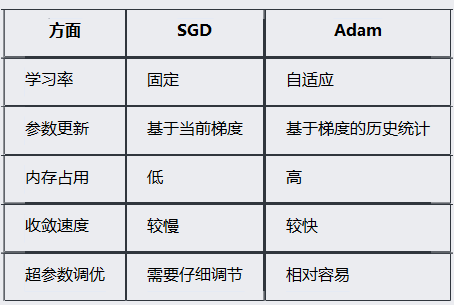
一、SGD和Adam的区别
SGD是随机梯度下降
比较简单,有固定的学习率。对应的公式为:param = param - lr * gradient
需要手动调整lr,收敛速度慢
Adam(adaptive Moment Estimation)自适应矩估计
每个参数有各自的学习率,收敛速度快,内存需求高,参数调优更容易
区别表:
使用于不同的优化器
python
optimizer = optim.SGD(model.parameters(), lr=0.03,momentum=0.9)
optimizer = torch.optim.Adam(model.parameters(),
lr=0.03,
weight_decay=0.001) #换一个优化器二、Dataset
数据准备
1、 数据分类
训练集 train / val / test Data
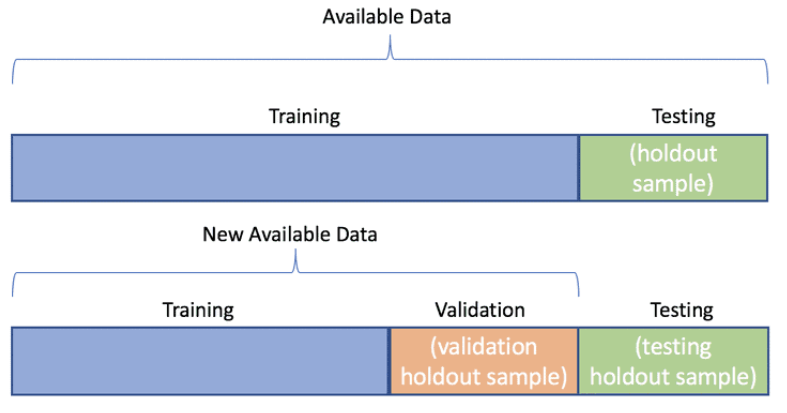
train data : 用于训练模型,调整参数
val data : 验证模型,评估模型在未见过数据上的表现,防止过拟合
test data : 用模型预测
2、继承Dataset
处理的数据均需要继承Dataset
并且重新定义 init 、getitem、len
从csv中读入数据,并且对数据进行处理
比如:去除首行/列,年份、价格(大数)、标准化、字符串转化浮点数
准备训练数据、验证数据、预测数据
trainset = covidDataset(train_path,'train',feature_dim=feature_dim, all_feature=all_col)
valset = covidDataset(train_path,'val',feature_dim=feature_dim, all_feature=all_col)
testset = covidDataset(test_path,'test',feature_dim=feature_dim, all_feature=all_col)
下面是房价预测和新冠人数预测数据读入处理
python
class houseDataset(Dataset):#数据集处理接口
def __init__(self, path, mode="train", feature_dim=5):
with open(path,'r') as f:
csv_data = list(csv.reader(f))
for index in range(1, len(csv_data)):
csv_data[index][1] = processdate(csv_data[index][1])
csv_data[index][2] = str(eval(csv_data[index][2]))
x = np.delete(np.array(csv_data)[1:].astype(float), [0, 2, 16], axis=1)
y = np.array(csv_data)[1:, 2].astype(float)/10**6# 除以百万进行缩放
self.x = torch.tensor(x)
self.y = torch.tensor(y)
self.x = (self.x - self.x.mean(dim=0,keepdim=True)) / self.x.std(dim=0,keepdim=True) # 标准化
print('Finished reading the {} set of house Dataset ({} samples found)'
.format(mode, len(self.x)))
def __getitem__(self, item):
return self.x[item].float(), self.y[item]
def __len__(self):
return len(self.x)
# 年份处理
def processdate(date):
date_num = (int(date[:4]) - 2014)*12 + (int(date[4:6])-5)# 计算到2014.5的总月份
return date_num
python
class covidDataset(Dataset):
def __init__(self, path, mode="train", feature_dim=5, all_feature=False):
with open(path,'r') as f:
csv_data = list(csv.reader(f))
column = csv_data[0]
x = np.array(csv_data)[1:,1:-1]
y = np.array(csv_data)[1:,-1]
if all_feature:
col_indices = np.array([i for i in range(0,93)]) # 若全选,则选中所有列。
else:
_, col_indices = get_feature_importance(x, y, feature_dim, column) # 选重要的dim列。
# X_new = get_feature_importance_with_pca(x, feature_dim, column) # 选重要的特征
col_indices = col_indices.tolist() # col_indices 从array 转为列表。
