The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models
论文:https://openreview.net/forum?id=2GmDdhBdDk
代码:https://github.com/ShishirPatil/gorilla/tree/main/berkeley-function-call-leaderboard
榜单:https://gorilla.cs.berkeley.edu/leaderboard.html
- 简介
函数调用,也称为工具使用,是指大型语言模型调用外部函数、api或用户定义工具的能力,这是代理大型语言模型应用程序的基本功能。尽管它很突出,但由于两个原因,还没有一个标准的基准来评估函数调用:评估函数调用何时有效具有挑战性,以及获取各种实际函数的挑战。我们提出伯克利函数调用排行榜(BFCL),一个全面的基准,旨在评估函数调用在广泛的现实世界的设置。BFCL基准测试使用一种新颖的抽象语法树(AST)评估方法评估各种编程语言之间的串行和并行函数调用,该方法可以轻松扩展到数千个函数。我们使用专家策划和用户贡献的函数以及相关提示的组合来构建基准。最后,在有状态的多步代理设置中,BFCL基准评估了模型的弃权和推理能力。通过对各种模型的评估,我们观察到,虽然最先进的大型语言模型擅长单轮呼叫,但记忆、动态决策和长期推理仍然是开放的挑战。
数据类型
BFCL主要由四个部分组成:
- Agentic(665,权重40%):跨应用程序、数据库查询和聊天机器人上下文管理
- Web Search(200):片段(100),即含摘要等信息、无片段(100),即只有URL地址和标题。
- Memory(465):向量存储(155)、键值存储(155)、记录总和(155)
- Multi-Turn(800,权重40%):包含8个精选API套件和1000个查询,评估持续上下文管理和动态决策
- Base case(200):基础多轮(200)
- Augmented Cases(600):多轮缺失函数(200)、多轮缺失参数(200)、多轮缺失上下文(200)
- Live(1351,权重10%):由超过67000个社区贡献的真实live功能调用数据
- Simple(258):实时数据里的简单AST
- Multiple(1053):实时数据里的多个AST
- Parallel(16):实时数据里的并行AST
- Parallel Multiple(24):实时数据里的多个并行AST
- Non-Live(1150,权重10%):非实时数据里的函数调用
- Simple(550):简单Python AST(400)、简单Java AST(100)、简单Java Script AST(50)
- Multiple(200):多个 AST
- Parallel(200):并行 AST
