系列文章见
RVTLSSFPN类继承BaseLSSFPN,两个类中都有DepthNet,但两个是不一样的,可以查看代码,BaseLSSFPN的是这这样:
python
self.depth_conv = nn.Sequential(
BasicBlock(mid_channels, mid_channels),
BasicBlock(mid_channels, mid_channels),
BasicBlock(mid_channels, mid_channels),
ASPP(mid_channels, mid_channels),
build_conv_layer(cfg=dict(
type='DCN',
in_channels=mid_channels,
out_channels=mid_channels,
kernel_size=3,
padding=1,
groups=4,
im2col_step=128,
)),而RVTLSSFPN中是这样的:
python
self.context_conv = nn.Sequential(
nn.Conv2d(mid_channels,
mid_channels,
kernel_size=3,
stride=1,
padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels,
context_channels,
kernel_size=1,
stride=1,
padding=0),
)我们最终调用的是RVTLSSFPN类中的网络,添加测试代码如下:
python
###### 测试代码,查看depth_net结构 ######
dummy_input = torch.randn(1, kwargs['depth_net_conf']['in_channels'], 32, 32)
mats_dict = {
'intrin_mats': torch.randn(1, 1, 6, 4, 4),
'ida_mats': torch.randn(1, 1, 6, 4, 4),
'sensor2ego_mats': torch.randn(1, 1, 6, 4, 4),
'bda_mat': torch.randn(1, 4, 4),
}
print("\n=== depth_net 模型结构 ===")
print(self.depth_net)
with torch.no_grad():
output = self.depth_net(dummy_input, mats_dict)
print(f"depth_net 输出形状: {output.shape}")
total_params = sum(p.numel() for p in self.depth_net.parameters())
print(f'depth_net 模型参数总数: {total_params}\n')
# 导出为onnx格式
torch.onnx.export(
self.depth_net, # 要导出的模型
(dummy_input, mats_dict), # 模型的输入张量
"depth_net_rvt.onnx", # 导出文件名
export_params=True, # 是否导出训练好的参数
opset_version=11, # ONNX算子集版本
)
###### 测试代码结束 ######可以看到打印出的模型结构和输出结构如下:
python
=== depth_net 模型结构 ===
DepthNet(
(reduce_conv): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(context_conv): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 80, kernel_size=(1, 1), stride=(1, 1))
)
(depth_conv): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Conv2d(256, 70, kernel_size=(1, 1), stride=(1, 1))
)
)
depth_net 输出形状: torch.Size([1, 150, 32, 32])
depth_net 模型参数总数: 4761750导出的onnx结构如下:
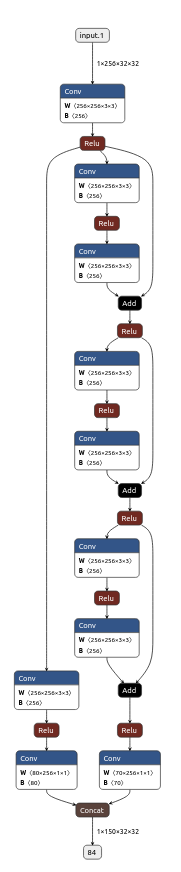
将代码copy至新文件中,可以生成一样的模型,这里BasicBlock使用了配置生成,可以参考Resnet18的BasicBlock,完整代码如下:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
"""搭建BasicBlock模块"""
expansion = 1 # 不做扩展
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__() # 调用父类 nn.Module的构造函数
# 使用BN层是不需要使用bias的,bias最后会抵消掉
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels) # BN层, BN层放在conv层和relu层中间使用
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3,stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None: # 保证原始输入X的size与主分支卷积后的输出size叠加时维度相同
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
"""神经网络的前向传播函数:
它接受一个输入张量X,然后通过一些卷积层和批量归一化层来计算输出张量Y。
如果存在下采样层,它将对输入张量进行下采样以使其与输出张量的尺寸相同。
最后,输出张量Y和输入张量X的恒等映射相加并通过ReLU激活函数进行激活。"""
class Mlp(nn.Module):
def __init__(self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.ReLU,
drop=0.0):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.drop1 = nn.Dropout(drop)
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop2 = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
class SELayer(nn.Module):
def __init__(self, channels, act_layer=nn.ReLU, gate_layer=nn.Sigmoid):
super().__init__()
self.conv_reduce = nn.Conv2d(channels, channels, 1, bias=True)
self.act1 = act_layer()
self.conv_expand = nn.Conv2d(channels, channels, 1, bias=True)
self.gate = gate_layer()
def forward(self, x, x_se):
x_se = self.conv_reduce(x_se)
x_se = self.act1(x_se)
x_se = self.conv_expand(x_se)
return x * self.gate(x_se)
class DepthNet(nn.Module):
