目录
文章目录
- 目录
- [NLP 的发展阶段](#NLP 的发展阶段)
-
- 符号主义阶段
- 联结主义和统计学习阶段
- [DL(Deep Learning,深度学习)阶段](#DL(Deep Learning,深度学习)阶段)
- [PLM(Pretrain Language Model,预训练语言模型)阶段](#PLM(Pretrain Language Model,预训练语言模型)阶段)
- [LLM(Large Language Model,大语言模型)阶段](#LLM(Large Language Model,大语言模型)阶段)
- [NLP 的关键任务](#NLP 的关键任务)
- [NLP 文本表示方法](#NLP 文本表示方法)
-
- [VSM 文本向量化表示法](#VSM 文本向量化表示法)
- [Word2Vec 文本词嵌入化表示法](#Word2Vec 文本词嵌入化表示法)
NLP 的发展阶段
NLP(Natural Language Processing,自然语言处理)是 AI 领域的一个重要分支,旨在使计算机能够理解和处理人类语言,实现人机之间的自然交流。
语言是人类智力的外化体现。1950 年,艾伦·图灵提出了图灵测试,他说:"如果一台机器可以通过使用打字机成为对话的一部分,并且能够完全模仿人类,没有明显的差异,那么机器可以被认为是能够思考的。" 图灵测试是判断机器是否能够展现出与人类不可区分的智能行为的测试。
在计算机领域,NLP 的主要处理对象之一就是 "自然语言文本" 数据,使得计算机能够执行各种复杂的文本处理任务,如:中文分词、子词切分、词性标注、文本分类、实体识别、关系抽取、文本摘要、机器翻译、自动问答等。这些任务不仅要求计算机能够识别和处理语言的表层结构,更重要的是可以理解语言背后的深层含义,包括语义、语境、情感和文化等方面的复杂因素。NLP 技术的进步为我们从海量文本中提取有用信息、理解语言的深层含义提供了强有力的工具。
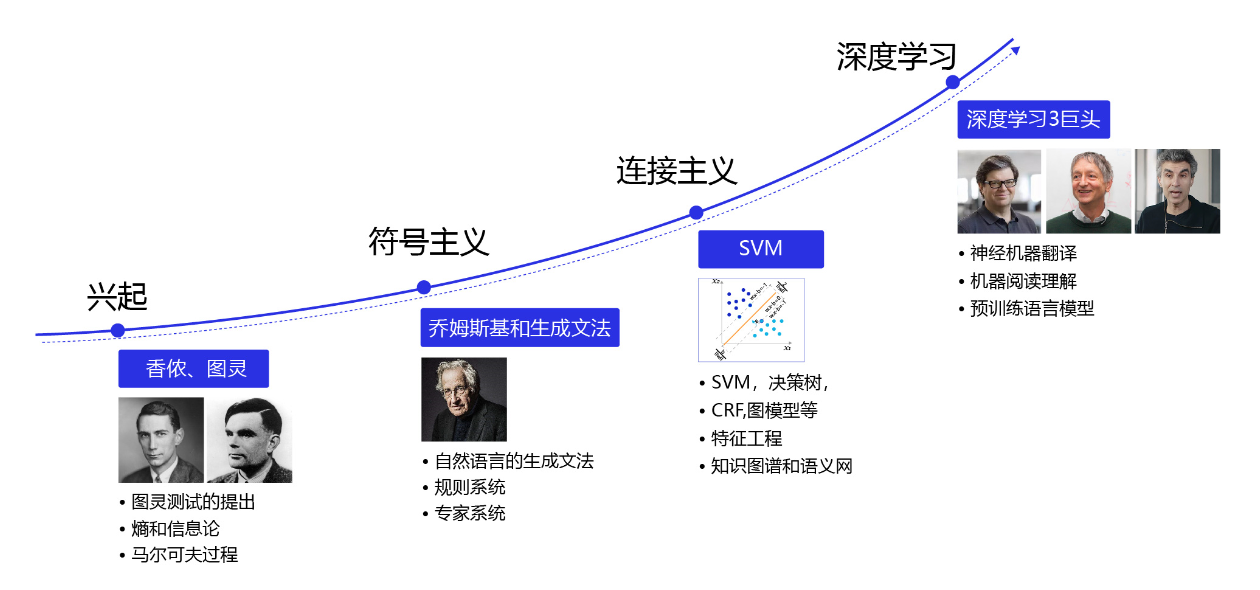
NLP 从诞生至今经历了符号主义阶段、统计学习阶段、深度学习阶段、PLM(Pretrain Language Model,预训练模型)阶段到而今的 LLM(Large Language Model,大语言模型)阶段的多次变革。每次技术变革都极大地推动了 NLP 技术的发展,使其在机器翻译、情感分析、实体识别和文本摘要等任务上取得了显著成就。
符号主义阶段
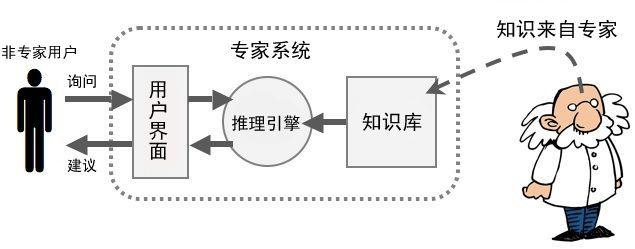
