目录
当你的机器学习项目因
ModuleNotFoundError: No module named 'tensorflow'而中断时,这可能不仅是缺少一个包的问题,更可能涉及CPU/GPU版本冲突、Python版本兼容性、以及环境路径的复杂迷宫。
从简单错误到复杂真相
TensorFlow的导入失败可能有多种完全不同的技术背景:
情景一:全新环境的基本缺失
# 在全新的Python环境中尝试
import tensorflow as tf
# 立即报错:
# ModuleNotFoundError: No module named 'tensorflow'最直接的情况------TensorFlow确实没有安装到当前环境。
情景二:Python版本不兼容的隐性问题
import sys
print(f"Python版本: {sys.version}")
# 如果显示 Python 3.12+
import tensorflow as tf # 可能报错TensorFlow 2.x对Python版本有严格限制,Python 3.12用户常遇此问题。
情景三:CPU与GPU版本的安装混淆
# 用户想要GPU版本,但安装了CPU版本
pip install tensorflow # 这是CPU版本
# 实际需要的是:
pip install tensorflow-gpu # 旧的GPU版本名称
# 或现代的正确方式:
pip install tensorflow # 2.x后统一,但需要匹配CUDA核心诊断:为什么TensorFlow如此敏感?
TensorFlow的环境敏感性源于其多层架构:
-
Python API层:用户直接交互的Python接口
-
C++核心层:高性能计算核心,需要特定编译器构建
-
硬件加速层:CUDA/cuDNN用于GPU加速,版本必须精确匹配
-
系统依赖层:特定操作系统库和运行时环境
当出现No module named 'tensorflow'时,通常意味着:
-
Python包完全缺失
-
Python版本不兼容
-
安装过程损坏或不完整
-
环境路径配置错误
系统性排查流程
第一步:环境基础诊断
import sys, platform, os
print("=" * 50)
print("环境诊断报告")
print("=" * 50)
print(f"操作系统: {platform.system()} {platform.machine()}")
print(f"Python版本: {sys.version}")
print(f"Python路径: {sys.executable}")
print(f"PATH包含: {len(os.environ.get('PATH', '').split(';'))}个条目")第二步:TensorFlow版本兼容性检查
TensorFlow与Python版本的官方兼容性:
-
TensorFlow 2.13+: Python 3.8-3.11
-
TensorFlow 2.12: Python 3.8-3.11
-
TensorFlow 2.11: Python 3.7-3.10
-
TensorFlow <2.10: Python 3.7-3.9
如果你的Python版本不在支持范围内,必然失败。
第三步:安装状态验证
# 检查已安装的TensorFlow相关包
pip list | findstr tensorflow # Windows
# 或
pip list | grep tensorflow # Linux/Mac
# 正确安装应显示:
# tensorflow 2.13.0
# tensorflow-estimator 2.13.0复杂情况:GPU支持的特殊挑战
对于需要GPU加速的用户,问题更加复杂:
CUDA与cuDNN版本矩阵
TensorFlow 2.13 → CUDA 11.8 + cuDNN 8.6