csv_data = np.array(csv_data[1:])[:,1:].astype(float) #取csvdata从第二行开始, 第二列开始的数据,并转为float
if mode == 'train': # 训练数据逢5选4, 记录他们的所在行
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
self.y = torch.tensor(csv_data[indices,-1]) # 训练标签是csvdata的最后一列。 要转化为tensor型
elif mode == 'val': # 验证数据逢5选1, 记录他们的所在列
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
# data = torch.tensor(csv_data[indices,col_indices])
self.y = torch.tensor(csv_data[indices,-1]) # 验证标签是csvdata的最后一列。 要转化为tensor型
else:
indices = [i for i in range(len(csv_data))] # 测试机只有数据
# data = torch.tensor(csv_data[indices,col_indices])
data = torch.tensor(csv_data[indices, :]) # 根据选中行取 X , 即模型的输入特征
self.data = data[:, col_indices] # col_indices 表示了重要的K列, 根据重要性, 选中k列。
self.mode = mode # 表示当前数据集的模式
self.data = (self.data - self.data.mean(dim=0,keepdim=True)) / self.data.std(dim=0,keepdim=True) # 对数据进行列归一化
assert feature_dim == self.data.shape[1] # 判断数据的列数是否为规定的dim列, 要不然就报错。
print('Finished reading the {} set of COVID19 Dataset ({} samples found, each dim = {})'
.format(mode, len(self.data), feature_dim)) # 打印读了多少数据
def __getitem__(self, item): # getitem 需要完成读下标为item的数据
if self.mode == 'test': # 测试集没标签。 注意data要转为模型需要的float32型
return self.data[item].float()
else : # 否则要返回带标签数据
return self.data[item].float(), self.y[item].float()
def __len__(self):
return len(self.data) # 返回数据长度。三、DataLoader
训练模型时,加载数据
trainloader = DataLoader(trainset, batch_size=config'batch_size',shuffle=True)
valloader = DataLoader(valset, batch_size=config'batch_size',shuffle=True) # 将数据装入loader 方便取一个batch的数据
train_val(model, trainloader,valloader,optimizer, loss, config'n_epochs', device,save_=config'save_path') # 开始训练
开始训练
python
def train_val(model, trainloader, valloader,optimizer, loss, epoch, device, save_):
# trainloader = DataLoader(trainset,batch_size=batch,shuffle=True)
# valloader = DataLoader(valset,batch_size=batch,shuffle=True)
model = model.to(device) # 模型和数据 ,要在一个设备上。
plt_train_loss = []
plt_val_loss = []
val_rel = []
min_val_loss = 100000 # 记录训练验证loss 以及验证loss和结果
for i in range(epoch): # 训练epoch 轮
start_time = time.time() # 记录开始时间
model.train() # 模型设置为训练状态
train_loss = 0.0
val_loss = 0.0
for data in trainloader: # 从训练集取一个batch的数据
optimizer.zero_grad() # 梯度清0
x , target = data[0].to(device), data[1].to(device) # 将数据放到设备上
pred = model(x) # 用模型预测数据
bat_loss = loss(pred, target, model) # 计算loss
bat_loss.backward() # 梯度回传, 反向传播。