- Parallel Multiple(200):并行多个AST
- Hallucination Measurement(1122,权重10%):幻觉识别能力测试
- Relevance(18):实时相关性
- Irrelevance(1122):非实时无关函数(240)、实时无关函数(882)
- Format Sensitivity(5200,可选项不加入权重)

细分种类: - Code
- python:特定于 Python 代码的测试
- simple_python:简单的 Python 函数调用。这是排行榜上non-live simple类别的一部分。
- non-python:测试 Python 以外的语言(例如 Java 和 JavaScript)的代码
- simple_java:简单的 Java 函数调用。这是排行榜上non-live simple类别的一部分。
- simple_javascript:简单的 JavaScript 函数调用。这是排行榜上non-live simple类别的一部分。
- python:特定于 Python 代码的测试
- non-live
- parallel:并行多个函数调用(只有单轮)
- multiple:按顺序调用多个函数(只有单轮)
- parallel_multiple:并行、按顺序调用多个函数(只有单轮)
- irrelvance:带有不相关函数调用的工具列表(只有单轮)
- live
- live_simple:用户贡献的简单函数调用(含单轮和多轮)
- live_multiple:用户按顺序贡献的多个函数调用(含单轮和多轮)
- live_parallel:用户并行贡献的多个函数调用(含单轮和多轮)
- live_parallel_multiple:用户并行和按顺序贡献的多个函数调用(只有单轮)
- live_irrelvance:用户贡献的函数调用,其中包含不相关的函数文档(含单轮和多轮)
- live_relvance:用户贡献的函数调用以及相关的函数文档(含单轮和多轮)
- Mutli_turn
- multi_turn_base:多轮函数调用的基本条目
- multi_turn_miss_func:缺少函数的多轮函数调用
- multi_turn_miss_param:缺少参数的多轮函数调用
- multi_turn_long_context:长上下文的多轮函数调用
- Agentic
- memory
- memory_vector:从向量数据库存储后端读取和写入测试
- memory_rec_sum:从递归符号存储后端读取和写入测试
- web search
- web_search_base:调用web search的基础实例
- web_search_no_snippet:调用web search搜索引擎片段被保留,迫使模型获取和读取网页
