知识图谱------构建安全大脑的"神经突触"
你好,我是陈涉川,第七篇我们要完成一个巨大的跨越:从"连接主义(Connectionism)"跨越到"符号主义(Symbolism)"。
前几篇讲的深度学习(Deep Learning),本质上是模拟直觉。它能一眼看出"这像个坏人",但说不出为什么。
而知识图谱(Knowledge Graph),本质上是模拟逻辑。它像福尔摩斯一样,把线索贴在墙上,用红线连起来,最终推导出:"因为 A 连着 B,B 属于 C,所以 A 是 C 的间谍。"
这将是《硅基之盾》中当前最具"智慧"气息的一篇。我们将深入数据结构的灵魂,构建安全大脑的神经突触。
引言:从"鹦鹉"到"侦探"
在之前的文章中,我们训练了极其强大的神经网络。它们能识别复杂的 DGA 域名,能从加密流量中嗅探出恶意软件的指纹。
但是,作为一个安全负责人,你是否遇到过这种尴尬的场景?
AI 系统: "警报!IP 192.168.1.105 极其可疑,置信度 99%!"
分析师: "为什么?它做了什么?"
AI 系统: "我不知道。但我的几百万个神经元被激活了,它看起来就像我以前见过的坏蛋。"
分析师: "......"
这就是深度学习的可解释性(Explainability)危机 。目前的 AI 像一只训练有素的鹦鹉,或者是直觉敏锐的猎犬,但它缺乏逻辑推理的能力。
它看到的是点(Data Points) ,而安全专家看到的是线(Relationships)。
- 那个 IP 是谁的?(实体)
- 它为什么在访问财务服务器?(关系)
- 这个财务服务器上周是不是刚爆出了 Log4j 漏洞?(背景知识)
- 这个 IP 之前是不是由于中了钓鱼邮件而被标记过?(历史情报)
当我们把这些孤立的"点",通过"线"连接起来,我们就得到了一张图。这张图,就是知识图谱(Knowledge Graph, KG)。
本篇将探讨如何构建这个能够进行逻辑推理的"安全大脑"。我们将从感性的概率判断,进化到理性的因果推演。
第一章:图的哲学------世界是网状的,不是表状的
在进入技术细节前,我们需要升级一下世界观。
1.1 关系型数据库(RDBMS)的局限
过去 40 年,我们的数据一直住在 Excel 表格(或 SQL 数据库)里。
- 表格 A:用户表
- 表格 B:资产表
- 表格 C:日志表
如果你想问:"哪个用户访问了受感染的资产?",你需要做 JOIN(连接) 操作。
当数据量达到亿级时,多表 JOIN 是数据库的噩梦。这不是简单的加法,而是指数级的性能消耗。当你要查询"A 连着 B,B 连着 C,C 连着 D"这种 4 跳(4-hop)查询时,传统数据库需要进行多次繁重的索引查找(Index Lookups)。每多一跳,查询复杂度就呈指数级上升。在表格里,你很难直观地看到"攻击链路",因为表格切断了事物之间的自然联系。
1.2 图(Graph)的崛起
现实世界不是表格,现实世界是网。
- 节点(Node/Vertex): 实体。如 IP地址、域名、恶意软件Hash、黑客组织、漏洞CVE。
- 边(Edge/Relationship): 关系。如 访问、解析为、包含、利用了、归属于。
知识图谱的定义:
知识图谱 = 实体(Entities) + 关系(Relations) + 属性(Attributes)。
本质上,它是由无数个 <主体, 谓语, 客体> 的**三元组(Triples)**构成的语义网络。
例子:
<IP: 1.2.3.4, 属于, 僵尸网络: Mirai>
<僵尸网络: Mirai, 利用了, 漏洞: CVE-2017-1000>
<漏洞: CVE-2017-1000, 存在于, 设备: 摄像头X>
通过这三个三元组,AI 瞬间就能推理出:这个 IP 正在试图攻击那种型号的摄像头。 不需要复杂的计算,只需要顺着藤摸瓜。
1.3 维度的升级:从三元组到四元组
现实世界不仅是网状的,更是流动的。安全是时间的艺术。
- IP 1.2.3.4 昨天是正常的家庭宽带。
- IP 1.2.3.4 今天早上被 Mirai 僵尸网络感染了。
- IP 1.2.3.4 今天下午被运营商清洗了。
如果图谱忽略时间,你会产生大量误报。因此,实战中的安全图谱必须是时序知识图谱(Temporal Knowledge Graph) 。我们需要将数据结构从三元组升级为四元组(Quads):
