目录
[LLM 的消息结构](#LLM 的消息结构)
[2.提示词模板(Prompt Template)](#2.提示词模板(Prompt Template))
[使用LangChain Hub的提示词模板](#使用LangChain Hub的提示词模板)
[示例选择器(Example selectors)](#示例选择器(Example selectors))
[通过语义 ngram 重叠选择示例(Ngram)](#通过语义 ngram 重叠选择示例(Ngram))
[4.输出解析器(Output parsers)](#4.输出解析器(Output parsers))
核心组件(Components)
1.消息(Messages)
消息是聊天模型中的通信单位,用于表示聊天模型的输入和输出,以及可能与对话关联的任何其他上下文或元数据。
LLM 的消息结构
每条消息都有一个角色和内容,以及因 LLM 的不同而不同的附加元数据。
**消息角色 (Role):**用来 区分对话中不同类型的消息,并帮助聊天模型了解如何响应给定的消息序列。

**消息内容 (Content):**表示多模态数据 (例如,图像、音频、视频)的消息文本或字典列表的内容。内容的具体格式可能因底层不同的 LLM 而异。目前 ,大多数模型都支持文本作为主要内容类型,对多模态数据的支持仍然有限。
下面展示一个OpenAI 的格式消息列表:
[
{
"role": "user",
"content": "Hello, how are you?",
},
{
"role": "assistant",
"content": "I'm doing well, thank you for asking.",
},
{
"role": "user",
"content": "Can you tell me a joke?",
}
]LangChain 接受下面的格式作为聊天模型的输入:
chat_model.invoke([
{
"role": "user",
"content": "Hello, how are you?",
},
{
"role": "assistant",
"content": "I'm doing well, thank you for asking.",
},
{
"role": "user",
"content": "Can you tell me a joke?",
}
])LangChain的消息
LangChain 提供了一种统一的消息格式,可以跨聊天模型使用,允许用户使用不同的聊天模型,而无需担心每个模型提供商使用的消息格式的具体细节。例如:
openai_model = init_chat_model("gpt-4o-mini", model_provider="openai")
anthropic_model = init_chat_model("claude-3-5-sonnet-latest",model_provider="anthropic")
deepseek_model = init_chat_model("deepseek-chat", model_provider="deepseek")
google_genai_model = init_chat_model("gemini-2.5-flash",model_provider="google_genai")
model = init_chat_model(...)这些模型提供商不同,但对于其输入和输出,统一使用 LangChain 的消息格式。LangChain 消息格式主要分为五种,分别是:

缓存历史消息
在与大型语言模型交互的过程中,我们常常体验到与智能助手进行连贯多轮对话的便利性。但目前 我们的系统还不支持此功能,代码如下:
from langchain_openai import ChatOpenAI
#定义模型
model=ChatOpenAI(model="gpt-4o-mini")
#这种调用方式不具备记忆功能
model.invoke("我叫小明").pretty_print()
model.invoke("你知道我是谁吗").pretty_print()
可以发现,聊天模型并不认识我们,更别说支持更多轮的对话了~
稍作修改,让我们将 AI 回复给我们的响应跟着新的用户消息一起发给聊天模型试试。代码如下:
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from langchain_openai import ChatOpenAI
#定义模型
model=ChatOpenAI(model="gpt-4o-mini")
#具备记忆功能
#可以看出,当我们把LLM回复给我们的消息(AIMessage)
#和用户消息(HumanMessage)同时发给LLM,此时LLM就具备记忆功能了
message=[
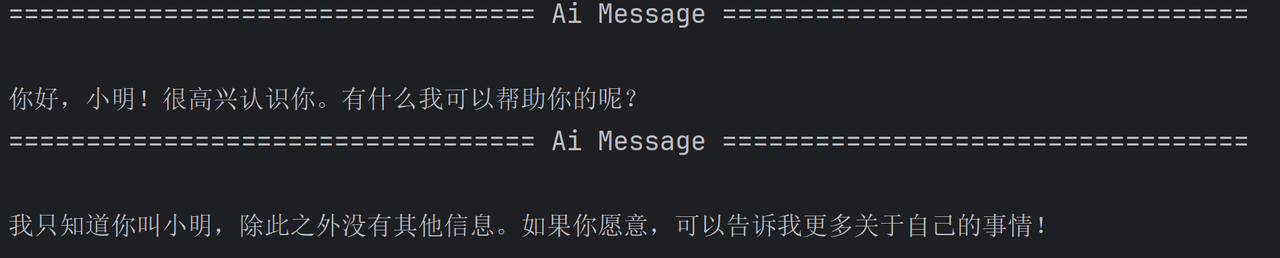
HumanMessage("我叫小明"),
AIMessage("你好,小明!很高兴认识你。有什么我可以帮你的吗?"),
HumanMessage("你知道我是谁吗")
]
model.invoke(message).pretty_print()
从结果可知,只要将历史消息,重新发送给聊天模型,那么就可以实现多轮对话的功能。
那么对于历史消息的管理就显得尤为重要。在 LangChain 老版本中,可以使用RunnableWithMessageHistory 消息历史类来包装另一个Runnable 并为其管理聊天消息历史记录。它将跟踪模型的输入和输出,并将其存储在某个数据存储中。未来的交互将加载这些消息,并将其作为输入的一部分传递给链。
代码如下:
#让大模型具有记忆功能
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI
#定义模型
model=ChatOpenAI(model="gpt-4o-mini")
#将消息存储在内存中
#定义消息的存储结构(key:会话,val:历史消息)
store={}
def get_session_history(session_id:str)->BaseChatMessageHistory:
if session_id not in store:
#InMemoryChatMessageHistory:自动将AIMessage和HumanMessage.......添加进来
store[session_id]=InMemoryChatMessageHistory()
return store[session_id]
#包装model,让model具备存储历史消息功能
model_with_history_message=RunnableWithMessageHistory(model,get_session_history)
#model为Runnable实例
#invoke可以通过config来配置 Runnable实例
config={"configurable":{"session_id":"1"}}
#每次在调用的时候,都会去内存中查找会话ID为1的历史消息
model_with_history_message.invoke("我叫小明",config=config).pretty_print()
model_with_history_message.invoke("你知道我是谁吗?",config=config).pretty_print()参数说明:
-
runnable :被包装 Runnable 实例,这里就是我们定义的聊天模型。
-
get_session_history :返回类型为 BaseChatMessageHistory 的函数,传入后作为回调函数。此函数接受一个 session_id 字符串类型,并返回相应的聊天消息历史记录实例。
-
invoke() 方法:此方法与其他 Runnable 实例的 .invoke() 方法相同。只不过注意其config配置,需要配置成 config={"configurable": {"session_id": ""}} ,让RunnableWithMessageHistory 可以读取到会话id。
管理历史消息
管理历史消息,无非就是理解如何"管理","管理"无非也就是一些"CRUD"。那么在了解如何管理消息之前,需要先了解下多轮对话的核心概念:上下文窗口。上下文窗口可以理解为模型的"短期工作记忆区",即 LLM 在一次处理请求时,所能查看和处理的最大Token 数量,它包含了:
-
用户的输入
-
大模型的输出
-
有时还包括系统指令(SystemMessage)和对话历史。
不同大模型支持的上下文窗口大小不同,例如:
-
OpenAI 下 GPT-5 模型上下文窗⼝为 400000 (最大 Token 数量)
-
GPT-4.1 模型上下文窗口为 1047576 (最大 Token 数量)
++消息裁剪++
下面演示一个通过 trim_messages 裁剪消息的示例(基于输入Token 数的修剪)。
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage,trim_messages
# 定义⼤模型
model = ChatOpenAI(model="gpt-4o-mini")
messages = [
SystemMessage(content="you're a good assistant"),
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
HumanMessage(content="What's my name?"),
]
print(model.invoke(messages))
