文章目录
- 一、简介
- 二、分析器(analyzer)使用
-
- 1、配置分析器
- 2、内置分析器:fingerprint(不常用)
- 3、内置分析器:keyword(不常用)
- 4、内置分析器:Language(多语言专用)
- [5、内置分析器:Pattern 正则](#5、内置分析器:Pattern 正则)
- 6、内置分析器:simple
- 7、内置解析器:standard(默认)
- 8、内置解析器:stop
- 9、内置解析器:whitespace
- 三、分词器(tokenizer)使用
-
- 1、内置分词器:char_group
- 2、内置分词器:classic
- 3、内置分词器:edge_ngram
- 4、内置分词器:keyword
- 5、内置分词器:letter
- 6、内置分词器:lowercase
- [7、内置分词器:ngram (可用,将词语拆成单个字)](#7、内置分词器:ngram (可用,将词语拆成单个字))
- [8、内置分词器:path_hierarchy (用于文件路径)](#8、内置分词器:path_hierarchy (用于文件路径))
- 9、内置分词器:pattern
- 10、内置分词器:simple_pattern
- 11、内置分词器:simple_pattern_split
- [12、内置分词器:standard (默认)](#12、内置分词器:standard (默认))
- [13、内置分词器:thai (泰语)](#13、内置分词器:thai (泰语))
- 14、内置分词器:uax_url_email
- 15、内置分词器:whitespace
- 四、IK中文分词器
一、简介
本文基于ES7.10版本(阿里云ES稳定版也是7.10版)。
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.10/analysis-overview.html
1、基本概念
文本分析发生在两个时间:
对文档编制索引时,将分析所有文本字段值。
当对文本字段运行全文搜索时,将分析查询字符串(用户正在搜索的文本)。
在大多数情况下,在索引和搜索时应该使用相同的分析器。这确保了字段的值和查询字符串被更改为相同形式的标记。反过来,这确保了令牌在搜索期间按预期匹配。
stopwords(停止词): 是指在文本分析过程中被忽略、过滤掉的高频无意义词汇,其核心作用是优化索引效率、提升检索精度。
2、tokenizer(分词器)和 analyzer(分析器)的区别
(1)区别
Tokenizer(分词器):仅负责 "切割",tokenizer 的唯一职责是把一段连续的文本(字符串)按照特定规则切分成一个个独立的 "词元(token)",它只做 "切割",不做其他处理。
Analyzer(分析器):负责 "完整的文本处理流程",analyzer 是一个 "组合组件",它封装了一套完整的文本分析流程,包含 3 个可选阶段(实际至少包含 tokenizer):

字符过滤器(Char Filter):预处理文本(如替换特殊字符、去除 HTML 标签);
分词器(Tokenizer):核心切割步骤(必须有,且只能有一个);
词元过滤器(Token Filter):对切割后的词元做二次处理(如转小写、停用词过滤、同义词替换、词干提取)。
analyzer 的核心就是 tokenizer,所有文本分析最终都要通过 tokenizer 完成切割,analyzer 只是在 tokenizer 的基础上增加了前后处理逻辑。
(2)常见使用场景
1.使用 ES 内置 analyzer(已包含默认 tokenizer)
这是最常用的方式,直接用 ES 预定义的 analyzer(如 standard、ik_smart、whitespace),无需手动指定 tokenizer,因为 analyzer 已经内置了对应的 tokenizer。
json
# 示例:使用内置 standard 分析器(内置 standard tokenizer)
POST _analyze
{
"analyzer": "standard",
"text": "Elasticsearch Is Good!"
}
# 输出结果:["elasticsearch", "is", "good"]2.自定义 analyzer(手动指定 tokenizer + 过滤器)
如果内置 analyzer 不满足需求,你可以自定义 analyzer,必须显式指定一个 tokenizer,还可以搭配 char filter 和 token filter。
json
# 示例:自定义分析器,指定 whitespace tokenizer + lowercase 过滤器
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": { # 自定义分析器
"type": "custom",
"char_filter": ["html_strip"], # 字符过滤器:去除HTML标签
"tokenizer": "whitespace", # 手动指定 tokenizer(空格分词)
"filter": ["lowercase"] # 词元过滤器:转小写
}
}
}
}
}
# 测试自定义分析器
POST my_index/_analyze
{
"analyzer": "my_custom_analyzer",
"text": "<p>Elasticsearch Is Good!</p>"
}
# 输出结果:["elasticsearch", "is", "good!"](去除HTML+空格切割+转小写,保留标点)3.单独测试 tokenizer(仅看切割效果)
虽然 analyzer 必须包含 tokenizer,但你可以单独调用 tokenizer 来测试切割效果(仅用于调试,实际索引/搜索时还是要通过 analyzer):
json
POST _analyze
{
"tokenizer": "whitespace", # 单独使用 tokenizer
"text": "Elasticsearch Is Good!"