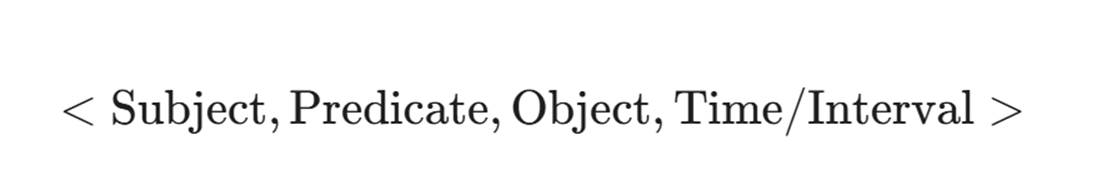
例子:
<IP: 1.2.3.4, 属于, 僵尸网络: Mirai, 2024-01-01 10:00 - 2024-01-01 14:00>
只有加上了时间戳,AI 才能精准推理出:"这个 IP 在那个特定时间窗口内 是恶意的,所以当时的访问是危险的。"
第二章:本体论(Ontology)------定义安全世界的语言
要建图,首先要"书同文,车同轨"。我们需要一套标准来定义什么是"IP",什么是"攻击"。
这就是本体论(Ontology) ,或者是图模式(Schema)。
2.1 为什么要定义本体?
如果你的图谱里,有的节点叫 IpAddress,有的叫 ip_addr,有的叫 Host,AI 就会精神分裂。
我们需要一个极其严谨的数据字典。
2.2 行业标准:STIX 2.1
不要自己造轮子。在网络安全威胁情报(CTI)领域,全球公认的标准是 OASIS 制定的 STIX (Structured Threat Information Expression)。
STIX 定义了 18 种核心领域对象(SDO),构成了我们图谱的骨架:
- Attack Pattern (攻击模式): 比如 "SQL Injection"。
- Campaign (战役): 黑客组织发起的一次有计划的行动。
- Identity (身份): 攻击者(如 APT29)或受害者(如 Acme Corp)。
- Indicator (指标/IOC): Indicator (指标/IOC): 这是检测规则。例如:"如果流量中包含字符串 'x-pwn',则是恶意"。(注意:这是逻辑判定标准,不是已经发生的事实)。
- Malware (恶意软件): 如 "WannaCry"。
- Observed Data (观测数据): 这是网络事实。例如:防火墙日志中实际记录的"IP A 在 10:00 访问了 IP B"。图谱的推理核心,往往就是拿 Indicator 去匹配 Observed Data。
- Vulnerability (漏洞): 如 CVE 编号。
- Course of Action (应对措施): 比如"封锁端口"。
2.3 关系(SRO)
同样,STIX 也定义了标准关系:
- targets (针对)
- uses (使用)
- attributed-to (归因于)
- mitigates (缓解)
- indicates (指示)
实战价值:
一旦你的数据清洗管道(ETL)遵循了 STIX 标准,你就拥有了与全球安全社区对话的能力。你可以直接导入 IBM X-Force 或 AlienVault 的威胁情报,无缝接入你自己的图谱中。
第三章:知识抽取(Knowledge Extraction)------从混沌到有序
既然有了骨架(Ontology),如何把肉(数据)填进去?
我们的数据源是杂乱无章的:
- 结构化数据: 防火墙日志、NetFlow(容易处理)。
- 非结构化数据: 安全厂商发布的 PDF 威胁报告、黑客论坛的帖子、Twitter 上的漏洞预警(极难处理)。
这时候,我们需要 NLP(自然语言处理) 技术来做"信息抽取"。
3.1 命名实体识别(NER)
这是第一步:从文本中把"实体"抠出来。
- 输入文本: "Lazarus group used the NukeSped malware to attack financial institutions in 2024."
- NER 模型输出:
- Lazarus group -> Threat Actor
- NukeSped -> Malware
- financial institutions -> Identity (Target)
- 2024 -> Time
在安全领域,通用的 BERT 模型效果不好。我们需要在安全语料上微调过的 SecBERT,它能精准识别 Trojan.Win32.Zapchast 是一个恶意软件,而不是一个文件名。
3.2 关系抽取(Relation Extraction)
这是第二步:判断实体之间的关系。
- 模型任务: 给定 Lazarus group 和 NukeSped,判断它们中间连什么线?