# 使⽤ trim_messages 减少发送给模型的消息数量(按照token数量)
trimmer = trim_messages(
max_tokens=65, # 修剪消息的最⼤令牌数,根据你想要的谈话⻓度来调整
strategy="last", # 修剪策略:"last"(默认):保留最后的消息。
# "first":保留最早的消息。
token_counter=model,# 传⼊⼀个函数或⼀个语⾔模型(因为语⾔模型有消息令牌计数⽅法)
include_system=True,# 如果想始终保留初始系统消息,可以指定include_system=True
allow_partial=False,# 是否允许拆分消息的内容
start_on="human",# 如果需要确保我们的第⼀条消息(不包括系统消息)始终是特定类型,可以指定 start_on
)
chain = trimmer | model
print(chain.invoke(messages))除了基于 token 的修剪,还可以通过设置 token_counter=len 根据消息数修剪聊天记录。在这种情况下, max_tokens 将控制最大消息数。示例如下:
#上下文长度
#进行消息裁剪
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage,trim_messages
# 定义⼤模型
model = ChatOpenAI(model="gpt-4o-mini")
messages = [
SystemMessage(content="you're a good assistant"),
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
HumanMessage(content="What's my name?"),
]
print(model.invoke(messages))
# 使⽤ trim_messages 减少发送给模型的消息数量(按照消息的数量)
# 使⽤ trim_messages 减少发送给模型的消息数量
trimmer = trim_messages(
max_tokens=11, # 最⼤消息数
strategy="last", # 修剪策略:"last"(默认):保留最后的消息。可获取消息列表中的最后⼀个 max_tokens
# "first":保留最早的消息。
token_counter=len, # 根据消息数裁剪
include_system=True,# 如果想始终保留初始系统消息,可以指定include_system=True
allow_partial=False,# 是否允许拆分消息的内容
start_on="human",# 如果需要确保我们的第⼀条消息(不包括系统消息)始终是特定类型,可以指定 start_on
)
chain = trimmer | model
print(chain.invoke(messages))++消息过滤++
在更复杂的场景下,我们可能会使用消息列表来跟踪状态,例如我们可能只想将这个完整消息列表的子集传递模型调用,而不是所有的历史记录。filter_messages 方法则可以轻松地按类型、ID 或名称过滤 message。
下面演示相关过滤示例,首先准备消息列表:
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage,filter_messages
# 历史消息记录
messages = [
SystemMessage("你是⼀个聊天助⼿", id="1"),
HumanMessage("⽰例输⼊", id="2"),
AIMessage("⽰例输出", id="3"),
HumanMessage("真实输⼊", id="4"),
AIMessage("真实输出", id="5"),
]按照类型进行筛选
#按照类型进行筛选
print(filter_messages(messages, include_types="human"))
filter_messages(include_types="human").invoke(messages)按类型+ID进行筛选:
#按照消息类型+ID进行筛选
print(filter_messages(messages, include_types=[HumanMessage, AIMessage],exclude_ids=["3"]))++消息合并++
若我们的消息列表存在连续某种类型相同的消息,但实际上某些模型不支持传递相同类型的连续消息。因此对于这种情况,我们可以使用 merge_message_runs 方法轻松合并相同类型的连续消息。
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage, merge_message_runs
from langchain_openai import ChatOpenAI
model=ChatOpenAI(model="gpt-4o-mini")
messages = [
SystemMessage("你是⼀个聊天助⼿。"),
SystemMessage("你总是以笑话回应。"),
HumanMessage("为什么要使⽤ LangChain?"),
HumanMessage("为什么要使⽤ LangGraph?"),
AIMessage("因为当你试图让你的代码更有条理时,LangGraph 会让你感到"节点"是个好主意!"),
]
merged=merge_message_runs(messages)
#打印合并后的消息
print("\n".join([repr(x) for x in merged]))
#merged=merge_message_runs()
#chain = merged | model
#chain.invoke(messages).pretty_print()
2.提示词模板(Prompt Template)
提示词模板(Prompt Template)是 LangChain 的核心抽象之一,它被广泛应用于构建大语言模型(LLM)应用的各个环节。
简单来说,只要是需要动态、批量、或有结构地向大语言模型【发送请求】的地方,几乎都会用到提示词模板。
一个简单的例子,假设我们想根据一个城市名询问 LLM 其历史,按照之前的做法,我们可以定义HumanMessage("请介绍上海的历史") 、 HumanMessage("请介绍西安的历史") 消息等等。可以发现每次询问都会
描写重复的消息内容: 请介绍xxx的历史 。
在 LangChain 中,针对这种情况,可以定义一个模板:
-
固定文本(模板): "请介绍{city}的历史。"
-
输入变量: "city"
定义好后,可以使⽤该模板:
-
当我们需要查询北京时,就将 city 变量赋值为 "北京"。模板引擎会⽣成: "请介绍北京的历史。"
-
当我们需要查询上海时,就将 city 变量赋值为 "上海"。模板引擎会⽣成: "请介绍上海的历史。"
文本提示词模板
LangChain 提供了 PromptTemplate 类来轻松实现这一功能。 PromptTemplate 实现了标准的Runnable 接口。
示例如下:
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate, MessagesPlaceholder
#定义文本提示词模板
#方式一
#prompt_template = PromptTemplate(
# input_variables=["language"],
# template="Translate the following into {language}",
#)
#方式二
prompt_template = PromptTemplate.from_template("将文本从[language_from]翻译成[language_to]")
print(prompt_template.invoke({
"language_from": "英文",
"language_to": "中文"
}))
#输出: text='将文本从[language_from]翻译成[language_to]'class langchain_core.prompts.prompt.PromptTemplate 类,其参数如下:
-
template :提示模板
-
input_variables :需要其值作为提示输入的变量的名称列表。
内置方法:
- from_template() :从模板定义提示模板。方法返回了一个 PromptTemplate 实例。
聊天提示词模板
ChatPromptTemplate 模板:专为 LangChain 聊天模型设计。可以方便地构建包含SystemMessage 、 HumanMessage 、 AIMessage 的消息模板。
如下代码所示:
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
model=ChatOpenAI(model="gpt-4o-mini")
#定义聊天提示词模板
chat_prompt_template = ChatPromptTemplate(
[
("system","将文本从[language_from]翻译成[language_to]"),
("user","{text}")
]
)
#实例化模板
messages=chat_prompt_template.invoke(
{
"language_from": "英文",
"language_to": "中文",
"text": "how are you?"