}
# 输出结果:["Elasticsearch", "Is", "Good!"](仅切割,无转小写)二、分析器(analyzer)使用
1、配置分析器
(1)测试分析器
从分析 API 的输出中可以看出,分析器不仅将单词转换为术语,还记录顺序或相对位置 (用于短语查询或单词邻近度查询), 原始文本中每个术语的开始和结束字符偏移量 (用于突出显示搜索片段)。
json
// 根据空格分词
POST _analyze
{
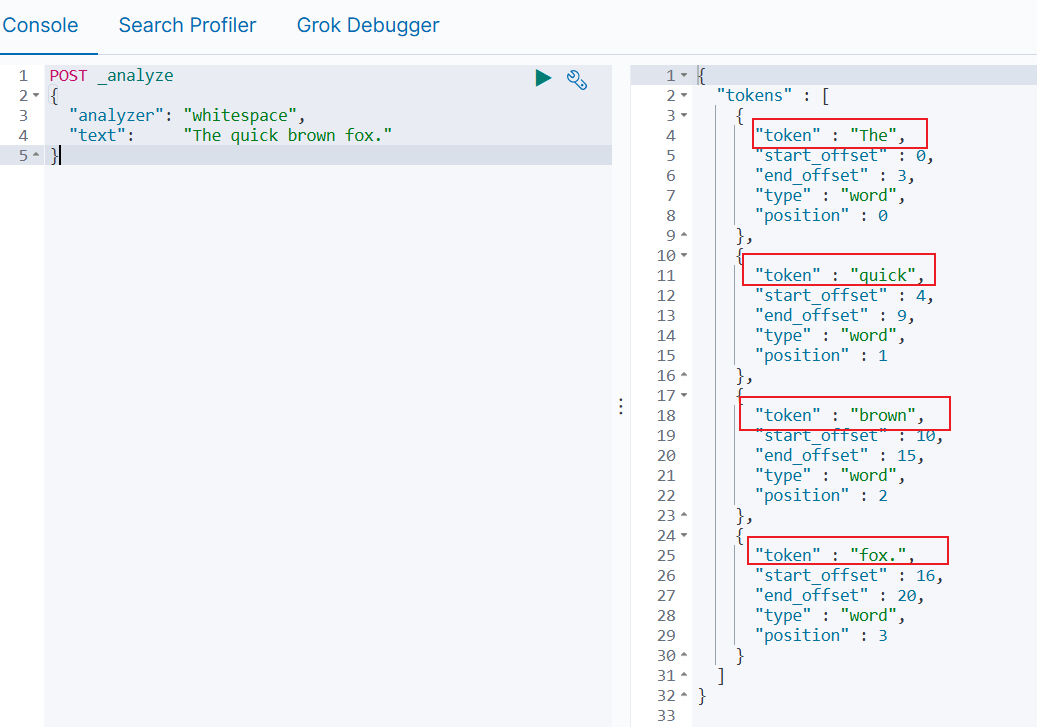
"analyzer": "whitespace",
"text": "The quick brown fox."
}
json
POST _analyze
{
"tokenizer": "standard",
// lowercase:把所有字母转为小写(如 Is → is);
// asciifolding:把带重音的特殊字符转为普通 ASCII 字符(如 déja 中的 é → e)。
"filter": [ "lowercase", "asciifolding" ],
"text": "Is this déja vu?"
}
// 修改指定索引,可以自定义分析器
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"std_folded": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"asciifolding"
]
}
}
}
},
"mappings": {
"properties": {
"my_text": {
"type": "text",
"analyzer": "std_folded"
}
}
}
}
// 查看指定索引的分析器
GET my-index-000001/_analyze
{
"analyzer": "std_folded",
"text": "Is this déjà vu?"
}
GET my-index-000001/_analyze
{
"field": "my_text",
"text": "Is this déjà vu?"
}(2)创建自定义分词器
json
// 为指定字段指定自定义分词器
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"std_english": {
"type": "standard",
"stopwords": "_english_"
}
}
}
},
"mappings": {
"properties": {
"my_text": {
"type": "text",
"analyzer": "standard",
"fields": {
"english": {
"type": "text",
"analyzer": "std_english" // 指定自定义分词器
}
}
}
}
}
}
POST my-index-000001/_analyze
{
"field": "my_text",
"text": "The old brown cow"
}
POST my-index-000001/_analyze
{
"field": "my_text.english",
"text": "The old brown cow"
}
json
```json
// 配置实例,最多一个字符,并且字母数字按照token处理
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ngram",
"min_gram": 1,
"max_gram": 1,
"token_chars": [
"letter",
"digit"
]
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_analyzer",
"text": "2 Quick Foxes.你好啊"
}
// 结果:
2 Q u i c k F o x e s 你 好 啊### (3)指定分析器:指定字段
映射索引时,可以使用分析器映射参数为`每个文本字段`指定分析器。
```json
// 为索引中的某个字段,指定分词器
PUT my-index-000001
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "whitespace"
}
}
}
}(4)指定分析器:索引的默认分析器
还可以使用 analysis.analyzer.default 设置索引默认分析器。
json
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "simple"
}
}
}
}
}(5)指定查询分析器:指定查询的搜索分析器(一般不需要)
json
GET my-index-000001/_search
{
"query": {
"match": {
"message": {
"query": "Quick foxes",
"analyzer": "stop" // 指定查询分析器
}
}
}
}(6)指定查询分析器:指定字段的查询分析器(一般不需要)
json
PUT my-index-000001
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "whitespace",
"search_analyzer": "simple" // 指定查询分析器,一般不需要单独配置
}
}
}
}(7)指定查询分析器:指定索引默认查询分析器(一般不需要)
json
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "simple"
},
"default_search": { // 索引默认查询分析器,一般不需要
"type": "whitespace"
}
}
}
}
}2、内置分析器:fingerprint(不常用)
输入文本是小写的,规范化以删除扩展字符,排序,重复数据删除和连接到一个单一的令牌。如果配置了停用词列表,停用词也将被删除。
(1)默认示例
json
// 默认示例
POST _analyze
{
"analyzer": "fingerprint",
"text": "Yes yes, Gödel said this sentence is consistent and."