符号主义学者认为人类理解力范围内的一切事物皆可以用符号来标记,人类理解力本身可以被描述成这些符号之间的运算。结合以上两者,得到一套带运算的符号系统(物理符号系统),它就等于人类的智能,并且,这套系统可以被完整地写进机器,从而机器便可拥有与人类一致的智能。在这个视角下,智能表现为对符号的操作(比如基于规则的推理)。符号逻辑思想之下最具代表性的实例就是专家系统。(Siri 最初就是一个专家系统。)
联结主义和统计学习阶段
联结主义学者又称为仿生学派,他们认为智力可以从大量简单的神经单元之间的联结之中涌现出来,正如生物人脑的实际情况那样。为此他们创造出一个数学模型,就是人工神经网络。但是,要如何调整这个模型,才能让它具备人类的智能而不是成为其他生物呢?这就是统计学习发挥作用的地方了。只有仿生的模型还不够,需要加以概率统计的 "操控",宛如给模型这匹野马上了一套马具。
DL(Deep Learning,深度学习)阶段
后来随着计算机科学、统计学、机器学习、深度学习、NLP 等多领域的发展和交叉融合,在 NLP 领域中诞生了 RNN(Recurrent Neural Network,循环神经网络)、LSTM(Long Short-Term Memory,长短时记忆网络)、Attention(注意力机制)等序列模型,取得了令人瞩目的成果。
PLM(Pretrain Language Model,预训练语言模型)阶段
PLM 的典型代表是 GPT-1/2、BERT 等,采用 Transformer 结构,通过在海量无监督文本上进行自监督预训练,结合在少量有监督文本上进行微调,实现了强大的自然语言理解能力。但是,PLM 仍然依赖于一定量有监督数据进行下游任务微调,且在自然语言生成任务上性能还不尽如人意,NLP 系统的性能距离人们所期待的通用人工智能还有不小的差距。
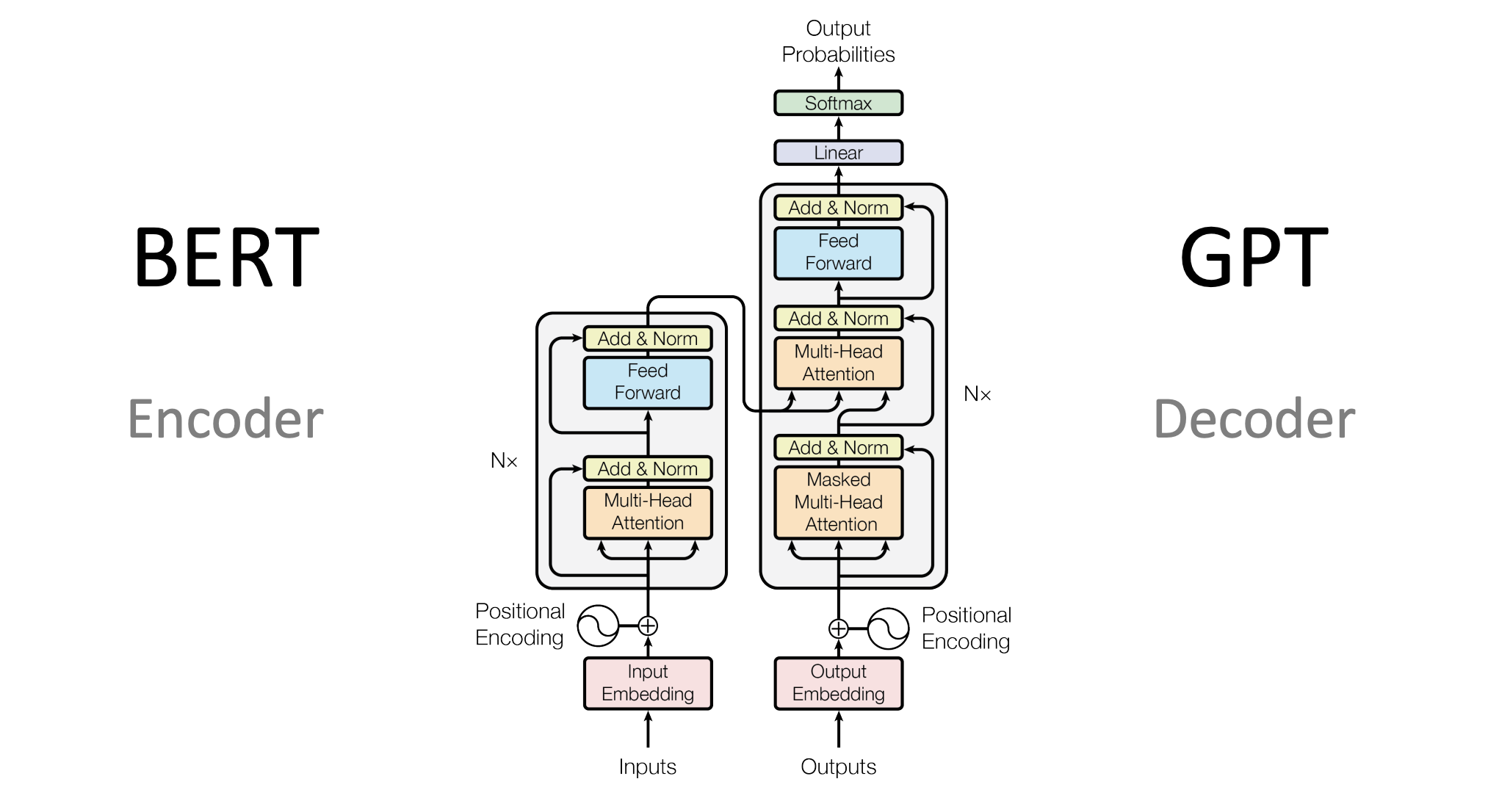
LLM(Large Language Model,大语言模型)阶段
LLM 则在 PLM 的基础之上,通过大量扩大模型参数、预训练数据规模,并引入 SFT 指令微调、RLHF 人类反馈强化学习等手段实现的突破性成果。相较于 PLM,LLM 具备了涌现能力、强大的上下文学习能力、指令理解能力和文本生成能力。在 LLM 阶段,NLP 研究者可以一定程度抛弃大量的监督数据标注工作,只需要为 SFT 提供少量监督示例。强大的指令理解能力与文本生成能力使 LLM 能够直接、高效、准确地响应用户指令,从而真正向通用人工智能的目标逼近。
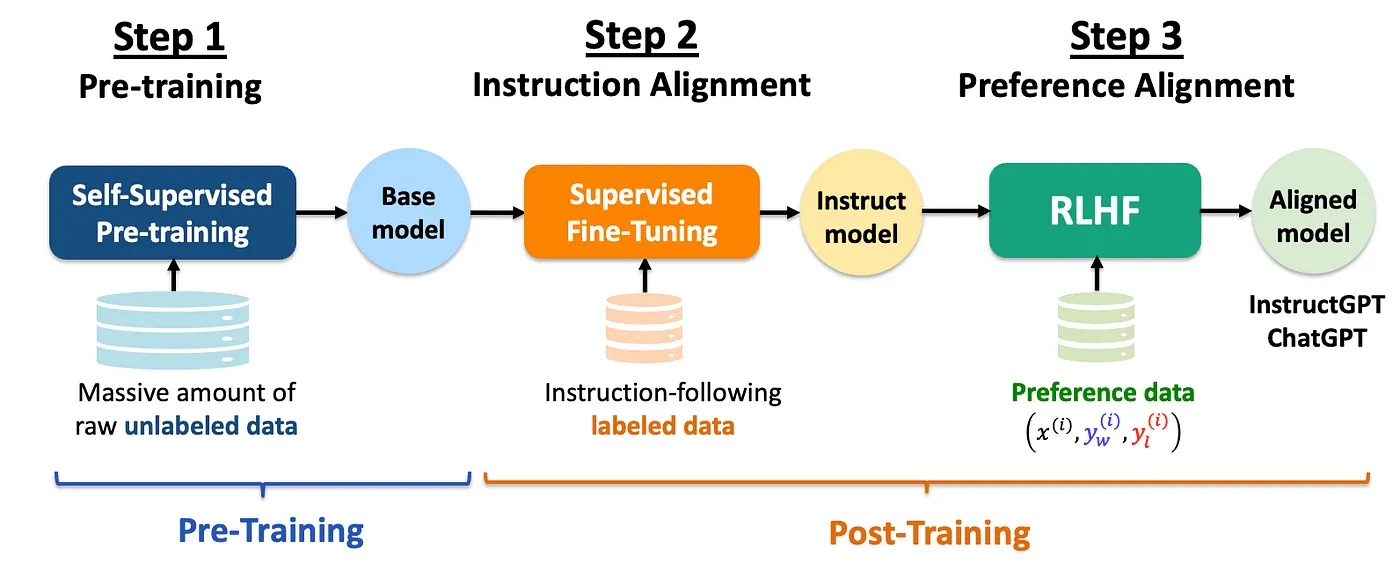
NLP 的关键任务
基础序列标注任务
中文分词
由于中文句子的词与词之间没有像英文那样的空格,所以无法直接通过空格来确定词的边界。因此,中文分词任务(Chinese Word Segmentation,CWS)是中文文本处理的基础,将连续的中文文本切分成有意义的词汇序列。