- memory
- (可选)format_sensitivity:用于依赖默认使用系统提示进行工具调用的提示模式模型,不支持原生工具调用的模型)
函数调用
https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html
● simple function:单个函数求值,包含最简单且最常见的格式,其中用户提供单个JSON函数文档。
● multiple funciton:多函数类别包含用户问题,从2-4个JSON函数文档中调用一个函数。模型需要能够根据用户提供的上下文选择调用的最佳函数。
● parallel function:根据一个用户问题,并行调用多个函数。模型需要能理解需要进行多少次函数调用,建模的问题可以使单句话或多句话。
● parallel multiple function:提供多个函数文档,每个函数调用都会调用零次或多次。
● function relevance detection:在函数相关性检测中,设计的场景中所提供的工具都与query不相关,不应该被调用。模型需要能够识别出来不调用函数,避免幻觉生成函数调用。
实时数据
https://gorilla.cs.berkeley.edu/blogs/12_bfcl_v2_live.html
根据从社区上收集到的实时数据构建的评测集。
● Irrelevance detection:在函数相关性检测中,设计的场景中所提供的工具都与query不相关,不应该被调用。模型需要能够识别出来不调用函数,避免幻觉生成函数调用。
● relevance detection: 提供的至少一个函数选项与用户查询相关,这里面的函数应该被调用。模型应该输出一些与用户查询相关的函数调用(一个或多个),我们不检查此类别中函数调用的正确性(例如,正确的参数值)。
多轮和多步函数调用
https://gorilla.cs.berkeley.edu/blogs/13_bfcl_v3_multi_turn.html
● single-turn: 在单轮交互中,助手可以通过进行一次函数调用来满足用户的请求。 这些请求通常是直接的、独立的,并且与状态无关(即,不依赖于 先前上下文)。
● multi-step: 多步骤交互需要助手执行多个内部函数调用来处理单用户请求。这个过程体现了助理主动计划和收集的能力,提供全面响应的信息。用户仅与模型交互一次(在开始阶段),然后模型与系统来回交互以完成任务。
● multi-turn: 多轮交互涉及用户和助手之间的扩展交换,包括多个对话轮次。每个回合可能涉及几个步骤,助手必须保留和利用先前交流中的上下文信息来有效处理后续查询。用户将在整个过程中与模型多次交互。
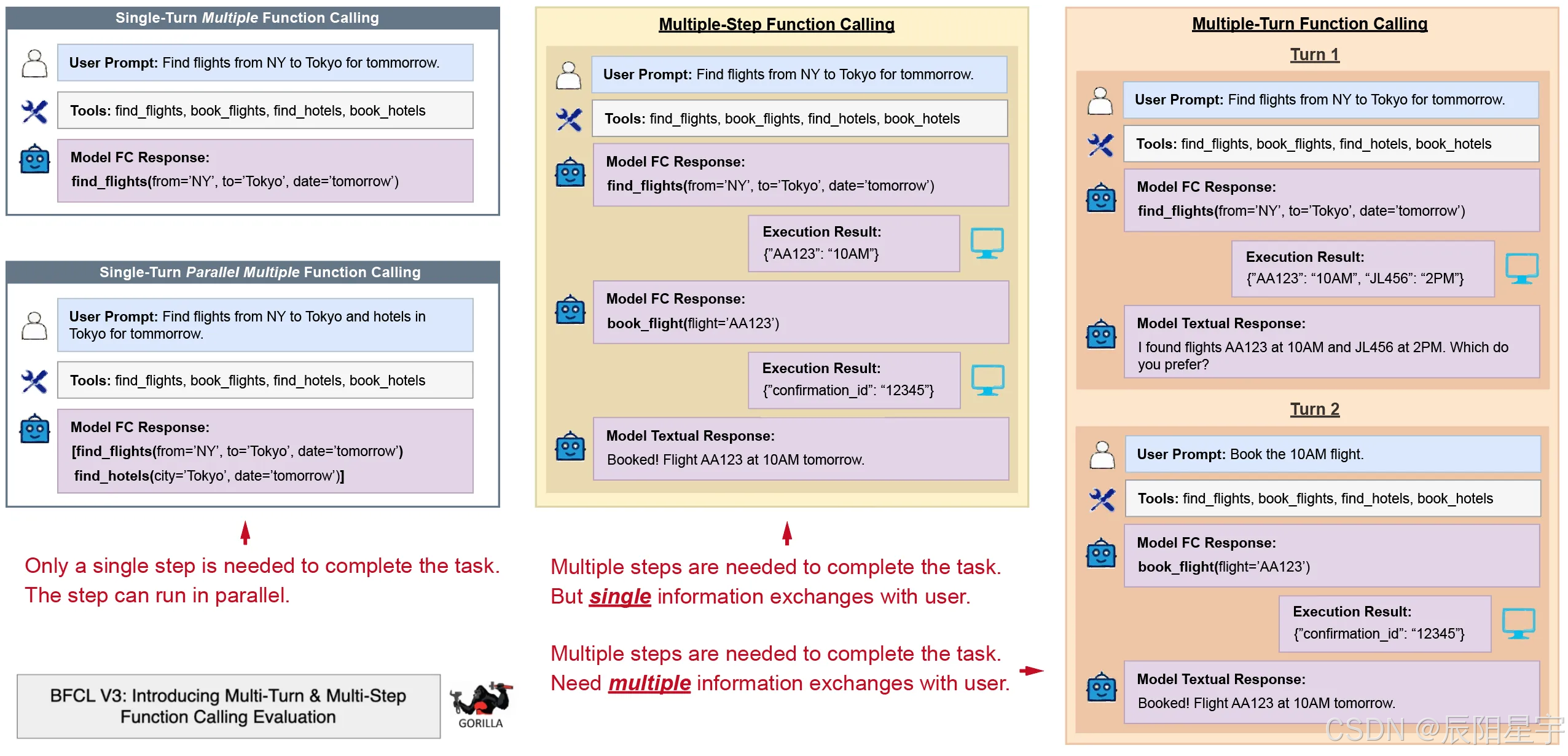
