文章目录
- 背景
- 目标
- 前置pre
- [1,Defining model 定义模型](#1,Defining model 定义模型)
- [2,Training 训练](#2,Training 训练)
- [3,Performance 性能](#3,Performance 性能)
-
-
-
- 场景1:模型推理/预测阶段(最常用)
- 场景2:固定部分网络参数(冻结权重)
- 写法1:with语句(上下文管理器,推荐)
- [写法2:装饰器 @torch.no_grad()](#写法2:装饰器 @torch.no_grad())
-
-
- 4,总结一下我们的简易PyTorch代码模板
-
- 1,配置文件(configs/config.yaml)
- 2,数据流水线(src/dataset.py)
-
- 1,先回顾numpy手搓数据的"原始操作"
- 2,Dataset:"按需取一条数据"的工具
-
- [1. Dataset的核心作用](#1. Dataset的核心作用)
- [2. 怎么用Dataset?3步搞定](#2. 怎么用Dataset?3步搞定)
- [3. 举个例子](#3. 举个例子)
- 类比numpy:
- 3,DataLoader:"智能装Batch"的工具
-
- [1. DataLoader的核心作用](#1. DataLoader的核心作用)
- [2. 怎么用DataLoader?](#2. 怎么用DataLoader?)
- [3. 怎么用DataLoader训练?](#3. 怎么用DataLoader训练?)
- 类比numpy:
- 4,Dataset和DataLoader的关系总结
- 5,快速上手
- 3,模型定义(src/model.py):最核心的变化
-
- 一些需要注意的细节:
-
- [1,Sequential函数的调用:为什么要把 layers 列表转换为 nn.Sequential?](#1,Sequential函数的调用:为什么要把 layers 列表转换为 nn.Sequential?)
- 2,forward函数中为什么只需要写一行,我在调用self.network时发生了什么?
- 4,训练逻辑(src/trainer.py)
- 5,推理逻辑(src/predict.py)
- 6,辅助脚本(src/utils.py)
- 7,主板(main.py)
- 8,完全独立地加载模型进行推理(Inference)
- 5,总结
背景
接着该系列前面的博客:
Chap1:Neural Networks with NumPy(手搓神经网络理解原理)
Chap1-1 Numpy手搓神经网络---入门PyTorch
我们已经掌握了神经网络的基本模块结构、项目文件组织,
我们已经清楚了神经元在网络中的流动行为,
那么现在,就是趁热打铁、逐层递进,从纯数据分析Numpy进入深度学习工程化PyTorch的最好时机。
本篇博客,就是对Chap1的螺旋数据分类任务,正式使用PyTorch框架搭建1个正规的神经网络,让我们能够更加直观地分析Numpy和PyTorch搭建神经网络的异同点。
目标

前置pre
此处我们还是使用同Chap1中的模拟数据,也就是nnfs库中螺旋数据
python
!pip install nnfs然后导入一些必要的数据,nnfs库的一些细节我已经用libinspector解构过了,细节可以参考前面链接中的Chap1博客
python
import numpy as np
import matplotlib.pyplot as plt
import nnfs
from nnfs.datasets import spiral_data
nnfs.init()重要的点来了,本篇博客我们将要使用PyTorch
python
import torch
import torch.nn as nn
import torch.optim as optim这3行代码,想必是任何深度学习入门书中前几章常见的代码了,是Python中使用PyTorch(深度学习框架)时的核心导入语句,分别对应框架基础功能、神经网络构建、优化器工具:
import torch
导入PyTorch的核心模块,是使用框架的基础。该模块提供了多维张量(Tensor,类似NumPy数组但支持GPU加速)、张量的数学运算(如加减乘除、矩阵运算)、数据序列化(张量存储与读取)等核心功能,也是后续其他子模块的依赖基础。神经网络的参数本质就是张量,计算过程就是张量运算import torch.nn as nn
导入PyTorch专门用于构建神经网络 的子模块nn(neural network的缩写)。该模块封装了神经网络的核心组件,比如:- 基础层(如全连接层
nn.Linear、卷积层nn.Conv2d、循环层nn.RNN); - 激活函数(如ReLU、Sigmoid,通过
nn.ReLU、nn.Sigmoid调用); - 损失函数(如交叉熵损失
nn.CrossEntropyLoss、均方误差损失nn.MSELoss); - 网络容器(如
nn.Sequential,用于按顺序堆叠网络层),方便快速搭建完整神经网络结构。
- 基础层(如全连接层
import torch.optim as optim
导入PyTorch的优化器子模块 ,用于实现神经网络的参数更新(即"训练过程"中的梯度下降相关逻辑)。该模块提供了多种经典优化算法,比如:- 随机梯度下降(
optim.SGD); - 自适应学习率优化器(如
optim.Adam、optim.RMSprop);
后续可通过该模块实例化优化器,传入网络参数和学习率等超参数,在训练循环中调用optimizer.step()完成参数更新。
- 随机梯度下降(
简单当成import numpy/pandas,或者说sklearn的逻辑,
但是具体分析构建组件时需要sklearn的其他子模块,这些子模块之间是层级化的关系。
一些基础介绍:
torch模块能做什么(和numpy的比较)
python
?torch
- 能做的1:多维张量 + 数学运算
张量是 PyTorch 的基础数据结构(类比 NumPy 的数组,但支持 GPU 加速)。torch模块提供了张量的创建(torch.tensor())、形状变换(torch.reshape())、数学运算(加减乘除、矩阵乘法等)的核心接口。
这也是torch.nn和torch.optim能正常工作的基础------神经网络的参数本质就是张量,计算过程就是张量运算。 - 能做的2:高效序列化工具
序列化指的是将张量或模型等数据保存为文件,或从文件中加载的过程(我们前面在机器学习中pickle、json系列博客中提到过)。torch提供了torch.save()和torch.load()等接口,可用于保存训练好的模型参数、中间张量结果,方便后续复用或部署。 - 能做的3:CUDA 加速支持
这是 PyTorch 用于高性能计算的关键特性。只要我们的设备有符合要求的 NVIDIA GPU,就可以通过tensor.cuda()或tensor.to('cuda')将张量转移到 GPU 上运算,大幅提升神经网络的训练速度。
一些硬件、依赖库的检查与简要说明
重点是torch和对应编译的CUDA版本信息
python
torch.__version__, torch.version.cuda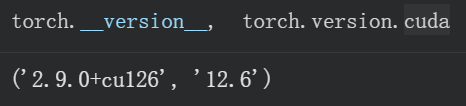
然后是其他的一些检查
python
import torch
import torch.nn as nn
import torch.optim as optim
# ===================== 1. 检查 PyTorch 核心版本 =====================
print(f"PyTorch 版本: {torch.__version__}")
# 总之估计检查什么模块, import torch.xx as xx, 就 xx is not None
print(f"torch.nn 模块是否可用: {nn is not None}")
print(f"torch.optim 模块是否可用: {optim is not None}")
# ===================== 2. 检查 CUDA 相关信息 =====================
print("\n===== CUDA 配置检查 =====")
# 检查 CUDA 是否可用(驱动+GPU 支持)
print(f"CUDA 是否可用: {torch.cuda.is_available()}")
if torch.cuda.is_available():
# CUDA 版本(PyTorch 编译时对应的 CUDA 版本)
print(f"PyTorch 编译的 CUDA 版本: {torch.version.cuda}")
# GPU 数量与名称
gpu_count = torch.cuda.device_count()
print(f"可用 GPU 数量: {gpu_count}")
for i in range(gpu_count):
print(f"GPU {i} 名称: {torch.cuda.get_device_name(i)}")
print(f"GPU {i} 计算能力: {torch.cuda.get_device_capability(i)}")
# 设置当前默认 GPU
# 明确将编号为「0」的 GPU 设为当前程序的默认 GPU。
# 后续代码中若未特别指定其他 GPU,所有需要调用 GPU 的计算(如模型加载、数据传输、梯度计算等)
# 都会自动在这块 GPU 上执行
torch.cuda.set_device(0)
print(f"当前使用的 GPU: {torch.cuda.current_device()}")
else:
print("警告: 未检测到可用 CUDA,将使用 CPU 训练(速度较慢)")
# ===================== 3. 检查 核心依赖库 版本 =====================
print("\n===== 核心依赖库检查 =====")
try:
import numpy
print(f"NumPy 版本: {numpy.__version__}")
except ImportError:
print("NumPy 未安装(部分数据处理功能可能受限)")
try:
import pillow
print(f"Pillow 版本: {pillow.__version__}")
except ImportError:
print("Pillow 未安装(图像数据加载功能受限)")
# 同理其他的一些核心依赖库也都可以检查
# ===================== 4. 检查 张量运算与 GPU 加速 =====================
print("\n===== 张量运算与 GPU 加速测试 =====")
# 创建测试张量
x = torch.randn(3, 3)
print(f"CPU 张量示例:\n{x}")
if torch.cuda.is_available():
# 张量转移到 GPU
x_gpu = x.cuda()
print(f"GPU 张量是否在 GPU 上: {x_gpu.is_cuda}")
# 测试 GPU 上的运算
y_gpu = x_gpu @ x_gpu # 矩阵乘法
print(f"GPU 张量矩阵乘法结果:\n{y_gpu}")
# ===================== 5. 检查 自动微分功能 =====================
print("\n===== 自动微分功能检查 =====")
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = x ** 2
z = y.sum()
z.backward()
print(f"张量梯度计算结果: {x.grad}")
print("自动微分功能正常" if x.grad is not None else "自动微分功能异常")输出信息如下
python
PyTorch 版本: 2.9.0+cu126
torch.nn 模块是否可用: True
torch.optim 模块是否可用: True
===== CUDA 配置检查 =====
CUDA 是否可用: True
PyTorch 编译的 CUDA 版本: 12.6
可用 GPU 数量: 1
GPU 0 名称: Tesla T4
GPU 0 计算能力: (7, 5)
当前使用的 GPU: 0
===== 核心依赖库检查 =====
NumPy 版本: 2.0.2
Pillow 未安装(图像数据加载功能受限)
===== 张量运算与 GPU 加速测试 =====
CPU 张量示例:
tensor([[ 0.1899, -0.6731, 1.3258],
[-1.1812, 0.1211, 0.0036],
[ 0.7011, -0.5506, -1.7120]])
GPU 张量是否在 GPU 上: True
GPU 张量矩阵乘法结果:
tensor([[ 1.7607, -0.9393, -2.0204],
[-0.3648, 0.8078, -1.5717],
[-0.4167, 0.4041, 3.8584]], device='cuda:0')
===== 自动微分功能检查 =====
张量梯度计算结果: tensor([2., 4., 6.])
自动微分功能正常总体来说,Torch版本和CUDA版本需要匹配对应(⚠️非常重要!)
细节可以参考我之前的博客:如何为我们的GPU设备选择合适的CUDA版本和Torch版本?
总之,我们每次都可以先检查一下配置环境中的Torch版本和CUDA版本,
这里有一个模块torch.cuda,是PyTorch 中专门用于管理 GPU 相关操作的模块,只有当环境中存在可用 GPU 且 PyTorch 安装了 GPU 版本(如基于 CUDA 的版本)时,该模块的功能才能正常使用。
1,Defining model 定义模型

1,定义神经网络类
在Chap1我们用Numpy手搓的神经网络中,
我们足足用了7个Class来定义我们模型的组件
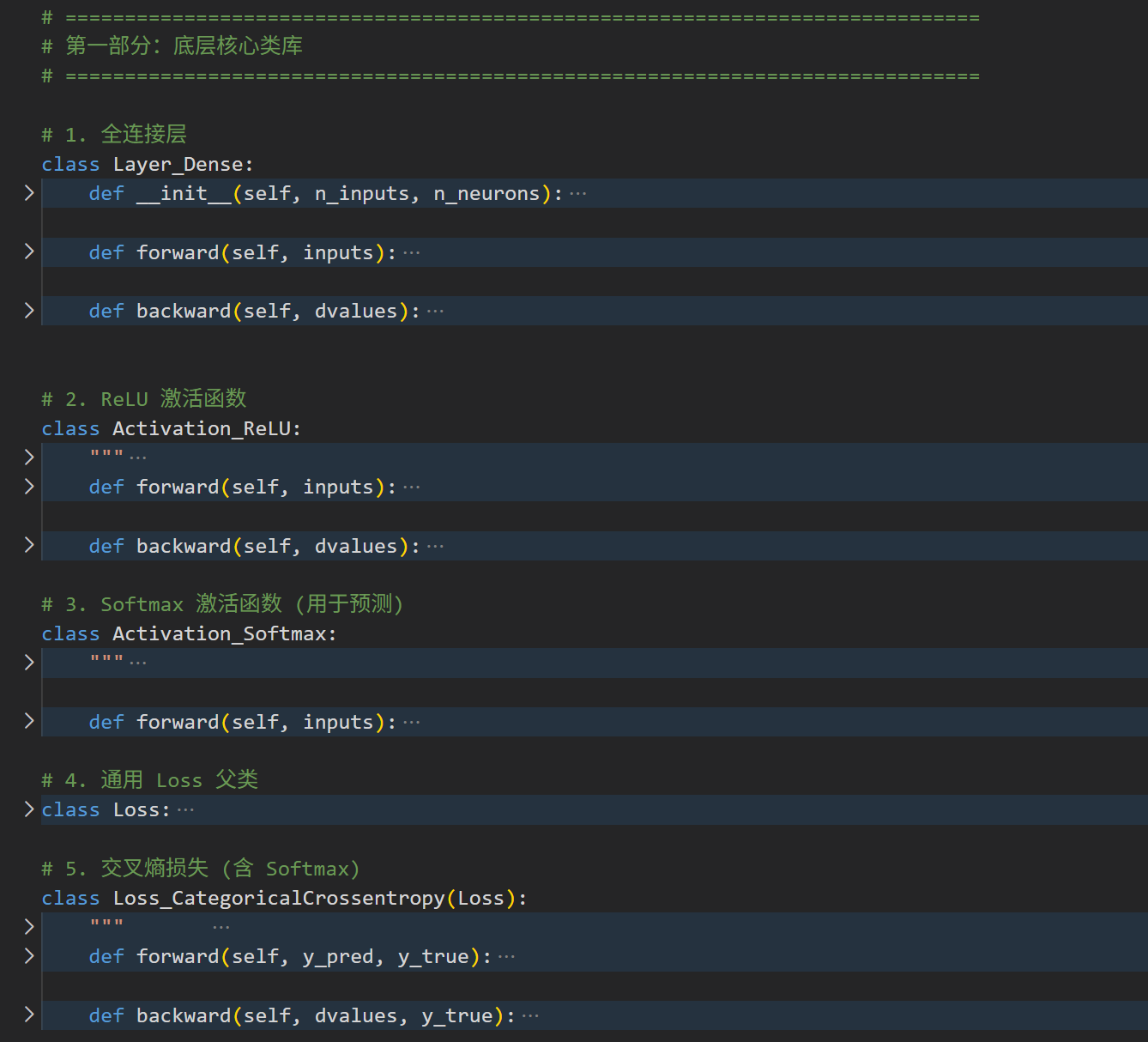
但是在使用PyTorch时,我们就不需要自己写那么多类了,我们只需要一个简简单单调用底层api的model框架类!
1个就够了!
python
# custom NN inheriting from nn.Module
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
# first dense (fully connected) layer with 2 input features, 64 output neurons
self.dense1 = nn.Linear(2, 64)
# define activation function (ReLU) for first hidden layer
self.relu1 = nn.ReLU()
# # second desne layer with 64 input neurons, 3 output neurons
self.dense2 = nn.Linear(64, 3)
# forward pass
# computes output of model given input data x
def forward(self, x):
# pass input x through first dense layer
x = self.dense1(x)
# apply ReLU activation function to output of first dense layer
x = self.relu1(x)
# pass output of ReLU activation function through second dense layer
x = self.dense2(x)
# return output of second dense layer
return x整体上都很好理解,就是一个简单的Python代码,
主要是下面这一行:
python
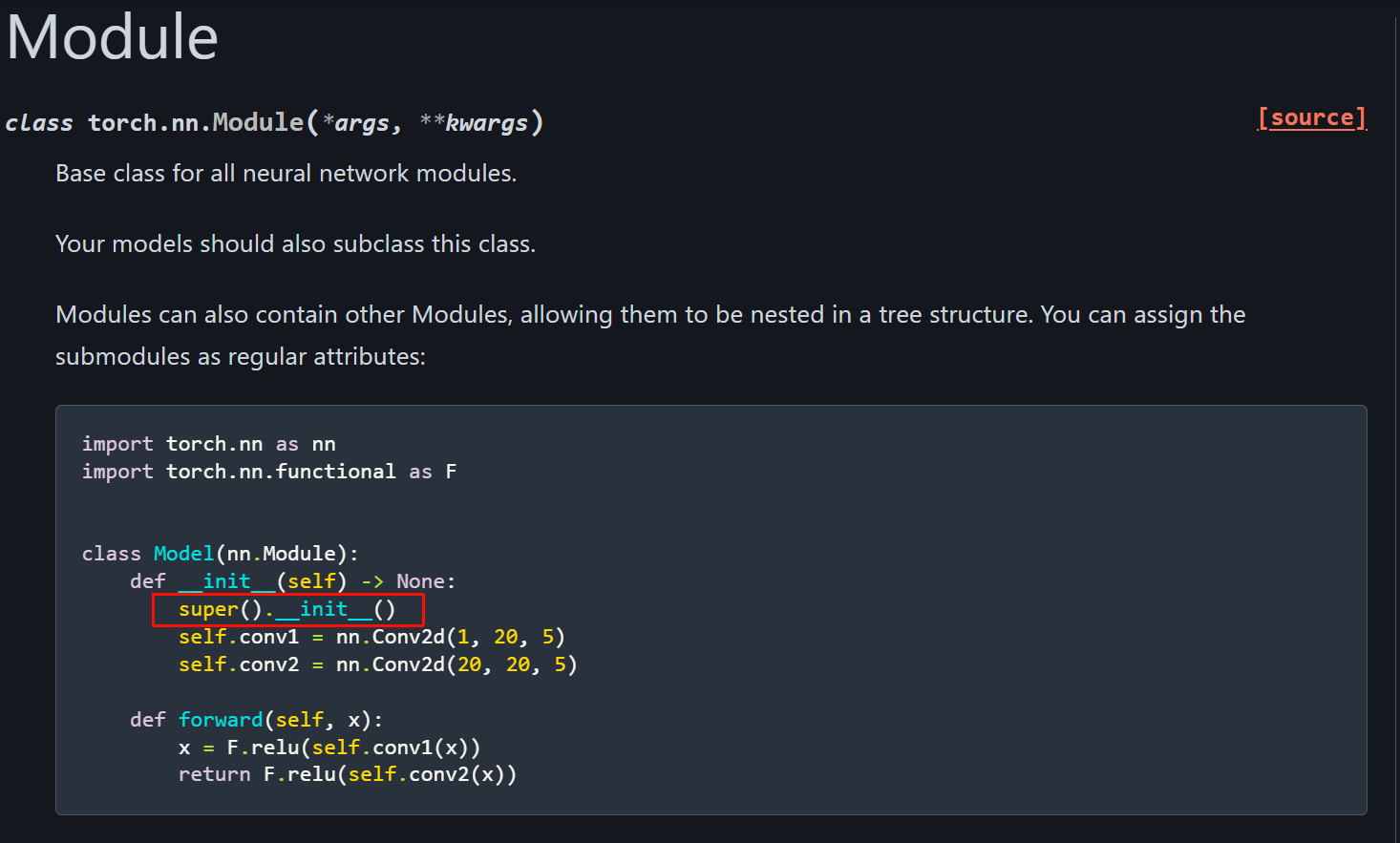
super(MyModel, self).__init__()父类初始化:必须调用!这行代码初始化了 PyTorch 的内部机制 (如将层注册到计算图、初始化参数管理系统等)。如果不写,模型根本跑不起来。
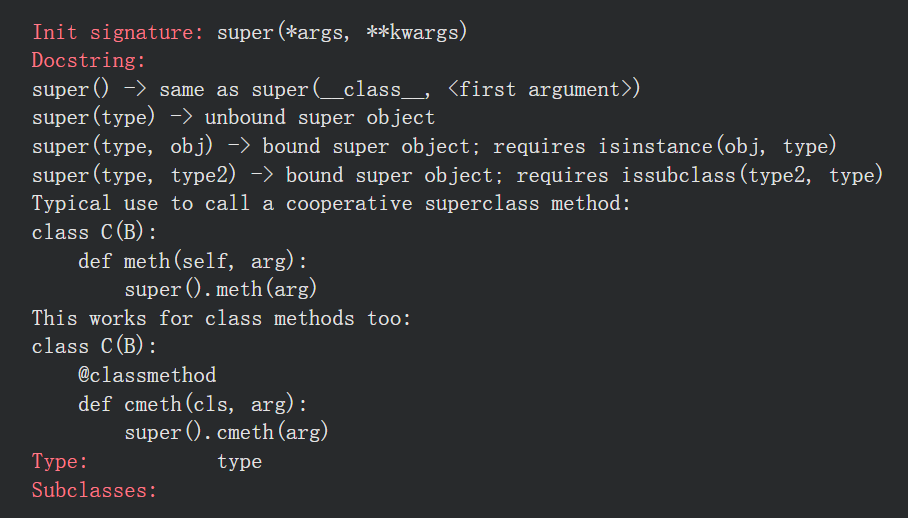
简单来说,我们自己定义的MyModel类继承了父类nn.Module,这里就是将MyModel的对象self,转化为类nn.Module的对象,然后用nn.Module的init初始化方法进行初始化,相当于MyModel有了父类初始化的那一套东西(可能写出来比较复杂)

参考:https://docs.pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module
- 本质:nn.Sequential 把一组子模块包装成一个可调用的 nn.Module。self.network = nn.Sequential(*layers) 会把 layers 中的每个子模块注册为当前模块的子模块(parameters/buffers/children 被正确跟踪),并实现了按顺序把输入张量传递给每个子模块的逻辑。
- 当你在 forward 中写 return self.network(x) 时,实际发生的是:
- 调用 nn.Module.call(处理 hooks、register/grad 等),然后执行 Sequential.forward。
- Sequential.forward 大致等价于:
for module in self._modules.values():
x = module(x)
return x
(即把 tensor 依次送进每个子模块,前一层的输出成为后一层输入) - 所有子模块的参数、状态会被 .to(device)/.train()/.eval()/state_dict() 等递归操作影响。
- 与手写 attribute + forward 的关系与区别:
- 等价性:功能上等价------你可以把每一层注册为属性(self.dense1, self.relu1, ...)并在 forward 中逐步调用,得到完全相同的计算图和参数管理。
- 优点(Sequential):代码更简洁、构建动态网络更方便、按列表顺序自动执行;适合"线性串联"模块。
- 限制(手写/复杂场景):如果需要分支、跳跃连接、多个输入/输出或某些层需要额外参数,手写 forward 或使用 nn.ModuleList 更灵活。
- 注册差别:把模块放进普通 Python list(self.layers = ...)不会自动注册;nn.Sequential/nn.ModuleList/赋给 self.attr 才会注册。
- 注意事项:
- 传入 activation=nn.ReLU() 时你把同一实例复用了------对无状态激活(ReLU)没问题,但对有状态层(BatchNorm、Dropout 带训练/推理行为除外)或需要独立实例的层,要每层创建新的实例(例如 activation_cls())。
- 若层需要额外参数或不同签名,不能用纯 Sequential。
示例(等价写法):
python
# python
seq = nn.Sequential(nn.Linear(10, 20), nn.ReLU(), nn.Linear(20, 5))
# 等价于
class M(nn.Module):
def __init__(self):
super().__init__()
self.l1 = nn.Linear(10,20)
self.a1 = nn.ReLU()
self.l2 = nn.Linear(20,5)
def forward(self, x):
x = self.l1(x)
x = self.a1(x)
x = self.l2(x)
return x总结:nn.Sequential 只是把"逐层调用"的样板代码封装并确保子模块被正确注册与管理,传入 x 时按顺序把张量传递给每一层并返回最终输出。
官方文档的说法是:
- 在 PyTorch 中构建模型通常通过继承 torch.nn.Module。
- 必须在子类的 init 中调用父类构造器(super(...).init()),并且应在注册子模块(self.conv = ...)之前调用。
- 推荐在 Python3 中直接使用 super().init()。
为什么要调用 super(...).init()?
- 调用 Module.init():初始化 nn.Module 的内部状态,包括:
- _parameters、_buffers、_modules 等内部字典;
- training 标志(train()/eval() 相关);
- hook 管理结构等。
- 启用特殊的 setattr 行为:Module.setattr 会拦截属性赋值并自动把赋予的 nn.Module / nn.Parameter / Tensor 注册到对应的内部字典(_modules/_parameters/_buffers)。如果不先执行父类构造器,这些内部字典未初始化,属性赋值不会被正确注册,从而导致参数不在 model.parameters() 中、不参与 to()/cuda()/state_dict() 等操作。
- 在多重继承或复杂基类情形中,正确调用父类构造器能保证父类的内部初始化逻辑被执行。
至于写法上,super(MyModel, self).init() vs super().init()
- 在 Python 3 中,推荐用 super().init()(更简洁且等价)。
- super(MyModel, self).init() 是 Python2/3 通用写法(显式写法),在单继承下两者效果相同。
简而言之,始终在子类 init 的首行(或至少在分配子模块之前,搭建静态网络结构前)调用 super().init(),这样才能正确注册子模块与参数,确保模型在训练/保存/迁移设备等场景下表现正常。
2,创建多分类数据集
现在我们来创建用于训练的数据集,训练数据和训练任务同Chap1。