}
// 结果:产生一条
{
"tokens" : [
{
"token" : "and consistent godel is said sentence this yes",
"start_offset" : 0,
"end_offset" : 52,
"type" : "fingerprint",
"position" : 0
}
]
}(2)可选配置
separator:用于连接术语的字符。默认是空格。
max_output_size:最大字符数,默认255,超过这个数的将被丢弃。
stopwords:停止词,默认停止词_none_
stopwords_path:包含停止字的文件的路径。
json
// 配置示例
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_fingerprint_analyzer": {
"type": "fingerprint", // 选择分析器
"stopwords": "_english_", // 停止词
"separator": "," // 分隔符
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_fingerprint_analyzer",
"text": "Yes yes, Gödel said this sentence is consistent and."
}
// 以下为执行结果:
{
"tokens" : [
{
"token" : "consistent,godel,said,sentence,yes", // 排序、以逗号分隔、去掉英文的停止词
"start_offset" : 0,
"end_offset" : 52,
"type" : "fingerprint",
"position" : 0
}
]
}3、内置分析器:keyword(不常用)
(1)默认示例
keyword分析器是一个"noop"分析器,它将整个输入字符串作为单个标记返回。
json
// 示例,输入啥就输出啥,输出同样的字符串:The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.
POST _analyze
{
"analyzer": "keyword",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}(2)可选配置
keyword分析器不可配置。
4、内置分析器:Language(多语言专用)
支持的语言:arabic, armenian, basque, bengali, brazilian, bulgarian, catalan, cjk, czech, danish, dutch, english, estonian, finnish, french, galician, german, greek, hindi, hungarian, indonesian, irish, italian, latvian, lithuanian, norwegian, persian, portuguese, romanian, russian, sorani, spanish, swedish, turkish, thai.
5、内置分析器:Pattern 正则
Pattern 分析器使用Java正则表达式将文本拆分。正则表达式应该匹配标记分隔符, 而不是标记本身。正则表达式默认为 \W+(所有非单词字符,除了 a-zA-Z0-9_ 之外的所有字符)。
(1)默认示例
json
POST _analyze
{
"analyzer": "pattern",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}结果如下:
json
{
"tokens" : [
{
"token" : "the",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "2",
"start_offset" : 4,
"end_offset" : 5,
"type" : "word",
"position" : 1
},
{
"token" : "quick",
"start_offset" : 6,
"end_offset" : 11,
"type" : "word",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 12,
"end_offset" : 17,
"type" : "word",
"position" : 3
},
{
"token" : "foxes",
"start_offset" : 18,
"end_offset" : 23,
"type" : "word",
"position" : 4
},
{
"token" : "jumped",
"start_offset" : 24,
"end_offset" : 30,
"type" : "word",
"position" : 5
},
{
"token" : "over",
"start_offset" : 31,
"end_offset" : 35,
"type" : "word",
"position" : 6
},
{
"token" : "the",
"start_offset" : 36,
"end_offset" : 39,
"type" : "word",
"position" : 7
},
{
"token" : "lazy",
"start_offset" : 40,
"end_offset" : 44,
"type" : "word",
"position" : 8
},
{
"token" : "dog",
"start_offset" : 45,
"end_offset" : 48,
"type" : "word",
"position" : 9
},
{
"token" : "s",
"start_offset" : 49,
"end_offset" : 50,
"type" : "word",
"position" : 10
},
{
"token" : "bone",
"start_offset" : 51,
"end_offset" : 55,
"type" : "word",
"position" : 11
}
]
}(2)可选配置
pattern:Java 正则表达式 ,默认值为 \W+(除了 a-zA-Z0-9_ 之外的所有字符)。
flags:Java 正则表达式标志 。标志应采用管道分隔,例如"CASE_INSENSITIVE|COMMENTS"