}
)
print(messages)
model.invoke(messages).pretty_print()
# chain = chat_prompt_template | model
# print(chain.invoke({
# "language_from": "英文",
# "language_to": "中文",
# "text": "how are you?"
# }
# ))
消息占位符
在上⾯的 ChatPromptTemplate 中,我们看到了如何格式化两条消息,每条消息都是⼀个字符串。但如果我们希望将消息插入特定位置怎么办?使用MessagesPlaceholder 。MessagesPlaceholder 负责在特定位置添加消息列表。
代码如下:
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
#消息占位符
prompt_template = ChatPromptTemplate([
("system","你是一个聊天助手"),
MessagesPlaceholder("msgs"), #消息占位
])
messages=[
HumanMessage(content="中国⾸都是哪⾥?"),
AIMessage(content="中国⾸都是北京。"),
HumanMessage(content="那法国呢?")
]
formatted_ptompt_template = prompt_template.invoke({"msgs":messages})
print(formatted_ptompt_template)使用LangChain Hub的提示词模板
LangChain Hub 是一个用于上传、浏览、拉取和管理提示词(prompts)的地方。随着 LLM 的发展,提示词变得越来越重要。LangChain 正在打造一个与像 GitHub 这样的传统平台,GitHub长期以来一直是共享和协作代码的首选平台。于是推出了 LangChain Hub 平台。
LangChain Hub 官网地址:https://smith.langchain.com/hub/
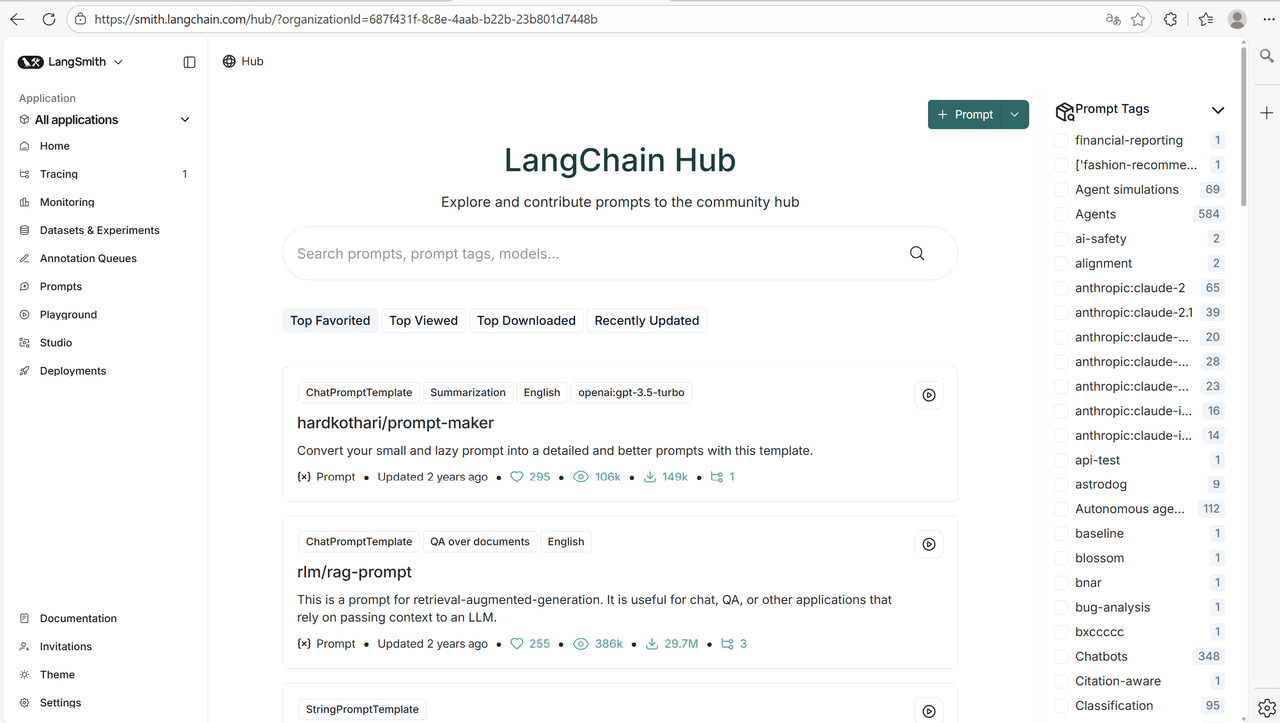 目前收藏最高的提示词模板是: hardkothari/prompt-maker ,我们就以它为示例,演示一下如何使用LangChain Hub 上的提示词。
目前收藏最高的提示词模板是: hardkothari/prompt-maker ,我们就以它为示例,演示一下如何使用LangChain Hub 上的提示词。
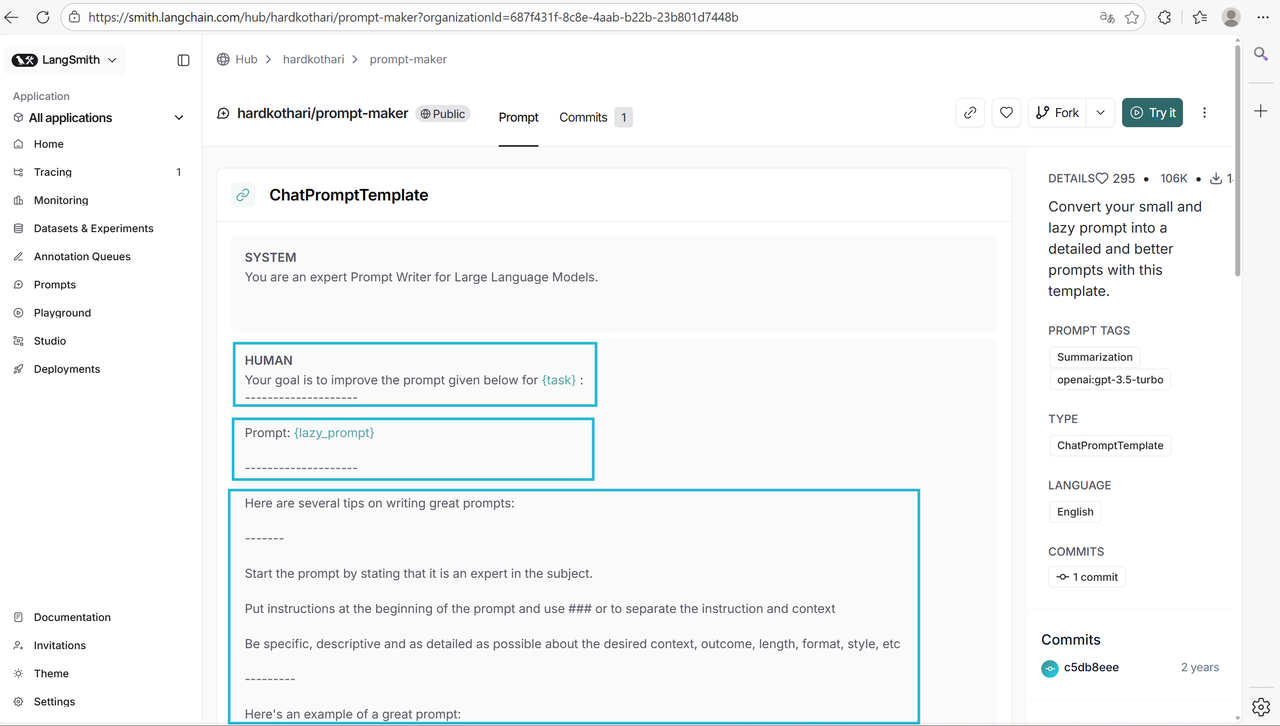
要想使用该能力,需要先申请并配置 LangSmith 环境变量: LANGSMITH_API_KEY="你的LangSmith API Key" 。接着,需要从 hub 拉取相应的提示,并使用。
代码如下:
from langchain_openai import ChatOpenAI
from langsmith import Client
client = Client()
#拉取提示词(这个提示词模板,会对我们输入的提示词进行优化)
prompt = client.pull_prompt("hardkothari/prompt-maker")
model=ChatOpenAI(model="gpt-4o-mini")
#定义链
chain = prompt | model
while True:
task=input("你的任务是什么?(输入quit退出)\n")
if task=="quit":
break
lazy_prompt=input("你当前的提示词是什么?(输入quit退出)\n")
if lazy_prompt=="quit":
break
chain.invoke({"task":task,"lazy_prompt":lazy_prompt}).pretty_print()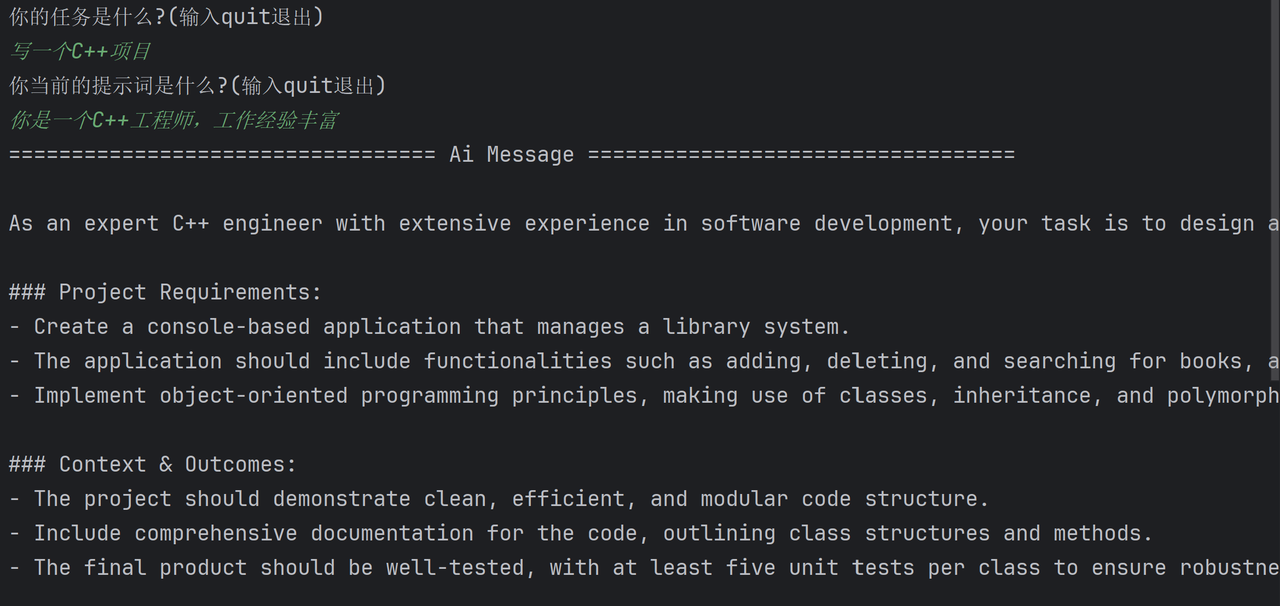