- 输出: uses (使用)。
- 生成三元组: <Lazarus, uses, NukeSped>。
3.3 实体对齐(Entity Alignment)与融合
这是最头疼的一步。
- 报告 A 提到了 APT28。
- 报告 B 提到了 Fancy Bear。
- 报告 C 提到了 Sofacy。
知识图谱必须知道:这三个名字指的是同一个黑客组织。
我们需要维护一个庞大的同义词库(Alias DB),利用图嵌入(Graph Embedding)计算节点相似度,将这些节点合并(Merge)为一个节点,消除歧义。
第四章:存储引擎------图数据库(Graph Database)的选择
数据抽取出来了,存哪儿?
存 MySQL?绝对不行。
当你要查询"A 连着 B,B 连着 C,C 连着 D,D 的属性是 X"这种 4 跳(4-hop)查询时, MySQL 需要进行多次繁重的索引查找(Index Lookups)。每多一跳,查询复杂度就呈指数级上升。如果表里有 1000 万行数据,这个查询可能要跑 20 分钟。
在安全攻防中,我们需要毫秒级响应。
4.1 图数据库的魔力:免索引邻接(Index-Free Adjacency)
图数据库(如 Neo4j, Nebula Graph)在物理存储层面,直接保存了节点之间的指针。
- 原理: 节点 A 知道它直接连着节点 B(内存地址)。
- 性能: 从 A 走到 B,不需要查索引,直接跳过去。复杂度是 O(1)。
- 结果: 无论图有多大,查询"邻居"的速度是恒定的。这使得深度的关联分析成为可能。
4.2 选型指南
- Neo4j:
- 优点: 老牌,社区极其成熟,Cypher 查询语言(类似 SQL)非常好用。
- 缺点: 单机版性能有上限,大规模分布式集群(Causal Clustering)需要昂贵的企业版授权。
- 适用: 中小型企业,构建数亿节点以内的图谱。
- Nebula Graph / HugeGraph:
- 优点: 专为超大规模图设计,原生分布式,存储计算分离(存更适合云原生环境)。国内大厂(腾讯、百度等)常用。
- 缺点: 运维复杂度高,生态工具略逊 Neo4j。
- 适用: 互联网大厂,节点数达到百亿级。
- TigerGraph (商业闭源,性能强劲):
- 优点: 强大的并行图计算能力(GSQL),适合做实时图算法分析。
专业建议: 对于大多数刚刚起步构建安全大脑的企业,Neo4j 是最佳的切入点。它的可视化工具(Neo4j Bloom)能让你直观地向老板展示"黑客的攻击路径",这对申请预算非常有帮助。
4.3 避坑指南:超级节点(Supernode)的诅咒
在实战中,你会遇到一种可怕的现象:稠密节点爆炸。 想象一下,如果把全公司的 DNS 日志导入图谱。
- 节点:8.8.8.8 (Google DNS)。
- 入边:公司里每一台电脑每天都会连接它几千次。
- 结果:8.8.8.8 这个节点上可能挂了几亿条边。
当你试图查询"谁连接了 8.8.8.8"或者让图算法(如 GNN)经过这个节点时,内存会瞬间溢出,系统崩溃。这就是图论中著名的"毛球(Hairball)"问题。
解决方案:
- 剪枝(Pruning): 在数据清洗(ETL)阶段,过滤掉白名单中的高频公共节点。
- 特殊处理: 在算法运行前,标记并跳过这些度数极高的节点(Hubs)。
第五章:可视化------看见看不见的战线
知识图谱不仅是给 AI 读的,也是给人看的。
在 SOC 的大屏上,知识图谱提供了上帝视角。
5.1 溯源分析(Provenance Analysis)
当我们在图上点选一个受感染的服务器节点,并展开它的"入边(Incoming Edges)",我们可以清晰地看到:
- 它被哪个 IP 访问过?
- 那个 IP 同时还访问了哪些其他设备?(横向移动检测)
- 那个 IP 的 WHOIS 信息关联到哪个注册邮箱?
- 那个邮箱在暗网数据泄露中是否出现过?
