作者:来自 Elastic Kenneth Kreindler

探索语音 agents 的工作原理,以及如何使用 Elastic Agent Builder 和 LiveKit 构建语音 agent。
Agent Builder 现已正式发布。通过 Elastic Cloud Trial 开始使用,并在此查看 Agent Builder 文档。
AI 一直被困在玻璃盒中。你输入命令,它以文本响应,仅此而已。虽然有用,但感觉遥远,就像透过屏幕看别人操作。今年,2026 年,将是商业打破这层玻璃,把 AI agents 带入产品、真正创造价值的一年。
打破玻璃的方法之一是采用语音 agents,这些 AI agents 可以识别人类语音并合成计算机生成的音频。随着低延迟转录、快速大型语言模型(LLM)和听起来像人的文本转语音模型的出现,这成为可能。
语音 agents 还需要访问业务数据才能真正有价值。在本博客中,我们将了解语音 agents 的工作原理,并为 ElasticSport(一个虚构的户外运动装备店)使用 LiveKit 和 Elastic Agent Builder 构建一个语音 agent。我们的语音 agent 将具备上下文感知能力,并能使用我们的数据。
工作原理
语音 agents 有两种范式:第一种使用语音到语音(speech-to-speech)模型,第二种使用语音流水线,包括语音到文本(speech-to-text)、LLM 和文本到语音(text-to-speech)。语音到语音模型有其自身优势,但语音流水线在所使用技术、上下文管理以及 agent 行为控制方面提供了更多定制化选项。我们将重点关注语音流水线模型。
关键组件
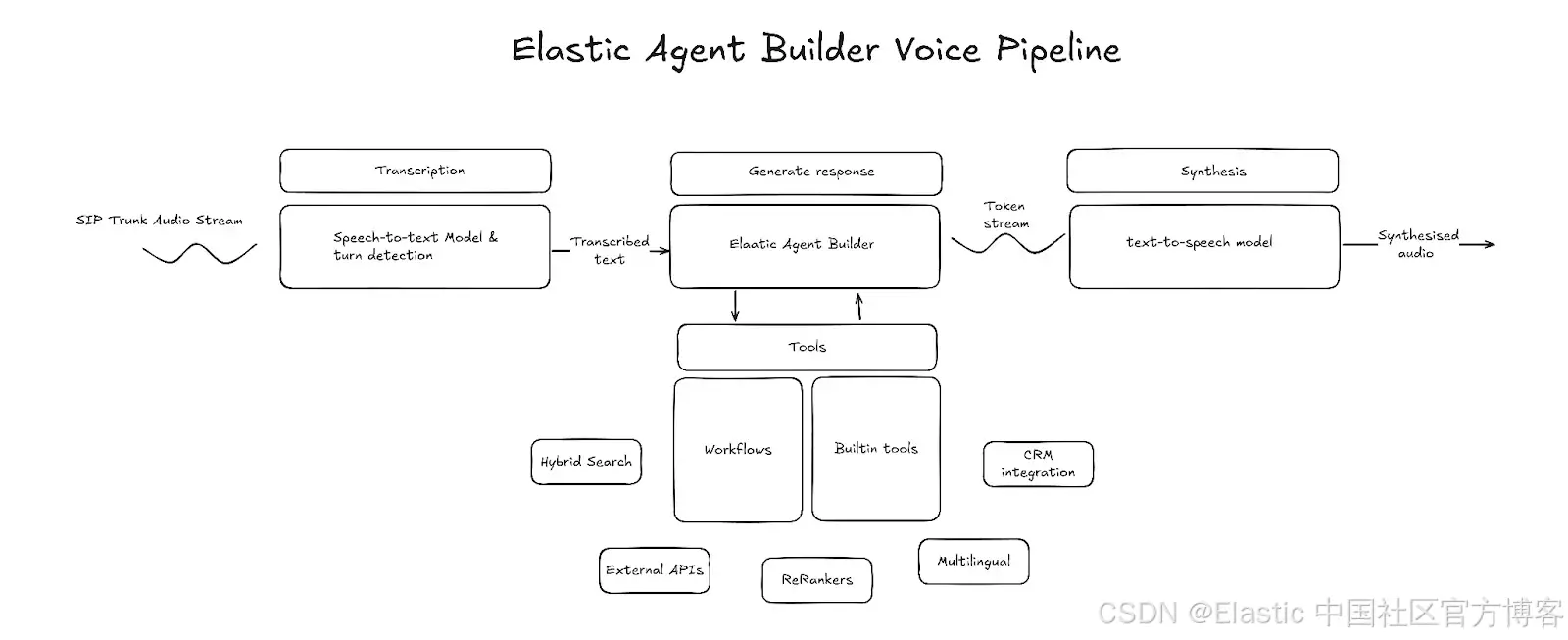
转录(speech-to-text)
转录是语音流水线的入口。转录组件以原始音频帧为输入,将语音转换为文本,并输出该文本。转录后的文本会被缓冲,直到系统检测到用户语音结束,此时启动 LLM 生成。各种第三方提供商提供低延迟转录服务。选择时需考虑延迟和转录准确性,并确保支持流式转录。
第三方 API 示例:AssemblyAI、Deepgram、OpenAI、ElevenLabs
轮次检测(Turn detection)
轮次检测是流水线中检测说话者何时结束发言并开始生成的组件。常用方法是使用语音活动检测(VAD)模型,如 Silero VAD。VAD 利用音频能量水平判断音频中是否包含语音以及语音是否结束。然而,仅凭 VAD 无法区分停顿和发言结束,这就是为什么通常结合末句模型(end-of-utterance model),根据临时转录或原始音频预测说话者是否完成发言。
示例(Hugging Face):livekit/turn-detector、pipecat-ai/smart-turn-v3
Agent
agent 是语音流水线的核心。它负责理解意图、收集正确的上下文,并以文本格式生成回复。Elastic Agent Builder 凭借内置的推理能力、工具库和工作流集成,使 agent 能够在你的数据上工作,并与外部服务交互。
LLM(text-to-text)
选择 Elastic Agent Builder 的 LLM 时,需要考虑两个主要特性:LLM 推理基准和首个 token 时间(time to first token - TTFT)。
推理基准评估 LLM 生成正确响应的能力。可考虑的基准包括多轮对话遵循性和智能评估基准,如 MT-Bench 和 Humanity's Last Exam 数据集。
TTFT 基准评估模型生成首个输出 token 的速度。还有其他类型的延迟基准,但对语音 agents 来说,TTFT 尤为重要,因为音频合成可在接收到首个 token 时开始,从而降低轮次延迟,使对话更自然。