3.少样本提示(few-shotting)
少样本提示是一种通过向 LLM 提供少量具体示例或样本,来教会它如何执行某项特定任务的技术。提高模型性能的最有效方法之一是给出一个【模型示例】指导大模型你想做什么、怎么做。下面用一个例子解释少样本提示的作用。
对于 LangChain 就需要创建⼀个FewShotChatMessagePromptTemplate 对象来实例化示例集。FewShotChatMessagePromptTemplate 是一个提示词模板,专门用来将示例集实例化为聊天消息,用法如下所示:
#少样本提示
from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
from langchain_openai import ChatOpenAI
model=ChatOpenAI(model="gpt-4o-mini")
#定义案例
examples = [
{"text":"2 😍 3 等于多少?","output":"2 😍 3 等于6"},
{"text":"3 😍 5 等于多少?","output":"3 😍 5 等于15"}
]
#要想将案例加入到聊天提示词模板中,需要先将案例转化成消息列表,然后再插入到消息列表中
#要想转化为消息列表,通过提示词模板+案例(参数)
#定义与案例有关的提示词模板
examples_prompt_template = ChatPromptTemplate([
("user","{text}"), #用户输入
("ai","{output}") #ai回复
])
#定义少量提示词模板
few_prompt_template=FewShotChatMessagePromptTemplate(
examples=examples,
example_prompt=examples_prompt_template
)
#定义聊天提示词模板
chat_prompt_template = ChatPromptTemplate([
("system","计算{number1} 😍 {number2} 等于多少?"),
few_prompt_template,
("user","{number1}😍{number2}等于多少?")
])
#定义链
chain = chat_prompt_template | model
print(chain.invoke({
"number1":10,"number2":3,
}))
使用案例1:推理引导
#少量提示词模板1: 推理引导
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
from langchain_openai import ChatOpenAI
#定义模型
model = ChatOpenAI(model="gpt-4o-mini")
#定义样本提示词模板
examples_prompt_template = PromptTemplate.from_template("Question :{question}\n{answer}")
#定义案例
examples = [
{
"question": "李⽩和杜甫,谁更⻓寿?",
"answer": """
是否需要后续问题:是的。
后续问题:李⽩享年多少岁?
中间答案:李⽩享年61岁。
后续问题:杜甫享年多少岁?
中间答案:杜甫享年58岁。
所以最终答案是:李⽩
"""
},
{
"question": "腾讯的创始⼈什么时候出⽣?",
"answer": """
是否需要后续问题:是的。
后续问题:腾讯的创始⼈是谁?
中间答案:腾讯由⻢化腾创⽴。
后续问题:马化腾什么时候出⽣?
中间答案:马化腾出⽣于1971年10⽉29⽇。
所以最终答案是:1971年10⽉29⽇
""",
},
{
"question": "孙中⼭的外祖⽗是谁?",
"answer": """
是否需要后续问题:是的。
后续问题:孙中⼭的⺟亲是谁?
中间答案:孙中⼭的⺟亲是杨太夫⼈。
后续问题:杨太夫⼈的⽗亲是谁?