这个训练任务就是一个简单的多分类任务,用的螺旋数据我们在该系列博客的Chap1、Chap1-1中都提到过:
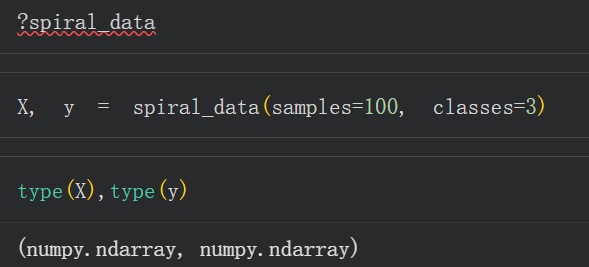
数据就是简单的Numpy中的多维数组,
但是我们现在不是在numpy中手搓网络,而是要用pytorch,所以我们得先把这个numpy中的多维数组数据转换为tensor张量,就用torch.tensor函数。
(PyTorch 模型只能处理张量(Tensor)格式数据,需将原始的 NumPy 数组(spiral_data 通常返回 NumPy 数组)转换为张量)
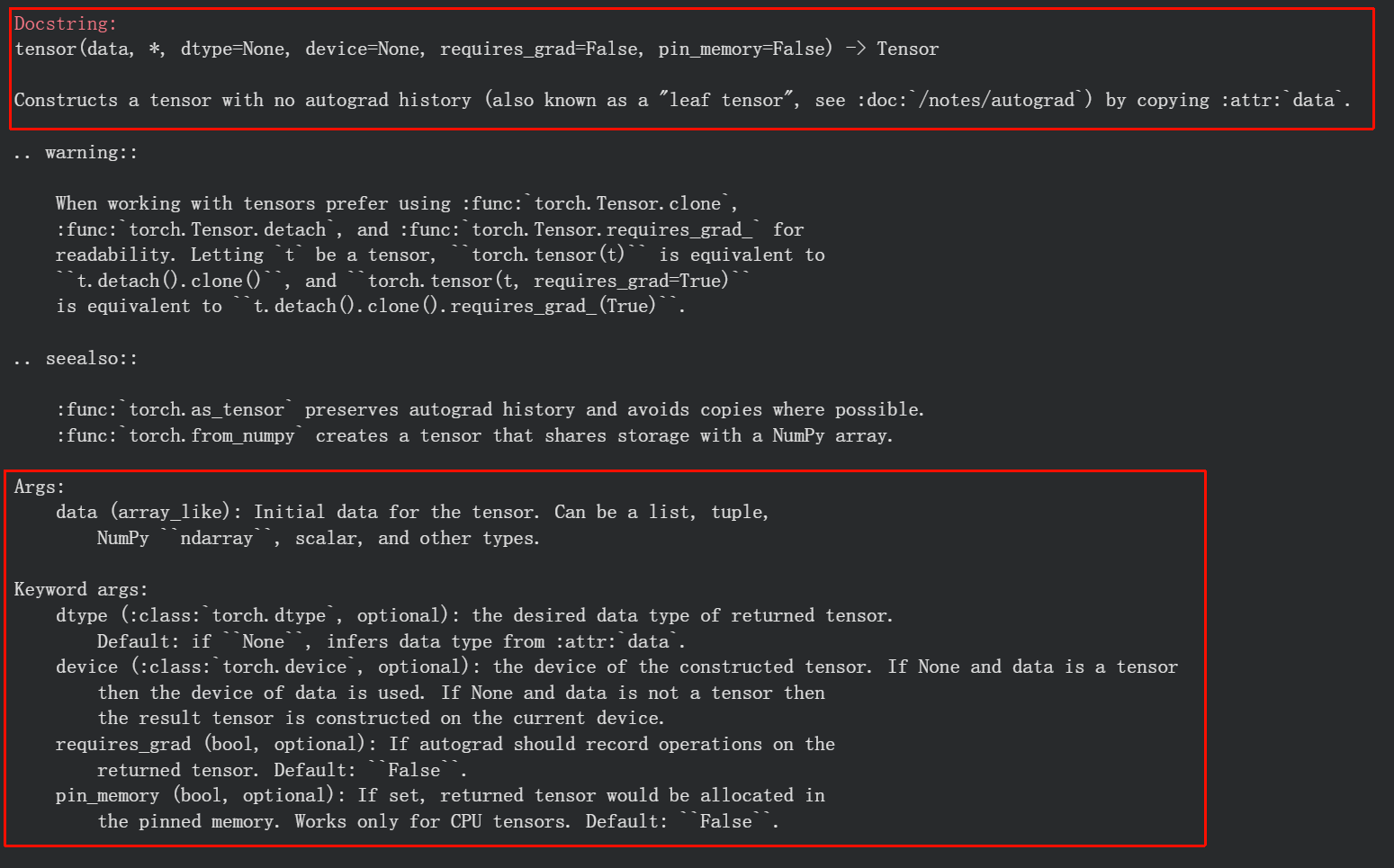
因为我们一般都是用Numpy用惯了,直接torch.tensor一键切换到torch,无缝衔接我们的数据科学
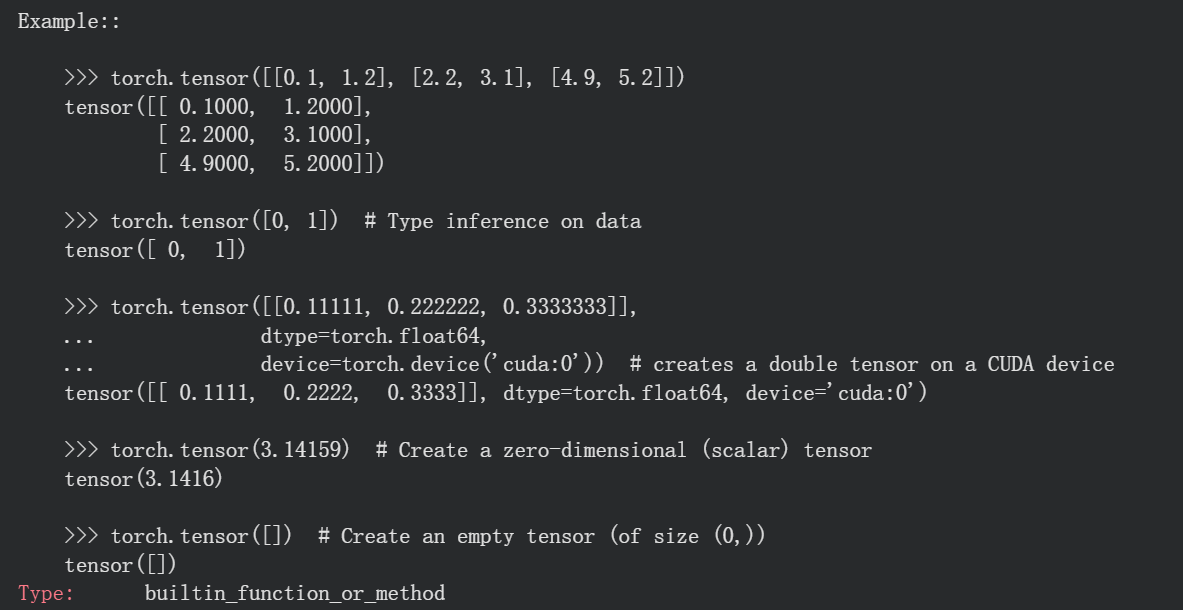
我们一般只需要注意输入数据以及dtype这两个参数即可,
然后因为是分类任务,feature就用float32,class用long

然后参考:https://docs.pytorch.org/docs/stable/generated/torch.Tensor.long.html
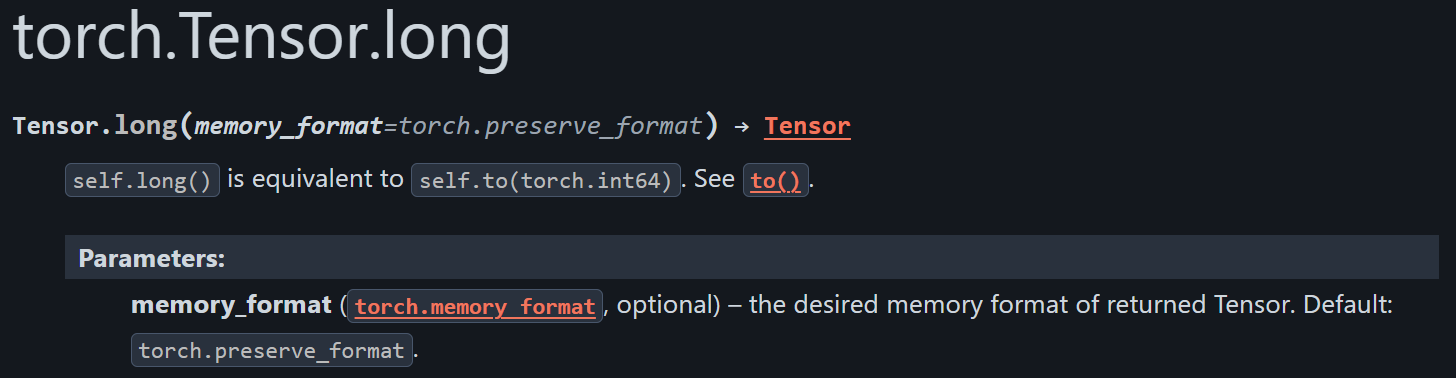
torch.long = torch.int64(64 位有符号整数),是分类任务标签的标准类型。
python
# generate data for a classification task
X, y = spiral_data(samples=100, classes=3)
# convert dataset to pytorch tensors
# PyTorch 模型只能处理张量(Tensor)格式数据,需将原始的 NumPy 数组(spiral_data 通常返回 NumPy 数组)转换为张量
# 特征通常为浮点类型, 一般默认用float32
X = torch.tensor(X, dtype=torch.float32)
# 分类任务的标签需为整数型(表示类别索引), long(64位整数)是 PyTorch 中交叉熵损失函数(CrossEntropyLoss)要求的标签类型
# 参考https://docs.pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html
# torch.long = torch.int64(64 位有符号整数),是分类任务标签的标准类型。
y = torch.tensor(y, dtype=torch.long)
# visualize dataset
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap='brg')3,实例化模型、损失函数和优化器

python
# 实例化model,指定loss和优化器
# Define the model
model = MyModel()
# Loss and optimizer
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.05, weight_decay=5e-7)这个没什么好说的,就是调用API;
需要注意的是这里的model.parameters()

这实际上,model.parameters 是 MyModel 类中继承自 nn.Module 的一个方法,所以打印的时候会显示<bound method Module.parameters of MyModel(...)>,
这是一个方法对象,而不是参数列表。
如果我们要查看具体的参数:
或者是打印出来
python
# 或者是
for name, p in model.named_parameters():
print(name, p.shape, p.requires_grad)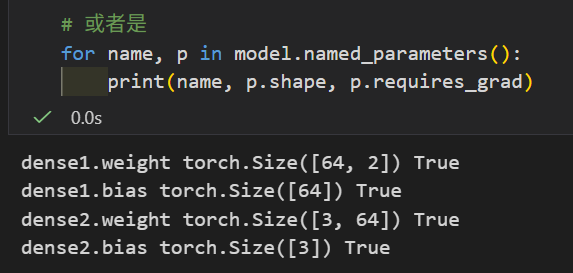
可以对照在model构建时网络层结构参数
直观逻辑上,我们会觉得参数反了。
对于全连接层 nn.Linear(in_features=I, out_features=O),直观上会认为 "权重矩阵是 I, O 形状"------ 因为单个样本输入是 I(I 个特征),要通过 "输入 × 权重矩阵" 得到 O(O 个输出),数学上需要满足 1, I × I, O = 1, O(矩阵乘法要求 "前矩阵列数 = 后矩阵行数")。
这时候看到 PyTorch 输出的权重形状是 O, I,就会觉得 "反了。
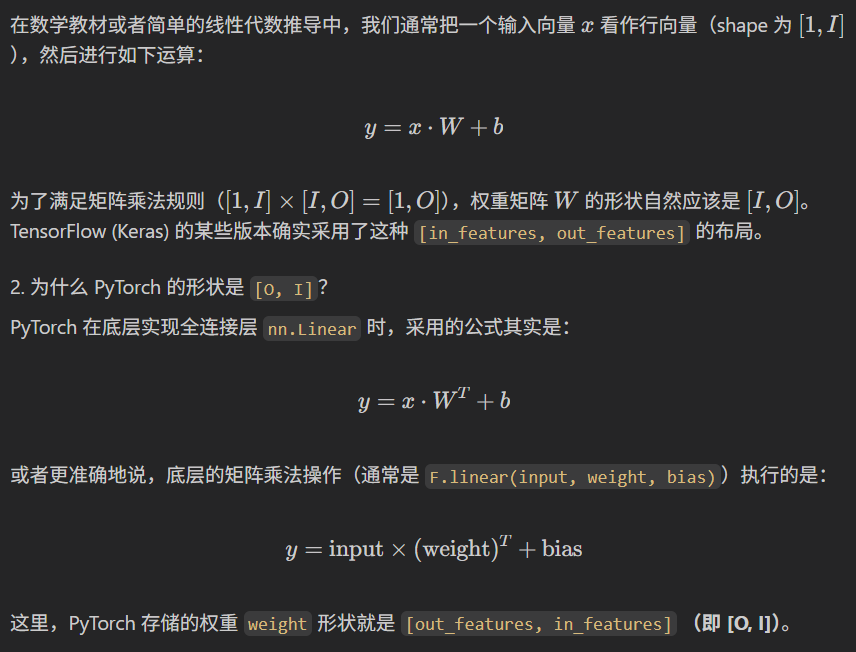
PyTorch中这样做是有深层原因的,主要是为了计算效率和底层实现的约定。
简单来说,如果权重的shape是output feature,input feature:
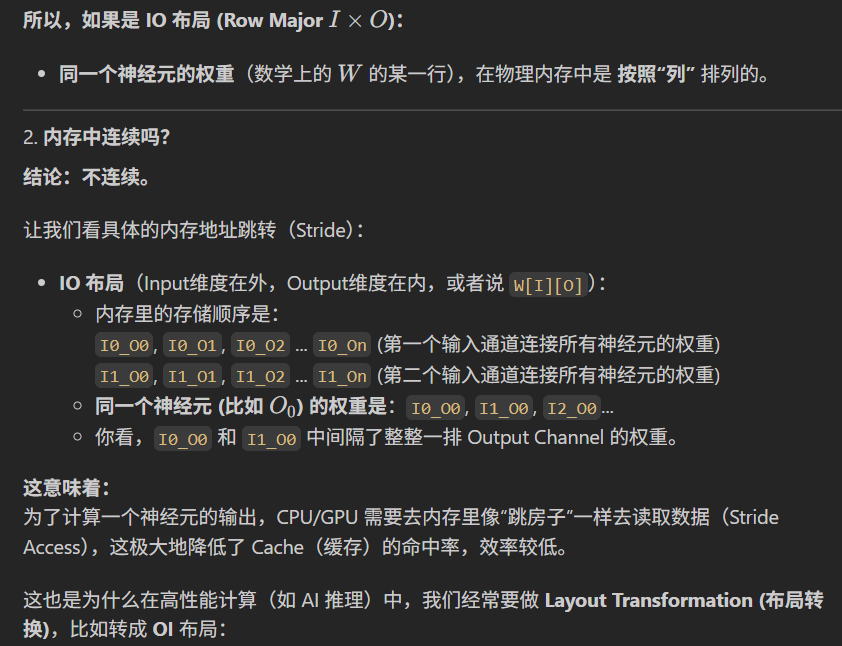
- 输出神经元的独立性:计算某一个输出神经元的值时,需要将该神经元对应的所有权重与输入向量做点积。
- 连续内存访问:如果权重矩阵的形状是
[O, I],也就是每一行对应一个输出神经元的所有权重。在内存中,行通常是连续存储的。- 当我们计算第 k 个输出时,CPU/GPU 可以快速读取第 k 行的连续内存块(包含所有相关的输入权重)。
- 相比之下,如果形状是
[I, O],那么描述同一个输出神经元的权重在内存中是跳跃分布的(步长为 OO),这会导致缓存命中率(Cache Hit Rate)降低,拖慢计算速度。
2,Training 训练

依据我们前面Numpy手搓神经网络的算法逻辑,一个正常的训练循环(每一个epoch轮次中),应该是下面这样的:
- 前向传播,也就是model接受输入数据X,然后经过内部层层计算(权重相乘、加偏置、激活函数等),然后得到输出结果outputs
- 实例化loss损失函数,衡量model的预测outputs和真实标签label的区别
- 反向传播与优化:我们每一轮epoch更新参数,每一轮batch批次需要当前批次的梯度来更新参数,而上一轮batch的原始梯度必须清零,但Adam会保留上一轮的动量信息,用于优化当前的更新方向,这里需要区分原始梯度和动量信息。
标准流程如下:

清空梯度和保留动量这两个概念这里很容易搞混,导致我们搞不清楚为什么每一轮epoch开始前都需要清空梯度信息。


还有一种想法会认为:不仅梯度(Gradient)决定方向,动量(Momentum)也决定方向。如果把梯度清零了,动量信息由于'依赖于梯度',难道不会也没了吗?
实际上是不会,因为这两个数值存储的位置不同,作用也不同。


好了,原理步骤就是上面这么简单,但是当我们开始传入数据的时候,问题来了:
我们的输入数据X传给model实例的哪个API接口?换句话说,哪个API接口认得,或者是能够合理处理我们的数据?
这是我们的model:
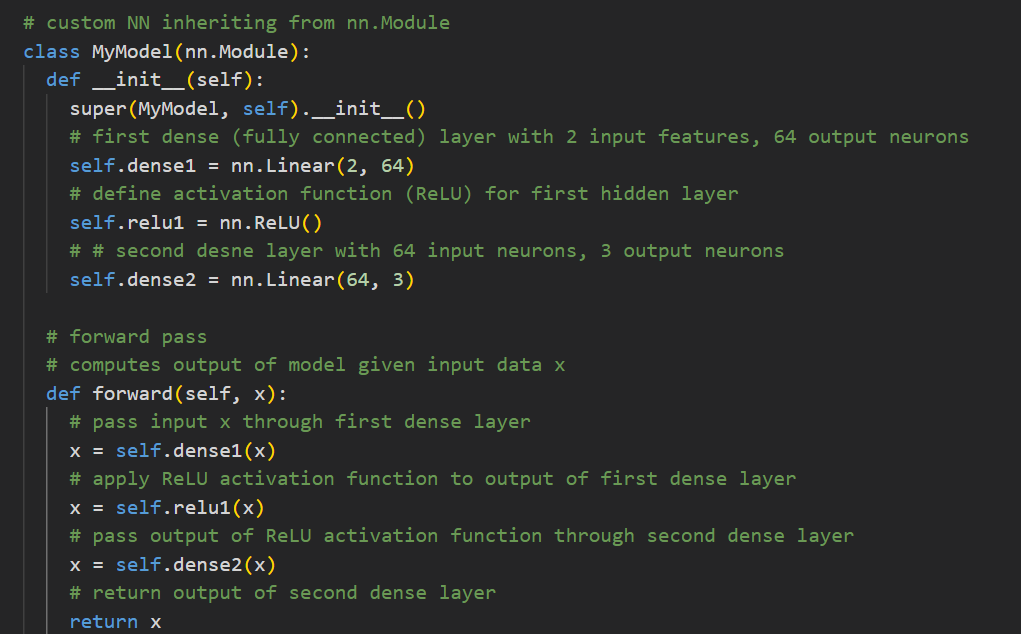
实例化后的:
我们可以看到,只有model的forward接口里有X,也就是只有forward接受输入数据。
但是!
我们实际的代码是下面这样的:
markdown
# Train in loop
for epoch in range(10001):
# Forward pass
outputs = model(X)
# Calculate the loss
loss = loss_function(outputs, y)
# Zero gradients, backward pass, and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Calculate accuracy
_, predicted = torch.max(outputs, 1)
accuracy = (predicted == y).float().mean()
# Print epoch, accuracy, loss, learning rate every 100 epochs
if epoch % 100 == 0:
print(f'Epoch: {epoch}, Accuracy: {accuracy.item():.3f}, Loss: {loss.item():.3f}, Learning Rate: {optimizer.param_groups[0]["lr"]}')这里很奇怪是不是:
为什么不用forward方法,而是用model实例本身,
如果model实例本身也作为一个函数调用的话,依据python中面向对象编程的常识,我们是默认这个类实现了一个内部的call方法,然后实例作为函数调用本事是调用其call方法。
也就是说,model(X)其实是model.call(X),因为我们就是想要简单的前向传播数据,
这里面不用model.forward(X),而是直接用model,难道其call内部实现就是调用self.forward?
如果是这样的话,那不是多此一举吗,我直接调用forward方法不就好了?
现实情况确实是这样的:

那么问题来了,除非这个call调用不是简单的self.forward,不然我们没必要绕来绕去!
现实情况是:虽然 call 最终会运行 forward,但它做的远不止这些。这是为什么官方强烈推荐使用 model(X) 而不是 model.forward(X) 的根本原因。
nn.Module 的 call 方法伪代码逻辑大致如下:
markdown
def __call__(self, input):
# 1. 处理 Hooks (钩子)
# 在 forward 执行之前,可能会有一些"前钩子"(Pre-hooks)需要运行
for hook in self._forward_pre_hooks.values():
hook(self, input)
# 2. 调用真正的 forward 函数
result = self.forward(input)
# 3. 处理 Hooks (钩子)
# 在 forward 执行之后,可能会有一些"后钩子"(Forward hooks)需要运行
for hook in self._forward_hooks.values():
hook_result = hook(self, input, result)
# ...处理钩子的返回值等
return result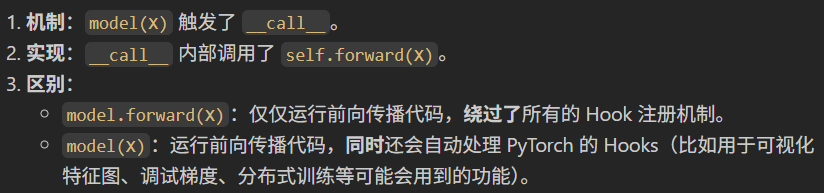
简单来说就是call继承的远远不止是父类的自动调用forward方法这么简单,所以我们也不能简单的self.forward

