文章目录
- [1 概要](#1 概要)
- [2 AIPP](#2 AIPP)
-
- [2.1 什么是AIPP](#2.1 什么是AIPP)
- [2.2 AIPP都能做什么](#2.2 AIPP都能做什么)
- [2.3 如何使用AIPP的功能](#2.3 如何使用AIPP的功能)
-
- [2.3.1 静态AIPP](#2.3.1 静态AIPP)
- [2.3.2 动态AIPP](#2.3.2 动态AIPP)
- [3 本工程引入AIPP](#3 本工程引入AIPP)
-
- [3.1 aipp.cfg配置文件](#3.1 aipp.cfg配置文件)
- [3.2 推理过程函数更改](#3.2 推理过程函数更改)
- [3.3 效果](#3.3 效果)
- [4 总结](#4 总结)
- [5 其他章节](#5 其他章节)
1 概要
最近博主准备了一个可以检测车辆的网络模型,准备部署到华为和香橙派联合出版的香橙派 Ai Pro上(Oriange Pi Ai Pro),此推理板使用的是Ascend3130B4的芯片。其中,博主学习CANN
的相关知识以满足模型优化的需求。
具体的学习路径如下:
- 项目介绍
- 项目优化(AIPP的使用)
- 项目再次优化(AIPP+DVPP的使用)
硬件环境:
- 香橙派AI Pro (Ubuntu) : 用于部署最终的模型
- 宿主机(Windows):用于编写代码
整体流程:
在宿主机上编写完程序后通过Mobaxterm的SSH将文件上传到香橙派上,随后进行模型转换(.ONNX->.om),最后实现运行
2 AIPP
2.1 什么是AIPP
受网络结构和训练方式等因素的影响,绝大多数神经网络模型对输入数据都有格式上的限制。在计算机视觉领域,这个限制大多体现在图像的尺寸、色域、归一化参数等。如果源图或视频的尺寸、格式等与网络模型的要求不一致时,我们需要对其处理,使其符合模型的要求,这个操作,一般称之为数据预处理。

2.2 AIPP都能做什么

总结一下,虽然都是数据预处理,但AIPP与DVPP的功能范围不同(比如DVPP可以做图像编解码、视频编解码,AIPP可以做归一化配置),处理数据的计算单元也不同,AIPP用的AI Core计算加速单元,DVPP就是用的专门的图像处理单元。
AIPP、DVPP可以分开独立使用,也可以组合使用。组合使用场景下,一般先使用DVPP对图片/视频进行解码、抠图、缩放等基本处理,但由于DVPP硬件上的约束,DVPP处理后的图片格式、分辨率有可能不满足模型的要求,因此还需要再使用AIPP进行色域转换、抠图、填充等处理。
例如,在昇腾310 AI处理器,由于DVPP仅支持输出YUV格式的图片,如果模型需要RGB格式的图片,则需要再使用AIPP进行色域转换。
2.3 如何使用AIPP的功能
下文以此为例:测试图片分辨率为250250、图片格式为YUV420SP,模型对图片的要求为分辨率224 224、图片格式为RGB,因此需要通过AIPP实现抠图、图片格式转换2个功能。关于各种格式转换,其色域转换系数都有模板,可从《ATC工具使用指南》获取,参见"昇腾文档中心"。
2.3.1 静态AIPP
- 构造AIPP配置文件*.cfg。
抠图:有效数据区域从左上角(0, 0)像素开始,抠图宽高为224 224。
图片格式转换:输入图片格式为YUV420SP_U8,输出图片格式通过色域转换系数控制。
css
aipp_op {
aipp_mode : static # AIPP配置模式
input_format : YUV420SP_U8 # 输入给AIPP的原始图片格式
src_image_size_w : 250 # 输入给AIPP的原始图片宽高
src_image_size_h : 250
crop: true # 抠图开关,用于改变图片尺寸
load_start_pos_h: 0 # 抠图起始位置水平、垂直方向坐标
load_start_pos_w: 0
crop_size_w: 224 # 抠图宽、高
crop_size_h: 224
csc_switch : true # 色域转换开关
matrix_r0c0 : 256 # 色域转换系数
matrix_r0c1 : 0
matrix_r0c2 : 359
matrix_r1c0 : 256
matrix_r1c1 : -88
matrix_r1c2 : -183
matrix_r2c0 : 256
matrix_r2c1 : 454
matrix_r2c2 : 0
input_bias_0 : 0
input_bias_1 : 128