中间答案:杨太夫⼈的⽗亲是杨胜辉。
所以最终答案是:杨胜辉
""",
},
{
"question": "电影《红⾼粱》和《霸王别姬》的导演来⾃同⼀个国家吗?",
"answer": """
是否需要后续问题:是的。
后续问题:《红⾼粱》的导演是谁?
中间答案:《红⾼粱》的导演是张艺谋。
后续问题:张艺来⾃哪⾥?
中间答案:中国。
后续问题:《霸王别姬》的导演是谁?
中间答案:《霸王别姬》的导演是陈凯歌。
后续问题:陈凯歌来⾃哪⾥?
中间答案:中国。
所以最终答案是:是
""",
},
]
#定义少量提示词模板
#FewShotPromptTemplate 少样本文本提示词模板
few_shot_prompt_template = FewShotPromptTemplate(
examples=examples,
example_prompt=examples_prompt_template,
suffix="Question : {input}", #将输入的变量放入到示例之后
input_variables=["input"], #输入变量列表
)
# print(few_shot_prompt_template.invoke({"input":"<教父>和<星球大战>的导演是同一个国家的吗?"}).to_string())
# #定义链
chain = few_shot_prompt_template | model
chain.invoke({"input": "<教父>和<星球大战>的导演是同一个国家的吗?"}).pretty_print()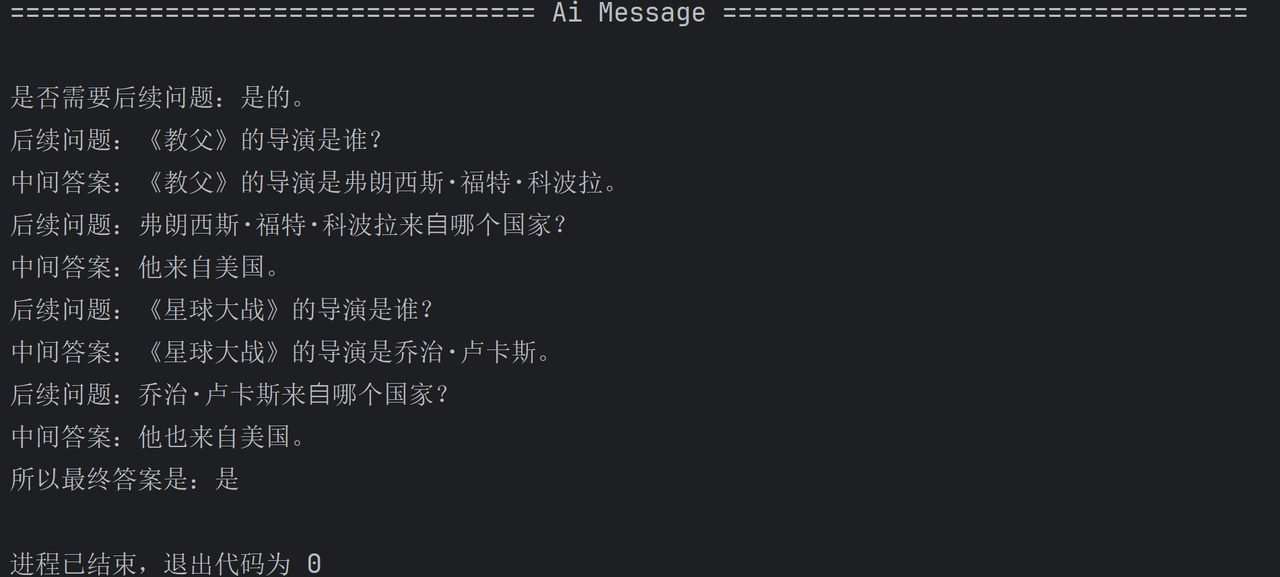
使用案例2:增强LanggChain信息提取能力
#样本提示词模板2:增强信息推理能力
from typing import List, Optional
from langchain_core.messages import SystemMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.utils.function_calling import tool_example_to_messages
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
#1.定义模型
model= ChatOpenAI(model="gpt-4o-mini")
#2.定义结构化输出
class Person(BaseModel):
"""⼀个⼈的信息。"""
name: Optional[str] = Field(default=None, description="这个人的名字")
hair_color: Optional[str] = Field(default=None, description="如果知道这个人头发的颜⾊")
skin_color: Optional[str] = Field(default=None, description="如果知道这个人的肤色")
height_in_meters: Optional[str] = Field(default=None, description="以米为单位的高度")
class Data(BaseModel):
"""提取关于⼈的数据。"""
people: List[Person]
#3.定义示例
examples = [
(
"海洋是⼴阔而蓝色的。它有两万多英尺深。",
Data(people=[]), # 没有⼈物信息的情况
),
(
"小强从中国远行到美国。",
Data(people=[Person(name="⼩强", height_in_meters=None, skin_color=None,hair_color=None),])
),
]
#4.将示例转化为消息列表(AIMessage/HumanMessage/...)
messages=[]
for txt,tool_call in examples:
if tool_call.people:
ai_response="检测到人"
else:
ai_response="未检测到人"
messages.extend(tool_example_to_messages(
txt, #输入的文本
[tool_call], #工具(使用pydantic对象作为工具)
ai_response=ai_response, #让LLM强制生成ai_response
))
# print(messages)
#输出
# [
# HumanMessage(content='海洋是⼴阔⽽蓝⾊的。它有两万多英尺深。', additional_kwargs={}, response_metadata={}),
# AIMessage(content='', additional_kwargs={'tool_calls': [{'id': '9402077d-db91-4d81-ba0d-6f374d2617ac', 'type': 'function', 'function': {'name': 'Data', 'arguments': '{"people":[]}'}}]}, response_metadata={}, tool_calls=[{'name': 'Data', 'args': {'people': []}, 'id': '9402077d-db91-4d81-ba0d-6f374d2617ac', 'type': 'tool_call'}]),
# ToolMessage(content='You have correctly called this tool.', tool_call_id='9402077d-db91-4d81-ba0d-6f374d2617ac'),
# AIMessage(content='未检测到人', additional_kwargs={}, response_metadata={}),
# HumanMessage(content='⼩强从中国远⾏到美国。', additional_kwargs={}, response_metadata={}),
# AIMessage(content='', additional_kwargs={'tool_calls': [{'id': '4d65ef45-0d2b-4ec6-b4ae-2c947ffa7ba3', 'type': 'function', 'function': {'name': 'Data', 'arguments': '{"people":[{"name":"⼩强","hair_color":null,"skin_color":null,"height_in_meters":null}]}'}}]}, response_metadata={}, tool_calls=[{'name': 'Data', 'args': {'people': [{'name': '⼩强', 'hair_color': None, 'skin_color': None, 'height_in_meters': None}]}, 'id': '4d65ef45-0d2b-4ec6-b4ae-2c947ffa7ba3', 'type': 'tool_call'}]),
# ToolMessage(content='You have correctly called this tool.', tool_call_id='4d65ef45-0d2b-4ec6-b4ae-2c947ffa7ba3'),
# AIMessage(content='检测到人', additional_kwargs={}, response_metadata={})
# ]
#5.定义提示词模板
prompt_template = ChatPromptTemplate([
SystemMessage(content="你是⼀个提取信息的专家,只从⽂本中提取相关信息。""如果您不知道要提取的属性的值,属性值返回null"),
MessagesPlaceholder("example_messages"), #消息占位符(传入示例)