TensorFlow 2.12 → CUDA 11.8 + cuDNN 8.6
TensorFlow 2.11 → CUDA 11.2 + cuDNN 8.1
TensorFlow 2.10 → CUDA 11.2 + cuDNN 8.1常见GPU安装错误
bash
# 错误1:CUDA版本不匹配
Could not load dynamic library 'cudart64_110.dll'
# 错误2:cuDNN缺失
Could not load dynamic library 'cudnn64_8.dll'
# 错误3:驱动过时
CUDA driver version is insufficient for CUDA runtime version高效解决方案:确定性环境配置
如果你需要快速获得可用的TensorFlow环境,而不是花费数小时处理版本兼容性和依赖问题,自动化配置是最佳选择。
使用专业的环境配置工具,整个过程简化为:
-
打开工具,清晰看到所有你本机的环境,选择环境后,点"装库
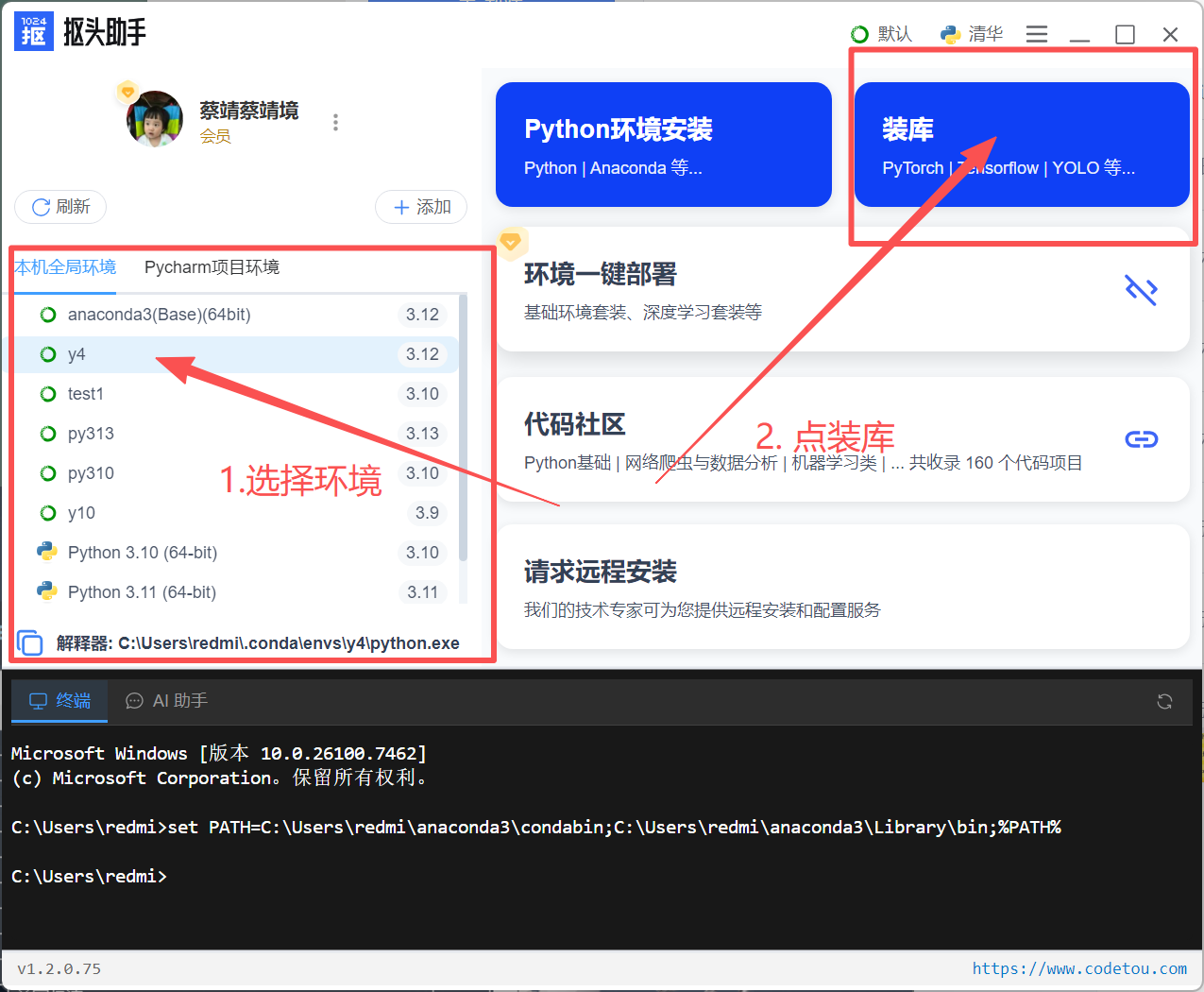
-
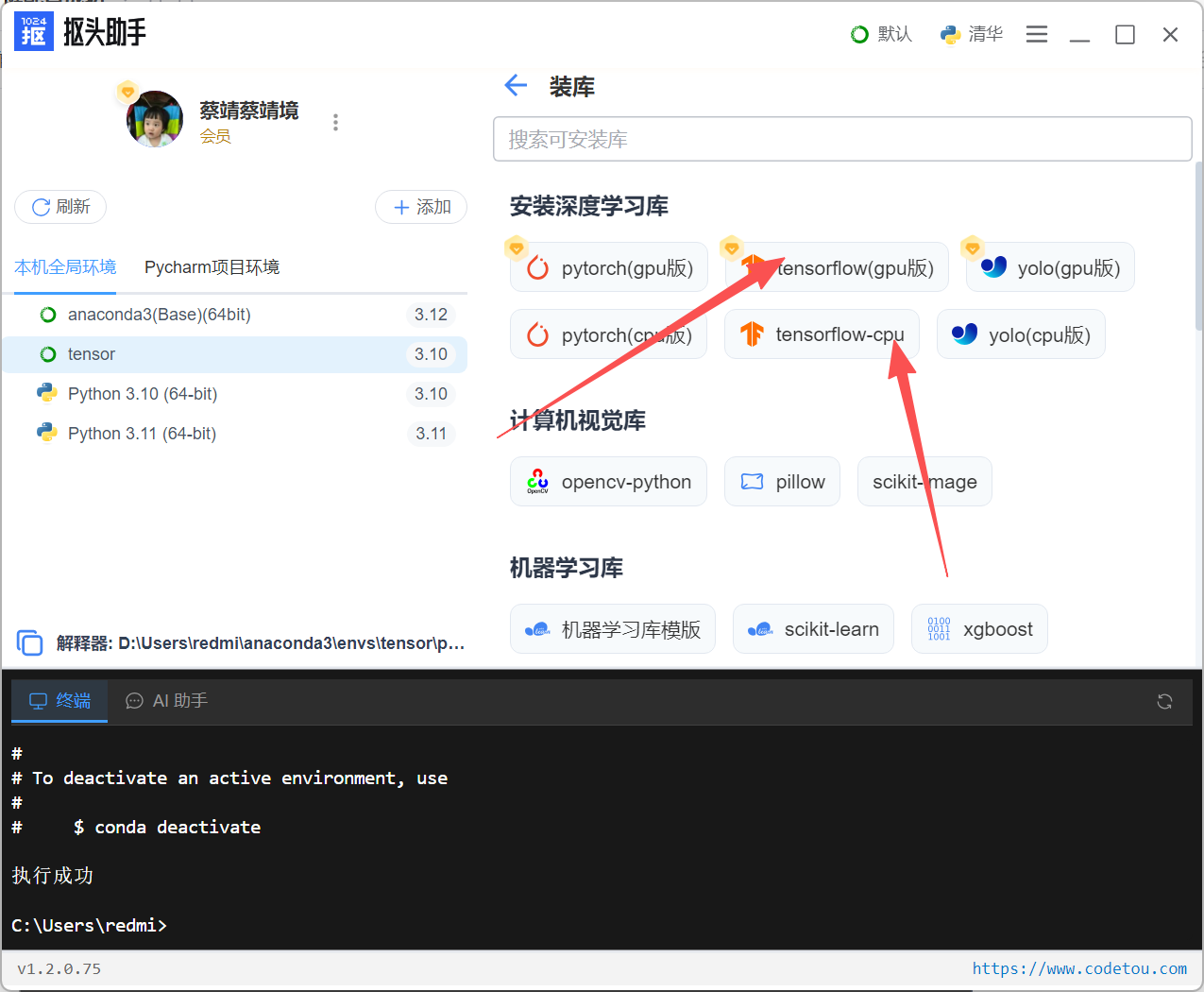
指定需求(CPU/GPU,TensorFlow版本)
-
选择版本号,点击"开始安装"
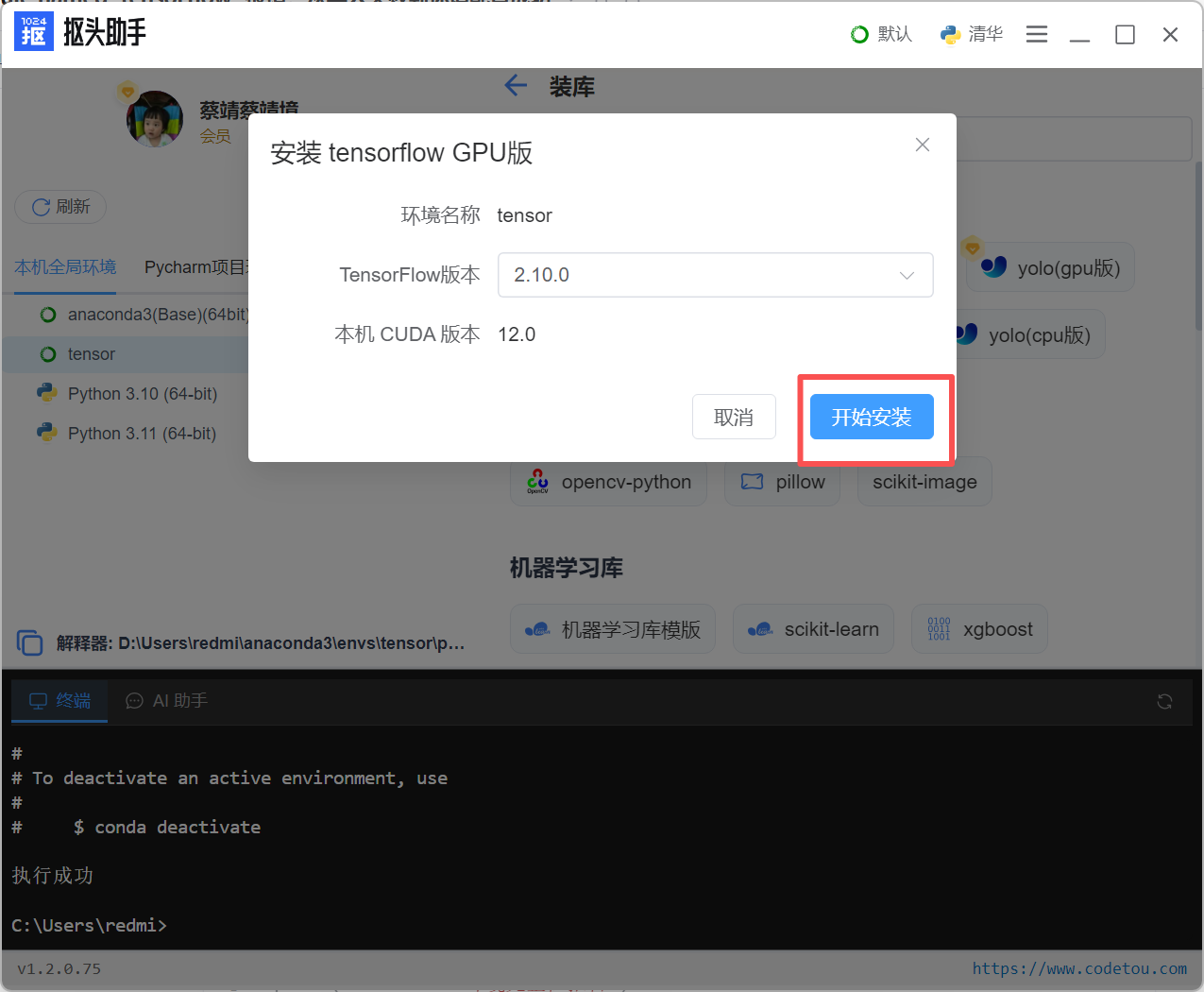
工具会自动:检测系统环境,Python版本、选择兼容的TensorFlow版本、安装所有必要依赖、配置CUDA/cuDNN(如需要)、验证安装完整性和正确性。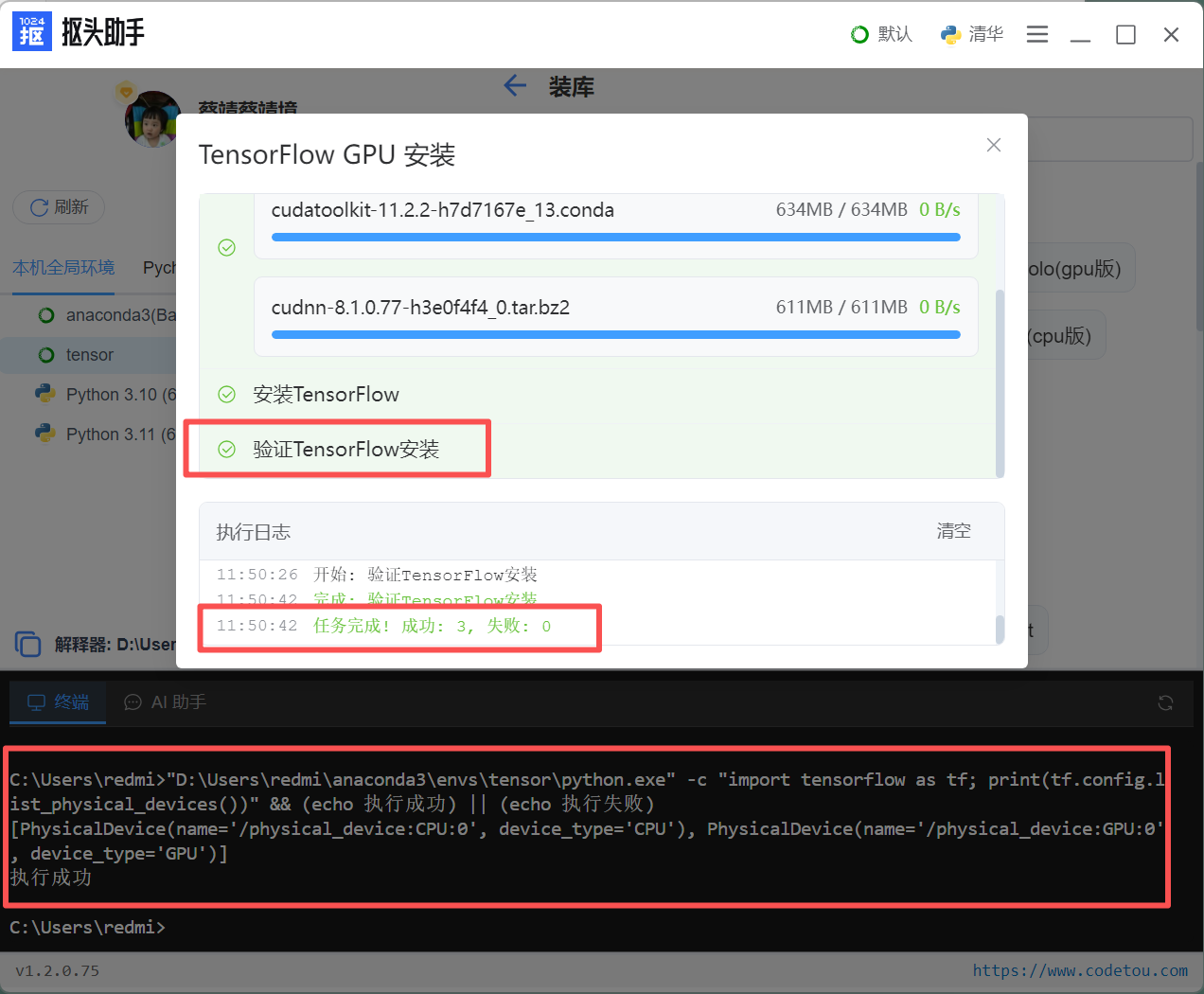
👉 进入抠头助手官网下载工具codetou.com
!!注意!! 使用抠头助手期间不要打开VPN,因为下载使用的是国内镜像源。
环境完整性验证
配置完成后,运行全面测试:
python
import tensorflow as tf