简单总结: model(x)** 等同于调用 model.__call__(x) ,而 __call__ 内部会去调 model.forward(x) ,而且父类nn.Module的 **nn.Module.__call__** 内部做了一些复杂的幕后工作(比如处理 Hooks)**
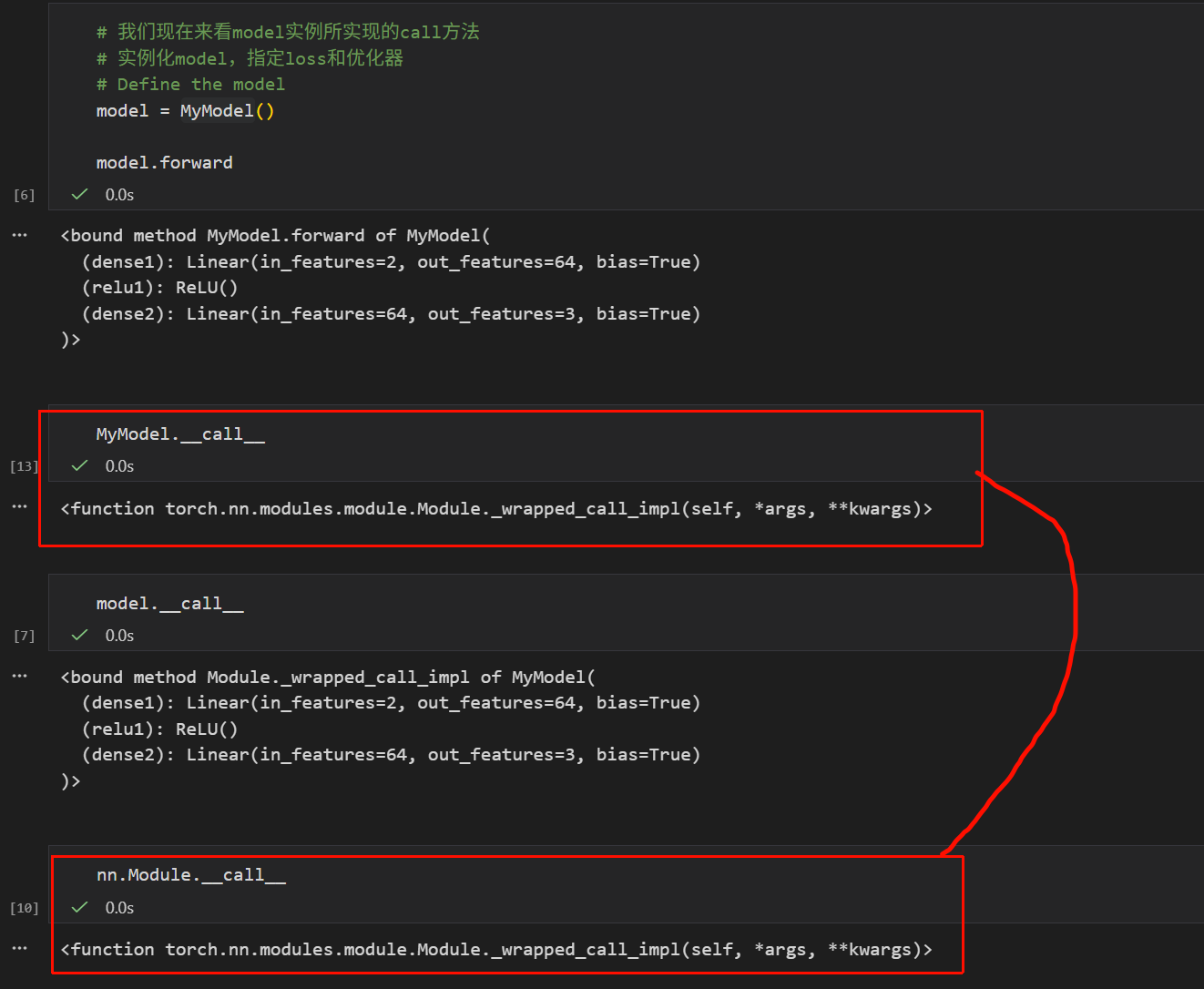
上面这个截图其实就很清晰了,我们能够非常明确地看到,实例model的call,其实是绑定类MyModel的Module._wrapped_call_impl函数,也就是继承自父类nn.Module的call方法。
这两个call就是同一个函数对象。
另外进源码可以看到:
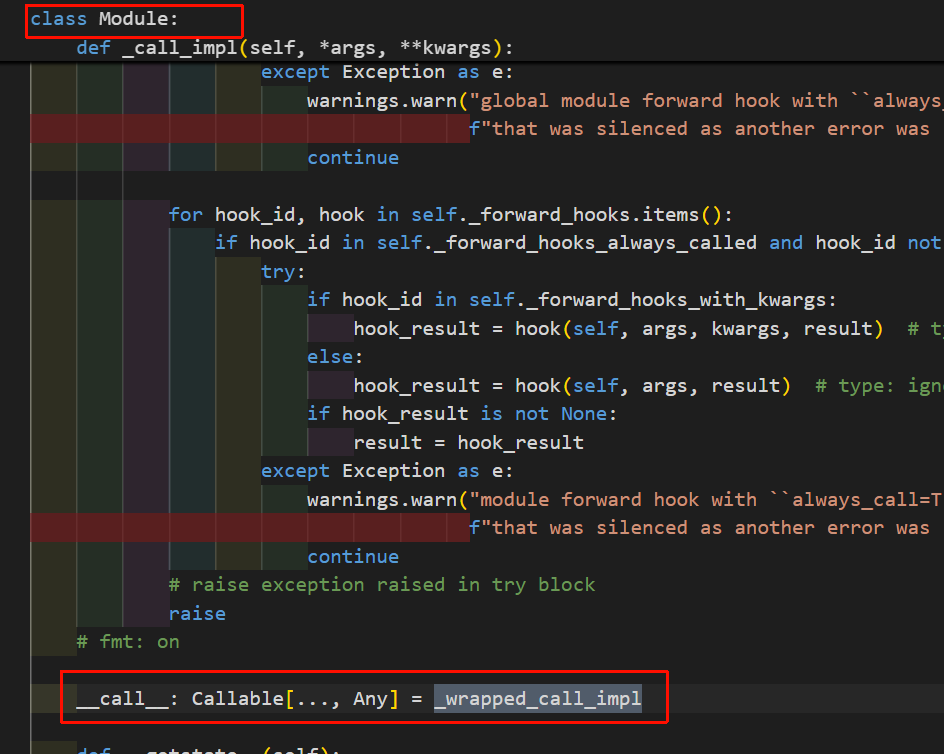
调用的call_impl比较长,简单说,这个函数的逻辑是默认情况下(未编译),模块走 _call_impl → 最终调用子类 forward

还有一个问题就是我们没有在call函数中显式声明x的形状,那为什么model(x)能够直接运行,我可以任意修改x的形状,它都不一定会报错,也就是它是如何知道x是什么样子的?
- 动态图机制 (Dynamic Computational Graph): PyTorch 是动态图框架。它不需要像早期的 TensorFlow 那样先定义好"水管多粗"(Input Shape),然后再通水。
- 运行时推断: 当我们把数据
x真正喂进去的那一刻(运行时),PyTorch 内部的操作(比如self.conv1(x))才会去检查x的形状。- 如果我们定义的卷积层
self.conv1期望输入是 3 通道,而我们的x只有 1 通道,程序会在运行的那一瞬间报错。 - 只要我们的
x形状符合我们在__init__中定义的层(比如 Conv2d, Linear)的要求,数据就会顺畅流过。
- 如果我们定义的卷积层

前面的训练流程理解了之后,我们再来看这里的outputs是什么,
这里我们以训练完成的最后一个epoch为例,
最后一个epoch的输出,也就是最后一次epoch的预测结果,
这个张量是一个300行的logits向量,每一行都是对1个样本在该次预测中的分类结果,
然后这里推荐一个vscode插件:data wrangler,
简单来说,Data Wrangler 是一个简化数据清理和准备的无代码工具,它提供了一个交互式用户界面,允许我们查看和分析数据,显示列统计信息和可视化内容。
我们就先来查看一下这个输出向量的一些统计可视化,注意,这个是logits向量,不是softmax归一化之后的概率,所以不是概率行向量,但是我们可以简单依据每一行max的索引,判断是分类到0、1、2这3类中的哪一类
然后就是看每一行也就是每一个样本输出结果的max值,其对应的index也就是索引处是label
至于torch.max看着很像numpy.argmax,
第2个参数就是axis,沿着什么轴
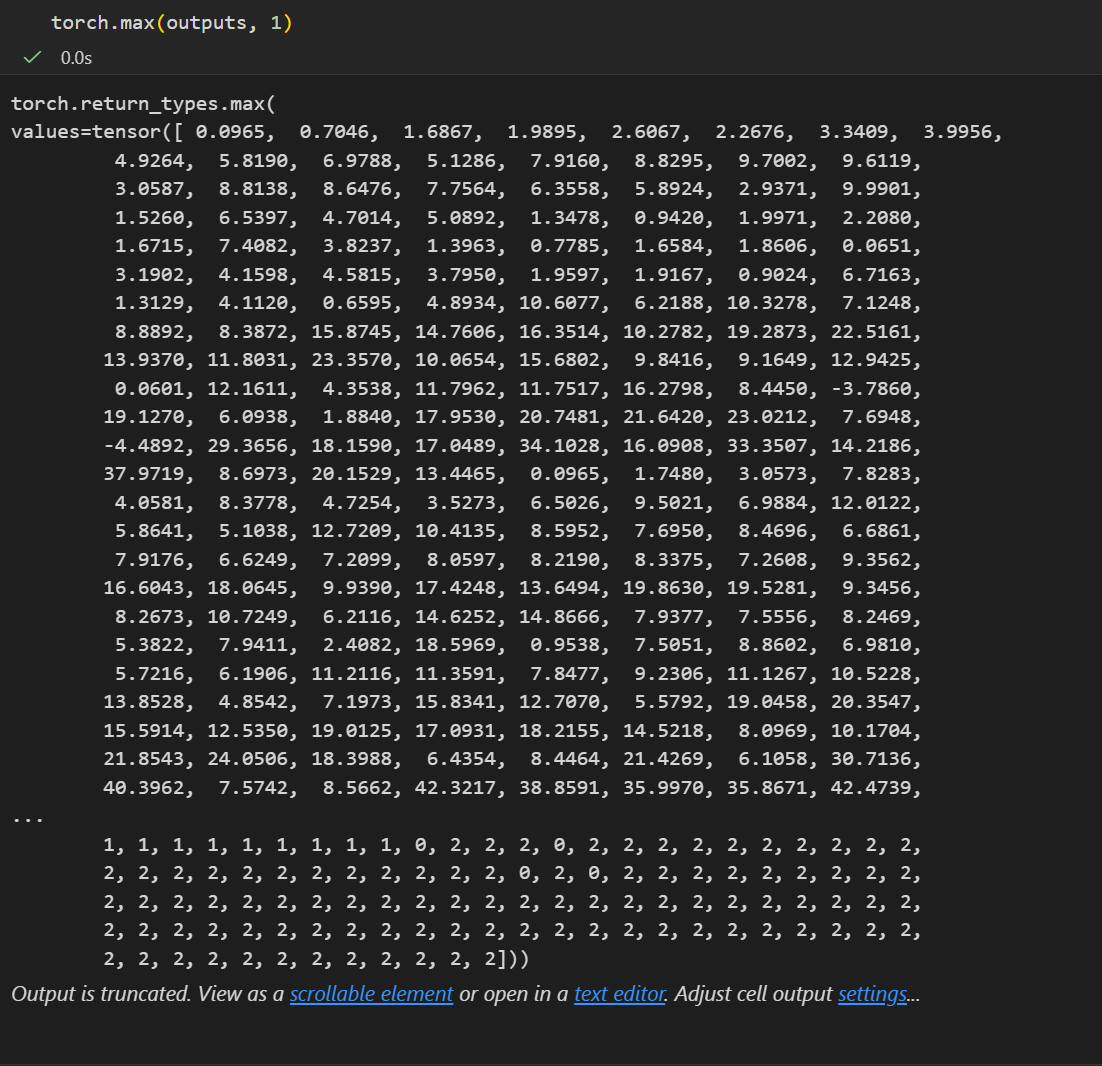
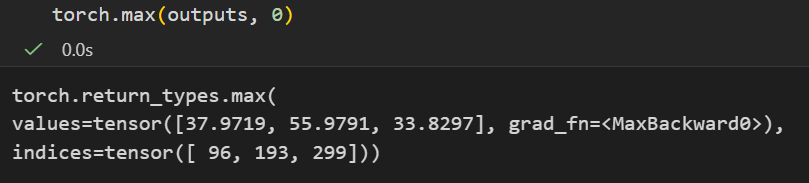
我们可以看到返回值其实是有两个键值对的,
所以我们是可以直接解包出来的:
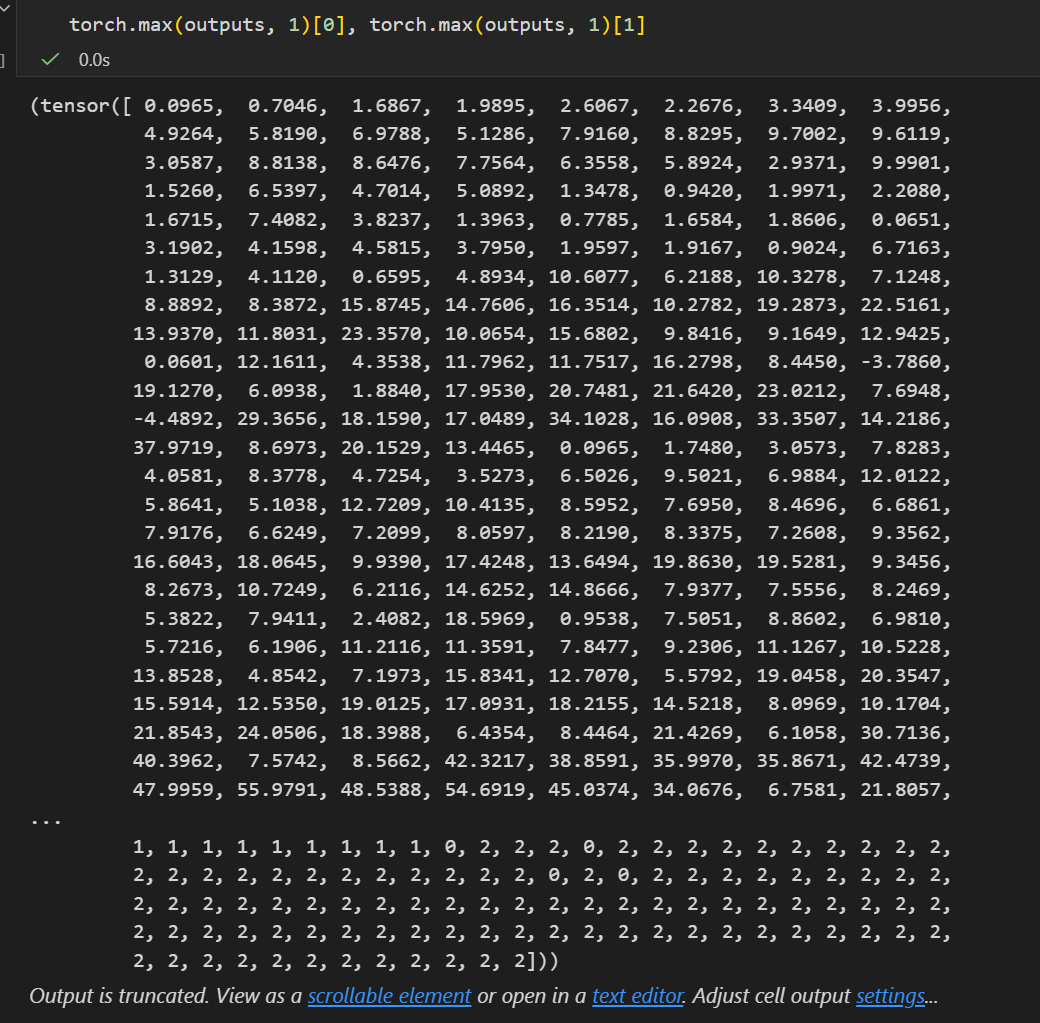
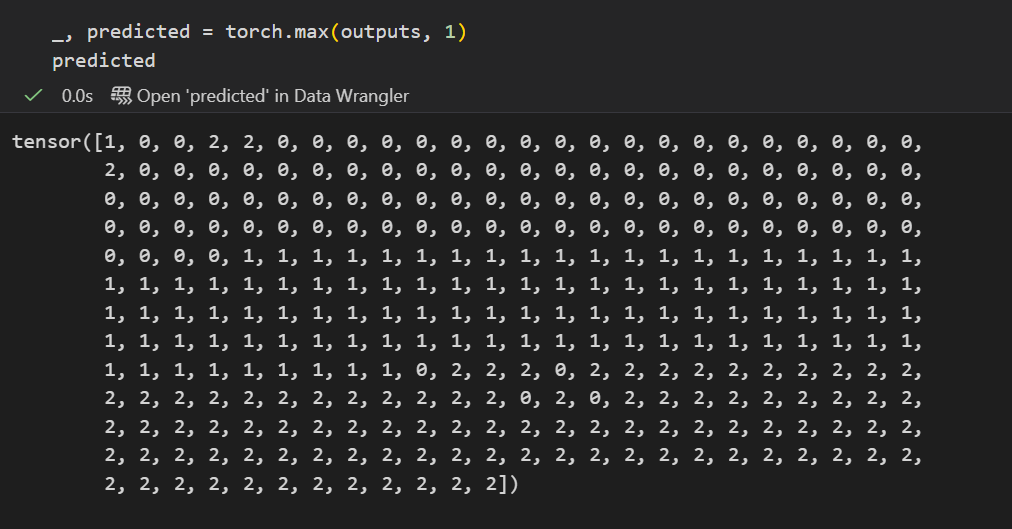
基本上最后一轮epoch预测返回的结果就是3类均分
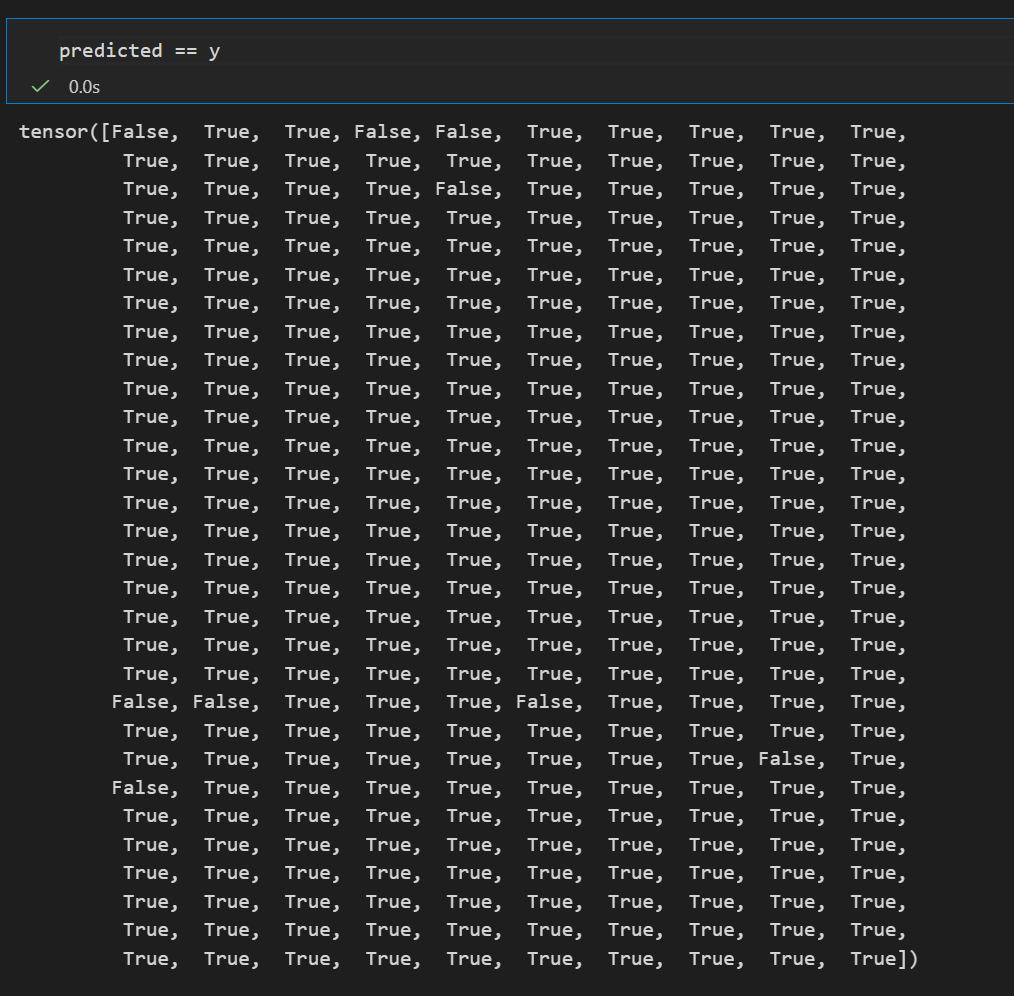
然后一整个tensor,布尔逻辑张量转换为01数值张量,再取均值就是准确率
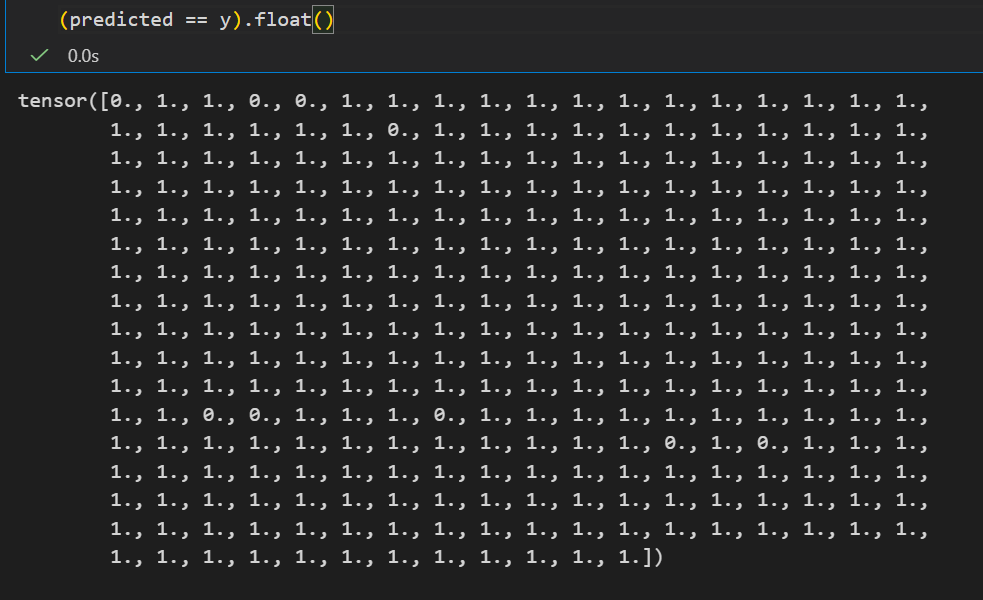
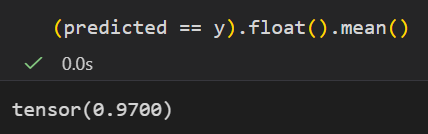
可以看到最后一个epoch训练下来,准确率已经能够达到97%了。
3,Performance 性能

这一块没什么好说的了,就是将训练好的model,用来在测试集上测试一下预测效果。
markdown
# 准备网格数据
# create meshgrid of points covering the feature space
# 定义网格的精细度
h = 0.02
# determine min and max values for x,y axes
# 计算坐标轴的绘图范围, 为了图好看, 在最大最小值基础上稍微外扩了一点±1
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
# create meshgrid of points with spacing h
# 生成从min到max每隔0.02也就是前面的分辨率h 一个点的序列
# 把这两个序列生成交叉的网格矩阵xx和yy, 它们包含了绘图区域内每一个像素点的坐标
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# convert meshgrid to torch tensor
# ravel把二维矩阵拉平成一维长条, 然后把这两个长条左右拼接起来, 变成1个形状为(N,2)的大数组
# 这就好比生成了成千上万个模拟数据点, 覆盖了整个画面区域
# 再将numpy数组转换为张量
meshgrid_points = torch.tensor(np.c_[xx.ravel(), yy.ravel()], dtype=torch.float32)
# pass meshgrid points through model
# 上下文管理器, 声明只是做推理(预测), 不需要计算梯度, 也不需要反向传播, 可以节省内存, 跑得快
with torch.no_grad():
# 下面几行都是在手动执行model的前向传播, 其实可以直接调用model(meshgrid_points)
# 但是没有这么做, 而是把model里的层拆开单独运行
# 如果只是运行forward方法的话,
# 其实只能拿到logits, 然后后面的softmax还是需要自己手动计算, 因为model中已经被封装合并在loss里了, 其实这一步还是要拆开
# forward pass through first dense
z1 = model.dense1(meshgrid_points)
# apply relu activation
a1 = torch.relu(z1)
# forward pass through second dense
z2 = model.dense2(a1)
# 然后是手写softmax函数并将输出logits转换为概率分布
# compute softmax probabilities for each class
exp_scores = torch.exp(z2 - torch.max(z2, axis=1, keepdim=True).values)
probs = exp_scores / torch.sum(exp_scores, axis=1, keepdim=True)
# predictions
# determine predicted class for each point in meshgrid
# 在概率最高的维度上获取最大值的索引, 也就是model对每一个网格点预测的类别(我们的背景中是0、1、2)
_, predictions = torch.max(probs, axis=1)
# reshape predictions to match shape of meshgrid
# 将预测结果转回numpy
# 也就是将拉平的一维结果重新还原为和xx一样的二维网格形状
Z = predictions.numpy().reshape(xx.shape)
# plot decision boundary based on predictions
# 依据网格坐标(xx,yy)+对应高度值(类别z)画出等高线填充图
plt.contourf(xx, yy, Z, cmap='brg', alpha=0.8)
# plot original data on top of decision boundary
# 在背景上上原始点
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap='brg')
# plot limits set to match extent of meshgrid
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.show()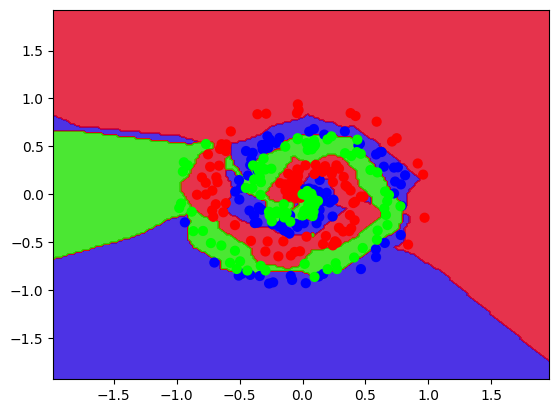
然后这里需要纠正1个新手很容易犯的误区,就是我们在推理的时候为什么要禁用梯度计算,
也就是一般很多入门教程中都会出现这句代码
markdown
torch.no_grad()很多人会好奇,我前向传播的时候也没有调用backward相关的函数API啊,为什么还要担心梯度计算会占用内存的问题,如果不计算内存,那我为什么不直接调用forward方法,然后加速推理呢?