("user", "{new_message}"), #用户输入的信息
])
#将返回结构绑定到模型
model_with_struct=model.with_structured_output(Data)
#定义链
chain = prompt_template | model_with_struct
print(chain.invoke(
{
"example_messages": messages,
"new_message": "篮球场上,⾝⾼两⽶的中锋王伟默契地将球传给⼀⽶七的后卫挚友李明,完成⼀记绝杀。这对⽼友⽤⼗年配合弥补了⾝⾼的差距。"
}
))输出结果:
people=[
Person(name='王伟', hair_color=None, skin_color=None, height_in_meters='2'),
Person(name='李明', hair_color=None, skin_color=None, height_in_meters='1.7')
]示例选择器(Example selectors)
一旦我们有了示例数据集,就需要考虑提示中应该有多少个示例。关键的权衡是,更多的示例通常会提高性能,但更大的提示会增加成本和延迟。超过某个阈值,太多示例可能会开始混淆模型。
找到正确数量的示例在很大程度上取决于模型、任务、示例的质量以及成本和延迟限制。有趣的是,模型越好,它需要精准的示例就越少。但其实,最佳的方法是使用不同数量的示例进行一些实验。
若此时我们有【大量】的示例数据集。对于大模型来说,就没必要全部使用与参考。我们需要有一种方法可以根据给定的输入,从数据集中选择示例。
在 LangChain 中,示例选择器就可以帮我们从一组【示例的集合】中根据具体策略选择正确的【示例子集】构建少样本提示。
选择策略有:
-
Length :根据特定【长度】内可以容纳的数量选择示例。
-
Similarity :使用输入和示例之间的【语义相似性】来决定选择哪些示例。
-
MMR :使用输入和示例之间的【最大边际相关性】来决定要选择哪些示例。
-
Ngram :使用输入和示例之间的【ngram 重叠】来决定要选择哪些示例。
这些其实都是自然语言处理(NLP)里的相似性衡量问题。
按长度选择示例 (Length)
当我们担心构造提示时,将超过上下文窗口长度,根据特定长度内可以容纳的数量选择示例。对于较长的输⼊,它将选择更少的示例来包含;而对于较短的输入,它将选择更多示例。
实现按长度选择示例的示例选择器是:
Class langchain_core.example_selectors.length_based.LengthBasedExampleSelector 类,其参数如下:
-
example_prompt : PromptTemplate,用于格式化示例的提示模板。
-
Examples : 模板所需的示例列表。
-
max_length : 提示的最大程度,超过该长度将剪切示例。
-
get_text_length : 测量提示长度的方法。默认为字数统计。
#示例选择器------按长度选择示例
from sys import prefixfrom attr.validators import max_len
from langchain_core.example_selectors import LengthBasedExampleSelector
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate反义词示例集合
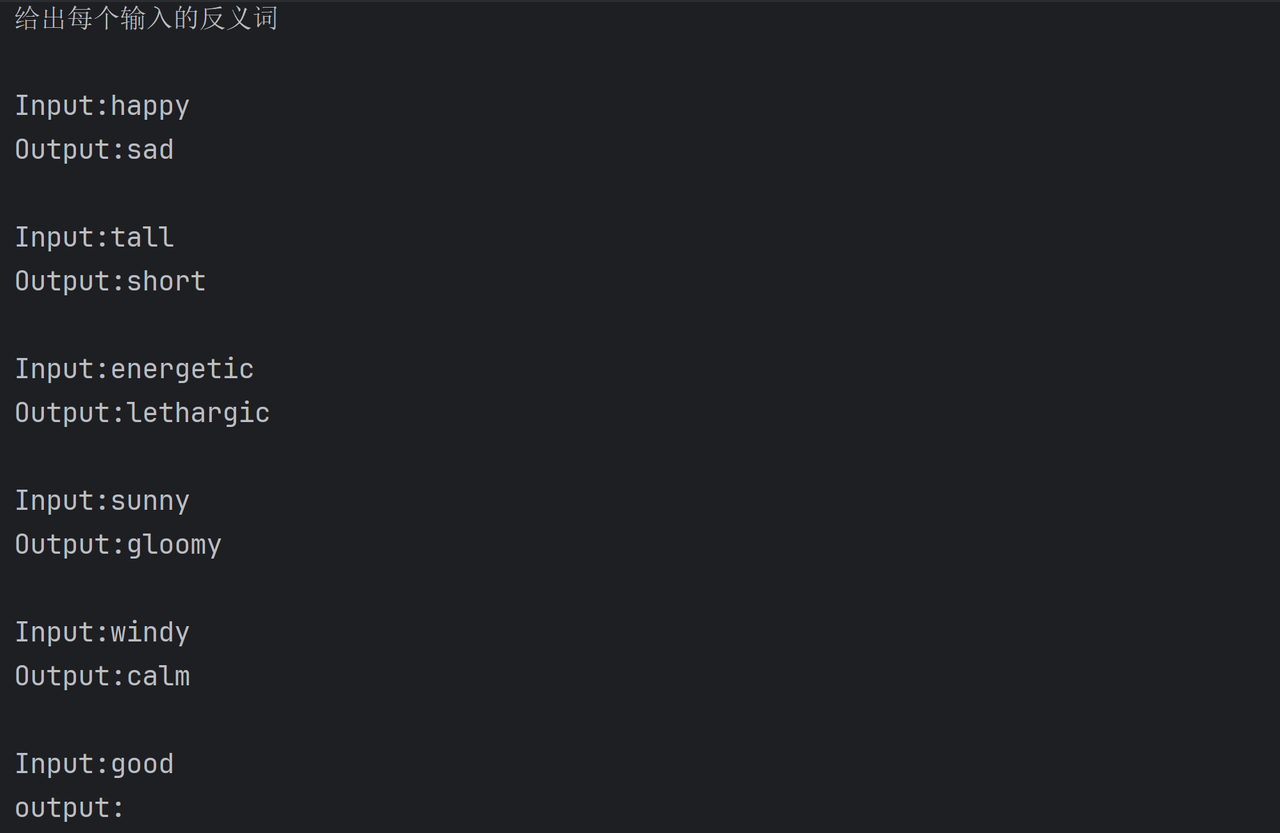
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]#定义示例模板(将示例格式化为文本)
example_template = PromptTemplate.from_template("Input:{input}\nOutput:{output}")#定义示例选择器(按照长度)
example_selector = LengthBasedExampleSelector(
examples=examples, #传入示例
example_prompt=example_template, #传入示例模板,将示例格式化为文本
max_length=25, #格式化文本的最大长度
# ⽤于获取字符串⻓度的函数,⽤于确定包含哪些⽰例。
# 如果没有指定,它是作为默认值提供的。
# 该函数返回⼀个整数,表⽰字符串中由换⾏符或空格分隔的"单词"数量
# get_text_length: Callable[[str], int] = lambda x: len(re.split("\n| ",x))
)#定义少样本提示模板
few_prompt_template = FewShotPromptTemplate(
example_selector = example_selector, #示例选择器
example_prompt=example_template, #示例模板
prefix="给出每个输入的反义词", #将prefix添加到示例输入之前
suffix = "Input:{adjective}\noutput:",#将suffix添加到输入之后
input_variables=["adjective"],
)print(few_prompt_template.invoke({"adjective": "good"}).to_messages()[0].content)
按语义相似性选择示例(Similarity)
什么是语义相似?它是衡量文本在【含义上】的接近程度。例如下述两段文本:
text1 = "我喜欢猫"
text2 = "我讨厌狗"
这两段文本表面相似度低,但语义上都是表达对动物的态度。
再例如:
text1 = "苹果很甜"
text2 = "苹果市值创新高"
"苹果"可以指水果或公司,语义相似可以解决一词多义问题,因此这两段文本语义上不相似。
LangChain 能根据输入和示例之间的语义相似性来决定选择哪些示例,它通过查找与输入具有最大余弦相似性的嵌入式示例来实现这一点。
实现按语义相似性选择示例的示例选择器是:
class langchain_core.example_selectors.semantic_similarity.SemanticSimilarityExampleSelector 类,
内置方法:
- from_examples() :根据示例集生成语义相似示例选择器
输入:
-
examples :示例列表
-
embeddings :初始化的嵌入 API 接口,如 OpenAIEmbeddings()
-
vectorstore_cls :向量存储数据库接口类。
-
k :最终要选择的示例的数量。默认值为 4。
输出:语义相似性示例选择器
#示例选择器------按语义相似性
from sys import prefix
from attr.validators import max_len
from langchain_chroma import Chroma
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
from langchain_openai import OpenAIEmbeddings
# 反义词⽰例集合
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
#定义示例模板(将示例格式化为文本)
example_template = PromptTemplate.from_template("Input:{input}\nOutput:{output}")
#定义示例选择器(按照语义相似性)
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples, #示例
OpenAIEmbeddings(model="text-embedding-3-large"), #嵌入式类(用于生成向量)