● Base multi-turn:此类别涵盖基础但足够多样化 基本的多轮交互。在此类别中,我们提供所有必要的信息------无论是来自 用户请求消息、上一轮的执行结果或探索性函数的输出------ 完成任务。该模型预计能够毫无歧义地处理多轮交互。
● augmented multi-turn:这些类别引入了额外的复杂性,例如 不明确的提示或情况 其中模型必须跨轮处理多条信息(类似于多跳 QA)。 模型必须展示更细致的决策、消歧和条件逻辑 多转。 Augmented Multi-Turn 数据集中包含以下四个子类别:
○ missing parameters: 测试模型识别必要时的能力用户请求中缺少信息,无法从系统推断出信息。在这些情况下, 模型应该要求澄清而不是做出无根据的假设。
○ missing functions: 要求模型识别没有可用的功能可以满足用户的要求。一旦模型指出了这个问题,我们就会提供缺失的函数下一个回合。 与基础数据集相比,此场景在开始时保留了一部分函数, 挑战模型推断是否需要附加功能。
○ long-context multi-turn: 挑战模型保持准确性的能力 以及在冗长、信息密集的上下文中的相关性。我们引入大量无关数据 (例如,数百个文件或数千条记录)来测试模型提取关键信息的能力 从海量的信息中获取细节。
○ composite: 结合了所有三个增强挑战 - 缺少参数、 缺失功能和长上下文------进入一个高度复杂的场景。虽然罕见,但成功在这里强烈表明该模型可以作为大规模的自主代理有效地发挥作用,即使在 复杂且苛刻的条件。

数据合成
https://gorilla.cs.berkeley.edu/blogs/13_bfcl_v3_multi_turn.html
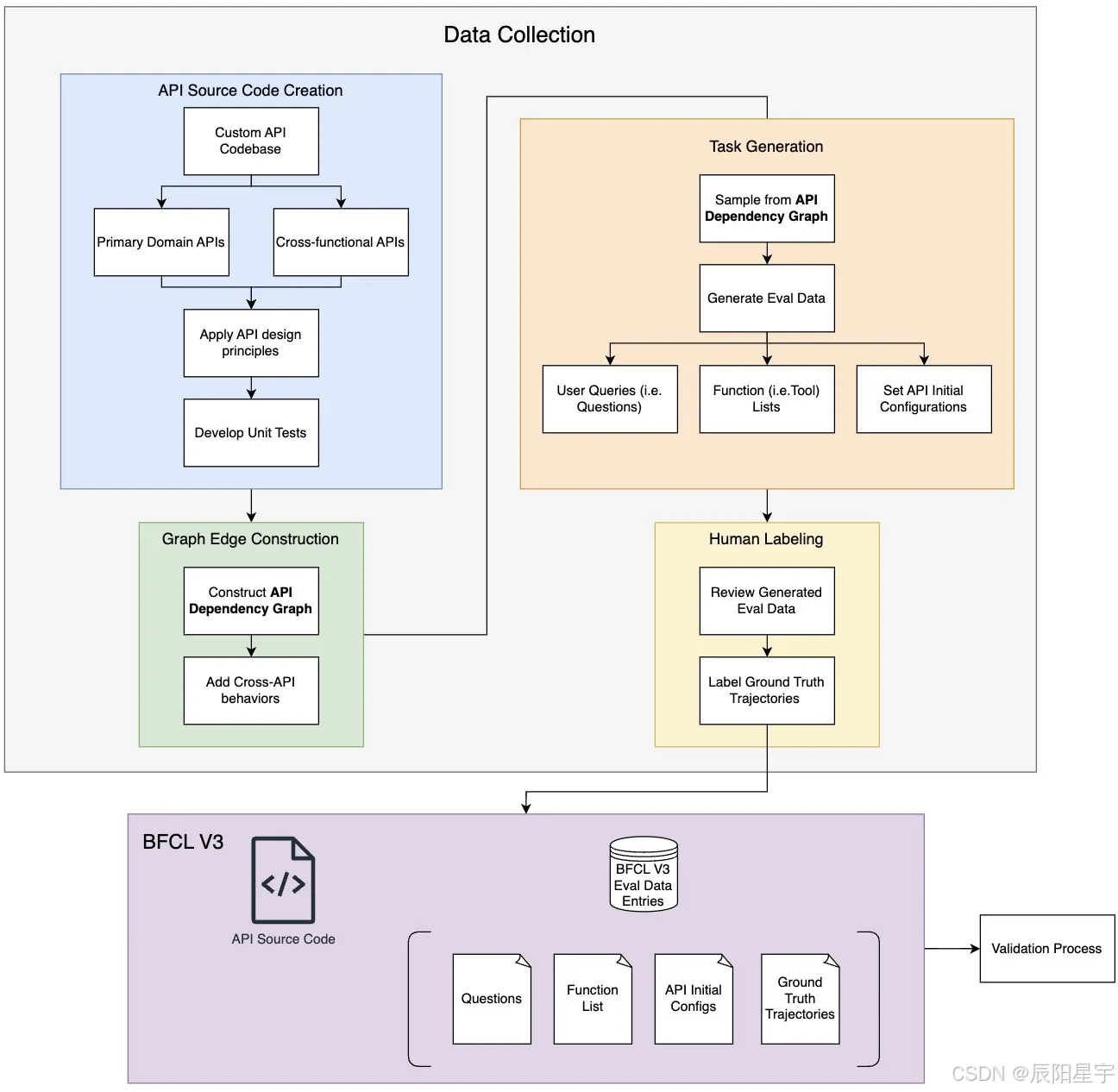
- API代码库构建
数据集始于创建受常见现实世界启发的自定义 API 代码库。这些 API 跨越八个领域(四个主要 API 和四个配套 API):
● 主领域API
○ 车辆:Vehicle Control: startEngine(...), displayCarStatus(...), estimate_distance(...)
○ 交易:Trading Bots: get_stock_info(...), place_order(...), get_watchlist(...)
○ 旅行:Travel Booking: book_flight(...), get_nearest_airport_by_city(...), purchase_insurance(...)
○ 文件系统:Gorilla File System: ls(...), cd(...), cat(...)
● 跨领域API
○ Message API: send_message(...), delete_message(...), view_messages_received(...)
