文章目录
- 一、提出背景
- [二、GRPO 的算法缺陷](#二、GRPO 的算法缺陷)
-
- [2.1 优势估计的局限性](#2.1 优势估计的局限性)
- [2.2 裁剪机制的副作用](#2.2 裁剪机制的副作用)
- [2.3 token-level 重要性采样的缺陷](#2.3 token-level 重要性采样的缺陷)
- [2.4 本质:优化目标的单位与奖励的单位不匹配](#2.4 本质:优化目标的单位与奖励的单位不匹配)
- [三、GSPO 算法原理](#三、GSPO 算法原理)
-
- [3.1 Sequence-level 优化目标](#3.1 Sequence-level 优化目标)
- [3.2 Sequence-level 裁剪机制](#3.2 Sequence-level 裁剪机制)
- [3.3 梯度对比(GSPO vs GRPO)](#3.3 梯度对比(GSPO vs GRPO))
- [3.4 GSPO 的 token 级表达](#3.4 GSPO 的 token 级表达)
- [四、GSPO 在 MoE 模型中的应用](#四、GSPO 在 MoE 模型中的应用)
-
- [4.1 为什么 GRPO 在 MoE 架构中难以收敛?](#4.1 为什么 GRPO 在 MoE 架构中难以收敛?)
- [4.2 Routing Replay:让旧网络"重来一次"](#4.2 Routing Replay:让旧网络“重来一次”)
- [4.3 GSPO 的优势](#4.3 GSPO 的优势)
- 五、小结
一、提出背景
强化学习(RL)在大规模语言模型的训练中逐渐成为关键技术,但随着模型规模的扩大和任务复杂度的增加,现有算法(如GRPO )常常在训练过程中出现稳定性问题 ,特别是在长响应生成时。这是因为GRPO依赖于token级别的奖励和重要性比率,在长序列中容易导致噪声累积,进而引发模型崩溃。
为了解决这一问题,Qwen团队 提出了 GSPO(Group Sequence Policy Optimization) 。GSPO通过采用序列级别的优化 ,引入基于序列似然的稳定重要性比率,解决了GRPO在长响应训练中的不稳定性问题。
GSPO的创新点
- 序列级别的重要性比率定义:GSPO计算整个响应的序列似然比率进行优化,而非基于token级别的重要性比率,从而避免了GRPO在长序列中产生的噪声积累。
- 序列级别的裁剪与奖励优化:GSPO对整个响应进行裁剪和奖励优化,确保了训练的稳定性和效率,避免了token级别裁剪带来的不稳定问题。
二、GRPO 的算法缺陷
在阅读以下内容之前,请确保你已经掌握了 GRPO 以及 重要性采样 等相关原理。
推荐阅读:【强化学习】深度解析 GRPO:从原理到实践的全攻略
这里直接引用 GRPO 的目标函数(忽略与讨论内容无关的KL散度项):
J GRPO ( θ ) = E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ old ( ⋅ ∣ q ) 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ min ( r i , t ( θ ) A \^ i , t , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A \^ i , t ) \mathcal{J}{\text{GRPO}}(\theta) = \mathbb{E}{(q,a) \sim \mathcal{D}, \{o_i\}{i=1}^G \sim \pi{\theta_{\text{old}}}(\cdot | q)}\left \\textcolor{blue}{\\frac{1}{G} \\sum_{i=1}\^G \\frac{1}{\|o_i\|} \\sum_{t=1}\^{\|o_i\|}} \\min \\left(r_{i,t}(\\theta) \\hat{A}_{i,t}, \\text{clip} \\left(r_{i,t}(\\theta), 1-\\epsilon, 1+\\epsilon \\right) \\hat{A}_{i,t} \\right) \\right JGRPO(θ)=E(q,a)∼D,{oi}i=1G∼πθold(⋅∣q) G1i=1∑G∣oi∣1t=1∑∣oi∣min(ri,t(θ)A^i,t,clip(ri,t(θ),1−ϵ,1+ϵ)A^i,t)
其中:
-
重要性采样比 r i , t ( θ ) r_{i,t}(\theta) ri,t(θ) 定义为:
r i , t ( θ ) = π θ ( o i , t ∣ q , o i , < t ) π θ old ( o i , t ∣ q , o i , < t ) r_{i,t}(\theta) = \frac{\pi_{\theta}(o_{i,t} \mid q, o_{i,<t})}{\pi_{\theta_{\text{old}}}(o_{i,t} \mid q, o_{i,<t})} ri,t(θ)=πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)
表示当前策略 π θ \pi_{\theta} πθ 与旧策略 π θ old \pi_{\theta_{\text{old}}} πθold 之间的 token-level 概率比值。
-
优势估计 A ^ i , t \hat{A}_{i,t} A^i,t 定义为:
A ^ i , t = R i − mean ( { R i } i = 1 G ) std ( { R i } i = 1 G ) \hat{A}{i,t} = \frac{R_i - \text{mean}(\{R_i\}{i=1}^G)}{\text{std}(\{R_i\}_{i=1}^G)} A^i,t=std({Ri}i=1G)Ri−mean({Ri}i=1G)表示对于第 i i i 个输出的第 t t t 个 token 的优势估计 。 mean ( { R i } ) \text{mean}(\{R_i\}) mean({Ri}) 和 std ( { R i } ) \text{std}(\{R_i\}) std({Ri}) 是所有输出的奖励的均值和标准差。标准化处理消除了不同响应之间奖励尺度的差异,确保了各个输出的奖励在相同的尺度上进行比较。
2.1 优势估计的局限性
从 A ^ i , t \hat{A}_{i,t} A^i,t 的公式中可以看出,它是与变量 t t t 无关的。因此有:
∀ t ∈ { 1 , 2 , ⋯ , ∣ o i ∣ } , A ^ i , t = A ^ i = R i − mean ( { R i } i = 1 G ) std ( { R i } i = 1 G ) \forall t \in \{1, 2, \cdots, |o_i|\}, \quad \hat{A}{i,t} = \hat{A}{i} = \frac{R_i - \text{mean}(\{R_i\}{i=1}^G)}{\text{std}(\{R_i\}{i=1}^G)} ∀t∈{1,2,⋯,∣oi∣},A^i,t=A^i=std({Ri}i=1G)Ri−mean({Ri}i=1G)
这意味着 o i o_i oi 中的所有 token 共享相同的优势 A ^ i \hat{A}_{i} A^i 。这种设计使得 token-level 的优化目标变得冗余,没有充分利用每个 token 的独立信息。当响应长度增加时,token 之间的依赖关系变得更加复杂,简单地使用相同的优势估计来优化每个 token 显然不足以捕捉每个 token 在整体响应中的不同影响。这会导致模型无法准确地学习每个 token 对最终输出的贡献,进而降低训练效率和稳定性。
2.2 裁剪机制的副作用
GRPO 使用裁剪机制来限制重要性采样比的范围,防止离线策略样本对训练的影响:
clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) \text{clip}(r_{i,t}(\theta), 1-\epsilon, 1+\epsilon) clip(ri,t(θ),1−ϵ,1+ϵ)
然而,这种裁剪机制在实际应用中也存在问题:
- 累积误差:裁剪机制虽然限制了单个 token 的重要性采样比,但这些裁剪后的值在长序列中会不断累积,导致整体训练信号的偏差。
- 过度裁剪:为了防止高方差噪声的影响,裁剪范围通常设置得较窄,这可能导致大量有用的训练信号被裁剪掉,降低训练效率。
2.3 token-level 重要性采样的缺陷
重要性采样的基本原则
通过从行为分布 π beh \pi_{\text{beh}} πbeh 中采样的样本来估计目标分布 π tar \pi_{\text{tar}} πtar 下函数 f f f 的期望:
E z ∼ π tar f ( z ) = E z ∼ π beh π tar ( z ) π beh ( z ) f ( z ) . \mathbb{E}{z \sim \pi{\text{tar}}}f(z) = \mathbb{E}{z \sim \pi{\text{beh}}} \left \\frac{\\pi_{\\text{tar}}(z)}{\\pi_{\\text{beh}}(z)} f(z) \\right. Ez∼πtarf(z)=Ez∼πbehπbeh(z)πtar(z)f(z).