这种关联跳跃(Link Analysis),能让初级分析师拥有高级专家的直觉。
5.2 子图匹配(Subgraph Matching)
我们可以定义一种"攻击模式图"(Pattern Graph)。
例如,黄金票据(Golden Ticket)攻击的模式是:
- 攻击者获取 krbtgt 账号 hash。
- 攻击者生成伪造的 TGT。
- 攻击者在短时间内访问域控制器。
我们将这个小的"模式图"放到整个巨大的"全网流量图"里去匹配 。这就好比在巨大的拼图里找特定的一块。一旦匹配成功,不仅意味着发现了攻击,还意味着我们完整地捕获了攻击的全貌(Context)。
第六章:经典图算法------图谱上的战术地图
在深度学习介入之前,经典的数学图论算法已经是极其强大的武器。它们不需要训练庞大的模型,利用图的拓扑结构,就能发现隐藏在复杂连接中的战术意图。
6.1 路径分析(Pathfinding):攻击链路预测
在平面的网络拓扑图中,我们只知道 A 连着 B。但在知识图谱中,我们关心的是最短攻击路径(Shortest Attack Path)。
- 场景: 攻击者控制了外网的一台 Web 服务器(起点),他的目标是内网的核心数据库(终点)。
- 算法: Dijkstra 算法或 A* 算法。
- 计算逻辑:
图谱中不仅有物理连接,还有"权限连接"。
-
- Web Server --has_vuln--> RCE
- Web Server --can_access--> App Server
- App Server --stored_cred--> Admin Password
- Admin Password --can_login--> Core DB
- 实战价值:
AI 会自动计算出从"外网"到"皇冠资产"的所有可行路径。CISO 不需要修补所有漏洞,只需要切断那些**处于所有关键路径交汇点(Choke Point)**上的节点,就能以最小成本瘫痪攻击者的路线。
6.2 中心性算法(Centrality):寻找幕后黑手
不是所有节点都生而平等。谁是网络中的关键人物?
- PageRank 算法:
- 原理: 源于 Google 搜索。如果很多重要节点指向你,那你也重要。
- 安全应用(MalwareRank): 如果一个域名被多个已知的恶意 IP 访问,或者被多个恶意样本硬编码引用,那么这个域名的"恶意 PageRank"分数就会极高。这能帮我们在通过黑名单确认之前,就识别出潜在的 C2(命令控制)服务器。
- 介数中心性(Betweenness Centrality):
- 原理: 衡量一个节点在多少条"最短路径"上充当了桥梁。
- 安全应用: 用于发现跳板机(Pivot Point)。如果内网中某台打印机虽然不起眼,但它是连接"办公区"和"数据中心"的唯一桥梁,它的介数中心性会异常高。这台打印机就是必须重点监控的咽喉要地。
6.3 社区发现(Community Detection):团伙挖掘
黑客往往是团伙作案,僵尸网络(Botnet)也是集群行动。但在海量日志中,他们混杂在正常用户里。
- 算法: Louvain 算法或 Label Propagation(标签传播)。
- 原理: 寻找图中的"紧密子结构"。物以类聚,人以群分。
- 实战效果:
你可能会发现,有 5000 个看似无关的 IP,它们虽然访问的目标不同,但它们总是共享同一组 DNS 服务器,且总是在深夜同一时间段活跃。
Louvain 算法会将这 5000 个节点染成同一种颜色------这意味着你发现了一个隐蔽的 DGA 僵尸网络。你不需要逐个封禁,你可以直接封禁整个"社区"。
第七章:图嵌入(Graph Embedding)------从符号到向量的桥梁
经典算法很强,但它们处理的是"离散符号"。深度学习模型(如神经网络)只能吃"连续向量"。
我们需要一个翻译器,把图上的节点(Node)翻译成向量(Vector)。这就是图嵌入。
7.1 TransE:关系的算术题
这是知识图谱嵌入(KGE)的鼻祖。它的核心思想极其优美:
如果三元组 <头实体 h, 关系 r, 尾实体 t> 成立,那么在向量空间中,应该满足:
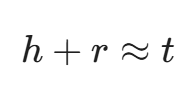
- 安全隐喻:
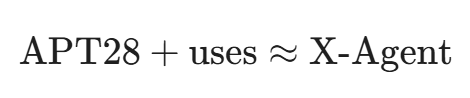