Chroma, #存储向量:向量数据库
k=2, #生成示例的数量
)
#定义少样本提示模板
few_prompt_template = FewShotPromptTemplate(
example_selector = example_selector, #示例选择器
example_prompt=example_template, #示例模板
suffix = "Input:{adjective}\noutput:",#将suffix添加到输入之后
input_variables=["adjective"],
)
print(few_prompt_template.invoke({"adjective": "good"}).to_messages()[0].content)按最大边际相关性选择示例(MMR)
什么是最大边际相关性?它是一种重新排序算法,它使用语义相似性作为基础工具,从一个候选集中挑选出一组既能代表查询主题又彼此多样化的结果。
MMR(Maximum Marginal Relevance,最大边际相关性) 是 LangChain 中用于「优化相似性检索结果」的核心算法 ------ 它解决了纯语义相似度检索的痛点(比如返回结果高度重复),能在「相关性」和「多样性」之间做平衡。
听起来好像和语义相似性类似,用一个例子看下两者的区别:
【语义相似性】就像面试官衡量每个应聘者与职位要求的匹配度。他会给每个应聘者打一个分数。
【最大边际相关性】就像团队经理(MMR算法)要组建一个团队。目标是选出一组"精华"结果,
而不是一个单一结果:
每个成员都要满足基本职位要求(满足相关性)。
但经理不希望团队里全是只会一种技能的程序员。他需要前端、后端、算法、测试等不同专长的人,以确保团队能力全面、减少冗余(新颖性/多样性)。
经理的策略是:先招一个最匹配的技术大牛(第⼀步),然后接下来招的人,既要技术达标,又要和已招的人技能互补(迭代过程)。
了解下使用最大边际相关性的场景,更能让我们理解其概念:
语义相似性使用场景:搜索引擎的基础排序、重复检测、聚类、语义搜索。
MMR 使用场景:
-
推荐系统:推荐与用户兴趣相关但又不同类型的物品,避免"信息茧房"。
-
文档摘要:从长文档中选择能代表主旨又包含不同信息的句子,避免摘要内容重复。
-
RAG (检索增强生成):在从知识库检索完一堆相关文档后,使用 MMR 进行去重和多样化筛选,再交给LLM生成答案,能有效提升答案质量和减少幻觉。
实现:
LangChain 提供了按最大边际相关性选择示例的能力,该示例选择器是:
Class langchain_core.example_selectors.semantic_similarity.MaxMarginalRelevanceExampleSelector 类,
内置方法:
from_examples() :根据示例集生成 MMR 示例选择器
输入:
-
examples :示例列表
-
embeddings :初始化的嵌入 API 接口,如 OpenAIEmbeddings()
-
vectorstore_cls :向量存储数据库接口类。
-
k :最终要选择的示例的数量。默认值为 4。
输出:MMR 示例选择器
#示例选择器------MMR
from sys import prefix
from attr.validators import max_len
from langchain_chroma import Chroma
from langchain_core.example_selectors import MaxMarginalRelevanceExampleSelector
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
from langchain_openai import OpenAIEmbeddings
# 反义词⽰例集合
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
#定义示例模板(将示例格式化为文本)
example_template = PromptTemplate.from_template("Input:{input}\nOutput:{output}")
#定义示例选择器(MMR)
example_selector = MaxMarginalRelevanceExampleSelector.from_examples(
examples, #示例
OpenAIEmbeddings(model="text-embedding-3-large"), #嵌入式类(用于生成向量)
Chroma, #存储向量:向量数据库
k=2, #生成示例的数量
)
#定义少样本提示模板
few_prompt_template = FewShotPromptTemplate(
example_selector = example_selector, #示例选择器
example_prompt=example_template, #示例模板
suffix = "Input:{adjective}\noutput:",#将suffix添加到输入之后
input_variables=["adjective"],
)
print(few_prompt_template.invoke({"adjective": "good"}).to_messages()[0].content)通过语义 ngram 重叠选择示例(Ngram)
什么是**【** ngram 】?ngram 指一个文本序列中连续的 n 个词(word) 或字符(character)。
什么是**【** ngram 重叠】?通过计算它们之间共同拥有的 ngram 数量来一种衡量两段文本相似度的方法。
例如下述两段文本:
text1 = "苹果手机很好用" (分词后: 苹果 手机 很 好用 )
text2 = "这款手机很好用" (分词后: 这款 手机 很 好用 )
这两段文本单词重复度很高,连续三个词的相同的情况也存在,因此 ngram 重叠高。
再看个例子:
text1 = 苹果手机很好用" (分词后: 苹果 手机 很 好用 )
text2 = "iPhone 非常不错" (分词后: iPhone 非常 不错 )
这两段文本在含义上非常相似,但它们的 ngram 重叠度为 0。
因此,传统 ngram 重叠是一种表面形式的匹配。它只关心词是否完全一样,但对于同义词却无法处理。
什么是【语义 ngram 重叠】?不再比较词本身,而是比较词背后的语义向量(Embedding)。也就是说,它不是看两个词 苹果 和 iPhone 的字面是否相同,而是计算它们在语义空间中的向量是否相似。如果相似度超过某个阈值,就认为它们"重叠"了。还是看这个例子:
text1 = "苹果手机很好用" (分词后: 苹果 手机 很 好用 )
text2 = "iPhone 非常不错" (分词后: iPhone 非常 不错 )
计算 苹果 和 iPhone 的向量相似度 → 得分 0.95 (很高,视为重叠)
计算 手机 和 iPhone 的向量相似度 → 得分 0.88 (很高,但可能不会同时计分,取决于算法设计,避免重复计算)
计算 很 和 非常 的向量相似度 → 得分 0.90 (很高,视为重叠)
计算 好用 和 不错 的向量相似度 → 得分 0.82 (很高,视为重叠)
最终,语义上的 nigram 重叠度可能为 3 或 4(非常相似!)。
那么语义 ngram 重叠的使用场景是什么?语义 ngram 重叠常用于需要更精准语义评估的场景,例如剽窃检测 , 能够发现那些改换了词汇但保留了核心思想的"智能"剽窃。
LangChain 实现按语义 ngram 重叠选择示例的示例选择器是:
Class langchain_community.example_selectors.ngram_overlap.NGramOverlapExampleSelector 类,
其参数如下:
-
example_prompt :PromptTemplate,用于格式化示例的提示模板。
-
examples :模板所需的示例列表。
-
