系列文章目录
--
文章目录
- 系列文章目录
- 前言
- 零、大模型时代的"微调"困境
-
- [0.1 "提示"范式的兴起与局限](#0.1 “提示”范式的兴起与局限)
- [0.2 参数高效微调的诞生](#0.2 参数高效微调的诞生)
- [一、参数高效微调 PEFT](#一、参数高效微调 PEFT)
-
- [1.1 冻结思想](#1.1 冻结思想)
- [1.2 PEFT 技术发展脉络](#1.2 PEFT 技术发展脉络)
-
- [1.2.1 Adapter Tuning](#1.2.1 Adapter Tuning)
- [1.2.2 Prefix Tuning](#1.2.2 Prefix Tuning)
- [1.2.3 Prompt Tuning](#1.2.3 Prompt Tuning)
- [1.2.4 P-Tuning v2](#1.2.4 P-Tuning v2)
-
- [1.2.4.1 P-Tuning 的主要逻辑](#1.2.4.1 P-Tuning 的主要逻辑)
- 二、LoRA
-
- [2.1 低秩近似的核心思想](#2.1 低秩近似的核心思想)
-
- [2.1.1 内在秩](#2.1.1 内在秩)
- 总结
前言
零、大模型时代的"微调"困境
自
BERT模型发布以来,"预训练-微调"(Pre-train and Fine-tune) 的范式在自然语言处理领域取得了巨大成功。不过,当模型参数规模从
BERT的数亿级别跃升至GPT-3的千亿级别时,传统的 全量微调(Full Fine-Tuning) 遇到了挑战。
- 简而言之,遇到了以下几个问题:
- 高昂的训练成本:想想也知道,一个千亿参数大模型背后消耗的巨大的计算资源、时间、人力等。
- 巨大的存储压力:如果为每一个下游任务都保存一份完整的、千亿级别的模型副本,将导致难以承受的存储开销。
- 灾难性遗忘:千亿参数大模型背后是汇聚的海量知识,但是针对特定任务进行微调时,模型很可能忘记了在预训练截断学到的通用知识,泛化能力得到了损害。
- 训练不稳定性:大模型的网络结构"又宽又深",其训练过程对学习率等超参数极为敏感,很容易出现梯度消失/爆炸等问题,导致训练失败。
0.1 "提示"范式的兴起与局限
2020 年
GPT-3论文带来了一种全新的、无需训练的范式------上下文学习 In-Context Learning。
- 由此诞生了提示词工程 Prompt Engineering ,仅通过在输入中提供一些任务示例(即 提示 Prompt),就能引导大模型完成特定任务。
- 这种人工设计的、离散的文本指令,我们称之为 "硬提示"(Hard Prompt)。
- 但是实际上这种范式存在着明显的局限性,比如需要大量试错,需要专业设计,每个模型接受度也不一样等等。
0.2 参数高效微调的诞生
- 如何找到一种既能有效利用大模型能力,又不必承受全量微调高昂成本的方法?
- 学术界和工业界开始探索一种全新的方法:参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)。
一、参数高效微调 PEFT
PEFT的思想借鉴了计算机视觉领域的迁移学习(Transfer Learning) 。在 CV 任务中,我们通常会冻结预训练模型(如ResNet)负责提取通用特征的卷积层,仅微调后面的全连接层来适应新的分类任务。PEFT将这一思想应用于Transformer架构,并发展出多条技术路线。
1.1 冻结思想
- 核心思想:冻结(freeze) 预训练模型 99% 以上的参数,仅调整其中极小一部分(通常<1%)的参数,或者增加一些额外的"小参数",从而以极低的成本让模型适应下游任务。
1.2 PEFT 技术发展脉络
1.2.1 Adapter Tuning
Adapter Tuning是PEFT领域的开创性工作之一,由 Google 在 2019 年为BERT模型设计。
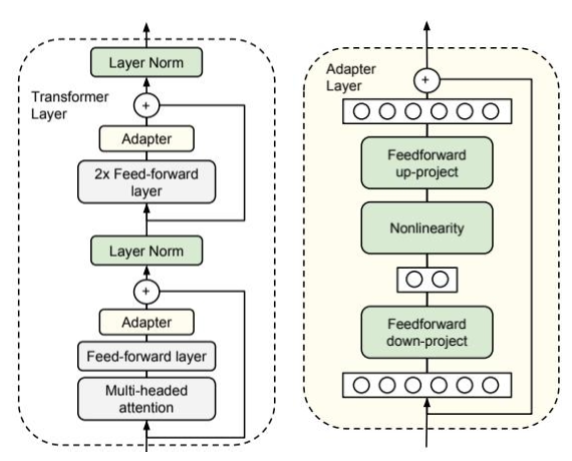
- 其思路是在 Transformer 的每个块中插入小型的"适配器"(Adapter)模块。
- 位置: 注意力头 → 前馈网络 → Adapter → 下一层
- 内部构造:
输入信息
压缩室
激活函数ReLU
膨胀室
输出
-
Adapter 模块自身的结构:
- 压缩室:一个"降维"的全连接层(Feedforward down-project),将高维特征映射到低维空间。
- 激活函数:一个非线性激活函数(Nonlinearity)。
- 膨胀室:一个"升维"的全连接层(Feedforward up-project),再将特征映射回原始维度。
- 输出:一个贯穿该模块的残差连接,将模块的输出与原始输入相加,保证信息流的稳定。
-
为什么有效?