lowercase:是否转小写,默认true。
stopwords:一个预定义的停止词列表,如 _english_ 或者一个包含停止词列表的数组。默认 _none_。
stopwords_path:包含停止字的文件的路径。
json
// 示例:除了默认的\W+以外,加上下划线也参与拆分
PUT my-index-000002
{
"settings": {
"analysis": {
"analyzer": {
"my_email_analyzer": {
"type": "pattern",
"pattern": "\\W|_",
"lowercase": true
}
}
}
}
}
POST my-index-000002/_analyze
{
"analyzer": "my_email_analyzer",
"text": "John_Smith@foo-bar.com"
}
// 结果数组为:
[ john, smith, foo, bar, com ]6、内置分析器:simple
simple 分析器将文本分解为任何非字母字符(如数字、空格、连字符和撇号)处的标记,丢弃非字母字符,并转为小写。
(1)默认示例
json
// 默认示例:
POST _analyze
{
"analyzer": "simple",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// 结果数组:
[ the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ]7、内置解析器:standard(默认)
standard分析器是默认分析器。 它基于语法的标记化(基于 Unicode 文本 分割算法),并适用于大多数语言。
(1)默认示例
json
POST _analyze
{
"analyzer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// 结果数组:
[ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog's, bone ](2)可选配置
max_token_length:最大长度,默认255。
stopwords:一个预定义的停止词列表,如 _english_ 或者一个包含停止词列表的数组。默认 _none_。
stopwords_path:包含停止字的文件的路径。
json
// 示例:最长5个字符
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_english_analyzer": {
"type": "standard",
"max_token_length": 5,
"stopwords": "_english_"
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_english_analyzer",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// 结果数组:
[ 2, quick, brown, foxes, jumpe, d, over, lazy, dog's, bone ]8、内置解析器:stop
stop分析器与simple 分析器相同 但增加了对删除停止词的支持。 它默认使用_english_停止词。
(1)默认示例
json
POST _analyze
{
"analyzer": "stop",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// 结果数组
[ quick, brown, foxes, jumped, over, lazy, dog, s, bone ](2)可选配置
stopwords:一个预定义的停止词列表,如 _english_ 或者一个包含停止词列表的数组。默认 _english_。
stopwords_path:包含停止字的文件的路径。
json
// 示例:指定停止词
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_stop_analyzer": {
"type": "stop",
"stopwords": ["the", "over"]
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_stop_analyzer",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}9、内置解析器:whitespace
whitespace 通过空格进行词语拆分。
不可以额外配置。
(1)默认示例
json
POST _analyze
{
"analyzer": "whitespace",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// 结果数组:
[ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog's, bone. ]三、分词器(tokenizer)使用
分词器接收一段字符流,将其拆分成一个个单独的"标记"(通常是指单个单词),然后输出一个由这些标记组成的新字符流。
1、内置分词器:char_group
char_group分词器会在遇到属于特定字符集的字符时,将文本拆分。
这种分词方式特别适用于那些需要简单自定义分词规则的情况,同时也不适合那些无法承受使用pattern分词器所带来的性能开销的场景。
可选配置:
tokenize_on_chars:这是一个包含用于对字符串进行分词处理的字符列表。每当遇到该列表中的某个字符时,就会开始一个新的分词单元。这些字符既可以是单个字符(例如 -),也可以是字符组合:空白、字母、数字、标点、符号。
max_token_length:token的最大长度。如果遇到超过此长度的token,那么它将会以 max_token_length 为间隔被分割开来。默认值为 255。
json
// 示例,通过空格、 - 、换行来分词
POST _analyze
{
"tokenizer": {
"type": "char_group",
"tokenize_on_chars": [
"whitespace",
"-",
"\n"
]
},
"text": "The QUICK brown-fox"
}
// 输出结果数组
The QUICK brown fox2、内置分词器:classic