○ Twitter API: post_tweet(...), retweet(...), comment(...)
○ Ticket API: create_ticket(...), get_ticket(...), close_ticket(...)
○ Math API: logarithm(...), mean(...), standard_deviation(...) - 图边构建
一旦建立了 API 代码库,我们就构建一个图,其中每个函数代表一个节点。我们手动构建连接边,这意味着函数的输出是下游函数的输入。这图允许我们对跨 API 行为进行建模,模拟跨 API 的真实多轮函数调用 不同的域。每当我们需要数据集时,我们都会对图上的一个节点进行采样,并随机遍历生成执行路径的图。通过执行路径,我们可以推断出场景 这将提交给LLM。 - 任务生成
● 问题:采用 Persona hub 数据集来生成多样化的评估数据集和不同的角色,包括职业、年龄段等。
● 函数列表:对于每个查询,为模型提供可用函数列表,从主要函数和配到API中提取。
● 初始化配置:这些配置对于在交互开始时设置状态至关重要。
数据集中的每个数据点都映射到图中的可行路径。例如,如果模型需要 预订机票,它可能会调用 TravelBookingAPI 和 MessagingAPI 进行确认预订。
数据校验
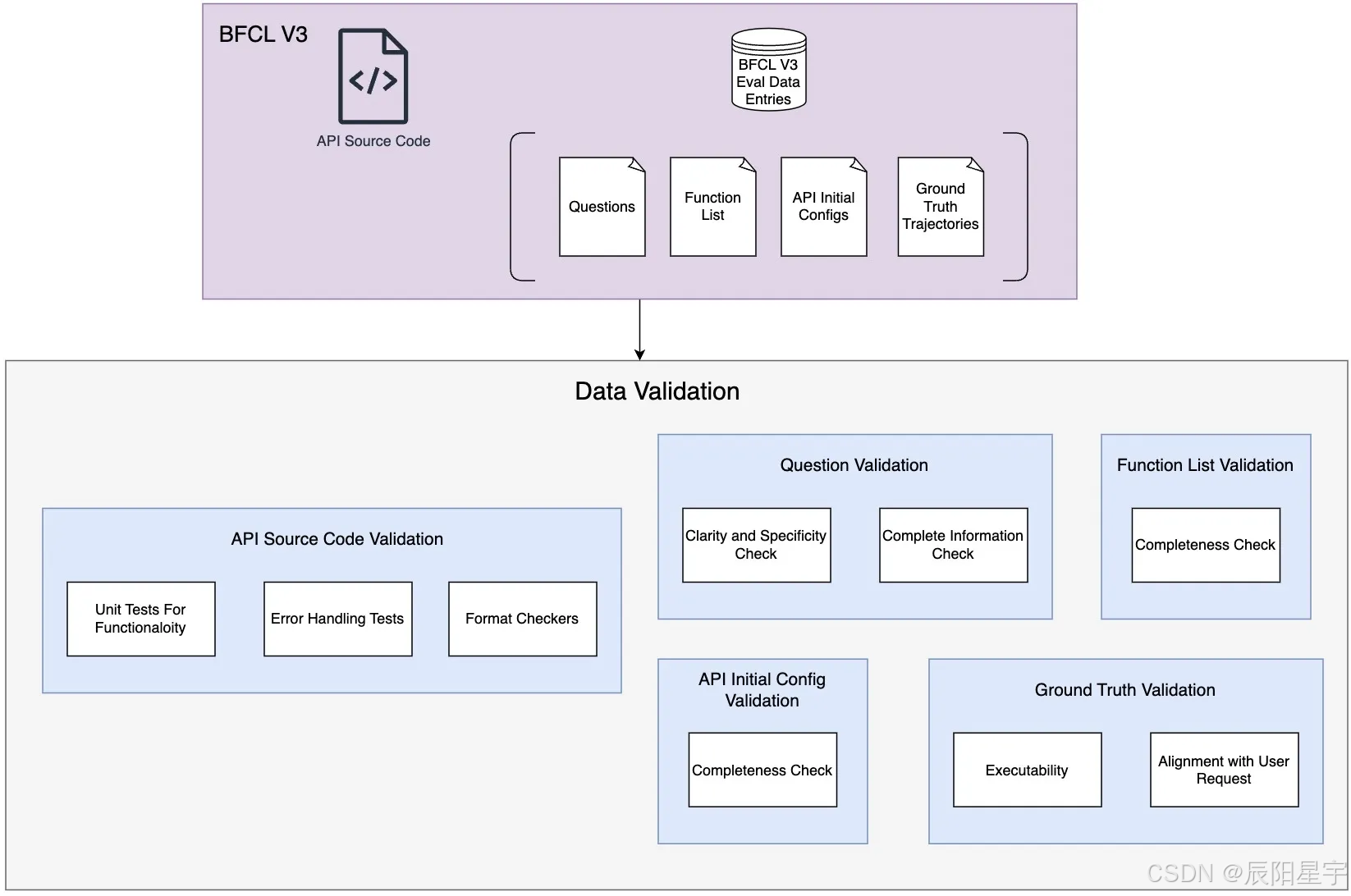
- 问题校验
每个问题都会经过审查,以确保它只会调用一个可能的正确答案。关键检查包括:
● 清晰度和特异性:对模糊的问题进行细化,以提供更具体的信息指示。
● 完整信息:当前回合或之前的问题和之前的问题通过在环境中进行探索,模型必须包含所有必要的细节来调用正确的函数。 - 人工校验
● 保证可执行
● 执行路径合理且与问题一致
● 执行路径在逻辑上一致。 - 初始配置验证
● 完整性:确保任务的所有必需信息都包含在初始配置。
● 唯一性:确保所有初始化信息都是唯一的,无法在后来轮到。
函数列表验证
● 完整性:所有必需的函数必须出现在函数列表中,允许模型进行适当的调用。
Web Search
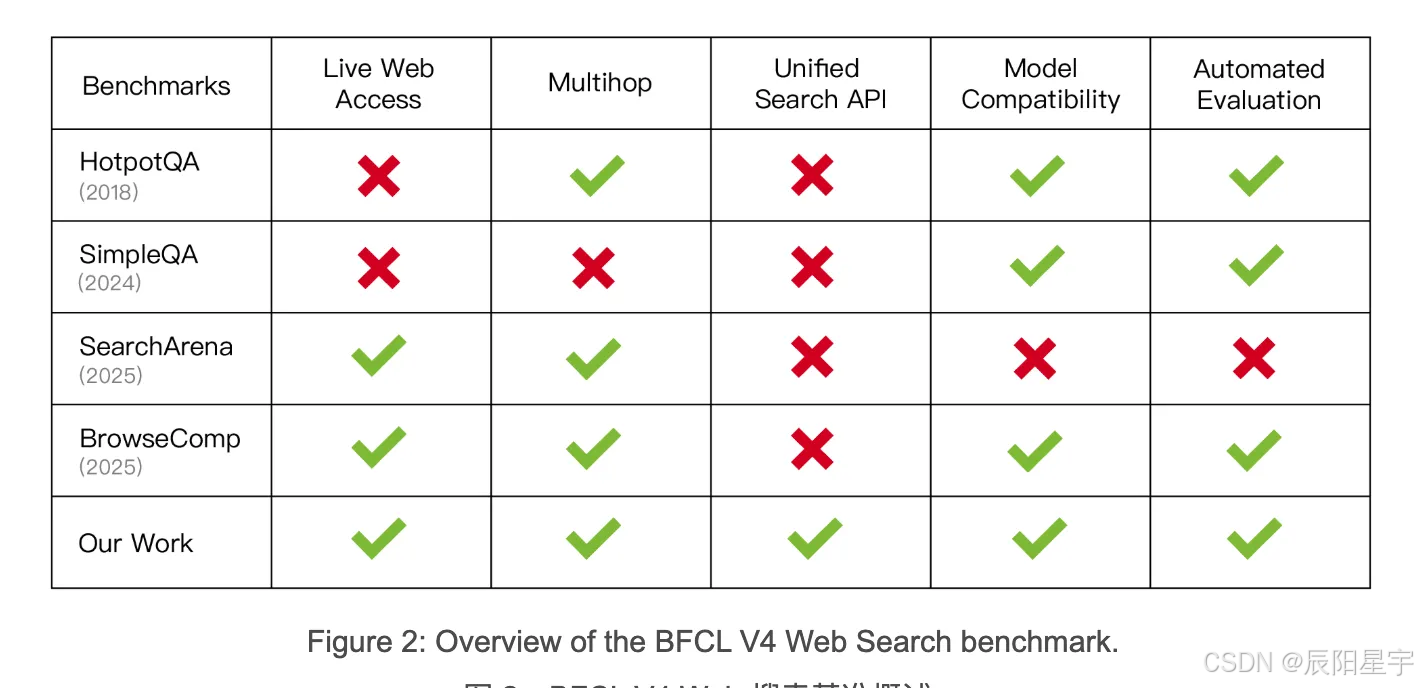
https://gorilla.cs.berkeley.edu/blogs/15_bfcl_v4_web_search.html
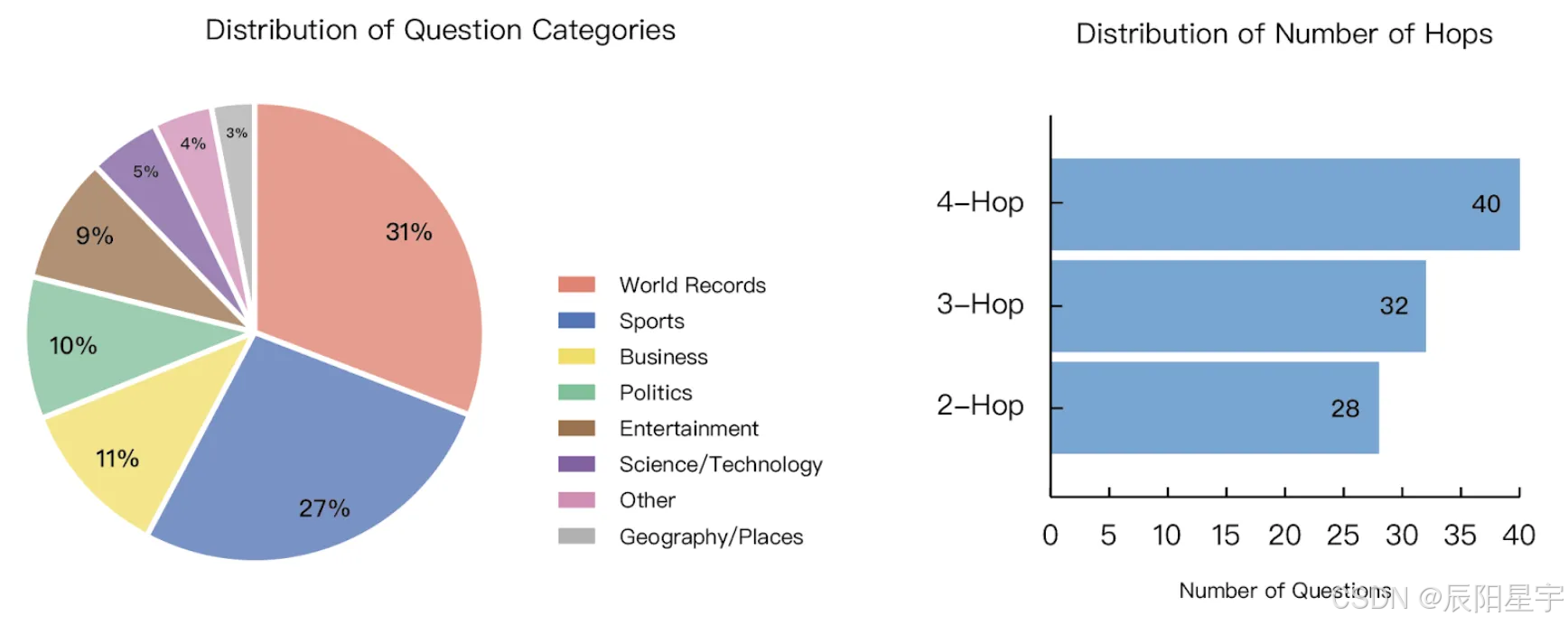
此类别包含 100 个跨越各个领域的人工多跳问题。在评估过程中,模型配备了 DuckDuckGo 搜索 API 和检索网页内容的功能。
根据以下原则设计基准:
● 标准化搜索界面。所有查询都通过 DuckDuckGo Search API,因此 每个模型都在相同的、保护隐私的搜索界面下运行。
