一、冯诺依曼体系结构
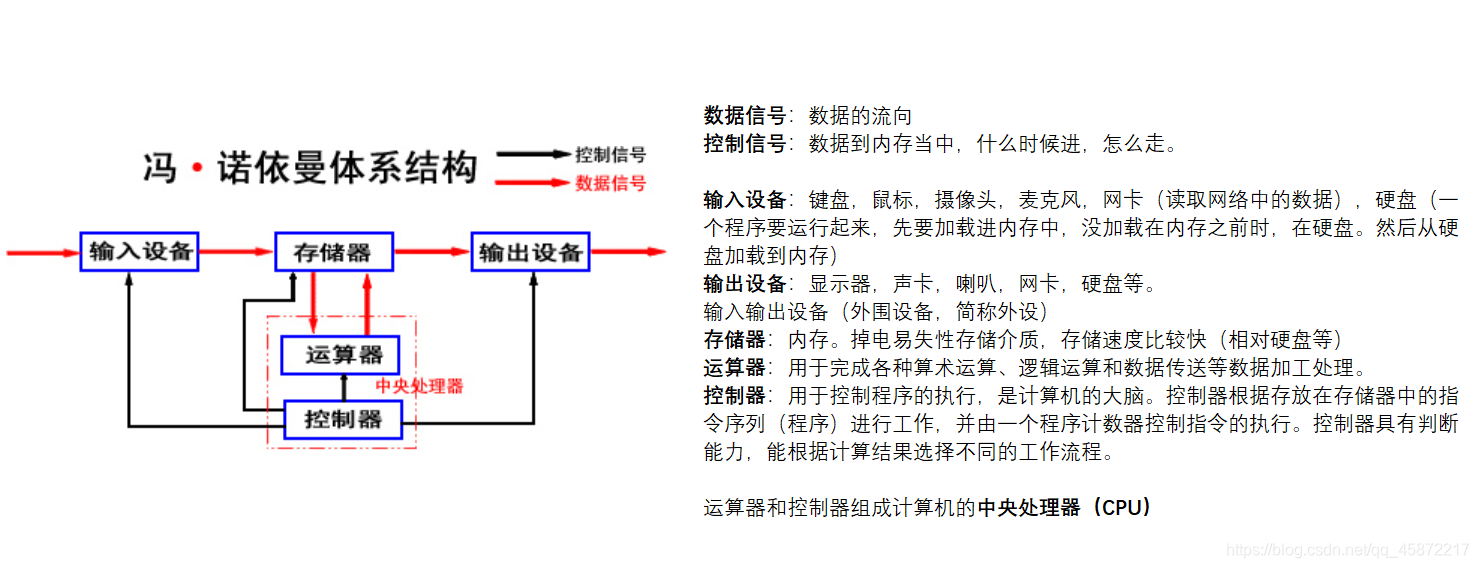
讲进程,就必须从冯诺依曼体系结构开始。
冯诺依曼体系结构实际上非常简单,涉及到输入设备、储存器、输出设备、运算器和控制器,其中所谓CPU正指的是运算器和控制器。
数据从硬盘(容量大、速度慢)运送到容量小速度快的CPU进行运算,并在运算完输送回硬盘。
二、OS(操作系统)
任何计算机系统都包含⼀个基本的程序集合,称为操作系统(OS)。笼统的理解,操作系统包括:
- 内核(进程管理,内存管理,文件管理,驱动管理)
- 其他程序(例如函数库,shell程序等等)
为什么要有操作系统?操作系统是软件,可以对所有软硬件资源进行管理,也可以为用户提供一个良好的执行环境。
"先描述,再组织"正是OS的管理方式。
试想:如果你是老板,你手底下有1000多名员工,就算你可以设置多级管理来辅助组织进行控制,你不能掌控这些人的信息,你就无法给出准确的方针。
而如果有excel等软件统计出来的信息,你是不是就能便于管理?比如员工的id、薪资、工作岗位、负责范围等等,这样你只需要实时更新他们的信息,就能做出更好的决策。
这就是"先描述,后组织"
操作系统也是这么做的,他描述了各种文件、软硬件的信息(可以直接打开某一文件的属性查看,实际情况利用结构体struct来管理),然后再利用数据结构(如链表)来组织、控制这些东西。
三、进程
进程是怎么被描述的呢?
在Linux里,进程被task_struct(process control block,即PCB的一种)描述,内容包括:
- 标示符: 描述本进程的唯⼀标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器: 程序中即将被执行的下⼀条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下文数据: 进程执行时处理器的寄存器中的数据。
- I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
- 其他信息
进程=PCB+自己程序代码与数据
链接方式
多个进程之间,我们正是使用链表来链接的,但和我们常说的,保存下一个表头的那种双向链表不一样,进程之间使用的链表单独维护了next和prev。
cpp
//原先
struct old{
//...
struct old* next;
struct old* prev;
//...
};
//现在
struct list_head{
struct list_head* next,prev;
}
struct new{
//...
struct list_head tasks;
//...
}全新的设计有什么好处?
原先的设计中已经被彻底写死了,任务1后必须是任务2,然后是3、4、5。
而全新的设计里,任务1后可以是任务2,也可以通过多次塞入next与prev,使得可以通过链表访问6、7、8。
那这样的设计如何拿到struct的地址呢?
我们可以利用地址的相对性来获取。
假设这个list_head是PCB的第一个成员,那么list_head保存的数据就是进程的地址。
假设前面有多个成员,那么这些成员所占用的内存相同的情况下,我们可以利用地址偏移得到进程地址。
父子进程
我们可以利用fork函数来在一个进程中创建子进程,父子进程代码共享,数据各自开辟空间,私有一份**(采用写时拷贝)**
cpp
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
int ret = fork();
if(ret < 0){
perror("fork");
return 1;
}
else if(ret == 0){ //child
printf("I am child : %d!, ret: %d\n", getpid(), ret);
}
else{ //father
printf("I am father : %d!, ret: %d\n", getpid(), ret);
}
sleep(1);
return 0;
}fork函数在实际使用时会返回两个返回值,当返回的是0时,说明该进程为子进程,返回的大于0时,说明该进程为父进程,并且返回值为子进程的pid的值,当返回的小于0时,此时子进程未成功创建。
为什么fork会有两个返回值?
fork采用写时拷贝,此时父进程和子进程将会共用一段代码,只有出现不同时才会将不同的地方分别存储,那么这个时候fork的返回值就会由父进程和子进程分别返回一个,这样共有两个。
为什么父进程要返回子进程的pid,而子进程只需要返回0
因为父进程需要拿到子进程的pid,一个父进程可以有多个子进程,并需要依靠不同的pid来分辨。而子进程不需要返回其他值,只有子进程又开辟了子进程才会返回它的子进程的pid。
进程可以有哪些状态
进程也有自己的分类,linux里的分类是这样的:
bash
static const char *const task_state_array[] = {
"R (running)",
"S (sleeping)",
"D (disk sleep)",
"T (stopped)",
"t (tracing stop)",
"X (dead)",
"Z (zombie)",
};R对应运行状态
S对应睡眠状态(可中断休眠状态)
D对应磁盘睡眠状态(不可中断休眠状态)
T对应停止状态
X对应死亡状态,一般很难利用ps命令看到
Z对应僵尸状态,即某一进程已结束但未回收(可能的情况是子进程已结束,但父进程陷入死循环未结束,导致未回收子进程)