classic 分词器是一种基于语法的分词工具,非常适合用于处理英语文档,除了英语,对其他语言不是很友好。
该分词器具备一些规则,可用于特别处理缩写词、公司名称、电子邮件地址以及互联网主机名等内容。
它会在遇到任何标点符号时对单词进行分割,并同时删除这些标点符号。不过,如果某个点后面没有跟随任何空白字符,那么这个点仍然会被视为该单词的一部分。
它会根据连字符来分割单词;但如果某个词中包含数字,那么整个词就会被视为产品编号而不会被分割。
它将电子邮件地址和互联网主机名视为一个统一的标识符。
可选配置:
max_token_length:token的最大长度。如果遇到超过此长度的token,那么它将会以 max_token_length 为间隔被分割开来。默认值为 255。
json
// 示例:
POST _analyze
{
"tokenizer": "classic",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// 结果数组:
[ The, 2, QUICK, Brown, Foxes, jumped, over, the, lazy, dog's, bone ]
json
// 示例:指定分词器,最大token为5
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "classic",
"max_token_length": 5
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_analyzer",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// 结果数组:
[ The, 2, QUICK, Brown, Foxes, jumpe, d, over, the, lazy, dog's, bone ]3、内置分词器:edge_ngram
edge_ngram分词器在遇到列表中指定的某个字符时,会首先将文本分解成单词;随后,它会为每个单词生成N-gram结构,其中N-gram的起始位置始终固定在该单词的开头。
在默认设置下,edge_ngram分词器会将输入的文本视为一个整体单元,并生成长度至少为1、最多为2的N-gram序列。
这些
默认的字符长度设置几乎毫无用处。在使用之前,你必须先对相关参数进行配置。
通常,我们建议在索引创建时和搜索时都使用相同的analyzer分词器。但对于edge_ngram分词器来说,建议则有所不同。只有在索引创建时使用edge_ngram分词器才是合理的,这样才能确保索引中包含那些不完整的单词,从而便于进行匹配操作。而在搜索时,则只需搜索用户输入的完整词汇即可(前缀匹配)。
json
// 示例
POST _analyze
{
"tokenizer": "edge_ngram",
"text": "Quick Fox"
}
// 结果数组
[ Q, Qu ]可选配置:
min_gram:一个"gram"中字符的最小长度。默认值为1。
max_gram:一个 Gram 中字符的最大长度。默认值为 2。(规定最大为10,因此长度超过10个字符的搜索词可能无法被搜索出来)
token_chars:应该被包含在标记中的字符类别。Elasticsearch会将对那些不属于所指定类别的字符进行分割处理。默认值为[](保留所有字符)。
custom_token_chars:应被视为令牌组成部分的自定义字符。(可选:letter - 字母、digit - 数字、whitespace - 空格、punctuation - 标点、symbol - 符号、custom - 自定义)
json
// 示例:将字母和数字都视为分词单元,并生成长度至少为2、最多为10的分词结果。
PUT my-index-00001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 10,
"token_chars": [
"letter",
"digit"
]
}
}
}
}
}
POST my-index-00001/_analyze
{
"analyzer": "my_analyzer",
"text": "2 Quick Foxes."
}
// 结果数组:(相当于会前缀匹配)
[ Qu, Qui, Quic, Quick, Fo, Fox, Foxe, Foxes ]
json
// 使用示例:
PUT my-index-00001
{
"settings": {
"analysis": {
"analyzer": {
"autocomplete": {
"tokenizer": "autocomplete",
"filter": [
"lowercase" // 小写
]
},
"autocomplete_search": {
"tokenizer": "lowercase" // 搜索分析器只需要转小写即可,不需要再经过tokenizer
}
},
"tokenizer": {
"autocomplete": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 10,
"token_chars": [
"letter"
]
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "autocomplete",
"search_analyzer": "autocomplete_search"
}
}
}
}
PUT my-index-00001/_doc/1
{
"title": "Quick Foxes" // 分词为:[qu, qui, quic, quick, fo, fox, foxe, foxes]
}
POST my-index-00001/_refresh
GET my-index-00001/_search
{
"query": {
"match": {
"title": {
"query": "Quick Fo", // 搜索[quick, fo],不需要再进行edge_ngram分词
"operator": "and"
}
}
}
}4、内置分词器:keyword
keyword 分词器接收任何输入的文本,然后将其原封不动地作为单个词项输出出来。
json
// 示例
POST _analyze
{
"tokenizer": "keyword",
"text": "New York"
}
// 结果数组:
[ New York ]可选配置:
buffer_size:在一次操作中读取到术语缓冲区中的字符数量。默认值为 256。术语缓冲区的容量会按照这个数值逐渐增加,直到所有文本都被读取完毕为止。建议不要更改这个设置。