● 多跳推理。每个问题都需要多个推理步骤,要求模型将其分解为子问题并从多个来源收集信息。
● 与模型无关的设置。任何遵循指令的语言模型都可以集成到该管道无需针对特定任务进行微调或自定义工具。
- 问题示例与构建
问题示例:
How many floors does the tallest building have in the city that received the most international tourists in 2024?
回答这个问题涉及三个单独的搜索:
● 确定 2024 年国际游客最多的城市(答案:曼谷)
● 确定曼谷最高的建筑(答案:Iconsiam 的 Magnolias Waterfront Residences)
● 求 Iconsiam Magnolias Waterfront Residences 的楼层数(答案:70)
问题生成过程
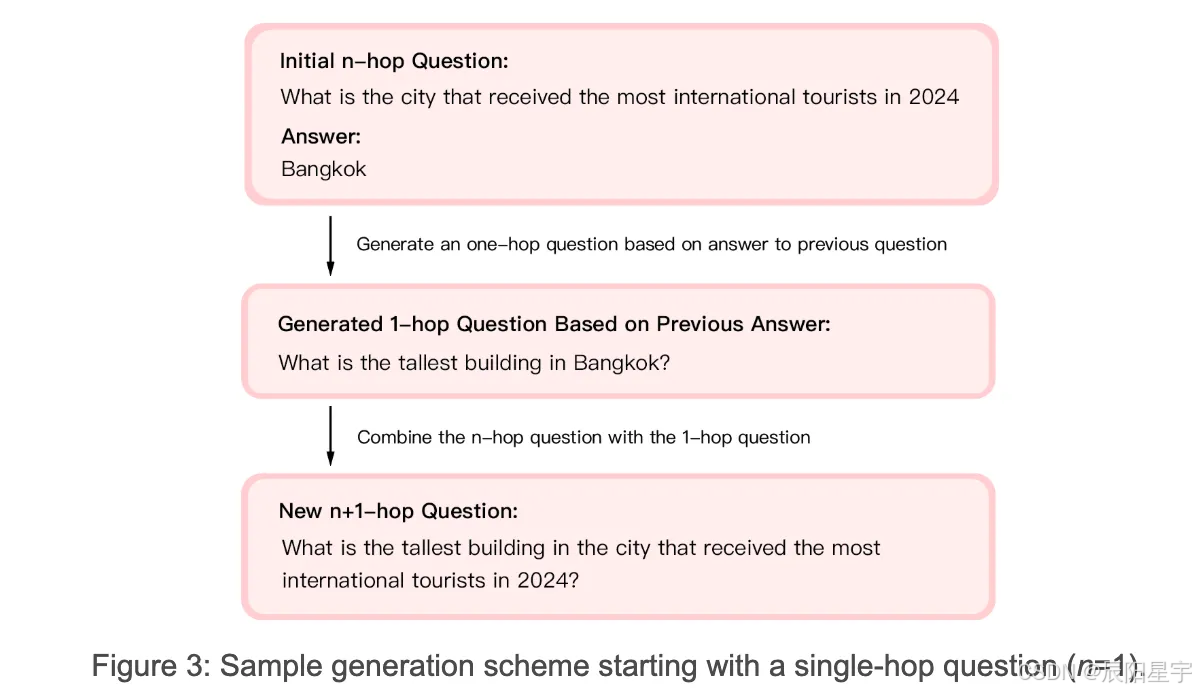
被剔除的问题:重复、常识、不明确、是或否的问题
- 常见失败示例
● 没有使用工具:有些模型尽管可以使用搜索工具,但仅依赖于其内部知识。这经常输出过时或不完整的信息。
● 对未来事件的错误假设:模型假设事件尚未发生,因此完全省略搜索。
● 关键词选择不当:某些模型无法将多跳查询分解为可管理的部分。相反,他们粘贴整个将问题转化为单一搜索,希望找到一个一体化的网页。
● 误解网站内容:即使检索到正确的网页,模型仍然可能误读其内容并产生错误的答案。
● 片段对其的影响
○ 模型可能直接从片段中获取答案,不再访问网站。删除片段后,被迫让模型访问页面获取信息。
○ 片段中含有噪声信息,导致正确性降低,不含片段时候噪声信息被删除会提升正确率。
● URL拦截器:当URL访问被拦截时候,默认为不明确的替代原,导致错误答案。
Memory
https://gorilla.cs.berkeley.edu/blogs/16_bfcl_v4_memory.html
BFCL v4 提供结构化内存测试后端。这些系统允许代理在对话期间通过以下方式存储和检索信息使用一组专用内存工具。有了这些功能, 模型可以跟踪重要细节,参考过去交互,并提供更加无缝、上下文感知的 用户体验。在设计内存数据集时,我们重点关注 在五个实用领域:客户支持、医疗保健、学生咨询、财务和个人生产力。每个域都具有复杂的多轮对话,旨在对压力测试模型保持对话连贯性、回忆的能力 先前陈述的事实,并不断适应作为上下文发展。
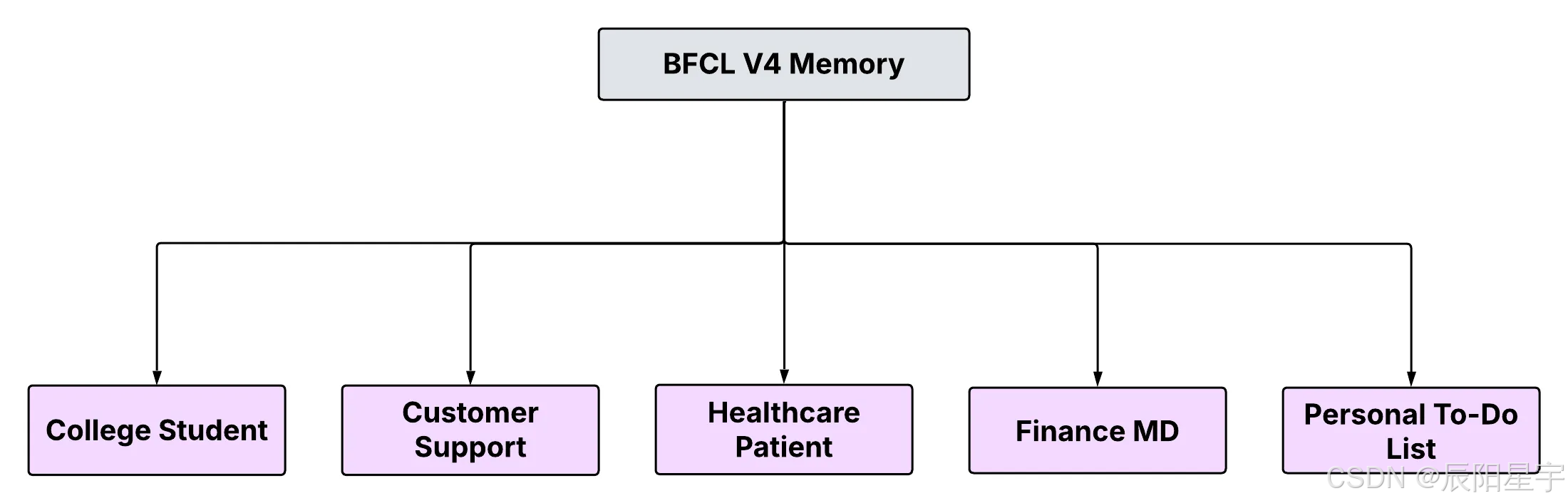
类型:
● 大学生建议:测试模型是否可以保留学术和个人背景来支持短期和长期学生咨询。
● 客户支持:评估连续性处理用户问题、偏好和之前的交互有效的服务。
● 个人待办事项列表: 评估模型的管理不断变化的日常任务和例行公事的能力一致的回忆。