我们先来稍微讲一下torch.no_grad()的作用:
torch.no_grad() 的唯一核心目的:在其包裹的代码块内,禁用所有张量的梯度计算与梯度追踪。
- 被它包裹的操作,不会为张量生成
grad_fn(梯度函数),也不会反向传播计算梯度grad; - 不会修改原张量的
requires_grad属性,只是「临时屏蔽梯度功能」。
然后核心使用场景如下:
场景1:模型推理/预测阶段(最常用)
模型训练完成后,做预测/验证/测试时,完全不需要计算梯度。
- 用
torch.no_grad()包裹推理代码,能大幅节省显存/内存开销(梯度会占用大量显存); - 同时能显著提升推理速度,避免了无用的梯度计算开销。
场景2:固定部分网络参数(冻结权重)
训练时如果想「冻结某几层权重不更新」(比如预训练模型微调),把这部分层的前向传播代码包裹在torch.no_grad()内,这部分层的参数就不会计算梯度,反向传播时也不会更新权重。
然后就是语法上,主流写法:
写法1:with语句(上下文管理器,推荐)
最规范的写法,局部生效 ,仅with代码块内禁用梯度,出了代码块自动恢复梯度计算,无副作用,优先用这种:
python
import torch
x = torch.randn(3,3, requires_grad=True) # 张量开启梯度追踪
with torch.no_grad():
y = x * 2 # 该操作无梯度追踪,y.requires_grad=False
z = y.mean()
# 出了no_grad,梯度功能自动恢复
w = x + 1 # w.requires_grad=True写法2:装饰器 @torch.no_grad()
针对整个函数生效,适合把「推理函数」整体标记为无梯度,代码更简洁:
python
@torch.no_grad()
def predict(model, x):
# 函数内所有操作都禁用梯度,专门用于推理
return model(x)
# 调用时直接用,无需额外包裹
output = predict(my_model, test_data)一些需要注意的细节:
- 只读不修改 :不会改变张量本身的
requires_grad属性(比如原张量是True,包裹后还是True,只是临时失效); - 反向传播无效 :
no_grad内的操作,即使调用loss.backward(),也不会为相关参数计算梯度,参数权重不会更新; - 仅对浮点张量有效 :PyTorch中只有浮点型张量(float32/float64) 能计算梯度,整型/布尔型张量本身无梯度,用不用
no_grad无影响。
与 torch.set_grad_enabled(False) 的区别,很多人会混淆这两个功能,核心差异只有「作用范围」:
torch.no_grad()→ 「局部生效」:只作用于包裹的代码块/装饰的函数,不影响全局;torch.set_grad_enabled(False)→ 「全局生效」:执行后,整个程序的梯度计算都被禁用,需要手动调用torch.set_grad_enabled(True)恢复。
结论:优先用 torch.no_grad(),因为无全局副作用,代码更安全,不会忘记恢复梯度导致训练失败。
torch.no_grad() 是PyTorch的无梯度上下文管理器,核心是「禁用梯度计算」,主要用在模型推理提速省显存,语法支持with语句和装饰器,局部生效、无副作用,是PyTorch开发的高频API。
回到我们的问题,误区在哪里呢?
误区在于,forward前向传播时,其实是默认会计算梯度的!
还记得我们前面输出model参数的时候吗,模型的层(比如说我们这里的dense1、dense2)的参数张量,默认都是requires_grad=True,
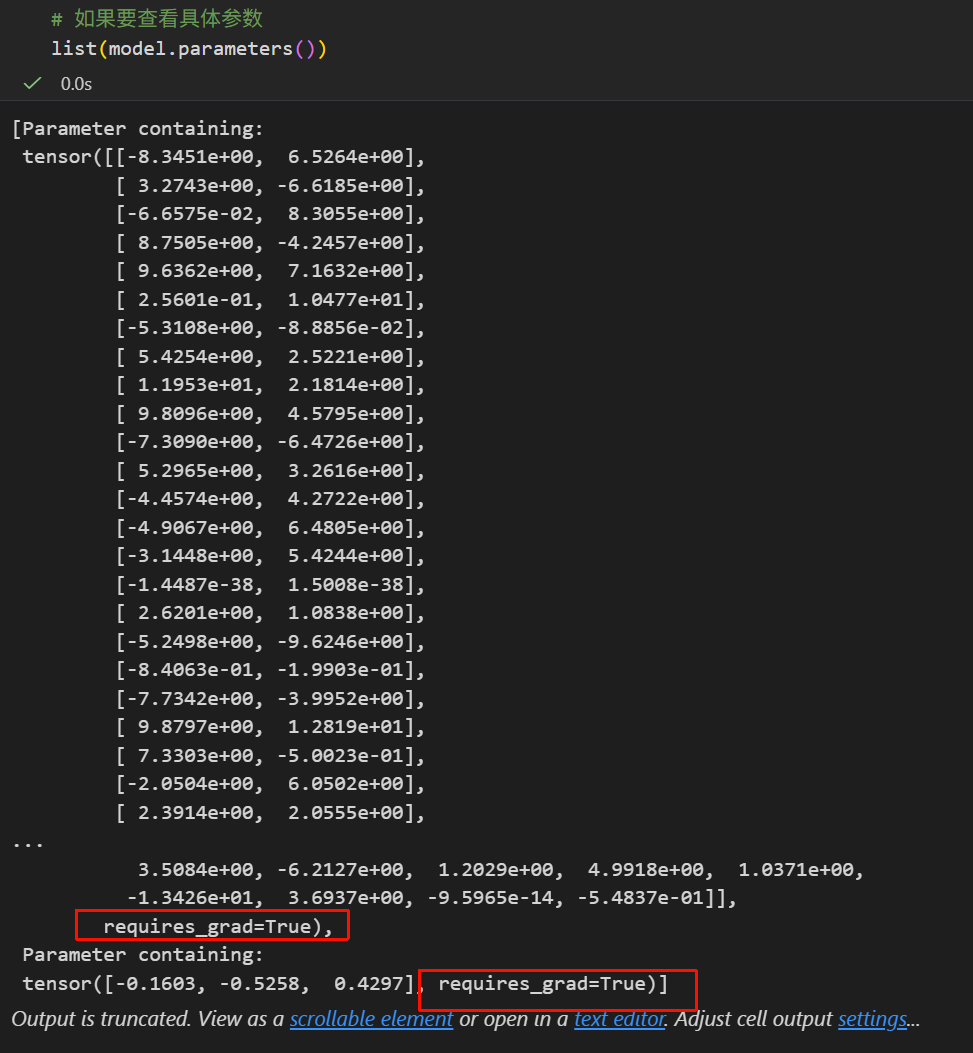
正常来说,梯度的计算,和我们是否只调用model.forward无关,和:
- model的层的参数张量相关,默认都是requires_grad=True
- 我们输入的张量,如果是float浮点型,即使没有手动设置requires_grad=True,但是经过带梯度的层计算后,输出的张量都会被梯度追踪(track)


4,总结一下我们的简易PyTorch代码模板
我们把前面的代码粗略地整合在一起,大概如下
python
import numpy as np
import matplotlib.pyplot as plt
import nnfs
from nnfs.datasets import spiral_data
nnfs.init()
import torch
import torch.nn as nn
import torch.optim as optim
# custom NN inheriting from nn.Module
class MyModel(nn.Module):
def __init__(self):
# 在子类初始化中调用父类构造器
super(MyModel, self).__init__()
# 而且必须在注册子模块,也就是搭建网络结构前调用
# first dense (fully connected) layer with 2 input features, 64 output neurons
self.dense1 = nn.Linear(2, 64)
# define activation function (ReLU) for first hidden layer
self.relu1 = nn.ReLU()
# # second dense layer with 64 input neurons, 3 output neurons
self.dense2 = nn.Linear(64, 3)
# forward pass
# computes output of model given input data x
def forward(self, x):
# pass input x through first dense layer
x = self.dense1(x)
# apply ReLU activation function to output of first dense layer
x = self.relu1(x)
# pass output of ReLU activation function through second dense layer
x = self.dense2(x)
# return output of second dense layer
return x
# generate data for a classification task
X, y = spiral_data(samples=100, classes=3)
# convert dataset to pytorch tensors
# PyTorch 模型只能处理张量(Tensor)格式数据,需将原始的 NumPy 数组(spiral_data 通常返回 NumPy 数组)转换为张量
# 特征通常为浮点类型, 一般默认用float32
X = torch.tensor(X, dtype=torch.float32)
# 分类任务的标签需为整数型(表示类别索引), long(64位整数)是 PyTorch 中交叉熵损失函数(CrossEntropyLoss)要求的标签类型
# 参考https://docs.pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html
# torch.long = torch.int64(64 位有符号整数),是分类任务标签的标准类型。
y = torch.tensor(y, dtype=torch.long)
# 实例化model,指定loss和优化器
# Define the model
model = MyModel()
# Loss and optimizer
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.05, weight_decay=5e-7)
# Train in loop
for epoch in range(10001):
# Forward pass
# 前向传播数据, 本质call是调用子类model的forward方法
outputs = model(X)
# Calculate the loss
# 计算loss
loss = loss_function(outputs, y)
# Zero gradients, backward pass, and optimize
# 先梯度清零, 防止不同batch的参数更新建议不一致
optimizer.zero_grad()
# 对于当前loss反向传播, 计算对参数的梯度(动量和当前梯度)
loss.backward()
# 利用动量和当前梯度更新参数
optimizer.step()
# Calculate accuracy
# 只要索引值, 作为label
_, predicted = torch.max(outputs, 1)
accuracy = (predicted == y).float().mean()
# Print epoch, accuracy, loss, learning rate every 100 epochs
if epoch % 100 == 0:
print(f'Epoch: {epoch}, Accuracy: {accuracy.item():.3f}, Loss: {loss.item():.3f}, Learning Rate: {optimizer.param_groups[0]["lr"]}')现在我们要做的,和前面Chap1、Chap1-1一样,
就是从这些简略的手写版神经网络中,尽可能地抽象出、整理出比较规范正式的代码逻辑结构,
同样地我们按照Chap1中定义的习惯来
python
project_root/
│
├── data/ # 存放原始数据和处理后的数据
│ ├── raw/
│ └── processed/
│
├── configs/ # 配置文件 (超参数、路径)
│ └── config.yaml
│
├── src/ # 核心源代码
│ ├── __init__.py
│ ├── dataset.py # 1. 数据处理 (Data Loader)
│ ├── model.py # 2. 模型定义 (Network Architecture)
│ ├── trainer.py # 3. 训练逻辑 (Training Loop)
│ ├── utils.py # 4. 辅助函数 (Metrics, Logging)
│ └── predict.py # 5. 推理/预测逻辑
│
├── main.py # 项目入口 (整合所有模块)
├── requirements.txt # 依赖库
└── README.md1,配置文件(configs/config.yaml)
如果是原始的简略版神经网络,我们各种自定义的参数和超参数会散落在代码各种,修改起来非常麻烦,需要到处去找。
但是现在,正式一点地做法,我们能够将所有的超参数都全部提取到YAML文件中。
这样我们修改实验设置就无需改动代码,甚至可以编写脚本批量生成不同的config文件进行超参数搜索,
比如说在经典机器学习中,配合optuna进行超参数优化,就可以在yaml文件抽象层上对超参数进行处理。
一般超参数设置,也主要是data、model、trainer这3大块核心配置。
比如说我这里的超参数设置,也就是data中模拟数据生成的一些参数,model也就是架构中对layer层的一些维度设置等,trainer中对于训练、优化器的一些参数设置
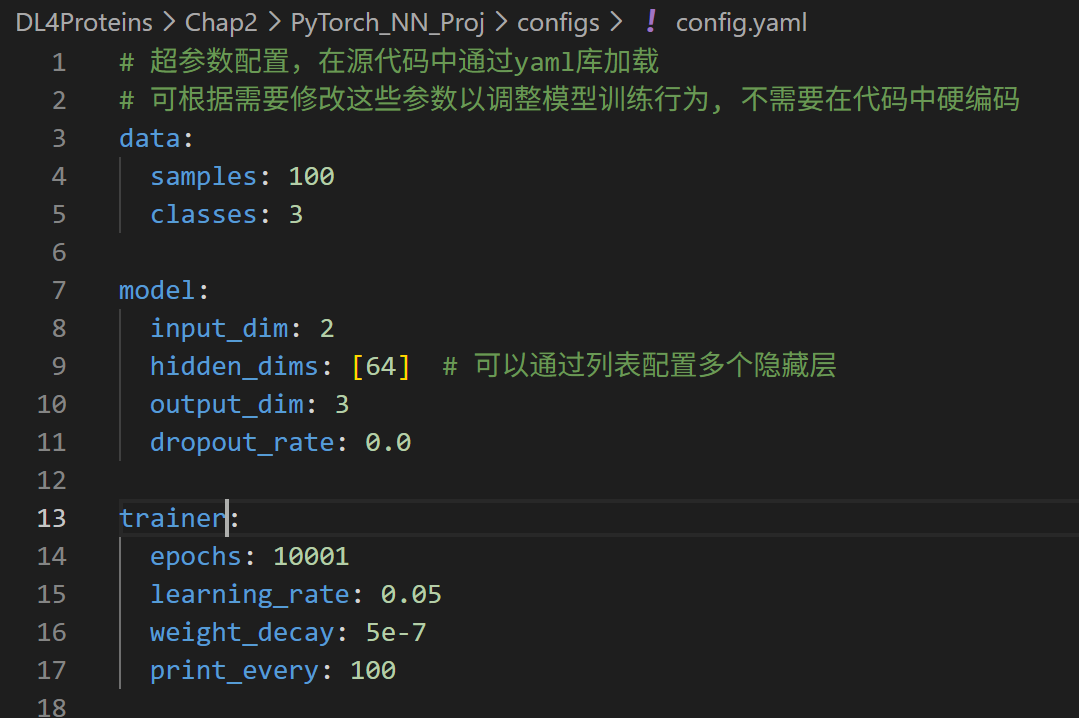
bash
# 超参数配置,在源代码中通过yaml库加载
# 可根据需要修改这些参数以调整模型训练行为, 不需要在代码中硬编码
data:
samples: 100
classes: 3
model:
input_dim: 2
hidden_dims: [64] # 可以通过列表配置多个隐藏层
output_dim: 3
dropout_rate: 0.0
trainer:
epochs: 10001
learning_rate: 0.05
weight_decay: 5e-7
print_every: 1002,数据流水线(src/dataset.py)
我们前面的代码中,对于输入数据的处理非常简单,就是生成一个模拟数据,然后将生成的X,y转入内存变量,手动转换为tensor。
但是正式的数据处理中,我们一般会用PyTorch的Dataset和DataLoader。
1,先回顾numpy手搓数据的"原始操作"
用numpy做神经网络时,我们可能会写这样的代码:
python
import numpy as np
# 1. 全量读数据(痛点1:数据大了装不下内存)
X = np.load("all_data_x.npy") # 假设100万条数据,几GB,直接占满内存
y = np.load("all_data_y.npy")
# 2. 手动Shuffle(痛点2:每次epoch都要自己写打乱逻辑)
shuffle_idx = np.random.permutation(len(X))
X_shuffle = X[shuffle_idx]
y_shuffle = y[shuffle_idx]
# 3. 手动切Batch(痛点3:循环计算索引,容易写错)
batch_size = 32
for i in range(0, len(X), batch_size):
# 手动算当前batch的起止索引
X_batch = X_shuffle[i:i+batch_size]
y_batch = y_shuffle[i:i+batch_size]
# 然后喂给模型核心痛点:
- 数据全量加载:几TB的工业数据(如ImageNet)根本装不下内存;
- 手动操作繁琐:切batch、shuffle要自己写逻辑,容易出错;
- 没有加速:读数据是"单线程",等数据的时间比模型计算还长。
而Dataset和DataLoader就是为解决这些痛点而生的------前者负责"按需读数据",后者负责"智能装Batch"。
2,Dataset:"按需取一条数据"的工具
我们可以把Dataset理解成"数据货架":货架上不放所有商品(数据),只记着每个商品的位置(路径/索引),当我们要第i个商品时,它才去仓库拿出来、简单处理(如洗干净shuffle、切好batch)再给我们。
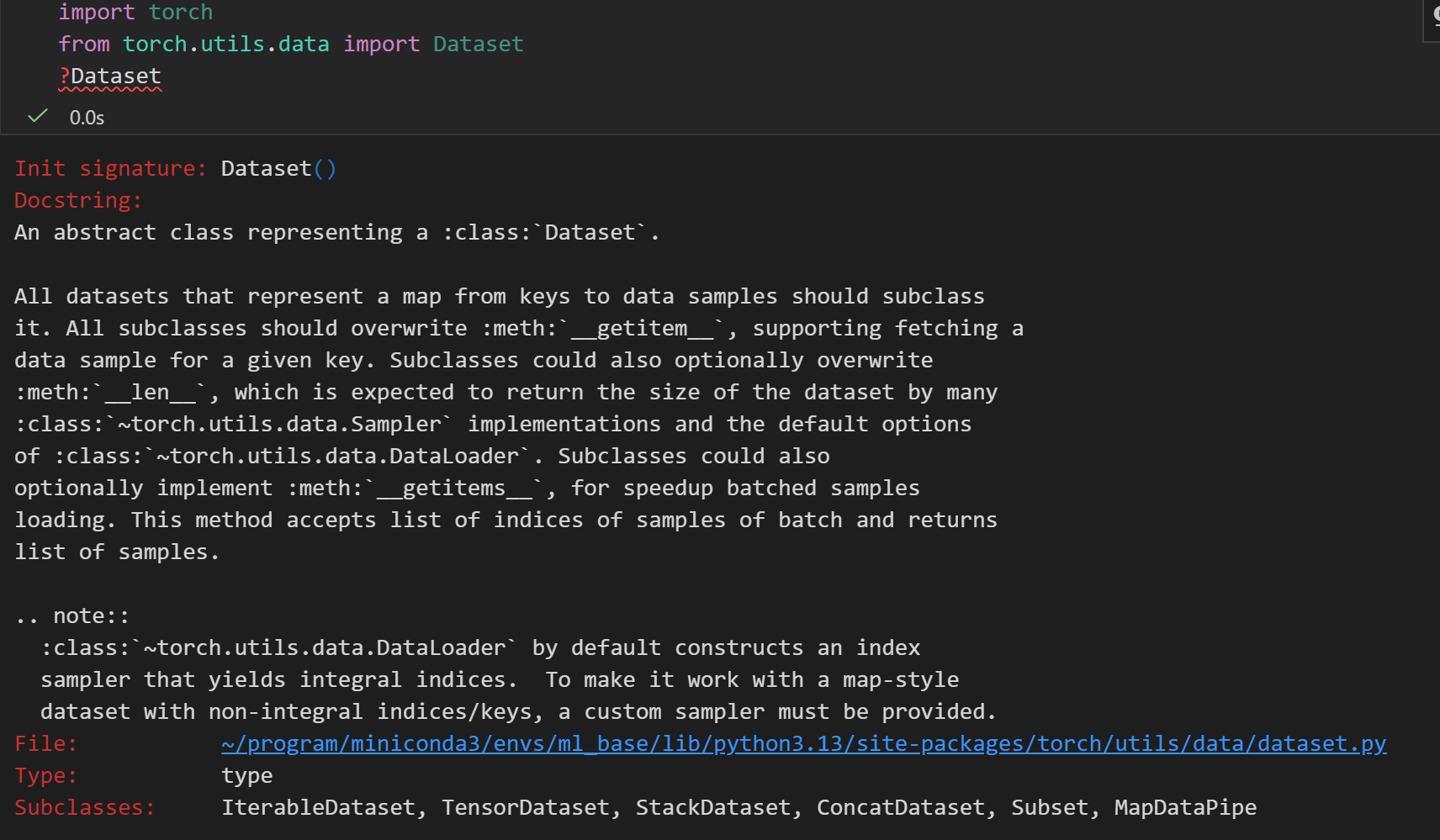
1. Dataset的核心作用
- 懒加载(Lazy Loading):不一次性读所有数据,只在需要某一条时才读取(解决内存爆炸问题);
- 统一接口:不管是图片、文本、CSV,都用同样的方式取数据(避免每种数据写一套读逻辑)。
2. 怎么用Dataset?3步搞定
PyTorch要求:自定义Dataset必须继承torch.utils.data.Dataset,并重写3个方法:
| 方法名 | 作用 |
|---|---|
__init__ |
初始化:存数据路径、预处理函数(如图片Resize、归一化),不读具体数据 |
__getitem__ |
核心:根据索引idx,读取1条数据并处理成Tensor(返回x, y) |
__len__ |
返回数据总条数(让DataLoader知道"有多少数据要处理") |
3. 举个例子
假设我们有个data.csv,每行是1个样本,列是(特征1, 特征2, 标签),比如:
plain
0.5,1.2,0
1.3,0.8,1
2.1,0.3,0
...我们就可以继承Torch的Dataset类,自定义Dataset代码如下:
python
import torch
# 首先要导入torch的Dataset
from torch.utils.data import Dataset
import pandas as pd
# 导入之后可以继承
# 自定义Dataset,继承自torch的Dataset
class MyCSVDataSet(Dataset):
def __init__(self, csv_path, transform=None):
"""
初始化:只做"准备工作",不读具体数据
:param csv_path: 数据文件路径
:param transform: 可选的预处理函数(如归一化)
"""
# 读CSV的"表头+路径",不读具体数据(相当于记货架位置)
self.df = pd.read_csv(csv_path)
self.transform = transform # 存预处理函数
def __getitem__(self, idx):
"""
核心:按索引取1条数据,处理后返回
:param idx: 数据索引(比如第0条、第1条)
:return: 处理好的x(特征,Tensor)、y(标签,Tensor)
"""
# 1. 按索引取1行数据(终于读具体数据了!)
row = self.df.iloc[idx]
# 2. 拆分特征和标签(根据我们的CSV格式调整)
x = row[["feature1", "feature2"]].values # numpy数组
y = row["label"]
# 3. 预处理(比如转Tensor、归一化)
if self.transform:
x = self.transform(x)
# 转成PyTorch的Tensor(numpy手搓时要手动转,这里统一处理)
x = torch.tensor(x, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.long)
return x, y # 返回1条数据的(x,y)
def __len__(self):
"""返回数据总条数(货架上有多少商品)"""
return len(self.df)类比numpy:
numpy是"把整个超市(仓库)的商品全堆在货架上"(全量读内存),而Dataset是"货架墙上贴个清单,要第idx个商品时,才去仓库拿"(按需读取)。
3,DataLoader:"智能装Batch"的工具
有了Dataset(货架),还需要DataLoader(快递员)------它帮我们按"批量"把货架上的商品打包,还能打乱顺序、多个人一起搬(多进程加速),不用我们自己动手。
1. DataLoader的核心作用
解决numpy手搓的3个痛点:
- 自动切Batch :不用自己算
i:i+batch_size,直接给我们批量数据; - 自动Shuffle:每个epoch(一轮训练)自动打乱数据顺序,防止模型过拟合;
- 多进程加速 :用
num_workers参数开启多进程读数据,避免"模型等数据"; - 自动处理最后一批:如果数据总数不是batch_size的整数倍,最后一批自动处理(不用我们补零或丢弃)。
2. 怎么用DataLoader?
一步搞定,把自定义的Dataset实例传进去,再指定几个关键参数即可:
python
from torch.utils.data import DataLoader
# 1. 先创建Dataset实例(准备好货架)
# 可选:定义预处理函数(比如归一化)
def normalize(x):
return (x - x.mean()) / x.std()
dataset = MyCSVDataSet(
csv_path="data.csv", # 我们的数据路径
transform=normalize # 预处理
)
# 2. 创建DataLoader(安排快递员)
dataloader = DataLoader(
dataset=dataset, # 要打包的货架
batch_size=32, # 每次打包32条数据(batch大小)
shuffle=True, # 每个epoch打乱顺序(训练时开,测试时关)
num_workers=2, # 2个进程一起读数据(加速,根据CPU核心数调整)
drop_last=False # 最后一批不够32条时,是否丢弃(一般False)
)3. 怎么用DataLoader训练?
训练时直接用for循环迭代dataloader,每次得到一个batch的x和y,直接喂给模型:
python
# 假设我们有个简单模型
model = torch.nn.Linear(2, 2) # 输入2维,输出2维(分类)
loss_fn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# 训练10个epoch(遍历10次所有数据)
for epoch in range(10):
model.train()
total_loss = 0.0
# 迭代dataloader,每次得到一个batch
for batch_x, batch_y in dataloader:
# 1. 前向传播
outputs = model(batch_x)
# 2. 算损失
loss = loss_fn(outputs, batch_y)
# 3. 反向传播+更新参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 累加损失
total_loss += loss.item() * batch_x.size(0) # 乘batch大小,避免小batch权重低
# 打印每个epoch的平均损失
avg_loss = total_loss / len(dataset)
print(f"Epoch {epoch+1}, Avg Loss: {avg_loss:.4f}")这里的for循环,要深入理解的话,需要查看下面对Dataset和DataLoader的关系小节,
简单来说,dataloader能被for循环,本质处理是:我们每循环一次,它就自动完成调用Dataset的getitem拿数据------》拼batch------》返回(batch_x,batch_y)的全流程,最终把批量数据喂到我们的model里。
把这个<font style="color:rgb(31, 35, 41);background-color:rgba(0, 0, 0, 0);">for</font>循环过程,对应到我们熟悉的场景里:
| 代码逻辑 | 现实场景类比 |
|---|---|
<font style="color:rgb(31, 35, 41);background-color:rgba(0, 0, 0, 0);">for epoch in range(10)</font> |
我们要求打包员(DataLoader)把仓库里的货(全量数据)完整配送 10 轮(10 个 epoch) |
<font style="color:rgb(31, 35, 41);background-color:rgba(0, 0, 0, 0);">for batch_x, batch_y in dataloader</font> |
每一轮配送(1/10)中,打包员一次送 1 个包裹(batch) ,直到把所有货送完;我们每次接一个包裹,拆出里面的<font style="color:rgb(31, 35, 41);background-color:rgba(0, 0, 0, 0);">x</font>(货物)和<font style="color:rgb(31, 35, 41);background-color:rgba(0, 0, 0, 0);">y</font>(快递单) |
<font style="color:rgb(31, 35, 41);background-color:rgba(0, 0, 0, 0);">model(batch_x)</font> |
我们把包裹里的货物(批量数据)交给工厂(模型)加工 |
类比numpy:
numpy手搓时要自己写for i in range(0, len(X), batch_size),而DataLoader直接帮我们把batch喂到嘴边,循环里只需要关注"模型计算",不用管数据怎么来的。
4,Dataset和DataLoader的关系总结
| 组件 | 核心职责 | 类比生活场景 | numpy手搓的对应操作 |
|---|---|---|---|
| Dataset | 单条数据的"读取+预处理" | 超市货架(按需取货) | 手动用np.load读单条数据 |
| DataLoader | 批量数据的"整合+加速" | 快递员(批量打包) | 手动切batch、shuffle、循环 |
简单说:Dataset管"一条数据怎么来",DataLoader管"多条数据怎么成批来"。
我们还是用仓库、货架的类比来理解,