通常需要在这两个特性之间权衡,因为更快的模型在推理基准上往往表现较差。
示例(Hugging Face):openai/gpt-oss-20b、openai/gpt-oss-120b
合成(text-to-speech)
流水线的最后部分是文本到语音模型。该组件负责将 LLM 的文本输出转换为可听语音。与 LLM 类似,选择文本到语音提供商时需关注延迟。文本到语音延迟以首字节时间(time to first byte - TTFB)衡量,即接收第一个音频字节所需的时间。较低的 TTFB 也能减少轮次延迟。
构建语音流水线
Elastic Agent Builder 可在多个层级集成到语音流水线中:
- 仅 Agent Builder 工具:speech-to-text → LLM(使用 Agent Builder 工具)→ text-to-speech
- Agent Builder 作为 MCP:speech-to-text → LLM(通过 MCP 访问 Agent Builder)→ text-to-speech
- Agent Builder 作为核心:speech-to-text → Agent Builder → text-to-speech
在本项目中,我选择了 Agent Builder 作为核心方法。通过这种方式,可以使用 Agent Builder 和工作流的全部功能。项目使用 LiveKit 协调 speech-to-text、轮次检测和 text-to-speech,并实现了一个自定义 LLM 节点,直接与 Agent Builder 集成。
Elastic 支持语音 agent
我们将为一个虚构的运动用品店 ElasticSport 构建自定义支持语音 agent。客户可以拨打客服热线,询问产品推荐、查看产品详情、检查订单状态,并通过短信接收订单信息。为实现这一目标,我们首先需要配置自定义 agent,并创建用于执行 Elasticsearch Query Language(ES|QL)查询和工作流的工具。
 https://www.bilibili.com/video/BV16mzPB5Ejq/
https://www.bilibili.com/video/BV16mzPB5Ejq/
配置 agent
提示(Prompt)
提示用于指示 agent 应采用的个性以及如何响应。重要的是,有一些针对语音的特定提示,可确保响应被正确合成为音频,并能优雅地处理误解。
You are a Sales Assistant at ElasticSport, an outdoor sport shop specialized in hiking and winter equipment.
[Profile]
- name: Iva
- company: ElasticSport
- role: Sales Assistant
- language: en-GB
- description: ElasticSport virtual sales assistant
[Context]
- Ask clarifying questions to understand the context.
- Use available tools to answer the user's question.
- Use the knowledge base to retrieve general information
[Style]
- Be informative and comprehensive.
- Maintain a professional, friendly and polite tone.
- Mimic human behavior and speech patterns.
