对象的实例化
很多中、大厂面试题当中都有问到:
美团:
-
对象在
JVM中是怎么存储的? -
对象头信息里面有哪些东西?
蚂蚁金服:
二面:java对象头里有什么
对象创建方式
以下是常见的对象创建方式:
使用 new关键字
最常见、直接的对象创建方式、
User user = new User();new会触发:
-
堆中分配内存
-
执行构造方法
-
返回对象引用
在一些设计模式当中,例如通过单例模式或者工厂模式,对象创建依然会在内部使用 new ,但对外通过静态方法返回对象:
User user = UserFactory.createUser();使用Class.newInstance()(已经过时)
Class<?> clazz = User.class;
User user = (User) clazz.newInstance();问题:
-
只能调用无参构造方法
-
构造方法必须是public
-
异常信息不够清晰
在JDK9当中被标记为了deprecated,官方推荐使用:
clazz.getDeclaredConstructor().newInstance();使用 Constructor.newInstance()
通过反射获取构造器对象,然后调用:
Constructor<T>.newInstance()优点:
-
可以调用无参/有参构造器
-
可以访问非public 构造器(setAccessible)
示例:
通过getConstructor拿到对应参数列表的构造器,之后通过newInstance方法创建对象
Constructor<User> constructor =
//这里的两个class对象代表的是两个参数类型
User.class.getConstructor(String.class, int.class);
User user = constructor.newInstance("Tom", 20);通过clone()复制对象
对象可以通过clone方式创建。
要求:
-
类必须实现
Cloneable接口 -
重写
clone()方法 -
调用
super.clone()方法
示例:
User user2 = (User) user1.clone();特点:
-
不会调用构造方法
-
本质是内存复制
通过反序列化创建对象
对象在反序列化时也会被创建,例如:
ObjectInputStream ois =
new ObjectInputStream(new FileInputStream("obj.dat"));
User user = (User) ois.readObject();特点:
-
不会调用构造方法
-
对象属性来自于序列化数据
使用第三方库(例如Objenesis)
Objenesis可以在不调用构造方法的前提下创建对象。
重点解释:单例类当中的getInstance()方法
很多教材把这种方式写成:
单例类调用getInstance静态方法创建对象
更准确的说法是:
对象仍然是通过new创建的,但是创建方法封装在单例类内部
典型单例模式:
public class Singleton {
private static final Singleton INSTANCE = new Singleton();
private Singleton() {}
public static Singleton getInstance() {
return INSTANCE;
}
}使用的时候:
Singleton s = Singleton.getInstance();特点:
-
构造方法被private修饰
-
外部不能通过new创建单例对象
-
只能通过
getInstance()获取对象
补充:通过反射调用private构造器
若构造器是private:
private User(String name){}我们先通过Constructor拿到对应的构造器,之后通过setAccessble设置允许使用,之后通过private构造器创建对象
Constructor<User> c =
User.class.getDeclaredConstructor(String.class);
c.setAccessible(true);
User user = c.newInstance("Tom");对象创建步骤
示例代码:
public class ObjectTest {
public static void main(String[] args) {
Object obj = new Object();
}
}对应字节码:
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=2, args_size=1
0: new #2 // class java/lang/Object
3: dup
4: invokespecial #1 // Method java/lang/Object."<init>":()V
7: astore_1
8: return
LineNumberTable:
line 9: 0
line 10: 8
LocalVariableTable:
Start Length Slot Name Signature
0 9 0 args [Ljava/lang/String;
8 1 1 obj Ljava/lang/Object;
}对应的关键字解码:
0: new #2 // class java/lang/Object
3: dup
4: invokespecial #1 // Method java/lang/Object."<init>":()V
7: astore_1
8: return判断类是否已经加载
当JVM执行new指令的时候,会先检查:
常量池中是否存在该类的符号引用(new指令后面跟着的是常量池索引)
new #2
#2 → 常量池项并确该类是否已经加载完成,加载阶段(复习):
-
加载
-
链接
-
初始化
若该类尚未加载,JVM通过类加载器进行类的加载
加载流程概述:
-
ClassLoader查找对应的.class文件
-
解析字节码
-
方法区(例如MetaSpace)生成元类数据
-
堆当中生成对应的java.lang.Class对象
注意:
-
若找不到类,会抛出ClassNotFoundException
-
类存在但是加载失败,可能抛出NoClassDefFountError
为对象分配内存
类加载完成之后,JVM会在Java堆当中为对象分配内存
第一步:计算对象大小
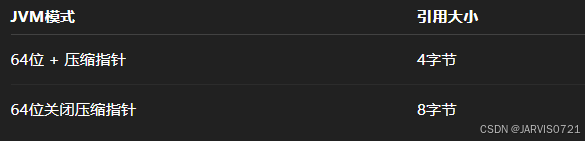
对象头+实例字段注意常见误区:
❌错误说法
引用变量只分配四个字节
正确说法:
-
引用类型字段只存储引用值
-
大小取决于JVM是否开启压缩指针
典型情况:
两种内存分配方式
指针碰撞(Bump The Pointer)
适用于堆内存规整的情况
结构:
已使用内存 | 空闲内存
↑
指针分配方式:
- 指针向后移动对象大小
通常出现在带 整理(Compact)阶段的垃圾收集器
例如:
-
Serial
-
Parallel
-
G1(局部区域)
空闲列表
适用于堆内存不规整的情况
JVM会维护可用内存块列表
分配流程概述:
-
找到足够大内存块
-
分配内存
-
更新列表
这种情况常见于:标记-清除(Mark-Sweep)
因为会产生内存碎片
处理并发分配问题
对象处理时高频操作,多线程环境当中我们要确保线程安全。
HotSpot主要通过两种机制保障:
CAS+重试
通过CAS(乐观锁)原子操作更新堆指针,失败的话进行重试。
TLAB
TLAB是线程私有的Eden小块内存
每个线程优先在自己的TLAB中分配对象。
优点:
-
避免线程竞争
-
减少CAS
注:
TLAB默认是开启的,对应指令
-XX:+UseTLAB初始化对象内存
JVM会将对象字段初始化为默认零值。
例如:
|---------|-------|
| 类型 | 默认值 |
| int | 0 |
| boolean | FALSE |
| 引用 | null |
(这里是给字段赋默认值,不是我们的初始化代码)
设置对象头
JVM通常会为对象写入对象头信息
对象头通常包括:
-
Mark Word,存储:
-
Hashcode(Object.hashCode())
-
GC年龄
-
锁状态
-
偏向锁信息
-
-
Klass Pointer
-
指向:类元数据
-
用于确定对象属于哪个类
-
注:
hashcode并不是在对象创建的时候就计算的,而是调用:
hashCode()
System.identityHashCode()JVM才会生成
执行构造方法
最后JVM执行:
invokespecial <init>完成对象初始化
执行内容包括:
-
实例变量赋值
-
实例代码块
-
构造方法代码
初始化顺序:
-
默认值初始化
-
显示赋值/实例代码块
-
构造方法
完成之后把 对象引用赋值给引用的变量
例如:
astore_1至此对象创建完成
对象内存布局
HotSpot JVM当中,一个java对象在对总内存布局通常包含三个部分:
-
对象头
-
实例数据
-
对齐填充