我们简单在代码层面上举例:
python
# 1. 仓库:硬盘里的 data.csv 文件(原始数据)
# 2. 创建货架:初始化Dataset,只存仓库地址+清单,不拿任何数据
dataset = MyCSVDataSet(csv_path="data.csv")
# 货架的能力:喊一声 dataset[0],货架自己去仓库拿第0条数据,返回单条(x,y)
single_x, single_y = dataset[0] # 只占1条数据的内存 ✔️
# 3. 创建打包员:把货架传进去,打包员只盯着货架干活
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# 打包员的能力:迭代dataloader,每次返回打好包的32条数据
for batch_x, batch_y in dataloader:
model(batch_x) # 直接喂模型 ✔️
所以前面看了 Dataset 的说明文档,结合这里的类比,我们就大概清除为什么我们继承torch的Dataset需要重写init、getitem、len这3 个方法,以后哪位这 3 个方法就是「智能货架的 3 个必备功能」:

最后总结就是:

python
import torch
from torch.utils.data import Dataset, DataLoader
?DataLoader
总而言之,我们可以粗略认为DataLoader就是通过调用Dataset暴露的核心API(也就是我们需要重写的getitem和len)来完成所有工作,也就是说它全程不碰原始数据,所有和获取数据相关的操作,都依赖Dataset提供的接口。

我们可以通过一个简单的示例,通过打印日志,来查看DataLoader如何调用Dataset的API:
python
import torch
from torch.utils.data import Dataset, DataLoader
# 自定义Dataset,加日志看调用过程
class MyDataset(Dataset):
def __init__(self):
self.data = [1,2,3,4,5] # 模拟仓库数据
def __getitem__(self, idx):
print(f"Dataset的__getitem__被调用了!idx={idx}") # 打印调用日志
return self.data[idx]
def __len__(self):
print(f"Dataset的__len__被调用了!") # 打印调用日志
return len(self.data)
# 创建Dataset和DataLoader
dataset = MyDataset()
dataloader = DataLoader(dataset, batch_size=2, shuffle=False)
# 迭代DataLoader,看调用过程
print("开始迭代DataLoader:")
for batch in dataloader:
print(f"DataLoader返回的batch:{batch}\n")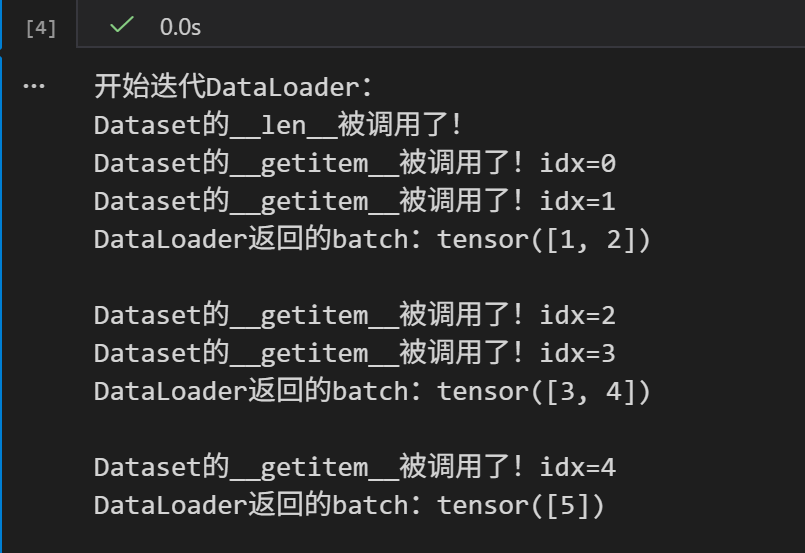
我们通过一个真实的实例,可以看到:

5,快速上手
把上面的代码整合起来,对于一般的任务,我们只需要改3个地方:
MyCSVDataSet里的特征/标签列名(根据我们的CSV调整);csv_path(我们的数据路径);- 模型结构(根据我们的任务调整)。
完整可运行代码:
python
import torch
import pandas as pd
from torch.utils.data import Dataset, DataLoader
from torch.nn import Linear, CrossEntropyLoss
from torch.optim import Adam
# ---------------------- 1. 自定义Dataset ----------------------
class MyCSVDataSet(Dataset):
def __init__(self, csv_path, transform=None):
self.df = pd.read_csv(csv_path)
self.transform = transform
def __getitem__(self, idx):
# 【改这里】根据我们的CSV列名调整!
x = self.df.iloc[idx][["feature1", "feature2"]].values # 特征列
y = self.df.iloc[idx]["label"] # 标签列
if self.transform:
x = self.transform(x)
x = torch.tensor(x, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.long)
return x, y
def __len__(self):
return len(self.df)
# ---------------------- 2. 预处理函数 ----------------------
def normalize(x):
"""简单归一化,可根据需求改"""
return (x - x.mean()) / (x.std() + 1e-8) # 加1e-8避免除零
# ---------------------- 3. 创建Dataset和DataLoader ----------------------
# 【改这里】我们的数据路径!
dataset = MyCSVDataSet(
csv_path="data.csv",
transform=normalize
)
dataloader = DataLoader(
dataset=dataset,
batch_size=32, # 根据显存调整(显存小就设16)
shuffle=True, # 训练时True,测试时False
num_workers=2, # CPU核心数的1/2~1/4(避免占用过多资源)
drop_last=False
)
# ---------------------- 4. 简单训练示例 ----------------------
# 【改这里】根据我们的任务调整模型!(这里是2分类示例)
model = Linear(in_features=2, out_features=2) # 输入2维,输出2类
loss_fn = CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-3)
# 训练5个epoch
for epoch in range(5):
model.train()
total_loss = 0.0
for batch_x, batch_y in dataloader:
# 前向传播
pred = model(batch_x)
# 计算损失
loss = loss_fn(pred, batch_y)
# 反向传播+更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 累加损失
total_loss += loss.item() * batch_x.shape[0]
# 打印进度
avg_loss = total_loss / len(dataset)
print(f"Epoch {epoch+1:2d} | Avg Loss: {avg_loss:.4f}")
print("训练结束!")小样本数据debug看shape上手,
- 先小数据测试 :先用100条数据做测试,确保
Dataset的__getitem__返回正确的x和y形状(比如x.shape应该是(特征数,),y是标量); - 查看Batch形状 :在
for batch_x, batch_y in dataloader里加print(batch_x.shape, batch_y.shape),确认batch_x是(batch_size, 特征数),batch_y是(batch_size,);
简单来说,我们不再像是numpy手搓神经网络那样,将内存中的变量X,y全部手动转变为Tensor,全量读入。
我们需要正式地自己写一个Dataset类,也就是需要继承torch的Dataset类,然后需要我们自己实现getitem接口,因为实际训练model时数据量很大,一般会有几TB,是无法一次性读入内存的,Dataset类就允许我们用到哪条读哪条(lazy loading)。
接着就是核心组件DataLoader,我们是前面简易版pytorch和手搓numpy,都是将数据全量传给model。
正式pytorch操作中,我们是直接调用torch的DataLoader函数,或者再封装一层(本身也是调用DataLoader),因为它能够自动帮我们处理batch切分(把大数据切成小块)、shuffle(每个Epoch打乱顺序防止过拟合)、multiprocessing(多进程加速读取)。
比如说,我这里就对DataLoader再进行了一层封装,调用
整体需要实现的组件其实很少,
重写一个dataset类,我这里是螺旋数据集,主要是重写一些比较重要的私有函数。
然后就是DataLoader的封装调用
python
# src/dataset.py
import torch
import numpy as np
import nnfs
from nnfs.datasets import spiral_data
from torch.utils.data import Dataset, DataLoader
# nnfs.init() # 通常在主程序入口调用
class SpiralDataset(Dataset):
"""
Description
---------
自定义 Dataset 类:负责从数据源读取并封装单个样本;
对比:
- 简易版:直接用 X, y 两个大张量塞进内存
- 工业版:必须继承 torch.utils.data.Dataset, 实现 __len__ 和 __getitem__
对于大数据集, __getitem__ 只在需要时加载单个文件,节省内存。
"""
def __init__(self, samples=100, classes=3):
"""
Description
---------
构造函数:初始化数据集
Args
---------
samples : int
每个类别的样本数
classes : int
类别数
Returns
---------
None
"""
# 实际项目中,这里通常接收文件路径 list,而不是直接生成数据
X, y = spiral_data(samples=samples, classes=classes)
self.X = torch.tensor(X, dtype=torch.float32)
self.y = torch.tensor(y, dtype=torch.long)
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
# 实际项目中,这里可能包含数据增强 (Augmentation)
return self.X[idx], self.y[idx]
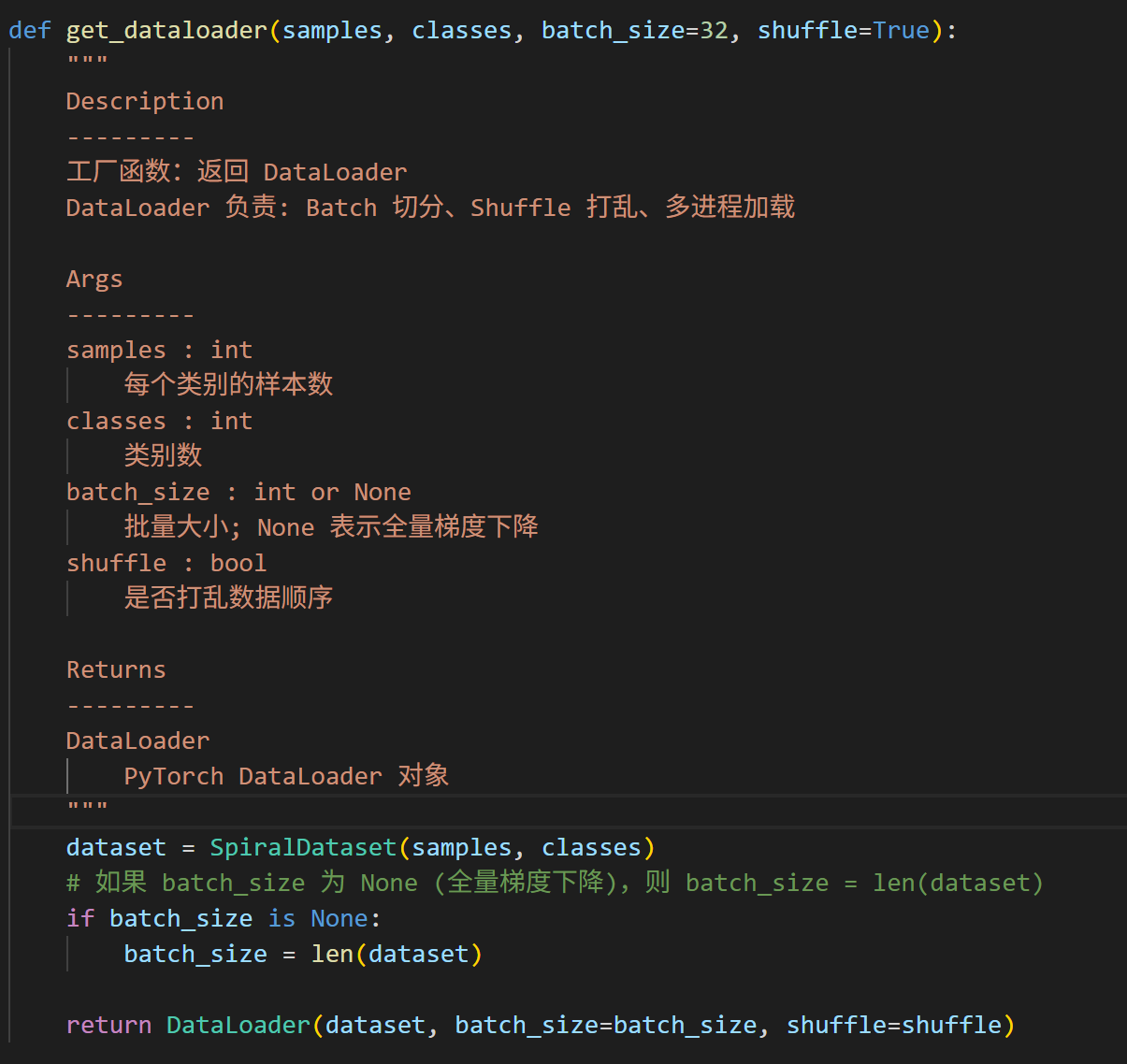
def get_dataloader(samples, classes, batch_size=32, shuffle=True):
"""
Description
---------
工厂函数:返回 DataLoader
DataLoader 负责: Batch 切分、Shuffle 打乱、多进程加载
Args
---------
samples : int
每个类别的样本数
classes : int
类别数
batch_size : int or None
批量大小; None 表示全量梯度下降
shuffle : bool
是否打乱数据顺序
Returns
---------
DataLoader
PyTorch DataLoader 对象
"""
dataset = SpiralDataset(samples, classes)
# 如果 batch_size 为 None (全量梯度下降),则 batch_size = len(dataset)
if batch_size is None:
batch_size = len(dataset)
return DataLoader(dataset, batch_size=batch_size, shuffle=shuffle)3,模型定义(src/model.py):最核心的变化
之前的博客Chap1中我们是自己手写了底层全连接每一层函数dense_layer,
然后我们再自己手动调用其api进行网络架构组建;
然后前面简易pytorch版我们是直接调用torch封装好的layer API,
我们这里同样还是调用layer的API,
同样的,我们只定义model结构和前向传播forward方法,绝不写训练逻辑。
1个简单的模板逻辑:
我们实际封装的代码示例:
python
# src/model.py
import torch
import torch.nn as nn
class UniversalMLP(nn.Module):
"""
Description
------------
通用多层感知机 (MLP) 模板
对比:
- 简易版:硬编码 self.dense1, self.dense2, 层数定死
- 工业版:接收参数列表 (hidden_dims),用 nn.Sequential 动态搭建
不变的地方: 只写 __init__ 定义层, forward 定义流向, Backward 自动完成自动微分
"""
def __init__(self, input_dim, hidden_dims, output_dim, activation=nn.ReLU, dropout_rate=0.0):
"""
Description
------------
初始化多层感知机, 动态构建隐藏层
Args
-----
input_dim : int
输入特征维度
hidden_dims : list of int
隐藏层维度列表, 每个元素代表一层的神经元数量
output_dim : int
输出维度 (类别数)
activation : nn.Module
激活函数模块, 默认为 ReLU
dropout_rate : float
Dropout 比例, 默认为 0.0 (不使用 Dropout)
"""
# 调用父类构造函数
super(UniversalMLP, self).__init__()
layers = []
prev_dim = input_dim
# 动态构建隐藏层
for h_dim in hidden_dims:
layers.append(nn.Linear(prev_dim, h_dim))
# 正常在 Linear 和 Activation 之间加 BatchNorm
# layers.append(nn.BatchNorm1d(h_dim))
# 添加激活函数和 Dropout
# 不要把同一个 activation 实例重复使用, 对于有状态的激活函数会出问题, 应为每层创建独立的实例
layers.append(activation())
if dropout_rate > 0:
layers.append(nn.Dropout(dropout_rate))
# 更新前一层维度
prev_dim = h_dim
# 输出层 (不加激活,因为 CrossEntropyLoss 包含 Softmax)
layers.append(nn.Linear(prev_dim, output_dim))
# 将列表转为 Sequential 容器
# 需要将其注册为 Module 的子模块
# 以便参数能被正确识别和更新
self.network = nn.Sequential(*layers)
def forward(self, x):
return self.network(x)一些需要注意的细节:
1,Sequential函数的调用:为什么要把 layers 列表转换为 nn.Sequential?
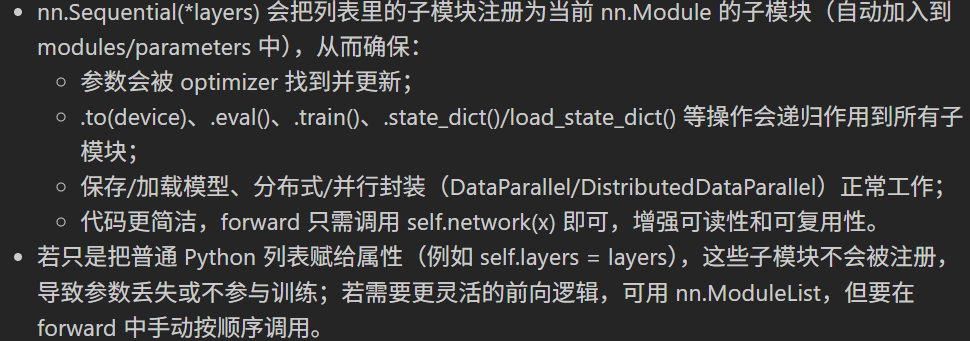
- 注册子模块和参数:直接把模块放到普通 Python 列表不会将它们注册为 nn.Module 的子模块。用 nn.Sequential 包装后,子模块及其参数会被注册,model.parameters() 和优化器能识别它们。
- 定义前向执行顺序:nn.Sequential 会按顺序应用其子模块,调用 self.network(x) 会依次执行 Linear、激活、Dropout 等,无需自写 forward 循环。