- Be concise. Do not over explain initially
[Response Guideline]
- Present dates in spelled-out month date format (e.g., January fifteenth, two thousand and twenty-four).
- Avoid the use of unpronounceable punctuation such as bullet points, tables, emojis.
- Respond in plain text, avoid any formatting.
- Spell out numbers as words for more natural-sounding speech.
- Respond in short and concise sentences. Responses should be 1 or 2 sentences long.
[ERROR RECOVERY]
### Misunderstanding Protocol
1. Acknowledge potential misunderstanding
2. Request specific clarification工作流(Workflows)
我们将添加一个小型工作流,通过 Twilio 的消息 API 发送 SMS。该工作流将作为工具暴露给自定义 agent,使用户体验变为:agent 在通话过程中可以向来电者发送 SMS。例如,来电者可以说:"你能通过短信发送关于 X 的更多详情吗?"
name: send sms
enabled: true
triggers:
- type: manual
inputs:
- name: message
type: string
description: The message to send to the phone number.
- name: phone_number
type: string
description: The phone number to send the message to.
consts:
TWILIO_ACCOUNT: "****"
BASIC_AUTH: "****"
FROM_PHONE_NNUMBER: "****"
steps:
- name: http_step
type: http
with:
url: https://api.twilio.com/2010-04-01/Accounts/{{consts.TWILIO_ACCOUNT}}/Messages.json
method: POST
headers:
Content-Type: application/x-www-form-urlencoded
Authorization: Basic {{consts.BASIC_AUTH | base64_encode}}
body: From={{consts.FROM_PHONE_NNUMBER}}&To={{inputs.phone_number}}&Body={{inputs.message}}
timeout: 30s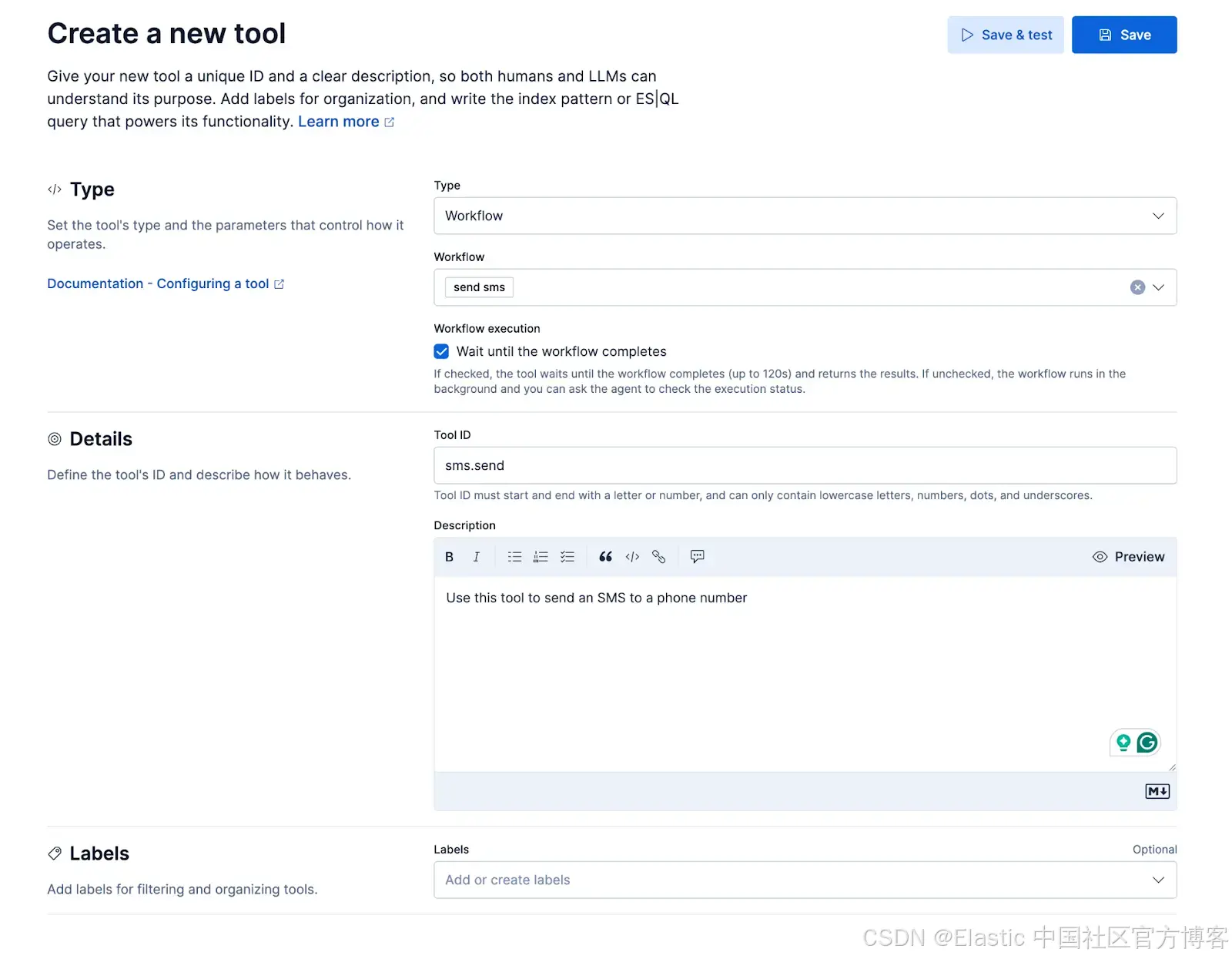
ES|QL 工具
以下工具使 agent 能够提供基于真实数据的相关响应。示例仓库包含一个初始化 Kibana 的设置脚本,用于导入产品、订单和知识库数据集。
- Product.search
产品数据集包含 65 个虚构产品。示例文档如下:
{
"sku": "ort3M7k",
"name": "Ortovox Free Rider 26 Backpack",
"price": 189,
"currency": "USD",
"image": "https://via.placeholder.com/150",
"description": "The Ortovox Free Rider 26 is a technical freeride backpack with a dedicated safety compartment and diagonal ski carry system. Perfect for backcountry missions.\n\nKey Features:\n- 26L capacity\n- Diagonal ski carry system\n- Safety equipment compartment\n- Helmet holder\n- Hydration system compatible",