bash
英文输入:The cat sits on the mat.
英文切割输出:[The | cat | sits | on | the | mat]
中文输入:今天天气真好,适合出去游玩.
中文切割输出:["今天", "天气", "真", "好", ",", "适合", "出去", "游玩", "。"]正确的分词结果对于后续的词性标注、实体识别等任务都很重要。如果分词不准确,将直接影响到整个文本处理的效果。
bash
输入:雍和宫的荷花开的很好。
正确切割:雍和宫 | 的 | 荷花 | 开 | 的 | 很 | 好 | 。
错误切割 1:雍 | 和 | 宫的 | 荷花 | 开的 | 很好 | 。 (地名被拆散)
错误切割 2:雍和 | 宫 | 的荷 | 花开 | 的很 | 好。 (词汇边界混乱)子词切分
对于特别长尾的生僻词或未见过的新词,模型很可能不认识,此时需要应用子词切分(Subword Segmentation)技术来进行 "猜测"。子词切分将词汇进一步分解为更小的单位,即子词,模型通过已知的子词单位来理解或生成生僻词或新词,比如英文中的词根词缀法。子词切分对于那些拼写复杂、合成词多的语言(如德语)或者在 PLM(如 BERT、GPT)中尤为重要。
bash
输入:unhappiness
不使用子词切分:整个单词作为一个单位,输出:"unhappiness"
使用子词切分(假设 BPE 算法):单词被分割为:"un"、"happi"、"ness"子词切分的方法有很多,如:BPE(Byte Pair Encoding)、WordPiece、Unigram、SentencePiece 等。如上,基本思想是将单词分解成更小的、频繁出现的片段,这些片段可以是单个字符、字符组合或者词根和词缀。即使模型从未见过 unhappiness 这个完整的单词,它也可以通过这些已知的子词来理解其大致意思为 "不幸福的状态"。
词性标注
词性标注(Part-of-Speech Tagging)的目标是为文本中的每个单词分配一个词性标签,如:名词、动词、形容词等。词性标注对于理解句子结构、进行句法分析、语义角色标注等高级 NLP 任务至关重要。
词性标注通常依赖于机器学习模型,如 RNN 和 LSTM 等。词性标注基于预先定义的词性标签集,如英文中的常见标签有名词(Noun,N)、动词(Verb,V)、形容词(Adjective,Adj)等。这些模型通过学习大量的标注数据来预测新句子中每个单词的词性。
通过词性标注,计算机可以更好地理解文本的含义,进而进行信息提取、情感分析、机器翻译等更复杂的处理。
bash
英文句子:She is playing the guitar in the park.