- "压缩-膨胀"过程像信息筛子:
- 通用知识(比如"爱"是褒义词)直接穿过Adapter不被改动
- 任务专属知识(比如"爱了爱了"在微博是夸,在论文里是病句)被Adapter重点加工
-
结果:BERT本体当"知识仓库",Adapter当"任务翻译官"------分工超默契!
-
调参对比
-
BERT-base是12层:
- 每层 = 768个神经元
- 全连接层 = 每个和其他所有连线 → 768×768 = 59万
- 12层总参数 = 1.1亿(实际109M,但还是"1亿参数俱乐部")
-
Adapter怎么省参数?------假设一层Adapter:
- 压缩层参数 = 768 × 64 = 49,152
- 膨胀层参数 = 64 × 768 = 49,152
- 单层Adapter总参数 = 49,152 × 2 = 98,304
- 12层总参数 = 98,304 × 12 ≈ 118万
-
优势:
- Adapter 模块可以用极少的参数量来模拟特定任务的知识。
- 这种方法不仅参数效率高、训练稳定,而且性能上能接近全量微调。
- 相比全量微调,能够显著降低可训练参数与优化器状态占用;
-
但是,由于各层插入了额外模块,这个操作会很复杂,而且需要给所有层都要加上额外模块,这样训练与推理时会带来一定的激活内存与算力开销。在千亿级规模且资源受限的条件下,工程实现更具挑战。
1.2.2 Prefix Tuning
2021 年,斯坦福大学的研究者提出了
Prefix Tuning,为PEFT开辟了一条全新的思路。
- 与
Adapter在模型内部"动手术"不同,Prefix Tuning选择在模型外部做文章。
1.2.3 Prompt Tuning
2021年,Google 提出了
Prompt Tuning,可以看作是Prefix Tuning的一个简化版。
Prefix Tuning虽然强大,但其复杂的训练过程和在每一层都添加参数的设计,在实践中不够便捷。Prompt Tuning也被称为一种 "软提示" 。 它的做法就是只在输入的 Embedding 层添加可学习的虚拟 Token(称为 Soft Prompt) ,而不再干预Transformer的任何中间层。
1.2.4 P-Tuning v2
由清华大学团队主导的
P-Tuning系列工作,对软提示进行了深入优化,最终发展出了效果更强、更通用的P-Tuning v2
Prompt Tuning虽然足够高效,但它的稳定性较差,且严重依赖超大模型的规模,这限制了其在更广泛场景中的应用。
1.2.4.1 P-Tuning 的主要逻辑
- 为了理解
P-Tuning v2的精髓,首先需要了解其前身P-Tuning v1。
二、LoRA
-
以
Adapter和各类Prompt Tuning为代表的PEFT技术。它们通过在模型中插入新的模块或在输入端添加可学习的提示,巧妙地实现了高效微调。 -
这些方法的核心,都是在尽量不"打扰"原始模型权重的前提下,通过影响模型的激活值来适应新任务。
-
当前社区应用最广泛的
PEFT方法------LoRA(Low-Rank Adaptation of Large Language Models)。 -
它不再"绕道而行",而是直击模型的权重矩阵,并提出一个观点:那就是大模型的参数更新,或许并不需要那么"兴师动众"。
2.1 低秩近似的核心思想
全量微调之所以成本高昂,是因为它需要为模型中每一个权重矩阵 W W W(维度可能高达数万)计算并存储一个同样大小的更新矩阵 Δ W ΔW ΔW。
- 为了解决这个问题,研究者们提出了像
Adapter Tuning和Prompt Tuning这样的参数高效微调方法。 - 但是,它们也存在一些未解决的痛点。
Adapter虽好,却会引入额外的推理延迟;Prompt Tuning则会占用输入序列长度,且优化难度较高。