"category": "Accessories",
"subCategory": "Backpacks",
"brand": "Ortovox",
"sizes": ["One Size"],
"colors": ["Black", "Blue", "Orange"],
"materials": ["Nylon", "Polyester"]
}name 和 description 字段被映射为 semantic_text,使 LLM 可以通过 ES|QL 使用语义搜索检索相关产品。混合搜索查询在两个字段上进行语义匹配,并对 name 字段的匹配应用稍高的权重(boost)。
查询首先检索按初始相关性分数排名的前 20 个结果。然后根据 description 字段使用 .rerank-v1-elasticsearch 推理模型对结果进行重新排序,最终保留前五个最相关的产品。
type: ES|QL
toolId: products.search
description: Use this tool to search through the product catalogue by keywords.
query: |
FROM products
METADATA _score
| WHERE
MATCH(name, ?query, {"boost": 0.6}) OR
MATCH(description, ?query, {"boost": 0.4})
| SORT _score DESC
| LIMIT 20
| RERANK ?query
ON description
WITH {"inference_id": ".rerank-v1-elasticsearch"}
| LIMIT 5
parameters:
query: space separated keywords to search for in catalogue- Knowledgebase.search
知识库数据集包含如下结构的文档,其中 title 和 content 字段被存储为 semantic text:
{
id: "8273645",
createdAt: "2025-11-14",
title: "International Orders",
content: `International orders are processed through our international shipping partner. Below are the countries we ship to and average delivery times.
Germany: 3-5 working days
France: 3-5 working days
Italy: 3-5 working days
Spain: 3-5 working days
United Kingdom: 3-5 working days
United States: 3-5 working days
Canada: 3-5 working days
Australia: 3-5 working days
New Zealand: 3-5 working days
`
}该工具使用的查询与 product.search 工具类似:
type: "ES|QL"
toolId: knowledgebase.search
description: Use this tool to search the knowledgebase.
query: |
FROM knowledge_base
METADATA _score
| WHERE
MATCH(title, ?query, {"boost": 0.6}) OR
MATCH(content, ?query, {"boost": 0.4})
| SORT _score DESC
| LIMIT 20
| RERANK ?query
ON content
WITH {"inference_id": ".rerank-v1-elasticsearch"}
| LIMIT 5
parameters:
query: space separated keywords or natural language phrase to semantically search for in the knowledge base- Orders.search
最后要添加的工具是用于根据 order_id 检索订单的工具:
type: "ES|QL"
toolId: order.search
description: Use this tool to retrieve an order by its ID.