这依赖于从行为分布 π beh \pi_{\text{beh}} πbeh 中采样多个样本( N ≫ 1 N \gg 1 N≫1) ,以便重要性权重 π tar ( z ) π beh ( z ) \frac{\pi_{\text{tar}}(z)}{\pi_{\text{beh}}(z)} πbeh(z)πtar(z) 能够有效地纠正分布不匹配。
GRPO 的误用
在 GRPO 中,重要性采样比 r i , t ( θ ) r_{i,t}(\theta) ri,t(θ) 是基于单个 token 的条件概率计算的:
r i , t ( θ ) = π θ ( o i , t ∣ q , o i , < t ) π θ old ( o i , t ∣ q , o i , < t ) r_{i,t}(\theta) = \frac{\pi_{\theta}(o_{i,t} \mid q, o_{i,<t})}{\pi_{\theta_{\text{old}}}(o_{i,t} \mid q, o_{i,<t})} ri,t(θ)=πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)
这个权重是基于从每个下一个token 分布 π θ old ( ⋅ ∣ q , o i , < t ) \pi_{\theta_{\text{old}}}(\cdot|q, o_{i,<t}) πθold(⋅∣q,oi,<t) 中采样的单样本 o i , t o_{i,t} oi,t ,因此它无法发挥预期的分布纠正作用。相反,这种单点估计方式更容易引入高方差的噪声。尤其是在生成长序列时,这些噪声会随着序列长度的增加而累积,并被裁剪机制进一步放大,导致训练过程不稳定,甚至可能出现不可逆的模型崩溃。
2.4 本质:优化目标的单位与奖励的单位不匹配
在 GRPO 中,尽管每个 token 都被单独计算了重要性采样比和优势估计,但奖励 R i R_i Ri 实际上是对整个序列 o i o_i oi 的评价。这就导致了一个核心问题:优化目标的单位(token 级别)与奖励的单位(序列级别)不匹配。
为什么优化目标的单位应该与奖励的单位匹配?
为了帮助更好地理解这个问题,我们可以把强化学习过程想象成一场团队接力赛。接力赛的目标是团队最终获胜(序列级奖励),而不是单个队员的个人成绩。如果教练只看每个队员的奔跑速度,并专注于提升每个队员的表现(token 级优化),那么即使某个队员跑得特别快,可能因为接力棒传递不顺利(token之间的衔接问题),团队依然无法获胜。这是因为教练忽略了获胜目标(奖励单位)是和整个团队协作(优化目标单位)紧密关联的,而不是单个队员的表现。
同样,在 RL 中,奖励是根据整个序列的评价得出的,而 GRPO 却试图在 token 级别进行归因和校正,这是荒谬而不可靠的。这种不匹配导致了训练信号的混乱,使得模型难以有效学习如何优化整个序列的输出。
三、GSPO 算法原理
3.1 Sequence-level 优化目标
为了解决上述核心问题,GSPO 放弃了 token 级别的优化目标,转向序列级别(Sequence-level) 的重要性权重和优化目标,从而确保优化目标与奖励的单位一致。
在语言生成的背景下观察到,序列级别的重要性权重 π θ ( o ∣ q ) π θ old ( o ∣ q ) \frac{\pi_\theta(o|q)}{\pi_{\theta_{\text{old}}}(o|q)} πθold(o∣q)πθ(o∣q) 具有明确的理论意义:它反映了从 π θ old ( ⋅ ∣ q ) \pi_{\theta_{\text{old}}}(\cdot|q) πθold(⋅∣q) 中采样的响应 o o o 与 π θ ( ⋅ ∣ q ) \pi_\theta(\cdot|q) πθ(⋅∣q) 的偏离程度,这与序列级奖励相匹配,并且可以作为裁剪机制的一个有意义的指标。
GSPO 序列级别的目标函数公式如下(++蓝色标记部分是和GRPO的差异,需重点关注++):