input_bias_2 : 128
}- 使能静态AIPP。
使用ATC工具转换模型时,可将AIPP配置文件通过insert_op_conf参数传入,将其配置参数保存在模型文件中。
css
atc --framework=3 --soc_version=${soc_version}
--model= $HOME/module/resnet50_tensorflow.pb
--insert_op_conf=$HOME/module/insert_op.cfg
--output=$HOME/module/out/tf_resnet50参数解释如下:
css
- framework:原始网络模型框架类型,3表示TensorFlow框架。
- soc_version:指定模型转换时昇腾AI处理器的版本,例如Ascend310。
- model:原始网络模型文件路径,含文件名。
- insert_op_conf:AIPP预处理配置文件路径,含文件名。
- output:转换后的*.om模型文件路径,含文件名,转换成功后,文件名自动以.om后缀结尾。- 调用AscendCL接口加载模型,执行推理。
2.3.2 动态AIPP
- 构造AIPP配置文件*.cfg。
css
aipp_op
{
aipp_mode: dynamic
max_src_image_size: 752640 # 输入图像最大内存大小,需根据实际情况调整
}- 使能动态AIPP。
css
atc --framework=3 --soc_version=${soc_version}
--model= $HOME/module/resnet50_tensorflow.pb
--insert_op_conf=$HOME/module/insert_op.cfg
--output=$HOME/module/out/tf_resnet50参数解释如下:
css
- framework:原始网络模型框架类型,3表示TensorFlow框架。
- soc_version:指定模型转换时昇腾AI处理器的版本,例如Ascend310。
- model:原始网络模型文件路径,含文件名。
- insert_op_conf:AIPP预处理配置文件路径,含文件名。
- output:转换后的*.om模型文件路径,含文件名,转换成功后,文件名自动以.om后缀结尾。- 调用AscendCL接口加载模型,设置AIPP参数后,再执行推理。
模型加载、执行可从参考往期的技术文章,请参见"基于昇腾计算语言AscendCL开发AI推理应用"。
调用AscendCL接口设置AIPP参数的代码示例如下:
css
aclmdlAIPP *aippDynamicSet = aclmdlCreateAIPP(batchNumber);
aclmdlSetAIPPSrcImageSize(aippDynamicSet, 250, 250);
aclmdlSetAIPPInputFormat(aippDynamicSet, ACL_YUV420SP_U8);
aclmdlSetAIPPCscParams(aippDynamicSet, 1, 256, 0, 359, 256, -88, -183, 256, 454, 0, 0, 0, 0, 0, 128, 128);
aclmdlSetAIPPCropParams(aippDynamicSet, 1, 2, 2, 224, 224, 0);
aclmdlSetInputAIPP(modelId, input, index, aippDynamicSet);
aclmdlDestroyAIPP(aippDynamicSet);3 本工程引入AIPP
本工程引入静态的AIPP
3.1 aipp.cfg配置文件
css
aipp_op {
aipp_mode: static
input_format : RGB888_U8 # 这里保持 RGB888_U8,表示输入是打包的3通道图像
src_image_size_w : 640 # 模型输入的宽
src_image_size_h : 640 # 模型输入的高
# 【关键点】开启 R 和 B 通道交换
# 你的输入是 BGR (OpenCV默认),开启这个后,AIPP 会把它转成 RGB 喂给模型
rbuv_swap_switch : true
# 归一化配置 (根据你的模型需求)
# 假设模型需要 input / 255.0
mean_chn_0 : 0
mean_chn_1 : 0
mean_chn_2 : 0
min_chn_0 : 0.0