print("=" * 60)
print("TensorFlow环境完整性报告")
print("=" * 60)
# 基础信息
print(f"✅ TensorFlow版本: {tf.__version__}")
print(f"✅ Keras版本: {tf.keras.__version__}")
# GPU检测
gpu_devices = tf.config.list_physical_devices('GPU')
cpu_devices = tf.config.list_physical_devices('CPU')
print(f"✅ CPU设备: {len(cpu_devices)}个")
print(f"✅ GPU设备: {len(gpu_devices)}个")
if gpu_devices:
for i, gpu in enumerate(gpu_devices):
details = tf.config.experimental.get_device_details(gpu)
print(f" GPU {i}: {gpu.name}")
print(f" 设备类型: {details.get('device_name', 'N/A')}")
# GPU计算测试
with tf.device('/GPU:0'):
a = tf.constant([[1.0, 2.0], [3.0, 4.0]])
b = tf.constant([[5.0, 6.0], [7.0, 8.0]])
c = tf.matmul(a, b)
print(f"✅ GPU矩阵乘法测试通过")
print(f" 计算结果:\n{c.numpy()}")
# 基础功能测试
print("\n🧪 基础功能测试:")
# 1. 张量运算
x = tf.constant([1, 2, 3])
y = tf.constant([4, 5, 6])