● 医疗保健患者: 测量准确度追踪病史、生活方式的改变以及持续的治疗计划。
● 财务董事总经理: 检查内存使用情况 在涉及长期的复杂财务咨询场景中 战略。

该数据集由3个部分组成:
● Context:反映的多轮对话 现实的用户代理交互和随着时间的推移不断变化的需求。
● Tool Integration:一组工具,使模型可以与记忆后端通讯。
● Question:每个问题都是手动编写的 与先前用户的多轮对话保持一致。
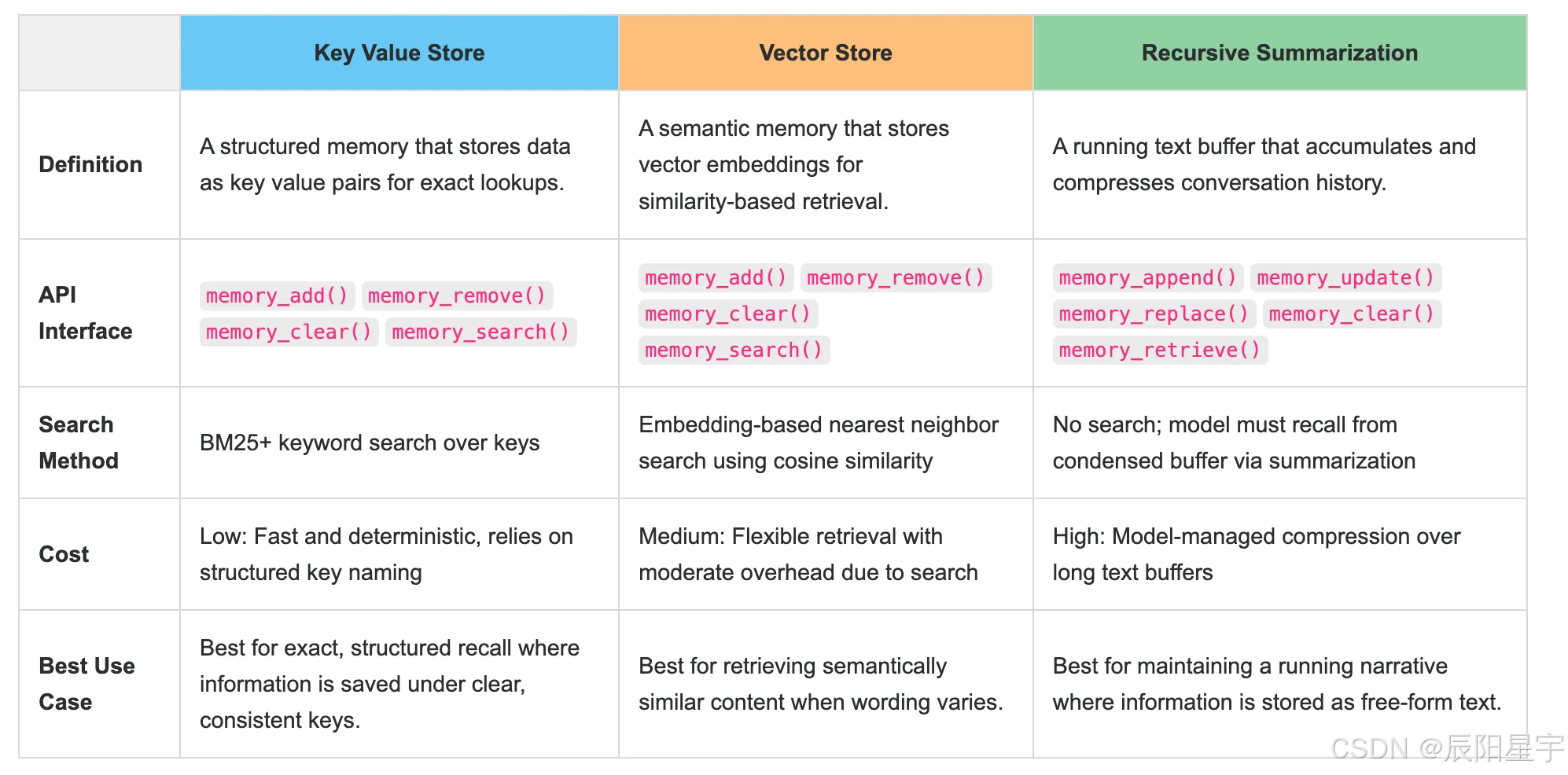
后端记忆系统
BFCL V4 的内存后端使模型能够 存储、检索和 管理上下文。我们实施了三个不同的 内存架构:键值存储、向量存储和递归 总结。每个内存后端都具有核心和存档功能 如上所述的记忆片段。
-
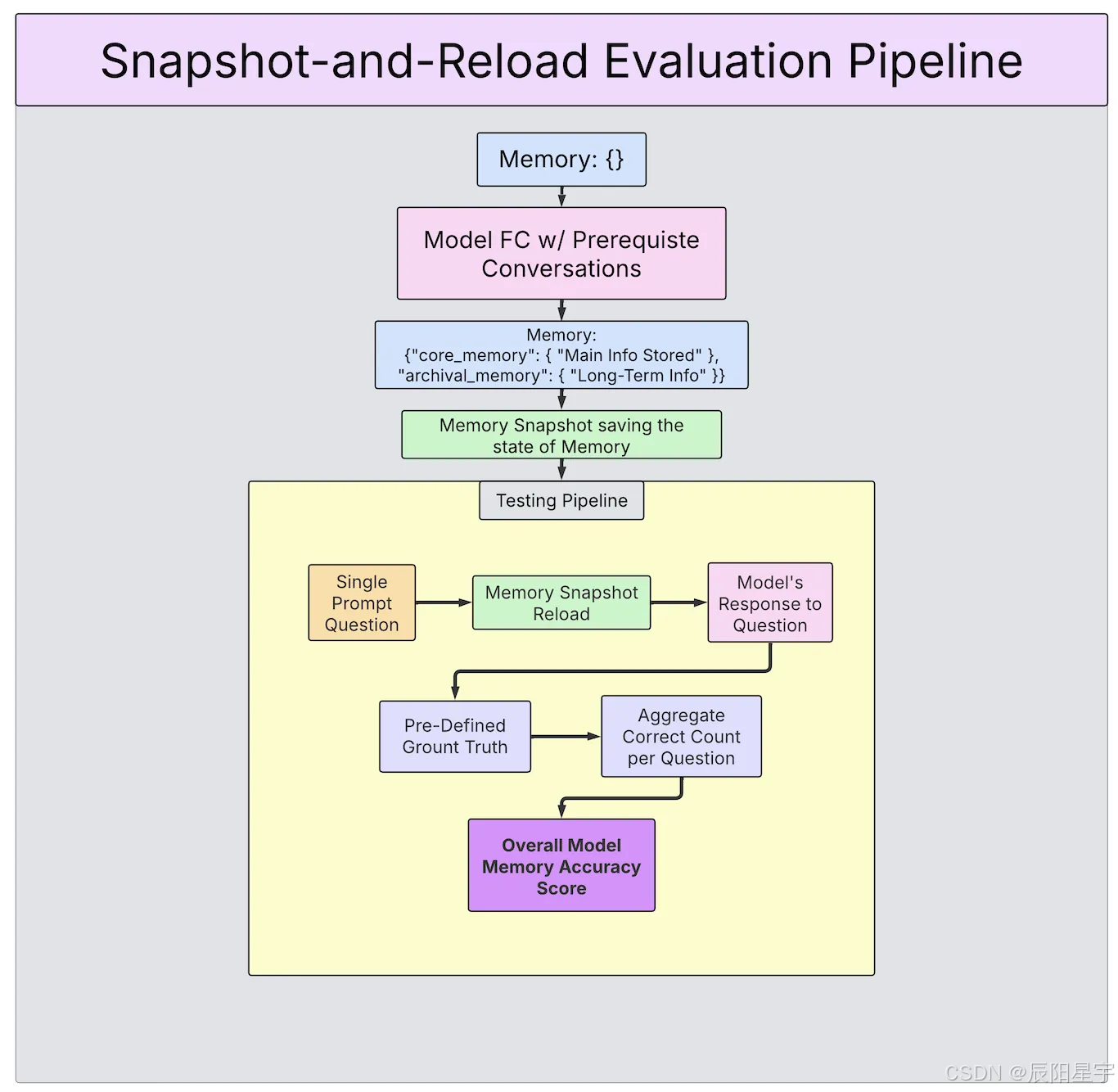
记忆管道流程:快照和加载
每个特定领域的数据集包含三个部分:
● 用必要的对话预先填充记忆:此阶段包括多个对话会话,每个会话 涵盖现实对话中不同的子主题。
● 评估有关预填充内存的问题:在评估阶段,最终的内存快照是 加载,模型呈现有针对性的后续 问题(例如,"下周末我要去哪里度假? 小型自由职业者?")。
● 验证者:根据真实情况评估响应以确定 正确性,验证模型是否准确存储和 通过记忆工具检索相关信息。
-
常见失败示例
● 模型过早地清楚了一个关键事实。
● 未能捕获和检索细微意图。
● 召回失败时候,过度自信产生幻觉而没有发现不确定性。
评估公式
分数计算方法:
O v e r a l l S c o r e = ( A g e n t i c × 40 % ) + ( M u l t i − T u r n × 30 % ) + ( L i v e × 10 % ) + ( N o n − L i v e × 10 % ) + ( H a l l u c i n a t i o n × 10 % ) Overall Score = (Agentic × 40\%) + (Multi-Turn × 30\%) + (Live × 10\%) + (Non-Live × 10\%) + (Hallucination × 10\%) OverallScore=(Agentic×40%)+(Multi−Turn×30%)+(Live×10%)+(Non−Live×10%)+(Hallucination×10%)
评估指标
-
(1)抽象语法树评估(AST)
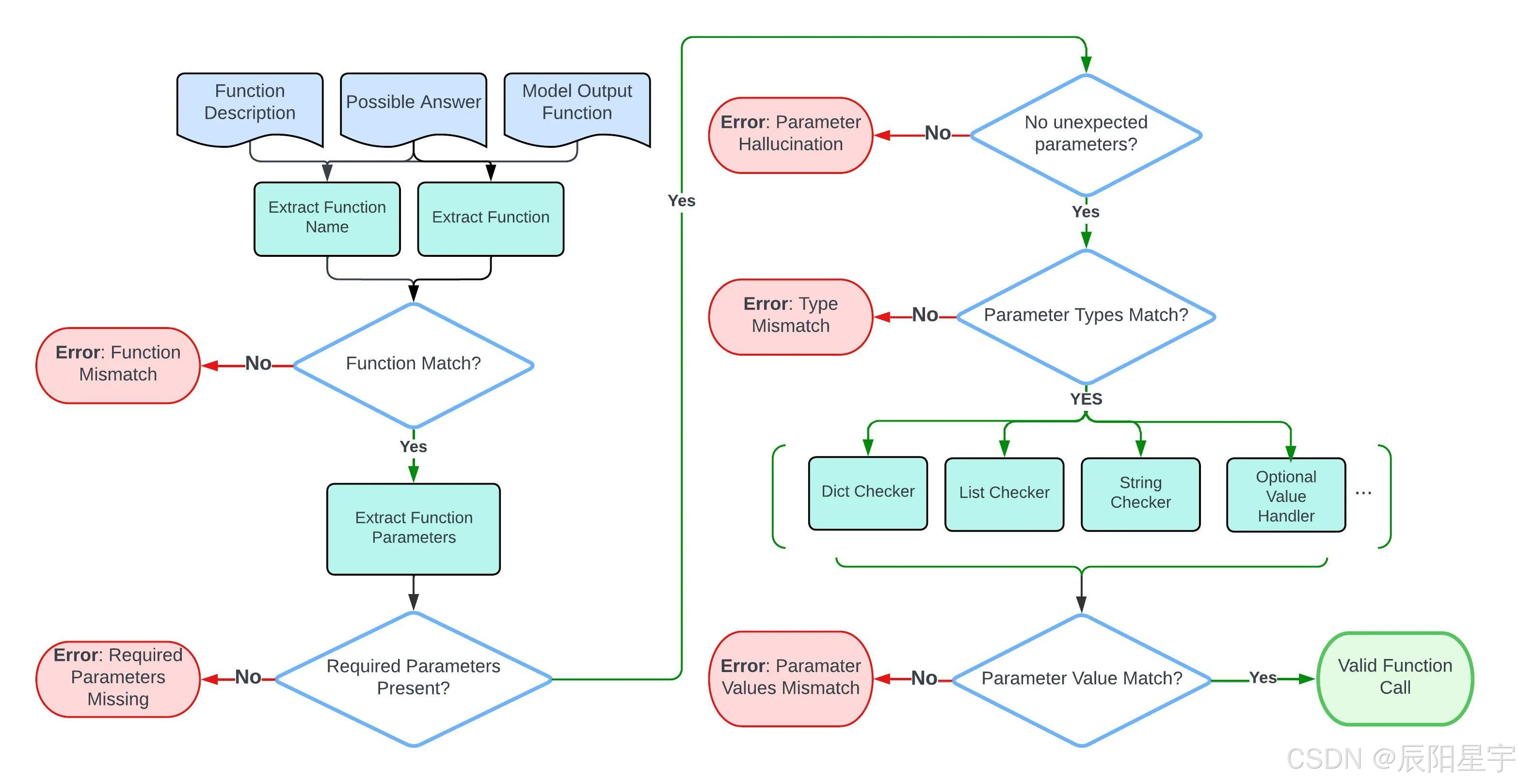
依次匹配:函数调用是否正确、请求参数是否正确(参数名、参数类型、参数值)。
● 参数类型
○ bool
■ 直接进行类型检查
○ integer, float