词性标注的结果如下:
She (代词,Pronoun,PRP)
is (动词,Verb,VBZ)
playing (动词的现在分词,Verb,VBG)
the (限定词,Determiner,DT)
guitar (名词,Noun,NN)
in (介词,Preposition,IN)
the (限定词,Determiner,DT)
park (名词,Noun,NN)
. (标点,Punctuation,.)实体识别
文本中的实体包括:人物、物品、事件、地方等等。实体识别(Named Entity Recognition)旨在自动识别文本中具有特定意义的实体,然后将它们分类为预定义的类别,如:人名、地点、组织、日期、时间等。
bash
输入:李雷和韩梅梅是北京市海淀区的居民,他们计划在2024年4月7日去上海旅行。
输出:[("李雷", "人名"), ("韩梅梅", "人名"), ("北京市海淀区", "地名"), ("2024年4月7日", "日期"), ("上海", "地名")]通过实体识别任务,我们不仅能识别出文本中的实体,还能了解它们的类别,为深入理解文本内容和上下文提供了重要信息。
关系抽取
关系抽取(Relation Extraction)可以在实体识别的基础之上继续识别实体之间的语义关系,比如:因果关系、拥有关系、亲属关系、地理位置关系等。
bash
输入:比尔·盖茨是微软公司的创始人。
输出:[("比尔·盖茨", "创始人", "微软公司")]关系抽取对于理解文本内容、构建知识图谱、提升机器理解语言的能力等方面具有重要意义。通过关系抽取,我们可以从文本中提取出有用的信息,帮助计算机更好地理解文本内容,为后续的知识图谱构建、问答系统等任务提供支持。
文本分类
文本分类(Text Classification)可以将给定的文本自动分配到一个或多个预定义的类别中。应用场景广泛,例如:情感分析、垃圾邮件检测、新闻分类、主题识别等。
bash
将新闻文章分类为 "体育"、"政治" 或 "科技" 三个类别之一。
文本:"NBA季后赛将于下周开始,湖人和勇士将在首轮对决。"
类别:"体育"
文本:"美国总统宣布将提高关税,引发国际贸易争端。"
类别:"政治"
文本:"苹果公司发布了新款 Macbook,配备了最新的m3芯片。"
类别:"科技"文本分类的关键在于理解文本的含义和上下文,并基于此将文本映射到特定的类别。随着深度学习技术的发展,使用神经网络进行文本分类已经成为一种趋势,它们能够捕捉到文本数据中的复杂模式和语义信息,从而在许多任务中取得了显著的性能提升。
文本摘要
文本摘要(Text Summarization)就是根据文本内容生成一段简洁准确的摘要,来概括原文的主要内容。文本摘要可以分为两大类:
- 抽取式摘要(Extractive Summarization):通过直接从原文中选取关键句子或短语来组成摘要。优点是摘要中的信息完全来自原文,因此准确性较高。然而,由于仅仅是原文中句子的拼接,有时候生成的摘要可能不够流畅。
- 生成式摘要(Abstractive Summarization):不仅涉及选择文本片段,还需要对这些片段进行重新组织和改写,并生成新的内容。生成式摘要更具挑战性,因为它需要理解文本的深层含义,并能够以新的方式表达相同的信息。生成式摘要通常需要更复杂的模型,如基于 Attention 的 Seq2Seq 模型。
bash
2021年5月22日,国家航天局宣布,我国自主研发的火星探测器"天问一号"成功在火星表面着陆。此次任务的成功,标志着我国在深空探测领域迈出了重要一步。"天问一号"搭载了多种科学仪器,将在火星表面进行为期90个火星日的科学探测工作,旨在研究火星地质结构、气候条件以及寻找生命存在的可能性。
抽取式摘要:我国自主研发的火星探测器"天问一号"成功在火星表面着陆,标志着我国在深空探测领域迈出了重要一步。
