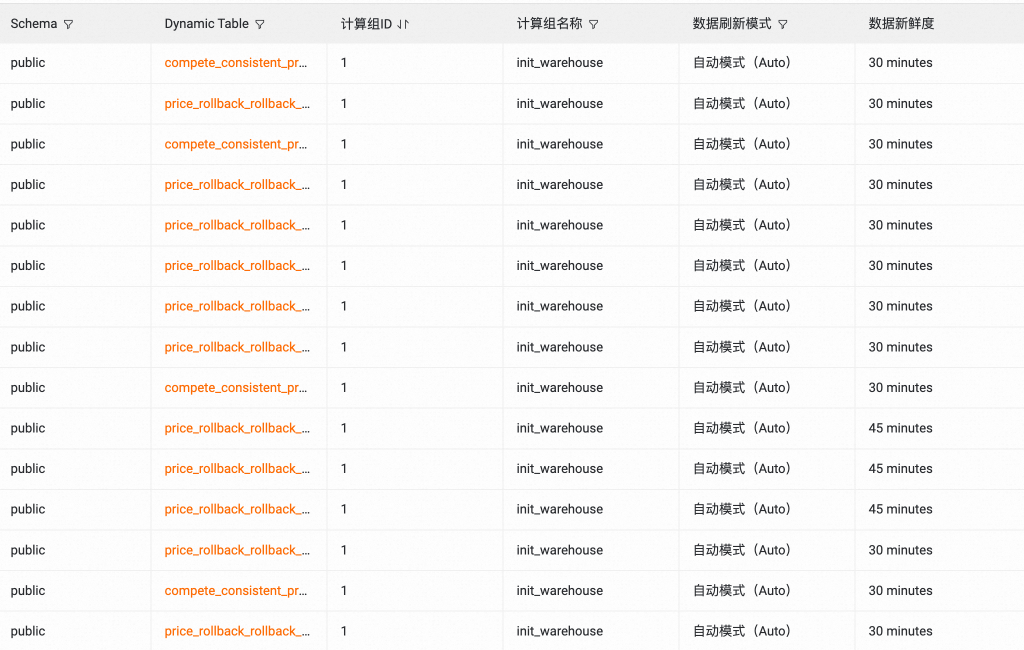

近实时报表构建
业务背景
数据看板的时效性越高,越能帮助运营及时发现问题,快速进行决策和业务调整。价格力团队内部分场景的报表数据原通过ODPS离线调度实现更新,但运营期望能有近实时分钟级数据。
解决方案
数据分层构建: 基于Hologres Dynamic Table实现ODS → DWD → DWS → ADS数据架构的近实时化改造
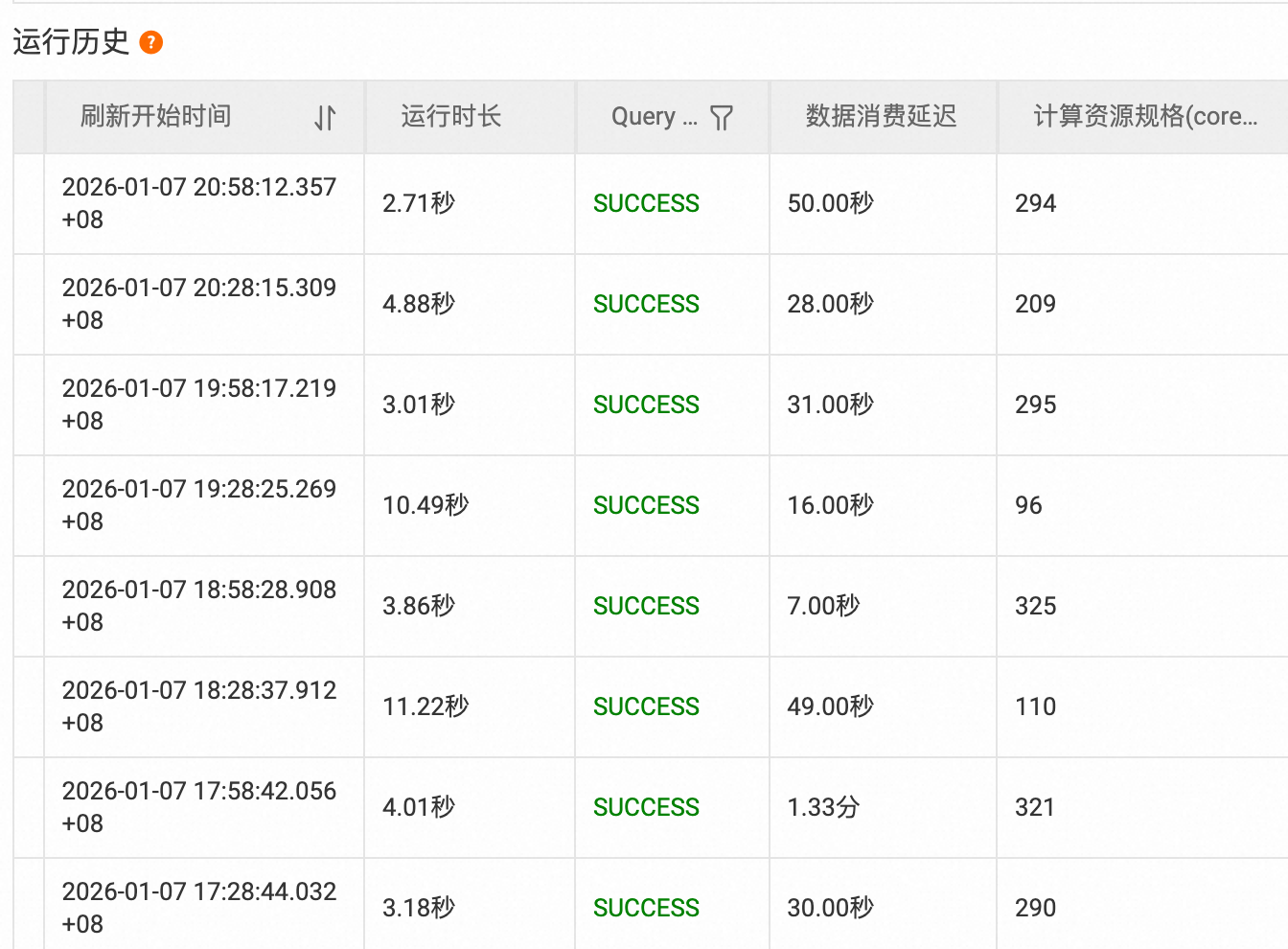
增量刷新策略: 采用动态表增量刷新 机制,设置分钟级 刷新间隔,实现近实时数据更新,并分钟级保存历史数据。
资源隔离保障: 通过使用HologresServerless资源减少与其他任务的资源竞争。