这意味着,如果我们训练好了这个向量空间,我们就可以做向量减法:
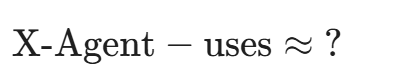
系统可能会输出距离这个结果最近的向量------APT28。
这不仅是识别,这是数学层面的归因(Attribution)。
7.2 Node2Vec:游走的智慧
这种方法让一个虚拟的"游走者"在图上随机乱逛(Random Walk),记录下他走过的路径序列。
然后,把这些路径序列当成"句子",扔进 Word2Vec 模型里训练。
- 结果: 结构相似的节点,会有相似的向量。
- 应用:
- IP A 和 IP B 可能完全没联系,甚至处于不同的子网。
- 但如果它们在图谱中的结构角色(Structural Role)相似(例如都只连接数据库端口,且都在凌晨活跃),它们的向量会靠得很近。
- 如果 IP A 被确认为攻击者,我们就可以根据向量距离,推断 IP B 也是攻击者。
第八章:图神经网络(GNN)------AI 的终极形态
这是目前 AI 安全领域的最前沿(State-of-the-art)。
GNN 结合了深度学习的感知能力 (处理节点本身的特征,如 Payload 文本)和图计算的逻辑能力(处理连接关系)。
8.1 消息传递机制(Message Passing)
GNN 的核心逻辑是:告诉我你的朋友是谁,我就知道你是谁。
在每一层神经网络运算中,每个节点都会聚合(Aggregate)它邻居的信息以及它自己的旧状态,来更新自己的状态。
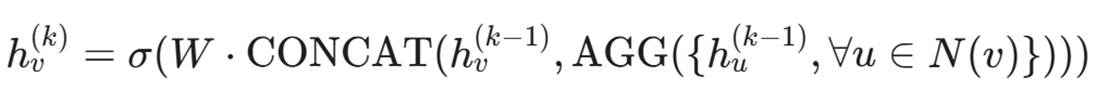
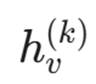 : 节点 v 在第 k 层的特征向量。
: 节点 v 在第 k 层的特征向量。- N(v): 节点 v 的邻居集合。
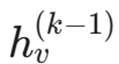 :节点 v 自身上一时刻的特征(不能忘本)。
:节点 v 自身上一时刻的特征(不能忘本)。- AGG :聚合邻居信息的函数(如求平均、最大值)。
- 解读: 一个 IP 节点的特征,不仅取决于它自己发了什么包,还取决于它连的域名是谁,它连的域名关联的注册人是谁。经过 2-3 层 GNN 聚合,这个 IP 节点就"吸取"了周围 3 跳以内的所有情报信息。
8.2 GraphSAGE 与 GAT
- GraphSAGE (Graph Sample and Aggregate):
- 解决了大图计算的性能问题。它不需要把全网图读入内存,而是对邻居进行采样。这使得它能在拥有十亿节点的企业内网中运行。
- GAT (Graph Attention Network):
- 引入了注意力机制(Attention)。
- 逻辑: 并不是所有邻居都重要。对于一个文件节点来说,它的"签名者"邻居比它的"创建时间"邻居更重要。GAT 能自动学习这种权重,聚焦于最关键的线索。
8.3 案例:横向移动(Lateral Movement)检测
这是 GNN 的杀手级应用。
- 传统方法: 很难判断一次 RDP(远程桌面)连接是否恶意,因为管理员也会用 RDP。
- GNN 方法:
- 构建一张由 账号、设备、进程 构成的动态图。
- 正常管理员的行为模式在图上是一棵相对固定的树(从管理机辐射)。
- 攻击者的横向移动在图上是一条单向的、不断探索的链条。
- GNN 能敏锐地识别出这种拓扑结构的异常,即使攻击者使用了合法的账号密码。
第九章:神经符号 AI(Neuro-symbolic AI)------推理的未来
我们在第一章到第六章建立了概率(AI),在第七章建立了逻辑(KG)。
未来的方向是将二者融合。
9.1 链接预测(Link Prediction):预判未来
知识图谱不仅能描述现状,还能预测未来。
- 任务: 给定当前的图谱,预测哪两个节点之间即将产生连接。
- 场景: 漏洞预警。
- 已知:黑客组织 A 偏好 WebLogic 组件。
- 已知:我司系统 B 刚刚上线了 WebLogic 组件。
- 推理: 虽然 黑客组织 A 还没攻击 我司系统 B,但图谱预测它们之间产生 Attack 边的概率高达 85%。
- 行动: 在攻击发生前,提前进行虚拟补丁加固。
9.2 可解释性(Explainability)的回归
还记得引言中那个无法解释原因的 AI 吗?