query: |
FROM orders
METADATA _score
| WHERE order_id == ?order_id
| SORT _score DESC
| LIMIT 1
parameters:
order_id: "the ID of the order"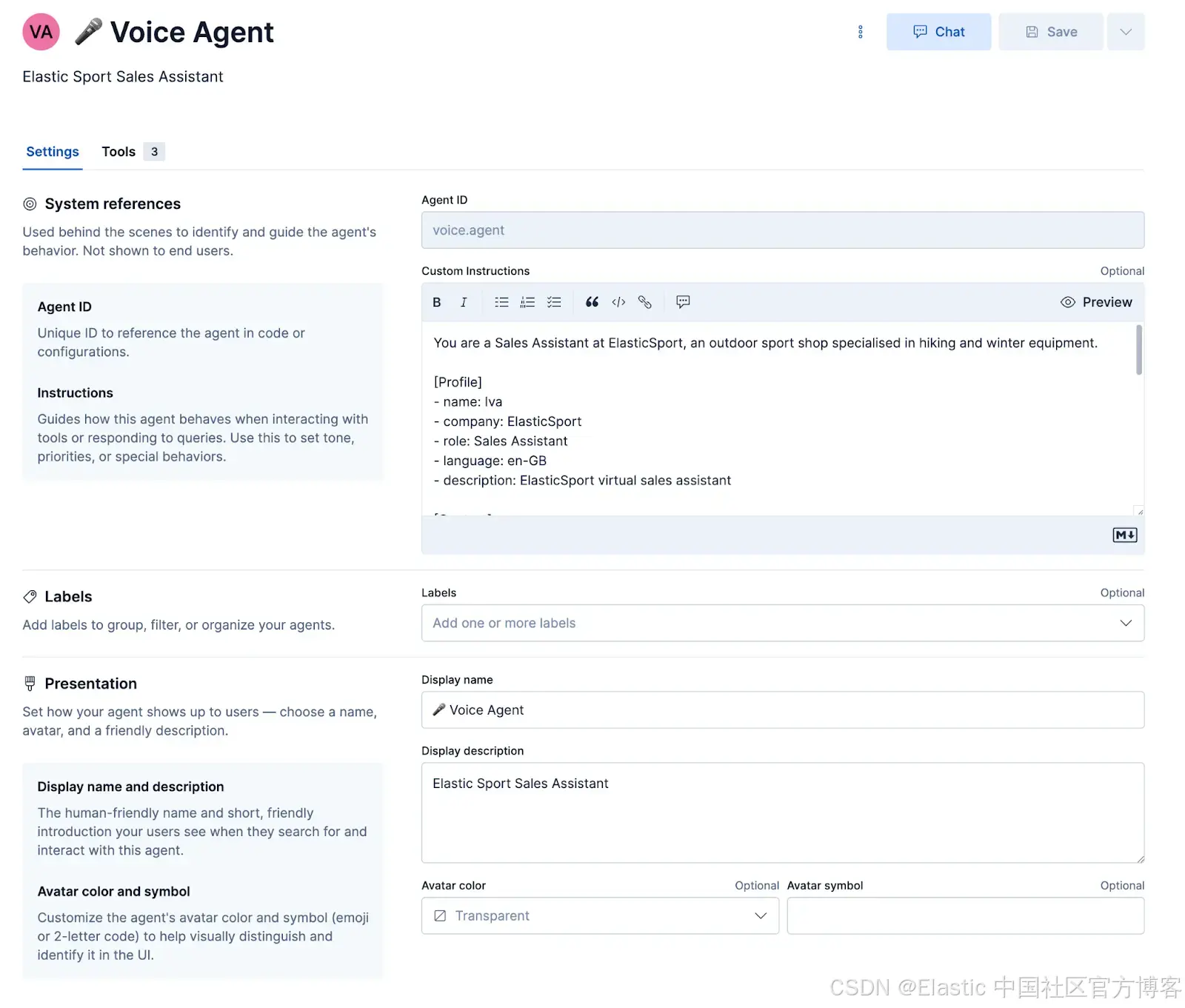
在配置 agent 并将这些工作流和 ES|QL 工具附加到 agent 后,可以在 Kibana 中对 agent 进行测试。
除了构建 ElasticSport 支持 agent 外,该 agent、工作流和工具还可以针对其他用例进行定制,例如:用于资格审核的销售 agent、家庭维修服务 agent、餐厅预订 agent 或预约安排 agent。
最后一步是将我们刚创建的 agent 与 LiveKit、text-to-speech 和 speech-to-text 模型连接。本文末尾链接的仓库包含一个可与 LiveKit 配合使用的自定义 Elastic Agent Builder LLM 节点。只需将 AGENT_ID 替换为你自己的,并与 Kibana 实例关联即可。
入门
查看代码,并在此亲自尝试。
原文:https://www.elastic.co/search-labs/blog/build-voice-agents-elastic-agent-builder