- 支持模块生命周期操作:model.to(device)、model.eval()/train()、model.state_dict()、torch.save/load 等在子模块被注册后都能正常工作。
- 可读性与维护性更好:网络结构清晰、紧凑,便于扩展和调试。
- 备选项与差异:
- nn.ModuleList 会注册模块但不实现顺序前向,需要在 forward 中手动迭代并调用;
- 纯 Python 列表既不注册模块也不定义前向,参数对优化器不可见;
- nn.ModuleDict 适合命名子模块,但同样不实现顺序前向行为。
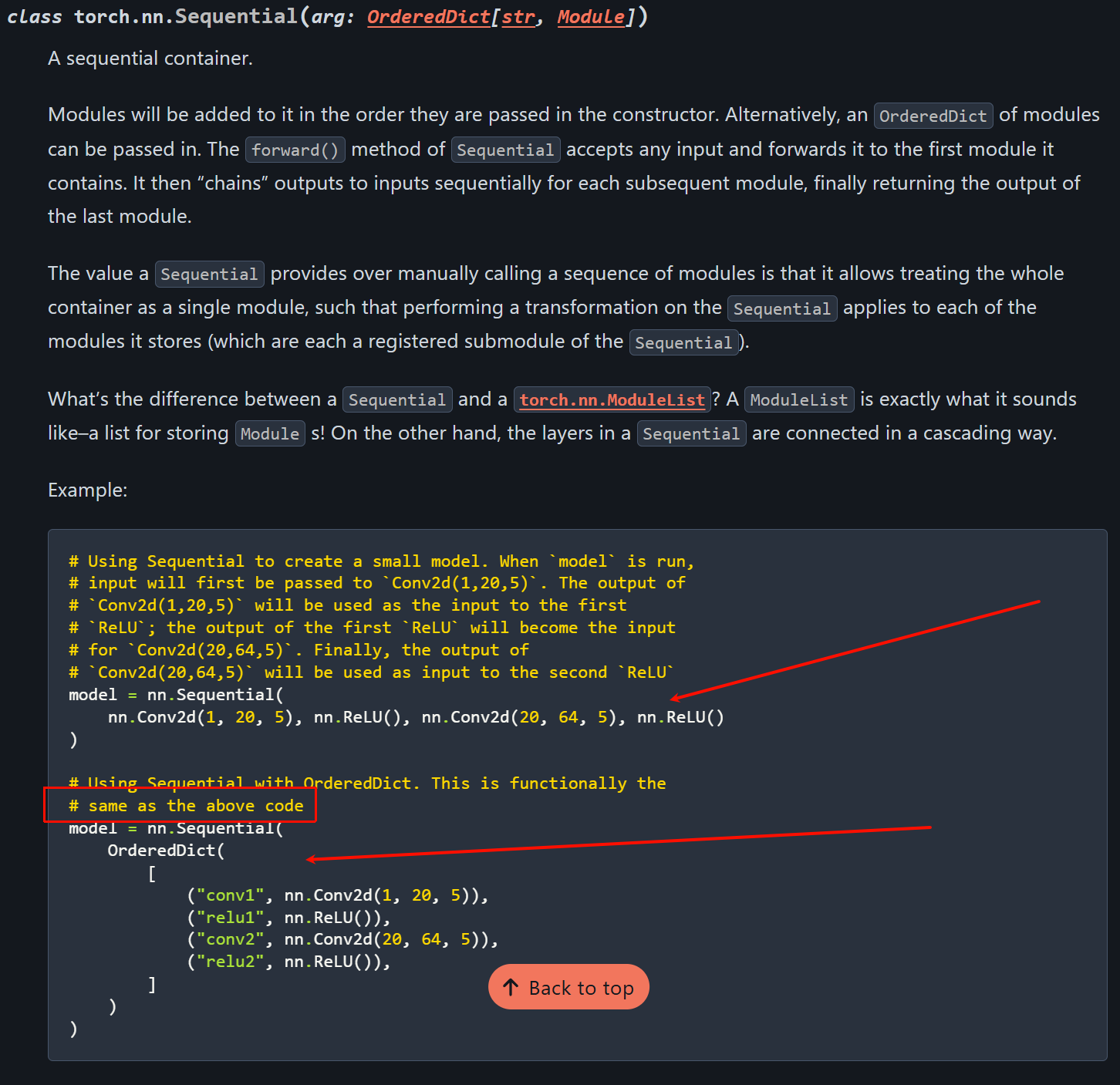
事实上,pytorch官网中也比较了nn.Sequential和nn.ModuleDict,
https://docs.pytorch.org/docs/stable/generated/torch.nn.Sequential.html
2,forward函数中为什么只需要写一行,我在调用self.network时发生了什么?
- 本质:nn.Sequential 把一组子模块包装成一个可调用的 nn.Module。self.network = nn.Sequential(*layers) 会把 layers 中的每个子模块注册为当前模块的子模块(parameters/buffers/children 被正确跟踪),并实现了按顺序把输入张量传递给每个子模块的逻辑。
- 当我们在 forward 中写 self.network(x) 时,实际发生的是:
- 调用 nn.Module.call(处理 hooks、register/grad 等),然后执行 Sequential.forward。
- Sequential.forward 大致等价于:
for module in self._modules.values():
x = module(x)
return x
(即把 tensor 依次送进每个子模块,前一层的输出成为后一层输入) - 所有子模块的参数、状态会被 .to(device)/.train()/.eval()/state_dict() 等递归操作影响。
- 与手写 attribute + forward 的关系:
我们前面的简易版pytorch代码,基本上都是在forward函数中手动按照顺序调用每一个全连接层:
python
# custom NN inheriting from nn.Module
class MyModel(nn.Module):
def __init__(self):
# 在子类初始化中调用父类构造器
super(MyModel, self).__init__()
# 而且必须在注册子模块,也就是搭建网络结构前调用
# first dense (fully connected) layer with 2 input features, 64 output neurons
self.dense1 = nn.Linear(2, 64)
# define activation function (ReLU) for first hidden layer
self.relu1 = nn.ReLU()
# # second dense layer with 64 input neurons, 3 output neurons
self.dense2 = nn.Linear(64, 3)
# forward pass
# computes output of model given input data x
def forward(self, x):
# pass input x through first dense layer
x = self.dense1(x)
# apply ReLU activation function to output of first dense layer
x = self.relu1(x)
# pass output of ReLU activation function through second dense layer
x = self.dense2(x)
# return output of second dense layer
return x- 等价性:功能上等价------我们可以把每一层注册为属性(self.dense1, self.relu1, ...)并在 forward 中逐步调用,得到完全相同的计算图和参数管理。
- 优点(Sequential):代码更简洁、构建动态网络更方便、按列表顺序自动执行;适合"线性串联"模块。
- 限制(手写/复杂场景):如果需要分支、跳跃连接、多个输入/输出或某些层需要额外参数,手写 forward 或使用 nn.ModuleList 更灵活。
- 注册差别:把模块放进普通 Python list(self.layers = [...])不会自动注册;nn.Sequential/nn.ModuleList/赋给 self.attr 才会注册。示例(等价写法):
python
# python
seq = nn.Sequential(nn.Linear(10, 20), nn.ReLU(), nn.Linear(20, 5))
# 等价于
class M(nn.Module):
def __init__(self):
super().__init__()
self.l1 = nn.Linear(10,20)
self.a1 = nn.ReLU()
self.l2 = nn.Linear(20,5)
def forward(self, x):
x = self.l1(x)
x = self.a1(x)
x = self.l2(x)
return x总而言之,nn.Sequential 只是把"逐层调用"的样板代码封装并确保子模块被正确注册与管理,传入 x 时按顺序把张量传递给每一层并返回最终输出。
4,训练逻辑(src/trainer.py)
前面讲过,我们的训练路逻辑并没有写在model定义中,
我们的训练逻辑最好是放在单独的一个trainer.py文件中。
对于前面简易版的pytorch代码,如下:
python
# Loss and optimizer
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.05, weight_decay=5e-7)
# Train in loop
for epoch in range(10001):
# Forward pass
# 前向传播数据, 本质call是调用子类model的forward方法
outputs = model(X)
# Calculate the loss
# 计算loss
loss = loss_function(outputs, y)
# Zero gradients, backward pass, and optimize
# 先梯度清零, 防止不同batch的参数更新建议不一致
optimizer.zero_grad()
# 对于当前loss反向传播, 计算对参数的梯度(动量和当前梯度)
loss.backward()
# 利用动量和当前梯度更新参数
optimizer.step()
# Calculate accuracy
# 只要索引值, 作为label
_, predicted = torch.max(outputs, 1)
accuracy = (predicted == y).float().mean()
# Print epoch, accuracy, loss, learning rate every 100 epochs
if epoch % 100 == 0:
print(f'Epoch: {epoch}, Accuracy: {accuracy.item():.3f}, Loss: {loss.item():.3f}, Learning Rate: {optimizer.param_groups[0]["lr"]}')可以看到,我们的损失函数(metric)、优化器都散落在外面,
然后我们手动裸写了for循环,非常不便于管理。
正常的写trainer类的话,我们应该输入model实例、optimizer优化器、criterion损失函数等。
然后接下来就是标准的训练步(5步法):
python
# 零、前、损、反、更
# 1, 梯度清零
optimizer.zero_grad()
# 2, 前向计算输出
output = model(x)
# 3, 计算loss
loss = criterion(out,y)
# 4, 反向传播梯度
loss.backward()
# 5, 更新参数
optimizer.step()另外,因为从trainer这个类开始,我们的model架构其实就已经不是纸上谈兵了,所以需要兼顾现实的硬件设备之类。
比如说使用CPU还是用GPU,也就是Device管理,需要能够自动处理.to(device),也就是支持代码在CPU和GPU之间无缝切换。
要实现的核心部分代码就是单轮epoch训练:
python
def train_epoch(self, dataloader):
"""
Description
-----------
训练单个 Epoch (遍历所有 Batch)
Args
-----
dataloader : torch.utils.data.DataLoader
训练数据的 DataLoader
Returns
-------
avg_loss : float
平均损失
avg_acc : float
平均准确率
"""
self.model.train() # 开启训练模式 (启用 Dropout/BatchNorm)
total_loss = 0
correct = 0
total = 0
for X_batch, y_batch in dataloader:
# 1. 搬运数据到 GPU/CPU
X_batch, y_batch = X_batch.to(self.device), y_batch.to(self.device)
# 2. 梯度清零
self.optimizer.zero_grad()
# 3. 前向传播
outputs = self.model(X_batch)
# 4. 计算损失
loss = self.criterion(outputs, y_batch)
# 5. 反向传播
loss.backward()
# 6. 更新参数
self.optimizer.step()
# 统计
total_loss += loss.item()
_, predicted = torch.argmax(outputs, dim=1)
total += y_batch.size(0)
correct += (predicted == y_batch).sum().item()
avg_loss = total_loss / len(dataloader)
avg_acc = correct / total
return avg_loss, avg_acc一些需要注意的地方:
- to(device):我们需要将整个model(包含所有parameters和buffers)递归地移动到指定设备(cpu或cuda上),.to(device)会返回同一个模块的引用,参数会被实际移动到目标设备,从此模型的forward/参数都在该device上。这样后续传入同设备的输入可以避免设备不匹配错误,同时.to(device)会影响 state_dict()/保存/加载行为。 除了模型,我们也需要将训练数据,也就是x_batch、y_batch这两个张量移动到trainer指定的设备(self.device),以便与model在同一设备上做前向/反向传播。
- optimizer.param_groups 是包含若干参数组的列表(每组是 dict),常见情况只有一个组;'lr' 是该组当前使用的学习率。
总得来说,trainer训练器主要是封装"模型 + 优化器 + 损失 + 训练循环"的细节:数据搬运(device)、前向、损失、反向、参数更新、统计与日志。
- 为什么要单独写 trainer/train_epoch和fit
- 去重:把每次训练的通用流程抽象,避免到处复制相同的 for-loop。
- 统一设备/参数管理:统一调用 model.to(device)、optimizer 管理、state_dict 保存/加载。
- 可扩展性:方便加入学习率调度、checkpoint、early stopping、日志、metric 记录、混合精度、分布式训练等。
- 可测试/复现:集中配置(seed、optimizer 参数、scheduler)更便于单元测试和重现实验。
- 易用性:上层只需要准备 dataloader 和超参即可调用 fit,适合实验与流水线。
- 训练器的典型职责(可扩展)
- 数据搬运(CPU/GPU)、batch loop、前向/反向/step。
- 统计与指标(loss/acc)、日志打印、可视化(TensorBoard)。
- Checkpoint(保存/恢复模型与优化器状态)。
- LR scheduler、gradient clipping、mixed precision(AMP)。
- Callback 机制(早停、评估、保存策略)。
- 支持分布式训练/多卡(DataParallel/DistributedDataParallel)。
总之常见做法就是将(单步/单epoch的训练逻辑)和(多epoch的调度/管理逻辑)分离:
- train_step/train_batch:一批数据(1个batch)的前向------》loss------》backward------》step,这无疑是最细粒度
- train_epoch:遍历dataloader,调用train_batch,收集指标,这是单epoch的逻辑
- validate/test:独立的评估函数(不反向传播)
- 上面写的fit,或者更一般会写成trainer.run函数之类,其实就是epoch的外层循环,按epoch调用train_epoch/validate,处理checkpoint、lr scheduler、early stopping、日志log、回调callback等等等
当然我们实际中并不是简单指定1个epoch总数,然后遍历完所有的epoch再停止。
不只靠"固定 epoch 数"训练,而是使用更常用的停止/控制机制:
- 验证集早停(Early Stopping):监控 validation loss/metric,若在 patience 个 epoch 内无改善则停止(最常用)。
- 学习率调度器(LR Scheduler):ReduceLROnPlateau 等根据 val loss 降低 lr,配合早停更稳。
- 最大步数 / 时间预算:按 max_steps、max_hours 或 GPU 预算停止(生产环境常用)。
- 指标收敛判定:loss 变化小于阈值或梯度范数 < eps 时停止。
- 检查点与回滚:保存最优模型(based on val),训练可在恢复点继续或回滚。
- 自动调参/搜索停止:基于超参调度器(如 Optuna)自动终止不良试验。
那么,一般如何知道多少 epoch?
- 用验证曲线(loss/metric vs epoch)观察是否过拟合或未收敛;通常先给一个上限,用早停自动结束。
- 开始实验可用较大上限 + 早停(patience 5~10 常见),结合 ReduceLROnPlateau。
- 小数据/快速收敛任务 epoch 少,复杂任务/大数据可能几百或按步数控制。
总的来说:工程中通常同时使用验证集 + ReduceLROnPlateau + EarlyStopping + checkpoint(保存最优模型)来自动管理何时停止训练。
另外对于trainer,一般真实项目通常会有训练封装,自写 Trainer 或使用成熟库(PyTorch Lightning 的 Trainer、HuggingFace Trainer等)。自定义 Trainer 便于满足特定需求,框架化 Trainer 则省时且功能完备。
此处举1个例子:
用的就是lightning框架里的成熟的trainer函数
python
from lightning import Callback, LightningDataModule, LightningModule, Trainer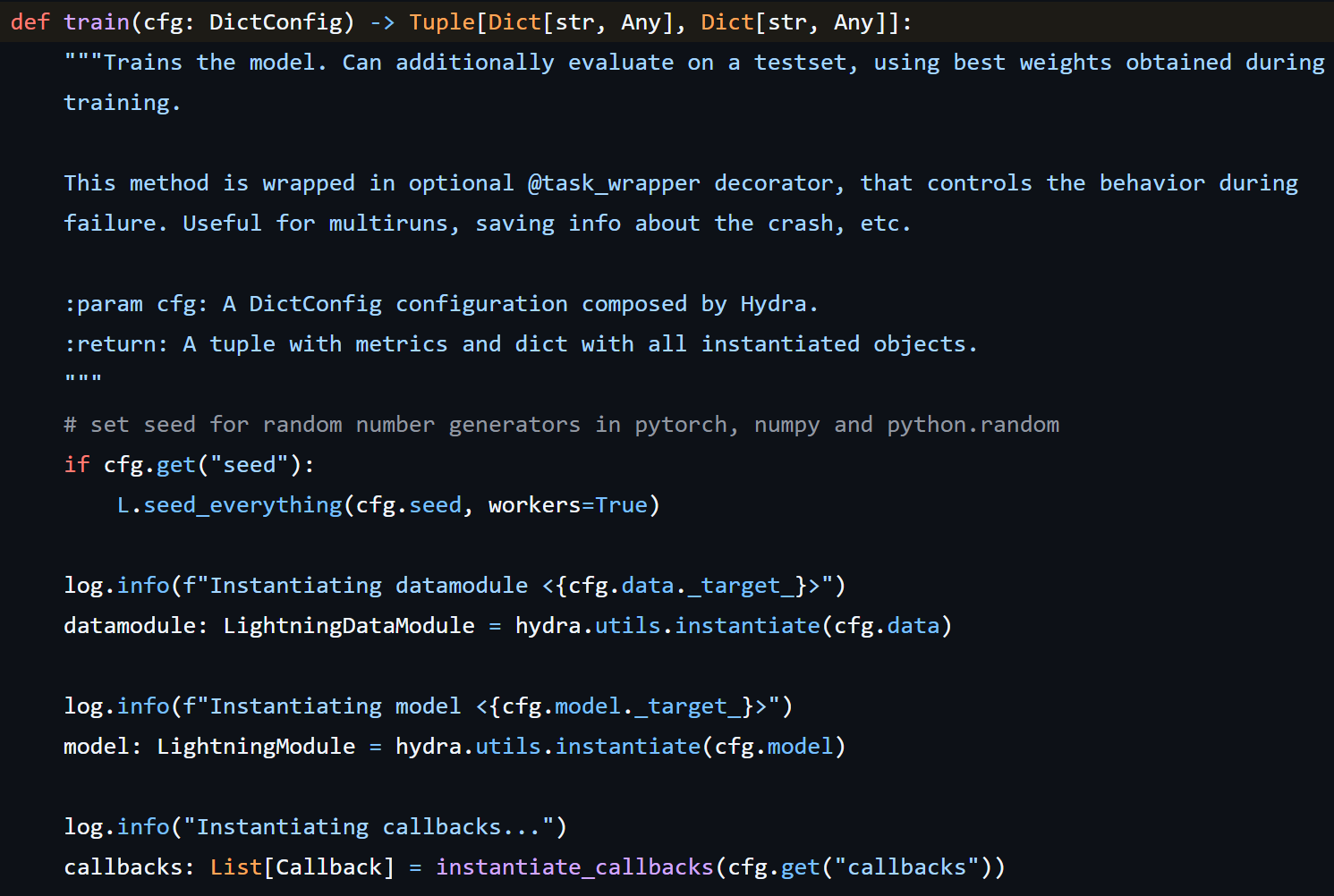
看了比较多的计算生物学结构方面的深度学习项目model,见到比较多的项目配置都是:PyTorch Lightning 的训练流程与 Hydra 的配置管理结合。
目的其实都是一样的,为了实现训练参数的灵活配置、实验复现和参数搜索。核心是通过 Hydra 管理模型、数据、训练器、回调等所有配置项,避免硬编码参数。
参考https://github.com/ashleve/lightning-hydra-template
这个是我个人常用的样板:

- PyTorch Lightning 负责封装训练逻辑
- 把 PyTorch 繁琐的训练循环(前向传播、梯度更新、设备分发等)抽象成
<font style="color:rgb(255, 255, 255);background-color:rgb(51, 51, 51);">LightningModule</font> - 把数据加载流程抽象成
<font style="color:rgb(255, 255, 255);background-color:rgb(51, 51, 51);">LightningDataModule</font> - 用
<font style="color:rgb(255, 255, 255);background-color:rgb(51, 51, 51);">Trainer</font>统一调度训练生命周期,用<font style="color:rgb(255, 255, 255);background-color:rgb(51, 51, 51);">Callback</font>插入自定义钩子逻辑 - 开发者只需关注模型算法和数据处理的核心代码
- 把 PyTorch 繁琐的训练循环(前向传播、梯度更新、设备分发等)抽象成
- Hydra 负责管理配置参数
- 把所有可配置项(模型超参、数据路径、训练器参数、回调参数)分层写在 YAML 文件中
- 支持配置组合和命令行覆盖,无需修改代码即可调整实验参数
- 自动生成实验日志目录,方便复现结果
我们这部分的代码模板如下
5,
python
# src/trainer.py
import torch
import torch.nn as nn
import torch.optim as optim
class Trainer:
"""
Description
-----------
训练器 (Trainer) 逻辑, model实际训练流程封装
对比:
- 简易版:裸写 for 循环,代码很难复用,换个模型又要重写
- 工业版:封装成类。管理 model, optimizer, criterion
支持 'mini-batch' 循环 (loader),支持 device 切换 (GPU)
"""
def __init__(self, model, optimizer=None, criterion=None, device='cpu'):
"""
Description
-----------
初始化训练器
Args
-----
model : torch.nn.Module
待训练的神经网络模型
optimizer : torch.optim.Optimizer, optional
优化器,默认 Adam
criterion : torch.nn.Module, optional
损失函数,默认 交叉熵损失
device : str, optional
设备,'cpu' 或 'cuda',默认 'cpu'
Returns
-------
None
"""
self.model = model.to(device)
self.device = device
# 默认使用交叉熵损失 (分类任务标准)
self.criterion = criterion if criterion else nn.CrossEntropyLoss()
# 默认使用 Adam
self.optimizer = optimizer if optimizer else optim.Adam(model.parameters(), lr=0.001)
# 训练历史记录
self.history = {'loss': [], 'acc': []}
def train_epoch(self, dataloader):
"""
Description
-----------
训练单个 Epoch (遍历所有 Batch)
Args
-----
dataloader : torch.utils.data.DataLoader
训练数据的 DataLoader
Returns
-------
avg_loss : float
平均损失
avg_acc : float
平均准确率
"""
self.model.train() # 开启训练模式 (启用 Dropout/BatchNorm)
total_loss = 0
correct = 0
total = 0
for X_batch, y_batch in dataloader:
# 1. 搬运数据到 GPU/CPU
X_batch, y_batch = X_batch.to(self.device), y_batch.to(self.device)
# 2. 梯度清零
self.optimizer.zero_grad()
# 3. 前向传播
outputs = self.model(X_batch)
# 4. 计算损失
loss = self.criterion(outputs, y_batch)
# 5. 反向传播
loss.backward()
# 6. 更新参数
self.optimizer.step()
# 统计
total_loss += loss.item()
_, predicted = torch.argmax(outputs, dim=1)
total += y_batch.size(0)
correct += (predicted == y_batch).sum().item()
avg_loss = total_loss / len(dataloader)
avg_acc = correct / total
return avg_loss, avg_acc
def fit(self, dataloader, epochs, print_every=10):
"""
Description
-----------
全流程训练入口, 前面只是单 epoch 训练, 这里是多 epoch 循环
Args
-----
dataloader : torch.utils.data.DataLoader
训练数据的 DataLoader
epochs : int
训练轮数
print_every : int, optional
每隔多少轮打印一次日志, 默认 10
Returns
-------
history : dict
训练历史记录,包含 'loss' 和 'acc' 列表
"""
for epoch in range(epochs):
loss, acc = self.train_epoch(dataloader)
self.history['loss'].append(loss)
self.history['acc'].append(acc)
if (epoch) % print_every == 0:
# 获取当前学习率用于打印
current_lr = self.optimizer.param_groups[0]['lr']
print(f'Epoch: {epoch}, Accuracy: {acc:.3f}, Loss: {loss:.3f}, LR: {current_lr}')
return self.history5,推理逻辑(src/predict.py)
我们前面的简易版pytorch中其实并没有额外准备推理模块,我们只是在另外的测试数据上进行了性能演示
python
# create meshgrid of points covering the feature space
h = 0.02
# determine min and max values for x,y axes
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
# create meshgrid of points with spacing h
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# convert meshgrid to torch tensor
meshgrid_points = torch.tensor(np.c_[xx.ravel(), yy.ravel()], dtype=torch.float32)
# pass meshgrid points through model
with torch.no_grad():
# forward pass through first dense
z1 = model.dense1(meshgrid_points)
# apply relu activation
a1 = torch.relu(z1)
# forward pass through second dense
z2 = model.dense2(a1)
# compute softmax probabilities for each class
exp_scores = torch.exp(z2 - torch.max(z2, axis=1, keepdim=True).values)
probs = exp_scores / torch.sum(exp_scores, axis=1, keepdim=True)
# predictions
# determine predicted class for each point in meshgrid
_, predictions = torch.max(probs, axis=1)
# reshape predictions to match shape of meshgrid
Z = predictions.numpy().reshape(xx.shape)
# plot decision boundary based on predictions
plt.contourf(xx, yy, Z, cmap='brg', alpha=0.8)
# plot original data on top of decision boundary
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap='brg')
# plot limits set to match extent of meshgrid
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.show()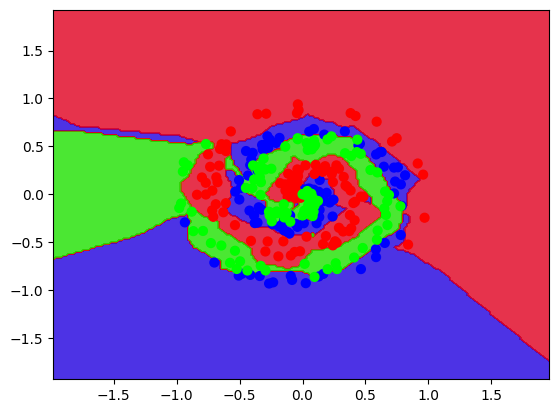
也就是我们没有独立的推理模块,只是在训练过程中顺便直接 model(X) 得到预测结果、简单地打印accuracy。
以下是我们的改良模板
python
# src/predict.py
import torch
import numpy as np
def predict(model, X, device='cpu'):
"""
Description
-----------
推理逻辑, 在测试/预测阶段使用
对比:
- 简易版:直接 model(X) 得到预测结果
- 工业版:
1. model.eval() 关闭 Dropout/BatchNorm 随机性
2. torch.no_grad() 关闭梯度计算引擎,节省显存并加速
3. 处理 device (GPU -> CPU) 和 tensor -> numpy 转换
Args
----
model : torch.nn.Module
训练好的模型
X : np.ndarray
原始数据, 输入特征数据,形状为 (num_samples, num_features), 即 batch 数据
device : str
运行设备,'cpu' 或 'cuda'
"""
# 将model切换到评估模式, 关闭 Dropout 和 BatchNorm 的随机性, 确保推理结果稳定
model.eval() # 切换评估模式
# 将输入数据转换为 tensor 并移动到指定设备, 测试数据
X_tensor = torch.as_tensor(X, dtype=torch.float32).to(device)
# 或X_tensor = torch.tensor(X, dtype=torch.float32).to(device)
# 推理阶段不需要计算梯度, 测试/预测阶段使用
# 关闭 autograd 追踪,节省显存并加速前向推理(不需要梯度)
with torch.no_grad(): # 上下文管理器,禁止梯度计算
logits = model(X_tensor)
# 如果需要概率,手动加 Softmax (因为模型输出是 logits)
probs = torch.softmax(logits, dim=1)
# 获取最大概率的类别索引
predictions = torch.argmax(probs, dim=1)
# 将结果从 GPU 移动到 CPU 并转换为 numpy 数组返回, 方便后续与sklearn等后续cpu上处理库兼容
return predictions.cpu().numpy()简化之后就是
python
model.eval()
X_tensor = torch.as_tensor(X, dtype=torch.float32).to(device)
with torch.no_grad():
logits = model(X_tensor)
probs = torch.softmax(logits, dim=1)
preds = torch.argmax(probs, dim=1)主要需要注意的地方有2个:
1,model.eval():将model切到评估模式,也就是相当于设置每个子模块的training=False。
主要影响的层:Dropout停用(不随机丢弃),BatchNorm使用running_mean/running_var(不更新统计,也不使用当前batch的均值方差,因为训练集的数据分布和测试集的数据分布不一致,归一化时的均值、方差参数偏差会比较大,会影响model推理)。
一般就是推理/验证阶段必须调用,保证行为确定且与训练统计分离。
不影响下面提到的梯度计算开关,也就是不会关闭autograd,不会改变参数的requires_grad。
2,torch.no_grad():上下文管理器,临时关闭autograd的梯度跟踪与计算题构建。
一般就是为了在推理/验证阶段节省显存、加速前向、避免不必要的计算图,在no_grad内对张量的操作不会记录到计算图,不能用于backgrad。
不影响前面model的train/eval模式,不会切换BatchNorm/Dropout,也不改变参数的requires_grad标志,只是临时不追踪运算。
6,辅助脚本(src/utils.py)
其实除了上面的model架构、训练逻辑、推理逻辑之外,其余的一些函数、脚本、数据处理技巧,我们都可以放到辅助脚本文件中,
此处以前面的简易版pytorch代码为例,我们就可以将加载配置文件、监控训练过程(比如说绘制训练过程中的损失以及正确率等指标)等在这里进行设置。
我们此处简单的示例:
python
# src/utils.py
import yaml
import matplotlib.pyplot as plt
def load_config(config_path):
"""
Description
-----------
加载 YAML 配置文件
Args
-----
config_path : str
配置文件路径
"""
with open(config_path, 'r') as f:
return yaml.safe_load(f)
def plot_history(history):
"""
Description
-----------
绘制训练过程中的损失和准确率曲线
Args
-----
history : dict
训练历史记录,包含 'loss' 和 'acc' 两个列表
"""
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(history['loss'], label='Loss')
plt.title('Loss Curve')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history['acc'], label='Accuracy', color='orange')
plt.title('Accuracy Curve')
plt.legend()
plt.show()
# plt.savefig('training_result.png')7,主板(main.py)
前面定义了各种class类和模块,现在我们需要按照实际训练model的步骤以及逻辑,像搭积木一样,将所有的文件以及流程都串起来。
比如说,读取config文件,然后实例化Dataset、Model、Trainer,再将它们串起来。
简单来说就像是项目的入口,只要别人一看我们的代码中的main.py就能够知道数据怎么流向模型。
为了更像工程化的深度学习项目靠拢,我们这里对前面搭建的几个基本模块进行一些增量修改,但是主要功能、主要逻辑以及主要流程以及职责是不变的,这个是我们过渡到pytorch工业级深度学习项目所需要关注的。
数据输入处理方面:
python
# src/dataset.py
import torch
import numpy as np
import nnfs
from nnfs.datasets import spiral_data
from torch.utils.data import Dataset, DataLoader, random_split
# nnfs.init() # 通常在主程序入口调用
class SpiralDataset(Dataset):
"""
Description
---------
自定义 Dataset 类:负责从数据源读取并封装单个样本;
必须继承 torch.utils.data.Dataset, 实现 __len__ 和 __getitem__,
对于大数据集, __getitem__ 只在需要时加载单个文件 (Lazy Loading),节省内存
"""
def __init__(self, samples=100, classes=3):
"""
Description
---------
构造函数:初始化数据集
Args
---------
samples : int
每个类别的样本数
classes : int
类别数
Returns
---------
None
"""
# 实际项目中,这里通常接收文件路径 list,而不是直接生成数据
X, y = spiral_data(samples=samples, classes=classes)
self.X = torch.tensor(X, dtype=torch.float32)
self.y = torch.tensor(y, dtype=torch.long)
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
# 实际项目中,这里可能包含实时的数据增强 (Augmentation)
# 例如: torchvision.transforms
return self.X[idx], self.y[idx]
def get_dataloader(samples, classes, batch_size=32, shuffle=True, val_split=0.0):
"""
Description
---------
构建并返回 DataLoader, DataLoader负责batch批量加载数据/切分/shuffle打乱/多进程预取等
Args
---------
samples : int
每个类别的样本数
classes : int
类别数
batch_size : int or None
批量大小; None 表示全量梯度下降
shuffle : bool
是否打乱数据顺序
val_split : float
验证集比例 (0.0 ~ 1.0)
Returns
---------
DataLoader or (DataLoader, DataLoader)
Train DataLoader, [Val DataLoader]
Notes
---------
- 1. 不只返回一个 loader, 通常需要 Train/Val/Test split, 返回多个dataloader
- 2. 使用 num_workers 进行多进程预取: 待补充
- 3. 使用 pin_memory 加速 Host-to-Device 传输 (如果用 GPU): 待补充
"""
full_dataset = SpiralDataset(samples, classes)
# 全量梯度下降情况
if batch_size is None:
batch_size = len(full_dataset)
if val_split > 0:
val_size = int(len(full_dataset) * val_split)
train_size = len(full_dataset) - val_size
train_dataset, val_dataset = random_split(full_dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=shuffle)
# 验证集通常不shuffle
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
return train_loader, val_loader
else:
# 或者不显示给出shuffle参数, 在具体示例时再分别调整修改
return DataLoader(full_dataset, batch_size=batch_size, shuffle=shuffle)model架构方面
python
# src/model.py
import torch
import torch.nn as nn
class UniversalMLP(nn.Module):
"""
Description
------------
通用多层感知机 (MLP) 模板, 适用于分类/回归任务, 可用于进一步扩展(适用于tabular数据等)
Notes
------------
- 1. 不变的地方: 只写init定义层, forward定义流向, backward自动完成自动微分处理
- 2. 支持字符串指定激活函数, 也就是添加多种激活函数选择
- 增加权重初始化 (_init_weights)
"""
def __init__(self, input_dim, hidden_dims, output_dim, activation='relu', dropout_rate=0.0):
"""
Description
------------
初始化多层感知机, 动态构建隐藏层
Args
-----
input_dim : int
输入特征维度
hidden_dims : list of int
隐藏层维度列表, 每个元素代表一层的神经元数量
output_dim : int
输出维度 (类别数)
activation : str or nn.Module
激活函数模块名称('relu', 'tanh', 'sigmoid', 'leaky_relu') 或 nn.Module 类, 默认使用 ReLU
dropout_rate : float
Dropout 比例, 默认为 0.0 (不使用 Dropout)
Returns
-------
None
"""
# 调用父类构造函数
super(UniversalMLP, self).__init__()
layers = []
prev_dim = input_dim
# 激活函数选择:支持字符串或类
def get_activation(act):
if isinstance(act, str):
act = act.lower()
if act == 'relu': return nn.ReLU()
if act == 'tanh': return nn.Tanh()
if act == 'sigmoid': return nn.Sigmoid()
if act == 'leaky_relu': return nn.LeakyReLU()
raise ValueError(f"Unsupported activation string: {act}")
# 检查是否是元类(类的类), 或者是否继承自nn.Module
elif isinstance(act, type) and issubclass(act, nn.Module):
return act() # 实例化
else:
return act # 假设已经是实例,注意深拷贝问题,但在 Sequential 中主要关注每层是否独立
# 动态构建隐藏层
for h_dim in hidden_dims:
layers.append(nn.Linear(prev_dim, h_dim))
# BatchNorm 通常放在 Activation 之前 (ResNet v1) 或之后 (ResNet v2),这里演示放在前面, 也就是Linear和Activation之间
# layers.append(nn.BatchNorm1d(h_dim))
# 添加激活函数和Dropout
# 确保每次都生成一个新的 Activation 实例, 为每一层创建独立的实例, 不要把同一个activation实例重复使用在多层
layers.append(get_activation(activation))
if dropout_rate > 0:
layers.append(nn.Dropout(dropout_rate))
# 更新前一层维度
prev_dim = h_dim
# 输出层 (不加激活,因为 CrossEntropyLoss 包含 Softmax)
layers.append(nn.Linear(prev_dim, output_dim))
# 将列表转为 Sequential 容器
# 将各模块注册为 Module 的子模块, 以便参数能被正确识别和更新
self.network = nn.Sequential(*layers)
# 显示调用初始化
# 对全连接线性层权重进行初始化, 默认初始化可能导致训练不稳定/梯度消失/爆炸
# 我们只有全连接层, 所以这里只处理 nn.Linear; 我们只用 ReLU 激活函数, 所以选择 Kaiming 初始化
self.network.apply(self._init_weights)
def _init_weights(self, m):
"""
Description
-----------
权重初始化方法, Kaiming / Xavier 初始化,比默认初始化收敛更快
Args
----
m : nn.Module
模块实例, 通常是 nn.Linear, nn.Conv2d 等
Notes
-----
- 1. 初始化没做好容易梯度消失/爆炸,导致训练失败
- 2. Kaiming 初始化适合 ReLU 激活函数, Xavier 初始化适合 Sigmoid/Tanh 激活函数
- 3. 因为我们整个网络只包含全连接层, 所以这里只处理 nn.Linear, 忽略其他类型模块; 然后因为我们使用的是ReLU激活函数,
所以我们选择 Kaiming 初始化方法
"""
# 只初始化全连接线性层
if isinstance(m, nn.Linear):
# Kaiming He 初始化 (适合 ReLU)
# Kaiming正态分布初始化, 针对ReLU类激活函数设计的权重初始化方法, 避免深层网络训练时出现梯度消失/爆炸问题
# fan_out 保证反向传播时梯度方差的量级稳定(输出维度决定初始化范围)
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
# 对全连接层偏置初始化为0
nn.init.constant_(m.bias, 0)
def forward(self, x):
"""
Description
-----------
前向传播逻辑
Args
----
x : torch.Tensor
输入特征张量, 形状为 (batch_size, input_dim), 即 (批大小, 输入特征维度)
Returns
-------
torch.Tensor
输出张量, 形状为 (batch_size, output_dim), 即 (批大小, 输出维度/类别数)
"""
return self.network(x)训练逻辑方面
python
# src/trainer.py
import torch
import torch.nn as nn
import torch.optim as optim
import logging
import os
# 获取 logger
logger = logging.getLogger(__name__)
class EarlyStopping:
"""
Description
-----------
早停 (Early Stopping) 逻辑封装, 当验证集损失在 patience 个 epoch 内没有降低时,停止训练
"""
def __init__(self, patience=5, min_delta=0, path='best_model.pth'):
"""
Description
-----------
初始化早停参数
Args
-----
patience : int
容忍的最大不提升 epoch 数 (轮数, 即多少个 epoch 内验证集损失没有降低则停止训练)
min_delta : float
最小提升幅度 (即验证集损失必须降低至少 min_delta 才算提升)
path : str
最佳模型保存路径
Returns
-------
None
"""
self.patience = patience
self.min_delta = min_delta
self.path = path
# 没有提升的 epoch 计数器
self.counter = 0
# 最佳损失初始化为 None
self.best_loss = None
# 是否触发早停
self.early_stop = False
def __call__(self, val_loss, trainer, epoch=None):
if self.best_loss is None:
self.best_loss = val_loss
# 首次记录,保存为最佳模型
trainer.save_checkpoint(self.path, is_best=True, epoch=epoch)
elif val_loss > self.best_loss - self.min_delta:
self.counter += 1
logger.info(f"EarlyStopping counter: {self.counter} out of {self.patience}")
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_loss = val_loss
# 发现更优模型,保存
trainer.save_checkpoint(self.path, is_best=True, epoch=epoch)
self.counter = 0
class Trainer:
"""
Description
-----------
训练器 (Trainer) 逻辑封装, 包含训练循环、评估、保存模型等功能, 也就是model实际训练流程封装
Notes
-----------
- 1. 改进的地方:
- 使用 logging 替代 print, 方便日志管理, 相比于print, logging 可以灵活配置输出格式和级别,
可以将日志文件同时输出到控制台+文件, 便于调试和记录训练过程
- 增加 save_checkpoint 和 load_checkpoint
- 支持 验证集评估 (evaluate)
- 支持 早停 (Early Stopping) 逻辑
"""
def __init__(self, model, optimizer=None, criterion=None, device='cpu', save_dir='checkpoints'):
"""
Description
-----------
初始化训练器
Args
-----
model : torch.nn.Module
待训练的模型
optimizer : torch.optim.Optimizer, optional
优化器实例, 如果为 None 则使用 Adam 优化器
criterion : torch.nn.Module, optional
损失函数实例, 如果为 None 则使用 CrossEntropyLoss, 即默认为分类任务使用的交叉熵损失函数
device : str, optional
运行设备, 'cpu' 或 'cuda'
save_dir : str, optional
模型检查点保存目录, 检查点checkpoint数据, 包含模型权重和训练过程中的上下文信息, 目的是让训练可以诶断点续训或复用中间状态
Returns
-------
None
"""
self.model = model.to(device)
self.device = device
# 默认使用交叉熵损失 (分类任务标准)
self.criterion = criterion if criterion else nn.CrossEntropyLoss()
# 默认使用 Adam
self.optimizer = optimizer if optimizer else optim.Adam(model.parameters(), lr=0.001)
# 初始化历史记录,确保即使 resume 也能接续
self.history = {'loss': [], 'acc': [], 'val_loss': [], 'val_acc': []}
self.save_dir = save_dir
# 确保保存目录存在
os.makedirs(self.save_dir, exist_ok=True)
def train_epoch(self, dataloader):
"""
Description
-----------
训练单个 Epoch (遍历所有 Batch)
Args
-----
dataloader : torch.utils.data.DataLoader
训练数据的 DataLoader
Returns
-------
avg_loss : float
平均损失
avg_acc : float
平均准确率
"""
# 开启训练模式 (启用 Dropout/BatchNorm), 注意与后面的model.eval()区分, 后者是评估模式
self.model.train()
total_loss = 0
correct = 0
total = 0
for X_batch, y_batch in dataloader:
# 1. 搬运数据到 GPU/CPU
X_batch, y_batch = X_batch.to(self.device), y_batch.to(self.device)
# 2. 梯度清零
self.optimizer.zero_grad()
# 3. 前向传播
outputs = self.model(X_batch)
# 4. 计算损失
loss = self.criterion(outputs, y_batch)
# 5. 反向传播
loss.backward()
# 6. 更新参数
self.optimizer.step()
# 统计
total_loss += loss.item()
predicted = torch.argmax(outputs, dim=1)
# 或者如下, 返回(value, index)
# _, predicted = torch.max(outputs.data, 1)
total += y_batch.size(0)
correct += (predicted == y_batch).sum().item()
avg_loss = total_loss / len(dataloader) if len(dataloader) > 0 else 0
avg_acc = correct / total if total > 0 else 0
return avg_loss, avg_acc
@torch.no_grad()
def evaluate(self, dataloader):
"""
Description
-----------
验证集评估函数, 使用 @torch.no_grad() 装饰器自动关闭梯度计算,节省显存
"""
self.model.eval()
total_loss = 0
correct = 0
total = 0
for X_batch, y_batch in dataloader:
X_batch, y_batch = X_batch.to(self.device), y_batch.to(self.device)
outputs = self.model(X_batch)
loss = self.criterion(outputs, y_batch)
total_loss += loss.item()
predicted = torch.argmax(outputs, dim=1)
total += y_batch.size(0)
correct += (predicted == y_batch).sum().item()
avg_loss = total_loss / len(dataloader) if len(dataloader) > 0 else 0
avg_acc = correct / total if total > 0 else 0
return avg_loss, avg_acc
def save_checkpoint(self, path, epoch=None, is_best=False):
"""
Description
-----------
保存model检查点, 包含模型权重和优化器状态等信息, 以便于断点续训或复用模型
Args
-----
path: 检查点文件保存路径 (如果是相对路径,则相对于 self.save_dir)
epoch: 当前轮数 (用于断点续传)
is_best: 是否是最佳模型标记
"""
# 如果 path 是文件名,则拼接 save_dir
if not os.path.isabs(path) and os.path.dirname(path) == '':
path = os.path.join(self.save_dir, path)
state = {
'epoch': epoch,
'model_state_dict': self.model.state_dict(),
'optimizer_state_dict': self.optimizer.state_dict(),
'history': self.history
}
torch.save(state, path)
logger.info(f"Checkpoint saved to {path}" + (f" (Epoch {epoch})" if epoch else ""))
def load_checkpoint(self, path):
"""
Description
-----------
加载模型检查点, 恢复模型权重和优化器状态
Args
----
path : str
检查点文件路径
Returns
-------
start_epoch: 恢复后的起始 epoch (下一轮从 start_epoch 开始)
"""
if not os.path.exists(path):
logger.warning(f"Checkpoint file not found: {path} - Starting from scratch.")
return 1
logger.info(f"Loading checkpoint from {path}...")
checkpoint = torch.load(path, map_location=self.device)
self.model.load_state_dict(checkpoint['model_state_dict'])
if self.optimizer and 'optimizer_state_dict' in checkpoint:
self.optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
# 恢复 history
if 'history' in checkpoint:
self.history = checkpoint['history']
# 获取保存时的 epoch,下一轮从 epoch + 1 开始
ckpt_epoch = checkpoint.get('epoch')
if ckpt_epoch is None:
ckpt_epoch = 0 # 防御性编程:如果是 None,则假设从头开始(或这是一个纯权重文件)
start_epoch = ckpt_epoch + 1