J GSPO ( θ ) = E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ old ( ⋅ ∣ q ) 1 G ∑ i = 1 G min ( s i ( θ ) A \^ i , clip ( s i ( θ ) , 1 − ϵ , 1 + ϵ ) A \^ i ) \mathcal{J}{\text{GSPO}}(\theta) = \mathbb{E}{(q,a) \sim \mathcal{D}, \{o_i\}{i=1}^G \sim \pi{\theta_{\text{old}}}(\cdot | q)}\left \\textcolor{blue}{\\frac{1}{G} \\sum_{i=1}\^G} \\min \\left(\\textcolor{blue}{s_{i}(\\theta)} \\hat{A}_{i}, \\text{clip} \\left(\\textcolor{blue}{s_{i}(\\theta)}, 1-\\epsilon, 1+\\epsilon \\right) \\hat{A}_{i} \\right) \\right JGSPO(θ)=E(q,a)∼D,{oi}i=1G∼πθold(⋅∣q)G1i=1∑Gmin(si(θ)A\^i,clip(si(θ),1−ϵ,1+ϵ)A\^i)
其中, s i ( θ ) s_i(\theta) si(θ) 表示基于序列似然的重要性比率:
s i ( θ ) = ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) ) 1 ∣ o i ∣ = exp ( 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ log π θ ( o i , t ∣ q , o i , < t ) π θ old ( o i , t ∣ q , o i , < t ) ) s_{i}(\theta) = \left( \frac{\pi_{\theta}(o_{i} \mid q)}{\pi_{\theta_{\text{old}}}(o_{i} \mid q)}\right)^{\frac{1}{|o_i|}} = \exp \left(\frac{1}{|o_i|}\sum_{t=1}^{|o_i|} \log \frac{\pi_{\theta}(o_{i,t} \mid q, o_{i,<t})}{\pi_{\theta_{\text{old}}}(o_{i,t} \mid q, o_{i,<t})} \right) si(θ)=(πθold(oi∣q)πθ(oi∣q))∣oi∣1=exp ∣oi∣1t=1∑∣oi∣logπθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)
A ^ i \widehat{A}_i A i 采用基于组的优势估计(同 GRPO):
A ^ i = R i − mean ( { R i } i = 1 G ) std ( { R i } i = 1 G ) , R i = r ( q , o i ) 表示第 i 个响应的奖励 \widehat{A}i = \frac{R_i - \text{mean}(\{R_i\}{i=1}^G)}{\text{std}(\{R_i\}_{i=1}^G)},\quad R_i = r(q, o_i)\;表示第i个响应的奖励 A i=std({Ri}i=1G)Ri−mean({Ri}i=1G),Ri=r(q,oi)表示第i个响应的奖励
通过这种方式,GSPO 避免了 GRPO 在 token 级别的优势估计问题,确保了训练信号在整个序列级别上的一致性。
3.2 Sequence-level 裁剪机制
GSPO 采用序列级裁剪 而不是 token 级裁剪,这使得优化目标与奖励的单位一致,并且能够有效地避免由于单个token的过大更新而影响整个响应的训练。
序列级裁剪的表达为:
clip ( s i ( θ ) , 1 − ϵ , 1 + ϵ ) \text{clip}(s_{i}(\theta), 1-\epsilon, 1+\epsilon) clip(si(θ),1−ϵ,1+ϵ)
- 为了避免不同长度响应的重要性比率波动过大 ,GSPO 在序列级重要性比率 s i ( θ ) s_i(\theta) si(θ) 的计算中采用了长度归一化。这减少了不同长度序列可能带来的变异性(方差),并确保了所有响应在同一个数值范围内进行处理。
- 观察到 GSPO 和 GRPO 之间的裁剪比例存在两个数量级的差异,尽管 GSPO 裁剪了更多的 token,但仍然实现了比 GRPO 更高的训练效率。

3.3 梯度对比(GSPO vs GRPO)
GSPO 目标函数的梯度(为简洁起见,省略了裁剪)