有了知识图谱,GNN 模型的输出可以携带推理子图(Reasoning Subgraph)。
新一代 AI 系统: "警报!IP 192.168.1.105 可疑。"
解释路径:
- 该 IP 访问了域名 x.com。
- 域名 x.com 解析到了 IP 1.1.1.1。
- IP 1.1.1.1 在威胁情报中被标记为 APT-29 的基础设施。
- 推论: 内网主机可能已被 APT-29 控制。
这不再是黑盒,这是白盒化的智能。安全分析师可以根据这个路径图,迅速验证真伪。
结语:水晶球与达摩克利斯之剑
至此,我们完成了《硅基之盾》这个专栏目前为止最艰难、也最辉煌的一块拼图。
如果说深度学习赋予了安全大脑"直觉",那么知识图谱则赋予了它"理性"。我们不再是在黑暗中依靠听觉辨位的盲剑客,而是拥有了一张实时更新、洞察秋毫的全景作战地图。在这个由节点和边构成的数字宇宙里,攻击者的每一步伪装,在逻辑的聚光灯下都无所遁形。
我们正在从感知智能(Perceptual Intelligence)迈向认知智能(Cognitive Intelligence)。
但是,当你凝视着屏幕上那张错综复杂、近乎全知的图谱时,你是否感到了一丝寒意?
这个系统知道一切。 它知道哪个员工在深夜违规访问了敏感数据; 它知道哪台服务器是整个网络的阿喀琉斯之踵; 它甚至能在攻击发生之前,就预判出谁是潜在的受害者。
我们赋予了机器像福尔摩斯一样的推理能力,但我们是否赋予了它像法官一样的判决权?当 AI 能够精准地通过图谱推导出"因为 A,所以 B"时,它下一步的动作是什么?是切断连接?是反制攻击?还是仅仅发出警告?
一旦这个推理过程出现极其微小的逻辑偏差(Bias),或者被恶意的"毒化数据"误导,它所造成的后果将不再是一次误报,而可能是一场自动化的灾难。我们制造了一个接近全知全能的"神",但我们还没教会它什么是"善"。
技术本身没有道德,但使用技术的结果充满代价。
下一章,我们将离开冰冷的机房和代码,走进充满灰度的现实世界。当 AI 手握生杀大权,当黑客也开始利用 AI 生成完美的谎言,我们该如何界定责任?我们该如何守住最后的底线?
请做好准备,第八篇------《伦理与法律:当 AI 成为黑客工具,我们如何界定责任?》,即将开庭。
附录:给技术人员的 Python 实战胶囊 (NetworkX + PyTorch Geometric)
为了让知识图谱不再抽象,这里提供一个极简的 GNN 节点分类 Demo(伪代码逻辑):
python
import torch
from torch_geometric.nn import GCNConv
from torch_geometric.data import Data
# 1. 定义图结构 (Edge Index)
# 假设 0号节点连接1号,1号连接2号... (源节点, 目标节点)
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
# 形状为 [2, num_edges],定义了边的流向。
# 2. 定义节点特征 (Node Features)
# 假设每个节点有 3 个特征:[流量大小, 端口数, 失败率]
x = torch.tensor([[-1, 0, 1], [2, 5, 0], [10, 2, 5]], dtype=torch.float)
# 3. 定义标签 (Labels)
# 0: 正常, 1: 恶意
y = torch.tensor([0, 0, 1], dtype=torch.long)
# 构建图数据对象
data = Data(x=x, edge_index=edge_index, y=y)
# 4. 定义一个简单的图卷积神经网络 (GCN)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
# 第一层卷积:输入3维特征 -> 输出16维隐藏特征
self.conv1 = GCNConv(3, 16)
# 第二层卷积:输入16维 -> 输出2类 (正常/恶意)
self.conv2 = GCNConv(16, 2)
# 输出逻辑:[是正常概率, 是恶意概率]
def forward(self, data):
x, edge_index = data.x, data.edge_index
# 消息传递与聚合
x = self.conv1(x, edge_index)
x = torch.relu(x)
# 第二次聚合 (这就捕获了 2-hop 的邻居信息)
x = self.conv2(x, edge_index)
return torch.log_softmax(x, dim=1)
# 初始化模型与推理
model = Net()
print("Model created. Ready to reason over the graph.")
# out = model(data)陈涉川
2026年01月23日