return start_epoch
def fit(self, dataloader, epochs, val_dataloader=None, print_every=10, patience=None, resume_from=None):
"""
Description
-----------
训练模型主函数, 包含多个 Epoch 的训练循环, 可选验证集评估
Args
----
dataloader : torch.utils.data.DataLoader
训练数据的 DataLoader
epochs : int
训练轮数
val_dataloader : torch.utils.data.DataLoader, optional
验证数据的 DataLoader, 如果提供则在每个 epoch 训练结束后同时进行评估
print_every : int
每隔多少个 epoch 打印一次日志信息
patience : int, optional
早停 Patience (需要 val_dataloader)
resume_from : str, optional
检查点路径,用于恢复训练
Returns
-------
history : dict
训练历史记录,包含 'loss' 和 'acc' (以及验证集的 'val_loss' 和 'val_acc' 如果提供了验证集)
Notes
-----
- 1. model最后保存的几个检查点:
- last_checkpoint.pth: 最新的检查点,用于断点续训
- best_model.pth: 验证集上表现最好的模型 (如果提供了验证集)
- final_model.pth: 训练结束时的最终模型 (用于归档)
如果需要使用训练好的model来进行预测, 可以加载 best_model.pth (如果有验证集) 或 final_model.pth
"""
start_epoch = 1
# 1. 断点续传逻辑
if resume_from:
start_epoch = self.load_checkpoint(resume_from)
if start_epoch > epochs:
logger.info(f"Training already completed (Current Epoch {start_epoch-1} >= Target {epochs}).")
return self.history
logger.info(f"Start training on {self.device} from epoch {start_epoch} to {epochs}")
best_acc = 0.0
# 尝试从历史中恢复 best_acc,避免逻辑中断
if self.history.get('val_acc'):
best_acc = max(self.history['val_acc'])
# 初始化早停 (注意传入完整路径)
early_stopping_path = os.path.join(self.save_dir, 'best_model.pth')
early_stopping = EarlyStopping(patience=patience, path=early_stopping_path) if patience else None
for epoch in range(start_epoch, epochs + 1):
loss, acc = self.train_epoch(dataloader)
self.history['loss'].append(loss)
self.history['acc'].append(acc)
val_msg = ""
if val_dataloader:
val_loss, val_acc = self.evaluate(val_dataloader)
self.history['val_loss'].append(val_loss)
self.history['val_acc'].append(val_acc)
val_msg = f" | Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.4f}"
# 早停逻辑 (监控 Val Loss)
if early_stopping:
early_stopping(val_loss, self, epoch=epoch)
if early_stopping.early_stop:
logger.info("Early stopping triggered")
break
else:
# 如果没有 early stopping,手动保存 val acc 最高的
if val_acc > best_acc:
best_acc = val_acc
self.save_checkpoint('best_model.pth', epoch=epoch, is_best=True)
# 定期保存 "最新" 的检查点 (覆盖式,用于断点续传)
self.save_checkpoint('last_checkpoint.pth', epoch=epoch, is_best=False)
if epoch % print_every == 0:
current_lr = self.optimizer.param_groups[0]['lr']
logger.info(f"Epoch {epoch}/{epochs} | Loss: {loss:.4f} | Acc: {acc:.4f} | LR: {current_lr}{val_msg}")
# 训练结束保存最后一个模型 (可以作为归档)
self.save_checkpoint('final_model.pth', epoch=epochs, is_best=False)
return self.history 辅助脚本utils
python
# src/utils.py
import os
import yaml
import random
import logging
import numpy as np
import matplotlib.pyplot as plt
import torch
def setup_logging(log_file='training.log'):
"""
Description
-----------
配置 logging, 让实验过程中的关键信息(如训练进度、评估结果等)同时记录到控制台和文件中,
方便实时查看和后续回朔查看
- 同时输出到控制台(Console)和文件(File)
- 格式: [时间] [级别] 消息
Args
-----
log_file : str
日志文件路径
"""
logging.basicConfig(
level=logging.INFO, # 日志级别, 只显示 INFO 及以上级别的日志
format='[%(asctime)s] [%(levelname)s] %(message)s', # 日志格式
handlers=[
logging.StreamHandler(), # 控制台输出
logging.FileHandler(log_file) # 文件输出
]
)
def seed_everything(seed=2026):
"""
Description
-----------
固定所有随机种子,保证实验可复现 (Reproducibility)
Args
-----
seed : int
随机种子
"""
# 固定python的random库的随机性(如shuffle等)
random.seed(seed)
# 固定python哈希随机性(如dict的遍历顺序)
os.environ['PYTHONHASHSEED'] = str(seed)
# 固定numpy库的随机性(如np.random.shuffle等, 随机数生成等)
np.random.seed(seed)
# 固定pytorch核心随机性(cpu/单卡场景下的model参数初始化/dropout等)
torch.manual_seed(seed)
# 固定pytorch单张gpu的随机性(确保单卡随机操作一致)
torch.cuda.manual_seed(seed)
# 固定pytorch多张gpu的随机性(确保多卡随机操作一致)
torch.cuda.manual_seed_all(seed)
# 固定 cuDNN 库(GPU 加速库)的算法确定性(避免非确定性算法导致结果波动)
# 可能会稍微降低性能,但保证确定性(cuDNN算法选择)
torch.backends.cudnn.deterministic = True
# 关闭 cuDNN 算法自动调优(避免动态选算法带来的随机性)
torch.backends.cudnn.benchmark = False
def load_config(config_path, defaults=None):
"""
Description
-----------
加载 YAML 配置文件并与 defaults 递归合并
Args
-----
config_path : str
配置文件路径
defaults : dict, optional
默认配置字典,用于补全 config 中缺失的项
Returns
-------
dict
合并后的配置字典
"""
if not os.path.exists(config_path):
raise FileNotFoundError(f"Config file not found: {config_path}")
with open(config_path, 'r') as f:
config = yaml.safe_load(f) or {}
# 递归合并输入的配置字典和默认的配置字典
# 仅作为补全使用,config 中已有的键值不被覆盖
# 仅作为示例,实际项目中可根据需要调整合并逻辑
def recursive_merge(default_dict, new_dict):
if not isinstance(default_dict, dict) or not isinstance(new_dict, dict):
return new_dict
result = default_dict.copy()
for k, v in new_dict.items():
if k in result and isinstance(result[k], dict) and isinstance(v, dict):
result[k] = recursive_merge(result[k], v)
else:
result[k] = v
return result
if defaults:
return recursive_merge(defaults, config)
return config
def plot_history(history, save_path=None, show=True):
"""
Description
-----------
绘制训练过程中的损失和准确率曲线 (包含训练集和验证集)
Args
-----
history : dict
训练历史记录,包含 'loss', 'acc', 'val_loss', 'val_acc'
save_path : str, optional
图片保存路径,如果为 None 则不保存
show : bool
是否调用 plt.show() 显示图片 (在无头服务器上设为 False)
"""
# 辅助转换函数
def to_cpu_list(data):
return [x if isinstance(x, (int, float)) else x.item() for x in data]
loss = to_cpu_list(history.get('loss', []))
val_loss = to_cpu_list(history.get('val_loss', []))
acc = to_cpu_list(history.get('acc', []))
val_acc = to_cpu_list(history.get('val_acc', []))
plt.figure(figsize=(12, 5))
# 绘制 Loss
plt.subplot(1, 2, 1)
if loss: plt.plot(loss, label='Train Loss')
if val_loss: plt.plot(val_loss, label='Val Loss', linestyle='--')
plt.title('Loss Curve')
plt.xlabel('Epochs')
plt.legend()
# 绘制 Accuracy
plt.subplot(1, 2, 2)
if acc: plt.plot(acc, label='Train Acc', color='orange')
if val_acc: plt.plot(val_acc, label='Val Acc', color='red', linestyle='--')
plt.title('Accuracy Curve')
plt.xlabel('Epochs')
plt.legend()
if save_path:
# 自动创建父目录
os.makedirs(os.path.dirname(save_path), exist_ok=True)
plt.savefig(save_path)
print(f"Figure saved to {save_path}")
if show:
plt.show()
plt.close() # 释放资源然后现在我们需要依据上面的内容修改一下我们的配置文件
也就是我们的yaml文件
python
# 超参数配置,在源代码中通过yaml库加载
# 可根据需要修改这些参数以调整模型训练行为, 不需要在代码中硬编码
data:
samples: 500
classes: 3
batch_size: 64 # None 在 yaml 中表示 null,最好显式指定数值
model:
input_dim: 2
hidden_dims: [64, 128, 32] # 可以通过列表配置多个隐藏层, 动态调整层深
output_dim: 3
activation: 'relu' # 新增:支持字符串配置
dropout_rate: 0.0
training:
epochs: 10000
learning_rate: 2e-3
weight_decay: 5e-4
print_every: 10
seed: 2026 # 复现性
save_dir: 'checkpoints' # 模型保存路径整体的文件组织结构和前面的基本一致:
然后就是我们主要的入口文件main
python
# main.py
import argparse
import datetime
import logging
import torch
import torch.optim as optim
import nnfs # 这个只是为了生成示例数据导入的一个特殊的库, 实际项目中不一定需要
from src.utils import load_config, plot_history, setup_logging, seed_everything
from src.dataset import get_dataloader
from src.model import UniversalMLP # 这里导入我们的model定义
from src.trainer import Trainer
# from src.predict import predict
def parse_args():
parser = argparse.ArgumentParser(description="A very simple PyTorch Neural Network Project")
parser.add_argument('--config', type=str, default='configs/config.yaml', help='Path to config file')
return parser.parse_args()
def main():
args = parse_args()
# 1. 基础设施初始化
# '2026-01-23_16-17-38'
setup_logging(log_file=f'training_{datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S")}.log')
logger = logging.getLogger(__name__)
logger.info("Project initialized.")
# 加载配置
cfg = load_config(args.config)
seed_everything(cfg['training'].get('seed', 2026))
# 初始化 nnfs (仅用于生成示例数据), 这个库在实际项目中不一定需要
nnfs.init()
# 自动选择设备 (GPU 优先)
device = "cuda" if torch.cuda.is_available() else "cpu"
logger.info(f"Using device: {device}")
# 2. 准备数据
# 工业级:通常会有 Train/Val Split
# 注意:这里我们演示 batch_size 的使用. 如果在 yaml 里 batch_size 设为 null,则代码 logic 需要处理
batch_size = int(cfg['data'].get('batch_size', None))
# 获取训练集和验证集 DataLoader
# 解释: 这里的划分是在 Dataset 层面进行的,与 batch_size 无关。
# 我们先将总数据随机划分为 训练集 和 验证集,然后分别封装成 DataLoader。
# 这样可以在每个 Epoch 结束时用验证集评估模型性能,监控过拟合.
# 训练集和验证集就划分1次, 后续每一次epoch就是拿这个训练集一直在shuffle取batch训练, 然后每个batch拿固定的这个验证集评估
train_loader, val_loader = get_dataloader(
samples=int(cfg['data']['samples']),
classes=int(cfg['data']['classes']),
batch_size=batch_size,
shuffle=True,
val_split=0.2 # 划分 20% 作为验证集
)
# 3. 构建模型 (动态结构)
model = UniversalMLP(
input_dim=int(cfg['model']['input_dim']),
hidden_dims=cfg['model']['hidden_dims'],
output_dim=int(cfg['model']['output_dim']),
activation=cfg['model'].get('activation', 'relu'),
dropout_rate=float(cfg['model']['dropout_rate'])
)
logger.info(f"Model structure:\n{model}")
# 4. 定义优化器
# weight_decay (权重衰减): 即 L2 正则化项.
# 作用: 限制权重数值的大小,防止模型过拟合. 值越大,惩罚越强
optimizer = optim.Adam(
model.parameters(),
lr=float(cfg['training']['learning_rate']),
weight_decay=float(cfg['training']['weight_decay'])
)
# 5. 初始化训练器并开始训练
trainer = Trainer(
model,
optimizer,
device=device,
save_dir=cfg['training'].get('save_dir', 'checkpoints')
)
logger.info("Start Training...")
history = trainer.fit(
train_loader,
epochs=int(cfg['training']['epochs']),
val_dataloader=val_loader, # 传入验证集
print_every=int(cfg['training']['print_every'])
)
# 6. 可视化并保存结果
plot_history(history, save_path=f"{cfg['training'].get('save_dir', 'checkpoints')}/training_curve.png", show=False)
logger.info("Training Finished.")
if __name__ == "__main__":
main()我们此处写成一个命令行脚本,只需要通过命令行传入配置文件参数即可
python
python main.py --config configs/config.yaml这里我们还是用生成的模拟螺旋数据,模拟3类,每一类共500个样本点,一共是1500个样本,每个样本我们提供二维的坐标,以及一个类别的label,
然后做一个多分类任务,实际训练过程中我们将完整的数据划分8:2出训练集:验证集(此处一次划分永远不变,然后训练集拿来下一步的全局epoch训练),
然后训练集中我们再划分batch,然后每一个epoch都要shuffle一次,然后每一个epoch前向传播计算loss------》求梯度------》反向传播梯度------》更新参数,直到完成一个epoch,
然后每一个batch的loss或者是预测的准确率我们可以累加起来,在一个epoch中输出一个训练集的平均loss以及平均准确率等指标;
然后注意这里我们再每一个epoch训练之后,同时还用这个epoch训练完毕的模型对验证集进行了测试,包括输出loss和准确率,主要是我们判断model好坏,或者是想实现早停的机制,我们就必须得在这里通过验证集来记录我们model到底训练得好还是不好,当然这里验证集只是评估以及保存最优模型用,当然没有参与到梯度计算、参数更新,也就是没有影响到下一个epoch的训练集的训练。
我截取部分训练日志如下
python
[2026-01-23 15:58:19,692] [INFO] Project initialized.
[2026-01-23 15:58:19,756] [INFO] Using device: cuda
[2026-01-23 15:58:19,758] [INFO] Model structure:
UniversalMLP(
(network): Sequential(
(0): Linear(in_features=2, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=128, bias=True)
(3): ReLU()
(4): Linear(in_features=128, out_features=32, bias=True)
(5): ReLU()
(6): Linear(in_features=32, out_features=3, bias=True)
)
)
[2026-01-23 15:58:20,198] [INFO] Start Training...
[2026-01-23 15:58:20,198] [INFO] Start training on cuda from epoch 1 to 10000
[2026-01-23 15:58:20,399] [INFO] Checkpoint saved to checkpoints/best_model.pth (Epoch 1)
[2026-01-23 15:58:20,435] [INFO] Checkpoint saved to checkpoints/last_checkpoint.pth (Epoch 1)
[2026-01-23 15:58:20,479] [INFO] Checkpoint saved to checkpoints/best_model.pth (Epoch 2)
[2026-01-23 15:58:20,584] [INFO] Checkpoint saved to checkpoints/last_checkpoint.pth (Epoch 2)
[2026-01-23 15:58:20,605] [INFO] Checkpoint saved to checkpoints/best_model.pth (Epoch 3)
[2026-01-23 15:58:20,610] [INFO] Checkpoint saved to checkpoints/last_checkpoint.pth (Epoch 3)
[2026-01-23 15:58:20,634] [INFO] Checkpoint saved to checkpoints/last_checkpoint.pth (Epoch 4)
[2026-01-23 15:58:20,675] [INFO] Checkpoint saved to checkpoints/last_checkpoint.pth (Epoch 5)
[2026-01-23 15:58:20,715] [INFO] Checkpoint saved to checkpoints/last_checkpoint.pth (Epoch 6)
[2026-01-23 15:58:20,742] [INFO] Checkpoint saved to checkpoints/last_checkpoint.pth (Epoch 7)
[2026-01-23 15:58:20,769] [INFO] Checkpoint saved to checkpoints/best_model.pth (Epoch 8)
[2026-01-23 15:58:20,776] [INFO] Checkpoint saved to checkpoints/last_checkpoint.pth (Epoch 8)
[2026-01-23 15:58:20,800] [INFO] Checkpoint saved to checkpoints/best_model.pth (Epoch 9)
[2026-01-23 15:58:20,817] [INFO] Checkpoint saved to checkpoints/last_checkpoint.pth (Epoch 9)
[2026-01-23 15:58:20,840] [INFO] Checkpoint saved to checkpoints/best_model.pth (Epoch 10)
[2026-01-23 15:58:20,861] [INFO] Checkpoint saved to checkpoints/last_checkpoint.pth (Epoch 10)
[2026-01-23 15:58:20,861] [INFO] Epoch 10/10000 | Loss: 0.8080 | Acc: 0.6992 | LR: 0.002 | Val Loss: 0.7696 | Val Acc: 0.7233
[2026-01-23 15:58:20,889] [INFO] Checkpoint saved to checkpoints/best_model.pth (Epoch 11)中间这一块就是我们写的简陋的多层感知机框架细节:
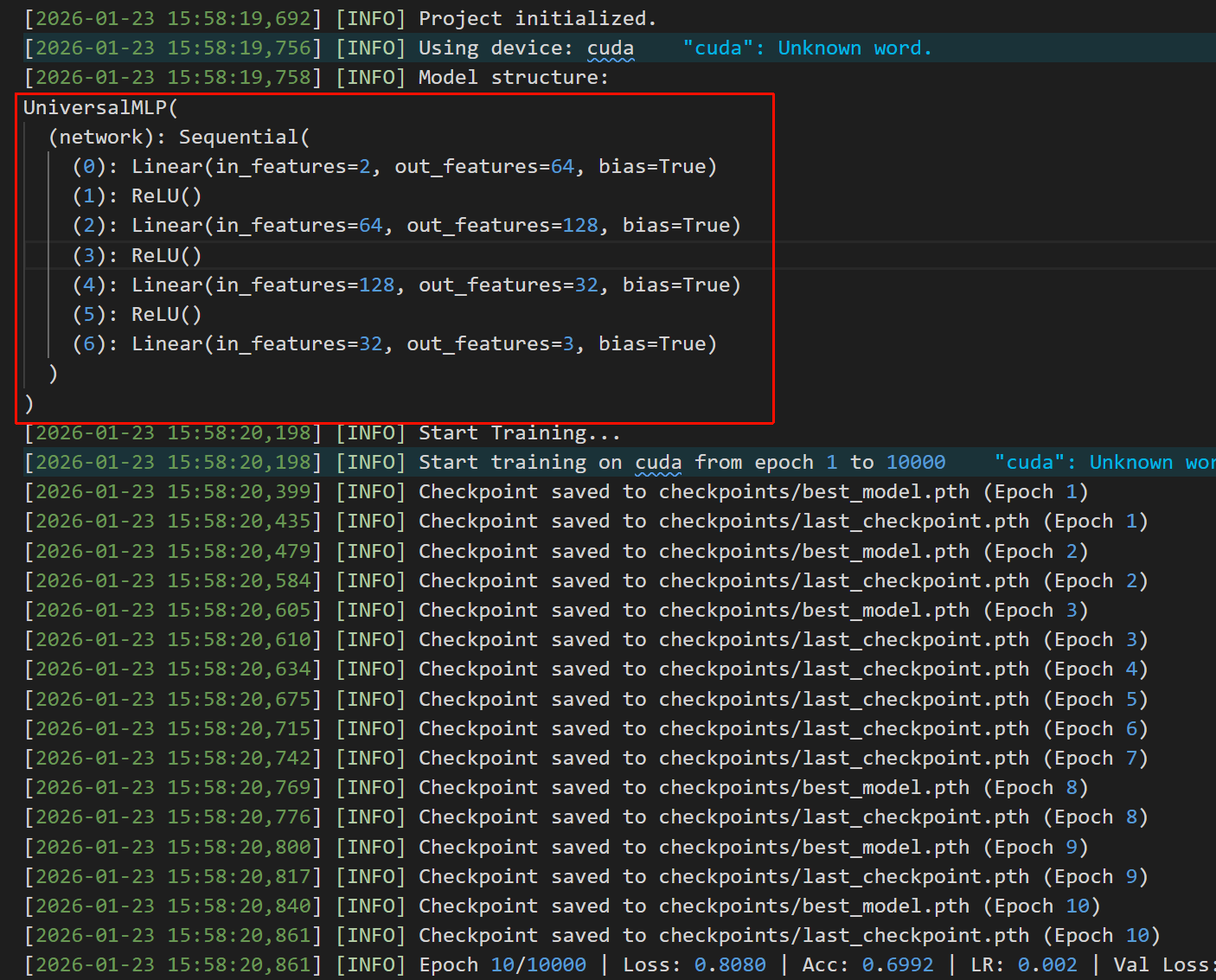
也就4层,
然后我们的训练过程监控如下,实际训练过程中并没有发生早停,所以1w个epoch都跑完了;
从训练效果上看,还行,符合我们的预期,总之我们可以不用支持向量机、二次判别分析等经典机器学习技巧,
只需要暴力叠起来层数,然后一股脑放进去训练(至少对于我们本章入门任务而言足够了)
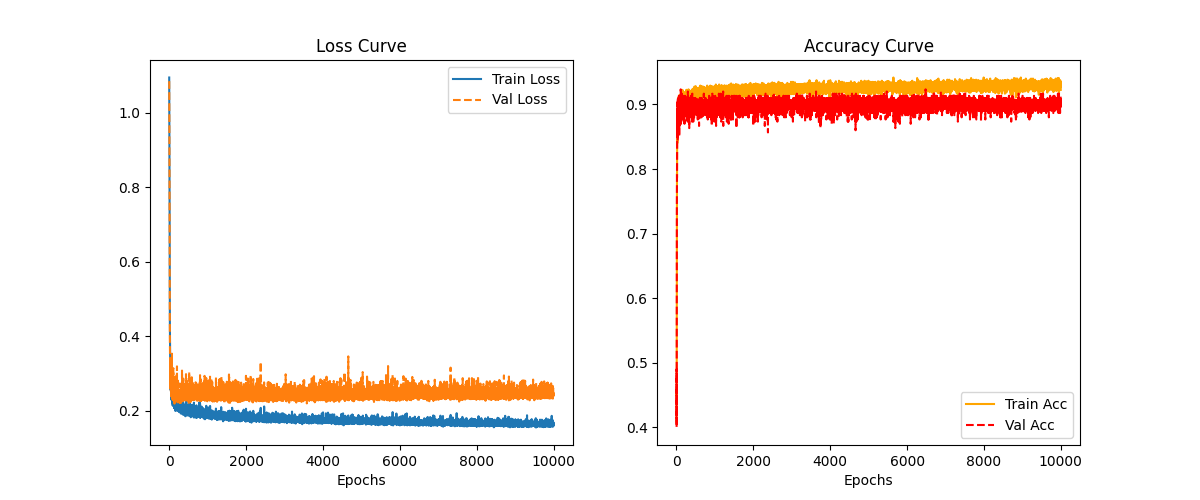
8,完全独立地加载模型进行推理(Inference)
推理是我们模型工程化不得不品的一环,也是我们模型训练的最终目的。
此处我们不依赖predict部分代码,而是如果我们想要在独立的测试脚本或者是随便一个notebook单元中进行测试的话,我们一般需要按照下面三步走:
- 实例化model架构(必须和训练时的参数一模一样)
- 加载权重文件(主要是处理state_dict,当然测试的话我们用前面训练中保存下来的最好的model的权重文件)
- 进入评估模式(eval,主要是batchnorm和dropout问题)
python
import torch
import sys
# ---------------------------------------------------------
# 1. 确保能导入 src 模块
# 就是需要将我们模型构建所依赖的各种脚本文件都加入到python路径中,
# 或者可以通过python路径去相对访问, 那一般就是sys.path.append
# ---------------------------------------------------------
current_dir # 假设current_dir是我们model所在的文件目录
if current_dir not in sys.path:
sys.path.append(current_dir)
from src.model import UniversalMLP # 导入模型定义
# ---------------------------------------------------------
# 2. 实例化模型架构
# ⚠️ 关键点:这里的参数必须与我们 config.yaml 中训练时的参数完全一致!
# ---------------------------------------------------------
# 假设我们在 config.yaml 里是这样配置的 (也就是前面训练时的实际情况):
model_params = {
"input_dim": 2, # 输入特征维度
"hidden_dims": [64, 128, 32], # 隐藏层结构
"output_dim": 3, # 输出类别数
"activation": 'relu' # 激活函数
}
# 初始化一个"空壳"模型
model = UniversalMLP(**model_params)
# ---------------------------------------------------------
# 3. 加载权重 (Best Weights)
# ---------------------------------------------------------
checkpoint_path = 'checkpoints/best_model.pth' # 最好权重的路径
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if os.path.exists(checkpoint_path):
print(f"Loading weights from {checkpoint_path}...")
# 加载 checkpoint 字典
checkpoint = torch.load(checkpoint_path, map_location=device)
# ⚠️ 注意: 我们的 Trainer 保存的是一个包含多个信息的字典
# 通常 key 是 'model_state_dict' 或 'state_dict'
if 'model_state_dict' in checkpoint:
model.load_state_dict(checkpoint['model_state_dict'])
else:
# 如果直接保存的是 state_dict (不常见但有可能)
model.load_state_dict(checkpoint)
print("✅ Model loaded successfully!")
else:
print(f"❌ Error: Checkpoint not found at {checkpoint_path}")
# ---------------------------------------------------------
# 4. 预测 (Inference)
# ---------------------------------------------------------
model.to(device)
model.eval() # ⚠️ 极其重要: 关闭 Dropout 和 BatchNrom 的训练行为
# 构造一个虚假数据样本用来测试 (batch_size=1, features=2)
dummy_input = torch.tensor([[0.5, -0.5]], dtype=torch.float32).to(device)
# 或者是使用nnfs再生成一个模拟数据
with torch.no_grad(): # ⚠️ 极其重要: 不计算梯度,节省显存并加速
logits = model(dummy_input)
probs = torch.softmax(logits, dim=1)
predicted_class = torch.argmax(probs, dim=1).item()
print(f"\n🔮 Prediction Results:")
print(f"Logits: {logits.cpu().numpy()}")
print(f"Probabilities: {probs.cpu().numpy()}")
print(f"Predicted Class: {predicted_class}")比如说我们这里的这个模拟测试数据,
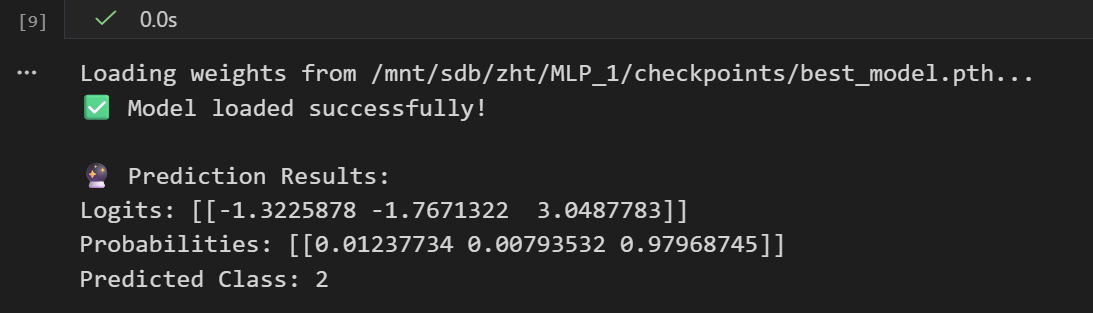
这里我们可以看一下权重文件,
可以发现,保存的是第111个epoch的网络参数,可以说我们一共1w个epoch,但是在前1%左右的位置处,我们的model已经收敛到在验证集上不错了,甚至后面99%左右的训练model都没有让验证集上loss降下来过。
总而言之,权重文件pth中的model_state_dict是我们需要的
我们这里再试一下,如果是使用模拟的批次处理数据会怎么样,到底准确率如何
python
import torch
import sys
import os
import nnfs
from nnfs.datasets import spiral_data
import numpy as np
# ---------------------------------------------------------
# 1. 确保能导入 src 模块
# 就是需要将我们模型构建所依赖的各种脚本文件都加入到python路径中,
# 或者可以通过python路径去相对访问, 那一般就是sys.path.append
# ---------------------------------------------------------
current_dir = "/mnt/sdb/zht/MLP_1" # 假设current_dir是我们model所在的文件目录
if current_dir not in sys.path:
sys.path.append(current_dir)
from src.model import UniversalMLP # 导入模型定义
# ---------------------------------------------------------
# 2. 实例化模型架构
# ⚠️ 关键点:这里的参数必须与我们 config.yaml 中训练时的参数完全一致!
# ---------------------------------------------------------
# 假设我们在 config.yaml 里是这样配置的 (也就是前面训练时的实际情况):
model_params = {
"input_dim": 2, # 输入特征维度
"hidden_dims": [64, 128, 32], # 隐藏层结构
"output_dim": 3, # 输出类别数
"activation": 'relu' # 激活函数
}
# 初始化一个"空壳"模型
model = UniversalMLP(**model_params)
# ---------------------------------------------------------
# 3. 加载权重 (Best Weights)
# ---------------------------------------------------------
checkpoint_path = '/mnt/sdb/zht/MLP_1/checkpoints/best_model.pth' # 最好权重的路径
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if os.path.exists(checkpoint_path):
print(f"Loading weights from {checkpoint_path}...")
# 加载 checkpoint 字典
checkpoint = torch.load(checkpoint_path, map_location=device)
# ⚠️ 注意: 我们的 Trainer 保存的是一个包含多个信息的字典
# 通常 key 是 'model_state_dict' 或 'state_dict'
if 'model_state_dict' in checkpoint:
model.load_state_dict(checkpoint['model_state_dict'])
print("✅ Model loaded successfully!")
else:
print(f"❌ Error: Checkpoint not found at {checkpoint_path}")
# ---------------------------------------------------------
# 4. 预测 (Inference)
# ---------------------------------------------------------
model.to(device)
model.eval() # ⚠️ 极其重要: 关闭 Dropout 和 BatchNrom 的训练行为
# 构造一个虚假数据样本用来测试
x_test, y_test = spiral_data(samples=100, classes=3)
x_test = torch.tensor(x_test, dtype=torch.float32).to(device)
y_test = torch.tensor(y_test, dtype=torch.long).to(device)
with torch.no_grad(): # ⚠️ 极其重要: 不计算梯度,节省显存并加速
logits = model(x_test)
probs = torch.softmax(logits, dim=1)
# 单个样本预测可以用.items()
predicted_classes = torch.argmax(probs, dim=1)
# 多个样本预测, 其实就是批量输出, 必须得先转换为numpy数组
logits_np = logits.cpu().numpy()
probs_np = logits.cpu().numpy()
predicted_classes_np = predicted_classes.cpu().numpy()
# 前面是先将y_test转换为tensor再迁移到gpu上, 现在反过来先从gpu迁移到cpu上再从tensor转换为numpy的ndarray
y_test_np = y_test.cpu().numpy()
print(f"\n🔮 Prediction Results:")
print(f"Logits: {logits_np}")
print(f"Probabilities: {probs_np}")
print(f"Predicted Class: {predicted_classes_np}")
print(f"accuracy {np.mean(predicted_classes_np == y_test_np)}")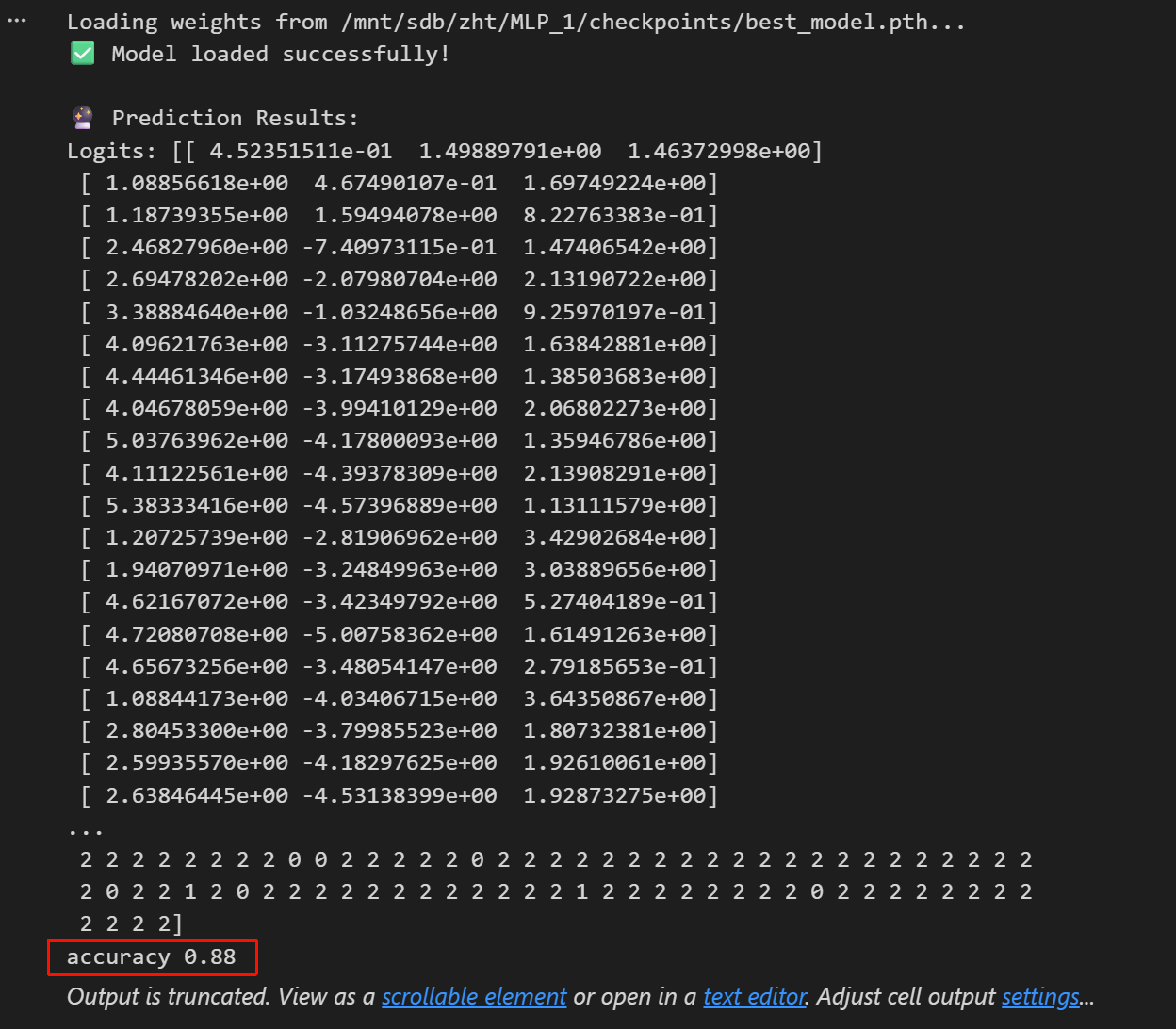
勉勉强强还行
5,总结
其实这个系列出到这里,已经算是从python纯数据分析能够接轨上pytorch生态以及神经网络了。
接下来的路其实就很好走了,
学好pytorch语法,然后直接去找感兴趣的架构(先学理论,再找模板),按照我们这里从numpy到pytorch的铺桥搭路,其实对于找到的模板,大部分应该都能够比较轻松地去理解了(前提是理论部分已经学完了)