json
// 通常与过滤器一起使用:
POST _analyze
{
"tokenizer": "keyword",
"filter": [ "lowercase" ],
"text": "john.SMITH@example.COM"
}
// 结果:转小写
[ john.smith@example.com ]5、内置分词器:letter
letter 遇到非字母字符,就会将文本分解成各个词素。但是对于汉语,通常支持不好,因为汉语不是用空格分隔的。
json
// 示例
POST _analyze
{
"tokenizer": "letter",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// 结果:
[ The, QUICK, Brown, Foxes, jumped, over, the, lazy, dog, s, bone ]6、内置分词器:lowercase
lowercase分词器每当遇到非字母字符时,它就会将文本分解成各个词素,同时还会将所有词素转换为小写形式。
从功能上来说,它相当于letter分词器与letter词元过滤器的结合体;不过它的效率更高,因为能够一次性完成这两项操作。
json
// 示例
POST _analyze
{
"tokenizer": "lowercase",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// 结果数组:转小写并且将单词分隔
[ the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ]7、内置分词器:ngram (可用,将词语拆成单个字)
ngram 首先将文本分解为单词,只要它遇到指定字符列表中的一个,然后它发出 指定长度的每个单词的 N 元语法 。
就像一个滑动窗口,可以在单词上移动-指定长度的连续字符序列。它们对于查询不使用空格或具有长复合词的语言(如德语)非常有用。
默认,ngram 标记器将初始文本视为单个标记,并生成最小长度为 1、最大长度为 2 的 N-gram。
json
// 示例
POST _analyze
{
"tokenizer": "ngram",
"text": "Quick Fox"
}
// 结果数组:
[ Q, Qu, u, ui, i, ic, c, ck, k, "k ", " ", " F", F, Fo, o, ox, x ]可选配置:
min_gram:一个字符的最小长度,默认1
max_gram:一个字符的最大长度,默认2
token_chars:应包含在标记中的字符类。Elasticsearch 将对不属于指定类的字符进行拆分。默认 [](保留所有字符)。(可选:letter - 字母、digit - 数字、whitespace - 空格、punctuation - 标点、symbol - 符号、custom - 自定义)
custom_token_chars:应视为标记一部分的自定义字符。
json
// 配置实例,最多一个字符,并且字母数字按照token处理
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ngram",
"min_gram": 1,
"max_gram": 1,
"token_chars": [
"letter",
"digit"
]
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_analyzer",
"text": "2 Quick Foxes.你好啊"
}
// 结果:
2 Q u i c k F o x e s 你 好 啊8、内置分词器:path_hierarchy (用于文件路径)
path_hierarchy 分词器会处理像文件系统路径这样的层次结构数据,根据路径分隔符对路径进行分割,并为路径中的每个组成部分生成一个对应的token。
json
// 示例:
POST _analyze
{
"tokenizer": "path_hierarchy",
"text": "/one/two/three"
}
// 结果数组
[ /one, /one/two, /one/two/three ]可选配置:
delimiter:用于作为路径分隔符的字符。默认值为 /。
replacement:一个可选的替换字符,用于作为分隔符。默认值为 delimiter。
buffer_size:指在一次操作中读取到术语缓冲区中的字符数量。默认值为 1024。术语缓冲区的容量会按照这个数值逐渐增加,直到所有文本都被读取完毕为止。建议不要更改这一设置。
reverse:如果设置为 true,则会以相反的顺序输出这些令牌。默认值为 false。
skip:需要跳过的初始令牌数量。默认值为 0。
json
// 示例:按照-字符来进行分割,并将这些字符替换为/。前两个被分成的"词元"会被忽略掉。
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "path_hierarchy",
"delimiter": "-",
"replacement": "/",
"skip": 2
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_analyzer",
"text": "one-two-three-four-five"
}
// 结果数组:
[ /three, /three/four, /three/four/five ]
// 如果我们将 reverse 设置为 true,那么就会产生如下结果:
[ one/two/three/, two/three/, three/ ]9、内置分词器:pattern
pattern 分词工具会使用正则表达式:一旦遇到单词分隔符,就会将文本分割成各个词元;或者,它会将符合正则表达式的整个文本片段直接作为词元来处理。
默认的模式是\W+,除了 a-zA-Z0-9_ 之外的所有字符。
json
// 示例
POST _analyze
{
"tokenizer": "pattern",
"text": "The foo_bar_size's default is 5."
}
// 结果:
[ The, foo_bar_size, s, default, is, 5 ]可选配置:
pattern:Java正则表达式,默认使用的是模式\W+。
flags:Java 正则表达式标志 。标志应采用管道分隔,例如"CASE_INSENSITIVE|COMMENTS"