■ 对于python测试,允许对期望浮点值的Python参数使用int值,以适应Python从int到float的自动转换功能。
■ 对于非Python测试(Java, Javascript等),如果函数中指定为float参数,则应该指定为float模型输出,如果为int则不正确。
■ 不允许int参数中输入的为float类型。
○ list, tuple
■ 必须遵循答案中的顺序,例如:1,2,3和2,3,1是不相等的。
■ 类型匹配递归地扩展了嵌套数据 结构(List 或 Tuple),其中外部类型和内部类型 元素必须 符合规定的要求。
○ string
■ 不区分大小写
■ 所有字符串在评估前都被标准化:删除空白、删除标点符号「,./-_*^」
■ 可能的日期"20th June", "2023-06-20", "06/20/2023", "Jun.20, 2023"
■ 可能的地点"New York City", "NYC"
■ 都有可能 "Manchester United", "Man United", "Man U", "MUFC"
○ Dict
■ 关注是否存在、每个答案关联值的准确性
■ 不考虑顺序因素
○ lists of dictionaries
■ 列表内的字典顺序会被考虑,字典内的顺序不考虑
● 参数填写
○ 对于可选参数(函数描述里没有列出是必选的,并且可能的答案包含空字符串""),可使用默认值或者不提供值。
○ 对于必选参数,模型需显示提供值,不能用默认值或者不提供值。
-
(2)多重/并行/并行多函数AST评估
评估过程首先将每个可能的答案与其功能相关联 文档。然后它迭代模型输出并调用 simple
每个函数的函数评估。评估采用全有或全无的评估方法。未能 寻找 对于任何给定的可能答案,所有模型输出的匹配都会产生 评估失败。
-
(3)可执行函数评估
在executable测试类别中,我们执行生成的API调用来检查正确性。由于 Non-REST 和 REST 测试的评估过程有所不同。
● Non-REST评估
○ 执行涉及运行指定的函数并检查其输出。
○ 评估标准(必须满足以下任一条件,具体取决于 可执行函数示例):
■ 精确匹配:输出必须与预期结果完全匹配。
■ 实时匹配:精确匹配的宽松形式,仅适用于数值执行结果,其中执行结果必须在一定百分比阈值 (20%) 之内 预期结果以适应 API 响应的实时更新。
■ 结构匹配:输出必须匹配 预期的数据类型。
● 对于List,长度与预测长度匹配,不检查每个元素的类型。
● 对于Dict,预测的key必须在存在的key中,不检查每个value。
● REST评估
○ 这些测试涉及执行 API 调用和评估:
■ 有效执行:评估API调用是否成功执行。
■ 响应类型准确性:确保 API 响应与正确的结构(例如 list of JSON 对象)。
■ JSON 密钥一致性:检查 JSON key值中生成的和正确的一致性。