print(f"✅ 张量加法: {x + y}")
# 2. 简单模型构建
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation='relu', input_shape=(5,)),
tf.keras.layers.Dense(1)
])
print(f"✅ 模型构建: {model.summary()}")
print("=" * 60)
print("环境验证完成!可以开始机器学习项目。")
print("=" * 60)为什么TensorFlow比PyTorch更"挑剔"?
-
统一构建系统:TensorFlow采用Bazel构建,对系统环境要求更严格
-
版本管理更保守:TensorFlow团队对新Python版本支持通常较慢
-
GPU依赖更复杂:CUDA/cuDNN版本矩阵比PyTorch更固定
-
历史兼容性负担:从1.x到2.x的巨大变化留下了许多兼容性问题
预防与最佳实践
-
使用虚拟环境:每个TensorFlow项目使用独立环境
-
明确Python版本:选择TensorFlow官方支持的Python版本
-
记录环境配置:使用
pip freeze或conda导出环境文件 -
优先使用Docker:对于生产环境,Docker提供最佳的可复现性
总结与选择
手动配置TensorFlow适合:有丰富系统管理经验、需要特定版本组合、或希望深入理解底层依赖的用户。
自动化环境配置适合:
-
需要快速开始机器学习项目的研究者
-
在多台机器上部署一致环境的团队
-
不想处理复杂依赖关系的开发者
-
需要确保实验可复现的学术工作
如果你选择手动安装:请仔细查阅TensorFlow官方安装指南,特别注意Python版本和GPU依赖的兼容性表格。
如果选择自动化配置:可以直接获得一个经过完整验证的TensorFlow环境,立即开始模型构建和训练。毕竟,机器学习工作的价值在于算法创新和模型优化,而非环境配置的重复劳动。