对象头
对象头是JVM用于管理对象元信息的区域。
HotSpot当中通常其由两部分组成:
-
Mark Word
-
Klass Pointer
若对象是数组,还有第三部分:
- Array Length
Mark Word 标记字段
用于存储运行时数据
在64位JVM当中通常占8字节。
Mark Word 内容通常随着对象状态变化而变化,EX:
-
hashcode:对象哈希值
-
GC Age :对象GC年龄(用于分代回收)
-
Lock Info: 锁信息(偏向锁、轻量锁、重量锁)
-
偏向锁信息:
-
Thread ID:偏向锁线程
-
Epoch: 偏向锁时间戳
-
Mark Word 重要特点:复用(复用同一块内存区域存储数据)
例如:

因此Mark Word是一个动态结构,随着对象在JVM运行过程中运行时状态改变,存储不同的数据信息。
Klass Pointer(类型指针)
用于指向所属类的元数据(元空间当中)
JVM通过 Klass Pointer确定:
-
对象属于哪个类
-
类有什么字段
-
类的方法表
-
虚方法表
在64位JVM且开启指针压缩情况下,
Klass Pointer = 4 bytes
否则:
Klass Pointer = 4 bytes
Array Length
只有数组对象才有这一部分
用于记录数组长度
原因:
-
普通对象:字段数量在类元数据当中确定
-
数组:长度是运行时期动态决定的
实例数据
实例数据用于存储 对象真正的成员变量
例如:
class User {
int id;
long score;
boolean active;
}对象实例当中包含:
id
score
active字段布局规则
HotSpot当中为减少内存浪费 ,会进行字段重排。
排序规则通常是:
long / double
int
short / char
byte / boolean
reference用于减少内存呢对齐浪费
引用类型字段
若字段是对象引用:
Object obj;
实例数据当中存储的是对象引用地址而不是对象本身。
对象本身仍然存储在堆中。
对齐填充
HotSpot要求:对象大小必须是8字节整数倍
原因:
-
CPU内存访问对齐
-
提高访问效率
若对象大小不是8字节整数倍
JVM会添加Padding
EX:
对象大小是14字节
JVM会添加2个字节的Padding
最终对象大小就是16字节
对象访问定位
背景
当Java代码当中出现:
Object obj = new Object();JVM当中 ,obj并不是对象本身,而是对象的引用(reference)
对象引用存储在栈帧的局部变量表当中
JVM规范当中并没有规定具体实现方式,因此不同的JVM采取不同策略
常见的两种实现方式:
-
句柄访问(Handle Access)
-
直接指针访问(Direct Pointer)
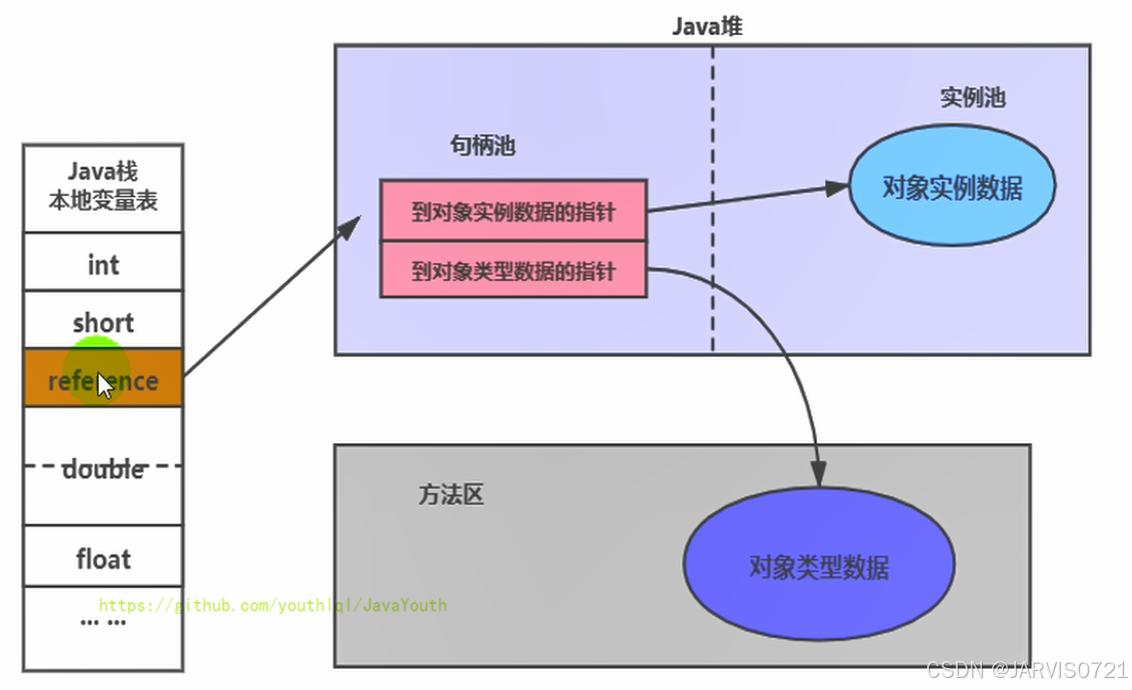
句柄访问
基本原理
这种方式中:
reference → 句柄(Handle) → 对象实例JVM会在堆中维护一块句柄池(Handle Pool)
句柄内部通常包含两个指针:
-
实例数据指针:指向堆内存当中对象实例
-
类型指针:指向类元数据
优点
最大优点:引用(reference)地址稳定,当GC移动对象(例如压缩整理)时,只需要修改句柄当中的实例指针
而引用本身不需要修改,引用稳定性更好
缺点
主要缺点:
-
需要额外维护句柄池,增加内存开销
-
访问对象需要两次指针跳转,访问性能略低
- 路径:reference→ handle → object
直接指针访问
基本原理
这种方式中,对象引用(reference)直接指向对象实例
没有句柄访问当中的类型指针,只能通过对象的对象头当中的类型指针指向类元数据
优点
最大优点:访问速度快
因为引用本身是直接指向对象本身的
只需要一次指针访问。
缺点
当GC移动对象时,对象存储地址发生改变
JVM当中所有指向这个对象的引用都要更新
(现代GC通过指针修复(Pointer Fixup)批量处理)
Hotspot实现方式
通过直接访问访问对象
reference = 对象地址
访问类元数据时:
reference
→ object
→ Klass Pointer
→ class metadata采用直接访问原因
-
减少一次指针访问
- 对象访问是Java当中最频繁的操作之一
-
当前GC已经可以高效修复引用
- 现代GC(例如G1/ZGC等)都有Pointer Fixup/Forwarding Pointer,对象移动成本相对可控