∇ θ J GSPO ( θ ) = ∇ θ E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ old ( ⋅ ∣ q ) 1 G ∑ i = 1 G s i ( θ ) A \^ i = E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ old ( ⋅ ∣ q ) 1 G ∑ i = 1 G s i ( θ ) A \^ i ⋅ ∇ θ log s i ( θ ) = E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ old ( ⋅ ∣ q ) 1 G ∑ i = 1 G ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) ) 1 ∣ o i ∣ A \^ i ⋅ 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ ∇ θ log π θ ( o i , t ∣ q , o i , \< t ) \begin{aligned} \nabla_\theta \mathcal{J}{\text{GSPO}}(\theta) & = \nabla\theta \mathbb{E}{(q, a) \sim \mathcal{D}, \{o_i\}{i=1}^G \sim \pi_{\theta_{\text{old}}}(\cdot|q)} \left \\frac{1}{G} \\sum_{i=1}\^G s_i(\\theta) \\widehat{A}_i \\right \\ & = \mathbb{E}{(q, a) \sim \mathcal{D}, \{o_i\}{i=1}^G \sim \pi_{\theta_{\text{old}}}(\cdot|q)} \left \\frac{1}{G} \\sum_{i=1}\^G s_i(\\theta) \\widehat{A}_i \\cdot \\nabla_\\theta \\log s_i(\\theta) \\right \\ & = \mathbb{E}{(q, a) \sim \mathcal{D}, \{o_i\}{i=1}^G \sim \pi_{\theta_{\text{old}}}(\cdot|q)} \left \\frac{1}{G} \\sum_{i=1}\^G \\textcolor{blue}{\\left( \\frac{\\pi_\\theta(o_i\|q)}{\\pi_{\\theta_{\\text{old}}}(o_i\|q)} \\right)\^{\\frac{1}{\|o_i\|}}} \\widehat{A}_i \\cdot \\frac{1}{\|o_i\|} \\sum_{t=1}\^{\|o_i\|} \\nabla_\\theta \\log \\pi_\\theta(o_{i,t}\|q, o_{i,\
GRPO 目标函数的梯度推导 (注意: A ^ i , t = A ^ i \widehat{A}_{i,t} = \widehat{A}_i A i,t=A i)
∇ θ J GRPO ( θ ) = ∇ θ E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ old ( ⋅ ∣ q ) 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ r i , t ( θ ) A \^ i , t = E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ old ( ⋅ ∣ q ) 1 G ∑ i = 1 G A \^ i ⋅ 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ π θ ( o i , t ∣ q , o i , \< t ) π θ old ( o i , t ∣ q , o i , \< t ) ∇ θ log π θ ( o i , t ∣ q , o i , \< t ) \begin{aligned} \nabla_\theta \mathcal{J}{\text{GRPO}}(\theta) & = \nabla\theta \mathbb{E}{(q, a) \sim \mathcal{D}, \{o_i\}{i=1}^G \sim \pi_{\theta_{\text{old}}}(\cdot|q)} \left \\frac{1}{G} \\sum_{i=1}\^G \\frac{1}{\|o_i\|} \\sum_{t=1}\^{\|o_i\|} r_{i,t}(\\theta) \\widehat{A}_{i,t} \\right \\ & = \mathbb{E}{(q,a) \sim \mathcal{D}, \{o_i\}{i=1}^G \sim \pi_{\theta_{\text{old}}}(\cdot|q)} \left \\frac{1}{G} \\sum_{i=1}\^G \\widehat{A}_i \\cdot \\frac{1}{\|o_i\|} \\sum_{t=1}\^{\|o_i\|} \\textcolor{blue}{\\frac{\\pi_\\theta(o_{i,t}\|q, o_{i,\
可见,GSPO 和 GRPO 的根本区别在于它们如何对 token 的对数似然的梯度进行加权。
- GRPO 中,token 根据其各自的"重要性权重" 进行加权 。然而,这些不等的权重在 ( 0 , 1 + ϵ ] (0, 1+\epsilon] (0,1+ϵ]( A ^ i > 0 \widehat{A}_i > 0 A i>0)或 [ 1 − ϵ , + ∞ ) [1-\epsilon, +\infty) [1−ϵ,+∞)( A ^ i < 0 \widehat{A}_i < 0 A i<0)之间变化,它们的影响会随着训练的进行而累积,导致不可预测的后果。
- GSPO 则是对所有 token 进行等权重处理,避免了 token 级别的高方差问题,使得梯度更新更加稳定。
3.4 GSPO 的 token 级表达
目标函数 (简记:把 GRPO 中的 r i , t ( θ ) r_{i,t}(\theta) ri,t(θ) 换成 s i , t ( θ ) s_{i,t}(\theta) si,t(θ) )
J GSPO-token ( θ ) = E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ old ( ⋅ ∣ q ) 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ min ( s i , t ( θ ) A \^ i , t , clip ( s i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A \^ i , t ) \mathcal{J}{\text{GSPO-token}}(\theta) = \mathbb{E}{(q,a) \sim \mathcal{D}, \{o_i\}{i=1}^G \sim \pi{\theta_{\text{old}}}(\cdot | q)}\left \\frac{1}{G} \\sum_{i=1}\^G \\frac{1}{\|o_i\|} \\sum_{t=1}\^{\|o_i\|} \\min \\left(\\textcolor{blue}{s_{i,t}(\\theta)} \\hat{A}_{i,t}, \\text{clip} \\left(\\textcolor{blue}{s_{i,t}(\\theta)}, 1-\\epsilon, 1+\\epsilon \\right) \\hat{A}_{i,t} \\right) \\right JGSPO-token(θ)=E(q,a)∼D,{oi}i=1G∼πθold(⋅∣q) G1i=1∑G∣oi∣1t=1∑∣oi∣min(si,t(θ)A^i,t,clip(si,t(θ),1−ϵ,1+ϵ)A^i,t)
其中
s i , t ( θ ) = sg s i ( θ ) ⋅ π θ ( o i , t ∣ q , o i , < t ) sg π θ ( o i , t ∣ q , o i , \< t ) \textcolor{blue}{s_{i,t}(\theta) = \text{sg}s_i(\\theta) \cdot \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\text{sg}\\pi_\\theta(o_{i,t}\|q, o_{i,\
π θ ( o i , t ∣ q , o i , < t ) sg π θ ( o i , t ∣ q , o i , \< t ) \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\text{sg}\\pi_\\theta(o_{i,t}\|q, o_{i,\