group:应该提取哪个捕获组作为标记。默认值为 -1(即按该捕获组进行分割)。
json
// 示例:按照逗号进行分隔
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "pattern",
"pattern": ","
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_analyzer",
"text": "comma,separated,values"
}
// 结果数组:
[ comma, separated, values ]10、内置分词器:simple_pattern
simple_pattern 使用正则表达式来捕获符合条件的文本,并将其作为术语进行处理。虽然它所支持的正则表达式功能比pattern分词器要有限,但分词速度通常更快。
这个分词器使用了Lucene正则表达式。
可选配置:
pattern:Lucene正则表达式,默认值为空字符串。
json
// 示例:生成的token都为三位数
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "simple_pattern",
"pattern": "[0123456789]{3}"
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_analyzer",
"text": "fd-786-335-514-x"
}
// 结果:
[ 786, 335, 514 ]11、内置分词器:simple_pattern_split
simple_pattern_split 分词器会使用正则表达式,在匹配到相应模式时将输入内容分割成各个词元。虽然它所支持的正则表达式功能比pattern分词器要有限,但分词速度通常更快。
分词器使用了Lucene正则表达式,默认的模式是空字符串,这种模式会生成一个包含全部输入内容的术语。因此,这个分词器应该始终使用非默认的模式进行配置。
可选配置:
pattern:一个 Lucene 正则表达式,默认值为空字符串。
json
// 基于下划线分隔
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "simple_pattern_split",
"pattern": "_"
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_analyzer",
"text": "an_underscored_phrase"
}
// 结果数组:
[ an, underscored, phrase ]12、内置分词器:standard (默认)
standard 分词工具提供了基于语法的分词功能(其分词原理遵循Unicode标准附录#29中规定的Unicode文本分割算法),并且适用于大多数语言。
json
POST _analyze
{
"tokenizer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// 结果数组:
[ The, 2, QUICK, Brown, Foxes, jumped, over, the, lazy, dog's, bone ]可选配置:
max_token_length:令牌的最大长度。如果遇到超过此长度的令牌,那么它将会以 max_token_length 为间隔被分割开来。默认值为 255。
json
// 示例:将standard分词器的分词数量设置为5
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "standard",
"max_token_length": 5
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_analyzer",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// 结果数组:
[ The, 2, QUICK, Brown, Foxes, jumpe, d, over, the, lazy, dog's, bone ]13、内置分词器:thai (泰语)
thai分词器会使用Java自带的泰语分词算法来将泰语文本分割成单词。对于其他语言的文本,通常也会采用与standard分词器相同的方式进行处理。
json
POST _analyze
{
"tokenizer": "thai",
"text": "การที่ได้ต้องแสดงว่างานดี"
}
// 结果:
[ การ, ที่, ได้, ต้อง, แสดง, ว่า, งาน, ดี ]14、内置分词器:uax_url_email
uax_url_email 分词器与standard分词器类似,不同之处在于它能够将URL和电子邮件地址识别为独立的标记。
json
// 示例:
POST _analyze
{
"tokenizer": "uax_url_email",
"text": "Email me at john.smith@global-international.com"
}
// 结果:
[ Email, me, at, john.smith@global-international.com ]
// 而standard的分词器会产生如下结果:
[ Email, me, at, john.smith, global, international.com ]可选配置:
max_token_length:令牌的最大长度。如果遇到超过此长度的令牌,那么它将会以 max_token_length 为间隔被分割开来。默认值为 255。
json
// 示例:将uax_url_email分词器的分词数量设置为5(仅用于演示目的)。
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "uax_url_email",
"max_token_length": 5
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_analyzer",
"text": "john.smith@global-international.com"
}
// 结果数组:
[ john, smith, globa, l, inter, natio, nal.c, om ]15、内置分词器:whitespace
whitespace 分词器一遇到空白字符,就会将文本分解成各个词素。
json
POST _analyze
{