threshold :算法亭子的阈值。默认设置为 -1.0。
对于负阈值:按 重叠分数 对示例进行排序,但不排除任何示例。
对于等于 0.0 的阈值:按 重叠分数 进行排序,并排除与输入没有 ngram 重叠的示例。
对于大于 1.0 的阈值:排除所有示例,并返回一个空列表。
#示例选择器------ngram重叠度检测
from sys import prefix
from attr.validators import max_len
from langchain_chroma import Chroma
from langchain_community.example_selectors import NGramOverlapExampleSelector
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
from langchain_openai import OpenAIEmbeddings
# 翻译⽰例
examples = [
{"input": "See Spot run.", "output": "看⻅Spot跑。"},
{"input": "My dog barks.", "output": "我的狗叫。"},
{"input": "Spot can run.", "output": "Spot可以跑。"},
]
#定义示例模板(将示例格式化为文本)
example_template = PromptTemplate.from_template("Input:{input}\nOutput:{output}")
#定义示例选择器(ngram)
example_selector = NGramOverlapExampleSelector(
examples=examples, #示例
example_prompt=example_template, #示例模板
threshold=0, #阈值
#阈值如果为负数:表示将不相干的示例(相似度为0的示例)也筛选出来
#阈值=0.0:表示输出的示例是与输入有关的
#阈值>=1.0:表示排除所有示例,返回空列表
)
#定义少样本提示模板
few_prompt_template = FewShotPromptTemplate(
example_selector = example_selector, #示例选择器
example_prompt=example_template, #示例模板
suffix = "Input:{sentence}\noutput:",#将suffix添加到输入之后
input_variables=["sentence"],
)
#示例输出的顺序是按照相似度进行排序的
print(few_prompt_template.invoke({"sentence": "See Spot run fast."}).to_messages()[0].content)4.输出解析器(Output parsers)
负责获取模型的输出,并将输出转换为更结构化的格式。当使用 LLM 生成结构化数据或规范化聊天模型和 LLM 的输出时,这很有用。
大型语言模型(LLM)的输出本质上是非结构化的文本。但在构建应用程序时,我们通常希望得到结构化的、机器可读的数据,这样可以将其转换为更适合下游任务的格式,比如:
-
JSON 对象
-
Python 字典或列表
-
一个特定的 Pydantic 模型实例
-
一个简单的布尔值或字符串枚举
输出解析器的作用就是架起这座桥梁:它们将 LLM 的非结构化文本输出转换为结构化格式。这使得与LLM 的交互从"模糊的文本对话"变成了"精确的数据 API 调用",是构建可靠、高效 LLM 应用不可或缺的组件。
解析文本输出
其实对于使用 StrOutputParser 输出解析器输出文本,它也实现了标准的 Runnable 接口。示例如下:
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
model = ChatOpenAI(model="gpt-4o-mini")
chain = model | StrOutputParser()
for chunk in chain.stream("写⼀⾸夏天的诗词,50字以内。"):
print(chunk, end="|")输出如下:
|炎|夏|骄|阳|照|,|绿|树|映|蓝|天|。|
|蝉|鸣|声|声|烈|,|荷|塘|映|清|鲜|。|
|微|风|拂|面|过|,|凉|意|透|心|间|。|
|烦|忧|随|汗|去|,|畅|享|此|夏|欢|。||若是不使用输出解析器,而是直接得到聊天模型返回的 AIMessage,文本内容则需要从消息中的content 字段获取。
解析结构化对象输出
要输出结构化对象,需要用到的输出解析器是 PydanticOutputParser 。
class langchain_core.output_parsers.pydantic.PydanticOutputParser 类,其参数如下:
- pydantic_object :要解析的 pydantic 模型。
内置方法:
-
invoke() :将单个输入转换为输出。
-
get_format_instructions() → str :重要!!
-
作用:生成一个指令字符串,这个字符串会被添加到发送给 LLM 的提示(Prompt)的末尾。
-
目的:告诉 LLM 应该以什么样的格式返回它的响应。例如,"请将你的回复封装在 XML 标签中"或"请以 JSON 格式输出,包含 'name' 和 'age' 两个字段"。
代码示例如下:
#自定义输出解析器
from typing import Optional, List
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
#定义模型
model=ChatOpenAI(model="gpt-4o-mini")
#定义结构化对象
class Joke(BaseModel):
setup: str=Field(description="这个笑话的主题") #setup:场景构建/前置条件
punchline: str=Field(description="这个笑话的妙处") #punchline:点睛之笔
rating: Optional[int]=Field(default=None,description="从1-10分,给这个笑话的评分") #rating:效果评分
#自定义输出解析器
parser = PydanticOutputParser(pydantic_object=Joke)
# print(parser.get_format_instructions())
#定义提示词模板
prompt = PromptTemplate(
template="回复用户的问题。\n返回结构说明:{format_instructions}。\n用户输入的问题:{query}",
partial_variables={"format_instructions":parser.get_format_instructions()},
input_variables=["query"],
)
#定义链
chain = prompt | model | parser
print(chain.invoke("请结合篮球和鸡,给我讲一个笑话"))
除了上面讲的文本、对象、JSON解析器,其实 LangChain 官方还提供了更多类型的解析器,如:
-
XML 解析器: XMLOutputParser
-
Yaml 解析器: YamlOutputParser
-
CSV 解析器: CommaSeparatedListOutputParser
-
枚举解析器: EnumOutputParser
-
日期解析器: DatetimeOutputParser 等等
除此之外,LangChain 还支持我们自定义输出解析器,以将模型输出结构化为自定义格式。
官方手册:https://reference.langchain.com/python/langchain_core/output_parsers/