注:sg· 表示仅取数值但停止梯度传播,对应 PyTorch 中的 detach 操作
目标函数梯度:
∇ θ J GSPO-token ( θ ) = ∇ θ E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ old ( ⋅ ∣ q ) 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ s i ( θ ) A \^ i , t = E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ old ( ⋅ ∣ q ) 1 G ∑ i = 1 G s i ( θ ) ⋅ 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ A \^ i , t ∇ θ π θ ( o i , t ∣ q , o i , \< t ) π θ ( o i , t ∣ q , o i , \< t ) = E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ old ( ⋅ ∣ q ) 1 G ∑ i = 1 G ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) ) 1 ∣ o i ∣ ⋅ 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ A \^ i , t ∇ θ log π θ ( o i , t ∣ q , o i , \< t ) \begin{aligned} \nabla_\theta \mathcal{J}{\text{GSPO-token}}(\theta) & = \nabla\theta \mathbb{E}{(q, a) \sim \mathcal{D}, \{o_i\}{i=1}^G \sim \pi_{\theta_{\text{old}}}(\cdot|q)} \left \\frac{1}{G} \\sum_{i=1}\^G \\frac{1}{\|o_i\|} \\sum_{t=1}\^{\|o_i\|} s_i(\\theta) \\widehat{A}_{i,t} \\right \\ & = \mathbb{E}{(q, a) \sim \mathcal{D}, \{o_i\}{i=1}^G \sim \pi_{\theta_{\text{old}}}(\cdot|q)} \left \\frac{1}{G} \\sum_{i=1}\^G s_i(\\theta) \\cdot \\frac{1}{\|o_i\|} \\sum_{t=1}\^{\|o_i\|} \\widehat{A}_{i,t} \\frac{\\nabla_\\theta\\pi_\\theta(o_{i,t}\|q, o_{i,\
对比 ∇ θ J GSPO-token ( θ ) \nabla_\theta \mathcal{J}{\text{GSPO-token}}(\theta) ∇θJGSPO-token(θ) 和 ∇ θ J GSPO ( θ ) \nabla\theta \mathcal{J}{\text{GSPO}}(\theta) ∇θJGSPO(θ) 两个公式,代入 A ^ i , t = A ^ i \widehat{A}{i,t} = \widehat{A}_i A i,t=A i 后可见,GSPO-token 和 GSPO 在优化目标、裁剪条件和理论梯度上是数值相同的,但 GSPO-token 享有按 token 调整优势的更高灵活性。
四、GSPO 在 MoE 模型中的应用
混合专家(Mixture-of-Experts,MoE)模型通过"稀疏激活"机制,每次前向计算只用到全部参数的一小部分。这样做既扩大了模型容量,又控制了计算量,是大模型常用的扩展手段。与密集模型的 RL 训练相比,MoE 模型的稀疏激活特性引入了独特的稳定性挑战。
4.1 为什么 GRPO 在 MoE 架构中难以收敛?
专家激活的波动性 : 当 π θ old \pi_{\theta_{\text{old}}} πθold 被更新时,路由器 (router) 可能也会改变。这意味着对于相同的样本,新策略 π θ \pi_\theta πθ 与旧策略 π θ old \pi_{\theta_{\text{old}}} πθold 激活的专家可能不同,导致专家的选择发生波动。