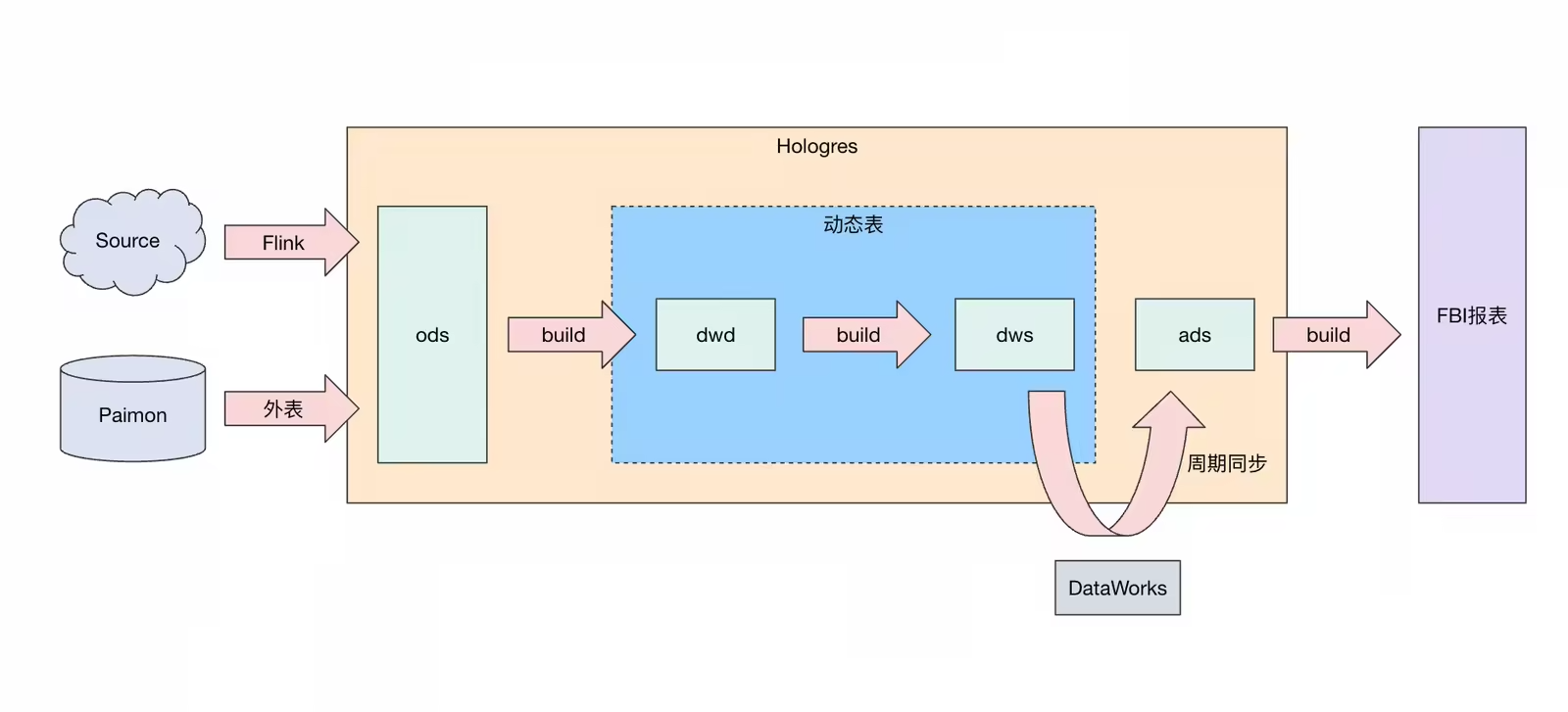
应用效果
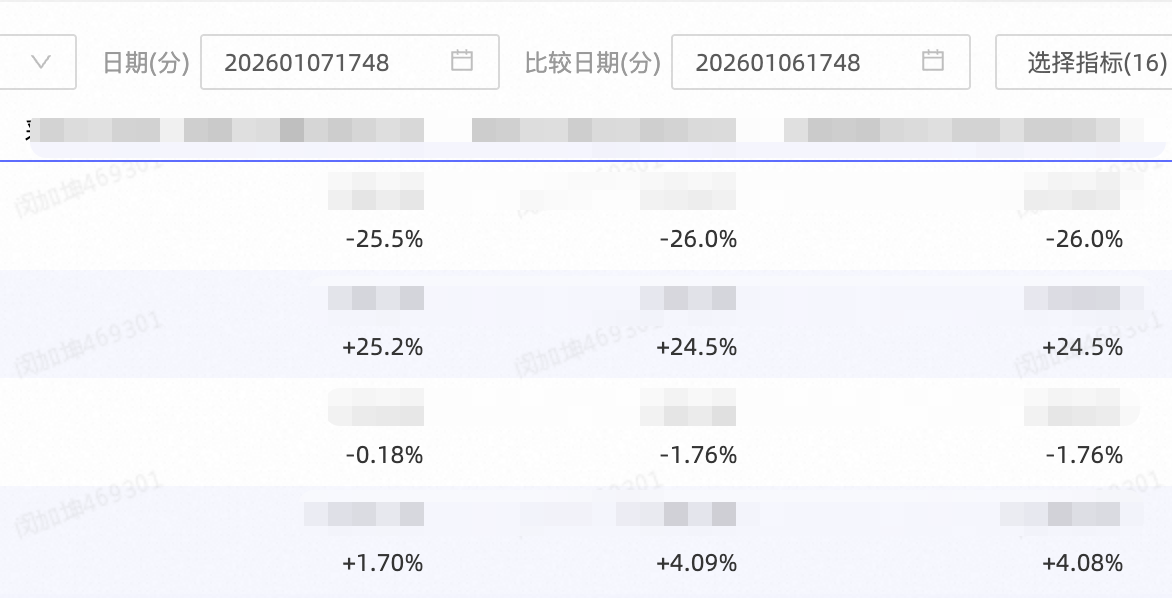
应用效果: 成功解决了数据看板的时效性痛点,亿级底表数据,输入RPS 1W 的处理时延从小时级降低至分钟级 ,可以灵活比对任意分钟数据的同比,双十一期间为运营团队提供了及时可靠的数据支撑。