def __init__(self, in_channels, mid_channels, context_channels, depth_channels,
camera_aware=True):
super(DepthNet, self).__init__()
self.camera_aware = camera_aware
self.reduce_conv = nn.Sequential(
nn.Conv2d(in_channels,
mid_channels,
kernel_size=3,
stride=1,
padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
)
if self.camera_aware:
self.bn = nn.BatchNorm1d(27)
self.depth_mlp = Mlp(27, mid_channels, mid_channels)
self.depth_se = SELayer(mid_channels) # NOTE: add camera-aware
self.context_mlp = Mlp(27, mid_channels, mid_channels)
self.context_se = SELayer(mid_channels) # NOTE: add camera-aware
self.context_conv = nn.Sequential(
nn.Conv2d(mid_channels,
mid_channels,
kernel_size=3,
stride=1,
padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels,
context_channels,
kernel_size=1,
stride=1,
padding=0),
)
self.depth_conv = nn.Sequential(
BasicBlock(mid_channels, mid_channels),
BasicBlock(mid_channels, mid_channels),
BasicBlock(mid_channels, mid_channels),
nn.Conv2d(mid_channels,
depth_channels,
kernel_size=1,
stride=1,
padding=0),
)
def forward(self, x, mats_dict):
x = self.reduce_conv(x)
if self.camera_aware:
intrins = mats_dict['intrin_mats'][:, 0:1, ..., :3, :3]
batch_size = intrins.shape[0]
num_cams = intrins.shape[2]
ida = mats_dict['ida_mats'][:, 0:1, ...]
sensor2ego = mats_dict['sensor2ego_mats'][:, 0:1, ..., :3, :]
bda = mats_dict['bda_mat'].view(batch_size, 1, 1, 4,
4).repeat(1, 1, num_cams, 1, 1)
mlp_input = torch.cat(
[
torch.stack(
[
intrins[:, 0:1, ..., 0, 0],
intrins[:, 0:1, ..., 1, 1],
intrins[:, 0:1, ..., 0, 2],
intrins[:, 0:1, ..., 1, 2],
ida[:, 0:1, ..., 0, 0],
ida[:, 0:1, ..., 0, 1],
ida[:, 0:1, ..., 0, 3],
ida[:, 0:1, ..., 1, 0],
ida[:, 0:1, ..., 1, 1],
ida[:, 0:1, ..., 1, 3],
bda[:, 0:1, ..., 0, 0],
bda[:, 0:1, ..., 0, 1],
bda[:, 0:1, ..., 1, 0],
bda[:, 0:1, ..., 1, 1],
bda[:, 0:1, ..., 2, 2],
],
dim=-1,
),
sensor2ego.view(batch_size, 1, num_cams, -1),
],
-1,
)
mlp_input = self.bn(mlp_input.reshape(-1, mlp_input.shape[-1]))
context_se = self.context_mlp(mlp_input)[..., None, None]
context_img = self.context_se(x, context_se)
context = self.context_conv(context_img)
depth_se = self.depth_mlp(mlp_input)[..., None, None]
depth = self.depth_se(x, depth_se)
depth = self.depth_conv(depth)
else:
context = self.context_conv(x)
depth = self.depth_conv(x)
return torch.cat([depth, context], dim=1)
def test_depth_net_model():
"""测试DepthNet模型的完整功能"""
# 模型参数
in_channels = 256
mid_channels = 256
output_channels = 80
depth_channels = 70
camera_aware = False
print("=== 创建DepthNet模型 ===")
model = DepthNet(in_channels=in_channels,
mid_channels=mid_channels,
context_channels=output_channels,
depth_channels=depth_channels,
camera_aware=camera_aware)
dummy_input = torch.randn(1, in_channels, 32, 32)
mats_dict = {
'intrin_mats': torch.randn(1, 1, 6, 4, 4),
'ida_mats': torch.randn(1, 1, 6, 4, 4),
'sensor2ego_mats': torch.randn(1, 1, 6, 4, 4),
'bda_mat': torch.randn(1, 4, 4),
}
print("\n=== depth_net 模型结构 ===")
print(model)
with torch.no_grad():
output = model(dummy_input, mats_dict)
print(f"depth_net 输出形状: {output.shape}")
total_params = sum(p.numel() for p in model.parameters())
print(f'depth_net 模型参数总数: {total_params}\n')
# 导出为onnx格式
torch.onnx.export(
model, # 要导出的模型
(dummy_input, mats_dict), # 模型的输入张量
"depth_net_new.onnx", # 导出文件名
export_params=True, # 是否导出训练好的参数
opset_version=11, # ONNX算子集版本
)
# 主测试函数
if __name__ == "__main__":
# 测试DepthNet模型
test_depth_net_model()view_aggregation_net有源代码,无需解析,直接使用即可。