"tokenizer": "whitespace",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// 结果数组:
[ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog's, bone. ]可选配置:
max_token_length:令牌的最大长度。如果遇到超过此长度的令牌,那么它将会以 max_token_length 为间隔被分割开来。默认值为 255。
四、IK中文分词器
elasticsearch-analysis-ik: https://github.com/medcl/elasticsearch-analysis-ik/releases
1、什么是IK分词器
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行---个匹配操作,默认的中文分词是将毎个字看成一个词,比如"我爱狂神"会被分为"我""爱""狂"神",这显然是不符合要求的,所以我们需要安装中文分词器IK来解决这个问题。
如果要使用中文,建议使用IK分词器!
IK提供了两个分词算法: ik_smart和 ik_max_word,其中 ik_smart为最少切分,ik_max_word为最细粒度划分!
2、离线安装(下载与es对应的版本!!!否则会启动报错)
①下载完,解压到ES目录下
D:\es\elasticsearch-7.6.0\plugins\elasticsearch-analysis-ik-7.6.0
②重启es,会出现加载ik插件
bash
[2021-05-07T09:51:29,253][INFO ][o.e.p.PluginsService ] [DESKTOP-KAO1R1F] loaded plugin [analysis-ik]③使用elasticsearch-plugin.bat,查看插件

3、使用kibana测试
json
GET _analyze
{
"analyzer" : "ik_smart",
"text" : "中国共产党"
}
{
"tokens" : [
{
"token" : "中国共产党",
"start_offset" : 0,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 0
}
]
}
json
GET _analyze
{
"analyzer" : "ik_max_word",
"text" : "中国共产党"
}
{
"tokens" : [
{
"token" : "中国共产党",
"start_offset" : 0,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中国",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "国共",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "共产党",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "共产",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "党",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 5
}
]
}②有些词被拆分了,需要自己来配置分词
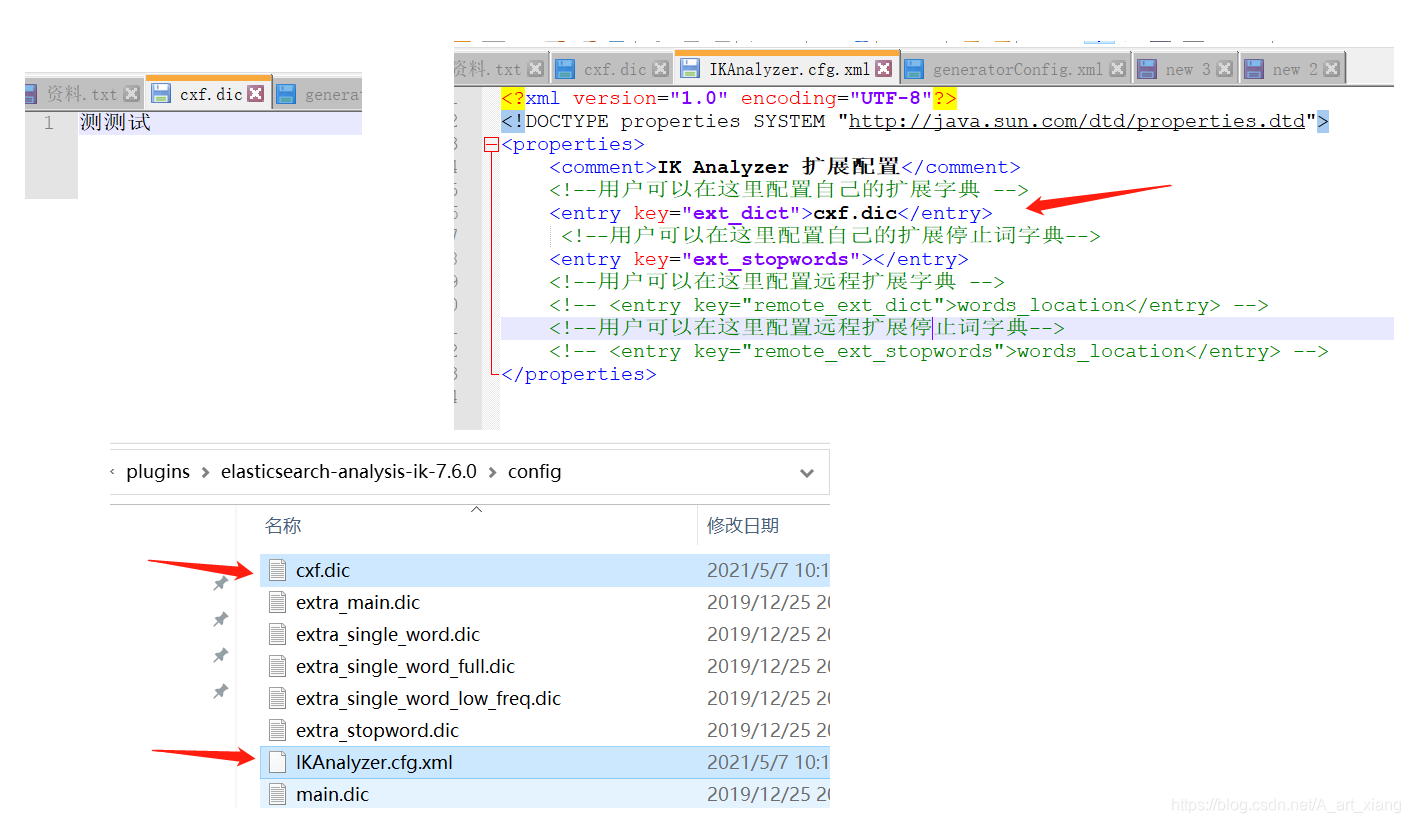
重启es看细节
bash
[2021-05-07T10:21:48,875][INFO ][o.e.g.GatewayService ] [DESKTOP-KAO1R1F] recovered [5] indices into cluster_state
[2021-05-07T10:21:49,223][INFO ][o.w.a.d.Monitor ] [DESKTOP-KAO1R1F] try load config from D:\es\elasticsearch-7.6.0\config\analysis-ik\IKAnalyzer.cfg.xml
[2021-05-07T10:21:49,228][INFO ][o.w.a.d.Monitor ] [DESKTOP-KAO1R1F] try load config from D:\es\elasticsearch-7.6.0\plugins\elasticsearch-analysis-ik-7.6.0\config\IKAnalyzer.cfg.xml
[2021-05-07T10:21:49,751][INFO ][o.w.a.d.Monitor ] [DESKTOP-KAO1R1F] [Dict Loading] D:\es\elasticsearch-7.6.0\plugins\elasticsearch-analysis-ik-7.6.0\config\cxf.dic4、在线安装
bash
# 拓展:可以在线安装
#查看已安装插件
bin/elasticsearch-plugin list
#安装插件
bin/elasticsearch-plugin install analysis-icu
#删除插件
bin/elasticsearch-plugin remove analysis-icu
json
# 测试分词效果
POST _analyze
{
"analyzer":"icu_analyzer",
"text":"中华人民共和国"
}
#ES的默认分词设置是standard,会单字拆分
POST _analyze
{
"analyzer":"standard",
"text":"青岛青岛青岛"
}
#ik_smart:会做最粗粒度的拆
POST _analyze
{
"analyzer": "ik_smart",
"text": "青岛青岛青岛"
}
#ik_max_word:会将文本做最细粒度的拆分
POST _analyze
{
"analyzer":"ik_max_word",
"text":"青岛青岛青岛"
}
json
# 创建索引时可以指定IK分词器作为默认分词器
PUT /es_db
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}5、拓展:查询指定索引分词器
json
GET /search_index/_analyze
{
"analyzer" : "search_index_analyzer",
"text" : "xxxxxxxxxxxxxxxx"
}