生成式摘要:"天问一号"探测器成功实现火星着陆,代表我国在宇宙探索中取得重大进展。文本摘要任务在信息检索、新闻推送、报告生成等领域有着广泛的应用。通过自动摘要,用户可以快速获取文本的核心信息,节省阅读时间,提高信息处理效率。
机器翻译
机器翻译(Machine Translation)不仅涉及到词汇的直接转换,更重要的是要准确传达源语言文本的语义、风格和文化背景等,使得翻译结果在目标语言中自然、准确、流畅。
bash
源语言:今天天气很好。
目标语言:The weather is very nice today.机器翻译的关键在于处理更长、更复杂的文本时,会面临长序列记忆难题的挑战。现如今基于神经网络的 Seq2Seq 模型、 Transformer 模型等已经能够学习到源语言和目标语言之间的复杂映射关系,从而实现更加准确和流畅的翻译。
自动问答
自动问答(Automatic Question Answering,Q&A)的关键在于能够理解提问人的真实意图,并根据给定的数据源自动提供准确的答案。自动问答涵盖了从简单的事实查询到复杂的推理和解释,通常涉及 NLP 的多个关键人物,例如:信息检索、文本理解、知识表示和推理等。
自动问答大致可分为三类:
- 检索式问答(Retrieval-based QA):通过搜索引擎等方式从大量文本中检索答案。
- 知识库问答(Knowledge-based QA):通过结构化的知识库来回答问题。
- 社区问答(Community-based QA):依赖于用户生成的问答数据,如问答社区、论坛等。
自动问答系统的开发和优化是一个持续的过程,随着技术的进步和算法的改进,这些系统在准确性、理解能力和应用范围上都有显著的提升。通过结合不同类型的数据源和技术方法,自动问答系统正变得越来越智能,越来越能够处理复杂和多样化的问题。
NLP 文本表示方法
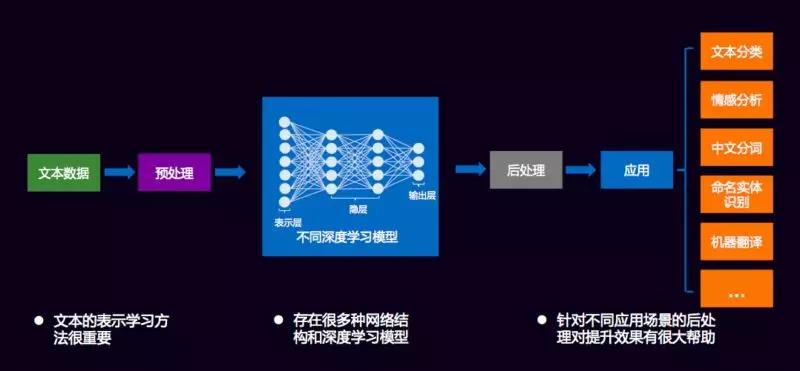
上述 NLP 关键任务的底层支撑之一就是 NLP 文本表示,指将自然语言文本内容转化为计算机可以处理的数据格式,目的是让文本的分析和处理更高效。它直接决定了 NLP 系统的质量和性能。
更具体而言,文本表示涉及到将文本中的语言单位(字、词、短语、句子等)以及它们之间的关系和结构信息转换为计算机能够理解和操作的形式,例如:向量、矩阵或其他数据结构。文本表示不仅仅需要保留足够的语义信息以便于后续的 NLP 任务,如文本分类、情感分析、机器翻译等,还需要考虑计算效率和存储效率。

VSM 文本向量化表示法
向量空间模型(Vector Space Model,VSM)是一种经典的 NLP 文本表示方法,其核心思想就是将文本转化为高维向量空间中的向量,继而通过比较向量之间的相似度来评估文本之间相关性。这些文本的类型包括:字、词、短语、句子、段落、整个文档、Query 查询等等。如下图所示,doc1、doc2 和 query 之间的距离表示了它们之间的相关程度。
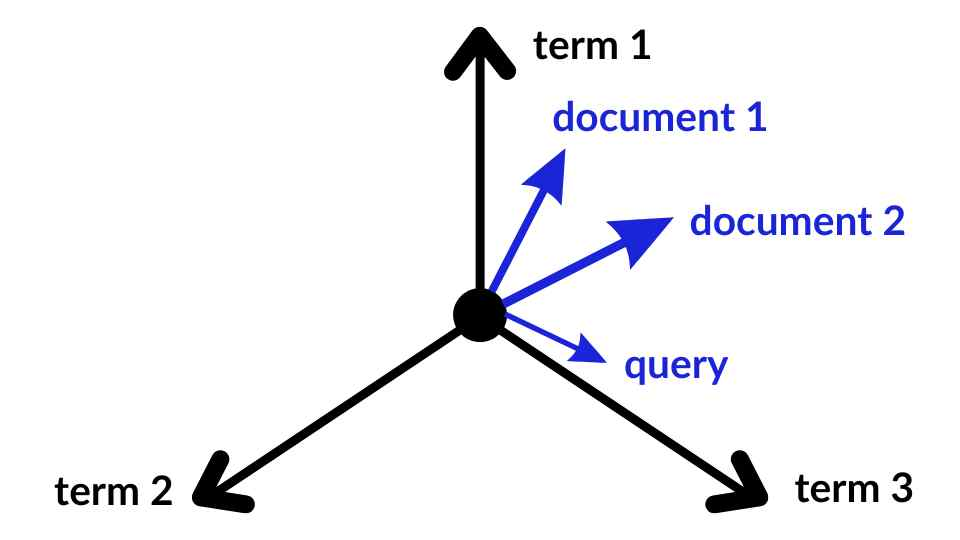
VSM 的核心流程包括 "构建向量空间、计算维度权重和评估相似度" 这三步。
- 构建向量空间:高维向量空间中的每一个维度都是一个词语,抽象化的称为特征项(term)。所以向量空间的维度由词汇表来决定,词汇表是一个基于分词技术的词语集合,包含所有可能出现的词语。该场景中 "空间维数 = 词汇表大小"。例如:如果词汇表大小为 16384 ,那么一个词向量都会被表示为一个长度为 16384 的数组,其中只有该词对应的位置为 1,其他位置都为 0。同理,下面是一个句子向量的例子。文档向量也类似。
bash
句子:"雍和宫的荷花很美"
词汇表大小:16384
句子向量包含 5 个词:["雍和宫", "的", "荷花", "很", "美"]
词向量 = [0, 0, ..., 1, 0, ..., 1, 0, ..., 1, 0, ..., 1, 0, ..., 1, 0, ...]
