PySpark与Scala Spark的区别
PySpark需通过 Py4J 桥接 JVM,有 10%-30% 性能损耗(UDF / 大数据量下明显);
优先选 Scala Spark 的场景:核心是 **"追求性能、底层开发、企业级生产环境"**
- 超大规模数据处理(TB/PB 级):比如离线批处理、复杂多表 Join、高频 UDF 计算 ------Scala 无跨语言开销,性能优势明显,能减少任务执行时间和资源消耗;
- 企业级生产环境(稳定性优先):比如金融 / 政务的核心数据处理任务 ------Scala 的静态类型能在编译期发现错误,避免线上运行时崩溃,且 Scala 的并发 / 线程模型更适配 Spark 的 JVM 架构;
- Spark 最新特性落地:比如 Spark 3.x 的最新流处理(Structured Streaming)、自适应执行(AQE)等特性 ------Scala 会第一时间支持,PySpark 可能滞后 1-2 个版本
优先选 PySpark 的场景
核心是 **"快速迭代、数据科学、团队技术栈适配"**:
- 数据探索 / 交互式分析 :比如分析师探索 Hive 中的数据、快速验证业务逻辑 ------PySpark 可配合 Jupyter Notebook 使用,支持交互式执行,且能无缝衔接 Pandas(
df.toPandas()),可视化更方便(Matplotlib/Seaborn); - 机器学习 / AI 场景:比如用 Spark 处理特征数据,再对接 Scikit-learn/TensorFlow/PyTorch------Python 是 AI 领域的主流语言,PySpark 能直接把 Spark DataFrame 转换成 Pandas DataFrame,复用 Python 的机器学习生态;
- 团队技术栈以 Python 为主:比如团队成员都是 Python 开发者(无 Scala 基础)------ 无需额外学习 Scala,降低协作成本,且 PySpark 的 API 设计更贴近 Python 习惯(比如函数式编程的写法更灵活);
选型建议(落地层面)
- 团队维度:如果团队以数据分析师、算法工程师为主 → 选 PySpark;如果是大数据平台开发团队 → 选 Scala Spark;
- 混合场景:企业级平台通常是 "Scala 做底层框架开发 + PySpark 做上层业务分析"------ 比如用 Scala 开发 Spark 通用处理组件,数据分析师用 PySpark 调用组件处理业务数据
- 轻量级任务 / 快速原型开发:比如小数据量 ETL、简单的统计分析 ------PySpark 开发速度快,代码量少,能快速落地需求,性能损耗可忽略不计。
避坑提醒:
- PySpark 慎用自定义 UDF(User-Defined Function)(尤其是高频调用):Python UDF 的跨语言开销会导致性能暴跌,可改用 Spark SQL 内置函数,或用 Pandas UDF(矢量化 UDF)优化;
- Scala Spark 注意函数式编程陷阱:比如避免频繁创建对象导致 JVM GC 压力,需熟悉 Spark 的 RDD/DataFrame 优化规则。
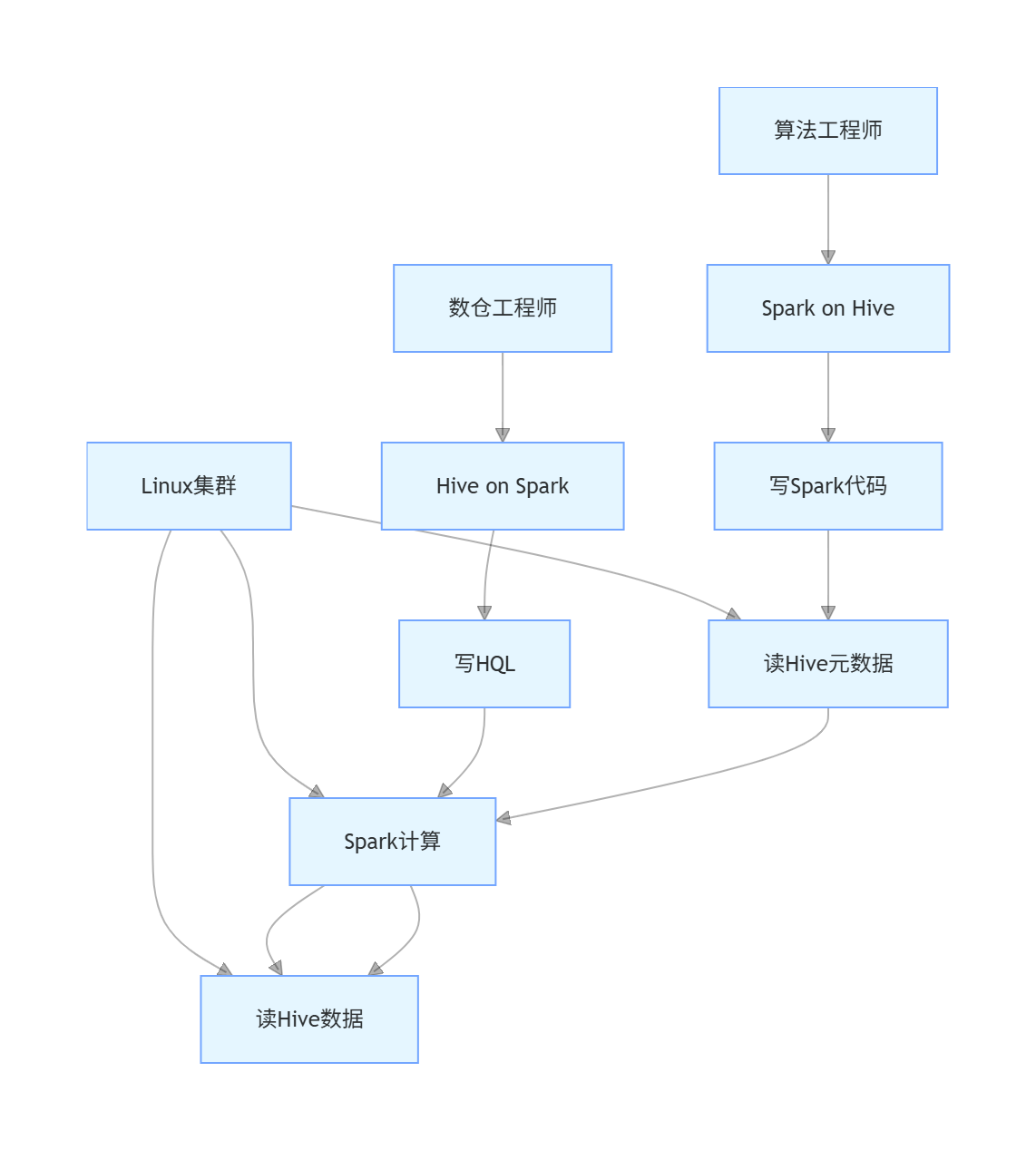
Hive on Spark和Spark on Hive可否在同一个集群实现?
spark用来搞计算