token-level 重要性比率失效 : 理论上,重要性比率应反映由参数更新引起的概率变化,且该变化应基于相同的结构 。然而由于专家的改变,条件概率 π θ ( o i , t ∣ q , o i , < t ) \pi_\theta(o_{i,t}|q, o_{i,<t}) πθ(oi,t∣q,oi,<t) 和 π θ old ( o i , t ∣ q , o i , < t ) \pi_{\theta_{\text{old}}}(o_{i,t}|q, o_{i,<t}) πθold(oi,t∣q,oi,<t) 不再来自同一子网络。这使得计算出的 r i , t ( θ ) r_{i,t}(\theta) ri,t(θ) 不再是"同一函数"的概率比,而变成了"两个不同函数"的比值。
高方差波动的引入 :失效的 r i , t ( θ ) r_{i,t}(\theta) ri,t(θ) 导致不可预测的高方差波动,这些波动与优化方向无关。这种结构性偏差和噪声扭曲了策略梯度的估计,使得训练变得不稳定,甚至可能导致模型崩溃。
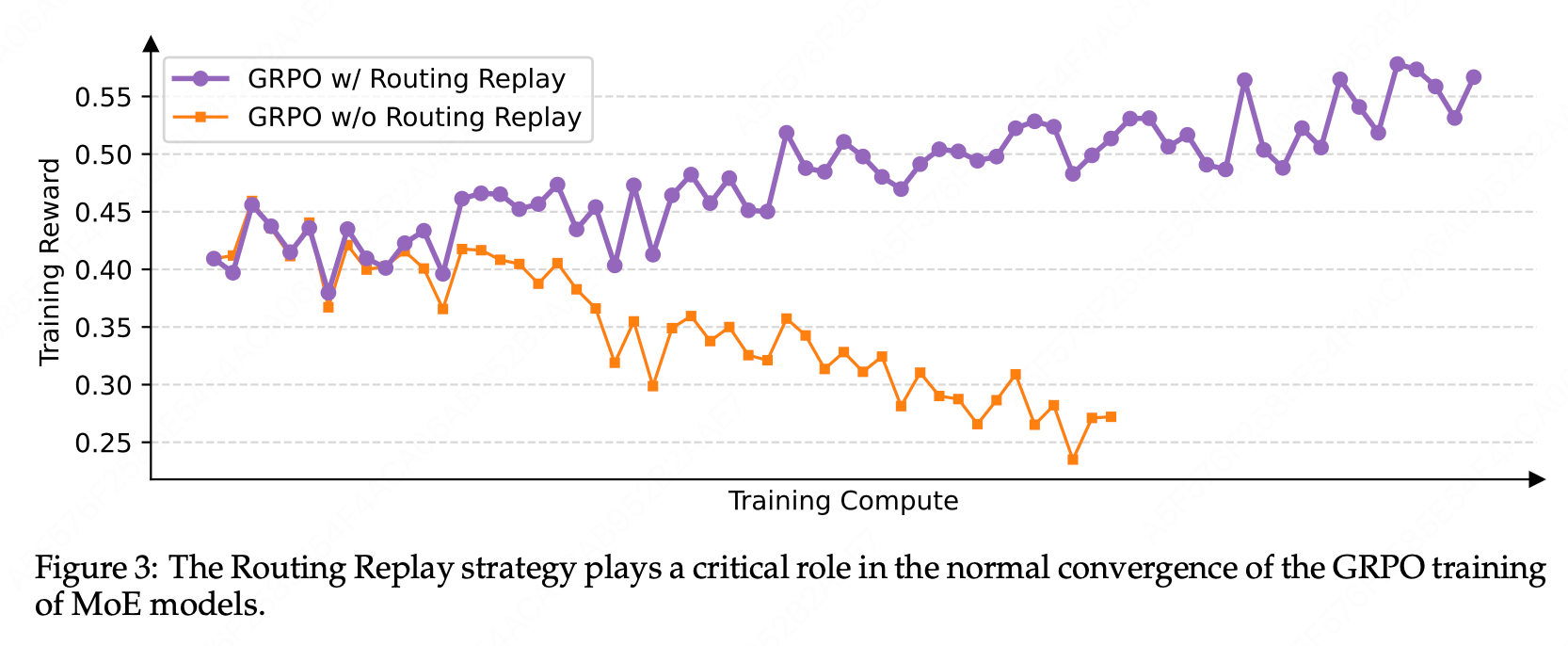
4.2 Routing Replay:让旧网络"重来一次"
为了确保 GRPO 等算法在混合专家(MoE)模型中能够稳定运行,研究者采用了 Routing Replay(路由回放)训练策略。
工作原理:
- 在从旧策略 π θ old \pi_{\theta_{\text{old}}} πθold 采样期间,记录专家的激活情况。
- 在训练新策略 π θ \pi_\theta πθ 时,强制使用与旧策略相同的路由路径。
具体而言,对于每个 token,Routing Replay 使得 π θ ( o i , t ∣ q , o i , < t ) \pi_\theta(o_{i,t}|q, o_{i,<t}) πθ(oi,t∣q,oi,<t) 和 π θ old ( o i , t ∣ q , o i , < t ) \pi_{\theta_{\text{old}}}(o_{i,t}|q, o_{i,<t}) πθold(oi,t∣q,oi,<t) 共享相同的激活网络,从而保证了 token-level 重要性比率的稳定性。
优缺点:
- 优点:有效地保持了模型在梯度更新中的稳定性。
- 缺点:增加了额外的内存和通信开销,且效率较低;同时限制了模型自由探索更优专家组合的能力。
这种策略虽有效,但仍为一种额外的"补丁",并未能完全解决模型优化的灵活性问题。
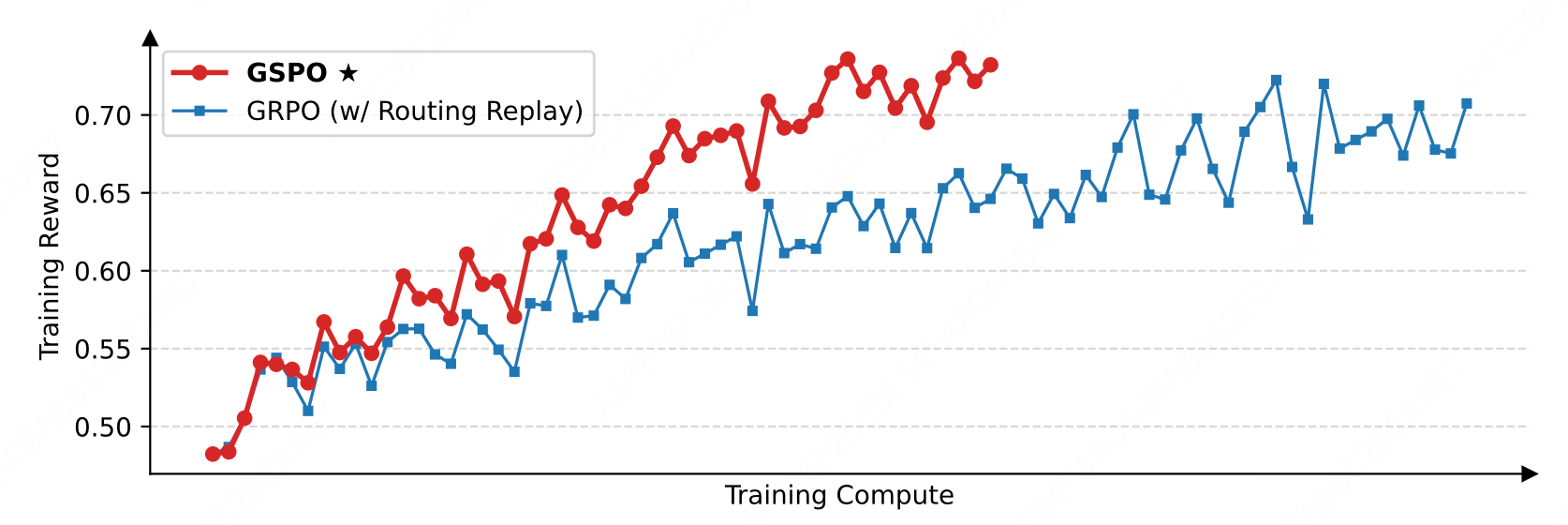
4.3 GSPO 的优势
尽管 Routing Replay 使 GRPO 训练 MoE 模型能够正常收敛,但其重用路由模式的做法也带来的许多弊端。相比之下,GSPO 通过聚焦于序列似然(即 π θ ( o i ∣ q ) \pi_\theta(o_i|q) πθ(oi∣q)),而不是单个 token 的似然(即 π θ ( o i , t ∣ q , o i , < t ) \pi_\theta(o_{i,t}|q, o_{i,<t}) πθ(oi,t∣q,oi,<t)),为 MoE 模型训练提供了以下优势:
- 提升稳定性:由于 MoE 模型始终保持着语言建模能力,序列似然不会剧烈波动,避免了专家激活的不稳定性。
- 简化训练 :消除了对 Routing Replay 的依赖,能够按照常规方式计算重要性比率 s i ( θ ) s_i(\theta) si(θ),稳定收敛并优化。
- 提高模型容量利用率:模型不受限制,可以充分发挥专家的潜力,提高模型的表达能力。
- 优化 RL 基础设施:由于训练引擎(例如 Megatron)和推理引擎(例如 SGLang 和 vLLM)之间存在精度差异,传统方法需重新计算旧策略下的似然。然而 GSPO 仅依赖序列级似然进行优化,可直接使用推理引擎的结果,避免了额外的计算工作,尤其适用于多轮强化学习和训练-推理分离的场景。
五、小结
Group Sequence Policy Optimization(GSPO)是 Qwen 团队提出的一种新型强化学习算法。遵循重要性采样的基本原则,基于序列似然定义重要性比率,并执行序列级的裁剪、奖励和优化。与 GRPO 相比,GSPO 在训练稳定性、效率和性能方面表现出显著优势,尤其在大规模训练混合专家(MoE)模型方面表现出色。