↑ ↑ ↑ ↑ ↑
实际有效维度:仅 5 维(非零维度),16384 维中只有 5 个位置为 1,其余 16379 个位置为 0。
数据稀疏率:(16384-5)/16384 ≈ 99.97%- 计算维度权重:权重计算的主体是(词、句子或文章)向量中每个有效词语的权重。常用算法有 TF-IDF、BM25 等,可以简单理解为词语出现次数越多权重就越高,反映了某个词语在句子中的重要程度。所以在第一步有了词位置向量之后,会再使用词权重值替换得到词权重向量。
bash
句子向量包含 5 个词:["雍和宫", "的", "荷花", "很", "美"]
词位置向量 = [0, 0, ..., 1, 0, ..., 1, 0, ..., 1, 0, ..., 1, 0, ..., 1, 0, ...]
词权重向量 = [0, 0, ..., 0.1, 0, ..., 0.2, 0, ..., 0.3, 0, ..., 0.4, 0, ..., 0.5, 0, ...]
- 评估相似度 :向量之间的相似度的几何数学含义就是 "距离"。常用的相似度算法有余弦相似度、欧氏距离、杰卡德系数等。
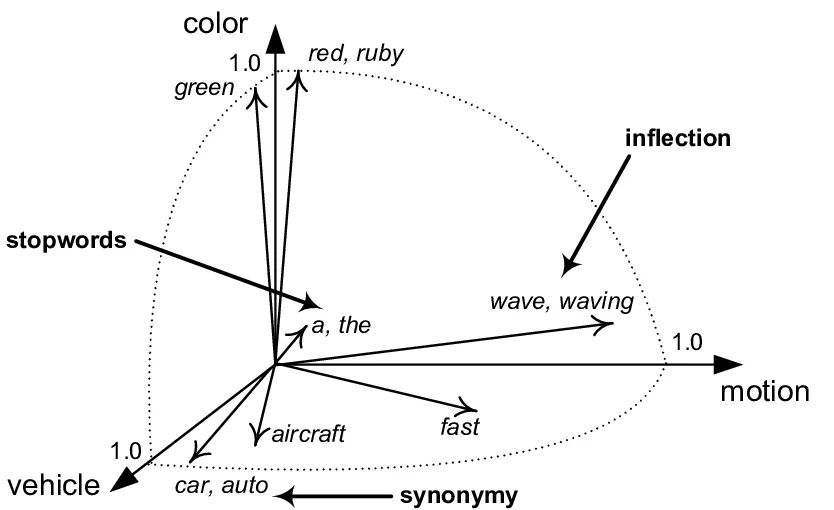
其中,余弦相似度 cosθ 的 θ 为两向量间夹角,值∈0,1,越接近 1 则越相似。
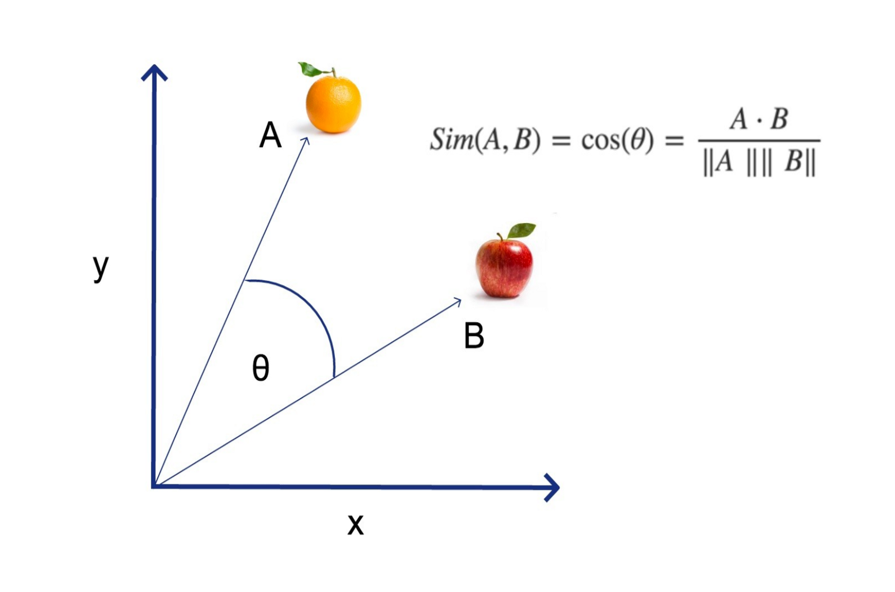
可见,VSM 非常适用于文本相似度计算、文本分类、信息检索等 NLP 任务。它将复杂的文本数据转换为易于计算和分析的数学形式,使得文本的相似度计算和模式识别成为可能。
然而,VSM 也存在很多问题。其中最主要的是数据稀疏性和维数灾难问题,因为特征项数量庞大导致向量维度极高,同时大多数元素的值为零。此外,由于模型基于特征项之间的独立性假设,忽略了文本中的结构信息,比如词序和上下文信息等,这也限制了模型的表现力。特征项的选择和权重计算方法的不足也是 VSM 需要解决的问题。
Word2Vec 文本词嵌入化表示法
2013 年,Google 提出 Word2Vec 模型开创了文本向量化表示的新时代,为 NLP 任务提供了更加有效的文本表示方法。
VSM 开创了通过向量来进行文本表示的先河,是后来 Word2Vec、GloVe 等众多 Word Embedding(词嵌入)技术的基础。就 Word2Vec 而言,它相较于 VSM 有 2 个关键改进:
- Word2Vec 解决了 VSM 无法理解语义的问题 :VSM 词向量只有权重信息,而没有语义信息。而 Word2Vec 的语义理解能力基于一个哲学思想:词的上下文环境决定了词的意义!所以在 Word2Vec 训练词向量的时候,是通过中心词的上下文词来计算出中心词向量的,因而这样的词向量也具有了上下文的语义信息。这对 NLP 推理场景非常重要。
- Word2Vec 解决了 VSM 高维稀疏向量的问题:VSM 词向量是高维稀疏的(维度 = 词汇表大小),存储和计算效率较低。而 Word2Vec 能够生成一个低维的高密度向量。
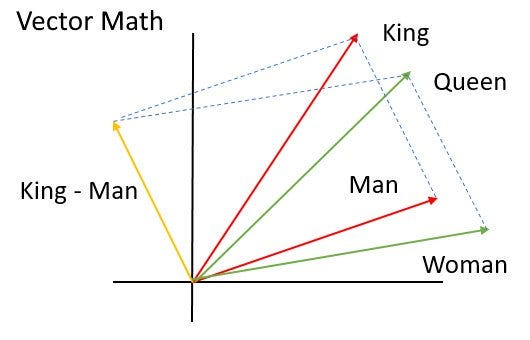
Word2Vec 是一种词嵌入(Word Embedding)技术,用于词汇表中的每个词语映射到一个词向量,这个词向量还能够包含词语的语义信息,且这个语义是上下文决定的。在空间几何表述中,语义相近的词(例如 "苹果" 和 "香蕉")对应的向量在空间中的距离也更近。因为在大量文本中,它们通常会出现在相似的上下文中。下面是一些具体的例子。


在具体实现层面,Word2Vec 是一个 AI 模型。Google 通过大规模的语料训练出了 {词: 向量} 的映射规则,再基于这个规则完成 "词→向量" 的映射,最终产出体现为一个词汇表。这就是 Word to Vector 的含义。
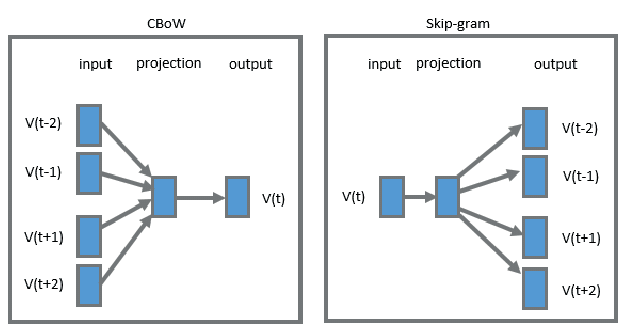
训练阶段:Word2Vec 模型在训练阶段要产出一个词汇表,里面记录了每个词的向量。Word2Vec 利用 "中心词" 在文本中的 "上下文词" 来学习到上下文的语义关系,使得语义相似的词在向量空间中距离较近。具体而言,Word2Vec 提供了 2 种训练方式。
- CBOW(Continuous Bag of Words,连续词袋模型) :用 "上下文词" 预测 "中心词"。适用于小型数据集。
- 逻辑:给定一个中心词的上下文,比如 "我吃 __ 很开心" 中的 "我、吃、很、开心",然后模型学习调整向量,让这些上下文词的向量能精准预测中心词 "苹果"。
- 结果:模型预测收敛后,语义相近的词,比如 "苹果" 和 "香蕉",因两者上下文分布相似,最终对应的向量在高维空间中距离也近。
- Skip-Gram(跳字模型) :与 CBOW 相反,用 "中心词" 预测 "上下文词"。在大型数据集中表现更好。
- 逻辑:给定中心词 "苹果",模型学习调整向量,让这个词的向量能精准预测其上下文 "我、吃、很、开心"。
- 结果:同样让语义相关的词拥有相似向量,如 "电脑" 和 "计算机"。