min_chn_1 : 0.0
min_chn_2 : 0.0
var_reci_chn_0 : 0.003921568627451
var_reci_chn_1 : 0.003921568627451
var_reci_chn_2 : 0.003921568627451
}3.2 推理过程函数更改
原来的推理前处理部分:
css
def preprocess(self, img_data = None):
"""
对输入图像进行预处理,以便进行推理。
返回:
image_data: 经过预处理的图像数据,准备进行推理。
"""
if img_data is None:
print("error img datas, please check again")
#获取输入图像数据
self.img = img_data
# 获取输入图像的高度和宽度
self.img_height, self.img_width = img_data.shape[1], img_data.shape[0]
# 将图像颜色空间从 BGR 转换为 RGB
img = cv2.cvtColor(self.img, cv2.COLOR_BGR2RGB)
# 保持宽高比,进行 letterbox 填充, 使用模型要求的输入尺寸
img, self.ratio, (self.dw, self.dh) = self.letterbox(img, new_shape=(self.input_width, self.input_height))
# 通过除以 255.0 来归一化图像数据
image_data = np.array(img) / 255.0
# 将图像的通道维度移到第一维
image_data = np.transpose(image_data, (2, 0, 1)) # 通道优先
# 扩展图像数据的维度,以匹配模型输入的形状
image_data = np.expand_dims(image_data, axis=0).astype(np.float32)
# 返回预处理后的图像数据
return image_data现在的推理前处理部分
css
def preprocess(self, img_data):
# 1. 检查数据
if img_data is None:
print("error img datas")
return None
# 2. Resize (Letterbox)
# img 是 3D 数组: (640, 640, 3)
img, self.ratio, (self.dw, self.dh) = self.letterbox(img_data, new_shape=(self.input_width, self.input_height))
# 【关键修复1】self.img 用于后续画图,必须保持 3D (H, W, C)
self.img = img
# 3. 准备推理数据 (增加 Batch 维度)
# image_data 是 4D 数组: (1, 640, 640, 3)
image_data = np.expand_dims(img, axis=0)
# 【关键修复2】强制内存连续并深拷贝
# 很多时候 invalid input size 是因为 numpy 数组仅仅是一个 view(视图),
# 导致传给 C++ 层的指针指向了错误的内存地址或长度。
if not image_data.flags['C_CONTIGUOUS']:
image_data = np.ascontiguousarray(image_data)
# 强制做一次 copy,确保它是独立的内存块 (解决 5769 size error 的绝招)
image_data = image_data
# 【调试打印】如果还报错,请看终端打印的这个大小是否为 1228800
# print(f"DEBUG: Input shape: {image_data.shape}, Bytes: {image_data.nbytes}")
return image_data注意:AIPP的调用时刻:
outputs = model.execute(img_data, ),调用这个二函数后会将图像传给AI Core处理,之后再传回给模型进行推理。
3.3 效果
原来:
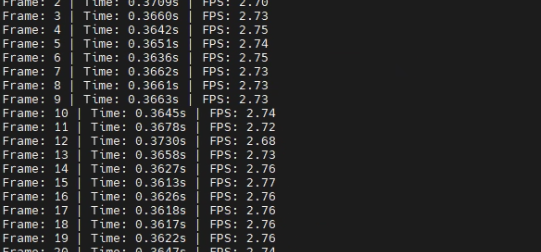
现在:
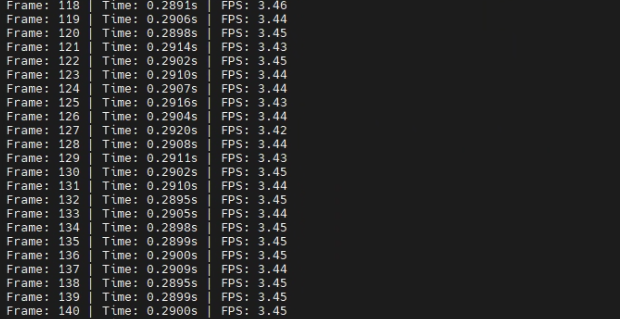
4 总结
本章节讲述了如何在模型推理的过程中使用AIPP。