optimizer.step() #用优化器更新模型。
train_loss += bat_loss.detach().cpu().item() #记录loss和
plt_train_loss. append(train_loss/trainloader.dataset.__len__())
#记录loss到列表。注意是平均的loss ,因此要除以数据集长度。
model.eval() # 模型设置为验证状态
with torch.no_grad(): # 模型不再计算梯度
for data in valloader: # 从验证集取一个batch的数据
val_x , val_target = data[0].to(device), data[1].to(device) # 将数据放到设备上
val_pred = model(val_x) # 用模型预测数据
val_bat_loss = loss(val_pred, val_target, model) # 计算loss
val_loss += val_bat_loss.detach().cpu().item() # 计算loss
val_rel.append(val_pred) #记录预测结果
if val_loss < min_val_loss:
torch.save(model, save_) #如果loss比之前的最小值小, 说明模型更优, 保存这个模型
plt_val_loss.append(val_loss/valloader.dataset.__len__()) #记录loss到列表。注意是平均的loss ,因此要除以数据集长度。
#
print('[%03d/%03d] %2.2f sec(s) TrainLoss : %.6f | valLoss: %.6f' % \
(i, epoch, time.time()-start_time, plt_train_loss[-1], plt_val_loss[-1])
) #打印训练结果。 注意python语法, %2.2f 表示小数位为2的浮点数, 后面可以对应。
# print('[%03d/%03d] %2.2f sec(s) TrainLoss : %3.6f | valLoss: %.6f' % \
# (i, epoch, time.time()-start_time, 2210.2255411, plt_val_loss[-1])
# ) #打印训练结果。 注意python语法, %2.2f 表示小数位为2的浮点数, 后面可以对应。
plt.plot(plt_train_loss) # 画图, 向图中放入训练loss数据
plt.plot(plt_val_loss) # 画图, 向图中放入训练loss数据
plt.title('loss') # 画图, 标题
plt.legend(['train', 'val']) # 画图, 图例
plt.show() # 画图, 展示四、Module
模型准备
1、训练阶段:
使用model.train()确保模型处于训练状态
特点:
启用Dropout层的随机丢弃功能
BatchNorm层使用当前批次的统计信息
允许参数更新和梯度计算
2、验证阶段:
使用model.eval()确保模型处于评估状态
通常配合torch.no_grad()使用
特点:
禁用Dropout层(不进行随机丢弃)
BatchNorm层使用训练期间学到的统计信息
不进行参数更新
3、自定义模型
继承Module
必须重写 init forward
init 初始化参数
forward:定义数据流动过程
python
class myNet(nn.Module):
def __init__(self,inDim):
super(myNet,self).__init__()
self.fc1 = nn.Linear(inDim, 64) # 全连接
self.relu = nn.ReLU() # 激活函数
self.fc2 = nn.Linear(64,1) # 全连接
def forward(self, x): #forward, 即模型前向过程
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
if len(x.size()) > 1:
return x.squeeze(1)
else:
return x五、损失函数自定义
正则化 : 自定义损失函数,确保模型的loss比较不会过拟合
loss=loss+常数∗θ2 loss = loss + 常数 * θ^2loss=loss+常数∗θ2
这里常数设置为0.00075
python
def mseLoss(pred, target, model):
loss = nn.MSELoss(reduction='mean')
''' Calculate loss '''
regularization_loss = 0
for param in model.parameters():
# TODO: you may implement L1/L2 regularization here
# 使用L2正则项
# regularization_loss += torch.sum(abs(param))
regularization_loss += torch.sum(param ** 2) # 正则化减少误差,防止过拟合
return loss(pred, target) + 0.00075 * regularization_loss
loss = mseLoss