上述 2 种方式最终都会输出一个词汇表字典,包含了 {词: 向量} 的映射关系,词向量的每一维数值都是 Word2Vec 模型训练后得到的最优值,表征该词的语义特征。并且,相较于 VSM 的高维稀疏向量(维度 = 词汇表大小,One-Hot 编码),Word2Vec 生成的是低维稠密向量(通常几百维),有助于减少计算复杂度和存储需求。
同时,Word2Vec 模型也可以很好的泛化到未见过的词,因为它是基于上下文信息学习的,而不是基于传统词典。但由于 CBOW 和 Skip-Gram 模型是基于局部上下文的,无法捕捉到长距离的依赖关系,缺乏整体的词与词之间的关系,因此在一些复杂的语义任务上表现不佳。
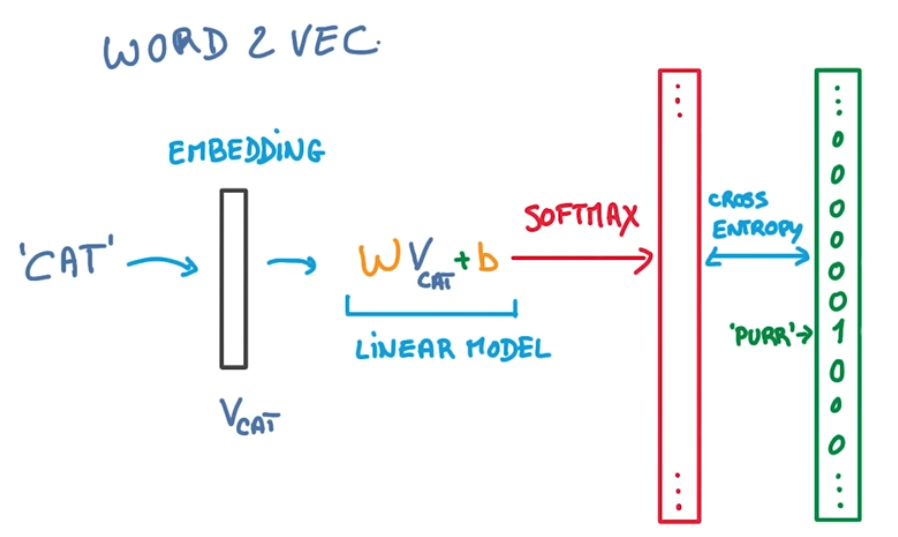
如下图所示,是一个 Skip-gram 模型的核心训练流程:
- 输入中心词:CAT
- 预测上下文词:PURR(猫发出的咕噜声)
- 嵌入层(Embedding):基于词汇表,将 CAT 转化为词向量 V_cat。
- 线性变换层:由权重矩阵 W 和偏置项 b 组成,计算得到一个 中间向量矩阵 W·V_cat + b。这个中间向量矩阵的维度等于整个词汇表的大小,每一维对应词汇表中一个词的 "预测得分"。
- Softmax 层:使用 Softmax 激活函数,将 "预测得分" 转化为概率分布(所有维度的概率和为 1)。表示以 CAT 为中心词时,词汇表中每个词作为其上下文词的概率。
- Loss 计算:红色框是 Softmax 输出的词汇表上下文概率分布预测值向量;绿色框是 PURR 的 One-Hot(独热)向量,只有对应 PURR 的位置是 1(必然出现),其余是 0,表示 PURR 是 CAT 的上下文词的真实值。同规格预测值和真实值求得 Loss 之后反向传播更新权重。使用交叉熵损失算法(Cross Entropy)来计算 Loss。
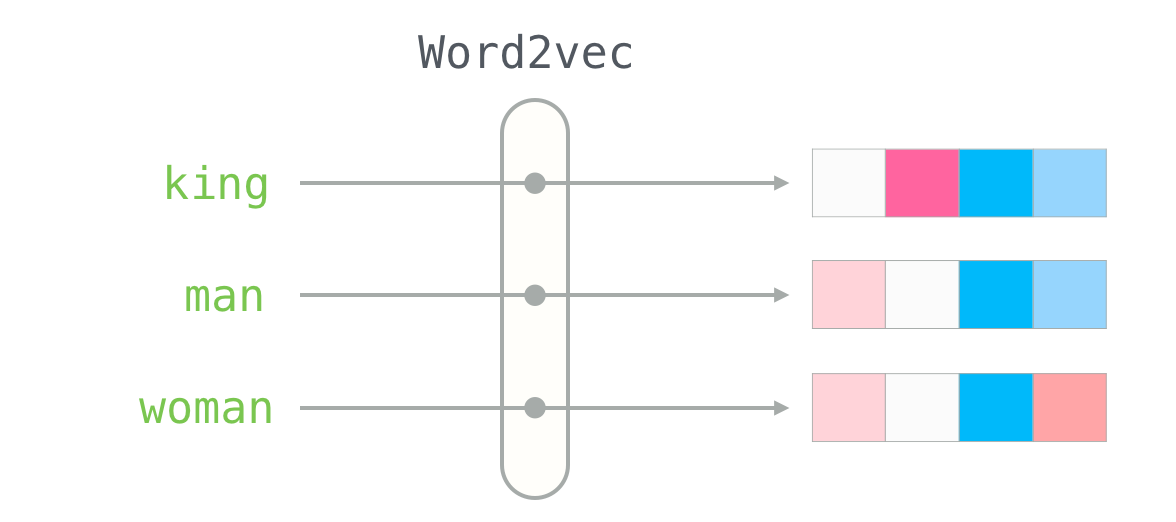
转换阶段:训练完成后,把单个词转为向量的过程极其简单。
- 若该词在训练好的词汇表中:直接从字典中取出对应的向量,比如查 "苹果",就返回训练好的 300 维数组。
- 若该词不在词汇表中:无现成向量,所以只能通过 "字符级向量拼接"、"相近词替换" 等方式近似,或者直接返回全 0 向量(无语义意义)。
值得一提的是,Work2Vec 有一个有趣的发现,就是可以使用向量运算来 "推理" 单词。例如:man 和 woman 的相对距离非常类似于 king 和 queen 的相对距离。big 和 biggest 的相对距离非常类似于 small 和 smallest 的相对距离。